Es scheint, dass das Thema abgedroschen ist - es wurde viel über Backup gesagt und geschrieben, daher gibt es nichts, was das Rad neu erfinden könnte. Nehmen Sie es einfach und tun Sie es. Jedes Mal, wenn der Systemadministrator eines Webprojekts vor der Aufgabe steht, Backups einzurichten, hängt es für viele mit einem großen Fragezeichen in der Luft. Wie sammle ich die Datensicherung richtig? Wo werden Backups gespeichert? Wie kann das erforderliche Maß an nachträglicher Speicherung von Kopien bereitgestellt werden? Wie kann der Sicherungsprozess für den gesamten Zoo verschiedener Software vereinheitlicht werden?

Für uns selbst haben wir dieses Problem 2011 zum ersten Mal gelöst. Dann haben wir uns hingesetzt und unsere Backup-Skripte geschrieben. Im Laufe der Jahre haben wir nur sie verwendet, und sie haben erfolgreich einen zuverlässigen Prozess zum Sammeln und Synchronisieren von Backups von Webprojekten unserer Kunden bereitgestellt. Backups wurden in unserem oder einem anderen externen Speicher gespeichert, mit der Möglichkeit, sie für ein bestimmtes Projekt zu optimieren.
Ich muss sagen, diese Skripte haben in vollem Umfang funktioniert. Aber je weiter wir wuchsen, desto vielfältiger wurden Projekte mit unterschiedlicher Software und externen Repositorys, die unsere Skripte nicht unterstützten. Zum Beispiel hatten wir keine Unterstützung für Redis und die heißen MySQL- und PostgreSQL-Backups, die später erschienen. Der Sicherungsprozess wurde nicht überwacht, es gab nur E-Mail-Benachrichtigungen.
Ein weiteres Problem war der Supportprozess. Im Laufe der Jahre sind unsere einst kompakten Skripte gewachsen und haben sich zu einem riesigen, unangenehmen Monster entwickelt. Und als wir uns zusammengetan und eine neue Version veröffentlicht haben, hat sich die Mühe gelohnt, das Update für den Teil der Kunden bereitzustellen, die die vorherige Version mit einer Art Anpassung verwendet haben.
Infolgedessen haben wir Anfang dieses Jahres eine willensstarke Entscheidung getroffen: Unsere alten Backup-Skripte durch etwas Moderneres zu ersetzen. Deshalb haben wir uns zuerst hingesetzt und die gesamte Wunschliste für eine neue Lösung aufgeschrieben. Es stellte sich ungefähr Folgendes heraus:
- Sichern Sie die Daten der am häufigsten verwendeten Software:
- Dateien (diskretes und inkrementelles Kopieren)
- MySQL (Cold / Hot-Backups)
- PostgreSQL (Cold / Hot-Backups)
- Mongodb
- Redis
- Speichern Sie Backups in beliebten Repositorys:
- Lokal
- FTP
- Ssh
- SMB
- Nfs
- Webdav
- S3
- Erhalten Sie Benachrichtigungen bei Problemen während des Sicherungsvorgangs
- Verfügen Sie über eine einzige Konfigurationsdatei, mit der Sie Backups zentral verwalten können
- Fügen Sie Unterstützung für neue Software hinzu, indem Sie externe Module anschließen
- Geben Sie zusätzliche Optionen zum Sammeln von Speicherauszügen an
- Sie können Backups regelmäßig wiederherstellen
- Einfache Erstkonfiguration
Wir analysieren die verfügbaren Lösungen
Wir haben uns bereits vorhandene Open-Source-Lösungen angesehen:
- Bacula und seine Gabeln, zum Beispiel Bareos
- Amanda
- Borg
- Vervielfältigung
- Duplizität
- Rsnapshot
- Rdiff-Backup
Aber jeder von ihnen hatte seine Nachteile. Zum Beispiel ist Bacula mit Funktionen überladen, die wir nicht benötigen. Die Erstkonfiguration ist aufgrund des großen manuellen Aufwands (z. B. zum Schreiben / Suchen nach Datenbanksicherungsskripten) und zum Wiederherstellen von Kopien, die Sie benötigen, spezielle Dienstprogramme usw., eine ziemlich mühsame Aufgabe.
