Haftungsausschluss: Ich berücksichtige keine Algorithmen und APIs für die Arbeit mit Ton- und Spracherkennung. In diesem Artikel geht es um Audioprobleme und deren Lösung mit Go.

phono ist ein Anwendungsframework für die Arbeit mit Sound. Seine Hauptfunktion besteht darin, aus verschiedenen Technologien einen Förderer zu erstellen, der Schall verarbeitet für dich in der Art, wie Sie brauchen.
Was hat der Förderer damit zu tun, abgesehen von verschiedenen Technologien, und warum ein anderes Framework? Jetzt lass es uns herausfinden.
Woher kommt der Ton?
Bis 2018 ist Klang zum Standard für die Interaktion von Menschen mit Technologie geworden. Die meisten IT-Giganten haben ihren eigenen Sprachassistenten erstellt oder tun dies gerade. Die Sprachsteuerung ist auf den meisten Betriebssystemen bereits verfügbar, und Sprachnachrichten sind ein typisches Merkmal jedes Messenger. In der Welt arbeiten ungefähr tausend Startups an der Verarbeitung natürlicher Sprache und ungefähr zweihundert an der Spracherkennung.
Mit Musik eine ähnliche Geschichte. Es wird von jedem Gerät abgespielt, und die Tonaufnahme steht jedem zur Verfügung, der über einen Computer verfügt. Musiksoftware wird von Hunderten von Unternehmen und Tausenden von Enthusiasten auf der ganzen Welt entwickelt.
Wenn Sie mit Ton arbeiten mussten, sollten Ihnen die folgenden Bedingungen bekannt vorkommen:
- Audio muss von einer Datei, einem Gerät, einem Netzwerk usw. bezogen werden.
- Audio muss verarbeitet werden : Effekte hinzufügen, transkodieren, analysieren usw.
- Audio muss in eine Datei, ein Gerät, ein Netzwerk usw. übertragen werden.
- Daten werden in kleinen Puffern übertragen.
Es stellt sich eine reguläre Pipeline heraus - es gibt einen Datenstrom, der mehrere Verarbeitungsstufen durchläuft.
Lösungen
Nehmen wir zur Klarheit eine Aufgabe aus dem wirklichen Leben. Zum Beispiel müssen Sie eine Stimme in Text umwandeln:
- Wir zeichnen Audio vom Gerät auf
- Lärm entfernen
- Ausgleichen
- Übergeben Sie das Signal an die Spracherkennungs-API
Wie jede andere Aufgabe hat auch diese mehrere Lösungen.
Stirn
Nur Hardcore Radfahrer Programmierer. Wir nehmen Sound direkt über den Soundkartentreiber auf, schreiben intelligente Rauschunterdrückung und Multiband-Equalizer. Das ist sehr interessant, aber Sie können Ihre ursprüngliche Aufgabe für einige Monate vergessen.
Lang und sehr schwierig.
Normal
Eine Alternative ist die Verwendung vorhandener APIs. Sie können Audio mit ASIO, CoreAudio, PortAudio, ALSA und anderen aufnehmen. Es gibt auch verschiedene Arten von Plugins für die Verarbeitung: AAX, VST2, VST3, AU.
Eine große Auswahl bedeutet nicht, dass Sie alles auf einmal verwenden können. In der Regel gelten die folgenden Einschränkungen:
- Operationssystem. Nicht alle APIs sind auf allen Betriebssystemen verfügbar. Beispielsweise ist AU eine native OS X-Technologie und nur dort verfügbar.
- Programmiersprache Die meisten Audiobibliotheken sind in C oder C ++ geschrieben. 1996 veröffentlichte Steinberg die erste Version des VST SDK, immer noch der beliebteste Plugin-Standard. Nach 20 Jahren ist es nicht mehr erforderlich, in C / C ++ zu schreiben: Für VST gibt es Wrapper in Java, Python, C #, Rust und wer weiß was noch. Obwohl die Sprache eine Einschränkung bleibt, wird jetzt sogar Ton in JavaScript verarbeitet.
- Funktionell. Wenn die Aufgabe einfach und unkompliziert ist, muss keine neue Anwendung geschrieben werden. Das gleiche FFmpeg kann viel.
In dieser Situation hängt die Komplexität von Ihrer Wahl ab. Im schlimmsten Fall müssen Sie sich mit mehreren Bibliotheken befassen. Und wenn Sie überhaupt kein Glück haben, mit komplexen Abstraktionen und völlig anderen Schnittstellen.
Was ist das Ergebnis?
