Einführung
Hallo Habr!
Ich möchte die Erfahrung des Schreibens von Migrationen für Postgres und Django teilen. Hier geht es hauptsächlich um Postgres. Django ist hier eine gute Ergänzung, da das Datenschema für Modelländerungen sofort automatisch migriert wird, dh eine ziemlich vollständige Liste der Arbeitsvorgänge zum Ändern des Schemas. Django kann durch jedes bevorzugte Framework / jede bevorzugte Bibliothek ersetzt werden - die Ansätze werden höchstwahrscheinlich ähnlich sein.
Ich werde nicht beschreiben, wie ich dazu gekommen bin, aber jetzt, wo ich die Dokumentation lese, komme ich auf die Idee, dass es notwendig war, dies früher mit größerer Sorgfalt und Aufmerksamkeit zu tun, daher empfehle ich es sehr.
Bevor ich weiter gehe, möchte ich die folgenden Annahmen treffen.
Sie können die Logik der Arbeit mit der Datenbank der meisten Anwendungen in drei Teile unterteilen:
- Migrationen - Ändern des Datenbankschemas (Tabellen). Nehmen wir an, wir führen sie immer in einem Thread aus.
- Geschäftslogik - direkte Arbeit mit Daten (in Benutzertabellen), arbeitet ständig und wettbewerbsfähig mit denselben Daten.
- Datenmigrationen - Ändern Sie keine Datenschemata, sie funktionieren im Wesentlichen wie Geschäftslogik. Wenn wir über Geschäftslogik sprechen, meinen wir standardmäßig auch Datenmigrationen.
Ausfallzeit ist ein Zustand, in dem ein Teil unserer Geschäftslogik für eine für den Benutzer spürbare Zeit nicht verfügbar ist / fällt / geladen wird. Nehmen wir an, dies sind einige Sekunden.
Das Fehlen von Ausfallzeiten kann eine kritische Bedingung für ein Unternehmen sein, an die sich alle Anstrengungen halten müssen.
Rollout-Prozess
Die Hauptanforderungen beim Rollout:
- Wir haben eine Arbeitsbasis.
- Wir haben mehrere Maschinen, auf denen sich die Geschäftslogik dreht.
- Autos mit Geschäftslogik sind hinter dem Balancer versteckt.
- Unsere Anwendung funktioniert gut vor, während und nach der fortlaufenden Migration (der alte Code funktioniert korrekt mit dem alten und dem neuen Datenbankschema).
- Unsere Anwendung funktioniert gut vor, während und nach der Aktualisierung des Codes auf den Autos (der alte und der neue Code funktionieren korrekt mit dem aktuellen Datenbankschema).
Wenn es eine große Anzahl von Änderungen gibt und der Rollout diese Bedingungen nicht mehr erfüllt, wird er in die erforderliche Anzahl kleinerer Rollouts unterteilt, die diese Bedingungen erfüllen. Andernfalls treten Ausfallzeiten auf.
Direkte Einführung:
- überflutete die Migration;
- entfernte einen Computer vom Balancer, aktualisierte den Computer und startete neu, gab den Computer an den Balancer zurück;
- wiederholte den vorherigen Schritt, um alle Autos zu aktualisieren.
Die umgekehrte Rollout-Reihenfolge ist für das Löschen von Tabellen und Spalten in einer Tabelle relevant, wenn wir automatisch Migrationen gemäß dem geänderten Schema erstellen und das Vorhandensein aller Migrationen zu CI überprüfen:
- entfernte einen Computer vom Balancer, aktualisierte den Computer und startete neu, gab den Computer an den Balancer zurück;
- wiederholte den vorherigen Schritt, um alle Autos zu aktualisieren;
- überflutete die Migration.
Theorie
Postgres ist eine ausgezeichnete Datenbank. Wir können eine Anwendung schreiben, die dieselben Daten in Hunderten und Tausenden von Streams schreibt und liest, und mit hoher Wahrscheinlichkeit können wir sicher sein, dass unsere Daten gültig bleiben und im Allgemeinen nicht vollständig ACID beschädigt werden. Postgres implementiert verschiedene Mechanismen, um dies zu erreichen. Einer davon ist das Blockieren.
Postgres hat verschiedene Arten von Sperren. Weitere Details finden Sie hier . Als Teil des Themas werde ich nur auf Sperren auf Tabellen- und Aufzeichnungsebene eingehen.
Sperren auf Tabellenebene
Auf Tabellenebene verfügt Postgres über verschiedene Arten von Sperren . Das Hauptmerkmal besteht darin, dass Konflikte auftreten, dh, zwei Vorgänge mit widersprüchlichen Sperren können nicht gleichzeitig ausgeführt werden:
| ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE |
|---|
ACCESS SHARE | | | | | | | | X. |
ROW SHARE | | | | | | | X. | X. |
ROW EXCLUSIVE | | | | | X. | X. | X. | X. |
SHARE UPDATE EXCLUSIVE | | | | X. | X. | X. | X. | X. |
SHARE | | | X. | X. | | X. | X. | X. |
SHARE ROW EXCLUSIVE | | | X. | X. | X. | X. | X. | X. |
EXCLUSIVE | | X. | X. | X. | X. | X. | X. | X. |
ACCESS EXCLUSIVE | X. | X. | X. | X. | X. | X. | X. | X. |
Beispielsweise müssen der ALTER TABLE tablename ADD COLUMN newcolumn integer und der ALTER TABLE tablename ADD COLUMN newcolumn integer SELECT COUNT(*) FROM tablename einzeln ausgeführt werden, da wir sonst nicht herausfinden können, welche Spalten an COUNT(*) .
Bei Django-Migrationen (vollständige Liste unten) gibt es die folgenden Vorgänge und die entsprechenden Sperren:
| Blockieren | Operationen |
|---|
ACCESS EXCLUSIVE | CREATE SEQUENCE , DROP SEQUENCE , CREATE TABLE , DROP TABLE , ALTER TABLE , DROP INDEX |
SHARE | CREATE INDEX |
SHARE UPDATE EXCLUSIVE | CREATE INDEX CONCURRENTLY , DROP INDEX CONCURRENTLY CREATE INDEX CONCURRENTLY , DROP INDEX CONCURRENTLY ALTER TABLE VALIDATE CONSTRAINT |
Von den Kommentaren haben nicht alle ALTER TABLE ACCESS EXCLUSIVE Locking, auch Django-Migrationen haben nicht CREATE INDEX CONCURRENTLY und ALTER TABLE VALIDATE CONSTRAINT , aber sie werden etwas später für eine sicherere Alternative zu Standardoperationen benötigt.
Wenn Migrationen nacheinander in einem Thread ausgeführt werden, sieht alles gut aus, da die Migration nicht mit einer anderen Migration in Konflikt steht, unsere Geschäftslogik jedoch nur während der Migration und des Konflikts funktioniert.
| Blockieren | Operationen | Konflikte mit Sperren | Konflikte mit Operationen |
|---|
ACCESS SHARE | SELECT | ACCESS EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW SHARE | SELECT FOR UPDATE | ACCESS EXCLUSIVE , EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW EXCLUSIVE | INSERT , UPDATE , DELETE | ACCESS EXCLUSIVE , EXCLUSIVE , SHARE ROW EXCLUSIVE , SHARE | ALTER TABLE , DROP INDEX , CREATE INDEX |
Zwei Punkte können hier zusammengefasst werden:
- Wenn es eine Alternative mit einfacherem Sperren gibt, können Sie sie als
CREATE INDEX und CREATE INDEX CONCURRENTLY . - Die meisten Migrationen zur Änderung des Datenschemas stehen in Konflikt mit der Geschäftslogik. Darüber hinaus stehen sie im Widerspruch zu
ACCESS EXCLUSIVE . Das heißt, wir können SELECT nicht einmal SELECT während diese Sperre gedrückt gehalten wird, und erwarten hier möglicherweise eine Ausfallzeit, außer in dem Fall, dass dieser Vorgang nicht sofort funktioniert und unsere Ausfallzeit auftritt ein paar Sekunden.
Es muss eine Auswahl geben, oder wir vermeiden immer ACCESS EXCLUSIVE , ACCESS EXCLUSIVE wir erstellen neue Platten und kopieren die Daten dort - zuverlässig, aber lange Zeit für eine große Datenmenge, oder wir machen ACCESS EXCLUSIVE so schnell wie möglich und machen zusätzliche Warnungen vor Ausfallzeiten - es ist potenziell gefährlich, aber schnell.
Sperren aufzeichnen
Auf der Aufzeichnungsebene gibt es auch Sperren https://www.postgresql.org/docs/current/static/explicit-locking.html#LOCKING-ROWS . Sie stehen ebenfalls in Konflikt, wirken sich jedoch nur auf unsere Geschäftslogik aus:
| FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE |
|---|
FOR KEY SHARE | | | | X. |
FOR SHARE | | | X. | X. |
FOR NO KEY UPDATE | | X. | X. | X. |
FOR UPDATE | X. | X. | X. | X. |
Dies ist der Hauptpunkt bei Datenmigrationen. Wenn wir also eine UPDATE -Datenmigration auf der gesamten Platte durchführen, wartet der Rest der Geschäftslogik, die die Daten aktualisiert, auf die Freigabe der Sperre und überschreitet möglicherweise unseren Ausfallzeitschwellenwert. Daher ist es besser, Aktualisierungen in Teilen für Datenmigrationen durchzuführen. Es ist auch erwähnenswert, dass bei Verwendung komplexerer SQL-Abfragen für Datenmigrationen die Aufteilung in Teile schneller funktionieren kann, da ein optimalerer Plan und optimale Indizes verwendet werden können.
Die Reihenfolge der Operationen
Ein weiteres wichtiges Wissen ist, wie Operationen ausgeführt werden, wann und wie sie Sperren aufheben und aufheben:
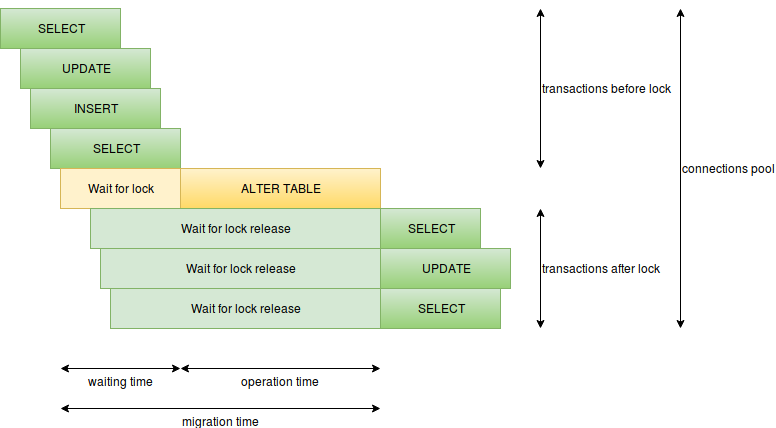
Hier können Sie folgende Elemente hervorheben:
- Ausführungszeit des Vorgangs - für die Migration ist es die Zeit, in der die Sperre gehalten wird. Wenn die schwere Sperre längere Zeit gehalten wird, tritt eine Ausfallzeit auf.
ALTER TABLE ADD COLUMN SET DEFAULT kann beispielsweise mit CREATE INDEX oder ALTER TABLE ADD COLUMN SET DEFAULT (in Postgres 11 ist dies besser). - Die Wartezeit für widersprüchliche Sperren - das heißt, die Migration wartet, bis alle widersprüchlichen Anforderungen erfüllt sind. Zu diesem Zeitpunkt warten neue Anforderungen auf unsere Migration. Langsame Anforderungen können hier sehr gefährlich sein, entweder einfach nicht optimal oder analytisch. Daher sollten währenddessen keine langsamen Anforderungen auftreten Migration.
- Die Anzahl der Anfragen pro Sekunde - Wenn viele Anfragen über einen längeren Zeitraum bearbeitet werden, können freie Verbindungen schnell beendet werden und anstelle eines problematischen Ortes kann die gesamte Datenbank in Ausfallzeiten geraten (es gibt nur ein Verbindungslimit für den Superuser). Hier müssen Sie langsame Anfragen vermeiden und die Anzahl der Anfragen reduzieren Starten Sie beispielsweise Migrationen während der minimalen Auslastung und trennen Sie kritische Komponenten mit ihren eigenen Datenbanken in verschiedene Dienste.
- Es gibt viele Migrationsvorgänge in einer Transaktion. Je mehr Vorgänge in einer Transaktion ausgeführt werden, desto länger wird die schwere Sperre gehalten. Daher ist es besser, schwere Operationen zu trennen, keine
ALTER TABLE VALIDATE CONSTRAINT oder Datenmigrationen in einer Transaktion mit einer schweren Sperre.
Zeitüberschreitungen
lock_timeout verfügt über Einstellungen wie lock_timeout und statement_timeout , die den Beginn von Migrationen sowohl vor schlecht geschriebener Migration als auch vor schlechten Bedingungen schützen können, unter denen eine Migration ausgelöst werden kann. Sie können sowohl global als auch für die aktuelle Verbindung installiert werden.
SET lock_timeout TO '2s' , vermeiden Sie Ausfallzeiten, wenn Sie vor der Migration auf langsame Anforderungen / Transaktionen warten: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-LOCK-TIMEOUT .
SET statement_timeout TO '2s' vermeidet Ausfallzeiten beim Starten einer starken Migration mit einer starken Sperre: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-STATEMENT-TIMEOUT .
Deadlocks
Bei Deadlocks bei Migrationen geht es nicht um Ausfallzeiten, aber es ist nicht angenehm, wenn die Migration geschrieben wird. In einer Testumgebung funktioniert es einwandfrei, aber beim Rolling auf dem Produkt werden Deadlocks abgefangen. Die Hauptprobleme können eine große Anzahl von Vorgängen in einer Transaktion und einem Fremdschlüssel sein, da in beiden Tabellen Sperren erstellt werden. Daher ist es besser, die Migrationsvorgänge zu trennen. Je atomarer, desto besser.
Datensatzspeicher
Postgres speichert Werte verschiedener Typen auf unterschiedliche Weise : Wenn Typen auf unterschiedliche Weise gespeichert werden, erfordert die Konvertierung zwischen ihnen eine vollständige Neufassung aller Werte. Glücklicherweise werden einige Typen auf dieselbe Weise gespeichert und müssen beim Ändern nicht neu geschrieben werden. Beispielsweise werden Zeilen unabhängig von ihrer Größe gleich gespeichert, und das Verringern / Erhöhen der Abmessung einer Zeile erfordert kein Umschreiben. Beim Verringern muss jedoch überprüft werden, ob alle Zeilen eine kleinere Größe nicht überschreiten. Andere Typen können ebenfalls auf ähnliche Weise gespeichert werden und haben ähnliche Eigenschaften.
Multiversion Concurrency Control (MVCC)
Gemäß der Dokumentation basiert die Postgres-Konsistenz auf Datenmultiversion, dh, jede Transaktion und Operation sieht ihre eigene Version der Daten. Diese Funktion kommt mit dem Konkurrenzzugriff perfekt zurecht und bietet auch einen interessanten Effekt, wenn ein Schema wie das Hinzufügen und Entfernen von Spalten nur dann geändert wird, wenn keine zusätzlichen Operationen zum Ändern von Daten, Indizes oder Konstanten vorhanden sind. Danach werden die Einfüge- und Aktualisierungsoperationen auf niedriger Ebene neu erstellt Datensätze mit allen erforderlichen Werten. Durch Löschen wird der entsprechende Datensatz als gelöscht markiert. VACUUM oder AUTO VACUUM ist für die Reinigung der verbleibenden Rückstände verantwortlich.
Django Beispiel
Wir haben jetzt eine Vorstellung davon, wovon Ausfallzeiten abhängen können und wie sie vermieden werden können. Bevor Sie jedoch Wissen anwenden, können Sie sich ansehen, was Django sofort bietet ( https://github.com/django/django/blob/2.1.2/django) /db/backends/base/schema.py und https://github.com/django/django/blob/2.1.2/django/db/backends/postgresql/schema.py ):
| Betrieb |
|---|
| 1 | CREATE SEQUENCE |
| 2 | DROP SEQUENCE |
| 3 | CREATE TABLE |
| 4 | DROP TABLE |
| 5 | ALTER TABLE RENAME TO |
| 6 | ALTER TABLE SET TABLESPACE |
| 7 | ALTER TABLE ADD COLUMN [SET DEFAULT] [SET NOT NULL] [PRIMARY KEY] [UNIQUE] |
| 8 | ALTER TABLE ALTER COLUMN [TYPE] [SET NOT NULL|DROP NOT NULL] [SET DEFAULT|DROP DEFAULT] |
| 9 | ALTER TABLE DROP COLUMN |
| 10 | ALTER TABLE RENAME COLUMN |
| 11 | ALTER TABLE ADD CONSTRAINT CHECK |
| 12 | ALTER TABLE DROP CONSTRAINT CHECK |
| 13 | ALTER TABLE ADD CONSTRAINT FOREIGN KEY |
| 14 | ALTER TABLE DROP CONSTRAINT FOREIGN KEY |
| 15 | ALTER TABLE ADD CONSTRAINT PRIMARY KEY |
| 16 | ALTER TABLE DROP CONSTRAINT PRIMARY KEY |
| 17 | ALTER TABLE ADD CONSTRAINT UNIQUE |
| 18 | ALTER TABLE DROP CONSTRAINT UNIQUE |
| 19 | CREATE INDEX |
| 20 | DROP INDEX |
Django deckt meine Migrationsbedürfnisse sehr gut ab. Jetzt können wir mit unserem Wissen sichere und gefährliche Vorgänge für Migrationen ohne Ausfallzeiten besprechen.
Wir werden sicherere Migrationen mit SHARE UPDATE EXCLUSIVE Locking oder ACCESS EXCLUSIVE , was sofort funktioniert.
Wir werden gefährliche Migrationen mit SHARE und ACCESS EXCLUSIVE Sperren aufrufen, die viel Zeit in ACCESS EXCLUSIVE nehmen.
Ich werde im Voraus einen nützlichen Link zur Dokumentation mit großartigen Beispielen hinterlassen.
Erstellen und löschen Sie eine Tabelle
CREATE SEQUENCE , DROP SEQUENCE , CREATE TABLE , DROP TABLE können als sicher bezeichnet werden, da die Geschäftslogik entweder nicht mehr mit der migrierten Tabelle funktioniert und das Löschen einer Tabelle mit FOREIGN KEY etwas später erfolgt.
Stark unterstützte Arbeitsblattvorgänge
ALTER TABLE RENAME TO - Ich kann es nicht als sicher bezeichnen, da es schwierig ist, eine Logik zu schreiben, die mit einer solchen Tabelle vor und nach der Migration funktioniert.
ALTER TABLE SET TABLESPACE - unsicher, da es die Platte physisch bewegt, und dies kann bei einem großen Volumen lange dauern.
Andererseits sind diese Vorgänge äußerst selten. Alternativ können Sie die Erstellung einer neuen Tabelle und das Kopieren von Daten in diese anbieten.
Spalten erstellen und löschen
ALTER TABLE ADD COLUMN , ALTER TABLE DROP COLUMN - kann als sicher bezeichnet werden (Erstellung ohne DEFAULT / NOT NULL / PRIMARY KEY / UNIQUE), da die Geschäftslogik entweder nicht mit einer migrierten Spalte funktioniert, das Verhalten beim Löschen einer Spalte mit FOREIGN KEY, andere Konstanten und Indizes werden später kommen.
ALTER TABLE ADD COLUMN SET DEFAULT , ALTER TABLE ADD COLUMN SET NOT NULL , ALTER TABLE ADD COLUMN PRIMARY KEY nullbare Spalten und weitere Änderungen.
Es ist erwähnenswert, dass das schnellere SET DEFAULT in Postgres 11 als sicher angesehen werden kann, aber es wird in Django nicht sehr nützlich, da Django SET DEFAULT nur zum Füllen der Spalte verwendet und dann DROP DEFAULT und im Intervall zwischen Migration und Aktualisierung von Maschinen mit erstellt In der Geschäftslogik können Datensätze erstellt werden, in denen keine Standardeinstellungen vorhanden sind, dh die Datenmigration.
Stark unterstützte Vorgänge in einem Arbeitsblatt
ALTER TABLE RENAME COLUMN - Ich kann es auch nicht als sicher bezeichnen, da es schwierig ist, eine Logik zu schreiben, die mit einer solchen Spalte vor und nach der Migration funktioniert. Vielmehr wird dieser Vorgang auch nicht häufig sein, da alternativ vorgeschlagen werden kann, eine neue Spalte zu erstellen und Daten in diese zu kopieren.
Spaltenwechsel
ALTER TABLE ALTER COLUMN TYPE - Der Vorgang kann sowohl gefährlich als auch sicher sein. Sicher, wenn postgres nur das Schema ändert und die Daten bereits im erforderlichen Format gespeichert sind und keine zusätzlichen Typprüfungen erforderlich sind, zum Beispiel:
varchar(LESS) von varchar(LESS) zu varchar(MORE) ;varchar(ANY) von varchar(ANY) zu text ;numeric(LESS, SAME) von numeric(LESS, SAME) zu numeric(MORE, SAME) .
ALTER TABLE ALTER COLUMN SET NOT NULL ist gefährlich, da es die darin enthaltenen Daten durchläuft und nach NULL ALTER TABLE ALTER COLUMN SET NOT NULL Glücklicherweise kann dieses Konstrukt durch ein anderes ersetzt werden. CHECK IS NOT NULL . Es ist erwähnenswert, dass dieser Ersatz zu einem anderen Schema führt, jedoch mit identischen Eigenschaften.
ALTER TABLE ALTER COLUMN DROP NOT NULL , ALTER TABLE ALTER COLUMN SET DEFAULT , ALTER TABLE ALTER COLUMN DROP DEFAULT - sichere Operationen.
Erstellen und Löschen von Indizes und Konstanten
ALTER TABLE ADD CONSTRAINT CHECK und ALTER TABLE ADD CONSTRAINT FOREIGN KEY sind unsichere Vorgänge, können jedoch als NOT VALID und dann als ALTER TABLE VALIDATE CONSTRAINT .
ALTER TABLE ADD CONSTRAINT PRIMARY KEY und ALTER TABLE ADD CONSTRAINT UNIQUE unsicher, da sie einen eindeutigen Index im Inneren erstellen. Sie können jedoch einen eindeutigen Index als CONCURRENTLY erstellen und dann die entsprechende Konstante mithilfe eines vorgefertigten Index über USING INDEX .
CREATE INDEX ist eine unsichere Operation, aber ein Index kann als CONCURRENTLY .
ALTER TABLE DROP CONSTRAINT CHECK , ALTER TABLE DROP CONSTRAINT FOREIGN KEY , ALTER TABLE DROP CONSTRAINT PRIMARY KEY , ALTER TABLE DROP CONSTRAINT UNIQUE , DROP INDEX - sichere Operationen.
Es ist erwähnenswert, dass ALTER TABLE ADD CONSTRAINT FOREIGN KEY und ALTER TABLE DROP CONSTRAINT FOREIGN KEY zwei Tabellen gleichzeitig sperren.
Wissen in Django anwenden
Django hat eine Operation in Migrationen, um SQL auszuführen: https://docs.djangoproject.com/de/2.1/ref/migration-operations/#django.db.migrations.operations.RunSQL . Über diese state_operations können Sie die erforderlichen state_operations und alternative Vorgänge für Migrationen anwenden, wobei Sie state_operations - die Migration, die wir ersetzen.
Dies funktioniert gut für den Code, obwohl zusätzliches Schreiben erforderlich ist. Sie können die Dirty Work jedoch im DB-Backend belassen, z. B. https://github.com/tbicr/django-pg-zero-downtime-migrations/blob/master/django_zero_downtime_migrations_postgres_backend/schema .py sammelt die beschriebenen Vorgehensweisen und ersetzt unsichere Vorgänge durch sichere Gegenstücke. Dies funktioniert für Bibliotheken von Drittanbietern.
Am Ende
Diese Praktiken ermöglichten es mir, ein identisches Schema, das von django erstellt wurde, sofort zu erhalten, mit Ausnahme des Ersetzens des Konstrukts CHECK IS NOT NULL anstelle von NOT NULL und einiger Konstruktnamen (z. B. für ALTER TABLE ADD COLUMN UNIQUE und eine Alternative). Ein weiterer Kompromiss kann die mangelnde Transaktionsfähigkeit für alternative Migrationsvorgänge sein, insbesondere wenn CREATE INDEX CONCURRENTLY und ALTER TABLE VALIDATE CONSTRAINT .
Wenn Sie nicht über postgres hinausgehen, gibt es viele Möglichkeiten, das Datenschema zu ändern, und sie können unter bestimmten Bedingungen in Kombination variiert werden:
- mit jsonb als schamlose lösung
- die Möglichkeit, Ausfallzeiten zu vermeiden
- Anforderung, Migrationen ohne Ausfallzeiten durchzuführen
Auf jeden Fall hoffe ich, dass sich das Material als nützlich erwiesen hat, um entweder die Betriebszeit zu erhöhen oder das Bewusstsein zu erweitern.