Eins ist Null zugunsten des menschlichen Gehirns. In einer
neuen Studie stellten Informatiker fest, dass Systeme der künstlichen Intelligenz den Test zur visuellen Erkennung von Objekten, mit denen jedes Kind problemlos umgehen kann, nicht bestehen.
"Diese qualitative und wichtige Studie erinnert uns daran, dass" Deep Learning "selbst nicht die Tiefe aufweisen kann, die ihm zugeschrieben wird", sagt Gary Marcus, ein Neurowissenschaftler an der New York University, der nicht mit dieser Arbeit verbunden ist.
Die Ergebnisse der Studie beziehen sich auf das Gebiet der Bildverarbeitung, wenn Systeme der künstlichen Intelligenz versuchen, Objekte zu erkennen und zu kategorisieren. Zum Beispiel können sie gebeten werden, alle Fußgänger in der Straßenszene zu finden oder einfach einen Vogel von einem Fahrrad zu unterscheiden - eine Aufgabe, die bereits für ihre Komplexität berühmt geworden ist.
Es steht viel auf dem Spiel: Computer beginnen allmählich, wichtige Operationen für Menschen auszuführen, wie z. B. automatische Videoüberwachung und autonomes Fahren. Und für eine erfolgreiche Arbeit ist es notwendig, dass die Fähigkeit der KI zur visuellen Verarbeitung dem Menschen zumindest nicht unterlegen ist.
Die Aufgabe ist nicht einfach.
Die neue Studie konzentriert sich auf die Verfeinerung des menschlichen Sehens und die Schwierigkeiten bei der Schaffung nachahmender Systeme. Wissenschaftler testeten die Genauigkeit eines Computer-Vision-Systems am Beispiel eines Wohnzimmers. AI hat es gut gemacht und den Stuhl, die Person und die Bücher im Regal korrekt identifiziert. Als Wissenschaftler der Szene jedoch ein ungewöhnliches Objekt hinzufügten - das Bild eines Elefanten - ließ das System aufgrund seiner Erscheinung alle vorherigen Ergebnisse vergessen. Plötzlich begann sie, den Stuhl als Sofa, den Elefanten als Stuhl zu bezeichnen und alle anderen Gegenstände zu ignorieren.
"Es gab alle möglichen Kuriositäten, die die Fragilität moderner Objekterkennungssysteme zeigten", sagt Amir Rosenfeld, Wissenschaftler an der York University in Toronto und Co-Autor einer Studie, die er und seine Kollegen
John Totsotsos , ebenfalls aus York, und
Richard Zemel von der University of Toronto.
Die Forscher versuchen immer noch, die Gründe zu klären, warum das Computer-Vision-System so leicht verwirrt wird, und sie haben bereits eine gute Vermutung. Der Punkt in der menschlichen Fähigkeit, den die KI nicht hat, ist die Fähigkeit zu erkennen, dass die Szene unverständlich ist, und wir müssen sie noch einmal genauer betrachten.
Elefant im Raum
Wenn wir die Welt betrachten, nehmen wir eine erstaunliche Menge visueller Informationen wahr. Das menschliche Gehirn verarbeitet es unterwegs. "Wir öffnen unsere Augen und alles passiert von selbst", sagt Totsotsos.
