Am 22. September veranstalteten wir unsere erste nicht standardmäßige Mitap für Entwickler hoch belasteter Systeme. Es war sehr cool, viele positive Rückmeldungen zu Berichten und entschied sich daher, diese nicht nur hochzuladen, sondern auch für Habr zu entschlüsseln. Heute veröffentlichen wir eine Rede von Ivan Bubnov, DevOps von BIT.GAMES. Er sprach über die Implementierung des Consul Discovery Service in einem bereits funktionierenden Hochlastprojekt für die Möglichkeit einer schnellen Skalierung und eines Failovers von Stateful Services. Außerdem geht es darum, einen flexiblen Namespace für Backend-Anwendungen und Fallstricke zu organisieren. Nun ein Wort an Ivan.Ich verwalte die Produktionsinfrastruktur im BIT.GAMES-Studio und erzähle die Geschichte der Einführung des Konsuls von Hashicorp in unserem Projekt „Guild of Heroes“ - Fantasy-Rollenspiel mit asynchronem PvP für mobile Geräte. Verfügbar bei Google Play, App Store, Samsung, Amazon. DAU etwa 100.000, online von 10 bis 13 Tausend. Wir machen das Spiel in Unity, also schreiben wir den Client in C # und verwenden unsere eigene BHL-Skriptsprache für die Spielelogik. Wir schreiben den Serverteil in Golang (von PHP darauf umgestellt). Als nächstes folgt die schematische Architektur unseres Projekts.
 In der Tat gibt es viel mehr Dienste, es gibt nur die Grundlagen der Spielelogik.
In der Tat gibt es viel mehr Dienste, es gibt nur die Grundlagen der Spielelogik.Also was wir haben. Von den staatenlosen Diensten sind dies:
- nginx, das wir als Frontend- und Load-Balancer verwenden und Kunden nach Gewichtskoeffizienten an unsere Backends verteilen;
- Gamed - Backends, kompilierte Anwendungen von Go. Dies ist die zentrale Achse unserer Architektur. Sie erledigen den Löwenanteil der Arbeit und kommunizieren mit allen anderen Backend-Diensten.
Von den Stateful-Diensten haben wir folgende:
- Redis, mit dem wir heiße Informationen zwischenspeichern (wir organisieren damit auch Chat im Spiel und speichern Benachrichtigungen für unsere Spieler);
- Percona Server für MySQL ist ein Repository für persistente Informationen (wahrscheinlich das größte und langsamste in jeder Architektur). Wir verwenden die Gabel von MySQL und werden hier heute ausführlicher darauf eingehen.
Während des Designprozesses hofften wir (wie alle anderen auch), dass das Projekt erfolgreich sein und einen Sharding-Mechanismus vorsehen würde. Es besteht aus zwei MAINDB-Datenbankentitäten und den Shards selbst.

MAINDB ist eine Art Inhaltsverzeichnis - es speichert Informationen darüber, auf welchen bestimmten Shard-Daten über den Fortschritt des Players gespeichert sind. Die gesamte Kette des Informationsabrufs sieht also ungefähr so aus: Der Client greift auf das Frontend zu, das es wiederum nach Gewicht an eines der Backends verteilt, das Backend geht an MAINDB, lokalisiert den Shard des Players und wählt die Daten direkt aus dem Shard selbst aus.
Aber als wir entwarfen, waren wir kein großes Projekt, also beschlossen wir, Shards Shards nur nominell herzustellen. Sie befanden sich alle auf demselben physischen Server und höchstwahrscheinlich auf derselben Datenbankpartitionierung auf demselben Server.
Für die Sicherung haben wir die klassische Master-Slave-Replikation verwendet. Es war keine sehr gute Lösung (ich werde etwas später sagen, warum), aber der Hauptnachteil dieser Architektur war, dass alle unsere Backends über andere Backend-Dienste ausschließlich über IP-Adressen Bescheid wussten. Und im Falle eines weiteren lächerlichen Unfalls im Rechenzentrum vom Typ "
Entschuldigung, unser Techniker hat das Kabel Ihres Servers getroffen, während er einen anderen gewartet hat, und wir haben sehr lange gebraucht,
um herauszufinden, warum Ihr Server nicht in Kontakt tritt ", waren erhebliche Bewegungen von uns erforderlich. Erstens ist dies die Neuerstellung und Vorinstallation von Backends vom IP-Sicherungsserver für den Ort des fehlgeschlagenen. Zweitens ist es nach dem Vorfall erforderlich, unseren Master aus der Sicherung aus der Reserve wiederherzustellen, da er sich in einem inkonsistenten Zustand befand, und ihn mit derselben Replikation in einen koordinierten Zustand zu versetzen. Dann haben wir die Backends wieder zusammengesetzt und neu geladen. All dies verursachte natürlich Ausfallzeiten.
Es kam eine Zeit, in der unser technischer Direktor (für den ich ihm so sehr danke) sagte: "Leute, hört auf zu leiden, wir müssen etwas ändern, lasst uns nach Auswegen suchen." Zunächst wollten wir einen einfachen, verständlichen und vor allem einfach zu verwaltenden Prozess der Skalierung und Migration unserer Datenbanken von Ort zu Ort erreichen, falls erforderlich. Darüber hinaus wollten wir durch die Automatisierung von Failovers eine hohe Verfügbarkeit erreichen.
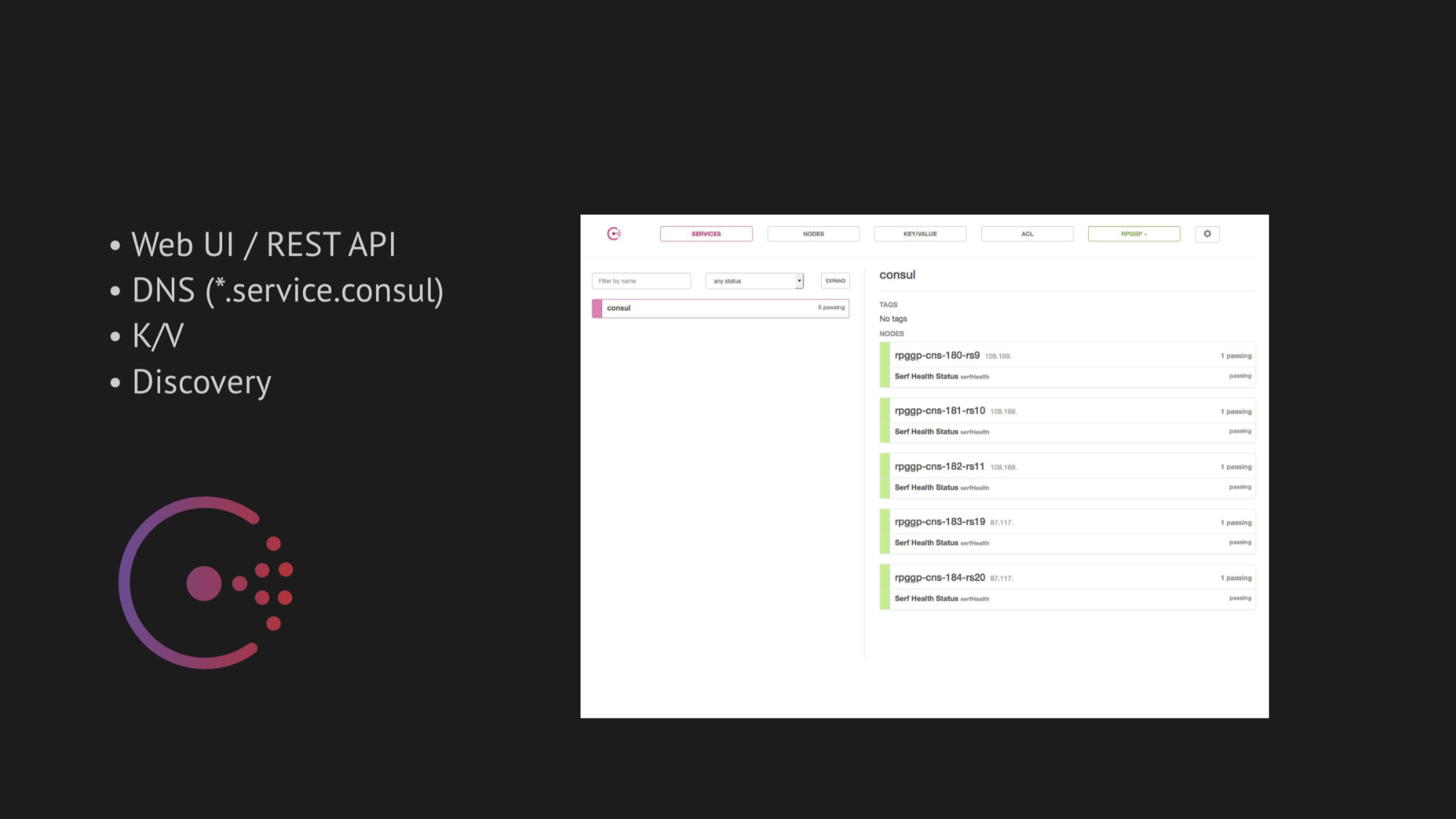
Die zentrale Achse unserer Forschung ist Konsul aus Hashicorp geworden. Erstens wurden wir beraten, und zweitens waren wir sehr angetan von seiner Einfachheit, Freundlichkeit und dem hervorragenden Technologie-Stack in einer Box: Discovery-Service mit Healthcheck, Schlüsselwertspeicherung und das Wichtigste, was wir verwenden wollten, war DNS, das an uns Adressen aus der Domäne service.consul auflöst.
Consul bietet auch großartige Web-Benutzeroberflächen und REST-APIs für die Verwaltung all dessen.
Für die Hochverfügbarkeit haben wir zwei Dienstprogramme für das automatische Failover ausgewählt:
- MHA für MySQL
- Redis-Sentinel

Im Fall von MHA für MySQL haben wir Agenten in Knoten mit Datenbanken gegossen, und diese haben ihren Status überwacht. Es gab eine gewisse Zeitüberschreitung beim Ausfall des Masters. Danach wurde ein Stopp-Slave erstellt, um die Konsistenz aufrechtzuerhalten, und unser Backup-Master vom angezeigten Master in einem inkonsistenten Zustand hat die Daten nicht erfasst. Und wir haben diesen Agenten einen Web-Hook hinzugefügt, der dort die neue IP des Backup-Masters in Consul selbst registriert hat, wonach es zur Ausgabe von DNS kam.
Mit Redis-Sentinel ist alles noch einfacher. Da er selbst den Löwenanteil der Arbeit ausführt, mussten wir bei der Gesundheitsprüfung nur berücksichtigen, dass Redis-Sentinel ausschließlich auf dem Hauptknoten stattfinden sollte.
Anfangs funktionierte alles perfekt wie eine Uhr. Wir hatten keine Probleme am Prüfstand. Es hat sich jedoch gelohnt, sich in die natürliche Umgebung der Datenübertragung eines geladenen Rechenzentrums zu begeben, sich an einige OOM-Kills zu erinnern (dies ist nicht genügend Speicher, bei denen der Prozess vom Systemkern beendet wird) und den Dienst oder komplexere Dinge wiederherzustellen, die die Verfügbarkeit des Dienstes beeinträchtigen. Wie sind wir sofort zu einem ernsthaften Risiko von Fehlalarmen oder gar keiner garantierten Reaktion gekommen (wenn Sie versuchen, einige Überprüfungen zu verdrehen, um Fehlalarmen zu entkommen)?

Zunächst hängt alles von der Schwierigkeit ab, den richtigen Gesundheitscheck zu schreiben. Es scheint, dass die Aufgabe ziemlich trivial ist - überprüfen Sie, ob der Dienst auf Ihrem Server und Pingani-Port ausgeführt wird. Wie die nachfolgende Praxis gezeigt hat, ist das Schreiben eines Healthchecks bei der Implementierung von Consul ein äußerst komplexer und zeitaufwändiger Prozess. Da so viele Faktoren, die die Verfügbarkeit Ihres Dienstes im Rechenzentrum beeinflussen, nicht vorhersehbar sind, werden sie erst nach einer bestimmten Zeit erkannt.
Darüber hinaus ist das Rechenzentrum keine statische Struktur, mit der Sie überflutet sind, und es funktioniert wie beabsichtigt. Leider (oder zum Glück) haben wir dies erst später erfahren, aber im Moment waren wir inspiriert und voller Zuversicht, dass wir alles in der Produktion umsetzen würden.

Zur Skalierung möchte ich kurz sagen: Wir haben versucht, ein fertiges Fahrrad zu finden, aber alle sind für bestimmte Architekturen konzipiert. Und wie im Fall von Jetpants konnten wir die Bedingungen, die er der Architektur einer dauerhaften Speicherung von Informationen auferlegte, nicht erfüllen.
Deshalb haben wir über unsere eigene Skriptbindung nachgedacht und diese Frage verschoben. Wir haben uns entschlossen, konsequent zu handeln und mit der Implementierung von Consul zu beginnen.

Consul ist ein dezentraler, verteilter Cluster, der auf der Grundlage des Klatschprotokolls und des Raft-Konsensalgorithmus arbeitet.
Wir haben ein unabhängiges Äquorum von fünf Servern (fünf, um die Split-Brain-Situation zu vermeiden). Für jeden Knoten wird der Consul-Agent im Agentenmodus verschüttet und der gesamte Healthcheck verschüttet (d. H. Es wurde kein Healthcheck auf einen bestimmten Server und andere auf bestimmte Server hochgeladen). Healthcheck wurde so geschrieben, dass sie nur dort bestehen, wo es einen Service gibt.
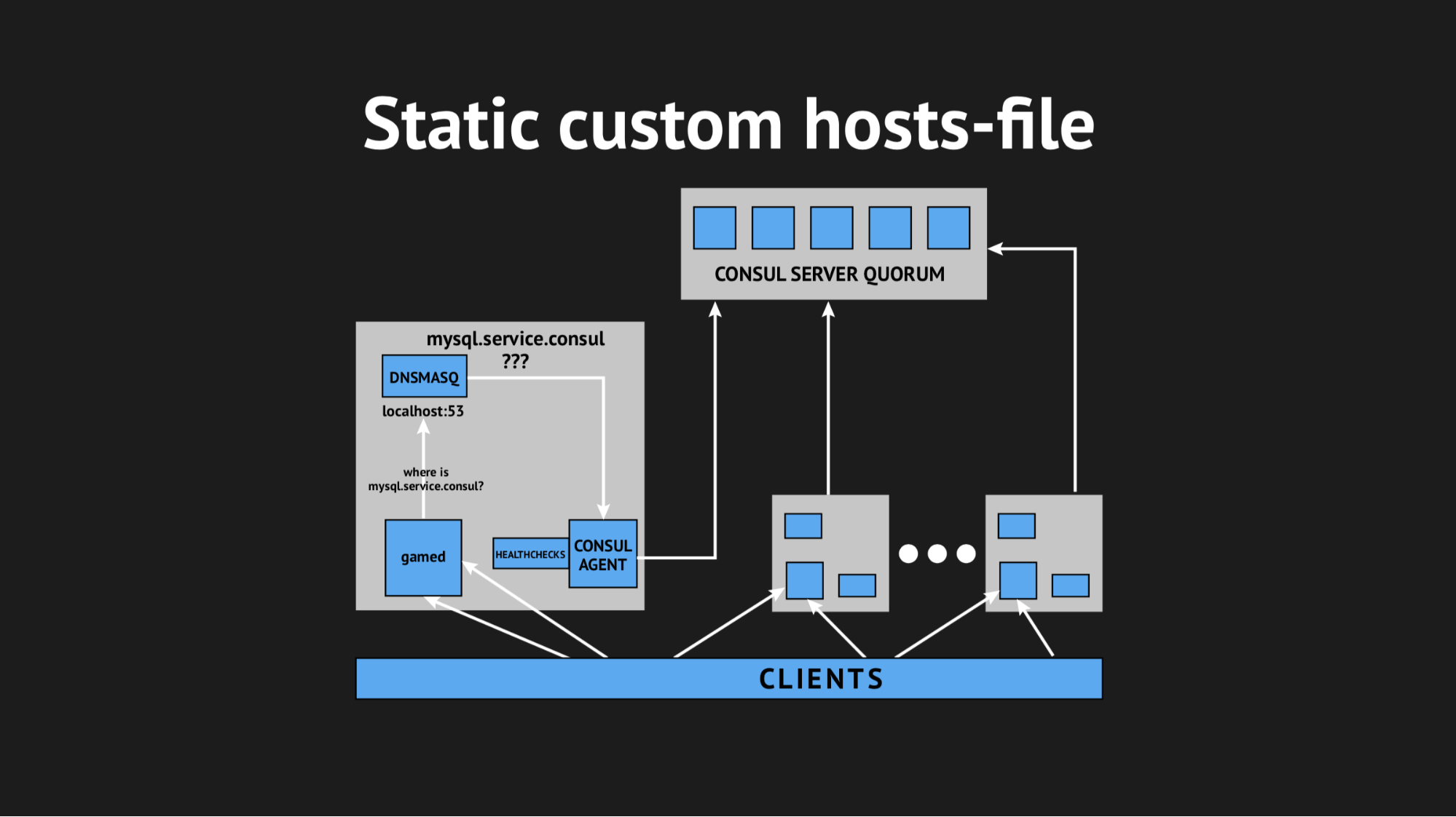
Wir haben auch ein anderes Dienstprogramm verwendet, damit wir unser Backend nicht lernen mussten, um Adressen aus einer bestimmten Domäne an einem nicht standardmäßigen Port aufzulösen. Wir haben Dnsmasq verwendet - es bietet die Möglichkeit, die Adressen auf den benötigten Clusterknoten (die in der realen Welt sozusagen nicht existieren, sondern ausschließlich innerhalb des Clusters existieren) vollständig transparent aufzulösen. Wir haben ein automatisches Skript zum Füllen von Ansible vorbereitet, alles in die Produktion hochgeladen, den Namespace optimiert und sichergestellt, dass alles vollständig ist. Und drückten die Daumen und luden unsere Backends neu, auf die nicht über IP-Adressen, sondern über diese Namen aus der Domäne server.consul zugegriffen wurde.
Alles begann beim ersten Mal, unsere Freude kannte keine Grenzen. Aber es war zu früh, um sich zu freuen, denn innerhalb einer Stunde stellten wir fest, dass auf allen Knoten, an denen sich unsere Backends befinden, der Lastdurchschnittsindikator von 0,7 auf 1,0 anstieg, was ein ziemlich fetter Indikator ist.
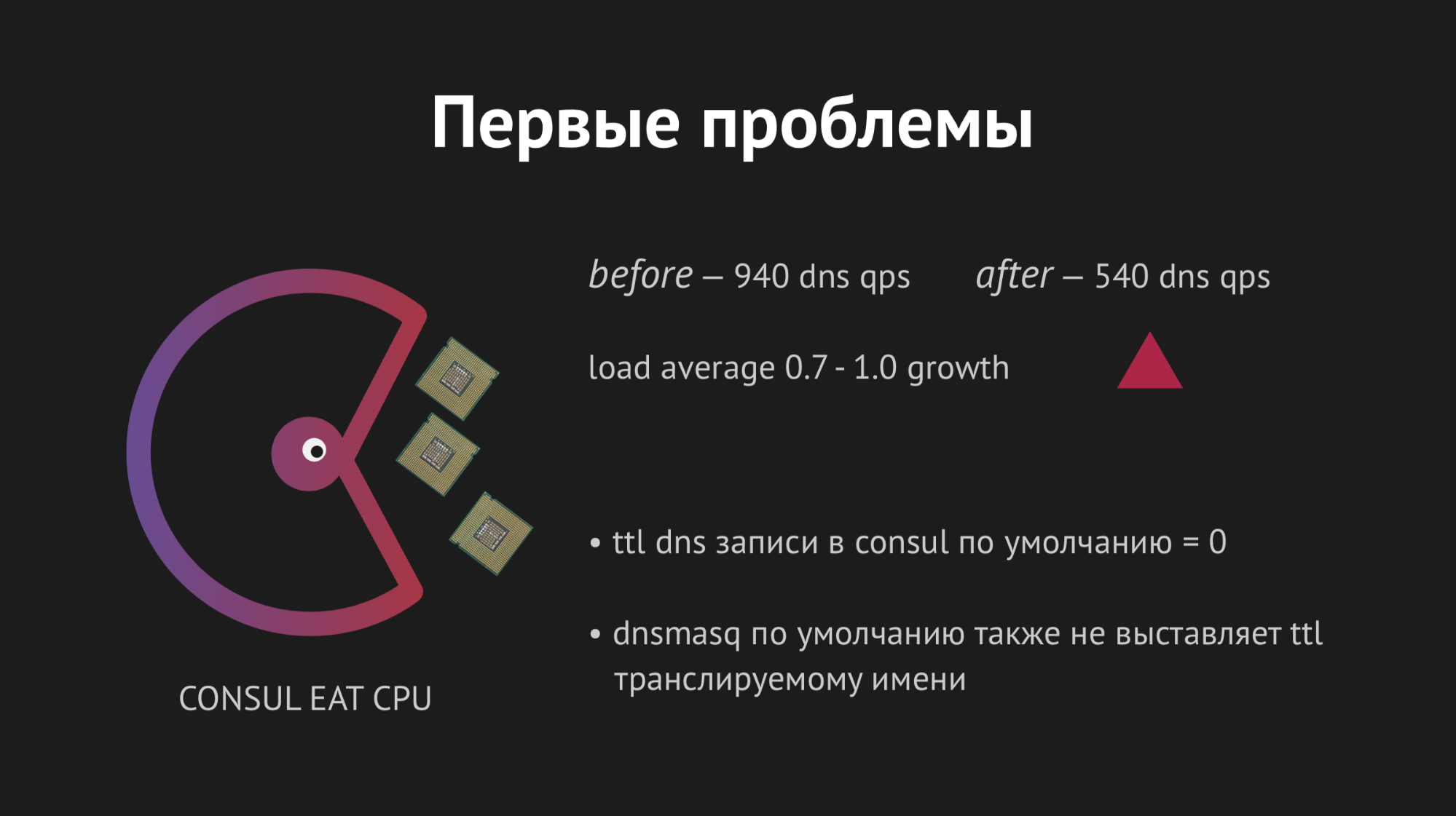
Ich stieg auf den Server, um zu sehen, was los war, und es wurde offensichtlich, dass die CPU Consul aß. Hier haben wir angefangen, es herauszufinden, haben mit strace angefangen (ein Dienstprogramm für Unix-Systeme, mit dem Sie verfolgen können, welcher Systemaufruf der Prozess ausgeführt wird), Dnsmasq-Statistiken ausgegeben, um zu verstehen, was auf diesem Knoten vor sich geht, und es hat sich herausgestellt, dass wir einen sehr wichtigen Punkt übersehen haben. Bei der Planung der Integration haben wir das Zwischenspeichern von DNS-Einträgen verpasst, und es stellte sich heraus, dass unser Backend Dnsmasq für jede seiner Bewegungen abgerufen hat und sich wiederum an Consul gewandt hat, was zu 940 DNS-Abfragen pro Sekunde führte.
Der Ausweg schien offensichtlich - drehen Sie einfach ttl und alles wird besser. Aber hier war es unmöglich, fanatisch zu sein, weil wir diese Struktur implementieren wollten, um einen dynamischen, einfach zu kontrollierenden und sich schnell ändernden Namespace zu erhalten (daher konnten wir beispielsweise keine 20 Minuten festlegen). Wir haben ttl auf die für uns maximal optimalen Werte gedreht und es geschafft, die Abfragerate pro Sekunde auf 540 zu reduzieren. Dies hatte jedoch keinen Einfluss auf die CPU-Verbrauchsanzeige.
Dann haben wir uns entschlossen, auf knifflige Weise mit einer benutzerdefinierten Hosts-Datei herauszukommen.
Es ist gut, dass wir alles dafür hatten: ein exzellentes Vorlagensystem von Consul, das basierend auf dem Status des Clusters und dem Vorlagenskript eine Datei jeglicher Art generiert, jede Konfiguration ist alles, was Sie wollen. Darüber hinaus verfügt Dnsmasq über einen Konfigurationsparameter für addn-hosts, mit dem Sie eine Nicht-System-Hosts-Datei als dieselbe zusätzliche Hosts-Datei verwenden können.
Was wir getan haben, hat das Skript in Ansible erneut vorbereitet, es in die Produktion hochgeladen und es sah ungefähr so aus:
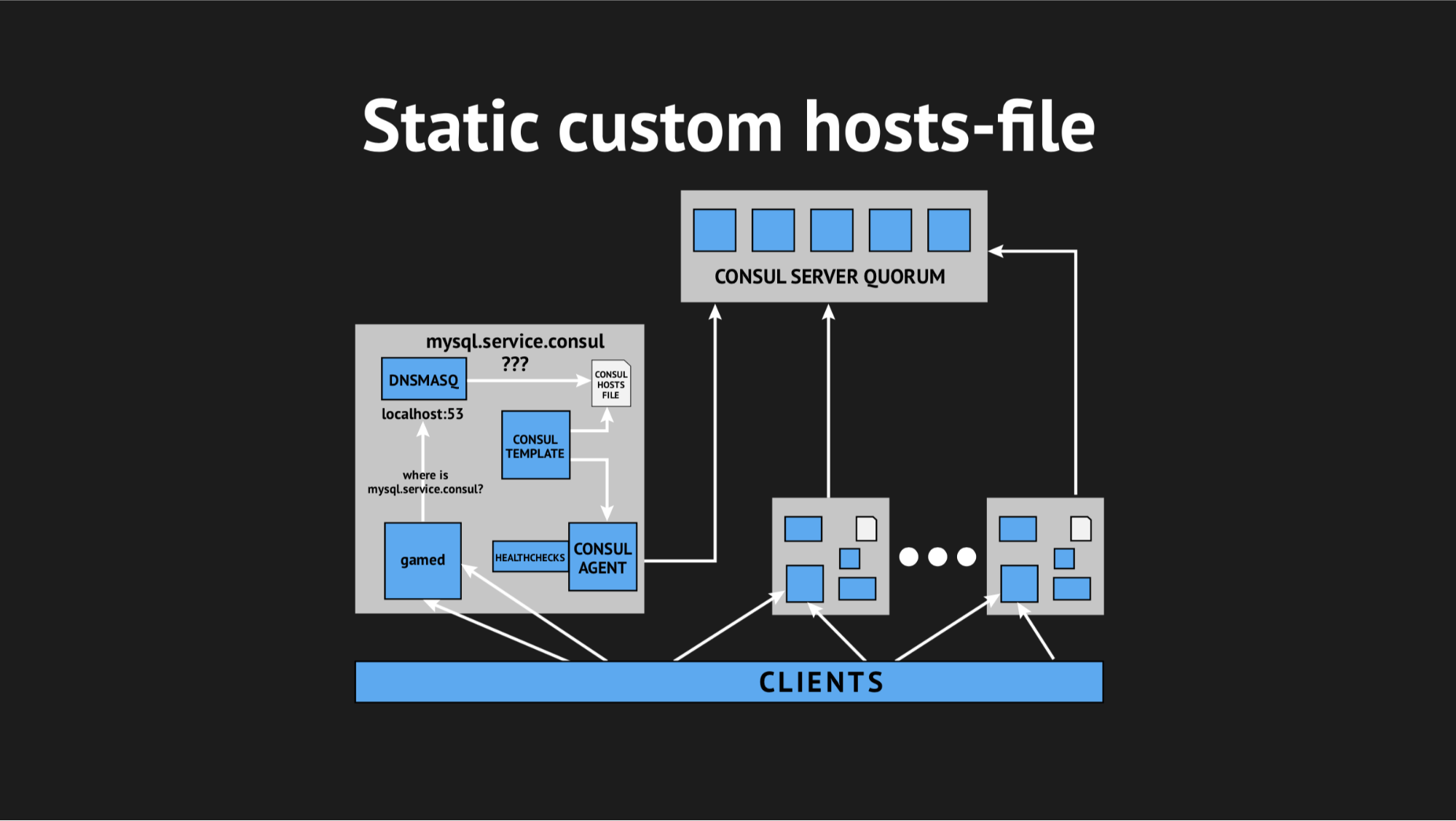
Es gab ein zusätzliches Element und eine statische Datei auf der Festplatte, die ziemlich schnell neu generiert wird. Jetzt sah die Kette ganz einfach aus: Das Spiel wandte sich an Dnsmasq, und das wiederum (anstatt den Consula-Agenten zu ziehen, der die Server fragen würde, wo wir diesen oder jenen Knoten hatten) sah sich nur die Datei an. Dies löste das Problem mit dem CPU-Verbrauch durch Consul.
Jetzt sah alles so aus, wie wir es geplant hatten - absolut transparent für unsere Produktion, praktisch ohne Ressourcen zu verbrauchen.
Wir waren an diesem Tag ziemlich gequält und gingen mit großer Besorgnis nach Hause. Sie hatten keine vergebliche Angst, denn nachts weckte mich ein Alarm der Überwachung und informierte mich, dass wir einen ziemlich großen (wenn auch kurzfristigen) Fehlerausbruch hatten.
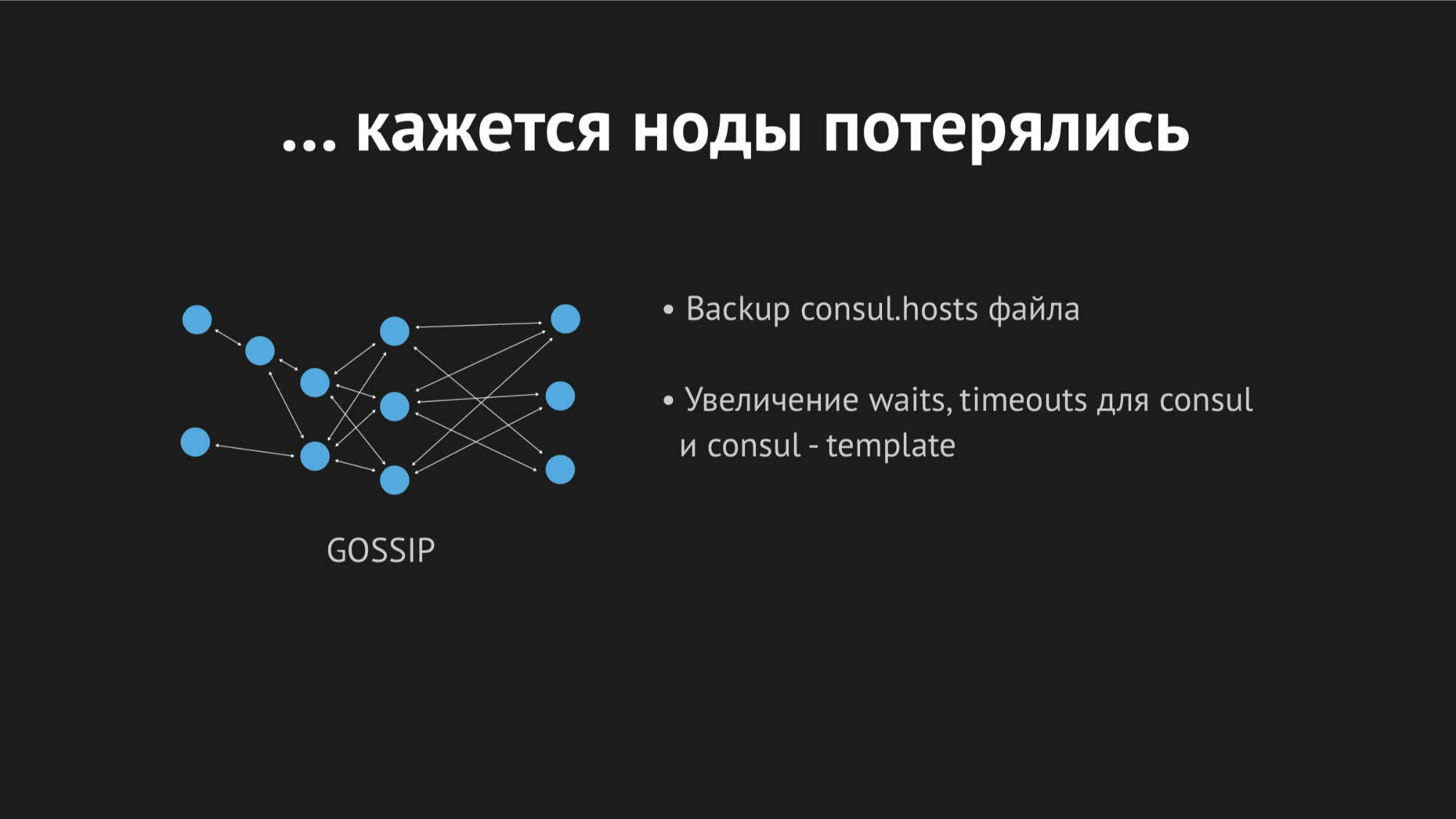
Als ich mich morgens mit den Protokollen befasste, sah ich, dass alle Fehler vom gleichen Typ eines unbekannten Hosts waren. Es war nicht klar, warum Dnsmasq den einen oder anderen Dienst aus einer Datei nicht verwenden konnte - es schien, als gäbe es ihn überhaupt nicht. Um zu verstehen, was los war, habe ich eine benutzerdefinierte Metrik hinzugefügt, um die Datei neu zu generieren. Jetzt wusste ich genau, wann sie neu generiert werden würde. Darüber hinaus verfügt die Consul-Vorlage selbst über eine hervorragende Sicherungsoption, d. H. Sie können den vorherigen Status der neu generierten Datei anzeigen.
Tagsüber wiederholte sich der Vorfall mehrmals und es wurde klar, dass zu einem bestimmten Zeitpunkt (obwohl er sporadisch und unsystematisch war) die Hosts-Datei ohne bestimmte Dienste erneut erbracht wurde. Es stellte sich heraus, dass es in einem bestimmten Rechenzentrum (ich werde keine Anti-Werbung machen) ziemlich instabile Netzwerke gibt - aufgrund von Netzwerkausfällen haben wir absolut unvorhersehbar aufgehört, Healthchecks zu bestehen, oder sogar die Knoten sind aus dem Cluster herausgefallen. Es sah ungefähr so aus:
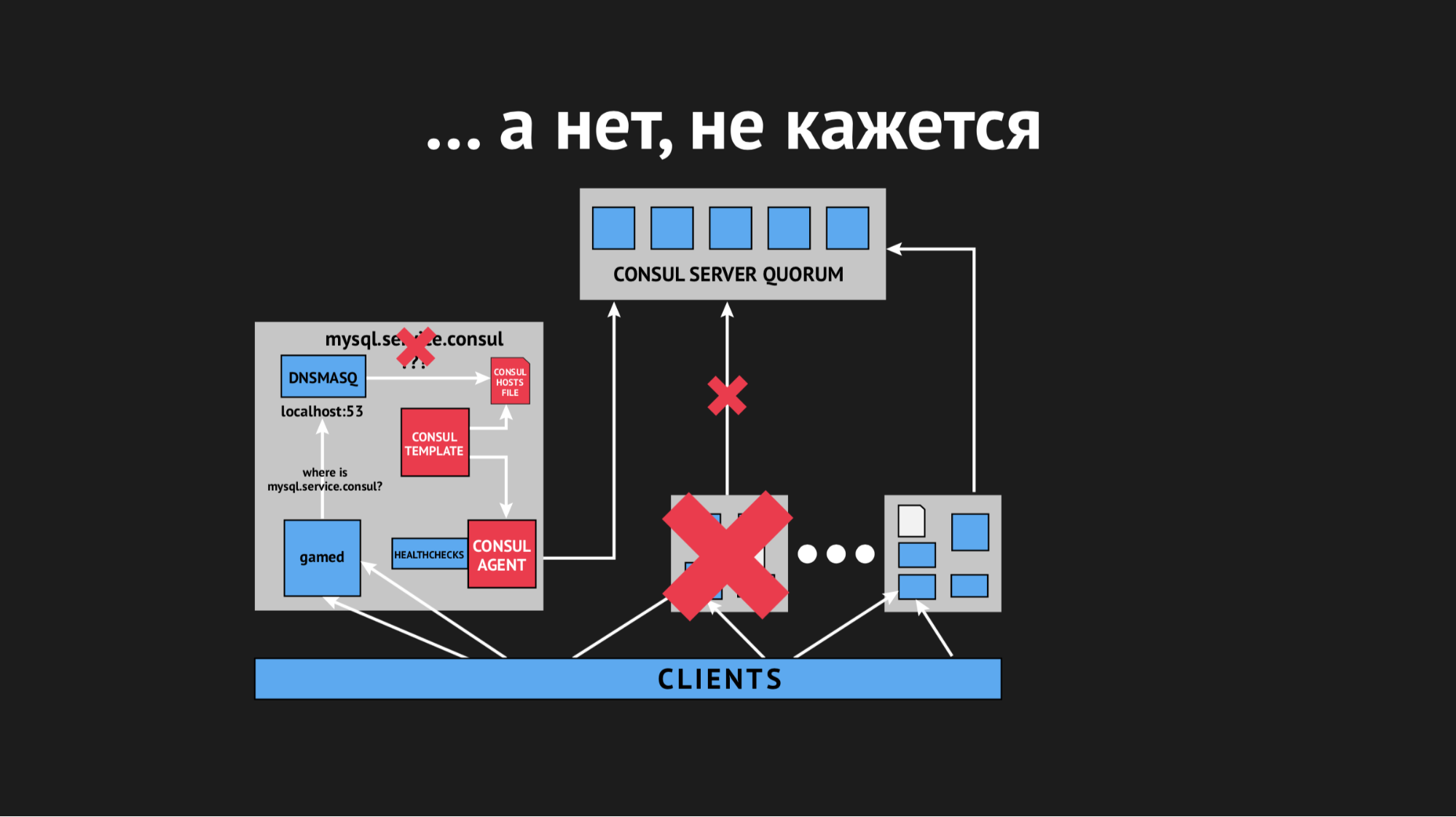
Der Knoten fiel aus dem Cluster heraus, der Consul-Agent wurde sofort darüber informiert, und die Consul-Vorlage hat die Hosts-Datei sofort ohne den von uns benötigten Dienst neu generiert. Dies war im Allgemeinen nicht akzeptabel, da das Problem lächerlich ist: Wenn der Dienst einige Sekunden lang nicht verfügbar ist, richten Sie Zeitüberschreitungen und Retrays ein (sie haben keine Verbindung hergestellt, aber das zweite Mal stellte sich heraus). Wir haben jedoch eine neue Struktur im Verkäufer provoziert, als der Dienst einfach aus dem Blickfeld verschwand und es keine Möglichkeit gab, eine Verbindung zu ihm herzustellen.
Wir begannen darüber nachzudenken, was zu tun ist, und drehten den Timeout-Parameter in Consul. Danach wird er identifiziert, nachdem der Knoten herausgefallen ist. Wir haben es geschafft, dieses Problem mit einem relativ kleinen Indikator zu lösen. Die Knoten fielen nicht mehr aus, aber dies half nicht bei der Überprüfung des Gesundheitszustands.
Wir begannen darüber nachzudenken, verschiedene Parameter für den Gesundheitscheck auszuwählen und irgendwie zu verstehen, wann und wie dies geschieht. Aber aufgrund der Tatsache, dass alles sporadisch und unvorhersehbar passierte, konnten wir es nicht tun.
Dann gingen wir zur Consul-Vorlage und beschlossen, eine Zeitüberschreitung dafür vorzunehmen. Danach reagiert sie auf eine Änderung des Status des Clusters. Auch hier war es unmöglich, fanatisch zu sein, weil wir zu einer Situation kommen konnten, in der das Ergebnis nicht besser wäre als das klassische DNS, wenn wir auf ein völlig anderes abzielten.
Und wieder kam unser technischer Direktor zur Rettung und sagte: „Leute, lasst uns versuchen, all diese Interaktivität aufzugeben, wir sind alle in Produktion und es gibt keine Zeit für Forschung, wir müssen dieses Problem lösen. Nutzen wir einfache und verständliche Dinge. “ So kamen wir zu dem Konzept, Schlüsselwertspeicher als Quelle für die Generierung einer Hosts-Datei zu verwenden.
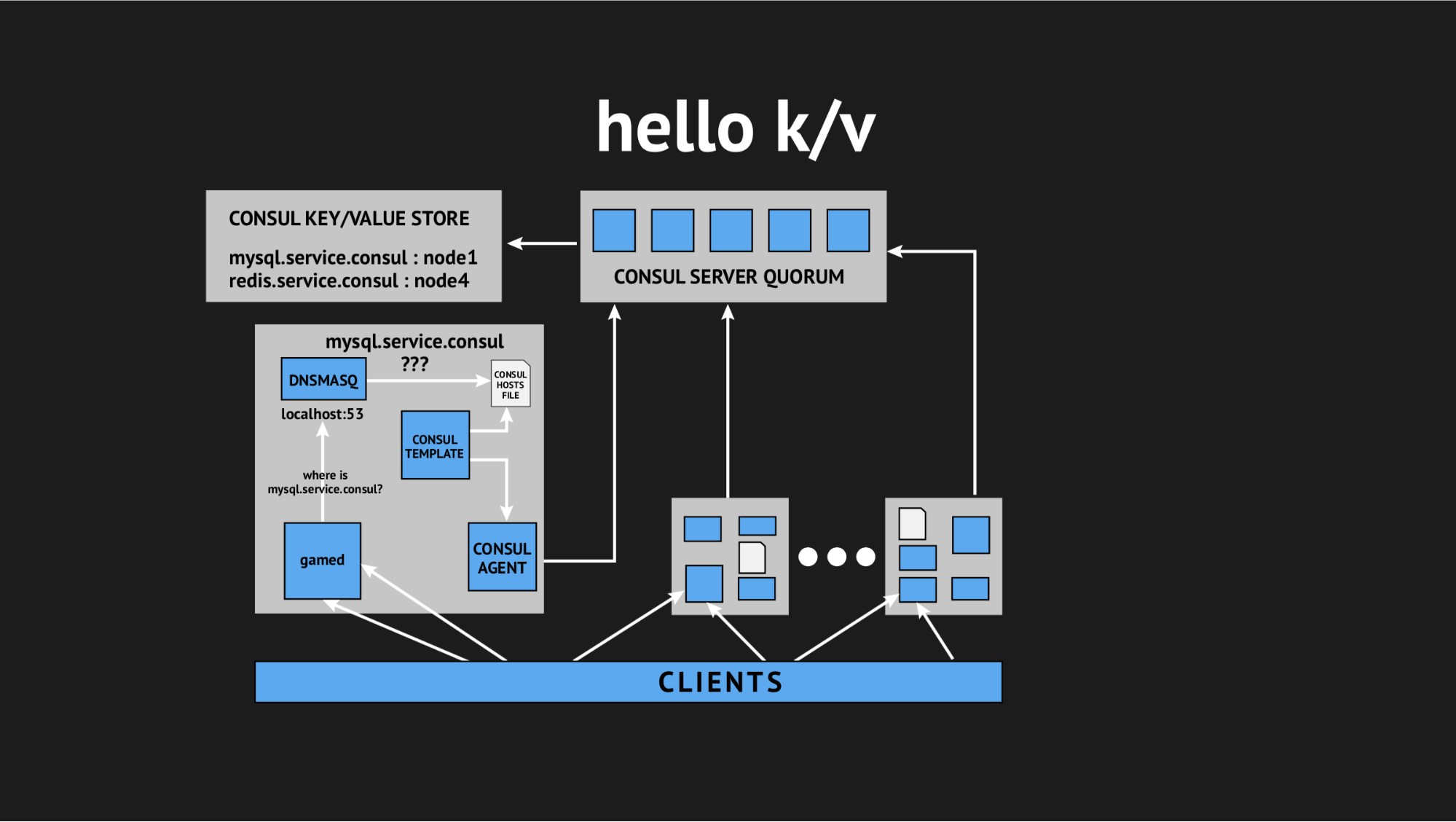
Wie es aussieht: Wir lehnen alle dynamischen Integritätsprüfungen ab und schreiben unser Vorlagenskript so um, dass es eine Datei basierend auf den im Schlüsselwertspeicher aufgezeichneten Daten generiert. Im Schlüsselwertspeicher beschreiben wir unsere gesamte Infrastruktur in Form des Schlüsselnamens (dies ist der Name des benötigten Dienstes) und des Schlüsselwerts (dies ist der Name des Knotens im Cluster). Das heißt, Wenn der Knoten im Cluster vorhanden ist, können wir seine IP-Adresse sehr einfach abrufen und in die Hosts-Datei schreiben.
Wir haben alles getestet, es in der Produktion gefüllt und es wurde in einer bestimmten Situation zu einer Silberkugel. Wieder quälten wir uns den ganzen Tag ziemlich, gingen nach Hause, kehrten aber bereits ausgeruht und ermutigt zurück, weil diese Probleme nicht wieder auftraten und im vergangenen Jahr nicht wieder auftraten. Daraus schließe ich persönlich, dass dies die richtige Entscheidung war (speziell für uns).
Also. Wir haben endlich das bekommen, was wir wollten und einen dynamischen Namespace für unsere Backends organisiert. Weiter haben wir uns um eine hohe Verfügbarkeit bemüht.

Tatsache ist jedoch, dass wir ziemlich Angst vor der Integration von Consul haben und aufgrund der Probleme, auf die wir gestoßen sind, dachten und entschieden, dass die Einführung von Auto-Failover keine so gute Lösung ist, weil wir wiederum falsch positive Ergebnisse riskieren oder Ausfälle. Dieser Prozess ist undurchsichtig und unkontrollierbar.
Aus diesem Grund haben wir einen einfacheren (oder komplexeren) Weg eingeschlagen: Wir haben beschlossen, das Failover dem Gewissen des diensthabenden Administrators zu überlassen, ihm jedoch ein weiteres zusätzliches Tool zur Verfügung gestellt. Wir haben die Master-Slave-Replikation durch die Master-Master-Replikation im schreibgeschützten Modus ersetzt. Dies beseitigt eine Menge Kopfschmerzen beim Failover'ov. Wenn Sie einen Assistenten erhalten, müssen Sie lediglich den Wert im k / v-Speicher über die Web-Benutzeroberfläche oder den Befehl in der API ändern und zuvor den schreibgeschützten Modus entfernen Backup-Master.
Nachdem der Vorfall beendet ist, kontaktiert der Master und kommt automatisch zu einem koordinierten Zustand ohne unnötige Aktionen. Wir haben bei dieser Option angehalten und sie wie zuvor verwendet - für uns ist sie so bequem wie möglich und vor allem so einfach, klar und kontrolliert wie möglich.
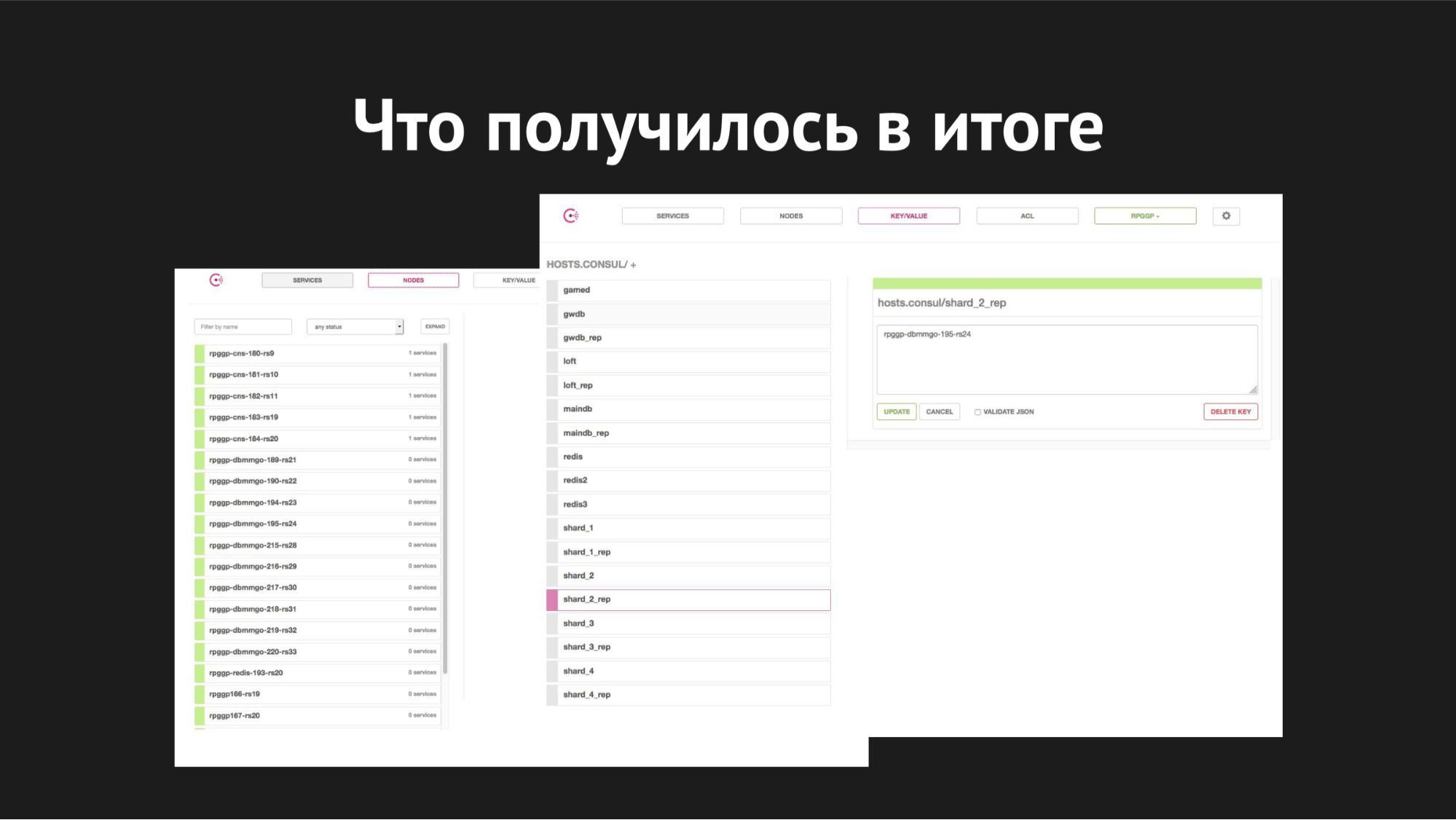 Consul Webinterface
Consul WebinterfaceRechts ist der k / v-Speicher und unsere Dienste sind sichtbar, die wir im Spiel verwenden; Wert ist der Name des Knotens.
Die Skalierung wurde implementiert, als die Shards bereits auf einem Server überfüllt waren, die Basen wuchsen, langsam wurden, die Anzahl der Spieler zunahm, wir tauschten und die Aufgabe hatten, alle Shards auf unsere verschiedenen separaten Server zu verteilen.

So sah es aus: Mit dem Dienstprogramm XtraBackup haben wir unser Backup auf einem neuen Serverpaar wiederhergestellt. Danach wurde der neue Master mit einem Slave auf dem alten Server aufgehängt. Es wurde ein konsistenter Zustand erreicht. Wir haben den Schlüsselwert in k / v-storage vom Namen des Knotens des alten Masters in den Namen des Knotens des neuen Masters geändert. Dann (als wir glaubten, dass alles korrekt lief und alle Spiele mit ihren Auswahlen, Aktualisierungen und Einfügungen an den neuen Master gingen) mussten wir nur die Replikation beenden und die begehrte Drop-Datenbank für die Produktion erstellen, da wir alle gerne mit unnötigen Datenbanken arbeiten.

Also haben wir die Scherben zerbrochen. Der gesamte Bewegungsprozess dauerte von 40 Minuten bis zu einer Stunde und verursachte keine Ausfallzeiten. Er war für unsere Backends völlig transparent und für die Spieler für sich genommen völlig transparent (mit der Ausnahme, dass das Spielen für sie einfacher und angenehmer wurde, sobald sie sich bewegten).

Bei den Failover-Prozessen beträgt hier die Umschaltzeit 20 bis 40 Sekunden zuzüglich der Reaktionszeit des diensthabenden Systemadministrators. So sieht es jetzt bei uns aus.
Was ich abschließend sagen möchte - leider sind unsere Hoffnungen auf eine absolute, umfassende Automatisierung in die harte Realität des Datenübertragungsmediums in einem geladenen Rechenzentrum und in zufällige Faktoren geraten, die wir nicht vorhersehen konnten.
Zweitens hat es uns wieder einmal gelehrt, dass eine einfache und bewährte Meise in den Händen Ihres Systemadministrators besser ist als ein neu reagierender, selbstreagierender, selbstskalierter Kran irgendwo hinter den Wolken, den Sie nicht einmal verstehen, ob er auseinander fällt oder wirklich begann zu skalieren.
Die Einführung einer Infrastruktur und Automatisierung in Ihrer Produktion sollte den Mitarbeitern, die sie bedienen, keine unnötigen Kopfschmerzen bereiten. Die Kosten für die Aufrechterhaltung der Infrastrukturproduktion sollten nicht wesentlich erhöht werden. Die Lösung sollte einfach, klar, für Ihre Kunden transparent, bequem und kontrolliert sein.
Fragen aus dem Publikum
Wie schreibt man k / v mit Servern - einem Skript oder patcht man es einfach?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . Das heißt, , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks