
Oft müssen Programmierer mit dem unbekannten Code eines anderen umgehen. Dies kann die Untersuchung interessanter Open-Source-Projekte und der Arbeitsbedarf sein - im Falle des Beitritts zu einem neuen Projekt, bei der Analyse einer großen Menge von Legacy-Code usw. Ich denke, jeder von euch ist darauf gestoßen.
Während dieser Arbeit hatte ich immer das Bedürfnis nach einem Tool, das speziell darauf zugeschnitten ist, das schnelle Eintauchen in große Mengen unbekannten Codes zu erleichtern. Im Laufe der Zeit tauchten immer mehr interessante Ideen in verschiedenen Bereichen auf, und alle erforderten das Studium großer Mengen des Codes anderer Leute. Dezentrale Netzwerke, Kryptowährungen, Compiler, Betriebssysteme - all dies sind große Projekte, bei denen erhebliche Mengen an Code untersucht werden müssen. Irgendwann entschied ich mich: Sie müssen nur dieses spezielle Werkzeug nehmen und herstellen. In diesem Artikel stelle ich Ihnen vor, was daraus entstanden ist.
Was kann im Allgemeinen beim Erlernen des Codes helfen? Natürlich ist es gut, wenn es eine detaillierte Dokumentation für den Code gibt - in der Regel ist er nicht vorhanden. Ein guter Codierungsstil und Kommentare sind ebenfalls gut, aber dies reicht normalerweise nicht aus. Es gibt auch verschiedene Generatoren für die Codedokumentation, z. B. Sauerstoff. Durch die Analyse der Codestruktur und spezieller Dokumentationskommentare generieren sie eine Dokumentation in Form von Hypertext im HTML-Format. Der Hauptnachteil einer solchen Dokumentation ist ihre Nichtinteraktivität; Während des Studierens des Codes hat der Programmierer möglicherweise ein neues Verständnis. Um dies in der Dokumentation wiederzugeben, müssen Sie neue Dokumentationskommentare schreiben und die gesamte Dokumentation erneut generieren.
Darüber hinaus bezieht sich eine solche Dokumentation nicht direkt auf Code in der Entwicklungsumgebung, d. H. Durch Klicken auf den Hyperlink wird die Datei mit diesem Code in der IDE nicht geöffnet. Für solche Tools gibt es eine gute Analogie, die in der Antike verwurzelt war: Die ersten Disassembler waren Befehlszeilentools, die Code ohne Benutzereingriff generierten. Dann kam der erste interaktive Disassembler ("IDA Pro"), der die aktive Teilnahme des Benutzers am Demontageprozess voraussetzte - Zuweisen von Namen von Variablen und Funktionen, Definieren von Strukturen, Schreiben von Kommentaren zum Code usw.
Die Analyse großer Mengen von Fremdcode in einer Hochsprache ist in gewisser Weise der Demontage sehr ähnlich. So begann ich eine Idee zu entwickeln, was genau ich will. Die meisten IDEs verfügen über klassische Bedienfelder für Dateiansicht und Klassenansicht, in denen die Struktur von Dateien sowie die darin enthaltenen Namen- / Klassenräume angezeigt werden. Diese Struktur ist jedoch normalerweise eng mit der Syntax der Sprache verbunden und ermöglicht es Ihnen nicht, benutzerdefinierte semantische Ladevorgänge durchzuführen. Das erste, was ich haben wollte, war die interaktive Fähigkeit, beliebige Bäume mit aussagekräftig benannten Code-Referenzen zu erstellen - auf dieselben Klassen und Funktionen oder auf beliebige Stellen überhaupt. Und das zweite ist der Wunsch, den Code irgendwie direkt im Editor zu markieren. Markierungen können verschiedene Bedeutungen haben: von einfach „gelernt“, „aussortiert“, „umgeschrieben“ bis hin zu Code, der zu verschiedenen semantischen Gruppen gehört. Sie können es mit einem Kommentar markieren, aber ich wollte etwas auffälligeres. Zum Beispiel Änderungen in der Hintergrundfarbe eines Codefragments. KDPV-Farbseparatoren sind also eine ziemlich genaue Analogie zur realen Welt.
