Heute werden wir über DevOps oder vielmehr hauptsächlich über Ops sprechen. Sie sagen, dass es nur sehr wenige Menschen gibt, die mit dem Automatisierungsgrad ihrer Abläufe zufrieden sind. Aber die Situation scheint reparabel zu sein. In diesem Artikel wird Nikolai Ryzhikov über seine Erfahrungen mit der Erweiterung von Kubernetes sprechen.

Das Material wurde auf der Grundlage von Nikolais Rede auf der Herbstkonferenz DevOops 2017 vorbereitet. Unter dem Schnitt - Video- und Textprotokoll des Berichts.
Derzeit arbeitet Nikolai Ryzhikov im Gesundheits-IT-Bereich an der Schaffung medizinischer Informationssysteme. Mitglied der St. Petersburger Community der funktionalen Programmierer FPROG. Aktives Mitglied der Online Clojure-Community, Mitglied des HL7 FHIR-Standards für den Austausch medizinischer Informationen. Programmiert seit 15 Jahren.
Welche Seite haben wir für DevOps? Seit 10 Jahren ist unsere DevOps-Formel recht einfach: Entwickler sind für den Betrieb verantwortlich, Entwickler werden bereitgestellt, Entwickler werden gewartet. Mit diesem Arrangement, das etwas hart aussieht, werden Sie auf jeden Fall zu DevOps. Wenn Sie DevOps schnell und schmerzhaft implementieren möchten, machen Sie die Entwickler für Ihre Produktion verantwortlich. Wenn die Jungs klug sind, werden sie anfangen, rauszukommen und alles zu verstehen.

Unsere Geschichte: Vor langer Zeit, als es keinen Chef und keine Automatisierung gab, haben wir bereits das automatische Capistrano eingesetzt. Dann fingen sie an, ihn zu langweilen, damit er Mode machen würde. Aber dann erschien Chef. Wir wechselten dorthin und gingen in die Cloud: Wir hatten unsere Rechenzentren satt. Dann erschien Ansible, Docker stand auf. Danach zogen wir mit dem handgeschriebenen Condo Docker Supervisor auf Camel nach Terraform. Und jetzt ziehen wir nach Kubernetes.

Was ist das Schlimmste an Operationen? Nur sehr wenige Menschen sind mit dem Automatisierungsgrad ihrer Abläufe zufrieden. Ich bestätige, dass dies beängstigend ist: Wir haben viele Ressourcen und Anstrengungen aufgewendet, um all diese Stapel für uns selbst zu sammeln, und das Ergebnis ist unbefriedigend.
Es besteht das Gefühl, dass sich mit dem Aufkommen von Kubernetes etwas ändern kann. Ich bin der schlanken Fertigung verpflichtet und aus seiner Sicht sind Operationen im Allgemeinen nicht nützlich. Ideale Operationen sind das Fehlen oder Minimum von Operationen in einem Projekt. Wert entsteht, wenn ein Entwickler ein Produkt herstellt. Wenn es fertig ist, bringt die Lieferung keinen Mehrwert. Aber Sie müssen die Kosten senken.

Für mich war das Ideal immer Heroku. Wir haben es für einfache Anwendungen verwendet, bei denen der Entwickler seinen Dienst bereitstellte. Es genügte, git push zu sagen und heroku zu konfigurieren. Es dauert eine Minute.

Wie man ist Sie können NoOps kaufen - auch Heroku. Und ich rate Ihnen zu kaufen, sonst besteht die Möglichkeit, mehr Geld für die Entwicklung des normalen Betriebs auszugeben.
Es gibt Deis-Leute, die versuchen, so etwas wie Heroku auf Kubernetes zu machen. Es gibt eine Cloud-Gießerei, die auch eine Plattform bietet, auf der gearbeitet werden kann.

Aber wenn Sie sich mit etwas Komplexerem oder Großem beschäftigen, können Sie es selbst tun. Zusammen mit Docker und Kubernetes wird dies nun zu einer Aufgabe, die in angemessener Zeit und zu angemessenen Kosten erledigt werden kann. Früher war es zu hart.