Am Ende kamen wir zu zwei wichtigen Schlussfolgerungen:
- Keine der vorhandenen Lösungen passte vollständig zu uns.
- Es scheint, dass wir selbst genug Erfahrung und Wahnsinn hatten, um unsere Entscheidung zu schreiben.
Also haben wir es getan.
Die Geburt von nxs-backup
Python wurde als Implementierungssprache ausgewählt - es ist einfach zu schreiben und zu warten, flexibel und bequem. Es wurde beschlossen, Konfigurationsdateien im Yaml-Format zu beschreiben.
Um das Sichern und Hinzufügen von Backups neuer Software zu vereinfachen, wurde eine modulare Architektur gewählt, bei der der Prozess des Sammelns von Backups jeder spezifischen Software (z. B. MySQL) in einem separaten Modul beschrieben wird.
Unterstützung für Dateien, Datenbanken und Remotespeicher
Derzeit werden die folgenden Arten von Sicherungen von Dateien, Datenbanken und Remote-Repositorys unterstützt:
DB:
- MySQL (Hot / Cold-Backups)
- PostgreSQL (Hot / Cold-Backups)
- Redis
- Mongodb
Dateien:
- Diskretes Kopieren
- Inkrementelles Kopieren
Remote-Repositorys:
- Lokal
- S3
- SMB
- Nfs
- FTP
- Ssh
- Webdav
Diskrete Sicherung
Für verschiedene Aufgaben sind entweder diskrete oder inkrementelle Sicherungen geeignet, daher wurden beide Typen implementiert. Sie können angeben, welche Methode auf der Ebene einzelner Dateien und Verzeichnisse verwendet werden soll.
Für diskrete Kopien (sowohl Dateien als auch Datenbanken) können Sie eine Retrospektive im Format Tage / Wochen / Monate festlegen.
Inkrementelle Sicherung
Inkrementelle Kopien von Dateien werden wie folgt erstellt:
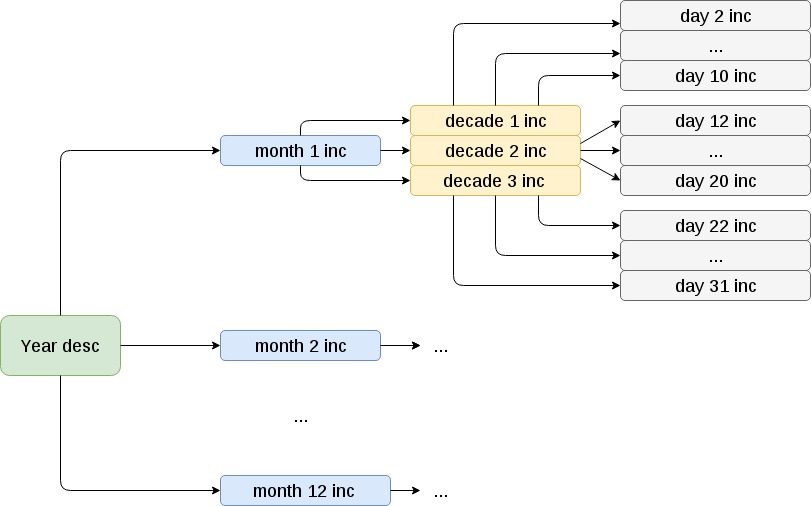
Zu Beginn des Jahres wird eine vollständige Sicherung durchgeführt. Als nächstes zu Beginn eines jeden Monats - eine inkrementelle monatliche Kopie im Vergleich zur jährlichen. Innerhalb der Menstruation - inkrementell dekadisch im Vergleich zum Monat. Innerhalb jeder inkrementellen Tageszeit von zehn Tagen im Verhältnis zum Zeitraum von zehn Tagen.
Es ist zu beachten, dass beim Arbeiten mit Verzeichnissen, die eine große Anzahl von Unterverzeichnissen enthalten (Zehntausende), zwar einige Probleme auftreten. In solchen Fällen wird die Sammlung von Kopien erheblich verlangsamt und kann mehr als einen Tag dauern. Wir gehen aktiv auf dieses Manko ein.
