Am 19. September
fand in Moskau
die erste thematische Metapher HUG (Highload ++ User Group)
statt , die sich mit Microservices befasste. Der Bericht „Betrieb von Microservices: Größe ist wichtig, auch wenn Sie über Kubernetes verfügen“ wurde geliefert, in dem wir Flants umfassende Erfahrung im Betrieb von Projekten mit Microservice-Architektur teilten. Zunächst wird es allen Entwicklern nützlich sein, die darüber nachdenken, diesen Ansatz in ihrem aktuellen oder zukünftigen Projekt anzuwenden.

Wir präsentieren das
Video mit dem Bericht (50 Minuten, viel informativer als der Artikel) sowie dem Hauptauszug daraus in Textform.
NB: Video und Präsentation sind ebenfalls am Ende dieser Veröffentlichung verfügbar. Einführung
Normalerweise hat eine gute Geschichte eine Handlung, eine Haupthandlung und eine Auflösung. Dieser Bericht ist eher eine Verschwörung und tragisch. Es ist auch wichtig zu beachten, dass es einen Blick auf die
Funktionsweise von Microservices bietet.
Ich werde mit einem solchen Zeitplan beginnen, dessen Autor (2015) Martin Fowler war:
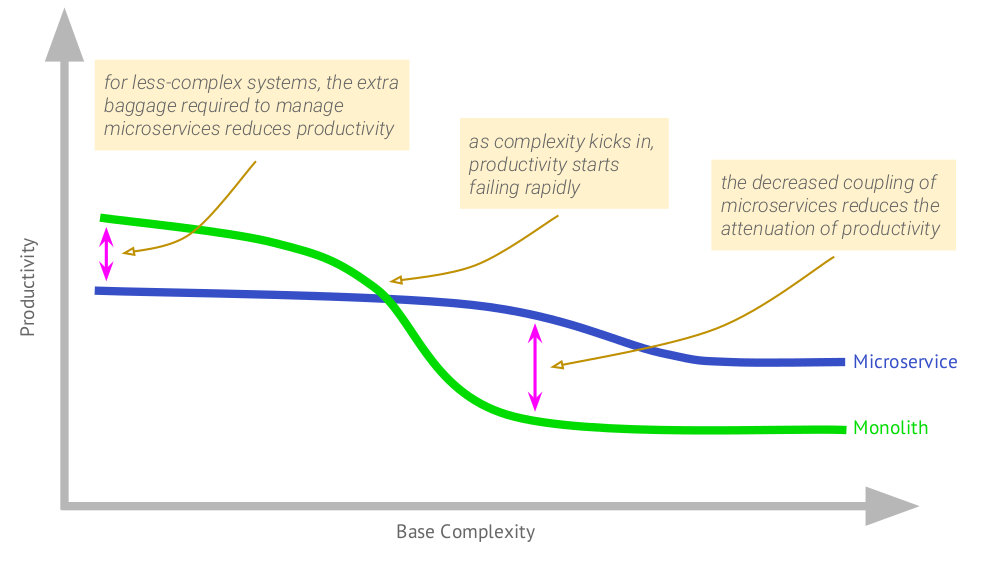
Es zeigt, wie bei einer monolithischen Anwendung, die einen bestimmten Wert erreicht hat, die Produktivität der Arbeit abnimmt. Microservices unterscheiden sich darin, dass die anfängliche Produktivität bei ihnen geringer ist. Mit zunehmender Komplexität ist jedoch die Verschlechterung der Effizienz für sie nicht so spürbar.
Ich werde dieses Diagramm für den Fall der Verwendung von Kubernetes ergänzen:
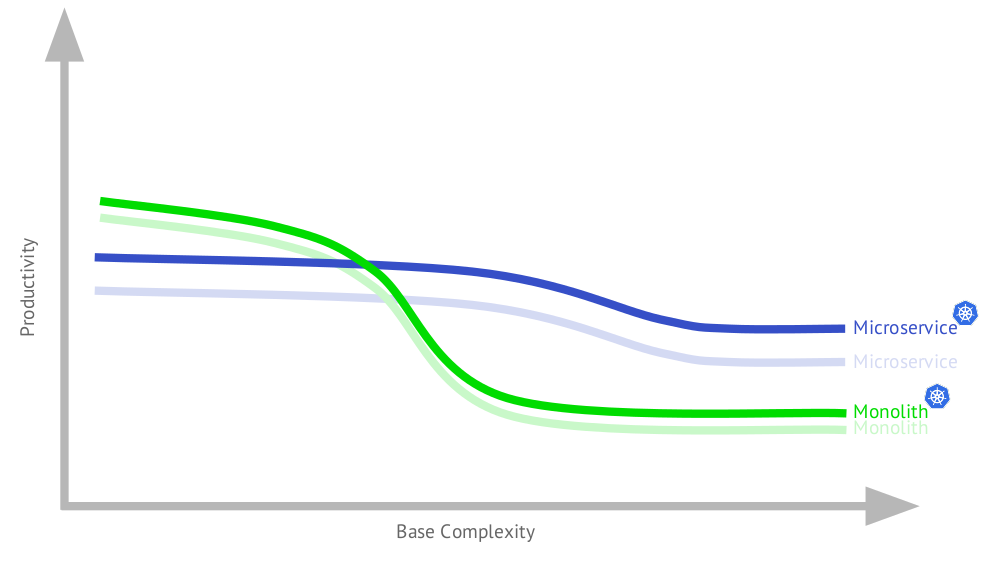
Warum wurde die Microservice-Anwendung besser? Weil eine solche Architektur ernsthafte Architekturanforderungen stellt, die wiederum perfekt von Kubernetes Funktionen abgedeckt werden. Andererseits wird ein Teil dieser Funktionalität auch für den Monolithen nützlich sein, insbesondere aus dem Grund, dass der typische Monolith heute nicht gerade ein Monolith ist (Details werden im Bericht weiter unten beschrieben).