Sie müssen zwischen sehr komplex und komplex wählen:
- Entweder beschäftigen Sie sich mit mehreren Low-Level-APIs, um Ihre Fahrräder zu schreiben
- entweder mit mehreren APIs umgehen und versuchen, sich mit ihnen anzufreunden
Unabhängig von der gewählten Methode kommt es immer auf den Förderer an. Die verwendeten Technologien können variieren, aber das Wesentliche ist dasselbe. Das Problem ist, dass Sie wieder schreiben müssen, anstatt ein echtes Problem zu lösen Fahrrad Förderband.
Aber es gibt einen Ausweg.
Phono

phono , um häufig auftretende Probleme zu lösen - um Sound zu empfangen, zu verarbeiten und zu senden . Dazu verwendet er die Pipeline als natürlichste Abstraktion. Es gibt einen Artikel im offiziellen Go- Blog , der das Pipeline-Muster beschreibt. Die Hauptidee der Pipeline besteht darin, dass es mehrere Stufen der Datenverarbeitung gibt, die unabhängig voneinander arbeiten und Daten über Kanäle austauschen. Was du brauchst.
Warum gehen?
Erstens sind die meisten Audioprogramme und Bibliotheken in C geschrieben, und Go wird häufig als Nachfolger bezeichnet. Darüber hinaus gibt es cgo und einige Ordner für vorhandene Audiobibliotheken . Sie können nehmen und verwenden.
Zweitens ist Go meiner persönlichen Meinung nach eine gute Sprache. Ich werde nicht tief gehen, aber ich werde das Multithreading bemerken. Kanäle und Gorutine vereinfachen die Implementierung des Förderers erheblich.
Abstraktion
Das Herzstück von phono ist der Typ pipe.Pipe . Er ist es, der die Pipeline implementiert. Wie im Beispiel aus dem Blog gibt es drei Arten von Phasen:
pipe.Pump (englische Pumpe) - empfängt Ton, nur Ausgangskanälepipe.Processor (englischer Prozessor) - Tonverarbeitungs- , Eingabe- und Ausgabekanälepipe.Sink (englische Senke) - Tonübertragung, nur Eingangskanäle
Innerhalb der pipe.Pipe Daten in Puffern übergeben. Regeln zum Erstellen einer Pipeline:
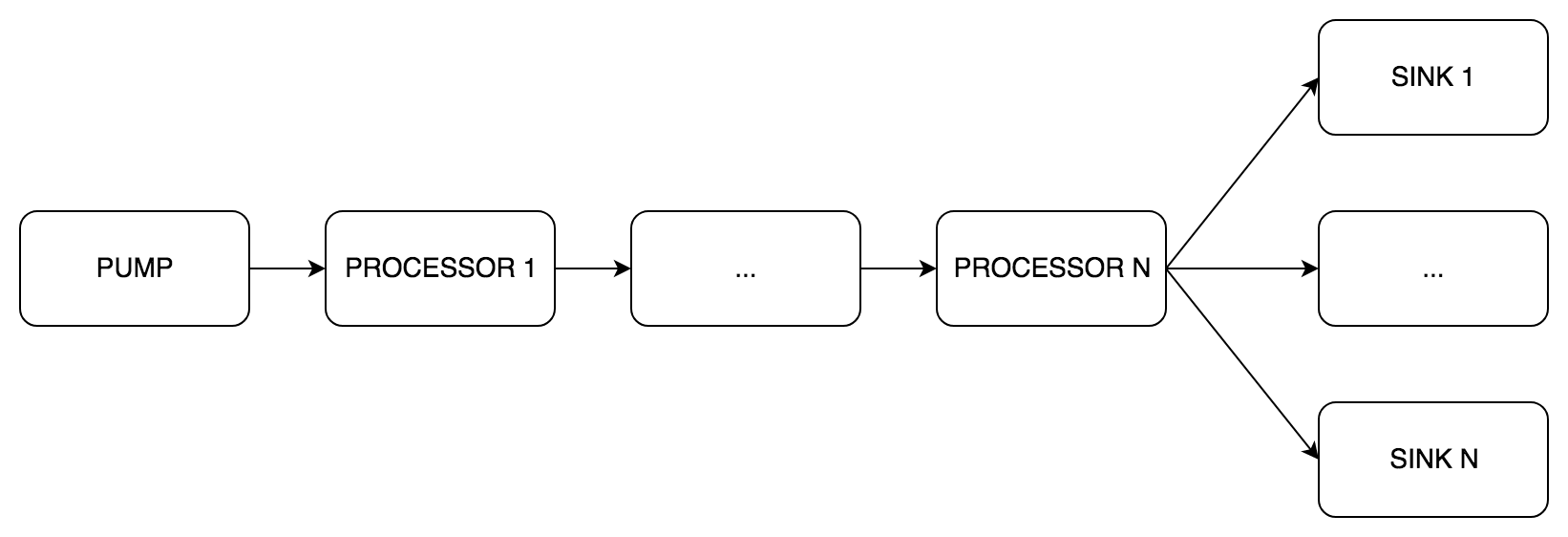
- Eine
pipe.Pump - Mehrere
pipe.Processor nacheinander platziert - Ein oder mehrere
pipe.Sink parallel platziert - Alle
pipe.Pipe müssen gleich sein:
- Puffergröße (Nachrichten)
- Abtastrate
- Anzahl der Kanäle
Die Mindestkonfiguration ist Pumpe und eine Spüle, der Rest ist optional.
Schauen wir uns einige Beispiele an.
Einfach
Aufgabe: Spielen Sie die WAV-Datei ab.
Bringen wir es in das Formular " Empfangen, Verarbeiten, Übertragen ":
- Holen Sie sich Audio aus einer WAV-Datei
- Übertragen Sie Audio auf ein Portaudio-Gerät

Audio wird gelesen und sofort abgespielt.
Code package example import ( "github.com/dudk/phono" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/wav" )
Zuerst erstellen wir die Elemente der zukünftigen Pipeline: wav.Pump und portaudio.Sink und übergeben sie an den pipe.New Konstruktor. Die p.Do(pipe.actionFn) error startet die Pipeline und wartet, bis sie beendet ist.
Härter
Aufgabe: Teilen Sie die WAV-Datei in Samples auf, erstellen Sie daraus einen Track, speichern Sie das Ergebnis und spielen Sie es gleichzeitig ab.
Eine Spur ist eine Folge von Samples, und ein Sample ist ein kleines Audiosegment. Um das Audio zu schneiden, müssen Sie es zuerst in den Speicher laden. Verwenden Sie dazu den asset.Asset Typ aus dem phono/asset Paket. Wir unterteilen die Aufgabe in Standardschritte:
- Holen Sie sich Audio aus einer WAV-Datei
- Audio in den Speicher übertragen
Jetzt machen wir Proben mit unseren Händen, fügen sie der Spur hinzu und beenden die Aufgabe:
- Holen Sie sich Audio von einer Spur
- Übertragen Sie Audio an
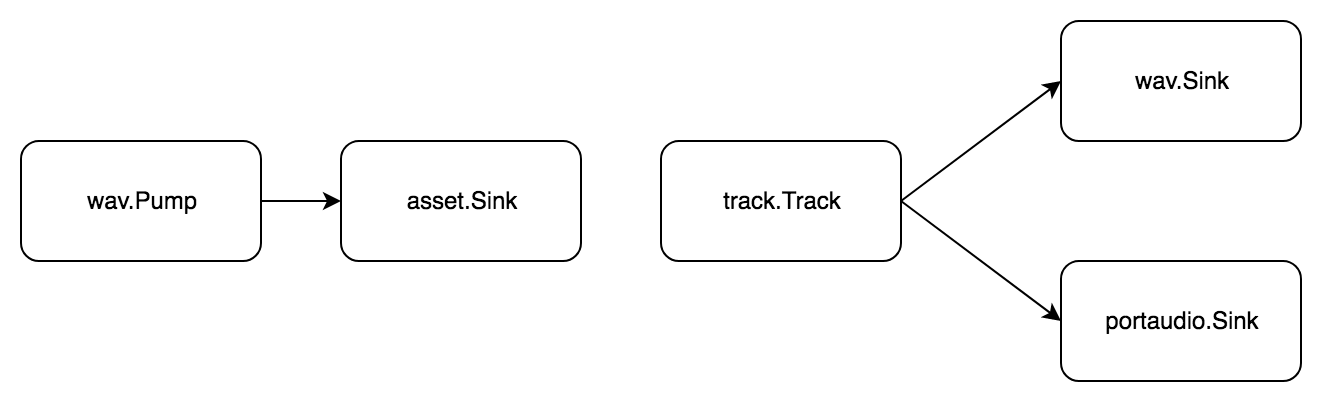
Wieder ohne Verarbeitungsstufe, aber zwei Pipelines!
Code package example import ( "github.com/dudk/phono" "github.com/dudk/phono/asset" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/track" "github.com/dudk/phono/wav" )
Im Vergleich zum vorherigen Beispiel gibt es zwei pipe.Pipe . Der erste überträgt Daten in den Speicher, damit Sie die Samples schneiden können. Der zweite hat am Ende zwei Empfänger: wav.Sink und portaudio.Sink . Bei diesem Schema wird der Ton gleichzeitig in einer WAV-Datei aufgezeichnet und abgespielt.
Härter
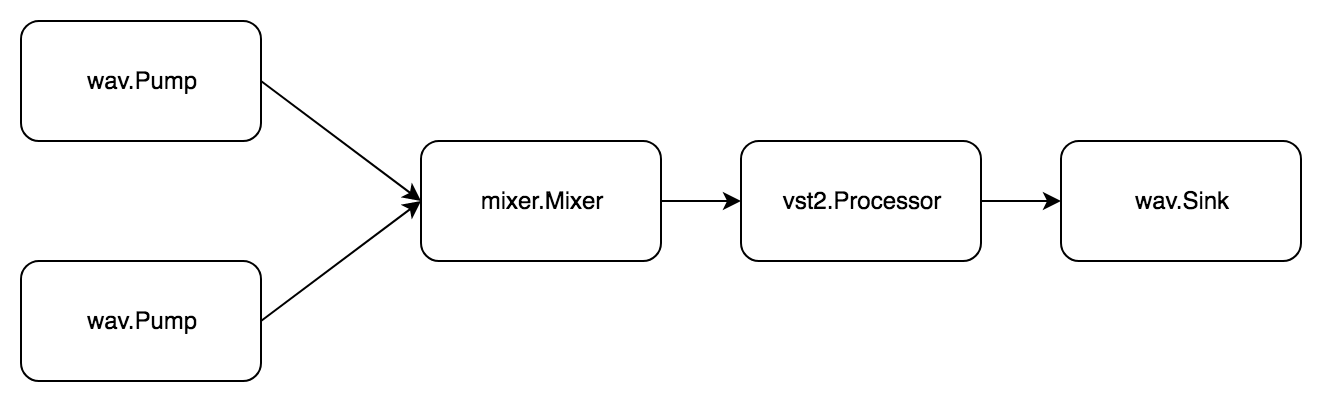
Aufgabe: Zwei WAV-Dateien lesen, mischen, das vst2-Plugin verarbeiten und in einer neuen WAV-Datei speichern.
Es gibt einen einfachen phono/mixer . phono/mixer im phono/mixer mixer.Mixer . Es kann Signale von mehreren Quellen übertragen und eine mischen. Zu diesem pipe.Pump gleichzeitig pipe.Pump und pipe.Sink .
Auch hier besteht die Aufgabe aus zwei Unteraufgaben. Der erste sieht so aus:
- Holen Sie sich die Audio-WAV-Datei
- Übertragen Sie Audio zum Mixer
Zweitens:
- Holen Sie sich Audio vom Mixer.
- Audio-Plugin verarbeiten
- Übertragen Sie Audio in eine WAV-Datei
Code package example import ( "github.com/dudk/phono" "github.com/dudk/phono/mixer" "github.com/dudk/phono/pipe" "github.com/dudk/phono/vst2" "github.com/dudk/phono/wav" vst2sdk "github.com/dudk/vst2" )
Es gibt bereits drei pipe.Pipe . Alle pipe.Pipe sind über einen Mischer miteinander verbunden. Verwenden Sie zum p.Begin(pipe.actionFn) (pipe.State, error) die Funktion p.Begin(pipe.actionFn) (pipe.State, error) . Im p.Do(pipe.actionFn) error der Aufruf nicht blockiert, sondern es wird einfach ein Status zurückgegeben, auf den dann mit dem p.Wait(pipe.State) error gewartet werden p.Wait(pipe.State) error .
Was weiter?
Ich möchte, dass phono das bequemste Anwendungsframework wird. Wenn Sie ein Problem mit dem Sound haben, müssen Sie keine komplexen APIs verstehen und keine Zeit damit verbringen, Standards zu studieren. Alles, was benötigt wird, ist, ein Förderband aus geeigneten Elementen zu bauen und es laufen zu lassen.
Ein halbes Jahr lang wurden folgende Pakete gedreht:
phono/wav - WAV-Dateien lesen / schreibenphono/vst2 - unvollständige Bindungen des VST2 SDK, während Sie nur das Plugin öffnen und seine Methoden aufrufen können, aber nicht alle Strukturenphono/mixer - Mixer, fügt N Signale ohne Balance und Lautstärke hinzuphono/asset - Pufferabtastungphono/track - sequentielles Lesen von Samples (Schicht unterbrochen)phono/portaudio - Signalwiedergabe während der Experimente
Zusätzlich zu dieser Liste gibt es einen ständig wachsenden Rückstand an neuen Ideen und Ideen, einschließlich:
- Countdown
- Variable on the fly Pipeline
- HTTP-Pumpe / Spüle
- Parameterautomatisierung
- Resampling-Prozessor
- Mischbalance und Lautstärke
- Echtzeitpumpe
- Synchronpumpe für mehrere Spuren
- Volle vst2
In den folgenden Artikeln werde ich analysieren:
pipe.Pipe Lebenszyklus - Aufgrund der komplexen Struktur wird sein Zustand vom endgültigen Atom gesteuert- wie man seine Pipeline-Stufen schreibt
Dies ist mein erstes Open-Source-Projekt, daher bin ich für jede Hilfe und Empfehlung dankbar. Willkommen zurück.
Referenzen