Nach den ersten Experimenten wurde mir schnell klar, dass dies ein Plug-In für die moderne Entwicklungsumgebung sein sollte und nicht mein eigener Editor. Es ist dumm und unpraktisch, von zwei Redakteuren gleichzeitig zu arbeiten. Die Aussicht, alle Möglichkeiten der Entwicklungsumgebung zu wiederholen, hat keine Freude gemacht, und warum sollte das getan werden, was bereits getan wurde? Daher das Plugin. Qt Creator wurde als erste IDE ausgewählt, einfach weil die beliebtesten Code-Navigationsvorgänge (Zur Definition gehen, Referenzen suchen usw.) so schnell wie möglich ausgeführt werden. Die nächste Umgebung ist Visual Studio und im Falle des Erfolgs des Konzepts selbst die Implementierung für andere IDEs.
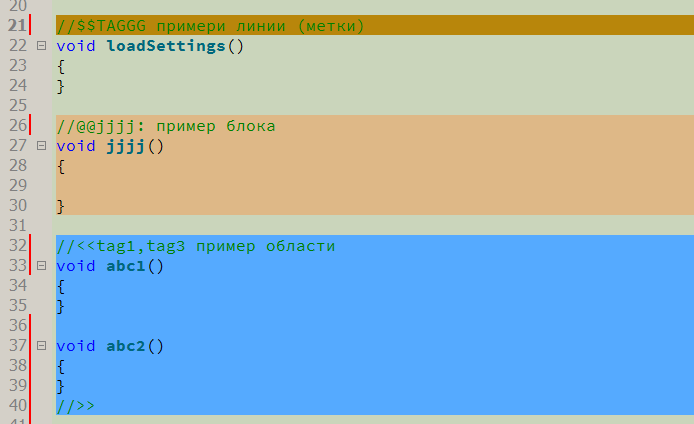
Nun dazu, wie alles arrangiert ist. Das Konzept der „Markerkommentare“ wird eingeführt. Dies ist ein regulärer Kommentar einer Programmiersprache (im Moment ist dies ein einzeiliger Kommentar "//", der in vielen Sprachen verwendet wird - C, C ++, C #, Java, ...), gefolgt von einer Folge von Sonderzeichen, gefolgt von einem Bezeichner und / oder Tags. Darauf kann ein normaler menschlicher Kommentar folgen. Ich habe drei Arten von Markerkommentaren eingeführt
- Kommentar, um einen beliebigen Bereich hervorzuheben. Der einzige Typ, der einen Markierungskommentar zum Schließen erfordert. Beginnt mit "// <<" und endet mit "// >>".
- Kommentar, um eine beliebige Zeile im Code anzugeben. Bezeichnet mit "// $$"
- Kommentar, um den syntaktisch korrekten Codeblock hervorzuheben. Es beginnt mit "// @@" und enthält den folgenden Codeblock, begrenzt durch geschweifte Klammern "{" und "}", die für Codeblöcke in den meisten C-ähnlichen Programmiersprachen verwendet werden. Eine vollständige Klammeranalyse wurde implementiert - verschachtelte geschweifte Klammern sind zulässig, und der Parser überspringt geschweifte Klammern in Zeilen und Kommentaren korrekt.
Unmittelbar nach den Sonderzeichen folgen ein oder mehrere durch Kommas getrennte Bezeichner. Bezeichner sind "Tags" und können bedeuten, was der Programmierer will - Zeichen "studiert", "umschreiben", "verstehen", Urheberschaft des Codes, die Beziehung des Codes zu einigen semantischen Gruppen usw. Sie können auch eine eindeutige Kennung angeben - diese wird zuerst platziert und durch einen Doppelpunkt vom Rest getrennt. Wenn Sie möchten, können Sie die Hintergrundfarbe des Code-Snippets explizit angeben. Am Ende der Liste der Tags wird ein Raster eingefügt. Danach wird die Farbe im RGB-Format angezeigt (obwohl diese Methode nicht die beste ist - wir werden später über einen anderen, "korrekteren" Weg sprechen). Und ganz am Ende können Sie ein Leerzeichen einfügen und dann einen regelmäßig von Menschen lesbaren Kommentar schreiben. Ich habe versucht, die Syntax so zu wählen, dass sie für eine schnelle Eingabe so einfach wie möglich ist, den Code nicht überfüllt und für gewöhnliche Kommentare geeignet ist.
Obwohl die manuelle Eingabe von Markerkommentaren möglich ist, sollten hierfür spezielle Symbolleistenschaltflächen verwendet werden. Der Cursor wird auf die gewünschte Position des Codes gesetzt und die Taste gedrückt (oder eine der letzten Optionen wird aus dem Menü ausgewählt).