Ein bisschen über Docker und Kubernetes
Eines der Probleme bei Operationen ist die Wiederholbarkeit. Das Tolle, was der Docker gebracht hat, sind zwei Phasen. Wir haben eine Bauphase.
Der zweite Punkt, der dem Docker gefällt, ist eine universelle Schnittstelle zum Starten beliebiger Dienste. Jemand hat Docker zusammengebaut, etwas hineingesteckt und Operationen ausgeführt. Es reicht aus, zu sagen, dass Docker ausgeführt und gestartet wird.

Was ist Kubernetes? Also haben wir Docker erstellt und müssen es irgendwo starten, integrieren, konfigurieren und mit anderen verbinden. Mit Kubernetes können Sie dies tun. Er führt eine Reihe von Abstraktionen ein, die als "Ressource" bezeichnet werden. Wir werden sie schnell durchgehen und sogar versuchen zu schaffen.
Abstraktion
Die erste Abstraktion ist ein POD oder eine Reihe von Containern. Richtig gemacht, was genau ist ein
Satz von Containern und nicht einer. Sets können untereinander Volumes durchsuchen, die sich über localhost sehen. Auf diese Weise können Sie ein Muster wie einen Beiwagen verwenden (dies ist der Zeitpunkt, an dem wir den Hauptcontainer starten, und es befinden sich Hilfscontainer in der Nähe, die ihm helfen).
Zum Beispiel der Botschafteransatz. In diesem Fall soll der Container nicht darüber nachdenken, wo sich einige Dienste befinden. Sie stellen einen Container daneben, der weiß, wo sich diese Dienste befinden. Und sie werden für den Hauptcontainer auf localhost verfügbar. Daher sieht die Umgebung so aus, als würden Sie lokal arbeiten.

Lassen Sie uns den POD erhöhen und sehen, wie er beschrieben wird. Vor Ort kann man Minikube entwickeln. Es verbraucht eine Menge CPUs, aber Sie können einen kleinen Kubernetes-Cluster auf einer Virtualbox erstellen und damit arbeiten.
Lassen Sie uns POD bereitstellen. Ich sagte, Kubernetes bewerben sich und überfluteten den POD. Ich kann sehen, welche PODs ich habe: Ich sehe, dass ein POD bereitgestellt wird. Dies bedeutet, dass Kubernetes diese Container gestartet hat.
Ich kann sogar in diesen Container gehen.
Aus dieser Perspektive ist Kubernetes für Menschen gemacht. In der Tat kann das, was wir ständig im Betrieb tun, beispielsweise bei der Kubernetes-Bindung, beispielsweise mit dem Dienstprogramm kubectl, problemlos durchgeführt werden.
Aber POD ist sterblich. Es beginnt als Docker-Lauf: Wenn jemand es stoppt, wird es niemand anheben. Zusätzlich zu dieser Abstraktion beginnt Kubernetes, Folgendes zu erstellen - beispielsweise ein Replikatset. Dies ist ein solcher Supervisor, der die PODs überwacht, ihre Anzahl überwacht und wenn die PODs fallen, werden sie angehoben. Dies ist ein wichtiges Selbstheilungskonzept in Kubernetes, mit dem Sie nachts ruhig schlafen können.
Über dem Replikatsatz befindet sich eine Abstraktion der Bereitstellung - auch eine Ressource, mit der Sie eine zeitlose Bereitstellung durchführen können. Beispielsweise funktioniert ein Replikatsatz. Wenn wir die Version des Containers, z. B. unsere, innerhalb der Bereitstellung bereitstellen und ändern, steigt ein weiteres Replikatset an. Wir warten, bis diese Container gestartet sind, durchlaufen ihre Integritätsprüfungen und wechseln dann schnell zum neuen Replikatsatz. Auch klassische und gute Praxis.

Lassen Sie uns einen einfachen Service abholen. Zum Beispiel haben wir eine Bereitstellung. Im Inneren beschreibt er das Muster der PODs, die er aufnehmen wird. Wir können diese Bereitstellung anwenden und sehen, was wir haben. Coole Funktion von Kubernetes - alles liegt in der Datenbank und wir können beobachten, was im System passiert.
Hier sehen wir eine Bereitstellung. Wenn wir versuchen, die PODs zu betrachten, sehen wir, dass einige PODs gestiegen sind. Wir können diesen POD nehmen und entfernen. Was passiert mit PODs? Einer wird zerstört und der zweite steigt sofort auf. Dieser Replikatset-Controller hat den gewünschten POD nicht gefunden und einen anderen gestartet.
Wenn es sich um eine Art Webdienst handelt oder innerhalb unserer Dienste kommunizieren muss, benötigen wir eine Serviceerkennung. Sie müssen dem Dienst einen Namen und einen Einstiegspunkt geben. Kubernetes bietet hierfür eine Ressource namens Service an. Er kann den Lastausgleich übernehmen und für die Serviceerkennung verantwortlich sein.

