Die Enron Corporation ist eine der bekanntesten Persönlichkeiten der amerikanischen Wirtschaft in den 2000er Jahren. Dies wurde nicht durch ihren Tätigkeitsbereich (Elektrizität und Verträge für seine Lieferung) erleichtert, sondern durch die Resonanz aufgrund von Betrug. Seit 15 Jahren ist das Unternehmenseinkommen schnell gewachsen, und die Arbeit darin versprach ein gutes Gehalt. Aber alles endete genauso flüchtig: im Zeitraum 2000-2001. Der Aktienkurs fiel von 90 USD / Stück auf fast Null, was auf aufgedeckten Betrug mit deklariertem Einkommen zurückzuführen war. Seitdem ist das Wort "Enron" ein Begriff im Haushalt und dient als Bezeichnung für Unternehmen, die nach einem ähnlichen Muster arbeiten.
Während des Prozesses wurden 18 Personen (einschließlich der größten Angeklagten in diesem Fall: Andrew Fastov, Jeff Skilling und Kenneth Lay) verurteilt.
![Bild! [Bild] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Gleichzeitig wurden ein Archiv der elektronischen Korrespondenz zwischen Mitarbeitern des Unternehmens, besser bekannt als Enron Email Dataset, und Insiderinformationen über das Einkommen der Mitarbeiter dieses Unternehmens veröffentlicht.
In dem Artikel werden die Quellen dieser Daten untersucht und ein darauf basierendes Modell erstellt, um festzustellen, ob eine Person des Betrugs verdächtigt wird. Klingt interessant? Dann willkommen im Habrakat.
Beschreibung des Datensatzes
Enron-Datensatz (Datensatz) ist ein zusammengesetzter Satz offener Daten, der Aufzeichnungen von Personen enthält, die in einem denkwürdigen Unternehmen mit dem entsprechenden Namen arbeiten.
Es kann 3 Teile unterscheiden:
- Zahlungen_Funktionen - eine Gruppe, die finanzielle Bewegungen charakterisiert;
- stock_features - eine Gruppe, die die mit Aktien verbundenen Zeichen widerspiegelt;
- email_features - Eine Gruppe, die Informationen über die E-Mails einer bestimmten Person in aggregierter Form wiedergibt.
Natürlich gibt es auch eine Zielvariable, die angibt, ob die Person des Betrugs verdächtigt wird (das Zeichen „Poi“ ).
Laden Sie unsere Daten herunter und beginnen Sie mit ihnen zu arbeiten:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
Danach verwandeln wir den Datensatz data_dict in einen Pandas-Datenrahmen, um das Arbeiten mit Daten zu vereinfachen:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
Wir gruppieren die Zeichen gemäß den zuvor angegebenen Typen. Dies sollte die Arbeit mit Daten danach erleichtern:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
Finanzdaten
In diesem Datensatz ist vielen ein NaN bekannt, der die übliche Lücke in den Daten ausdrückt. Mit anderen Worten, der Autor des Datensatzes konnte keine Informationen zu einem bestimmten Attribut finden, das einer bestimmten Zeile im Datenrahmen zugeordnet ist. Infolgedessen können wir annehmen, dass NaN 0 ist, da es keine Informationen über ein bestimmtes Merkmal gibt.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
Datenüberprüfung
Beim Vergleich mit dem Original-PDF , das dem Datensatz zugrunde liegt, stellte sich heraus, dass die Daten leicht verzerrt sind, da das Feld total_payments nicht für alle Zeilen im Zahlungsdatenrahmen die Summe aller Finanztransaktionen einer bestimmten Person ist. Sie können dies wie folgt überprüfen:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

Wir sehen, dass BELFER ROBERT und BHATNAGAR SANJAY falsche Zahlungsbeträge haben.
Sie können diesen Fehler beheben, indem Sie die Daten in den Fehlerzeilen nach links oder rechts verschieben und die Summe aller Zahlungen erneut zählen:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Bestandsdaten
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
Führen Sie auch in diesem Fall eine Validierungsprüfung durch:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

Wir werden den Fehler in den Beständen auf ähnliche Weise beheben:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
E-Mail-Korrespondenz
Wenn für diese Finanzen oder Aktien NaN gleich 0 war und dies in das Endergebnis für jede dieser Gruppen passt, ist es im Fall von E-Mail sinnvoller, NaN durch einen Standardwert zu ersetzen. Dazu können Sie Imputer verwenden:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
Gleichzeitig werden wir den Standardwert für jede Kategorie (unabhängig davon, ob wir eine Person des Betrugs vermuten) separat betrachten:
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
Endgültiger Datensatz nach Korrektur:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
Emissionen
Im letzten Schritt dieser Phase werden alle Ausreißer entfernt, die das Training verzerren können. Gleichzeitig stellt sich immer die Frage: Wie viele Daten können wir aus der Stichprobe entfernen und trotzdem als trainiertes Modell nicht verlieren? Ich folgte dem Rat eines der Dozenten des ML-Kurses (Maschinelles Lernen) zu Udacity - „10 entfernen und erneut auf Emissionen prüfen.“
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
Gleichzeitig werden keine Datensätze gelöscht, die Ausreißer sind und des Betrugs verdächtigt werden. Der Grund ist, dass es nur 18 Zeilen mit solchen Daten gibt, und wir können sie nicht opfern, da dies zu einem Mangel an Trainingsbeispielen führen kann. Infolgedessen entfernen wir nur diejenigen, die nicht des Betrugs verdächtigt werden, aber gleichzeitig eine Vielzahl von Anzeichen haben, anhand derer Emissionen beobachtet werden:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
Finalisieren
Wir normalisieren unsere Daten:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
Lässt die Zielvariable auf eine kompatible Ansicht abzielen:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

Infolgedessen 18 Verdächtige und 121 diejenigen, die nicht verdächtigt wurden.
Funktionsauswahl
Vielleicht ist einer der wichtigsten Punkte vor dem Erlernen eines Modells die Auswahl der wichtigsten Merkmale.
Multikollinearitätstest
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
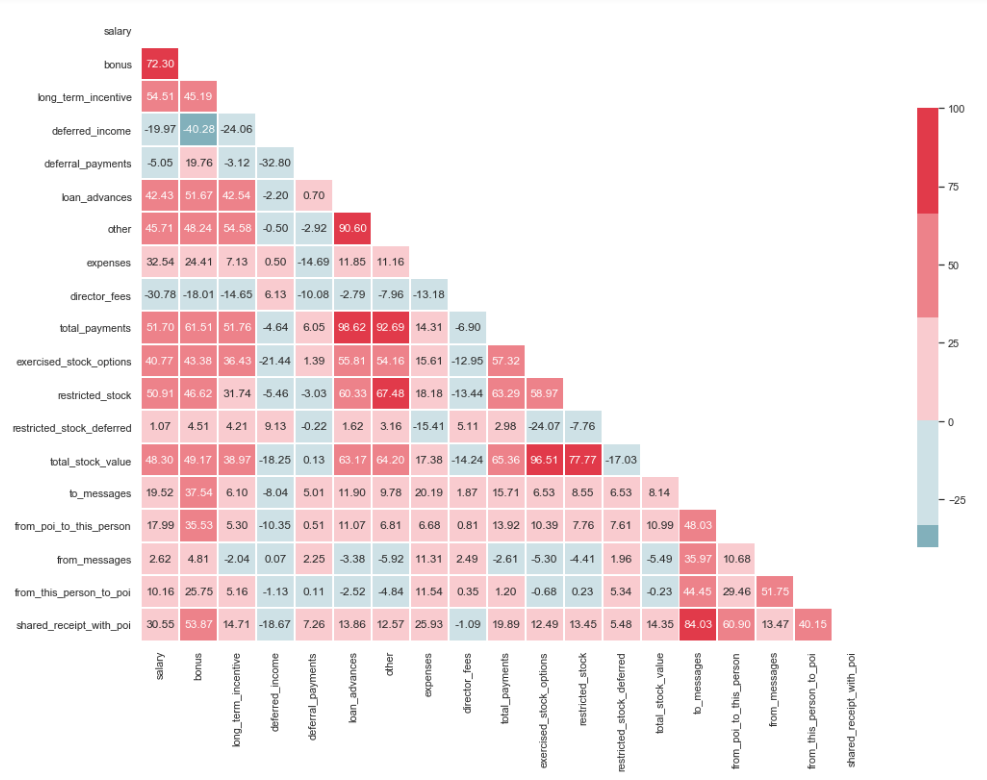
Wie Sie auf dem Bild sehen können, besteht eine ausgeprägte Beziehung zwischen 'credit_advanced' und 'total_payments' sowie zwischen 'total_stock_value' und 'beschränkter_stock'. Wie bereits erwähnt, sind 'total_payments' und 'total_stock_value' nur das Ergebnis der Addition aller Indikatoren in einer bestimmten Gruppe. Daher können sie gelöscht werden:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Neue Eigenschaften schaffen
Es besteht auch die Annahme, dass die Verdächtigen häufiger an Komplizen als an Mitarbeiter geschrieben haben, die daran nicht beteiligt waren. Infolgedessen sollte der Anteil solcher Nachrichten größer sein als der Anteil der Nachrichten an normale Mitarbeiter. Basierend auf dieser Aussage können Sie neue Zeichen erstellen, die den Prozentsatz der eingehenden / ausgehenden Personen im Zusammenhang mit Verdächtigen widerspiegeln:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Unnötige Zeichen herausfiltern
Im Toolkit der mit ML verbundenen Personen gibt es viele hervorragende Tools zur Auswahl der wichtigsten Funktionen (SelectKBest, SelectPercentile, VarianceThreshold usw.). In diesem Fall wird RFECV verwendet, da es eine Kreuzvalidierung enthält, mit der Sie die wichtigsten Merkmale berechnen und in allen Teilmengen der Stichprobe überprüfen können:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
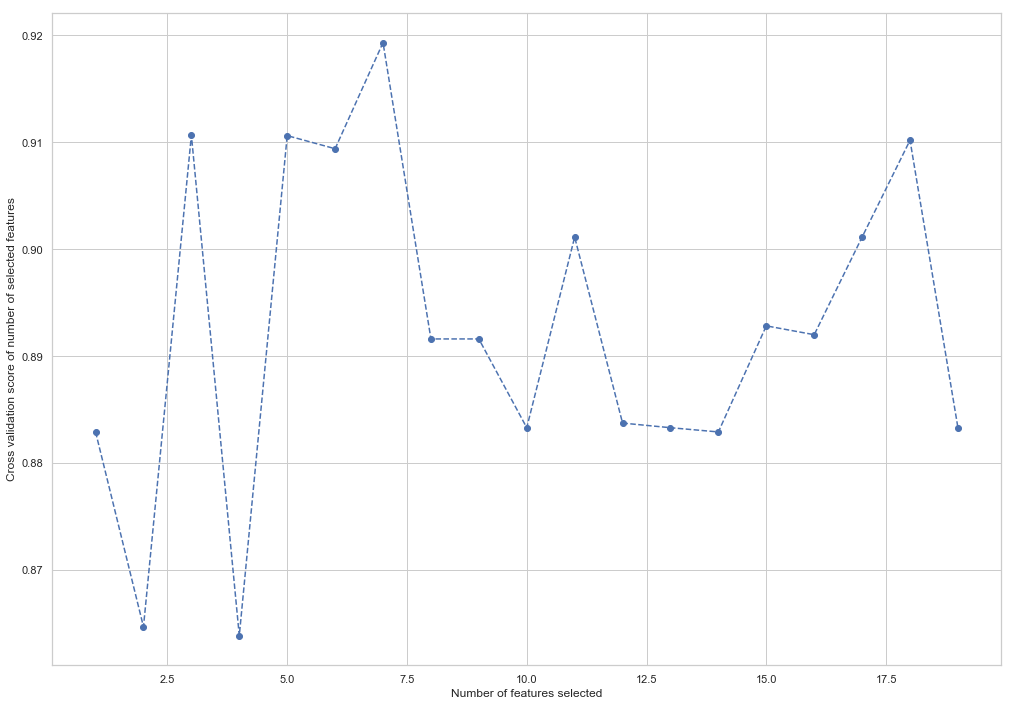
Wie Sie sehen können, hat RandomForestClassifier berechnet, dass nur 7 der 18 Attribute von Bedeutung sind. Die Verwendung des Restes verringert die Genauigkeit des Modells.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
Diese 7 Funktionen werden in Zukunft verwendet, um das Modell zu vereinfachen und das Risiko einer Umschulung zu verringern:
- Bonus
- deferred_income
- andere
- ausgeübte_Stock_Optionen
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
Ändern Sie die Struktur der Trainings- und Testmuster für das zukünftige Modelltraining:
X_train = X_train[columns] X_test = X_test[columns]
Dies ist das Ende des ersten Teils, in dem die Verwendung des Enron-Datensatzes als Beispiel für eine Klassifizierungsaufgabe in ML beschrieben wird. Basierend auf den Materialien aus dem Kurs Einführung in maschinelles Lernen über Udacity. Es gibt auch ein Python-Notizbuch , das die gesamte Abfolge der Aktionen widerspiegelt.
Der zweite Teil ist hier