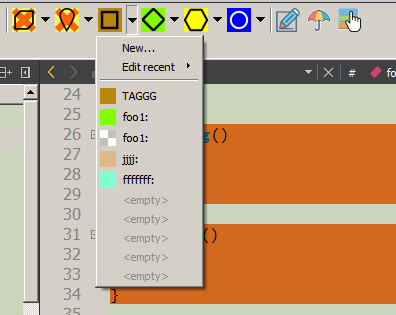
Bei Bedarf wird ein Eingabedialog geöffnet, in dem Sie Tags und Kennungen von Markerkommentaren sowie eine detaillierte Beschreibung eingeben und eine Hintergrundfarbe auswählen können. Diese Daten werden nicht nur in den Code eingegeben, sondern auch in den Baum „CRContentTree“, der seitlich im Baumfenster angezeigt wird (wo FileView, ClassView usw.). Es ist zu beachten, dass die Hintergrundfarbe „transparent“ sein kann - in diesem Fall wird die Hintergrundfarbe des umschließenden Blocks (falls vorhanden) verwendet oder die Hintergrundbeleuchtung wird überhaupt nicht verwendet.
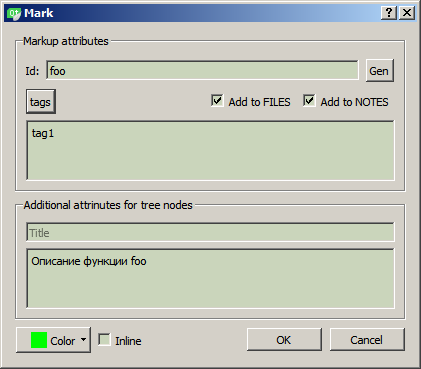
Im Moment besteht der Baum aus drei Hauptteilen (Knoten der obersten Ebene): DATEIEN, TAGS und ANMERKUNGEN (möglicherweise ist dies nicht die endgültige Lösung, da das Konzept noch nicht ganz offensichtlich ist und die Bequemlichkeit einer solchen Struktur).
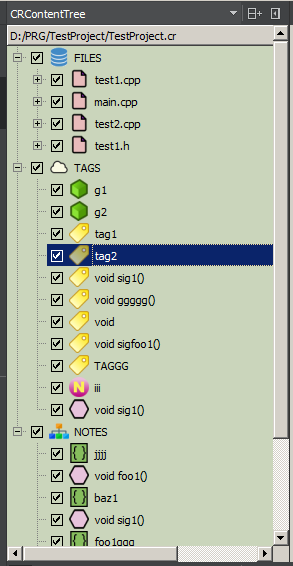
DATEIEN ist die Dateistruktur des Projekts, die aus der Projektdatei oder aus dem Speicherort der Quellen auf der Festplatte extrahiert wird. Dateiknoten werden während der ersten Baumgenerierung erstellt. Ein Doppelklick auf einen Dateiknoten öffnet normalerweise die Datei im IDE-Editor. Sie können das Hinzufügen von Markerkommentaren in DATEIEN angeben. Anschließend wird in der entsprechenden Datei ein untergeordneter Knoten angezeigt. Hier werden eindeutige Markerkommentar-IDs hinzugefügt. Das System überprüft die Eindeutigkeit des Bezeichners innerhalb des Dateiknotens des Baums und ermöglicht die automatische Generierung eines eindeutigen Namens.
TAGS ist eine globale Projekt-Tag-Cloud. Tags sind nicht an die Quellcodedatei gebunden und können in jeder Projektdatei so oft vorkommen, wie Sie möchten.
NOTES ist ein Ort zum Speichern von Knoten, die auf beliebige Weise gruppiert und nicht an die Dateistruktur gebunden sind. Jeder Knoten enthält sowohl einen Dateipfad als auch eine Kennung. Der Hauptzweck besteht darin, benutzerdefinierte logische Gruppen zu erstellen. Zum Beispiel "alle Funktionen, die neu geschrieben werden müssen" oder "alle Funktionen im Zusammenhang mit Kryptographie" oder "die Reihenfolge der Netzwerkkommunikationsfunktionen mit dem Server" (da die Knoten im Baum geordnet sind, können durch einfaches Platzieren der Knoten nacheinander beliebige Sequenzen angezeigt werden).
Jeder Baumknoten hat ein Kontextmenü. Der Knoten kann gelöscht werden (obwohl dadurch keine Markerkommentare aus dem Code entfernt werden - solange ich nicht sicher bin, ob dies erforderlich ist), können Sie ihn bearbeiten. Sie können Knoten hinzufügen, die nicht mit Markerkommentaren verknüpft sind: Sie können beispielsweise einen Link (Link) hinzufügen. Durch Doppelklicken auf einen solchen Knoten wird eine verwandte Ressource in einem zugeordneten Programm geöffnet, z. B. ein Hyperlink in einem Browser.
Jeder Knoten kann deaktiviert werden, indem das Kontrollkästchen im Knoten deaktiviert wird. Dadurch wird die Hervorhebung dieses Knotens und aller untergeordneten Knoten im Code entfernt. Wenn Sie beispielsweise die Häkchen von den drei Stammknoten (DATEIEN, TAGS und ANMERKUNGEN) entfernen, können Sie die Hervorhebung aller Markierungskommentare deaktivieren, mit Ausnahme derjenigen, deren Farbe im Code explizit angegeben ist (durch die Balken).
Ein Doppelklick auf den Knoten öffnet die entsprechende Datei in der IDE und positioniert den Cursor an der entsprechenden Codeposition. Für Tags, die wiederholt auftreten können, wird anstelle des Öffnens der Datei eine Liste aller Vorkommen erstellt, die in das CR-Ausgabefenster geladen wird. Durch Doppelklicken auf die entsprechende Zeile dieser Liste können Sie die Datei öffnen und im Code positionieren.
Jeder Knoten verfügt über ein Feld für eine detaillierte Beschreibung (mehrzeiliger Text beliebiger Länge). Diese Beschreibung wird mit einer einfachen Auswahl eines Knotens in der Baumstruktur (mit einem einzigen Mausklick) in den Bereich „CR-Info“ geladen. Sie platzieren den Cursor an einer beliebigen Stelle im markierten Bereich des Codes und klicken auf die Schaltfläche „Nachschlagen“ in der Symbolleiste. Die Bearbeitung ist immer verfügbar, der geänderte Text wird automatisch gespeichert (durch Fokusverlust). Ich denke darüber nach, das Markdown-Format in diesem Bereich zu unterstützen, aber bisher haben meine Hände diesen Punkt noch nicht erreicht.
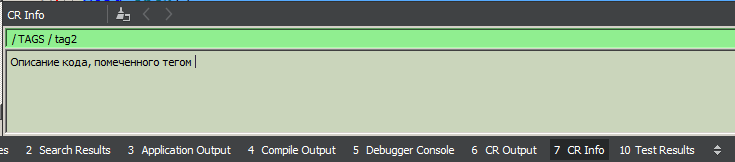
Es ist nicht immer wünschenswert (oder nicht immer bequem), Kommentare in den Code einzufügen. Daher ist die zweite Möglichkeit "Signaturen", d.h. als Markierungen des Codes selbst verwenden. Eine Signatur ist eine bestimmte Folge von Token (ohne Leerzeichen und Zeilenumbrüche - das heißt, „foo (1,2,3)“ und „foo (1, 2, 3) sind ein und dasselbe). Es gibt drei Arten von Signaturen:
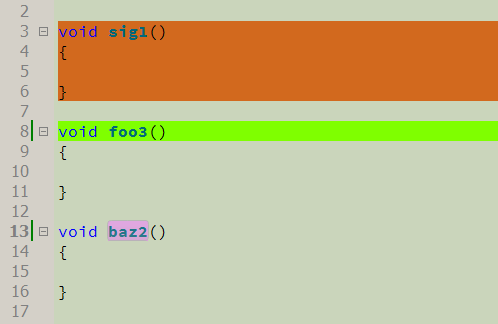
- Block - Ein Block wird hervorgehoben, beginnend mit einer Signatur und mit einer in geschweiften Klammern eingeschlossenen Codesequenz.
- einzeilig - Die gesamte Zeile mit der Signatur wird hervorgehoben
- symbolisch - nur die Signatursequenz wird hervorgehoben. Es ist zweckmäßig, solche Signaturen zu verwenden, um einzelne Namen hervorzuheben - Variablen, Funktionen, Klassen.
Die Arbeit mit Signaturblöcken ist dieselbe wie mit Markierungsblöcken. Ebenso werden Knoten in einem Baum erstellt.
Wenn für Markierungsknoten der Bezeichner und die Tags separat erstellt wurden, wird für Signaturknoten empfohlen, genau anzugeben, wie die Signatur betrachtet werden soll - als Bezeichner (an eine Datei angehängt) oder als globales Tag. Für „Namen“ ist es beispielsweise logisch, den Tag-Modus zu verwenden. Der entsprechende Name wird dann im gesamten Projekt im Code hervorgehoben.
Ein weiteres interessantes Feature ist die Codeabdeckung. Eine spezielle Funktion scannt den Code und ermittelt die Stellen, die überhaupt nicht markiert sind, und erstellt eine Liste dieser Stellen in der „CR-Ausgabe“. Dies berücksichtigt keine leeren Zeilen und Kommentare, d.h. Der Scan berücksichtigt nur signifikanten Code. Durch Doppelklicken auf die Listenzeile können Sie zu dieser Stelle im Code gehen und sie nach dem Studium auf die eine oder andere Weise markieren.
Ein bisschen über das Speicherformat der Datenbank. Tatsächlich werden nur Markerkommentare im Quellcode gespeichert. Der Inhalt des Baums wird in einer speziellen XML-Datei mit der Erweiterung ".cr" gespeichert. Es gibt keine explizite Bindung der Datenbankdatei an Projekte. Wenn Sie jedoch ein Projekt öffnen, wird versucht, eine Cr-Datei mit demselben Namen zu öffnen, wenn zuvor keine Cr-Datei hochgeladen wurde.
Zusammenfassend. Im Allgemeinen habe ich fast alles implementiert, was ich wollte. Das Konzept ist neu und ungewöhnlich. Daher dauert es einige Zeit und das Feedback der Benutzer, um zu verstehen, was entwickelt werden muss und was aufgegeben werden kann. Bei dem Versuch, so viele Möglichkeiten wie möglich zu realisieren, stellte sich heraus, dass etwas leicht zu kompliziert war, was unvermeidlich ist. Die Schnittstelle selbst ist möglicherweise noch nicht eingerichtet und wird sich ändern. Aber insgesamt scheint es ganz gut geklappt zu haben.
Was ist in den Plänen. Diese Version ist eine Demo, größtenteils roh und nicht für den kommerziellen Gebrauch gedacht. Ich habe einen Traum - mein eigenes kommerzielles Produkt herzustellen, das selbst ein kleines, aber stetiges Einkommen bringt und ausreicht, um andere interessante Projekte durchzuführen. Darüber hinaus sind einige Dinge nicht für den kommerziellen Gebrauch angepasst. Ich stelle mir vor, wie ein ähnliches System für den Mehrbenutzermodus angepasst werden kann, wobei zu berücksichtigen ist, dass der Code von mehreren Personen bearbeitet werden kann, die gleichzeitig über das Versionskontrollsystem arbeiten. Es ist auch möglich, in die Richtung zu schauen, in der vertraute Dokumentation (HTML) generiert wird, möglicherweise Tools für eine tiefere Integration in den Code (Parsen anstelle von Lexik / Klammer, automatisches Empfangen von Klassen- und Methodenlisten und Konvertieren in Baumknoten). Natürlich müssen Fehler behoben werden (die noch vorhanden sind) und die Funktionen verbessert werden. Und natürlich warte ich auf Ihre Kommentare mit Ideen und Vorschlägen :)
Das ist alles für den Moment (obwohl es noch einige kleine Funktionen gibt, die ich im Artikel nicht erwähnt habe - zum Beispiel hielt ich es für notwendig, Registerkarten hinzuzufügen, da es ohne sie wirklich traurig ist - obwohl es mehrere Plugins für Registerkarten gibt, werden einige grundlegende Qt-Befehle auch in der Symbolleiste angezeigt Ersteller nicht mit dem Plugin verwandt; etc.).
Download-Link:
https://www.dropbox.com/s/9iiw5x7elwy3tpe/CodeRainbow4.zip?dl=0Systemanforderungen: Windows, Qt Creator> = 4.5.1, kompiliert von MSVC2015 32bit (dies ist die Standard-Assembly, die auf download.qt.io verteilt wird)
Installation: Entpacken Sie das Archiv und kopieren Sie das Plugin in den Ordner c: /Qt/Qt5.10.1/Tools/QtCreator/lib/qtcreator/plugins (dies ist ein Beispiel für die Standard-Qt-Platzierung, wenn Sie Qt anders oder in einer anderen Version installiert haben - der Pfad ist anders) und Führen Sie Qt Creator (erneut) aus.