Sehen wir uns einen einfachen Service an. Wir verbinden es mit Deployment und PODs über Labels: eine solche dynamische Verbindung. Ein sehr wichtiges Konzept in Kubernetes: Das System ist dynamisch. Es spielt keine Rolle, in welcher Reihenfolge all dies erstellt wird. Der Service wird versuchen, PODs mit solchen Etiketten zu finden und deren Lastausgleich zu starten.
Service anwenden, schauen Sie, welche Services wir haben. Wir gehen in unseren Test-POD, der ausgelöst wurde, und machen nslookup. Kubernetes gibt uns ein DNS-ku, über das Dienste sich gegenseitig sehen und entdecken können.
Service ist eher eine Schnittstelle. Es gibt verschiedene Implementierungen, da die Aufgaben des Lastausgleichs und des Dienstes ziemlich kompliziert sind: Auf die eine Weise arbeiten wir mit normalen Datenbanken, auf der anderen mit geladenen und einige einfache sind recht einfach. Dies ist auch ein wichtiges Konzept in Kubernetes: Einige Dinge können eher als Schnittstellen als als Implementierungen bezeichnet werden. Sie sind nicht starr festgelegt, und unterschiedliche Cloud-Anbieter bieten beispielsweise unterschiedliche Implementierungen an. Das heißt, es gibt beispielsweise ein ressourcenbeständiges Volume, das bereits regelmäßig in jeder einzelnen Cloud implementiert ist.
Als nächstes möchten wir normalerweise den Webdienst herausbringen. Kubernetes hat eine Ingress-Abstraktion. Normalerweise wird dort SSL hinzugefügt.

Der einfachste Eingang sieht ungefähr so aus. Dort schreiben wir die Regeln: Für welche URLs, für welche Hosts, für welchen internen Service soll die Anfrage umgeleitet werden. Auf die gleiche Weise können wir unseren Eintritt erhöhen.
Nachdem Sie sich lokal bei den Hosts registriert haben, können Sie diesen Service von hier aus sehen.
Dies ist eine so regelmäßige Aufgabe: Wir haben einen bestimmten Webdienst bereitgestellt und uns ein wenig mit Kubernetes getroffen.
Wir werden alles bereinigen, das Eindringen entfernen und alle Ressourcen untersuchen.
Es gibt eine Reihe von Ressourcen, wie z. B. configmap und secret. Hierbei handelt es sich um reine Informationsressourcen, die Sie in einen Container einbinden und dort beispielsweise das Passwort von postgres übertragen können. Sie können dies Umgebungsvariablen zuordnen, die beim Start in den Container eingefügt werden. Sie können das Dateisystem mounten. Alles ist ganz bequem: Standardaufgaben, schöne Lösungen.
Es gibt ein dauerhaftes Volumen - eine Schnittstelle, die von verschiedenen Cloud-Anbietern unterschiedlich implementiert wird. Es ist in zwei Teile unterteilt: Es gibt einen dauerhaften Volumenanspruch (Anforderung), und dann wird ein EBS erstellt, das sich in den Container zieht. Sie können mit Stateful Service arbeiten.

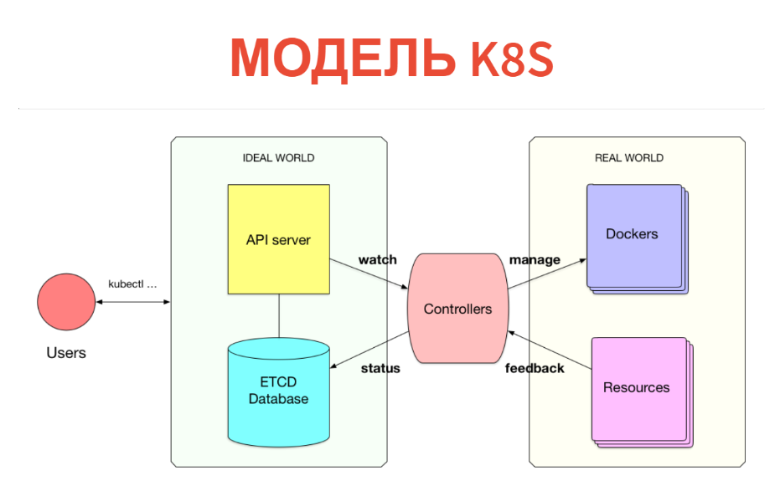
Aber wie funktioniert es innen? Das Konzept selbst ist sehr einfach und transparent. Kubernetes besteht aus zwei Teilen. Eine ist nur eine Datenbank, in der wir alle diese Ressourcen haben. Ressourcen können als Tablets betrachtet werden: Insbesondere handelt es sich bei diesen Instanzen lediglich um Aufzeichnungen in Tablets. Zusätzlich zu Kubernetes ist ein API-Server konfiguriert. Das heißt, wenn Sie einen Kubernetes-Cluster haben, kommunizieren Sie normalerweise mit dem API-Server (genauer gesagt, der Client kommuniziert mit ihm).
Dementsprechend wird das, was wir erstellt haben (PODs, Dienste usw.), einfach in die Datenbank geschrieben. Diese Datenbank wird durch ETCD implementiert, d.h. so dass es auf dem hochverfügbaren Niveau stabil ist.
Was kommt als nächstes? Weiter gibt es unter jeder Art von Ressourcen einen bestimmten Controller. Dies ist nur ein Dienst, der seine Art von Ressource überwacht und etwas in der Außenwelt tut. Wird beispielsweise ein Docker ausgeführt? Wenn wir PODs haben, gibt es für jeden Knoten einen Kubelet-Dienst, der die PODs überwacht, die an diesen Knoten angeschlossen sind. Und alles, was er tut, ist, dass Docker nach der nächsten regelmäßigen Überprüfung ausgeführt wird, ob dieser POD nicht vorhanden ist.
Was sehr wichtig ist - alles geschieht in Echtzeit, sodass die Leistung dieses Controllers höher als das Minimum ist. Oft nimmt der Controller immer noch die Metriken und schaut sich an, was er gestartet hat. Das heißt, Entfernt das Feedback aus der realen Welt und schreibt es in die Datenbank, damit Sie oder andere Controller es sehen können. Beispielsweise wird derselbe POD-Status in ETCD zurückgeschrieben.
Somit ist alles in Kubernetes implementiert. Es ist sehr cool, dass das Informationsmodell vom Operationssaal getrennt ist. In der Datenbank deklarieren wir über die übliche CRUD-Schnittstelle, was sein soll. Dann versucht der Satz von Controllern, alles richtig zu machen. Das passiert zwar nicht immer.
Dies ist ein kybernetisches Modell. Wir haben eine bestimmte Voreinstellung, es gibt eine Art Maschine, die versucht, die reale Welt oder Maschine an den Ort zu lenken, der benötigt wird. Es stellt sich nicht immer so heraus: Wir sollten eine Rückkopplungsschleife haben. Manchmal kann eine Maschine dies nicht und muss sich an eine Person wenden.
In realen Systemen denken wir in Abstraktionen der nächsten Ebene: Wir haben einige Dienste, Datenbanken und wir verbinden sie alle. Wir denken nicht an PODs und Ingresss und möchten eine nächste Abstraktionsebene aufbauen.

Damit der Entwickler so einfach wie möglich war: Er sagte einfach: „Ich möchte so und so einen Service starten“, und alles andere passierte im Inneren.
Es gibt so etwas wie HELM. Dies ist der falsche Weg - ansible Style Templating, bei dem wir nur versuchen, eine Reihe konfigurierter Ressourcen zu erzeugen und sie in einem Kubernetes-Cluster abzulegen.
Das Problem ist zum einen, dass dies nur zum Zeitpunkt des Walzens erfolgt. Das heißt, er kann nicht viel Logik implementieren. Zweitens verschwindet diese Abstraktion zur Laufzeit. Wenn ich mir meinen Cluster anschaue, sehe ich nur PODs und Dienste. Ich sehe nicht, dass so und so ein Dienst bereitgestellt wird, dass dort so und so eine Basis mit Replikation eingerichtet wird. Ich sehe dort nur Dutzende von Herden. Die Abstraktion verschwindet wie in einer Matrix.