Wie Sie sehen können, unterscheidet sich der endgültige Zeitplan (wenn sowohl monolithische als auch Microservice-Anwendungen in der Infrastruktur mit Kubernetes vorhanden sind) nicht wesentlich vom Original. Als nächstes werden wir über Anwendungen sprechen, die mit Kubernetes ausgeführt werden.
Nützlicher und schädlicher Microservice
Und hier die Hauptidee:

Was ist eine
normale Microservice-Architektur? Es sollte Ihnen echte Vorteile bringen und die Arbeitseffizienz steigern. Wenn Sie zum Diagramm zurückkehren, finden Sie hier Folgendes:
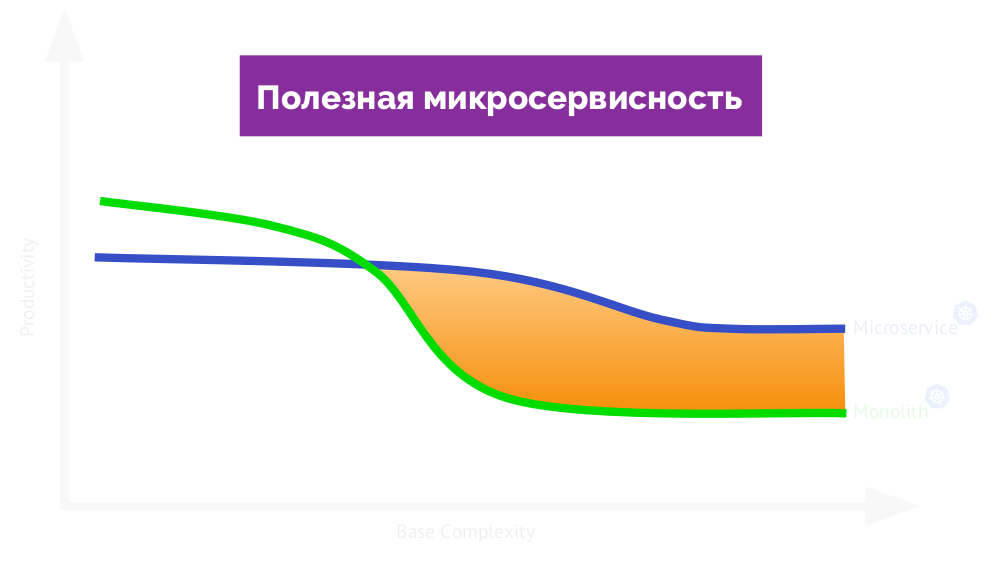
Wenn Sie es als
nützlich bezeichnen , wird auf der anderen Seite des Diagramms ein
schädlicher Mikrodienst angezeigt (der die Arbeit beeinträchtigt):
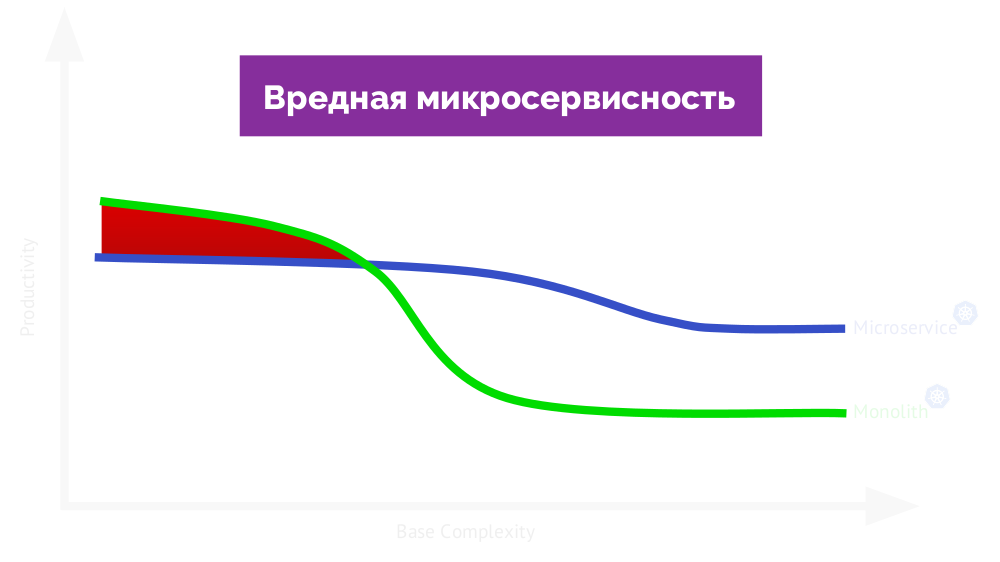
Zurück zur „Hauptidee“: Lohnt es sich überhaupt, meiner Erfahrung zu vertrauen? Seit Anfang dieses Jahres habe ich mir
85 Projekte angesehen . Nicht alle von ihnen waren Mikroservices (ungefähr ein Drittel bis die Hälfte von ihnen besaßen eine solche Architektur), aber dies ist immer noch eine große Anzahl. Wir (Flant-Unternehmen) als Outsourcer sehen eine Vielzahl von Anwendungen, die sowohl in kleinen Unternehmen (mit 5 Entwicklern) als auch in großen (~ 500 Entwickler) entwickelt wurden. Ein weiteres Plus ist, dass wir sehen, wie diese Anwendungen im Laufe der Jahre leben und sich entwickeln.
Warum Microservices?
Auf die Frage nach den Vorteilen von Microservices hat der bereits erwähnte Martin Fowler eine
ganz konkrete Antwort :
- klare Grenzen der Modularität;
- unabhängige Bereitstellung;
- Wahlfreiheit der Technologie.
Ich habe viel mit Architekten und Softwareentwicklern gesprochen und gefragt, warum sie Microservices benötigen. Und stellte seine Liste ihrer Erwartungen zusammen. Folgendes ist passiert:
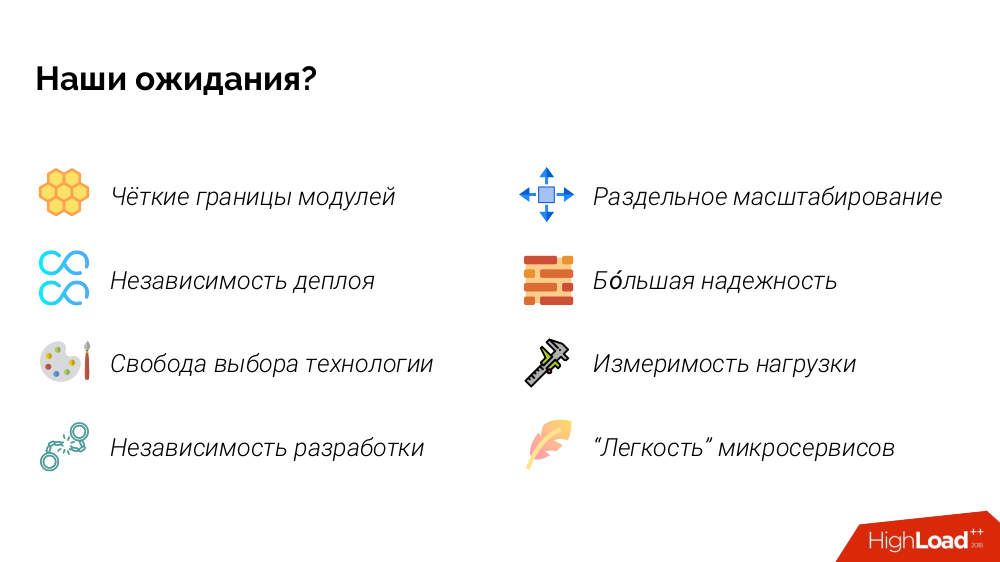
Wenn Sie einige der Punkte „in Empfindungen“ beschreiben, dann:
- klare Grenzen der Module: Hier haben wir einen schrecklichen Monolithen, und jetzt wird alles ordentlich in Git-Repositories angeordnet, in denen sich alles „in den Regalen“ befindet, nicht gemischt mit warm und weich;
- Bereitstellungsunabhängigkeit: Wir können Services unabhängig voneinander bereitstellen, damit die Entwicklung schneller verläuft (neue Funktionen parallel veröffentlichen).
- Entwicklungsunabhängigkeit: Wir können diesen Mikroservice diesem Team / Entwickler und dem anderen geben, damit wir uns schneller entwickeln können.
- Höhere Zuverlässigkeit: Wenn eine teilweise Verschlechterung auftritt (einer von 20 Mikrodiensten fällt aus), funktioniert nur eine Taste nicht mehr und das gesamte System funktioniert weiterhin.
Typische (schädliche) Microservice-Architektur
Um zu erklären, warum in Wirklichkeit nicht alles so ist, wie wir es erwarten, werde ich ein
kollektives Bild der Microservice-Architektur präsentieren, das auf Erfahrungen aus vielen verschiedenen Projekten basiert.
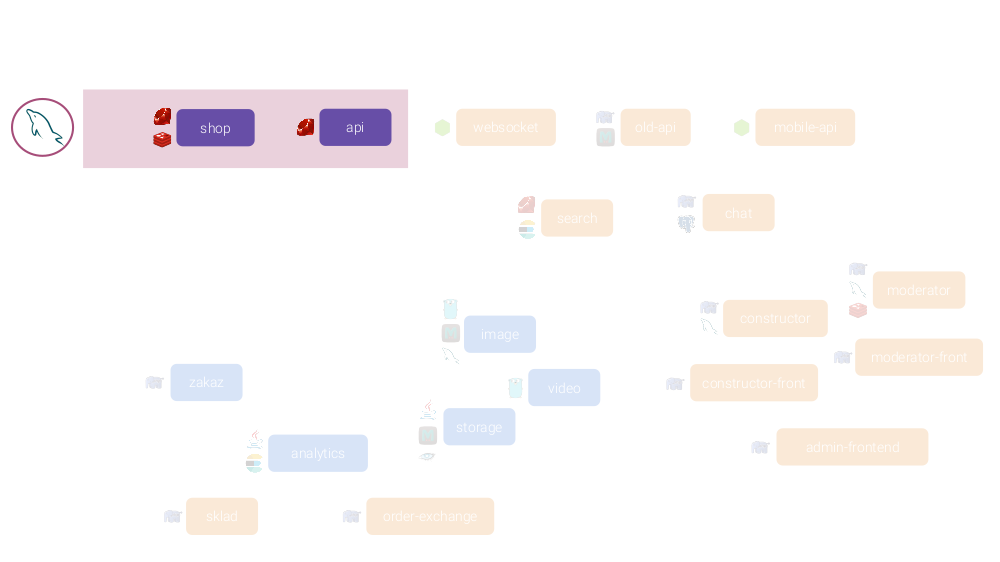
Ein Beispiel wäre ein abstrakter Online-Shop, der im Begriff ist, mit Amazon oder zumindest OZON zu konkurrieren. Die Microservice-Architektur sieht folgendermaßen aus:
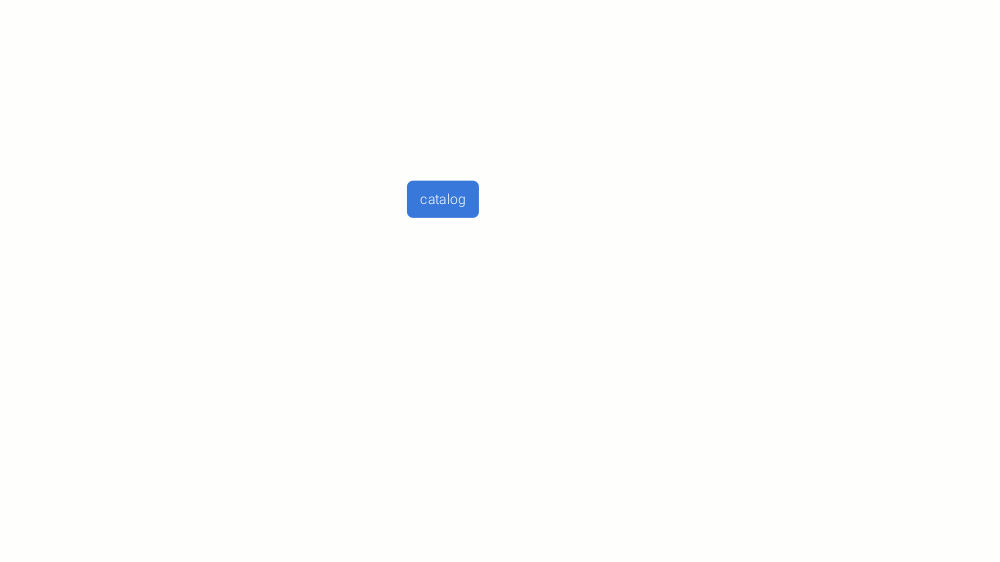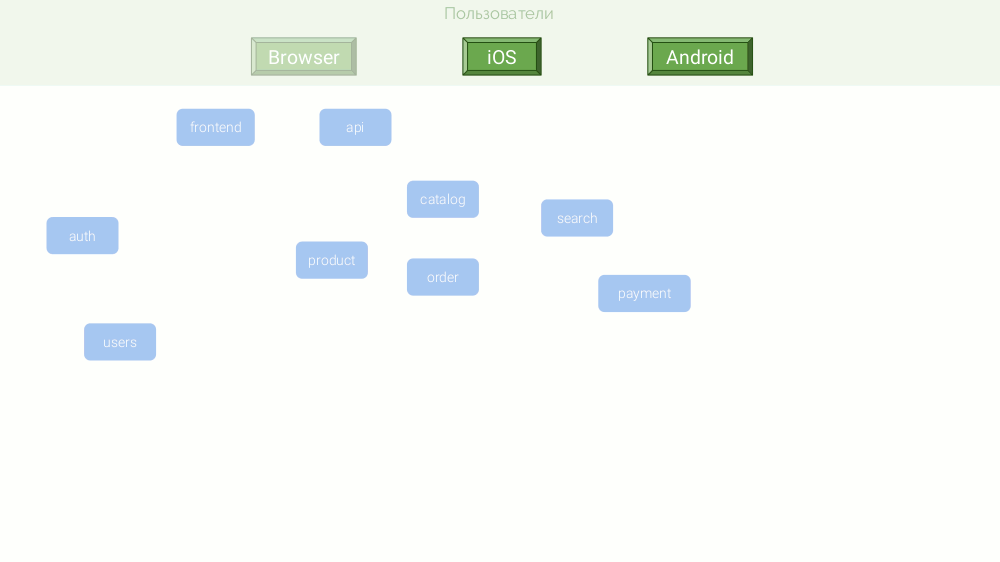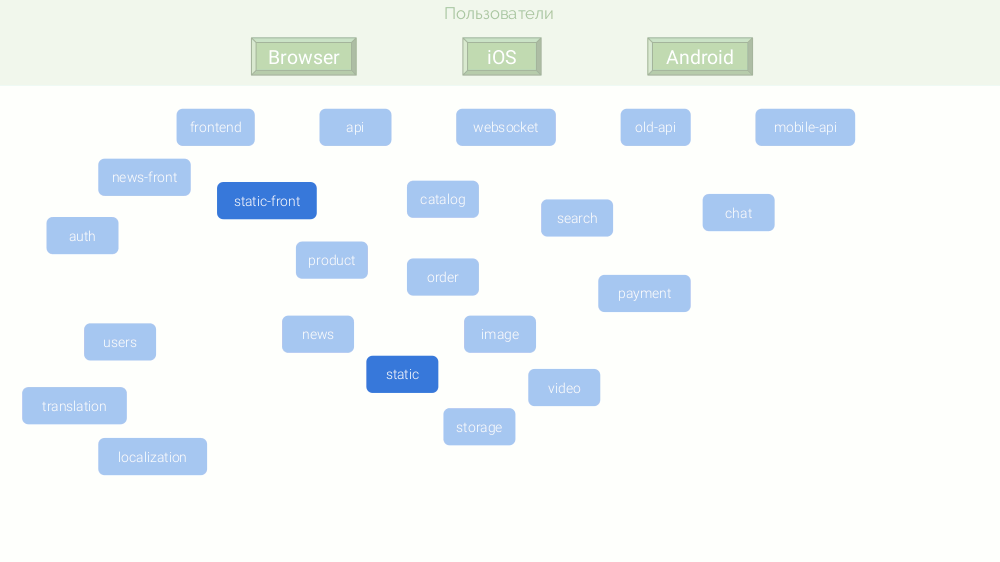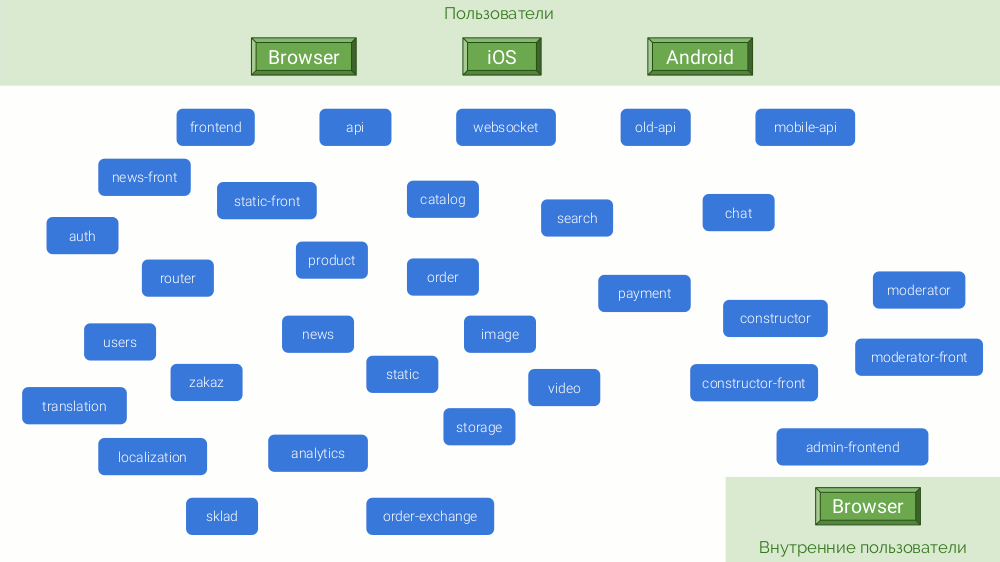
Aus einer Kombination von Gründen werden diese Mikrodienste auf verschiedenen Plattformen geschrieben:

Da jeder Mikrodienst autonom sein sollte, benötigen viele von ihnen eine eigene Datenbank und einen eigenen Cache. Die endgültige Architektur lautet wie folgt:
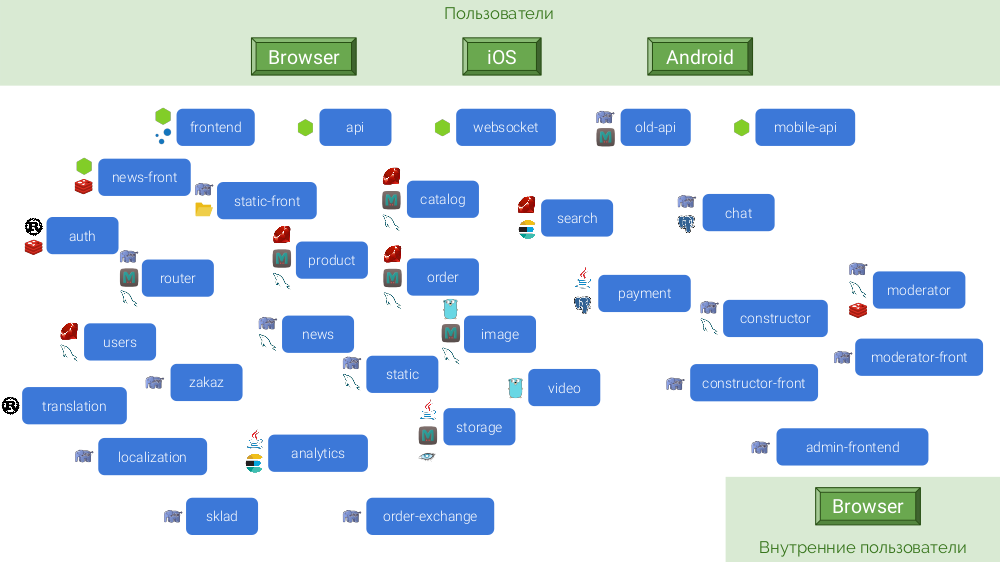
Was sind ihre Konsequenzen?
Fowler
hat einen Artikel zu diesem Thema - über die "Amortisation" für die Nutzung von Microservices:

Und wir werden sehen, ob unsere Erwartungen erfüllt werden.
Klare Grenzen von Modulen ...
Aber
wie viele Microservices müssen wir wirklich reparieren , um die Änderung einzuführen? Können wir überhaupt herausfinden, wie alles ohne einen verteilten Tracer funktioniert (schließlich wird jede Anfrage von der Hälfte der Microservices verarbeitet)?
Es gibt ein Muster mit einem
großen Schlammklumpen , aber hier erhalten wir einen verteilten Schlammklumpen. Um dies zu unterstützen, finden Sie hier ein Beispiel für den Ablauf von Abfragen:
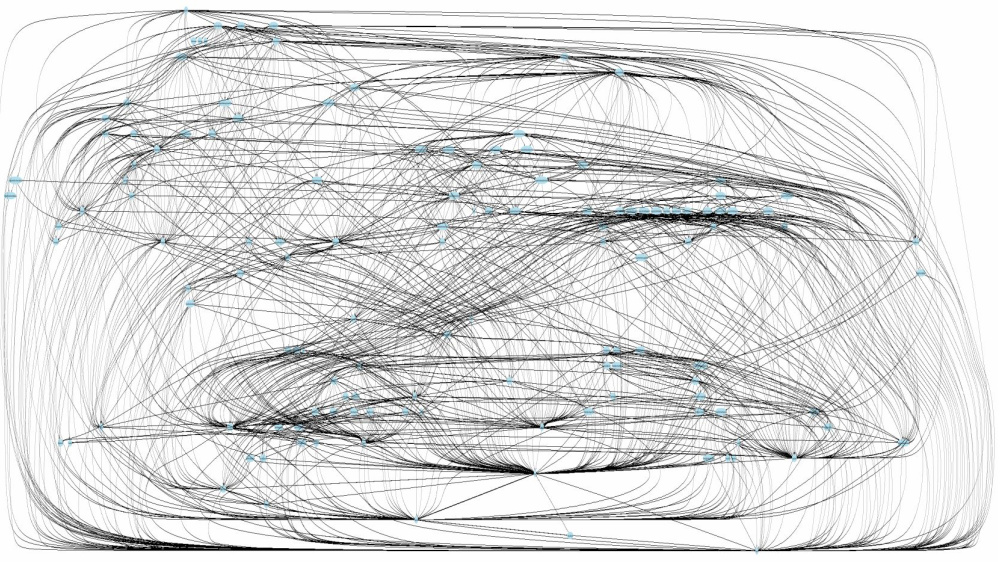
Bereitstellungsunabhängigkeit ...
Technisch wurde es erreicht: Wir können jeden Microservice separat rollen. In der Praxis müssen Sie jedoch berücksichtigen, dass
viele Microservices immer eingeführt werden, und wir müssen die
Reihenfolge ihrer Einführung berücksichtigen. Auf eine gute Weise müssen wir im Allgemeinen in einem separaten Schaltkreis testen, ob wir das Release in der richtigen Reihenfolge einführen.
Freiheit, Technologie zu wählen ...
Sie ist da. Es sei nur daran erinnert, dass Freiheit oft an Gesetzlosigkeit grenzt. Hier ist es sehr wichtig, keine Technologien zu wählen, nur um mit ihnen zu „spielen“.
Entwicklungsunabhängigkeit ...
Wie erstelle ich eine Testschaltung für die gesamte Anwendung (aus so vielen Komponenten)? Sie müssen es jedoch immer noch auf dem neuesten Stand halten. All dies führt dazu, dass die
tatsächliche Anzahl von Testschleifen , die wir im Prinzip enthalten können,
minimal ist .
Aber um all dies lokal bereitzustellen? .. Es stellt sich heraus, dass der Entwickler seine Arbeit oft unabhängig, aber zufällig erledigt, weil er warten muss, bis die Schaltung zum Testen freigegeben wird.
Separate Skalierung ...
Ja, aber es ist im Bereich des verwendeten DBMS begrenzt. In dem gegebenen Architekturbeispiel wird Cassandra keine Probleme haben, aber MySQL und PostgreSQL werden es haben.
Mehr Zuverlässigkeit ...
Nicht nur, dass der Ausfall eines Mikrodienstes häufig die ordnungsgemäße Funktion des gesamten Systems beeinträchtigt, es gibt auch ein neues Problem:
Es ist sehr schwierig, jeden Mikrodienst fehlertolerant zu machen . Da Microservices unterschiedliche Technologien verwenden (Memcache, Redis usw.), muss jeder über alles nachdenken und es implementieren, was natürlich möglich ist, aber enorme Ressourcen erfordert.
Messbarkeit der Last ...
Das ist wirklich in Ordnung.
Leichtigkeit von Mikrodiensten ...
Wir haben nicht nur einen enormen
Netzwerk-Overhead (DNS-Abfragen usw.), sondern auch aufgrund der vielen Unterabfragen begonnen,
die Daten zu
replizieren (Speicher-Caches), was zu einer erheblichen Speichermenge führte.
Und hier ist das Ergebnis der Erfüllung unserer Erwartungen:
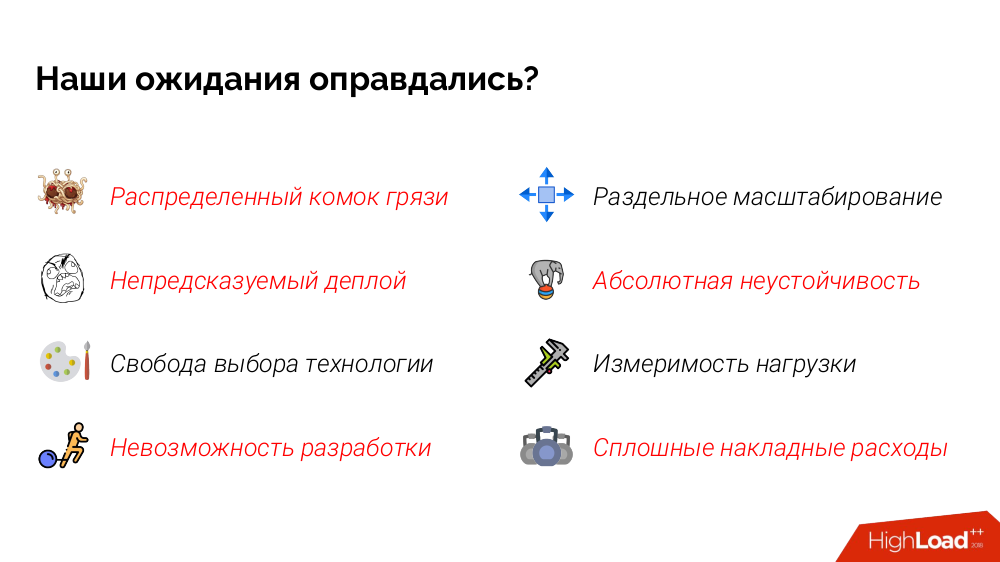
Aber das ist noch nicht alles!
Weil:
- Höchstwahrscheinlich brauchen wir einen Nachrichtenbus.
- Wie erstelle ich zum richtigen Zeitpunkt ein konsistentes Backup? Die einzige echte Option besteht darin, den Verkehr dafür auszuschalten. Aber wie geht das in der Produktion?
- Wenn wir über die Unterstützung mehrerer Regionen sprechen, ist die Organisation der Nachhaltigkeit in jeder Region eine sehr zeitaufwändige Aufgabe.
- Es besteht das Problem, zentralisierte Änderungen vorzunehmen. Wenn wir beispielsweise die Version von PHP aktualisieren müssen, müssen wir uns auf jedes Repository festlegen (und es gibt Dutzende davon).
- Die Zunahme der betrieblichen Komplexität ist exponentiell.
Was tun mit all dem?
Beginnen Sie mit einer monolithischen Anwendung . Die Erfahrung von Fowler
legt nahe, dass fast alle erfolgreichen Microservice-Anwendungen mit einem Monolithen begannen, der zu groß wurde und danach zerbrochen wurde. Gleichzeitig hatten fast alle Systeme, die von Anfang an als Microservice gebaut wurden, früher oder später ernsthafte Probleme.
Ein weiterer wertvoller Gedanke ist, dass Sie für ein erfolgreiches Projekt mit einer Microservice-Architektur
sowohl den Themenbereich als auch die Erstellung von Microservices sehr gut kennen sollten. Und der beste Weg, den Themenbereich zu kennen, ist die Herstellung eines Monolithen.
Aber was ist, wenn wir uns bereits in dieser Situation befinden?
Der erste Schritt zur Lösung eines Problems besteht darin, dem zuzustimmen und zu verstehen, dass es sich um ein Problem handelt, unter dem wir nicht länger leiden möchten.
Wenn wir im Fall eines überwucherten Monolithen (als wir keine Gelegenheit mehr hatten, Ressourcen dafür zu kaufen) ihn abschneiden, dann bekommen wir in diesem Fall das Gegenteil: Wenn übermäßiger Mikroservice nicht mehr hilft, sondern stört -
schneiden Sie den Überschuss ab und vergrößern Sie ihn !
Zum Beispiel für das oben diskutierte kollektive Bild ...
Befreien Sie sich von den zweifelhaftesten Microservices:

Kombinieren Sie alle Microservices, die für die Erstellung des Frontends verantwortlich sind:

... in einem Microservice, geschrieben in einer (modernen und normalen, wie Sie selbst denken) Sprache / Framework:

Es wird ein ORM (ein DBMS) und zunächst einige Anwendungen haben:
... im Allgemeinen kann dort viel mehr übertragen werden, nachdem das folgende Ergebnis erzielt wurde:

Darüber hinaus führen wir dies in Kubernetes in separaten Instanzen aus, was bedeutet, dass wir die Last weiterhin messen und separat skalieren können.
Zusammenfassen
Schauen Sie sich das Bild weiter an. Sehr oft entstehen all diese Probleme mit Microservices aufgrund der Tatsache, dass jemand seine Aufgabe übernommen hat, aber "Microservices spielen" wollte.
Im Wort "Microservices" ist der "Micro" -Teil überflüssig . Sie sind nur deshalb "mikro", weil sie kleiner als ein riesiger Monolith sind. Aber denken Sie nicht an sie als etwas Kleines.
Und für den letzten Gedanken zurück zum ursprünglichen Zeitplan:

Die an ihn geschriebene Notiz
(oben rechts) läuft darauf hinaus, dass die
Fähigkeiten des Teams, das Ihr Projekt erstellt, immer an erster Stelle stehen - sie spielen eine Schlüsselrolle bei Ihrer Wahl zwischen Microservices und einem Monolithen. Wenn das Team nicht über genügend Fähigkeiten verfügt, aber anfängt, Microservices zu entwickeln, wird die Geschichte definitiv fatal sein.
Videos und Folien
Video aus der Rede (~ 50 Minuten; leider vermittelt es nicht die zahlreichen Emotionen der Besucher, die die Stimmung des Berichts maßgeblich bestimmt haben, sondern wie es ist):
Präsentation des Berichts:
PS
Weitere Berichte in unserem Blog:
Sie könnten auch an folgenden Veröffentlichungen interessiert sein: