Freunde, guten Tag.
Es besteht ein klares Verständnis, dass die Mehrheit der ICO-Projekte im Wesentlichen ein immaterieller Vermögenswert ist. Das ICO-Projekt ist kein Mercedes-Benz Auto - es fährt unabhängig davon, wer es liebt oder nicht. Der Haupteinfluss auf das ICO wird durch die Stimmung der Menschen bestimmt - sowohl die Haltung gegenüber dem Gründer / Gründer des ICO als auch das Projekt selbst.
Es wäre schön, die Haltung der Menschen gegenüber dem Gründer des ICO und / oder des ICO-Projekts irgendwie zu messen. Welches wurde getan. Der Bericht ist unten.
Das Ergebnis war ein Tool zum Sammeln positiver / negativer Stimmungen aus dem Internet, insbesondere von Twitter.
Meine Umgebung ist Windows 10 x64, verwendet die Python 3-Sprache im Spyder-Editor in Anaconda 5.1.0, einer kabelgebundenen Netzwerkverbindung.
Datenerfassung
Ich werde die Stimmung von Twitter-Posts bekommen. Zuerst werde ich herausfinden, was der Gründer des ICO jetzt tut und wie positiv er darauf am Beispiel eines Paares berühmter Persönlichkeiten reagiert.
Ich werde die Python Tweepy Bibliothek verwenden. Um mit Twitter arbeiten zu können, müssen Sie sich als Entwickler registrieren, siehe twitter / . Holen Sie sich Twitter-Zugriffskriterien.
Der Code lautet wie folgt:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
Jetzt können wir uns an die Twitter-API wenden und etwas davon erhalten oder umgekehrt. Die Sache wurde Anfang August gemacht. Sie benötigen einige Tweets, um das aktuelle Projekt des Gründers zu finden. So gesucht:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
In searchinfo ersetzen wir den notwendigen Namen und leiten weiter. Das Ergebnis wurde in der Datei results.xlsx excel gespeichert.
Kreativ
Dann habe ich beschlossen, kreativ zu machen. Wir müssen die Projekte des Gründers finden. Projektnamen sind Eigennamen und werden großgeschrieben. Angenommen, dies scheint auch wahr zu sein, dass in jedem Tweet ein Großbuchstabe geschrieben wird: 1) der Name des Gründers, 2) der Name seines Projekts, 3) das erste Wort des Tweets und 4) fremde Wörter. Die Wörter 1 und 2 werden häufig in Tweets gefunden, und 3 und 4 sind selten. In der Häufigkeit sind wir 3 und 4 und werden ausgesondert. Ja, es stellte sich auch heraus, dass die Links häufig in Tweets vorkommen. 5) Wir werden sie auch entfernen.
Es stellte sich so heraus:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
Kreative Datenanalyse
In der Namensvariablen haben wir die Wörter und in der Variablen X die Stellen, an denen sie erwähnt werden. Tabelle X "Ausschalten" - Anzahl der Referenzen abrufen. Wir löschen Wörter, die selten erwähnt werden. In Excel speichern. Und in Excel erstellen wir ein schönes Balkendiagramm mit Informationen darüber, wie oft welche Wörter in welcher Abfrage erwähnt werden.
Unsere Super-ICO-Stars sind Le Minh Tam und Mike Novogratz. Diagramme:
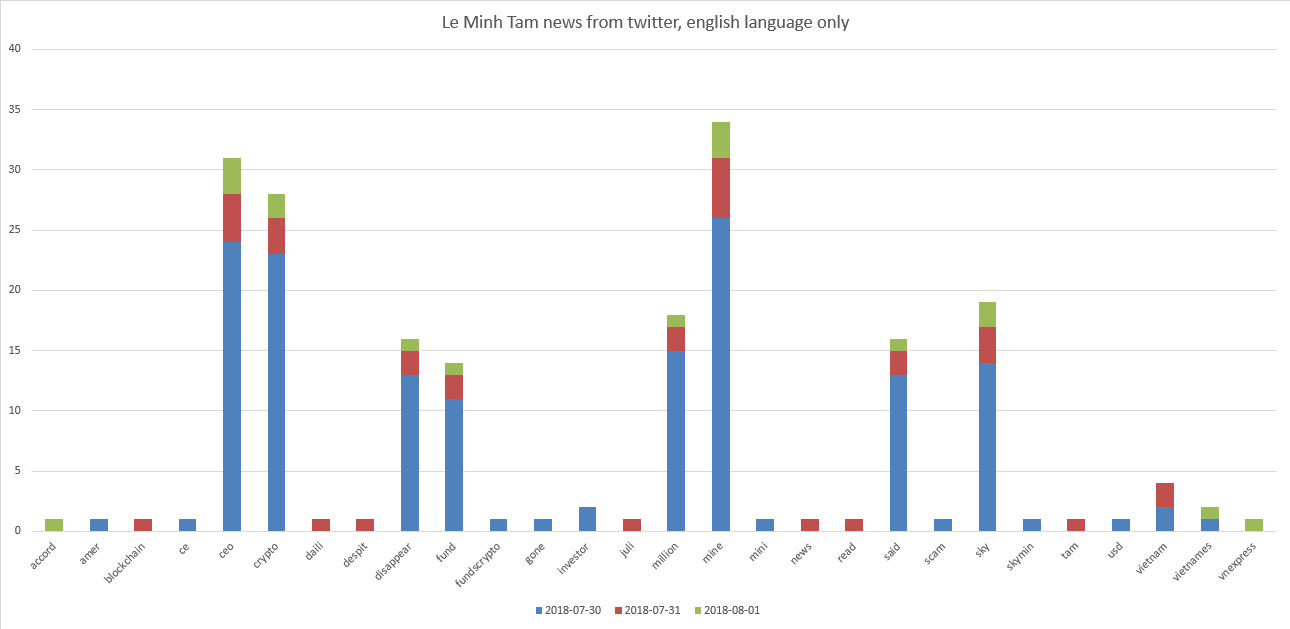
Es ist zu sehen, dass Le Minh Tam mit "CEO, Krypto, Mine, Himmel" verwandt ist. Und ein wenig "verschwinden, finanzieren, Millionen".
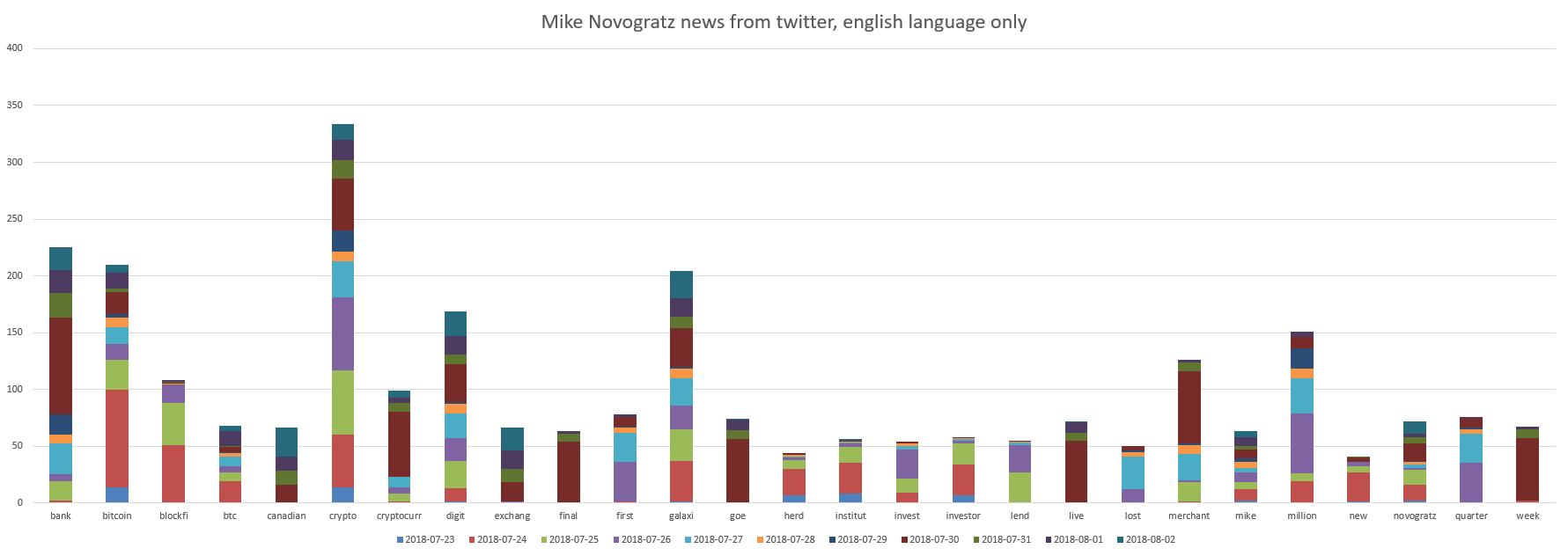
Es ist zu sehen, dass Mike Novogratz mit "Bank, Bitcoin, Krypto, Ziffer, Galaxie" verwandt ist.
Daten von X können in ein neuronales Netzwerk eingegossen werden und es kann lernen, alles zu bestimmen, aber Sie können:
Datenanalyse
Und dann hören wir auf herumalbern Seien Sie kreativ und verwenden Sie die Python TextBlob- Bibliothek. Die Bibliothek ist ein Wunder, wie gut.
Kluge Leute sagen, dass sie:
- Markieren Sie Sätze
- Teilemarkierung durchführen
- Stimmungen analysieren (dies ist für uns unten nützlich),
- Klassifizierung (naive Bayes, Entscheidungsbaum),
- übersetzen und definieren Sie die Sprache mit Google Translate,
- Tokenisierung durchführen (Text in Wörter und Sätze aufteilen),
- die Häufigkeit von Wörtern und Phrasen identifizieren,
- Parsen
- n-Gramm erkennen
- Beugung \ Deklination \ Konjugation von Wörtern (Pluralisierung und Singularisierung) und Lemmatisierung offenbaren,
- korrekte Schreibweise.
Die Bibliothek ermöglicht das Hinzufügen neuer Modelle oder Sprachen über Erweiterungen und verfügt über eine WordNet-Integration. Mit einem Wort, NLP ist ein Wunderkind .
Wir haben die Suchergebnisse in der obigen Datei results.xlsx gespeichert. Laden Sie es herunter und gehen Sie es mit der TextBlob-Bibliothek durch, um die Stimmung zu beurteilen:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
Großartig! Ein paar Codezeilen und ein Knall ergeben sich.
Ergebnisübersicht
Es stellt sich heraus, dass Anfang August 2018 die in der Abfrage „Le Minh Tam“ gefundenen Tweets etwas zeigen, das sich in den Tweets mit einer durchschnittlichen Bewertung aller Tweets minus 0,13 negativ widerspiegelt. Wenn wir uns die Tweets selbst ansehen, werden wir zum Beispiel sehen, dass der CEO von Crypto Mining mit 35 Millionen US-Dollar verschwunden sein soll. Le Minh Tam, CEO des Crypto-Bergbauunternehmens Sky Mining, hat ...
Und Mike Novogratz 'Freund hat etwas getan, das sich in den Tweets positiv widerspiegelte, mit einer durchschnittlichen Bewertung aller Tweets plus 0,03 . Sie können es so interpretieren, dass sich alles ruhig vorwärts bewegt.
Angriffsplan
Für die Zwecke der ICO-Bewertung lohnt es sich, Informationen über die Gründer des ICO und über das ICO selbst aus verschiedenen Quellen zu überwachen. Zum Beispiel:
Plan zur Überwachung eines ICO:
- Erstellen Sie eine Liste mit den Namen der Gründer des ICO und des ICO selbst.
- Wir erstellen eine Liste von Ressourcen für die Überwachung,
- Wir machen einen Roboter, der Daten für jede Zeile von 1 sammelt - für jede Ressource von 2, Beispiel oben,
- Wir machen einen Roboter, der alle 3 auswertet, das obige Beispiel,
- Speichern Sie die Ergebnisse 4 (und 3),
- Wiederholen Sie die Schritte 3 bis 5 Stunden auf automatisierte Weise. Die Ergebnisse der Bewertung können irgendwo veröffentlicht / gesendet / gespeichert werden.
- Wir überwachen automatisch die Sprünge in der Bewertung in Absatz 6. Wenn es Sprünge in der Bewertung in Absatz 6 gibt, ist dies eine Gelegenheit, eine zusätzliche Studie darüber durchzuführen, was fachmännisch geschieht. Und Panik auslösen oder umgekehrt freuen.
So etwas in der Art.
PS Nun, oder kaufen Sie diese Informationen, zum Beispiel hier thomsonreuters