Hallo Habr, in diesem Artikel werde ich über die Ignite- Bibliothek sprechen, mit der Sie neuronale Netze mithilfe des PyTorch-Frameworks einfach trainieren und testen können.
Mit ignite können Sie Zyklen schreiben, um das Netzwerk in nur wenigen Zeilen zu trainieren, Standardmetrikberechnungen aus der Box hinzuzufügen, das Modell zu speichern usw. Nun, für diejenigen, die von TF zu PyTorch gewechselt sind, können wir sagen, dass die Ignite-Bibliothek Keras für PyTorch ist.
Der Artikel wird im Detail ein Beispiel für das Training eines neuronalen Netzwerks für eine Klassifizierungsaufgabe unter Verwendung von Ignite untersuchen.

Füge PyTorch mehr Feuer hinzu
Ich werde keine Zeit damit verschwenden, darüber zu sprechen, wie cool das PyTorch-Framework ist. Jeder, der es bereits benutzt hat, versteht, worüber ich schreibe. Trotz all seiner Vorteile ist es in Bezug auf Schreibzyklen zum Trainieren, Testen und Testen neuronaler Netze immer noch auf einem niedrigen Niveau.
Wenn wir uns offizielle Beispiele für die Verwendung des PyTorch-Frameworks ansehen, sehen wir mindestens zwei Iterationszyklen nach Epoche und nach Stapeln des im Grid-Trainingscode festgelegten Trainings:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
Die Hauptidee der Ignite- Bibliothek besteht darin, diese Schleifen in eine einzige Klasse zu zerlegen, während der Benutzer mithilfe von Ereignishandlern mit diesen Schleifen interagieren kann.
Infolgedessen können wir bei Standard-Deep-Learning-Aufgaben viel an der Anzahl der Codezeilen sparen. Weniger Zeilen - weniger Fehler!
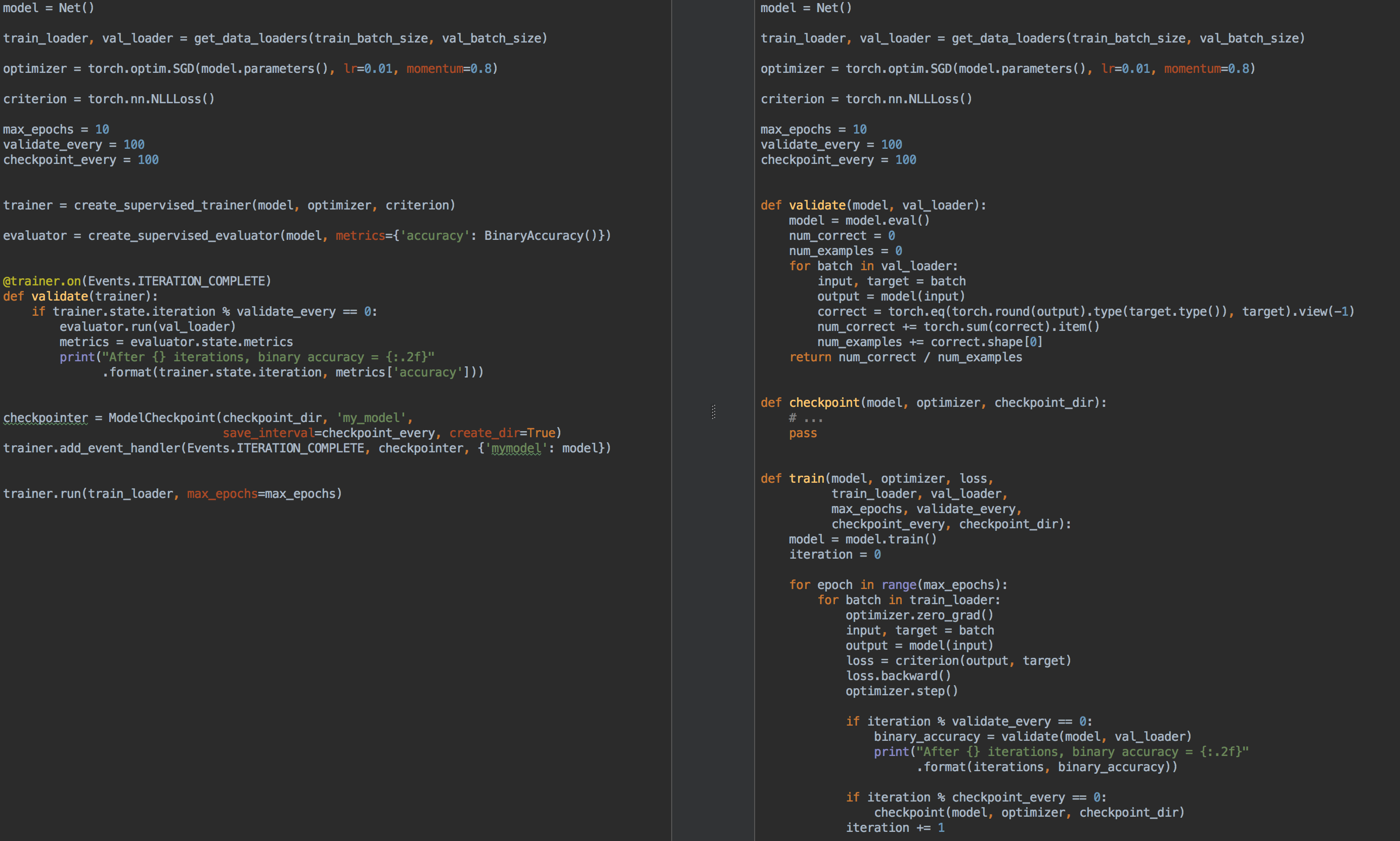
Zum Vergleich: Auf der linken Seite befindet sich links der Code für das Training und die Modellvalidierung mit ignite und auf der rechten Seite reines PyTorch:
Also nochmal, wofür ist Zünden gut?
- Sie müssen nicht mehr für jede
for epoch in range(n_epochs) und for batch in data_loader . - ermöglicht es Ihnen, Code besser zu faktorisieren
- ermöglicht es Ihnen, grundlegende Metriken sofort zu berechnen
- bietet "Brötchen" vom Typ
- Speichern der neuesten und besten Modelle (auch Optimierer und Planer der Lernrate) während des Trainings,
- früh aufhören zu lernen
- usw
- lässt sich leicht in Visualisierungstools integrieren: tensorboardX, visdom, ...
In gewisser Weise kann die Ignite- Bibliothek, wie bereits erwähnt, mit allen bekannten Keras und ihrer API zum Trainieren und Testen von Netzwerken verglichen werden. Außerdem ist die Ignite- Bibliothek auf den ersten Blick der tnt- Bibliothek sehr ähnlich, da beide Bibliotheken anfangs gemeinsame Ziele hatten und ähnliche Ideen für ihre Implementierung hatten.
Also, leuchten:
pip install pytorch-ignite
oder
conda install ignite -c pytorch
Als nächstes werden wir uns anhand eines konkreten Beispiels mit der API für die Ignite- Bibliothek vertraut machen.
Klassifizierungsaufgabe mit Zündung
In diesem Teil des Artikels werden wir ein Schulbeispiel zum Trainieren eines neuronalen Netzwerks für das Klassifizierungsproblem unter Verwendung der Zündbibliothek betrachten .
Nehmen wir also einen einfachen Datensatz mit Bildern von Früchten mit Kaggle . Die Aufgabe besteht darin, jedem Fruchtbild eine entsprechende Klasse zuzuordnen.
Bevor Sie ignite verwenden , definieren wir die Hauptkomponenten:
Datenstrom
- Trainingsbeispiel Batcher Loader,
train_loader - Checkout Batch Downloader,
val_loader
Modell:
- Nimm das kleine SqueezeNet-Gitter von
torchvision
Optimierungsalgorithmus:
Verlustfunktion:
Code from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
Jetzt ist es Zeit zu zünden :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
Mal sehen, was dieser Code bedeutet.
Motor Engine
Die Klasse ignite.engine.Engine ist das Bibliotheksframework, und das Objekt dieser Klasse ist trainer :
trainer = Engine(process_function)
Sie wird mit der Eingabefunktion process_function für die Verarbeitung einer Charge definiert und dient zur Implementierung von Durchläufen für das Trainingsmuster. In der Klasse ignite.engine.Engine geschieht Folgendes:
while epoch < max_epochs:
Zurück zur Funktion process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
Wir sehen, dass wir innerhalb der Funktion, wie im Fall des Modelltrainings üblich, die y_pred Vorhersagen berechnen, die Verlustfunktion, den loss und die Gradienten berechnen. Mit letzterem können Sie das Modellgewicht aktualisieren: optimizer.step() .
Im Allgemeinen gibt es keine Einschränkungen für den Code der Funktion process_function . Wir stellen nur fest, dass zwei Argumente als Eingabe verwendet werden: das Engine Objekt (in unserem Fall trainer ) und der Stapel vom Datenlader. Um beispielsweise ein neuronales Netzwerk zu testen, können wir ein anderes Objekt der Klasse ignite.engine.Engine definieren, in dem die Eingabefunktion einfach die Vorhersagen berechnet und einen Durchlauf durch das Testmuster einmal implementiert. Lesen Sie später darüber.
Der obige Code definiert also nur die erforderlichen Objekte, ohne mit dem Training zu beginnen. Grundsätzlich können Sie in einem minimalen Beispiel die Methode aufrufen:
trainer.run(train_loader, max_epochs=10)
und dieser Code reicht aus, um das Modell "leise" (ohne Ableitung von Zwischenergebnissen) zu trainieren.
Eine NotizBeachten Sie auch, dass die Bibliothek für Aufgaben dieses Typs eine bequeme Methode zum Erstellen des trainer bietet:
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
In der Praxis ist das obige Beispiel natürlich von geringem Interesse. Fügen wir daher die folgenden Optionen für den „Trainer“ hinzu:
- Anzeige des Verlustfunktionswertes alle 50 Iterationen
- Beginn der Berechnung der Metriken auf dem Trainingssatz mit einem festen Modell
- Beginn der Berechnung der Metriken an der Testprobe nach jeder Ära
- Speichern von Modellparametern nach jeder Ära
- Erhaltung der drei besten Modelle
- Änderung der Lerngeschwindigkeit je nach Epoche (Planung der Lernrate)
- Frühstopp-Training (Frühstopp-Training)
Ereignisse und Ereignishandler
Um die oben genannten Optionen für den „Trainer“ hinzuzufügen, bietet die Ignite- Bibliothek ein Ereignissystem und den Start von benutzerdefinierten Ereignishandlern. Somit kann der Benutzer in jeder Phase ein Objekt der Engine Klasse steuern:
- Motor gestartet / Start abgeschlossen
- Ära begann / endete
- Batch-Iteration gestartet / beendet
und führen Sie Ihren Code bei jedem Ereignis aus.
Zeigt Verlustfunktionswerte an
Dazu müssen Sie nur die Funktion bestimmen, in der die Ausgabe auf dem Bildschirm angezeigt wird, und sie dem "Trainer" hinzufügen:
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
Es gibt zwei Möglichkeiten, einen Ereignishandler hinzuzufügen: über add_event_handler oder über den on decorator. Das gleiche wie oben kann folgendermaßen gemacht werden:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
Beachten Sie, dass alle Argumente an die Ereignisbehandlungsfunktion übergeben werden können. Im Allgemeinen sieht eine solche Funktion folgendermaßen aus:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
Beginnen wir also mit dem Training in einer Ära und sehen, was passiert:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
Nicht schlecht! Gehen wir weiter.
Starten der Berechnung von Metriken für Trainings- und Testmuster
Berechnen wir die folgenden Metriken: durchschnittliche Genauigkeit, durchschnittliche Vollständigkeit nach jeder Ära seitens des Trainings und der gesamten Testprobe. Beachten Sie, dass wir die Metriken seitens der Trainingsstichprobe nach jeder Trainingsära und nicht während des Trainings berechnen. Somit ist die Messung der Effizienz genauer, da sich das Modell während der Berechnung nicht ändert.
Also definieren wir die Metriken:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
Als Nächstes erstellen wir zwei Engines, um das Modell mit ignite.engine.create_supervised_evaluator zu bewerten:
from ignite.engine import create_supervised_evaluator
Wir erstellen zwei Engines, um einem von ihnen zusätzliche Ereignishandler val_evaluator ( val_evaluator ), um das Modell zu speichern und das Lernen frühzeitig zu beenden (dazu weiter unten).
Schauen wir uns auch genauer an, wie die Engine zur Bewertung des Modells definiert ist, nämlich wie die Eingabefunktion process_function definiert ist, um eine Charge zu verarbeiten:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
Wir gehen weiter. Lassen Sie uns zufällig den Teil der Trainingsstichprobe auswählen, für den wir die Metriken berechnen:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
Als nächstes legen wir fest, an welchem Punkt des Trainings wir mit der Berechnung der Metriken beginnen und auf dem Bildschirm ausgeben:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
Du kannst rennen!
output = trainer.run(train_loader, max_epochs=1)
Wir kommen auf den Bildschirm
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
Schon besser !
Einige Details
Schauen wir uns den vorherigen Code etwas an. Der Leser hat möglicherweise die folgende Codezeile bemerkt:
metrics = train_evaluator.run(train_eval_loader).metrics
und wahrscheinlich gab es eine Frage zum Objekttyp, der von train_evaluator.run(train_eval_loader) , der das train_evaluator.run(train_eval_loader) hat.
Tatsächlich enthält die Engine Klasse eine Struktur namens state (Typ State ), um Daten zwischen Ereignishandlern übertragen zu können. Dieses Statusattribut enthält grundlegende Informationen zur aktuellen Ära, Iteration, Anzahl der Epochen usw. Es kann auch zum Übertragen von Benutzerdaten verwendet werden, einschließlich der Ergebnisse der Berechnung von Metriken.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
Berechnung von Metriken während des Trainings
Wenn die Aufgabe über ein großes Trainingsbeispiel verfügt und die Berechnung von Metriken nach jeder Trainingsepoche teuer ist, Sie jedoch weiterhin möchten, dass sich einige Metriken während des Trainings ändern, können Sie den folgenden RunningAverage Ereignishandler aus der Box verwenden. Zum Beispiel möchten wir die Genauigkeit des Klassifikators berechnen und anzeigen:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
Um die RunningAverage Funktionalität nutzen zu können, müssen Sie RunningAverage aus folgenden Quellen installieren:
pip install git+https:
Planung der Lernrate
Es gibt verschiedene Möglichkeiten, die Lerngeschwindigkeit mithilfe von Ignite zu ändern. Betrachten Sie als Nächstes die einfachste Methode, indem lr_scheduler.step() zu Beginn jeder Ära die Funktion lr_scheduler.step() aufrufen.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
Speichern der besten Modelle und anderer Parameter während des Trainings
Während des Trainings wäre es großartig, die Gewichte des besten Modells auf der Disc aufzuzeichnen und die Modellgewichte, Optimierungsparameter und Parameter zum Ändern der Lerngeschwindigkeit regelmäßig zu speichern. Letzteres kann nützlich sein, um das Lernen aus dem zuletzt gespeicherten Zustand fortzusetzen.
Ignite hat hierfür eine spezielle ModelCheckpoint Klasse. Erstellen ModelCheckpoint einen ModelCheckpoint Ereignishandler und speichern das beste Modell hinsichtlich der Genauigkeit im ModelCheckpoint . In diesem Fall definieren wir eine score_function Funktion, die dem Ereignishandler den Genauigkeitswert gibt und entscheidet, ob das Modell score_function oder nicht:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
Erstellen ModelCheckpoint nun einen weiteren ModelCheckpoint Ereignishandler, um den Lernstatus alle 1000 Iterationen beizubehalten:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
Also, fast alles ist fertig, fügen Sie das letzte Element hinzu:
Frühstopp-Training (Frühstopp)
Fügen wir einen weiteren Event-Handler hinzu, der das Lernen beendet, wenn sich die Modellqualität über 10 Epochen nicht verbessert. Wir werden die Qualität des Modells erneut mit der score_function score_function bewerten.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
Beginnen Sie mit dem Training
Um mit dem Training zu beginnen, reicht es aus, die run() -Methode aufzurufen. Wir werden das Modell für 10 Epochen trainieren:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
Bildschirmausgabe Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
Überprüfen Sie nun die auf der Festplatte gespeicherten Modelle und Parameter:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
und
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
Vorhersagen eines trainierten Modells
Erstellen Sie zunächst einen Testdatenlader (z. B. ein Validierungsbeispiel), sodass der Datenstapel aus Bildern und ihren Indizes besteht:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
Mit ignite erstellen wir eine neue Vorhersage-Engine für Testdaten. Dazu definieren wir die Funktion inference_update , die das Ergebnis der Vorhersage und den Index des Bildes zurückgibt. Um die Genauigkeit zu erhöhen, verwenden wir auch den bekannten Trick „Test Time Augmentation“ (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
Erstellen Sie als Nächstes Ereignishandler, die über den Stand der Vorhersagen informieren und die Vorhersagen in einem dedizierten Array speichern:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
Laden Sie vor dem Start das beste Modell herunter:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
Wir starten:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
Als nächstes nehmen wir standardmäßig den Durchschnitt der TTA-Vorhersagen und berechnen den Klassenindex mit der höchsten Wahrscheinlichkeit:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
Und jetzt können wir die Genauigkeit des Modells noch einmal anhand der Vorhersagen berechnen:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
Fazit
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
Vielen Dank für Ihre Aufmerksamkeit!