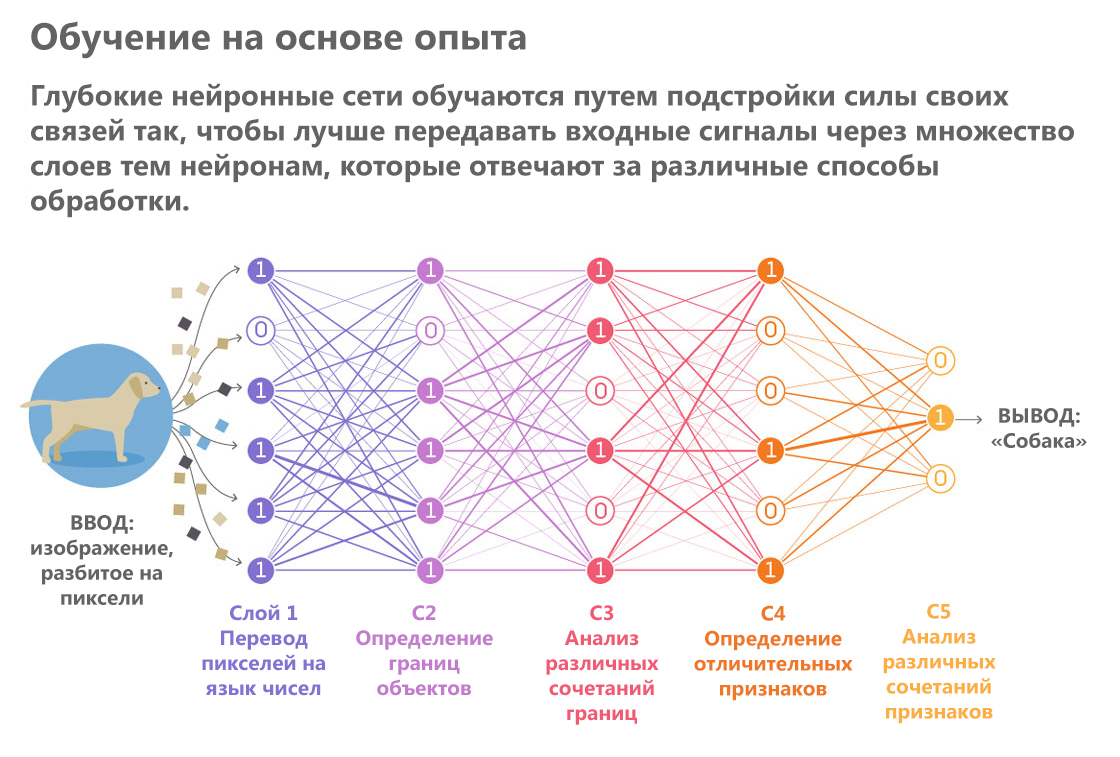
Künstliche Intelligenz hingegen erzeugt akribisch einen visuellen Eindruck, als würde man eine Beschreibung in Blindenschrift lesen. Er fährt mit seinen algorithmischen Fingerspitzen durch die Pixel und bildet daraus allmählich immer komplexere Darstellungen. Eine Vielzahl von KI-Systemen, die ähnliche Prozesse ausführen, sind neuronale Netze. Sie leiten ein Bild durch eine Reihe von „Ebenen“. Während jede Schicht durchläuft, werden einzelne Bilddetails wie die Farbe und Helligkeit einzelner Pixel verarbeitet, und auf der Grundlage dieser Analyse wird eine zunehmend abstrakte Beschreibung des Objekts gebildet.
„Die Ergebnisse der Verarbeitung der vorherigen Schicht werden wie auf einem Förderband auf die nächste übertragen und so weiter“, erklärt Totsotsos.
 Gepostet von: Lucy Reading-Ikkanda / Quanta Magazine
Gepostet von: Lucy Reading-Ikkanda / Quanta MagazineNeuronale Netze sind Experten für bestimmte Routineaufgaben im Bereich der visuellen Verarbeitung. Sie sind besser als Menschen, um hochspezialisierte Aufgaben wie die Bestimmung der Hunderasse und andere Sortierungen von Objekten in Kategorien zu bewältigen. Diese erfolgreichen Beispiele haben die Hoffnung geweckt, dass Computer-Vision-Systeme bald so intelligent werden, dass sie in überfüllten Straßen der Stadt ein Auto fahren können.
Es veranlasste Experten auch, ihre Schwachstellen zu untersuchen. In den letzten Jahren haben Forscher eine Reihe von Versuchen unternommen, feindliche Angriffe zu simulieren. Sie haben Szenarien entwickelt, die neuronale Netze zu Fehlern zwingen. In einem Experiment
täuschten Informatiker
das Netzwerk und zwangen es, die Schildkröte für eine Waffe zu nehmen. Eine andere Geschichte über erfolgreiches Betrügen war, dass die Forscher neben gewöhnlichen Gegenständen wie einer Banane einen Toaster in psychedelischen Farben auf das Bild
legten .
In der neuen Arbeit haben Wissenschaftler den gleichen Ansatz gewählt. Drei Forscher zeigten ein neuronales Netzwerkfoto eines Wohnzimmers. Es fängt einen Mann ein, der ein Videospiel spielt, auf der Kante eines alten Stuhls sitzt und sich nach vorne beugt. Als AI diese Szene "verdaute", erkannte sie schnell mehrere Objekte: eine Person, ein Sofa, einen Fernseher, einen Stuhl und ein paar Bücher.
Dann fügten die Forscher ein für ähnliche Szenen ungewöhnliches Objekt hinzu: ein Bild eines Elefanten in einem Halbprofil. Und das neuronale Netzwerk ist verwirrt. In einigen Fällen zwang das Erscheinen eines Elefanten sie, sich auf einen Stuhl für ein Sofa zu setzen, und manchmal sah das System bestimmte Objekte nicht mehr, deren Erkennung zuvor keine Probleme aufwies. Dies ist zum Beispiel eine Buchreihe. Darüber hinaus traten auch bei weit vom Elefanten entfernten Objekten Fehlschläge auf.
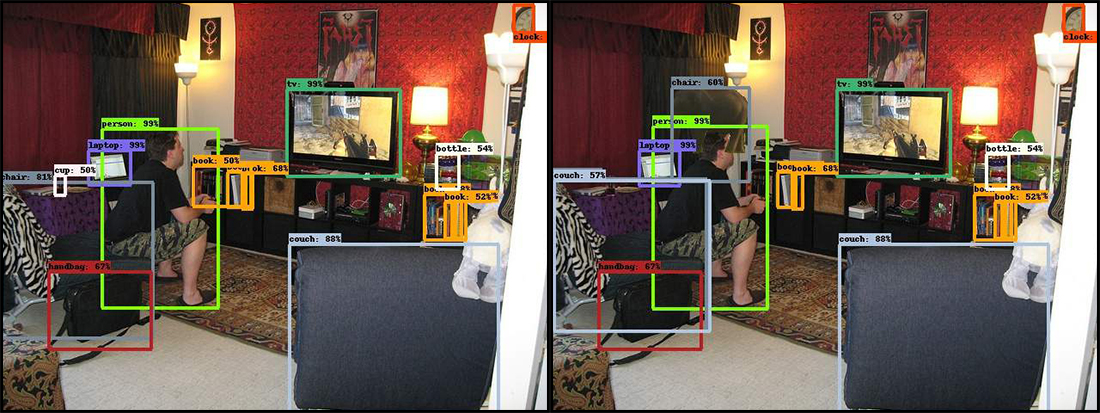 Auf dem Original links identifizierte das neuronale Netzwerk korrekt und mit hoher Sicherheit viele Objekte im Wohnzimmer, die voller verschiedener Dinge waren. Sobald der Elefant hinzugefügt wurde (Bild rechts), stürzte das Programm ab. Der Stuhl in der unteren linken Ecke verwandelte sich in ein Sofa, die Tasse daneben verschwand und der Elefant wurde zu einem Stuhl.
Auf dem Original links identifizierte das neuronale Netzwerk korrekt und mit hoher Sicherheit viele Objekte im Wohnzimmer, die voller verschiedener Dinge waren. Sobald der Elefant hinzugefügt wurde (Bild rechts), stürzte das Programm ab. Der Stuhl in der unteren linken Ecke verwandelte sich in ein Sofa, die Tasse daneben verschwand und der Elefant wurde zu einem Stuhl.Ähnliche Systemfehler sind für dasselbe autonome Fahren völlig inakzeptabel. Der Computer kann das Auto nicht fahren, wenn er Fußgänger nicht bemerkt, nur weil er einige Sekunden zuvor einen Truthahn am Straßenrand gesehen hat.
Was den Elefanten selbst betrifft, so unterschieden sich auch die Ergebnisse seiner Erkennung von Versuch zu Versuch. Das System hat es dann richtig ermittelt, manchmal als Schaf bezeichnet, und es dann überhaupt nicht bemerkt.
"Wenn ein Elefant wirklich im Raum erscheint, wird es wahrscheinlich jeder bemerken", sagt Rosenfeld. "Und das System hat nicht einmal seine Anwesenheit aufgezeichnet."
Enge Beziehung
Wenn Menschen etwas Unerwartetes sehen, sehen sie es besser. Egal wie einfach es sich anhört, „schauen Sie genauer hin“, dies hat echte kognitive Konsequenzen und erklärt, warum KI falsch ist, wenn etwas Ungewöhnliches auftritt.
Bei der Verarbeitung und Erkennung von Objekten geben die besten modernen neuronalen Netze Informationen nur in Vorwärtsrichtung durch sich selbst weiter. Sie beginnen mit der Auswahl von Pixeln am Eingang, gehen zu Kurven, Formen und Szenen über und machen in jeder Phase die wahrscheinlichsten Vermutungen. Jegliche Missverständnisse in den frühen Phasen des Prozesses führen zu Fehlern am Ende, wenn das neuronale Netzwerk seine „Gedanken“ zusammenfasst, um zu erraten, was es betrachtet.
„In neuronalen Netzen sind alle Prozesse eng miteinander verbunden, sodass immer die Möglichkeit besteht, dass jedes Merkmal irgendwo ein mögliches Ergebnis beeinflusst“, sagt Totsosos.
Der menschliche Ansatz ist besser. Stellen Sie sich vor, Sie hätten einen kurzen Blick auf ein Bild geworfen, das einen Kreis und ein Quadrat hat, eines rot, das andere blau. Danach wurden Sie gebeten, die Farbe des Quadrats zu benennen. Ein kurzer Blick reicht möglicherweise nicht aus, um sich die Farben richtig zu merken. Sofort kommt das Verständnis, dass Sie nicht sicher sind und Sie erneut suchen müssen. Und was sehr wichtig ist, während der zweiten Betrachtung wissen Sie bereits, worauf Sie sich konzentrieren müssen.
"Das menschliche visuelle System sagt:" Ich kann immer noch nicht die richtige Antwort geben, also gehe ich zurück und überprüfe, wo der Fehler aufgetreten sein könnte ", erklärt Totsotsos, der eine Theorie namens"
Selektive Abstimmung "entwickelt, die dieses Merkmal der visuellen Wahrnehmung erklärt.
Den meisten neuronalen Netzen fehlt die Fähigkeit, zurückzukehren. Diese Funktion ist sehr schwer zu entwerfen. Einer der Vorteile von unidirektionalen Netzwerken besteht darin, dass sie relativ einfach zu trainieren sind. Führen Sie die Bilder einfach durch die sechs genannten Ebenen und erhalten Sie das Ergebnis. Wenn neuronale Netze jedoch „genau hinschauen“ sollen, müssen sie auch zwischen einer feinen Linie unterscheiden, wann es besser ist, zurück zu gehen und wann sie weiterarbeiten. Das menschliche Gehirn wechselt leicht und natürlich zwischen solchen unterschiedlichen Prozessen. Und neuronale Netze benötigen eine neue theoretische Basis, damit sie dasselbe tun können.
Führende Forscher aus der ganzen Welt arbeiten in diese Richtung, brauchen aber auch Hilfe. Vor kurzem hat das Google AI-Projekt
einen Wettbewerb für Crowdsourcing-Bildklassifizierer
angekündigt , der zwischen Fällen absichtlicher Bildverzerrung unterscheiden kann. Die Lösung, die das Bild des Vogels klar vom Bild des Fahrrads unterscheiden kann, wird gewinnen. Dies wird ein bescheidener, aber sehr wichtiger erster Schritt sein.