Internes Lösungsmodell
Auf der anderen Seite bietet Kubernetes selbst bereits ein sehr interessantes und einfaches Erweiterungsmodell im Inneren. Wir können neue Arten von Ressourcen deklarieren, zum Beispiel die Bereitstellung. Dies ist eine Ressource, die auf PODs oder Replikaten basiert. Wir können einen Controller in diese Ressource schreiben, diese Ressource in die Datenbank einfügen und unsere kybernetische Schleife ausführen, damit alles funktioniert. Das klingt interessant und es scheint mir, dass dies der richtige Weg ist, um Kubernetes zu erweitern.

Ich möchte in der Lage sein, nur ein Manifest für meinen Service im Heroku-Stil zu schreiben. Ein sehr einfaches Beispiel: Ich möchte eine Art Anwendung in meiner realen Umgebung bereitstellen. Haben bereits Vereinbarungen, SSL, Domains gekauft. Ich möchte Entwicklern nur die einfachste Oberfläche bieten, die möglich ist. Das Manifest sagt mir, welchen Container ich heben soll, welche Ressourcen dieser Container noch benötigt. Er wirft diese Ankündigung in den Cluster und alles beginnt zu funktionieren.

Wie wird dies in Bezug auf benutzerdefinierte Ressourcen und Controller aussehen? Hier haben wir eine Ressourcenanwendung in der Datenbank. Und der Anwendungscontroller erzeugt drei Ressourcen. Das heißt, er schreibt eingehende Regeln für die Weiterleitung zu diesem Dienst auf, startet den Dienst für den Lastenausgleich und startet die Bereitstellung mit einer Konfiguration.
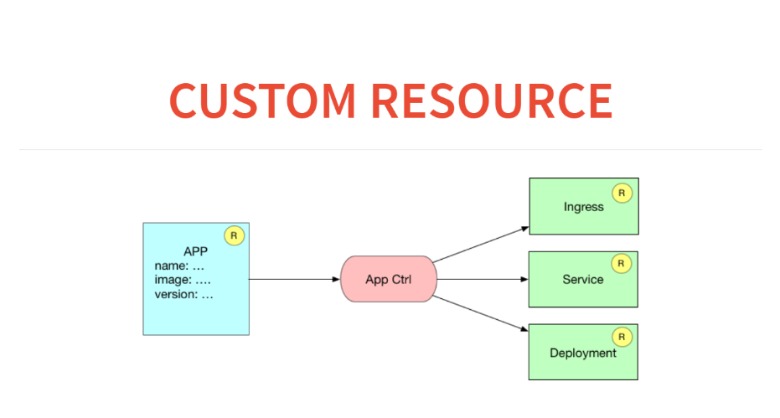
Bevor wir eine benutzerdefinierte Ressource in Kubernetes erstellen, müssen wir sie deklarieren. Dafür gibt es eine Meta-Ressource namens CustomResourceDefinition.
Um eine neue Ressource in Kubernetes zu deklarieren, reicht es aus, eine solche Ankündigung zu veröffentlichen. Betrachten Sie diese Erstellungs-Tabelle.
Erstellt eine Tabelle. Danach können wir durch den Kubectl-Zugriff auf die Ressourcen von Drittanbietern schauen, die wir haben. Sobald wir es angekündigt hatten, bekamen wir auch ein Banner. Wir können zum Beispiel kubeclt Apps bekommen. Aber bisher keine App.
Lass uns eine App schreiben. Danach können wir eine benutzerdefinierte Ressourceninstanz erstellen. Schauen wir es uns in YAML an und erstellen es per Post an eine bestimmte URL.
Wenn wir durch kubectl laufen und schauen, erscheint eine App. Aber während nichts passiert, liegt es nur in der Datenbank. Sie können beispielsweise alle App-Ressourcen übernehmen und anfordern.
Wir können eine zweite solche Ressource aus derselben Vorlage erstellen, indem wir einfach den Namen ändern. Hier ist die zweite Ressource.
Darüber hinaus sollte unser Controller Vorlagen erstellen, ähnlich wie HELM. Das heißt, nachdem ich eine Beschreibung unserer App erhalten habe, muss ich eine Ressourcenbereitstellung und einen Ressourcenservice generieren sowie einen Eintrag in Ingress vornehmen. Dies ist der einfachste Teil: Hier in Clojure ist Erlmacro. Ich übergebe die Datenstruktur, sie ruft die Bereitstellungsfunktion auf, übergibt sie an das Debugging, das die Pipeline ist. Und das ist eine reine Funktion: einfaches Templating. Dementsprechend könnte ich es in der naivsten Form sofort erstellen, in ein Konsolendienstprogramm verwandeln und mit der Verteilung beginnen.
Dasselbe tun wir für den Service: Die Servicefunktion akzeptiert die Deklaration und generiert die Kubernetes-Ressource für uns.
Wir machen dasselbe für die eingehende Linie.
Wie wird das alles funktionieren? Es wird etwas in der realen Welt geben und es wird geben, was wir wollen. Was wir wollen - wir nehmen die Anwendungsressource und generieren darauf, was sie sein soll. Und jetzt müssen wir sehen, was ist. Was wir über die REST-API anfordern. Wir können alle Dienste, alle Bereitstellungen erhalten.
Wie funktioniert unser benutzerdefinierter Controller? Er wird erhalten, was wir wollen und was ist, von diesem Div nehmen und sich bei Kubernetes bewerben. Dies ähnelt React. Ich habe mir ein virtuelles DOM ausgedacht, als einige Funktionen einfach einen Baum von JS-Objekten generieren. Und dann berechnet ein bestimmter Algorithmus den Patch und wendet ihn auf das reale DOM an.
Wir werden das gleiche hier tun. Dies erfolgt in 50 Codezeilen. Willst du - alles ist auf Github. Am Ende sollten wir die Funktion zum Abgleichen von Aktionen erhalten.
Wir haben eine Funktion zum Versöhnen von Aktionen, die nichts tut und nur diese Div berechnet. Sie nimmt, was ist und was gebraucht wird. Und dann gibt es heraus, was getan werden muss, um das erste zum zweiten zu bringen.
Lass uns an ihr ziehen. Es ist nichts falsch mit ihr, sie kann entkräftet werden. Sie sagt, dass Sie einen Ingress-Service erstellen, zwei Einträge darin vornehmen, eine Bereitstellung 1 und 2 erstellen und einen Service 1 und 2 erstellen müssen.
In diesem Fall sollte es bereits nur einen Dienst geben. Wir sehen vom Eingang, dass nur ein Eintrag übrig bleibt.
Dann müssen Sie nur noch eine Funktion schreiben, die diesen Patch auf den Kubernetes-Cluster anwendet. Dazu übergeben wir einfach Abstimmungsaktionen an die Abstimmungsfunktion, und alles wird angewendet. Und jetzt sehen wir, dass der POD gestiegen ist, die Bereitstellung erfolgt ist und der Dienst gestartet wurde.
Fügen wir einen weiteren Dienst hinzu: Führen Sie die Funktion zum Abgleichen von Aktionen erneut aus. Mal sehen, was passiert ist. Alles begann, alles ist in Ordnung.
Wie gehe ich damit um? Wir packen das alles in einen Docker-Container. Danach schreiben wir eine Funktion, die regelmäßig aufwacht, sich versöhnt und einschläft. Geschwindigkeit ist nicht sehr wichtig, sie kann fünf Sekunden lang schlafen und nicht so oft Versöhnungsaktionen durchführen.
Unser benutzerdefinierter Controller ist nur ein Dienst, der den Patch aktiviert und regelmäßig berechnet.
Jetzt haben wir zwei Dienste zaddeloino, lassen Sie uns eine der Anwendungen löschen. Mal sehen, wie unser Cluster reagiert hat: Alles ist in Ordnung. Wir löschen die zweite: Alles ist gelöscht.
Lassen Sie uns durch die Augen des Entwicklers sehen. Er muss nur sagen, dass Kubernetes sich bewerben und den neuen Dienst benennen. Wir machen das, unser Controller hat alles aufgenommen und erstellt.
Anschließend sammeln wir all dies in einem Bereitstellungsdienst und werfen diesen benutzerdefinierten Controller mithilfe der Kubernetes-Standardtools in den Cluster. Wir haben eine Abstraktion für 200 Codezeilen erstellt.
Es sieht alles nach HELM aus, ist aber tatsächlich mächtiger. Der Controller arbeitet in einem Cluster: Er sieht die Basis, sieht die Außenwelt und kann intelligent genug gemacht werden.
Eigenes CI
Betrachten Sie die Kubernetes-Erweiterungsbeispiele. Wir haben beschlossen, dass CI Teil der Infrastruktur sein sollte. Dies ist gut, es ist aus Sicherheitsgründen praktisch - ein privates Repository. Wir haben versucht, Jenkins zu verwenden, aber es ist ein veraltetes Tool. Ich wollte einen Hacker CI. Wir brauchen keine Schnittstellen, wir lieben ChatOps: Lassen Sie es einfach im Chat sagen, ob der Build gefallen ist oder nicht. Außerdem wollte ich alles lokal debuggen.

Wir setzten uns und schrieben unser CI in einer Woche. Nur als Erweiterung zu Kubernetes. Wenn Sie an CI denken, ist dies nur ein Tool, mit dem Jobs ausgeführt werden. Im Rahmen dieses Jobs erstellen wir etwas, führen Tests durch und stellen häufig bereit.
Wie funktioniert das alles? Es basiert auf dem gleichen Konzept von benutzerdefinierten Controllern.
Zunächst wird in Kubernetes beschrieben, welchen Repositorys wir folgen. Der Controller geht einfach zu Github und fügt Web-Hook hinzu. Wir haben immer noch Selbstbeobachtung.Als nächstes kommt der Web-Hook, dessen einzige Aufgabe darin besteht, den eingehenden JSON zu verarbeiten und in einer benutzerdefinierten Build-Ressource abzulegen, die sich auch zur Kubernetes-Datenbank summiert. Die Build-Ressource wird vom Build-Controller überwacht, der das Manifest im Projekt liest und den POD startet. In diesem POD werden alle erforderlichen Dienste gestartet.In POD ein sehr einfacher Agent, der eine Deklaration im Stil von Travis oder Circleci liest, und in YAML eine Reihe von Schritten. Er beginnt sie zu erfüllen. Am Ende des Builds wirft er sein Ergebnis in Telegramm.Eine weitere Funktion, die wir mit Kubernetes erhalten haben, ist, dass einer der Befehle zum Ausführen Ihres CI oder der kontinuierlichen Zustellung einfach während des True Sleep 10 festgelegt werden kann und Ihr POD bei diesem Schritt einfriert. Du machst kubectl exec, findest dich in deinem Build wieder und kannst debütieren.Eine weitere Funktion - alles basiert auf Dockern und Sie können das Skript lokal debuggen, indem Sie das Docker starten. Es dauerte zwei Wochen und 300 Codezeilen.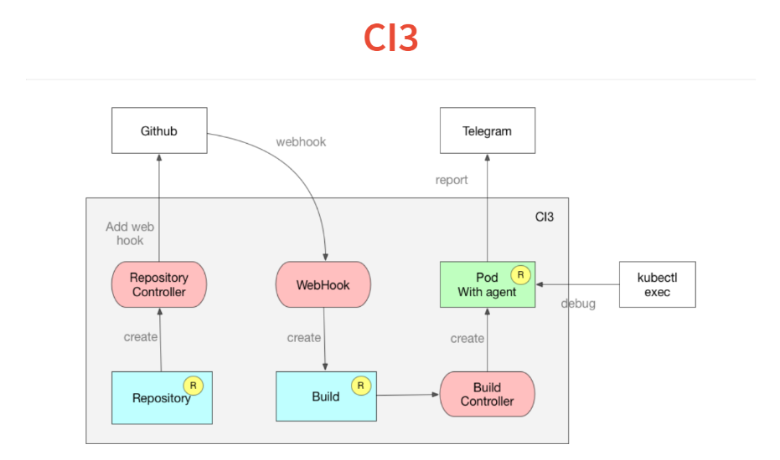
Arbeite mit Postgres
Unser Produkt basiert auf Postgres, wir verwenden alle möglichen interessanten Funktionen. Wir haben sogar eine Reihe von Erweiterungen geschrieben. Wir können jedoch kein RDS oder etwas anderes verwenden.Wir sind gerade dabei, einen Operator für ein unzerstörbares Postgres zu entwickeln. Ich werde Architektur klingen. Ich möchte sagen: "Cluster, gib mir ein Postgres, das nicht getötet werden kann." Hinzu kommt, dass ich zwei asynchrone Replikate benötige, eines synchron, tägliche Backups und bis zu einem Terabyte. Ich werfe alles, dann beginnt mein Cluster-Controller mit der Orchestrierung und Erweiterung meines Containers. Es werden Pginstance-Ressourcen erstellt, die für jedes Istance-Postgres verantwortlich sind. Dies werden Cluster-Postgres sein.Ein weiterer Pginstance-Controller, ganz einfach, versucht nur, POD auszuführen oder dort mit diesem Postgres bereitzustellen. Das Herz ist anhaltendes Volumen. Diese ganze Maschine übernimmt die volle Kontrolle über Postgres. Sie geben ihr einen Docker-Container, der nur binäre Postgres enthält. Alles andere: Der Controller selbst übernimmt die Konfiguration und Erstellung des Postgres-Startclusters. Er tut dies, damit wir später neu konfigurieren können und damit er Replikation, Protokollstufen usw. konfigurieren kann. Zu Beginn läuft der temporäre POD über das persistente Volume und erstellt dort einen Postgres-Cluster für den Master.Darüber hinaus beginnt die Bereitstellung mit dem Master. Dann wird auf die gleiche Weise ein dauerhaftes Volume erstellt. Ein anderer POD fährt durch, erstellt eine grundlegende Sicherung, zieht sie ab und darüber hinaus beginnt die Bereitstellung mit einem Slave.Als Nächstes erstellt der Cluster-Controller eine Sicherungsressource (nachdem dies mit Sicherungen beschrieben wurde). Und der Backup-Controller nimmt es bereits und wirft es in einen S3.
Was weiter?
Lassen Sie uns mit Ihnen die nahe Zukunft vorstellen. Es kann vorkommen, dass wir früher oder später über so interessante benutzerdefinierte Ressourcen und benutzerdefinierte Controller verfügen, dass ich sagen werde: "Gib mir Postgres, gib mir Kafka, lass mich CI und starte alles." Alles wird einfach sein.Wenn wir nicht über die nahe Zukunft sprechen, dann denke ich als deklarativer Programmierer, dass nur logische oder relationale Programmierung höher ist als funktionale Programmierung. Dort ist unsere Operationssemantik völlig unabhängig von der Informationssemantik. Wenn wir uns unsere benutzerdefinierten Controller genau ansehen, haben wir beispielsweise eine Ressourcenanwendung in unserer Datenbank. Und wir leiten daraus drei weitere zusätzliche Ressourcen ab. Dies ist der Datenbankansicht sehr ähnlich. Dies ist eine Tatsachenfeststellung. Dies ist eine logische oder Beziehungsansicht.Der nächste Schritt für Kubernetes besteht darin, eine gewisse Illusion einer relationalen oder logischen Basis anstelle einer gehackten REST-API zu vermitteln, in der Sie einfach eine Regel schreiben können. Da früher oder später alles in die Datenbank fließt, einschließlich Feedback, können die Regeln folgendermaßen klingen: "Wenn die Last auf diese Weise gestiegen ist, erhöhen Sie die Replikation auf diese Weise." Wir werden eine kleine SQL- oder logische Regel haben. Alles was Sie brauchen ist eine generische Engine, die diesem folgt. Aber das ist eine glänzende Zukunft.
— DevOops 2018 ! — .
«The DevOps Handbook» , «Learning Chef: A Guide to Configuration Management and Automation» , «How to containerize your Go code» «Liquid Software: How to Achieve Trusted Continuous Updates in the DevOps World» — . - .
: !
: 1 Sie können ein Ticket für DevOops 2018 mit einem Rabatt buchen.