Wir erholen uns von inkrementellen Sicherungen
Es gibt keine Probleme bei der Wiederherstellung nach diskreten Sicherungen. Nehmen Sie einfach eine Kopie für das erforderliche Datum und stellen Sie sie mit dem üblichen Konsolentar bereit. Inkrementelle Kopien sind etwas komplizierter. Um beispielsweise am 24. Juli 2018 wiederherzustellen, müssen Sie Folgendes tun:
- Erweitern Sie eine einjährige Sicherung, auch wenn sie in unserem Fall ab dem 1. Januar 2018 beginnt (in der Praxis kann dies ein beliebiges Datum sein, je nachdem, wann entschieden wurde, inkrementelle Sicherungen zu implementieren).
- Würfeln Sie ihm ein monatliches Backup für Juli
- Rollen Sie das Backup vom 21. Juli auf
- Rollup tägliches Backup für den 24. Juli
Um 2-4 Punkte auszuführen, müssen Sie gleichzeitig den Schalter -G zum Befehl tar hinzufügen, um anzuzeigen, dass es sich um eine inkrementelle Sicherung handelt. Natürlich ist dies nicht der schnellste Prozess, aber da es nicht so oft notwendig ist, sich von Backups zu erholen, und die Kosteneffizienz wichtig ist, erweist sich ein solches Schema als recht effektiv.
Ausnahmen
Häufig müssen Sie einzelne Dateien oder Verzeichnisse von Sicherungen ausschließen, z. B. Verzeichnisse mit Cache. Dies kann durch Angabe der entsprechenden Ausnahmeregeln erfolgen:
Beispiel für eine Konfigurationsdatei- target: - /var/www/*/data/ excludes: - exclude1/exclude_file - exclude2 - /var/www/exclude_3
Backup-Rotation
In unseren alten Skripten wurde die Rotation implementiert, sodass die alte Kopie erst gelöscht wurde, nachdem die neue erfolgreich zusammengestellt wurde. Dies führte zu Problemen bei Projekten, bei denen dem Sicherungsspeicher grundsätzlich genau eine Kopie zugewiesen wurde - eine neue Kopie konnte dort aufgrund von Speicherplatzmangel nicht gesammelt werden.
In der neuen Implementierung haben wir beschlossen, diesen Ansatz zu ändern: Löschen Sie zuerst den alten und sammeln Sie dann eine neue Kopie. Der Prozess des Sammelns von Backups sollte überwacht werden, um Probleme festzustellen.
Bei diskreten Sicherungen wird ein Archiv als alte Kopie betrachtet, die über das angegebene Speicherschema im Format Tage / Wochen / Monate hinausgeht. Bei inkrementellen Sicherungen werden Sicherungen standardmäßig ein Jahr lang gespeichert, und alte Kopien werden zu Beginn eines jeden Monats gelöscht, während Archive für denselben Monat des letzten Jahres als alte Sicherungen betrachtet werden. Vor dem Sammeln einer monatlichen Sicherung am 1. August 2018 prüft das System beispielsweise, ob Sicherungen für August 2017 vorhanden sind, und löscht diese in diesem Fall. Dies ermöglicht eine optimale Nutzung des Speicherplatzes.
Protokollierung
In jedem Prozess und insbesondere bei Backups ist es wichtig, auf dem Laufenden zu bleiben und herauszufinden, ob etwas schief gelaufen ist. Das System führt ein Protokoll seiner Arbeit und erfasst das Ergebnis jedes Schritts: Start / Stopp von Geldern, Start / Ende einer bestimmten Aufgabe, das Ergebnis des Sammelns einer Kopie in einem temporären Verzeichnis, das Ergebnis des Kopierens / Verschiebens einer Kopie von einem temporären Verzeichnis an einen permanenten Speicherort, das Ergebnis der Sicherungsrotation usw. ..
Ereignisse sind in 2 Ebenen unterteilt:
- Info : Informationsstand - der Flug ist normal, die nächste Stufe wurde erfolgreich abgeschlossen, ein entsprechender Informationseintrag erfolgt im Log
- Fehler : Fehlerstufe - etwas ist schiefgegangen, die nächste Stufe ist fehlgeschlagen, ein entsprechender Fehlerdatensatz wird im Protokoll erstellt
E-Mail-Benachrichtigungen
Am Ende der Sicherungssammlung kann das System E-Mail-Benachrichtigungen senden.
Es werden 2 Empfängerlisten unterstützt:
- Administratoren sind diejenigen, die den Server bedienen. Sie erhalten nur Benachrichtigungen über Fehler und sind nicht an Benachrichtigungen über erfolgreiche Operationen interessiert
- Geschäftsbenutzer - in unserem Fall sind dies Kunden, die manchmal Benachrichtigungen erhalten möchten, um sicherzustellen, dass bei Backups alles in Ordnung ist. Oder umgekehrt nicht wirklich. Sie können wählen, ob sie ein vollständiges Protokoll oder nur ein fehlerhaftes Protokoll erhalten möchten.
Struktur der Konfigurationsdatei
Die Struktur der Konfigurationsdateien ist wie folgt:
Strukturbeispiel /etc/nxs-backup ├── conf.d │ ├── desc_files_local.conf │ ├── external_clickhouse_local.conf │ ├── inc_files_smb.conf │ ├── mongodb_nfs.conf │ ├── mysql_s3.conf │ ├── mysql_xtradb_scp.conf │ ├── postgresql_ftp.conf │ ├── postgresql_hot_webdav.conf │ └── redis_local_ftp.conf └── nxs-backup.conf
Hier ist /etc/nxs-backup/nxs-backup.conf die Hauptkonfigurationsdatei, in der die globalen Einstellungen angegeben sind:
Konfigurationsdatei main: server_name: SERVER_NAME admin_mail: project-tech@nixys.ru client_mail: - '' mail_from: backup@domain.ru level_message: error block_io_read: '' block_io_write: '' blkio_weight: '' general_path_to_all_tmp_dir: /var/nxs-backup cpu_shares: '' log_file_name: /var/log/nxs-backup/nxs-backup.log jobs: !include [conf.d
Das Array von Aufgaben (Jobs) enthält eine Liste von Aufgaben (Jobs), die beschreiben, was genau gesichert werden soll, wo und in welcher Menge gespeichert werden soll. In der Regel werden sie in separate Dateien (eine Datei pro Job) verschoben, die über include in der Hauptkonfigurationsdatei verbunden sind.
Sie haben auch darauf geachtet, den Prozess der Vorbereitung dieser Dateien so weit wie möglich zu optimieren, und einen einfachen Generator geschrieben. Daher muss der Administrator keine Zeit damit verbringen, nach der Konfigurationsvorlage für einen Dienst zu suchen, z. B. MySQL, sondern einfach den folgenden Befehl ausführen:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.conf
Die Ausgabe generiert die Datei /etc/nxs-backup/conf.d/mysql_local_scp.conf :
Dateiinhalt - job: PROJECT-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: '' db_port: '' socket: '' db_user: '' db_password: '' auth_file: '' target: - all excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump store: days: '' weeks: '' month: '' - storage: scp enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump user: '' host: '' port: '' password: '' path_to_key: '' store: days: '' weeks: '' month: ''
Dabei bleiben nur einige notwendige Werte zu ersetzen.
Nehmen wir ein Beispiel. Angenommen, auf unserem Server im Verzeichnis / var / www befinden sich zwei Sites des 1C-Bitrix-Onlineshops (bitrix-1.ru, bitrix-2.ru), von denen jede mit einer eigenen Datenbank in verschiedenen MySQL-Instanzen arbeitet (Port 3306 für Bitrix_1_db und 3307 Port für Bitrix_2_db).
Die Dateistruktur eines typischen Bitrix-Projekts sieht ungefähr wie folgt aus:
├── ... ├── bitrix │ ├── .. │ ├── admin │ ├── backup │ ├── cache │ ├── .. │ ├── managed_cache │ ├── .. │ ├── stack_cache │ └── .. ├── upload └── ...
In der Regel wiegt das Upload- Verzeichnis viel und wächst nur mit der Zeit, sodass es schrittweise gesichert wird. Alle anderen Verzeichnisse sind diskret, mit Ausnahme von Verzeichnissen mit Cache und Sicherungen, die von nativen Bitrix-Tools erfasst wurden. Das Sicherungsspeicherschema für diese beiden Sites sollte identisch sein, während Kopien der Dateien sowohl lokal als auch auf dem Remote-FTP-Speicher gespeichert werden sollten und die Datenbank nur auf dem Remote-SMB-Speicher gespeichert werden sollte.
Die resultierenden Konfigurationsdateien für ein solches Setup sehen folgendermaßen aus:
bitrix-desc-files.conf (Konfigurationsdatei mit Jobbeschreibung für diskrete Sicherung) - job: Bitrix-desc-files type: desc_files tmp_dir: /var/nxs-backup/files/desc/dump_tmp sources: - target: - /var/www/*/ excludes: - bitrix/backup - bitrix/cache - bitrix/managed_cache - bitrix/stack_cache - upload gzip: yes storages: - storage: local enable: yes backup_dir: /var/nxs-backup/files/desc/dump store: days: 6 weeks: 4 month: 6 - storage: ftp enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: ftp_host user: ftp_usr password: ftp_usr_pass store: days: 6 weeks: 4 month: 6
bitrix-inc-files.conf (Konfigurationsdatei mit Jobbeschreibung für inkrementelle Sicherung) - job: Bitrix-inc-files type: inc_files sources: - target: - /var/www/*/upload/ gzip: yes storages: - storage: ftp enable: yes backup_dir: /nxs-backup/files/inc host: ftp_host user: ftp_usr password: ftp_usr_pass - storage: local enable: yes backup_dir: /var/nxs-backup/files/inc
bitrix-mysql.conf (Konfigurationsdatei mit Jobbeschreibung für MySQL-Backups) - job: Bitrix-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: localhost db_port: 3306 db_user: bitrux_usr_1 db_password: password_1 target: - bitrix_1_db excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' - connect: db_host: localhost db_port: 3307 db_user: bitrix_usr_2 db_password: password_2 target: - bitrix_2_db excludes: - information_schema - performance_schema - mysql - sys gzip: yes is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: smb enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: smb_host port: smb_port share: smb_share_name user: smb_usr password: smb_usr_pass store: days: 6 weeks: 4 month: 6
Optionen zum Sammeln von Backups
Im vorherigen Beispiel haben wir Jobkonfigurationsdateien für das gleichzeitige Sammeln von Sicherungen aller Elemente vorbereitet: Dateien (diskret und inkrementell), zwei Datenbanken und deren Speicherung in lokalen und externen (ftp, smb) Speichern.
Es bleibt die ganze Sache zu laufen. Der Start wird mit dem folgenden Befehl ausgeführt:
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIG
Es gibt mehrere reservierte Jobnamen:
- files - willkürliche Ausführung aller Jobs mit den Typen desc_files , inc_files ( dh im Wesentlichen werden nur Dateien gesichert )
- Datenbanken - zufällige Ausführung aller Jobs mit den Typen mysql , mysql_xtradb , postgresql , postgresql_hot , mongodb , redis ( dh nur die Datenbank sichern)
- external - zufällige Ausführung aller Jobs mit dem externen Typ (nur zusätzliche benutzerdefinierte Skripte ausführen, mehr dazu weiter unten)
- all - Nachahmung der Ausführung des Befehls nacheinander mit Jobdateien , Datenbanken , extern (Standardwert)
Da wir Datensicherungen beider Dateien und der Datenbank gleichzeitig (oder mit einem minimalen Unterschied) bei der Ausgabe erhalten müssen, wird empfohlen, nxs-backup mit Job all auszuführen, um eine konsistente Ausführung des beschriebenen Jobs (Bitrix-desc-) sicherzustellen. Dateien, Bitrix-inc_files, Bitrix-mysql).
Das heißt, ein wichtiger Punkt: Backups werden nicht parallel, sondern nacheinander mit einem minimalen Zeitunterschied gesammelt. Darüber hinaus prüft die Software beim nächsten Start selbst, ob der Prozess bereits im System ausgeführt wird. Wenn er erkannt wird, beendet er seine Arbeit automatisch mit der entsprechenden Markierung im Protokoll. Dieser Ansatz reduziert die Belastung des Systems erheblich. Minus - Backups einzelner Elemente werden nicht sofort, sondern mit einem gewissen Zeitunterschied gesammelt. Unsere Praxis zeigt jedoch, dass dies nicht kritisch ist.
Externe Module
Wie oben erwähnt, können dank der modularen Architektur die Funktionen des Systems mithilfe zusätzlicher Benutzermodule erweitert werden, die über eine spezielle Schnittstelle mit dem System interagieren. Das Ziel ist es, in Zukunft Unterstützung für Backups neuer Software hinzufügen zu können, ohne nxs-backup neu schreiben zu müssen.
Beispiel für eine Konfigurationsdatei - job: TEST-external type: external dump_cmd: '' storages: ….
Besondere Aufmerksamkeit sollte dem Schlüssel dump_cmd gewidmet werden , wobei der Wert der vollständige Befehl zum Ausführen eines externen Skripts ist. Darüber hinaus wird nach Abschluss dieses Befehls erwartet, dass:
- Ein fertiges Archiv mit Softwaredaten wird gesammelt
- Die Daten werden im JSON-Format in der folgenden Form an stdout gesendet:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }
- In diesem Fall sind die Schlüssel basename , extension , gzip ausschließlich für die Bildung des endgültigen Sicherungsnamens erforderlich.
- Bei erfolgreichem Abschluss des Skripts sollte der Rückkehrcode 0 und bei Problemen jeder andere sein.
Angenommen, wir haben ein Skript zum Erstellen eines Snapshots etcd /etc/nxs-backup-ext/etcd.py :
Die Konfiguration zum Ausführen dieses Skripts lautet wie folgt:
Konfigurationsdatei - job: etcd-external type: external dump_cmd: '/etc/nxs-backup-ext/etcd.py' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/external/dump store: days: 6 weeks: 4 month: 6
In diesem Fall ist das Programm beim Ausführen des Jobs etcd-external :
- Führen Sie das Skript /etc/nxs-backup-ext/etcd.py ohne Parameter aus
- Nach Abschluss des Skripts werden der Abschlusscode und die Verfügbarkeit der erforderlichen Daten in stdout überprüft
- Wenn alle Überprüfungen erfolgreich sind, wird derselbe Mechanismus wie bei den bereits integrierten Modulen verwendet, wobei der Schlüsselwert full_path als tmp_path verwendet wird. Wenn nicht, wird diese Aufgabe mit der entsprechenden Markierung im Protokoll abgeschlossen.
Support und Update
Der Prozess der Entwicklung und Unterstützung des neuen Backup-Systems wurde mit allen Kanonen von CI / CD implementiert. Keine Updates und Skriptänderungen mehr auf Kampfservern. Alle Änderungen werden über unser zentrales Git-Repository in Gitlab übertragen, wo die Zusammenstellung neuer Versionen von Deb / RPM-Paketen in der Pipeline registriert wird, die dann in unsere Deb / RPM-Repositorys hochgeladen werden. Danach werden sie über den Paketmanager an die Endclient-Server geliefert.
Wie lade ich nxs-backup herunter?
Wir haben ein Open-Source-Projekt für nxs-backup erstellt. Jeder kann es herunterladen und verwenden, um den Sicherungsprozess in seinen Projekten zu organisieren sowie an seine Bedürfnisse anzupassen und externe Module zu schreiben.
Der Quellcode für nxs-backup kann unter diesem Link aus dem Github-Repository heruntergeladen werden. Es gibt auch Installations- und Konfigurationsanweisungen.
Wir haben auch ein Docker-Image vorbereitet und auf DockerHub veröffentlicht .
Wenn Sie während des Einrichtungs- oder Verwendungsprozesses Fragen haben, schreiben Sie uns. Wir werden helfen, die Anweisungen zu verstehen und abzuschließen.
Fazit
In naher Zukunft werden wir folgende Funktionen implementieren:
- Integration überwachen
- Backup-Verschlüsselung
- Webbasierte Oberfläche zum Verwalten von Sicherungseinstellungen
- Bereitstellen von Sicherungen mit nxs-backup
- Und vieles mehr