Moderne Texteditoren können nicht nur piepen und das Programm nicht verlassen. Es stellt sich heraus, dass in ihnen ein sehr komplexer Stoffwechsel kocht. Möchten Sie wissen, welche Tricks durchgeführt werden, um Koordinaten schnell neu zu berechnen, wie Stile, Faltungen und Softwraps an den Text angehängt werden und wie alles aktualisiert wird, was die funktionale Datenstruktur und die Prioritätswarteschlange damit zu tun haben und wie der Benutzer getäuscht werden kann - willkommen bei der Katze!

Der Artikel basiert auf dem
Bericht von Alexei Kudryavtsev mit Joker 2017. Alexei schreibt seit etwa 10 Jahren Intellij IDEA in JetBrains. Unter dem Schnitt finden Sie Video- und Textabschriften des Berichts.
Datenstrukturen in Texteditoren
Um zu verstehen, wie der Editor funktioniert, schreiben wir ihn.

Das war's, unser einfachster Editor ist fertig.
Im Editor lässt sich der Text am einfachsten in einem Array von Zeichen oder, was die Speicherorganisation betrifft, in der Java-Klasse StringBuffer speichern. Um ein Zeichen durch Offset zu erhalten, rufen wir die StringBuffer.charAt (i) -Methode auf. Und um das Zeichen einzufügen, das wir auf der Tastatur eingegeben haben, rufen wir die StringBuffer.insert () -Methode auf, die das Zeichen irgendwo in der Mitte einfügt.
Was trotz der Einfachheit und Idiotie dieses Editors am interessantesten ist, ist die beste Idee, die Sie erfinden können. Es ist sowohl einfach als auch fast immer schnell.
Leider tritt bei diesem Editor ein Skalierungsproblem auf. Stellen Sie sich vor, wir haben viel Text darin gedruckt und werden einen weiteren Buchstaben in die Mitte einfügen. Folgendes wird passieren. Wir müssen dringend Platz für diesen Buchstaben schaffen, indem wir alle anderen Buchstaben um ein Zeichen nach vorne verschieben. Dazu verschieben wir diesen Buchstaben um eine Position, dann um die nächste und so weiter bis zum Ende des Textes.
So würde es im Gedächtnis aussehen:
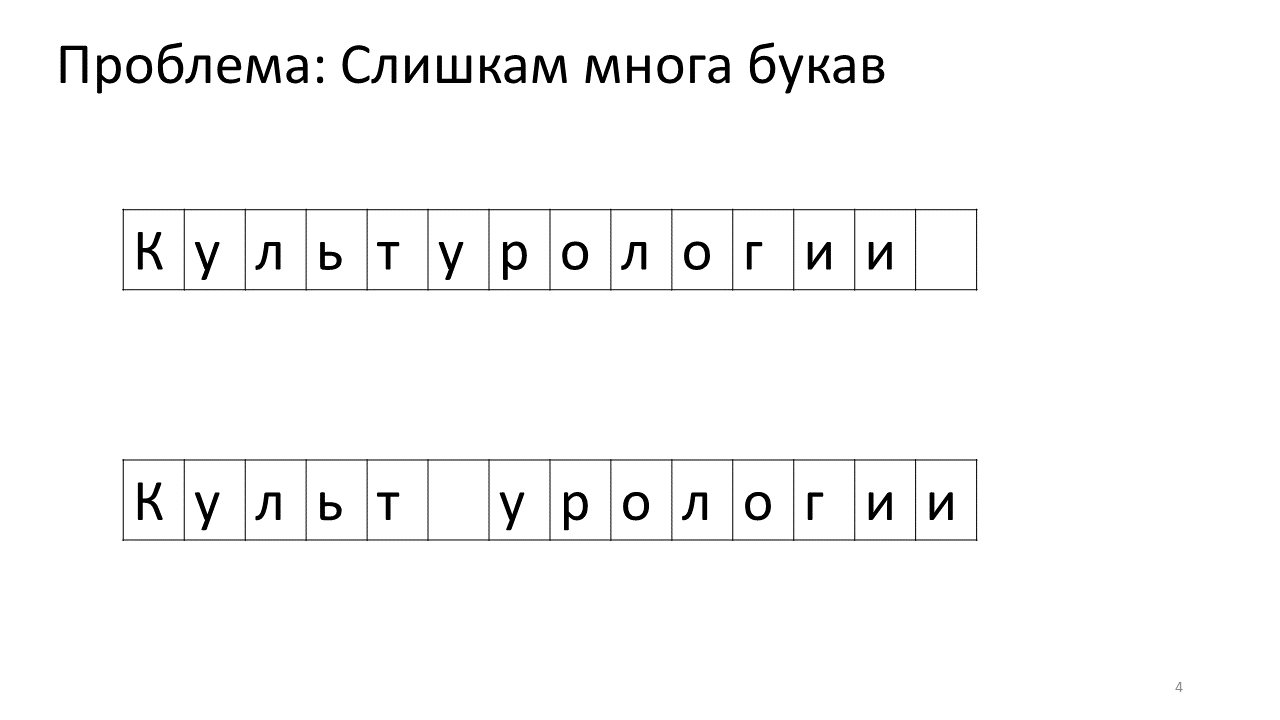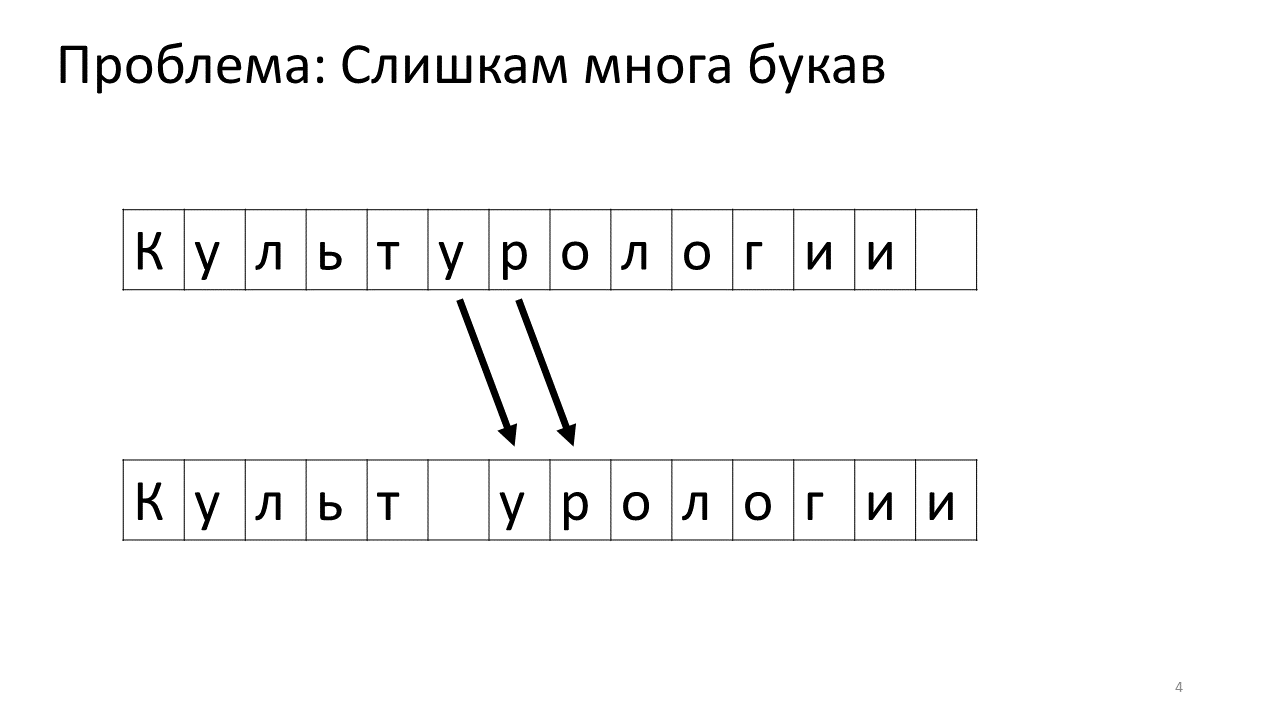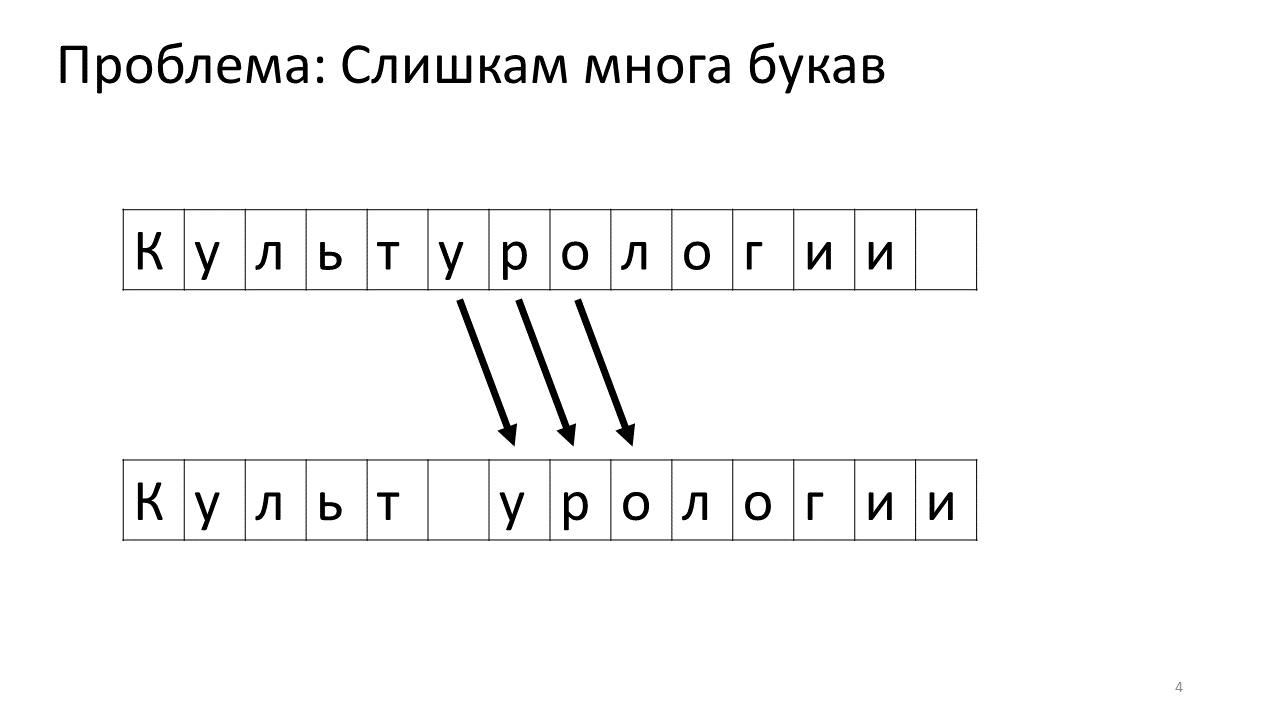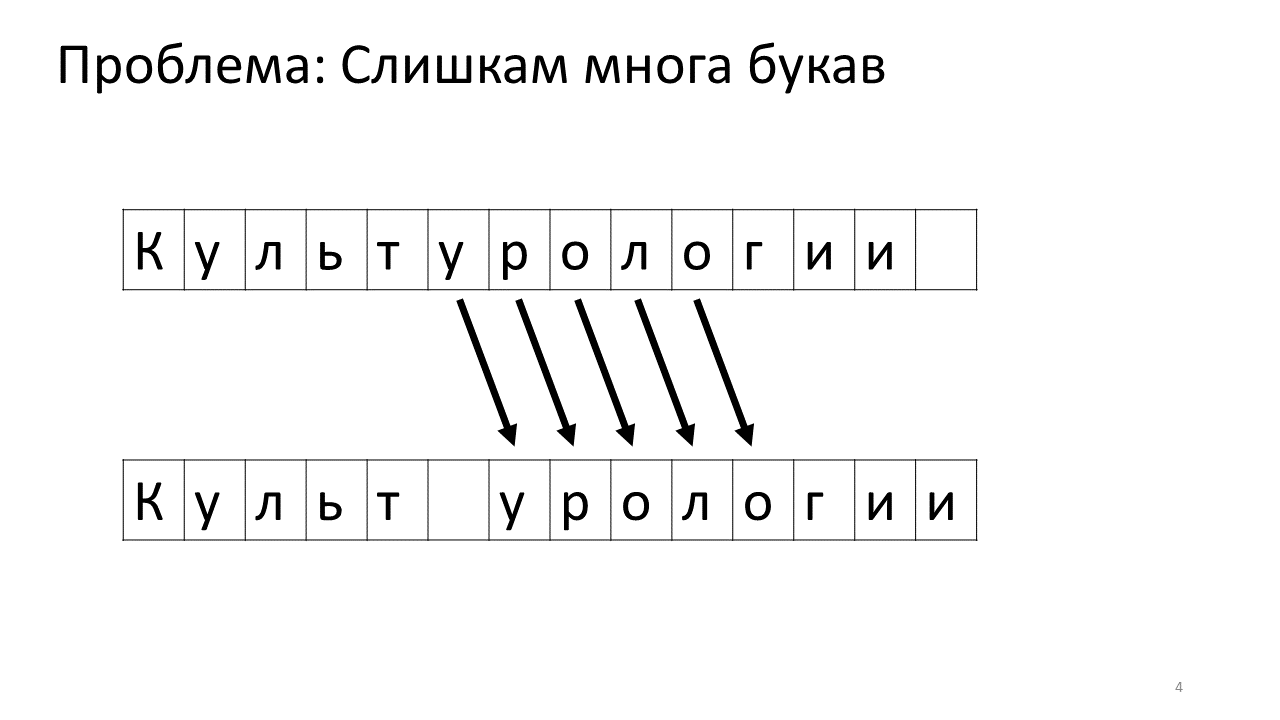
Das Verschieben all dieser vielen Megabyte ist nicht sehr gut: Es ist langsam. Für einen modernen Computer ist dies natürlich eine Kleinigkeit - eine Art erbärmlicher Megabyte, um sich hin und her zu bewegen. Bei einer sehr aktiven Textänderung kann dies jedoch spürbar sein.
Um dieses Problem des Einfügens eines Zeichens in die Mitte zu lösen, wurde vor langer Zeit eine Problemumgehung namens "Gap Buffer" entwickelt.
Lückenpuffer
Lücke ist die Lücke. Puffer ist, wie Sie sich vorstellen können, ein Puffer. Die Gap Buffer-Datenstruktur ist ein so leerer Puffer, dass wir für alle Fälle in der Mitte unseres Textes bleiben. Wenn wir etwas drucken mussten, verwenden wir diesen kleinen Textpuffer zum schnellen Tippen.

Die Datenstruktur hat sich ein wenig geändert - das Array ist an Ort und Stelle geblieben, aber zwei Zeiger sind erschienen: am Anfang des Puffers und am Ende. Um ein Zeichen mit einem gewissen Versatz aus dem Editor zu entnehmen, müssen wir verstehen, ob es vor oder nach diesem Puffer liegt, und den Versatz leicht korrigieren. Und um ein Zeichen einzufügen, müssen wir zuerst den Lückenpuffer an diese Stelle verschieben und ihn mit diesen Zeichen füllen. Und wenn wir über unseren Puffer hinausgingen, erstellen Sie ihn natürlich irgendwie neu. So sieht es auf dem Bild aus.

Wie Sie sehen können, bewegen wir uns zunächst für eine lange Zeit auf einem kleinen Lückenpuffer (blaues Rechteck) zum Bearbeitungsort (tauschen Sie einfach die Zeichen nacheinander vom linken und rechten Rand aus). Dann verwenden wir diesen Puffer und geben dort Zeichen ein.
Wie Sie sehen können, gibt es keine Bewegung von Megabyte an Zeichen, die Einfügung ist für eine konstante Zeit sehr schnell und es scheint, dass alle glücklich sind. Alles scheint in Ordnung zu sein, aber wenn unser Prozessor sehr langsam ist, wird ziemlich viel Zeit damit verschwendet, den Lückenpuffer und den Text hin und her zu bewegen. Dies machte sich insbesondere bei sehr kleinen Megahertz bemerkbar.
Stück Tisch
Zu dieser Zeit schrieb ein Unternehmen namens Microsoft einen Texteditor Word. Sie beschlossen, eine andere Idee anzuwenden, um die Bearbeitung zu beschleunigen, die als "Piece Table" bezeichnet wird, nämlich "Piece Table". Und sie schlugen vor, den Text des Editors in derselben einfachsten Zeichenfolge zu speichern, die sich nicht ändert, und alle Änderungen in einer separaten Tabelle von denselben bearbeiteten Teilen abzulegen.

Wenn wir also ein Zeichen nach Versatz suchen müssen, müssen wir dieses Stück finden, das wir bearbeitet haben, und dieses Zeichen daraus extrahieren. Wenn es nicht vorhanden ist, gehen Sie zum Originaltext. Das Einfügen eines Symbols wird einfacher. Wir müssen nur dieses neue Stück erstellen und zur Tabelle hinzufügen. So sieht es auf dem Bild aus:
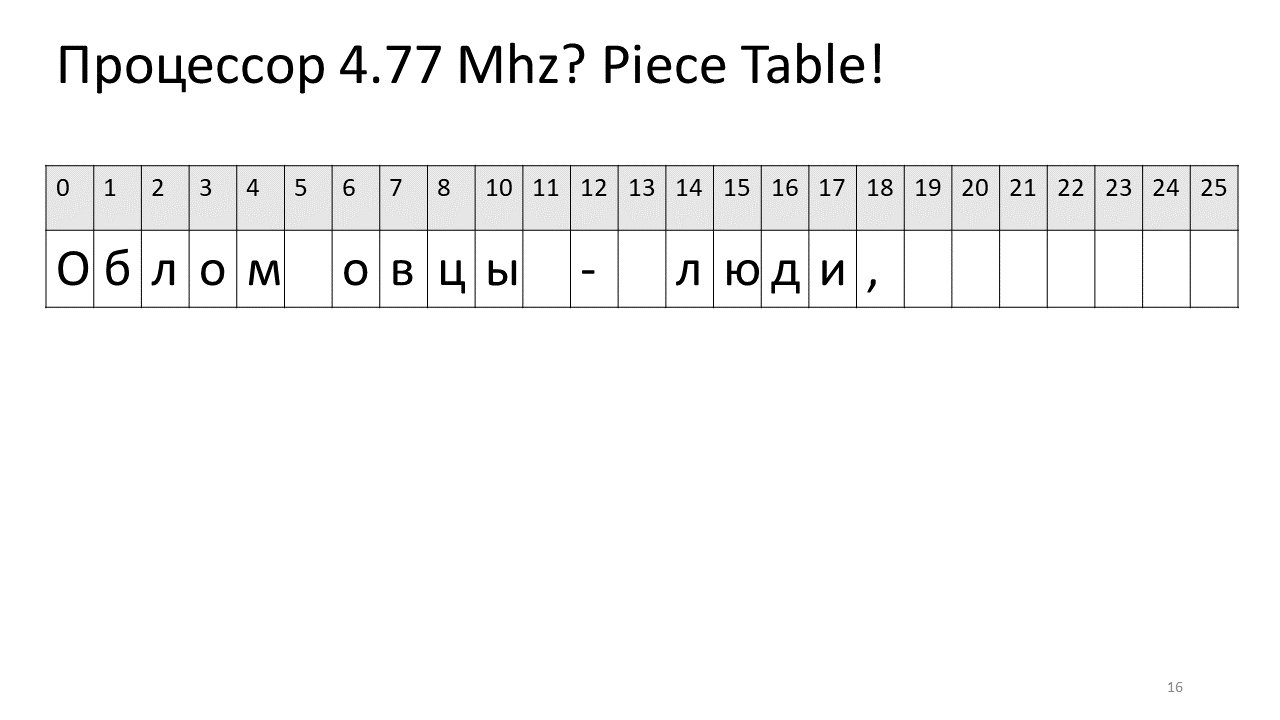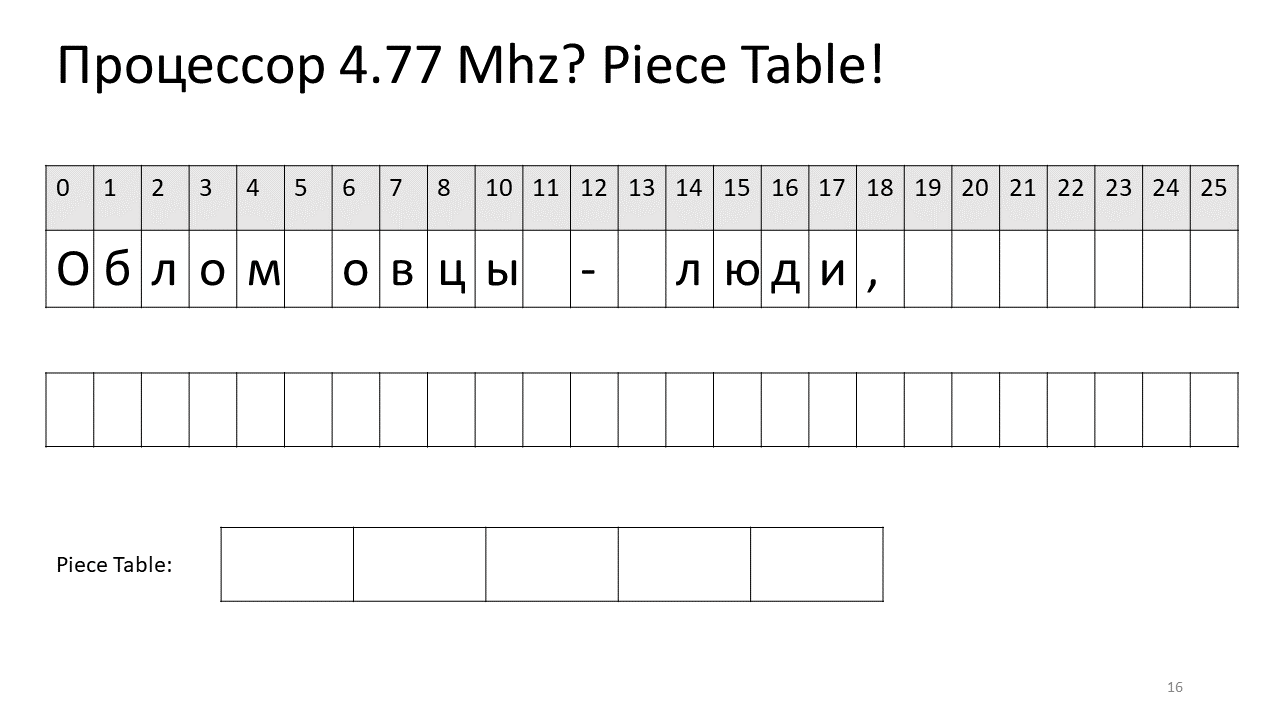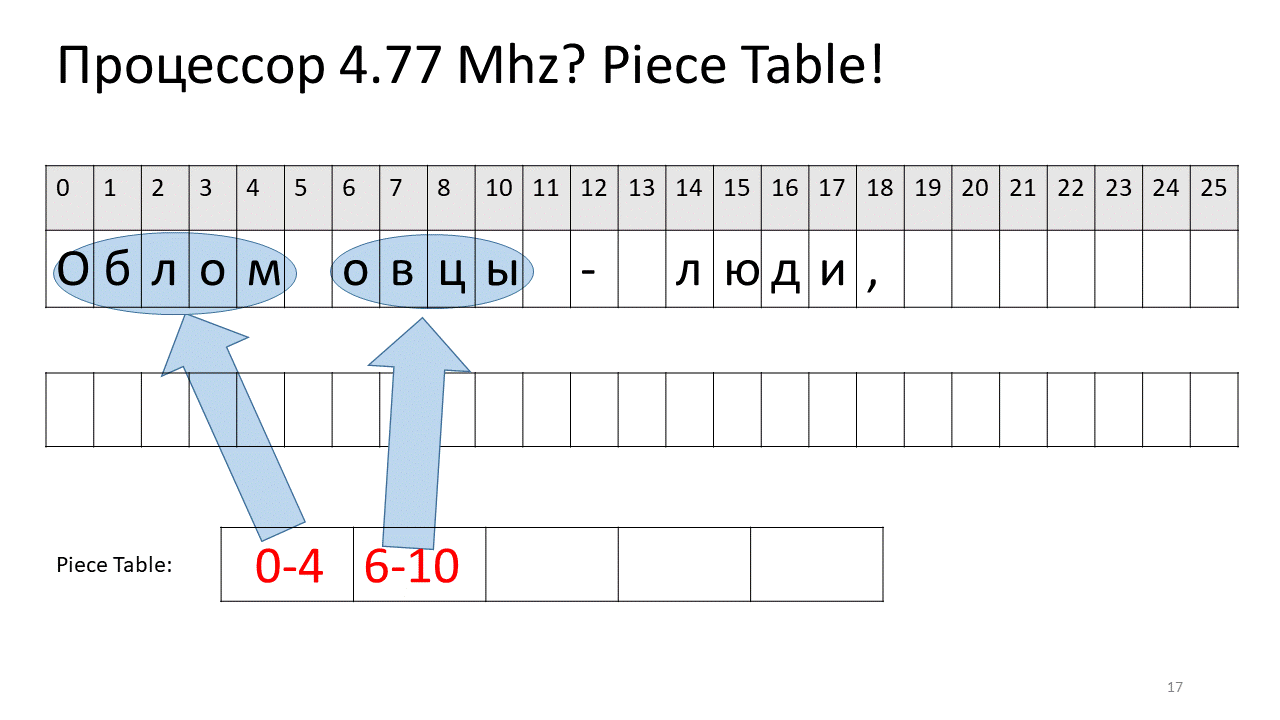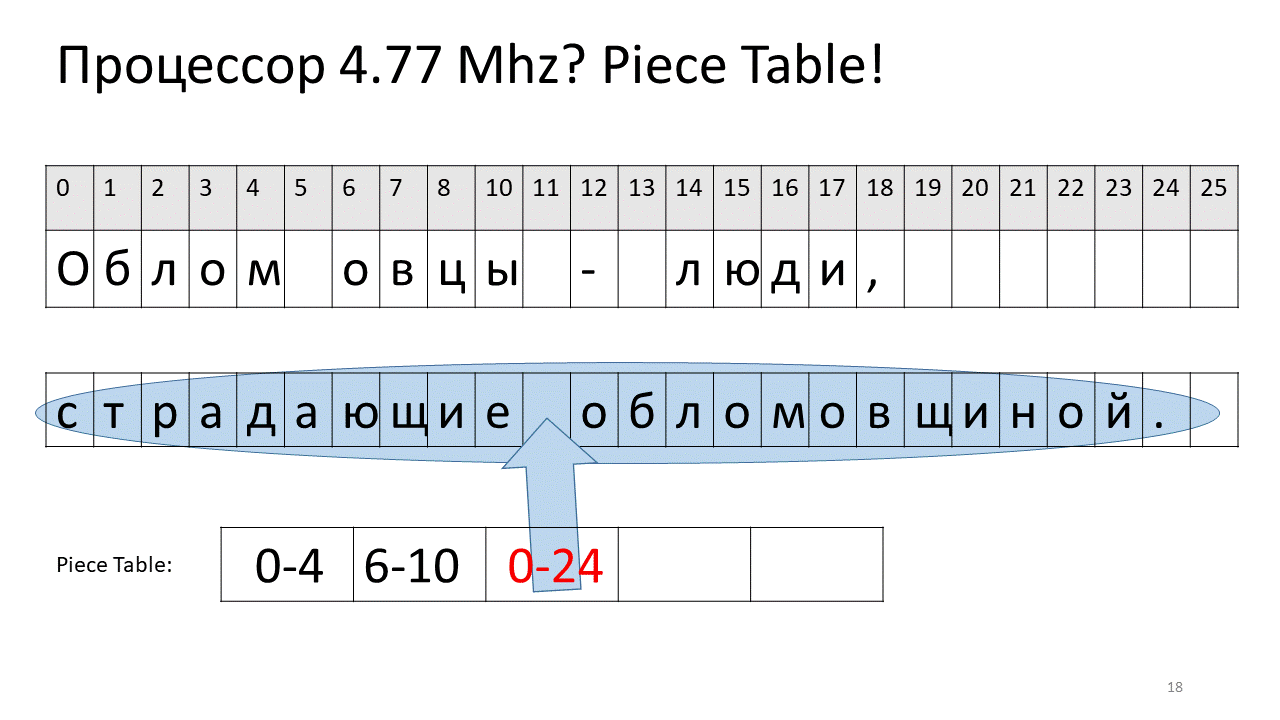
Hier wollten wir das Leerzeichen bei Offset 5 entfernen. Dazu fügen wir der Slices-Tabelle zwei neue Teile hinzu: eines zeigt das erste Fragment („Bummer“) und das zweite das Fragment nach der Bearbeitung („Schaf“). Es stellt sich heraus, dass die Lücke von ihnen verschwindet, diese beiden Teile zusammengeklebt sind und wir bereits einen neuen Text ohne Leerzeichen erhalten: „Oblomovtsy“. Dann fügen wir den neuen Text ("Leiden unter Oblomovismus") am Ende hinzu. Verwenden Sie einen zusätzlichen Puffer und fügen Sie der Stücktabelle ein neues Slice hinzu, das auf diesen neuesten hinzugefügten Text verweist.
Wie Sie sehen können, gibt es keine Bewegung hin und her, der gesamte Text bleibt an Ort und Stelle. Die schlechte Nachricht ist, dass es immer schwieriger wird, zum Symbol zu gelangen, da das Durchsuchen all dieser Teile ziemlich schwierig ist.
Zusammenfassend.
Was ist gut an
Piece Table :
- Schnell einbetten;
- Einfach rückgängig zu machen;
- Nur anhängen.
Was ist schlecht:
- Es ist furchtbar schwierig, auf ein Dokument zuzugreifen.
- Es ist furchtbar schwer umzusetzen.
Mal sehen, wen wir normalerweise was benutzen.
NetBeans, Eclipse und Emacs verwenden Gap Buffer - gut gemacht! Vi stört nicht und verwendet nur eine Liste von Zeilen. Word verwendet den Piece Table (sie haben kürzlich ihre alten Sorten angelegt und dort kann man sogar etwas verstehen).
Atom ist interessanter. Bis vor kurzem haben sie sich nicht darum gekümmert und eine JavaScript-Liste von Zeilen verwendet. Und dann beschlossen sie, alles in C ++ neu zu schreiben und häuften eine ziemlich komplizierte Struktur an, die der Piece Table ähnlich zu sein scheint. Diese Teile werden jedoch nicht in der Liste, sondern im Baum und im sogenannten Spreizbaum gespeichert. Dies ist ein Baum, der sich beim Einfügen selbst anpasst, sodass die letzten Einfügungen schneller sind. Sie haben eine sehr komplizierte Sache gemacht.
Was verwendet Intellij IDEA?
Nein, kein Lückenpuffer. Nein, du liegst auch falsch, kein Stück Tisch.
Ja, ganz richtig, dein eigenes Fahrrad.
Tatsache ist, dass sich die Anforderungen der IDE zum Speichern von Text geringfügig von denen in einem normalen Texteditor unterscheiden. Die IDE benötigt Unterstützung für verschiedene knifflige Dinge wie Wettbewerbsfähigkeit, dh parallelen Zugriff auf Text vom Editor. Zum Beispiel, damit viele verschiedene Backwaren es lesen und etwas tun können. (Inspection ist ein kleiner Code, der das Programm auf die eine oder andere Weise analysiert - zum Beispiel nach Orten sucht, die eine NullPointerException auslösen). IDE benötigt auch Unterstützung für bearbeitbare Textversionen. Während Sie mit einem Dokument arbeiten, befinden sich mehrere Versionen gleichzeitig im Speicher, sodass diese langen Prozesse weiterhin die alte Version analysieren.
Die Probleme
Wettbewerbsfähigkeit / Versionierung
Um die Parallelität aufrechtzuerhalten, werden Textoperationen normalerweise in "synchronisierte" oder in Lese- / Schreibsperren eingeschlossen. Leider lässt sich dies nicht sehr gut skalieren. Ein anderer Ansatz ist unveränderlicher Text, d. H. Ein unveränderliches Textrepository.

So sieht ein Editor mit einem unveränderlichen Dokument als unterstützende Datenstruktur aus.
Wie funktioniert die Datenstruktur?
Anstelle eines Arrays von Zeichen haben wir ein neues Objekt vom Typ ImmutableText, das Text in Form eines Baums speichert, in dem kleine Teilzeichenfolgen in den Blättern gespeichert sind. Wenn er mit einem gewissen Versatz darauf zugreift, versucht er, das unterste Blatt in diesem Baum zu erreichen, und er wird bereits nach dem Symbol gefragt, auf das wir uns bezogen haben. Und wenn Sie Text einfügen, erstellt er einen neuen Baum und speichert ihn an der alten Stelle.

Zum Beispiel haben wir ein Dokument mit dem Text "Kalorienfrei". Es ist als Baum mit zwei Substitutionsblättern "Demon" und "High-Calorie" implementiert. Wenn wir die Zeile "hübsch" in die Mitte einfügen möchten, wird eine neue Version unseres Dokuments erstellt. Und genau wird eine neue Wurzel erstellt, an die bereits drei Blätter angehängt sind: „Dämon“, „genug“ und „kalorienreich“. Darüber hinaus beziehen sich zwei dieser neuen Blätter möglicherweise auf die erste Version unseres Dokuments. Und für das Blatt, in das wir die Zeile „hübsch“ eingefügt haben, wird ein neuer Scheitelpunkt zugewiesen. Hier sind sowohl die erste als auch die zweite Version gleichzeitig verfügbar und alle unveränderlich, unveränderlich. Alles sieht gut aus.
Wer benutzt welche kniffligen Strukturen?

In GNOME verwenden beispielsweise einige ihrer Standard-Widgets eine Struktur namens Rope. Xi-Editor, der neue brillante Editor von
Raf Levien , verwendet Persistent Rope. Und Intellij IDEA verwendet diesen unveränderlichen Baum. Hinter all diesen Namen verbirgt sich tatsächlich mehr oder weniger dieselbe Datenstruktur mit einer baumartigen Darstellung des Textes. Außer dass GtkTextBuffer Mutable Rope verwendet, d. H. Einen Baum mit veränderlichen Eckpunkten, und Intellij IDEA und Xi-Editor - Unveränderlich.
Das nächste, was bei der Entwicklung eines Zeichenrepositorys in modernen IDEs berücksichtigt werden muss, sind Multicats. Mit dieser Funktion können Sie mit mehreren Wagen an mehreren Stellen gleichzeitig drucken.

Wir können etwas drucken und gleichzeitig an mehreren Stellen des Dokuments das einfügen, was wir dort gedruckt haben. Wenn wir uns ansehen, wie unsere untersuchten Datenstrukturen auf Multicarets reagieren, werden wir etwas Interessantes sehen.
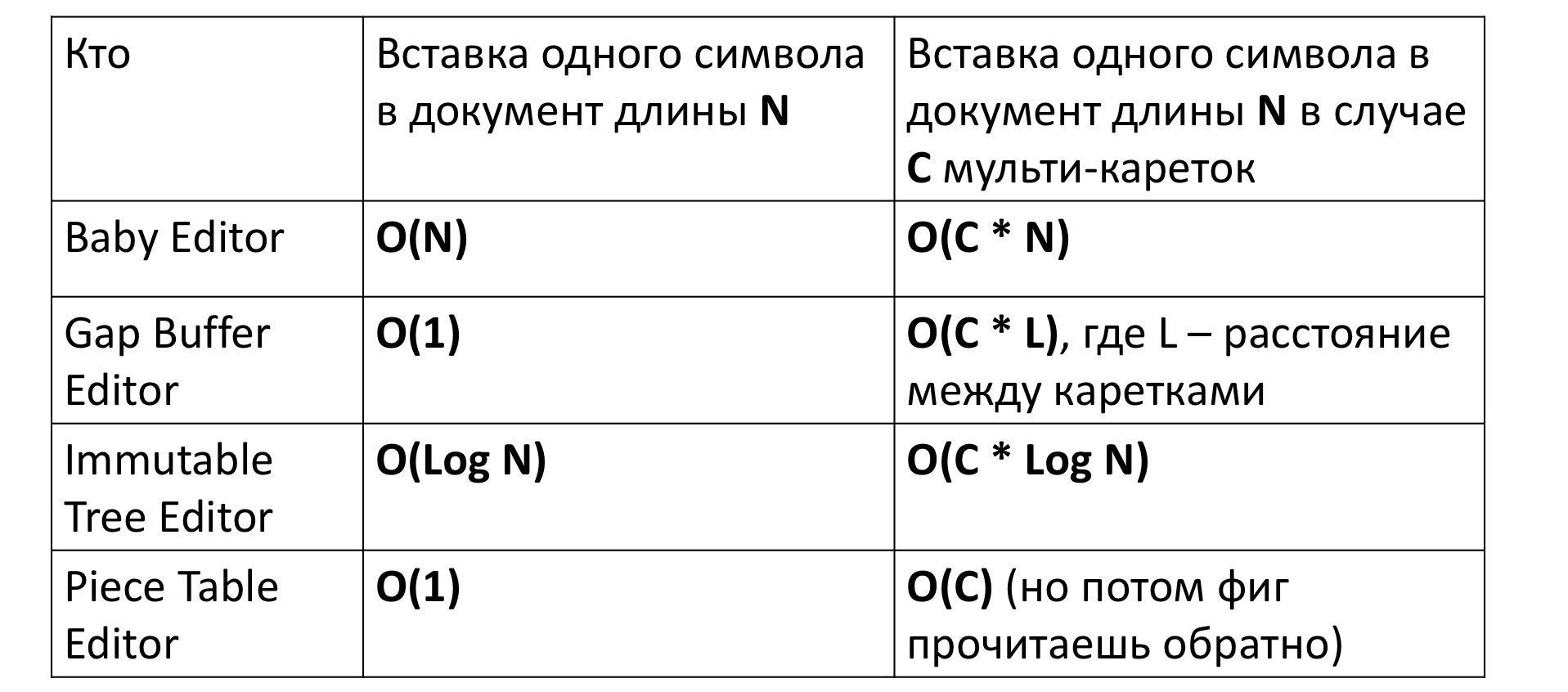
Wenn wir ein Zeichen in unseren allerersten primitiven Editor einfügen, dauert es natürlich eine lineare Zeit, um eine Reihe von Zeichen hin und her zu bewegen. Dies wird als O (N) geschrieben. Für den auf Gap Buffer basierenden Editor ist wiederum eine konstante Zeit erforderlich, für die er geprägt wurde.
Bei einem unveränderlichen Baum hängt die Zeit logarithmisch von der Größe ab, da Sie zuerst von der Spitze des Baums zu seinem Blatt gehen müssen - dies ist der Logarithmus und dann für alle Scheitelpunkte auf dem Pfad, um neue Scheitelpunkte für den neuen Baum zu erstellen - dies ist wieder der Logarithmus. Stück Tabelle erfordert auch eine Konstante.
Aber alles ändert sich ein wenig, wenn wir versuchen, die Zeit zu messen, zu der ein Zeichen in einen Editor mit mehreren Wagen eingefügt wird, dh an mehreren Stellen gleichzeitig eingefügt wird. Auf den ersten Blick scheint sich die Zeit proportional um den Faktor C zu erhöhen - die Anzahl der Stellen, an denen das Symbol eingefügt wird. Genau das passiert mit Ausnahme von Gap Buffer. In seinem Fall erhöht die Zeit anstelle der C-Zeiten unerwartet einige unverständliche C * L-Zeiten, wobei L der durchschnittliche Abstand zwischen den Wagen ist. Warum passiert das?
Stellen Sie sich vor, wir müssen die Zeile ", on" an zwei Stellen in unser Dokument einfügen.
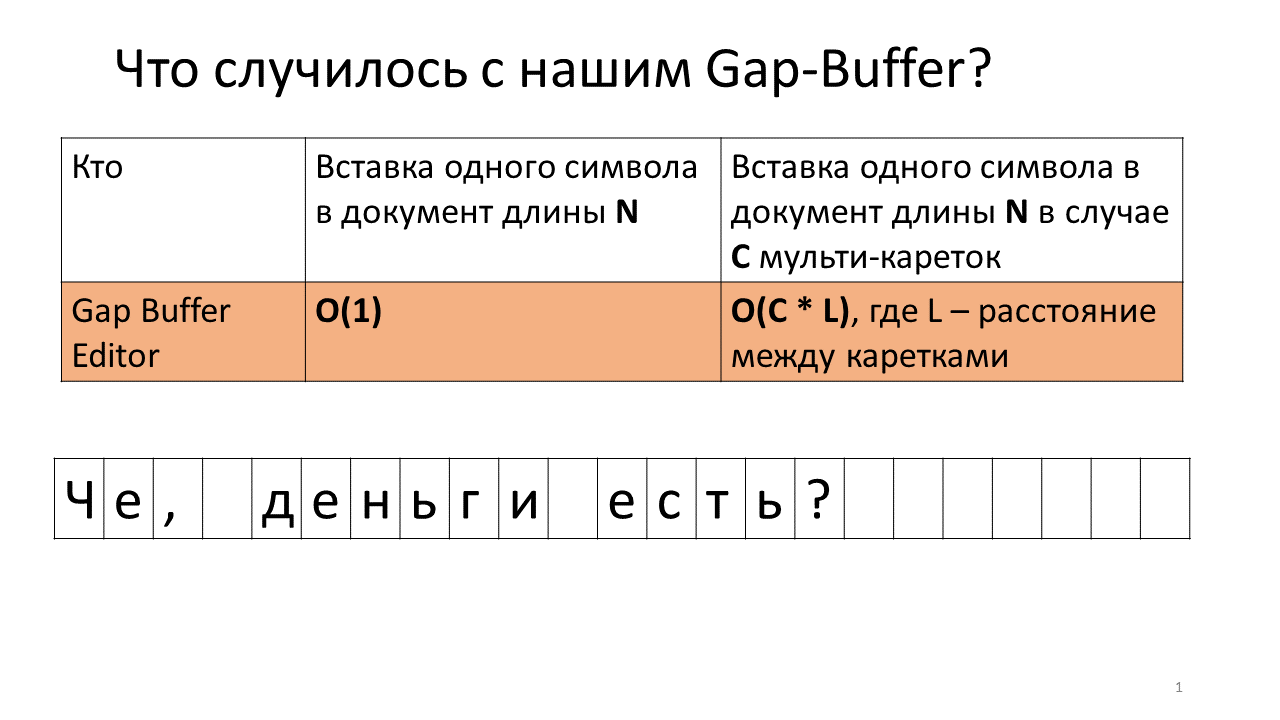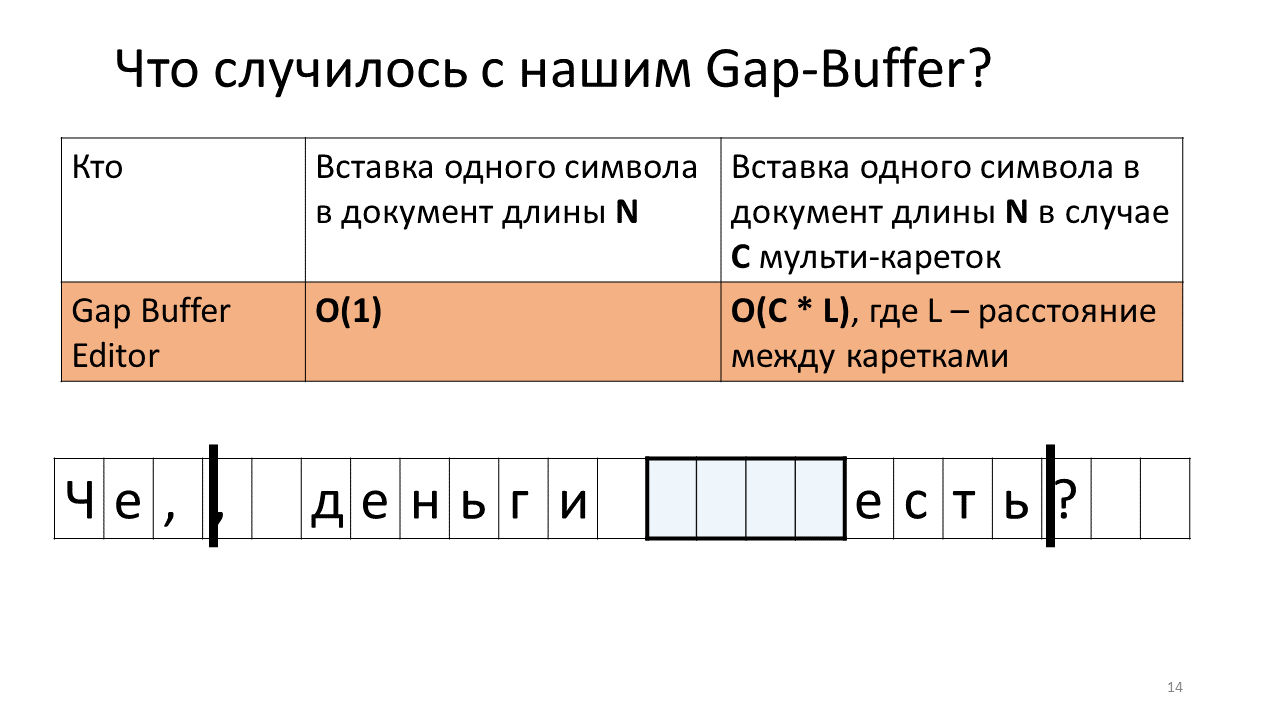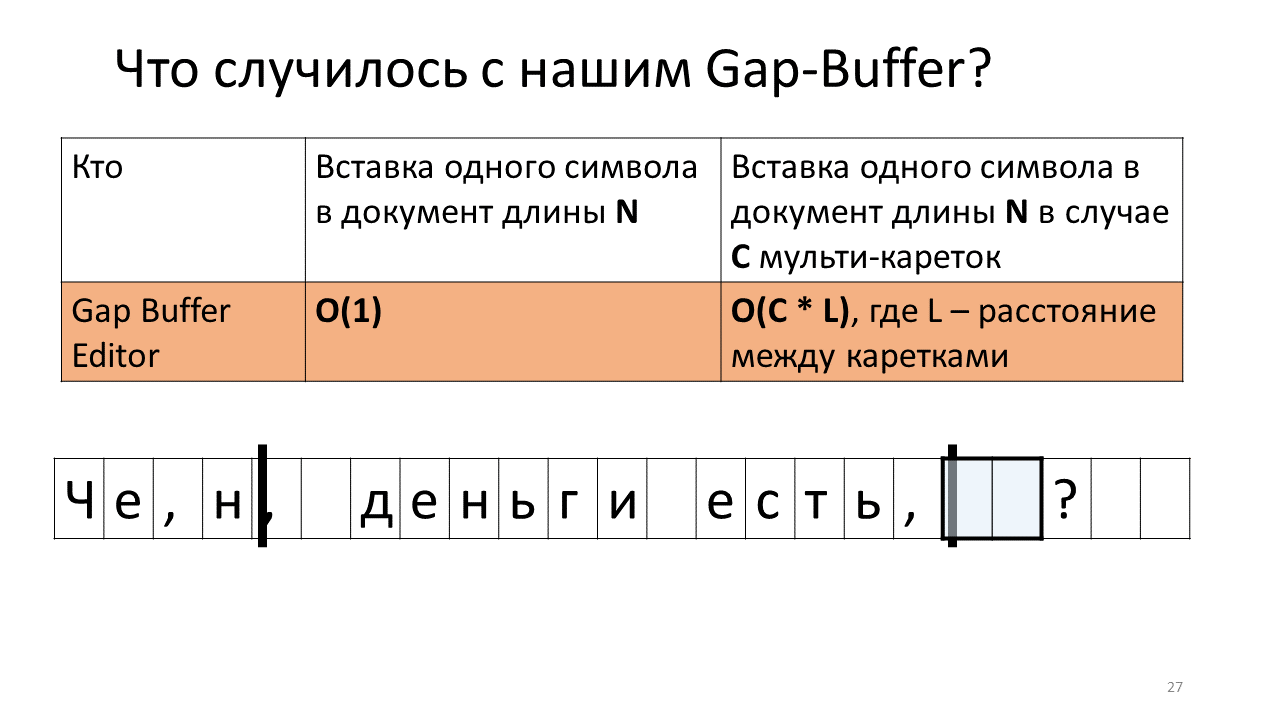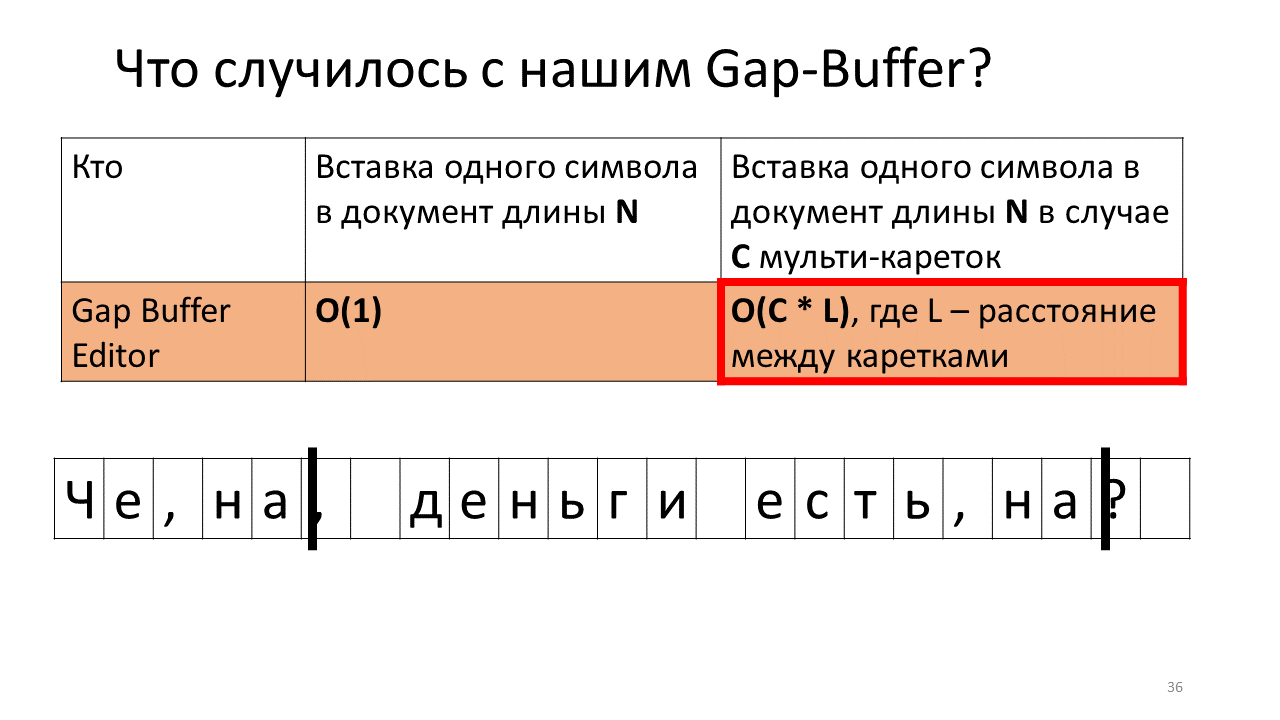
Dies geschieht zu diesem Zeitpunkt im Editor.
- Erstellen Sie im Editor einen Lückenpuffer (ein kleines blaues Rechteck im Bild).
- Wir starten zwei Wagen (schwarze fette vertikale Linien);
- Wir versuchen zu drucken;
- Fügen Sie ein Komma in unseren Lückenpuffer ein.
- Sie sollten es jetzt anstelle des zweiten Wagens einsetzen.
- Dazu müssen wir unseren Lückenpuffer an die Position des nächsten Wagens bewegen.
- Bedrucken Sie das Komma an zweiter Stelle.
- Jetzt müssen Sie das nächste Zeichen an der Position des ersten Wagens einfügen.
- Und wir müssen unseren Lückenpuffer zurückschieben;
- Fügen Sie den Buchstaben "n" ein.
- Und wir bewegen unseren langmütigen Puffer an den Ort des zweiten Wagens;
- Wir fügen dort unser "n" ein;
- Bewegen Sie den Puffer zurück, um das nächste Zeichen einzufügen.
Fühlen Sie, wohin alles geht?
Ja, es stellt sich heraus, dass aufgrund dieser zahlreichen Bewegungen des Puffers hin und her unsere Gesamtzeit zunimmt. Ehrlich gesagt ist es nicht so, dass es direkt entsetzt ist, da es zugenommen hat - erbärmliche Megabyte, Gigabyte für einen modernen Computer hin und her zu bewegen, ist kein Problem, aber es ist interessant, dass diese Datenstruktur bei Multikaten radikal anders funktioniert.
Zu viele Zeilen? LineSet!
Welche anderen Probleme gibt es in einem normalen Texteditor? Das schwierigste Problem ist das Scrollen, dh das Neuzeichnen des Editors, während der Wagen in die nächste Zeile verschoben wird.

Wenn der Editor einen Bildlauf durchführt, müssen wir verstehen, von welcher Zeile aus welches Symbol wir den Text in unserem kleinen Fenster zeichnen müssen. Dazu müssen wir schnell verstehen, welche Linie welchem Versatz entspricht.
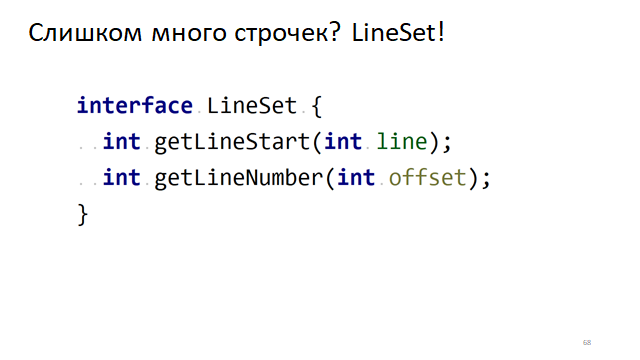
Hierfür gibt es eine offensichtliche Schnittstelle, wenn wir den Versatz im Text nach Zeilennummer verstehen müssen. Und umgekehrt, durch den Versatz im Text zu verstehen, in welcher Zeile es ist. Wie geht das schnell?
Zum Beispiel so:
Organisieren Sie diese Linien in einem Baum und markieren Sie jeden Scheitelpunkt dieses Baums, indem Sie den Anfang der Linie und das Ende der Linie verschieben. Um anhand des Versatzes zu verstehen, in welcher Zeile er sich befindet, müssen Sie lediglich eine logarithmische Suche in diesem Baum ausführen und ihn finden.
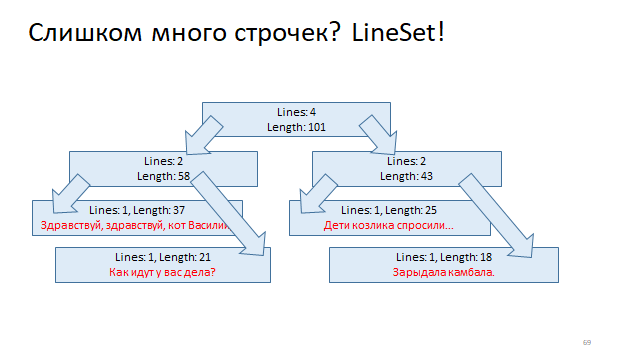
Ein anderer Weg ist noch einfacher.
Schreiben Sie in die Tabelle den Versatz des Zeilenanfangs und des Zeilenendes. Um dann den Versatz von Anfang und Ende durch die Zeilennummer zu ermitteln, müssen Sie auf den Index zugreifen.
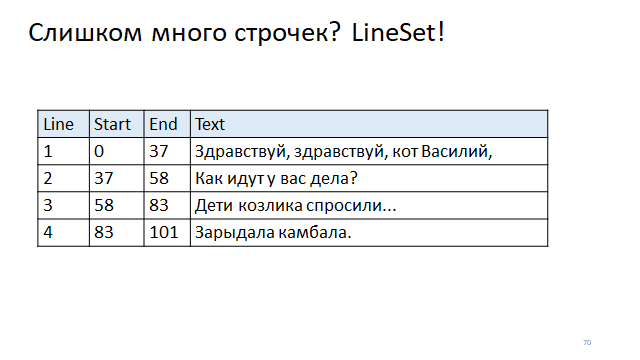
Interessanterweise werden in der realen Welt beide Methoden verwendet.

Beispielsweise verwendet Eclipse eine solche Holzstruktur, die, wie Sie sehen können, sowohl zum Lesen als auch zum Aktualisieren in einer logarithmischen Zeit funktioniert. Und IDEA verwendet eine Tabellenstruktur, für die das Lesen eine schnelle Konstante ist, es ist eine Indexumkehr in einer Tabelle, aber die Neuerstellung ist ziemlich langsam, da Sie die gesamte Tabelle neu erstellen müssen, wenn Sie die Länge einer Zeile ändern.
Immer noch zu viele Zeilen? Falten!
Was ist sonst noch schlimm, das über Texteditoren stolpert? Zum Beispiel Falten. Dies sind Textteile, die Sie „reduzieren“ und stattdessen etwas anderes anzeigen können.

Diese Punkte auf einem grünen Hintergrund im Bild verbergen viele Symbole hinter uns, aber wenn wir nicht daran interessiert sind, sie anzusehen (wie zum Beispiel bei den längsten langweiligen Java-Dokumenten oder Importlisten), verstecken wir sie und reduzieren sie Auslassungspunkte.
Und auch hier müssen Sie verstehen, wann es endet und wann die Region, die wir anzeigen müssen, beginnt und wie Sie alles schnell aktualisieren können. Wie das organisiert ist, werde ich etwas später erzählen.
Zu lange Schlangen? Soft Wrap!

Moderne Editoren können auch nicht ohne Soft Wrap leben. Das Bild zeigt, dass der Entwickler die JavaScript-Datei nach der Minimierung geöffnet und sofort bereut hat. Diese riesige JavaScript-Zeile passt, wenn wir versuchen, sie im Editor anzuzeigen, nicht in einen Bildschirm. Daher reißt Soft Wrap es gewaltsam in mehrere Linien und schiebt es in den Bildschirm.
Wie es organisiert ist - später.
Zu wenig Schönheit

Und schließlich möchte ich auch den Texteditoren Schönheit verleihen. Markieren Sie beispielsweise einige Wörter. Im obigen Bild sind die Schlüsselwörter fett blau hervorgehoben, einige statische Methoden kursiv, einige Anmerkungen - auch in einer anderen Farbe.
Wie lagern und verarbeiten Sie noch Falten, Soft-Wraps und Highlights?
Es stellt sich heraus, dass dies alles im Prinzip ein und dieselbe Aufgabe ist.
Zu wenig Schönheit? Range Textmarker!

Um all diese Funktionen zu unterstützen, müssen wir lediglich einige Textattribute an einem bestimmten Versatz in den Text einfügen, z. B. Farbe, Schriftart oder Text zum Falten. Darüber hinaus müssen diese Textattribute an dieser Stelle ständig aktualisiert werden, damit sie alle Arten von Einfügungen und Löschungen überstehen.
Wie wird das normalerweise umgesetzt? Natürlich in Form eines Baumes.
Problem: zu viel Schönheit? Intervallbaum!

Zum Beispiel haben wir hier einige gelbe Markierungen, die wir im Text behalten möchten. Die Intervalle dieser Highlights fügen wir einem Suchbaum hinzu, dem sogenannten Intervallbaum. Dies ist der gleiche Suchbaum, aber etwas kniffliger, da Intervalle anstelle von Zahlen gespeichert werden müssen.
Und da es sowohl gesunde als auch kleine Intervalle gibt, ist es keine triviale Aufgabe, sie zu sortieren, miteinander zu vergleichen und in einen Baum zu legen. Obwohl in der Informatik sehr bekannt. Dann schauen Sie sich in Ihrer Freizeit irgendwie an, wie es funktioniert. Also nehmen wir alle unsere Intervalle und setzen sie in einen Baum, und dann führt jede Änderung des Textes irgendwo in der Mitte zu einer logarithmischen Änderung in diesem Baum. Das Einfügen eines Zeichens sollte beispielsweise dazu führen, dass alle Intervalle rechts von diesem Zeichen aktualisiert werden. Dazu finden wir alle dominanten Scheitelpunkte für dieses Symbol und geben an, dass alle ihre Scheitelpunkte um ein Symbol nach rechts verschoben werden müssen.
Willst du immer noch Schönheit? Ligaturen!

Es gibt immer noch so eine schreckliche Sache - Ligaturen, die ich auch gerne unterstützen würde. Dies sind verschiedene Schönheiten, wie das Zeichen "! =" In Form eines großen Glyphen "ungleich" usw. gezeichnet ist. Glücklicherweise setzen wir hier auf einen Schwenkmechanismus, um diese Ligaturen zu unterstützen. Und nach unserer Erfahrung arbeitet er anscheinend auf einfachste Weise. In der Schriftart ist eine Liste all dieser Zeichenpaare gespeichert, die zusammen eine Art knifflige Ligatur bilden. Beim Zeichnen der Linie durchläuft Swing einfach alle diese Paare, findet die erforderlichen und zeichnet sie entsprechend. Wenn die Schrift viele Ligaturen enthält, wird die Anzeige anscheinend proportional langsamer.
Bremsen kippen
Und vor allem - ein weiteres Problem, das in modernen komplexen Editoren auftritt, ist die Optimierung des Trinkgeldes, dh das Drücken von Tasten und das Anzeigen des Ergebnisses.

Wenn Sie in Intellij IDEA einsteigen und sehen, was passiert, wenn Sie einen Knopf drücken, gibt es zufällig den folgenden Horror:
- Auf Knopfdruck müssen wir sehen, ob wir uns im Popup für die Fertigstellung befinden, um das Menü für die Fertigstellung zu schließen, wenn wir beispielsweise eine Eingabetaste eingeben.
- Sie müssen überprüfen, ob sich die Datei unter einem schwierigen Versionskontrollsystem wie Perforce befindet, das einige Maßnahmen ergreifen muss, um mit der Bearbeitung zu beginnen.
- Überprüfen Sie, ob das Dokument einen bestimmten Bereich enthält, der nicht gedruckt werden kann, z. B. einige automatisch generierte Texte.
- Wenn das Dokument durch einen Vorgang beendet wird, der nicht beendet wurde, müssen Sie die Formatierung abschließen und erst dann fortfahren.
- injected-, , , - .
- auto popup handler, , , .
- info , , . selection remove, selection , . selection , .
- typed handler, , .
- .
- undo, virtual space' write action.
- , .
!
, , . , . , listener , , - . editor view. - listener'.
, , - DocumentListener?
Editor.documentChanged() :
- error stripe;
- gutter size, ;
- editor component size, ;
- ;
- soft wrap, ;
- repaint().
repaint() — Swing, . , Repaint Swing.
- , repaint , :

paint-, , .
, , ?

, , . Intellij IDEA .

, - - , , , . ! , , , - — ! , - . . «Zero latency typing».
— .
? , — , Google Docs - - .
:
, , .
- . , , . . — , «intention preservation». , - , , , . — . , - , .
Operation transformation
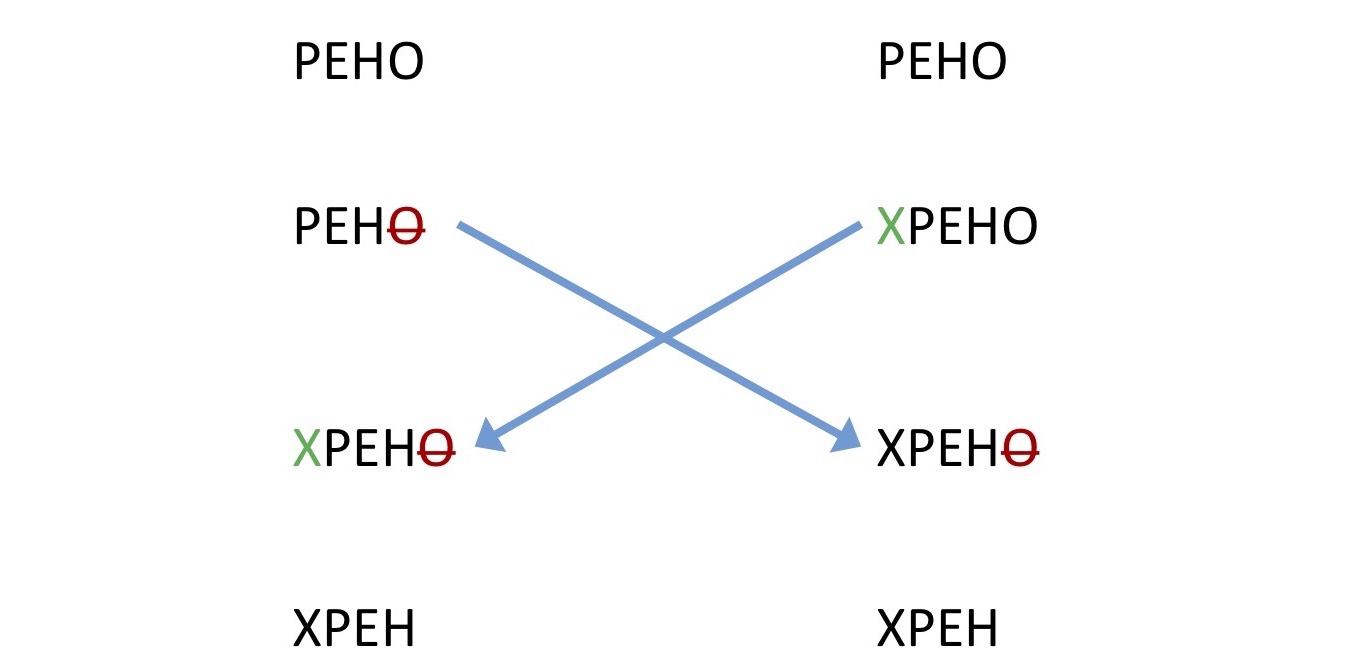
, , «operation transformation». . , - : , . Operation transformation . , , , - . , . , - . , , .
, , , . «TP2 puzzle».
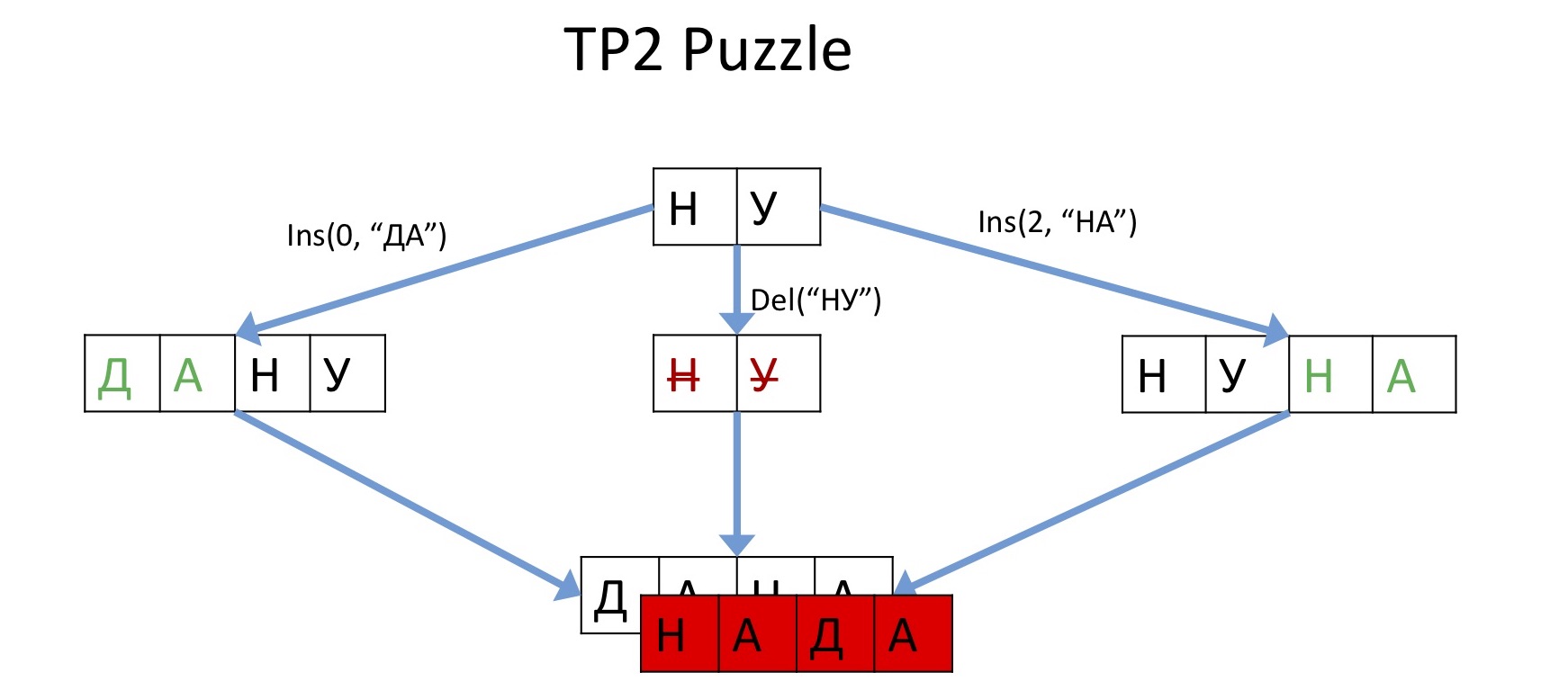
- , , . , Operation transformation , , , («»). («»). , . , Operation transformation, - .
, Google Docs, Google Wave - Etherpad. Operation transformation .
Conflict-free replicated data type
: « , OT!» , , . , , , , 100% . «CRDT» (Conflict-free replicated data type).

, , . , , , . , . - ( ), () ( ).

?
Ja , G-counter', , . , . «+1» , «+1» , , — «2». , , . G-counter, , . G-counter, . , , . . — . , CRDT. , .
Conflict-free replicated inserts
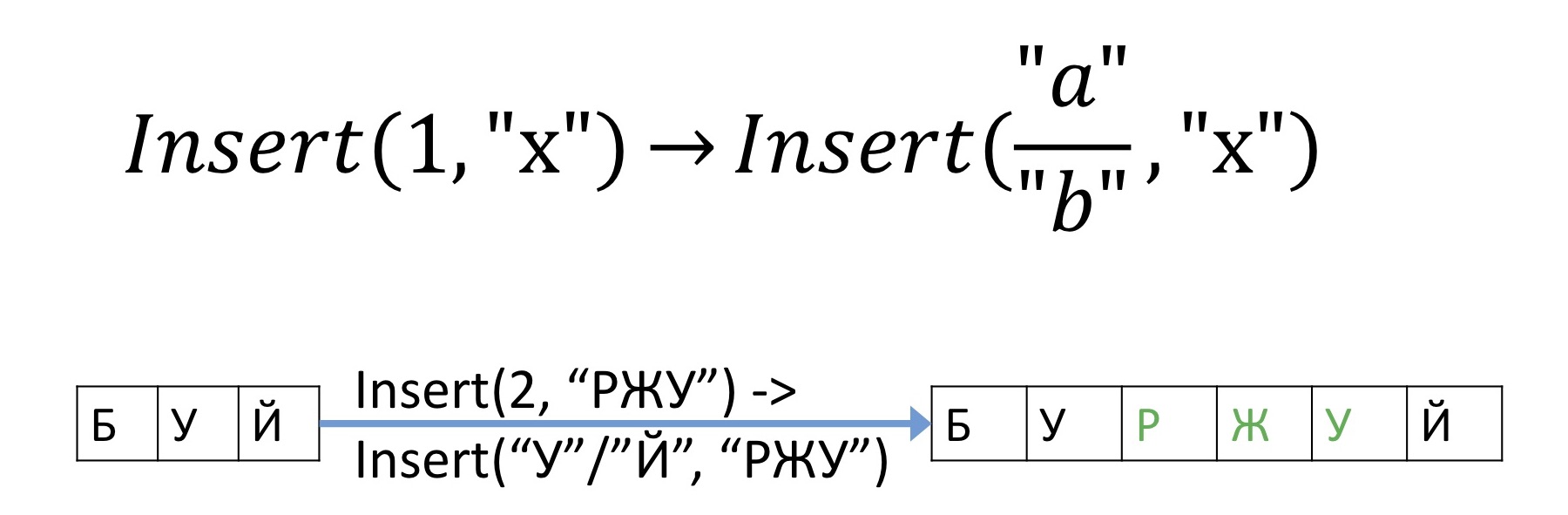
, , , . , , .
, , - - , , , , . , , , , . , , , , 2 «», , «» «» «».
Conflict-free replicated deletes
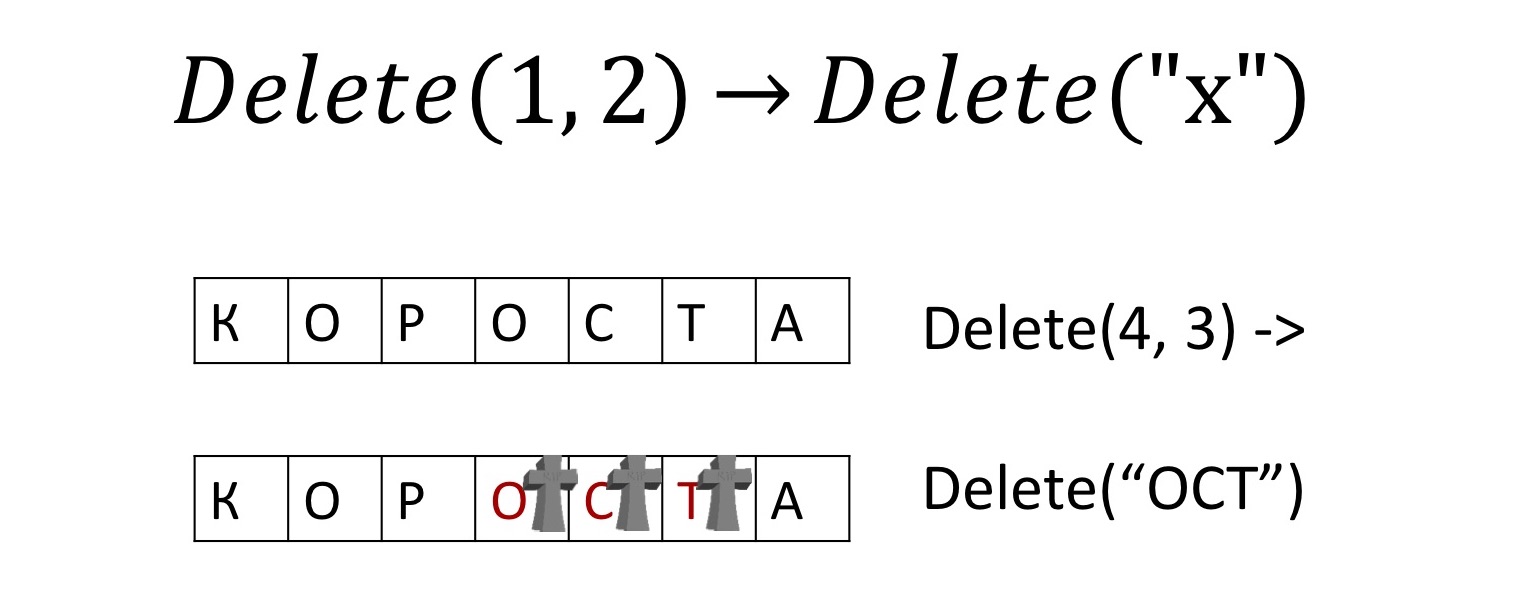
. , , , - . , , . , , , .
, .
Conflict-free replicated edits
, , CRDT - , , Xi-Editor, Fuchsia. , , .
Zipper
, «Zipper». , , . , , . , ( «» , , « »). , - . , - , . Zipper.
, . .
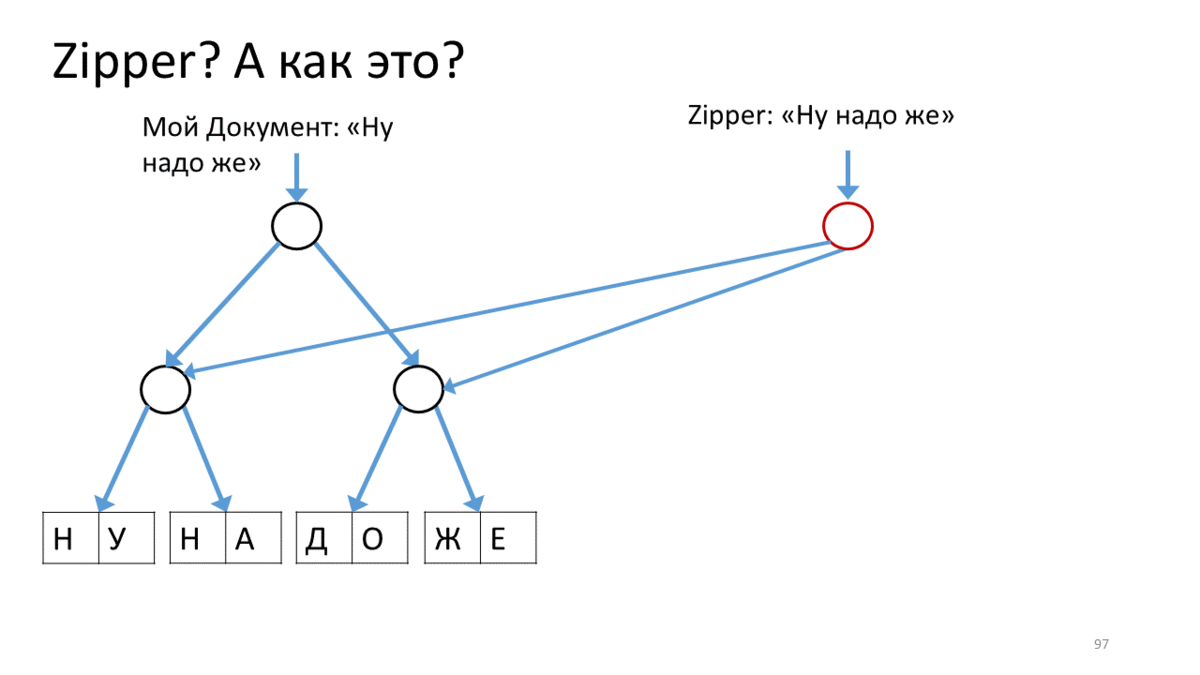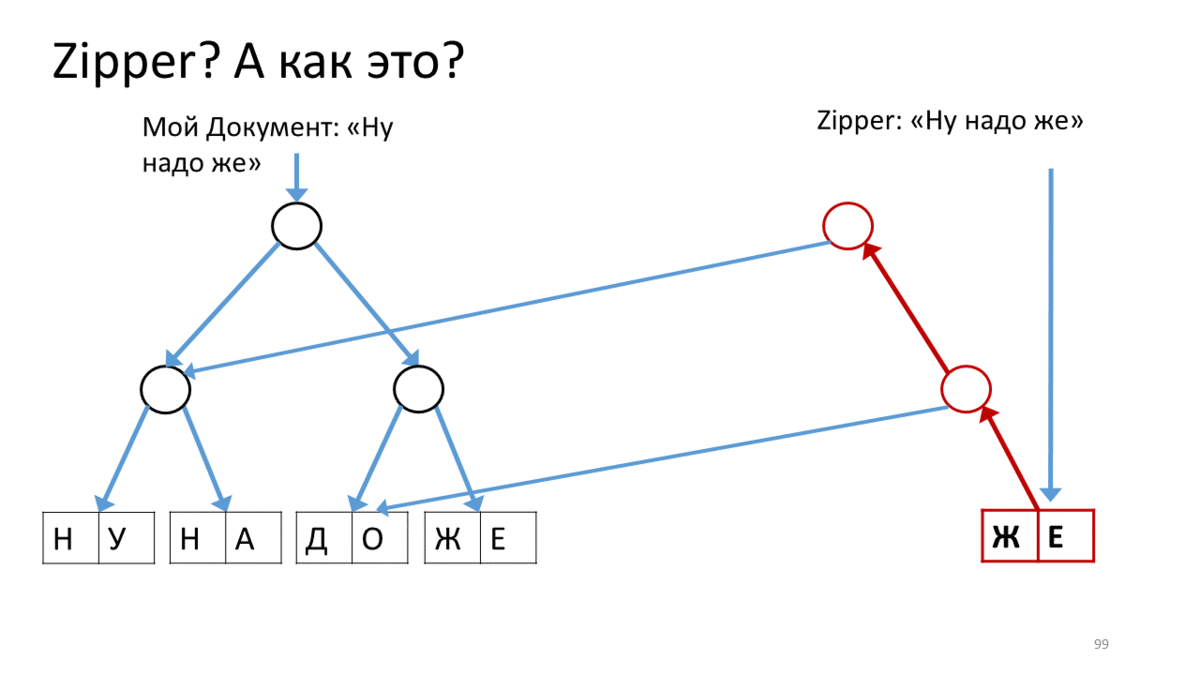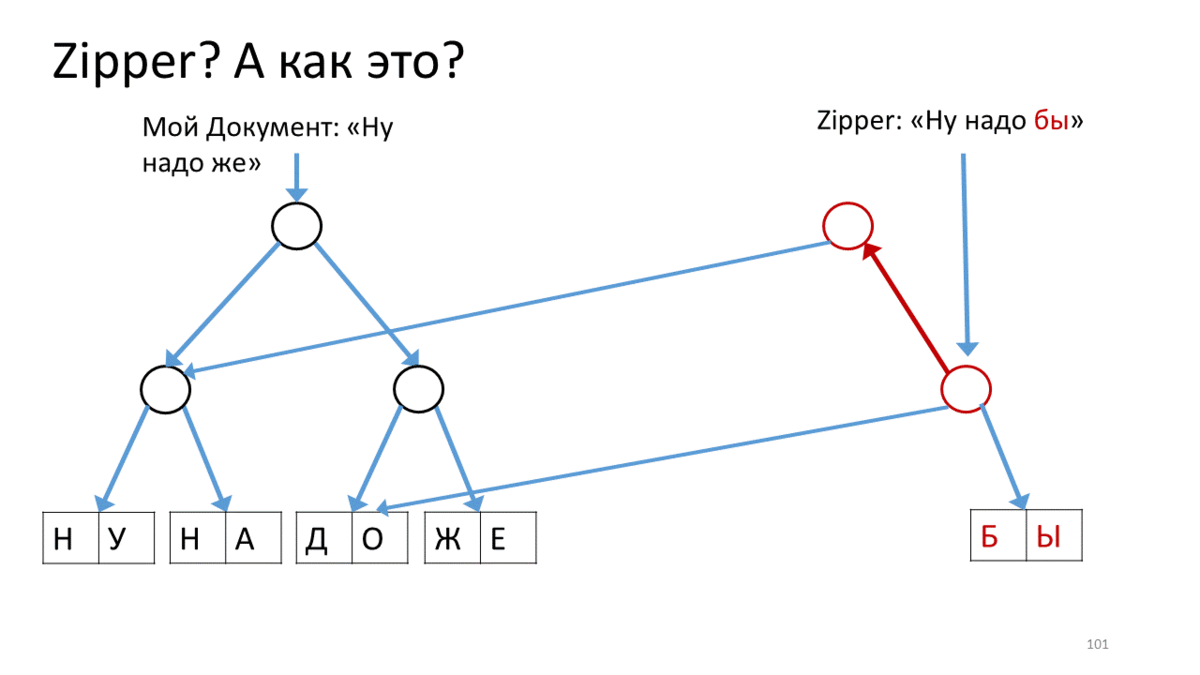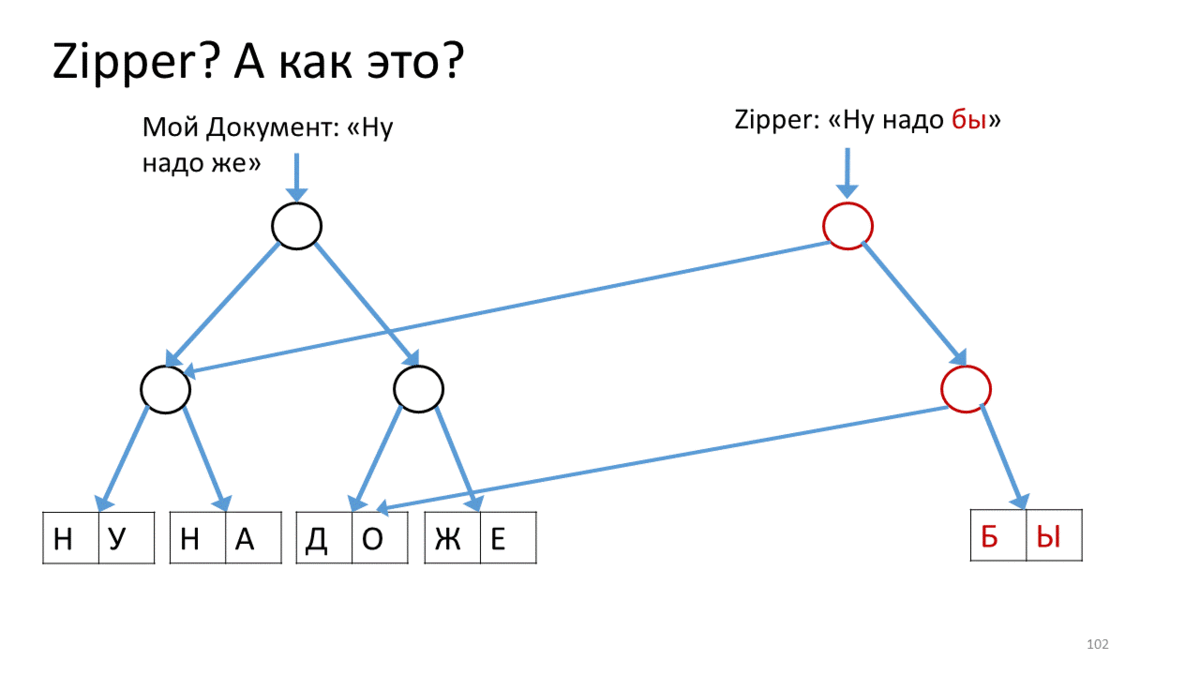
Zipper , (« »). Zipper' . — . (), , . , Zipper, - , . , , , ( ). , ( ). , . , .
, .
? -, , , , . , , . -, , . . Vielen Dank.
→
→
Referenzen
Zipper data structureCRDT in Xi Editor,
Visual Studio Code editor Piece Table .
, -
.
Möchten Sie noch leistungsfähigere Berichte, einschließlich Java 11? Dann warten wir beim Joker 2018 auf Sie . Referenten in diesem Jahr: Josh Long, John McClean, Marcus Hirth, Robert Scholte und andere ebenso coole Redner. Bis zur Konferenz verbleiben noch 17 Tage. Tickets auf der Website.