
Regressionstests sind ein sehr wichtiger Bestandteil der Arbeit an der Produktqualität. Und je mehr Produkte und je schneller sie sich entwickeln, desto mehr Aufwand ist erforderlich.
Yandex hat gelernt, die manuellen Testaufgaben für die meisten Produkte mithilfe von Assessoren zu skalieren - Remote-Mitarbeiter, die Stück für Stück Teilzeit arbeiten, und jetzt nehmen neben regulären Testern Hunderte von Assessoren an Yandex-Produkttests teil.
Dieser Beitrag sagt:
- Wie haben Sie es geschafft, manuelle Testaufgaben so formal wie möglich zu gestalten und Hunderte von Remote-Mitarbeitern damit zu schulen?
- Wie haben Sie es geschafft, den Prozess auf industrielle Schienen zu bringen, Tests in verschiedenen Umgebungen durchzuführen und SLA in Geschwindigkeit und Qualität standzuhalten?
- Auf welche Schwierigkeiten sie gestoßen sind und wie sie gelöst wurden (und einige haben sich noch nicht entschieden);
- Welchen Beitrag haben Tests von Assessoren zur Entwicklung von Yandex-Produkten geleistet, wie hat sich dies auf die Häufigkeit der Veröffentlichungen und die Anzahl der übersehenen Fehler ausgewirkt?
Der Text basiert auf der Abschrift des
Berichts von
Olga Megorskaya von unserer Piter-Konferenz im Mai Heisenbug 2018:
Ab dem Tag des Berichts konnten sich einige Zahlen ändern. In solchen Fällen haben wir die tatsächlichen Daten in Klammern angegeben. Das Folgende ist eine Perspektive aus der ersten Person:Heute werden wir über die Verwendung von Crowdsourcing-Techniken sprechen, um manuelle Testaufgaben zu skalieren.
Ich habe eine ziemlich seltsame Berufsbezeichnung: Leiter der Abteilung für Expertenbewertungen. Ich werde versuchen, anhand von Beispielen zu erzählen, was ich tue. In Yandex habe ich zwei Hauptverantwortungsbereiche:

Einerseits hängt dies alles mit Crowdsourcing zusammen. Ich bin verantwortlich für unsere Crowdsourcing-Plattform Yandex.Tolok.
Auf der anderen Seite können Teams, die, wenn Sie versuchen, eine universelle Definition zu geben, "massiven unproduktiven Stellenangeboten" zugeordnet werden. Es beinhaltet viele verschiedene Dinge, einschließlich eines unserer jüngsten Projekte: manuelle Tests mit Hilfe von Menschenmengen, die wir als „Tests durch Prüfer“ bezeichnen.
Meine Haupttätigkeit bei Yandex besteht darin, die linke und rechte Spalte des Bildes zusammenzuführen und zu versuchen, Aufgaben und Prozesse in der Massenproduktion mithilfe von Crowdsourcing zu optimieren. Und heute werden wir nur am Beispiel von Testaufgaben darüber sprechen.
Was ist Crowdsourcing?
Beginnen wir mit Crowdsourcing. Wir können sagen, dass dies ein Ersatz für das Fachwissen eines bestimmten Spezialisten durch die sogenannte „Weisheit der Masse“ in den Fällen ist, in denen das Fachwissen eines Spezialisten entweder sehr teuer oder schwer skalierbar ist.
Crowdsourcing wird seit vielen Jahren in verschiedenen Bereichen aktiv eingesetzt. Zum Beispiel mag die NASA Crowdsourcing-Projekte sehr. Dort erforschen und entdecken sie mit Hilfe der „Menge“ neue Objekte in der Galaxie. Dies scheint eine sehr schwierige Aufgabe zu sein, aber mit Hilfe von Crowdsourcing kommt es auf eine ziemlich einfache an. Es gibt eine
spezielle Website, auf der Hunderttausende von Fotos veröffentlicht werden, die mit Weltraumteleskopen aufgenommen wurden, und die jeden fragen, der dort nach bestimmten Objekten suchen möchte. Und wenn viele Leute das Objekt, das sie benötigen, verdächtig ähnlich finden, sind übergeordnete Spezialisten bereits verbunden und beginnen, es zu erkunden.
Im Allgemeinen ist Crowdsourcing eine solche Methode, wenn wir eine große Aufgabe auf hoher Ebene in viele einfache und homogene Unteraufgaben aufteilen, in denen sich viele unabhängige Künstler versammeln. Jeder der Darsteller kann eine oder mehrere dieser kleinen Aufgaben lösen, und alle zusammen arbeiten sie letztendlich für eine große gemeinsame Sache und sammeln großartige Ergebnisse für eine hochrangige Aufgabe.
Yandex Crowdsourcing
Wir haben bereits mehrere Jahre mit der Entwicklung unseres Crowdsourcing-Systems begonnen. Ursprünglich wurde es für Aufgaben im Zusammenhang mit maschinellem Lernen verwendet: zum Sammeln von Trainingsdaten, zum Konfigurieren neuronaler Netze, Suchalgorithmen usw.
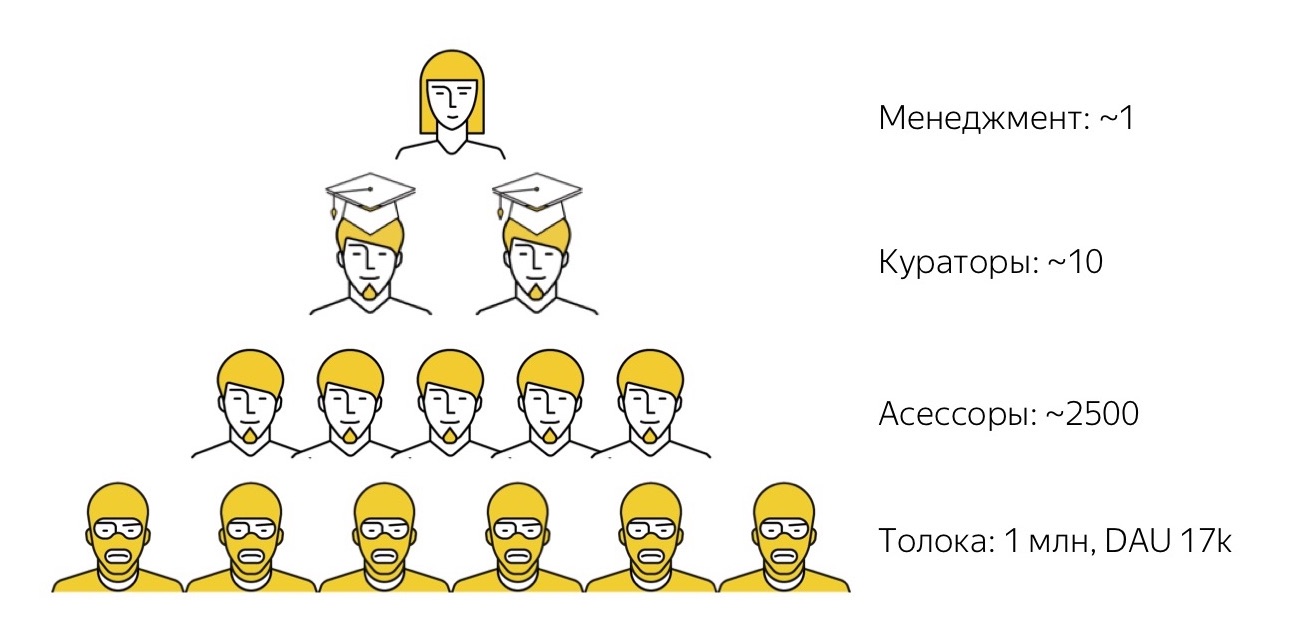
Wie funktioniert unser Crowdsourcing-Ökosystem? Erstens haben wir
Yandex.Toloka . Dies ist eine offene Crowdsourcing-Plattform, auf der sich jeder entweder als Kunde (Posten seiner Aufgaben, Festlegen eines Preises und Sammeln von Daten) oder als Ausführender (Finden interessanter Aufgaben, Erledigen und Erhalten einer kleinen Belohnung) registrieren kann. Wir haben die Decke vor einigen Jahren eingeführt. Jetzt haben wir mehr als eine Million registrierte Künstler (wir nennen sie Tokers), und jeden Tag erledigen im System etwa 17.000 Menschen Aufgaben.
Seit wir den Toloka ursprünglich mit Blick auf Aufgaben im Zusammenhang mit maschinellem Lernen erstellt haben, war es traditionell üblich, dass die meisten Aufgaben, die von Tolokern ausgeführt werden, Aufgaben sind, die für eine Person sehr einfach und trivial sind, für den Algorithmus jedoch immer noch recht schwierig. Schauen Sie sich beispielsweise ein Foto an und sagen Sie, ob es Inhalte für Erwachsene enthält oder nicht, oder hören Sie sich eine Audioaufnahme an und entschlüsseln Sie das, was Sie gehört haben.
Toloka ist ein sehr leistungsfähiges Tool in Bezug auf Leistung und Datenmenge, das beim Sammeln hilft, aber nicht trivial zu verwenden ist. Die Personen auf dem Bild tragen eine gelbe Sturmhaube, da alle Darsteller in Tolok anonym und den Kunden unbekannt sind. Und diese Tausenden von Anonymus zu verwalten, um sicherzustellen, dass sie genau das tun, was Sie brauchen, ist keine leichte Aufgabe. Daher können wir nicht alle Aufgaben, die wir bisher haben, mit Hilfe dieser absolut „wilden“ Menge lösen. Obwohl wir danach streben, werde ich später mehr dazu sagen.
Daher haben wir für übergeordnete Aufgaben die nächste Stufe von Darstellern. Dies sind die Personen, die wir als Prüfer bezeichnen. Das Wort "Gutachter" mag etwas seltsam sein. Es kam vom Wort "Bewertung", dh "Bewertung", weil ursprünglich Bewerter bei uns verwendet wurden, um subjektive Bewertungen der Qualität der Suchergebnisse zu sammeln. Diese Daten wurden dann als Ziel für das maschinelle Lernen der Suchrangfunktion verwendet. Seitdem ist viel Zeit vergangen, und die Prüfer haben begonnen, viele verschiedene andere Aufgaben auszuführen. Jetzt ist dies ein Haushaltswort: Die Aufgaben haben sich geändert, aber das Wort bleibt.
Unsere Gutachter sind Vollzeitmitarbeiter von Yandex, arbeiten jedoch in Teilzeit und vollständig aus der Ferne. Das sind Leute, die an ihrer eigenen Ausrüstung arbeiten. Wir interagieren nur aus der Ferne mit ihnen: Wir wählen sie aus der Ferne aus, trainieren sie aus der Ferne, arbeiten aus der Ferne mit ihnen und feuern sie gegebenenfalls aus der Ferne ab. Bei den meisten von ihnen überschneiden wir uns nie persönlich im Leben. Sie arbeiten nach jedem für sie geeigneten Zeitplan, Tag und Nacht: Sie haben Mindeststandards, die etwa 10 bis 15 Stunden pro Woche entsprechen, und sie können diese Zeit auf eine Weise trainieren, die zu ihnen passt. Assessoren lösen eine Vielzahl von Problemen: Sie sind mit der Suche, dem technischen Support, einigen Übersetzungen auf niedriger Ebene und mit Tests verbunden, über die wir später sprechen werden.
Unabhängig davon, welche Aufgabe wir übernehmen, heben sich die talentiertesten Mitarbeiter in der Regel immer von der Gruppe der Prüfer ab, die sie besser ausführen und für die diese Aufgabe interessanter ist. Wir wählen sie aus, verleihen ihnen den lauten Titel eines Super-Sprechers, und diese Leute üben bereits übergeordnete Funktionen von Kuratoren aus: Sie überprüfen die Qualität der Arbeit anderer Menschen, beraten sie, unterstützen sie und so weiter.
Und nur ganz oben in unserer Pyramide haben wir den ersten Vollzeitmitarbeiter, der im Büro sitzt und diese Prozesse verwaltet. Wir haben viel weniger solche Leute, die bereits auf einem viel höheren Niveau sind und über starke technische und Managementfähigkeiten verfügen, buchstäblich nur wenige. Ein solches System lässt uns zu dem Schluss kommen, dass diese Einheiten von "hochrangigen" Mitarbeitern Pipelines bauen und Produktionsketten verwalten, an denen Zehntausende, Hunderte und sogar Tausende von Personen beteiligt sind.
An sich ist dieses Schema nicht neu, doch Dschingis Khan hat es erfolgreich angewendet. Sie hat einige interessante Eigenschaften, die wir nutzen wollen. Die erste Eigenschaft ist durchaus verständlich - ein solches Schema ist sehr einfach zu skalieren. Wenn eine Aufgabe plötzlich anfangen muss, mehr zu tun, müssen wir nicht nach zusätzlichem Platz im Büro suchen, um irgendwo eine Person zu pflanzen. Im Allgemeinen können wir sehr wenig darüber nachdenken, was: einfach mehr Geld einschenken, mehr Künstler für dieses Geld einstellen, und talentiertere Leute in akademischen Kappen werden wahrscheinlich aus diesen Künstlern herauswachsen, und dieses ganze System wird weiter skalieren.
Die zweite Eigenschaft (und es war für mich überraschend) ist, dass eine solche Pyramide unabhängig vom Themenbereich, in dem sie angewendet wird, sehr gut nachgebildet wird. Dies gilt auch für den Bereich, über den wir heute sprechen werden - manuelle Testaufgaben.
Crowd Testing
Als wir den Testprozess mit Hilfe von Menschenmengen starteten, war das größte Problem das Fehlen einer positiven Referenz. Es gab keine Erfahrung, auf die wir uns beziehen und sagen konnten: "Nun, diese Jungs haben das getan, sie testen bereits mit Hilfe von Menschenmengen in einer uns sehr ähnlichen Rennstrecke, und dort ist alles in Ordnung, was bedeutet, dass bei uns alles in Ordnung sein wird." Daher mussten wir uns nur auf unsere persönlichen Erfahrungen verlassen, die vom Testbereich getrennt waren und sich eher auf die Einrichtung ähnlicher Produktionsprozesse bezogen, aber auf andere Bereiche.
Deshalb mussten wir tun, was wir können. Was können wir tun? Im Wesentlichen zerlegen Sie eine Aufgabe in Aufgaben mit unterschiedlichen Schwierigkeitsgraden und verteilen sie auf den Böden unserer Pyramide. Mal sehen, was wir haben.
Zuerst haben wir uns die Aufgaben angesehen, mit denen unsere Tester in Yandex beschäftigt sind, und sie gebeten, diese Aufgaben unter verschiedenen Schwierigkeitsgraden bedingt zu verteilen. Dies ist ein "Krankenhausdurchschnitt":
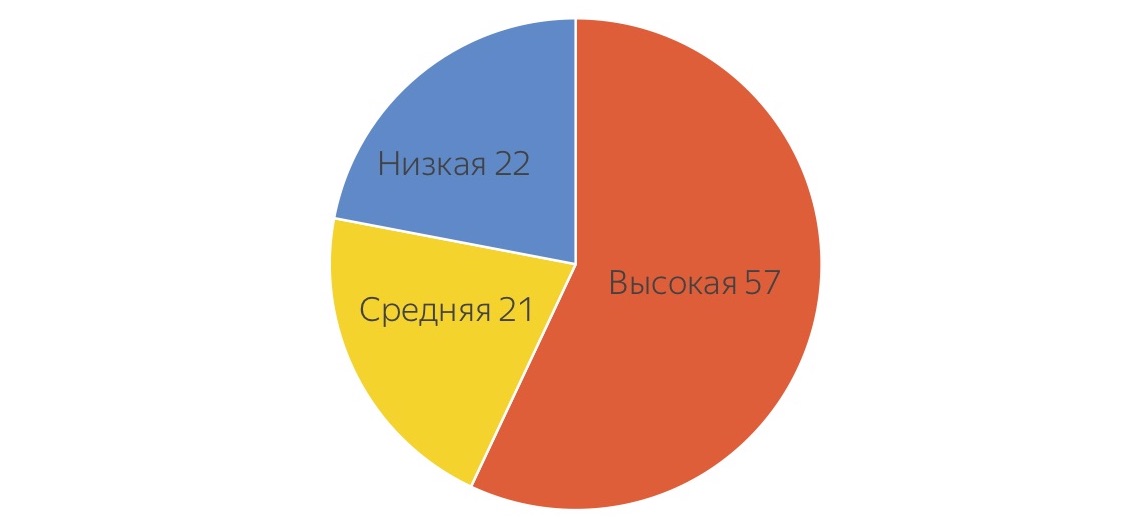
Sie schätzten, dass nur 57% ihrer Zeit für komplexe Aufgaben auf hoher Ebene aufgewendet werden, und etwa 20% für eine Routine auf sehr niedriger Ebene, die jeder loswerden möchte, und für etwas kompliziertere Aufgaben, die auch delegiert werden können. Von diesen Zahlen ermutigt, die zeigen, dass fast die Hälfte der Arbeit irgendwohin übertragen werden kann, haben wir Tests mit Menschenmengen erstellt.
Was sind unsere Ziele?
- Machen Sie das Testen nicht mehr zu dem Engpass, der regelmäßig in Produktionsprozessen aufgetreten ist, wenn die Veröffentlichung fertig ist, sondern warten Sie, bis die Tests bestanden sind.
- Entlasten Sie unsere coolen, sehr intelligenten, hochrangigen Spezialisten - Vollzeit-Tester - von der Routine und beschäftigen Sie sie mit wirklich interessanten und übergeordneten Aufgaben.
- Verbessern Sie die Vielfalt der Umgebungen, in denen wir Produkte testen.
- Lernen, mit Spitzenlasten umzugehen, weil unsere Tester sagten, dass sie oft ungleichmäßige Lasten haben. Selbst wenn ein Team im Durchschnitt Aufgaben erledigt, dauert es sehr lange, bis ein Spitzenwert erreicht ist.
- Da wir in Yandex in einigen Projekten immer noch einiges Geld für das Outsourcing von Tests ausgegeben haben, dachten wir, wir möchten ein bisschen mehr Ergebnisse für unser Geld erzielen, um unsere Outsourcing-Kosten zu optimieren.
Ich möchte betonen, dass es unter diesen Zielen keine Aufgabe gibt, Tester durch Menschenmengen zu ersetzen, sie irgendwie zu verletzen und so weiter. Alles, was wir tun wollten, war den Testteams zu helfen und die Routine auf niedriger Ebene zu eliminieren.
Mal sehen, was wir daraus gemacht haben. Ich werde gleich sagen, dass die Hauptaufgaben des Testens jetzt nicht mehr von der untersten Ebene der „Pyramide“, sondern von den Tolkern, sondern von den Gutachtern, unseren Vollzeitbeschäftigten, ausgeführt werden. Weiter werden wir hauptsächlich über sie diskutieren, bis auf das Ende.
Die Prüfer führen jetzt die Aufgaben der Regressionstests für uns durch und führen alle Arten von Umfragen durch, z. B. „Sehen Sie sich diese Anwendung an und hinterlassen Sie Ihr Feedback“. Mittlerweile sind rund 300 Personen für die vollwertige Regressaufgabe qualifiziert (
Hinweis: seit der Bericht 500 geworden ist ). Diese Zahl ist jedoch bedingt, da das von uns erstellte System für eine beliebige Anzahl von Personen funktioniert: so viel, wie wir brauchen. Jetzt wird unser Produktionsbedarf von ungefähr so vielen Menschen gedeckt. Dies bedeutet nicht, dass zu jedem Zeitpunkt alle bereit und bereit sind, die Aufgabe auszuführen: Da die Prüfer nach einem flexiblen Zeitplan arbeiten, sind jederzeit 100 bis 150 Personen bereit, eine Verbindung herzustellen. Aber der Pool der Darsteller ist ungefähr gleich. Und einfache Aufgaben wie Umfragen, bei denen Sie nur informelles Feedback von Benutzern einholen müssen, führen viel mehr Menschen durch: Hunderte und Tausende von Prüfern nehmen an solchen Umfragen teil.
Da es sich um Personen handelt, die an ihrer eigenen Ausrüstung arbeiten, verfügt jeder Prüfer über seine eigenen persönlichen Geräte. Dies ist standardmäßig ein Desktop und eine Art mobiles Gerät. Dementsprechend testen wir unsere Produkte auf persönlichen Geräten von Gutachtern. Es ist jedoch klar, dass sie nicht über alle möglichen Geräte verfügen. Wenn wir also in einer seltenen Umgebung testen müssen, verwenden wir den Remotezugriff über die Gerätefarm.
Jetzt werden Crowd-Tests bereits als Standardproduktionsprozess für etwa 40 (
Anmerkung: jetzt 60 ) Yandex-Dienste und -Teams verwendet: Dies sind Mail, Disk und Browser (mobil und Desktop) sowie Maps und Search und viele, viele wer. Das ist merkwürdig. Als wir uns für das Ende des dritten Quartals im Herbst 2017 Pläne machten, hatten wir ein ehrgeiziges Ziel: Zumindest fünf Teams, die unsere Testprozesse mit Hilfe von Menschenmengen nutzen würden, „irgendwie durch Betrug, sogar durch Bestechung“ anzuziehen. Und wir haben alle sehr überzeugt und gesagt: "Hab keine Angst, komm schon, probier es aus!" Aber schon nach wenigen Monaten hatten wir Dutzende von Teams.
Und jetzt lösen wir ein weiteres Problem: Wie schaffen wir es, immer mehr neue Teams zu verbinden, die sich diesen Prozessen anschließen möchten? Wir können also davon ausgehen, dass dies in Yandex bereits Standard ist, was sehr gut funktioniert.
Was haben wir in Bezug auf Produktionsindikatoren getan? Derzeit führen wir täglich etwa 3.000 Fälle von Regressionstests durch (
Hinweis: Ab
Oktober 2018 gibt es bereits 7.000 Fälle ). Die Testläufe dauern je nach Größe mehrere Stunden bis (zu Spitzenzeiten) 2 Tage. Die meisten Pässe in wenigen Stunden, innerhalb eines Tages. Durch die Einführung eines solchen Systems konnten wir die Kosten gegenüber dem Zeitraum, in dem wir Outsourcing eingesetzt haben, um etwa 30% senken. Dies ermöglichte es den Teams, im Durchschnitt viel öfter mehrmals zu veröffentlichen, da die Veröffentlichungen mit der Geschwindigkeit zu vergehen begannen, die für die Entwicklung verfügbar war, und nicht mit der Geschwindigkeit, die zum Testen zur Verfügung stand, als es manchmal zu einem Engpass kam.
Jetzt werde ich versuchen zu erzählen, wie wir den Produktionsprozess im Allgemeinen aufgebaut haben, wodurch wir zu diesem Schema gekommen sind.
Die Infrastruktur
Beginnen wir mit der technischen Infrastruktur. Diejenigen unter Ihnen, die Toloka als Plattform gesehen haben, stellen sich vor, wie die Benutzeroberfläche aussieht: Sie können sich beim System anmelden, Aufgaben auswählen, die Sie interessieren, und diese ausführen. Für interne Mitarbeiter haben wir eine interne Instanz von Toloka, in der wir unter anderem Aufgaben verschiedener Art für unsere Prüfer verteilen.
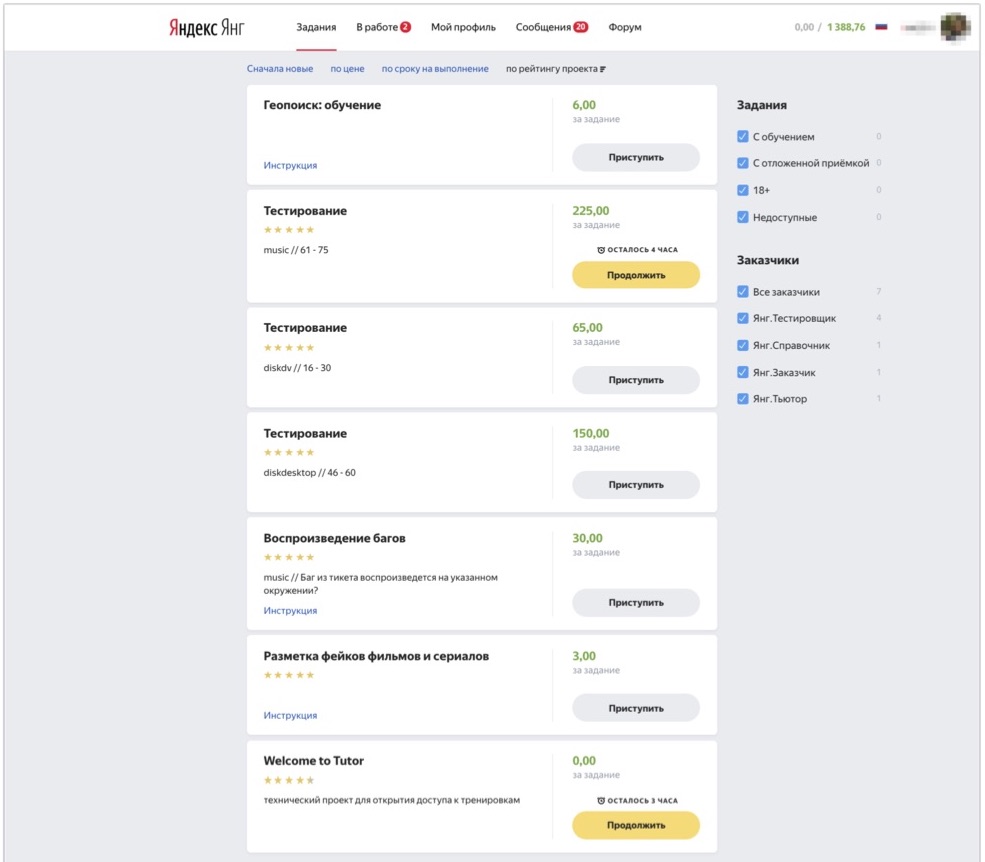
Das Bild zeigt, wie diese Schnittstelle aussieht. Hier sehen Sie die Aufgaben, die dem Prüfer zur Verfügung stehen: Hier gibt es mehrere Aufgaben zum Testen und mehrere Aufgaben eines anderen Typs, die der Prüfer aus diesem Beispiel auch ausführen kann. Und so kommt die Person, sieht die Aufgaben, die ihr gerade zur Verfügung stehen, klickt auf „Weiter“, erhält Testfälle zur Analyse und beginnt mit deren Ausführung.
Ein wichtiger Teil unserer Infrastruktur sind landwirtschaftliche Betriebe. Nicht alle Geräte sind verfügbar, daher handelt es sich in der Tat um ein Paar: einen Testfall und die Umgebung, in der Sie ihn überprüfen müssen. Wenn eine Person auf die Schaltfläche Weiter klickt, prüft das System, ob sie eine Umgebung zum Testen hat. Wenn ja, nimmt die Person die Aufgabe einfach an und testet sie auf einem persönlichen Gerät. Wenn nicht, senden wir es über den Fernzugriff auf die Farm.
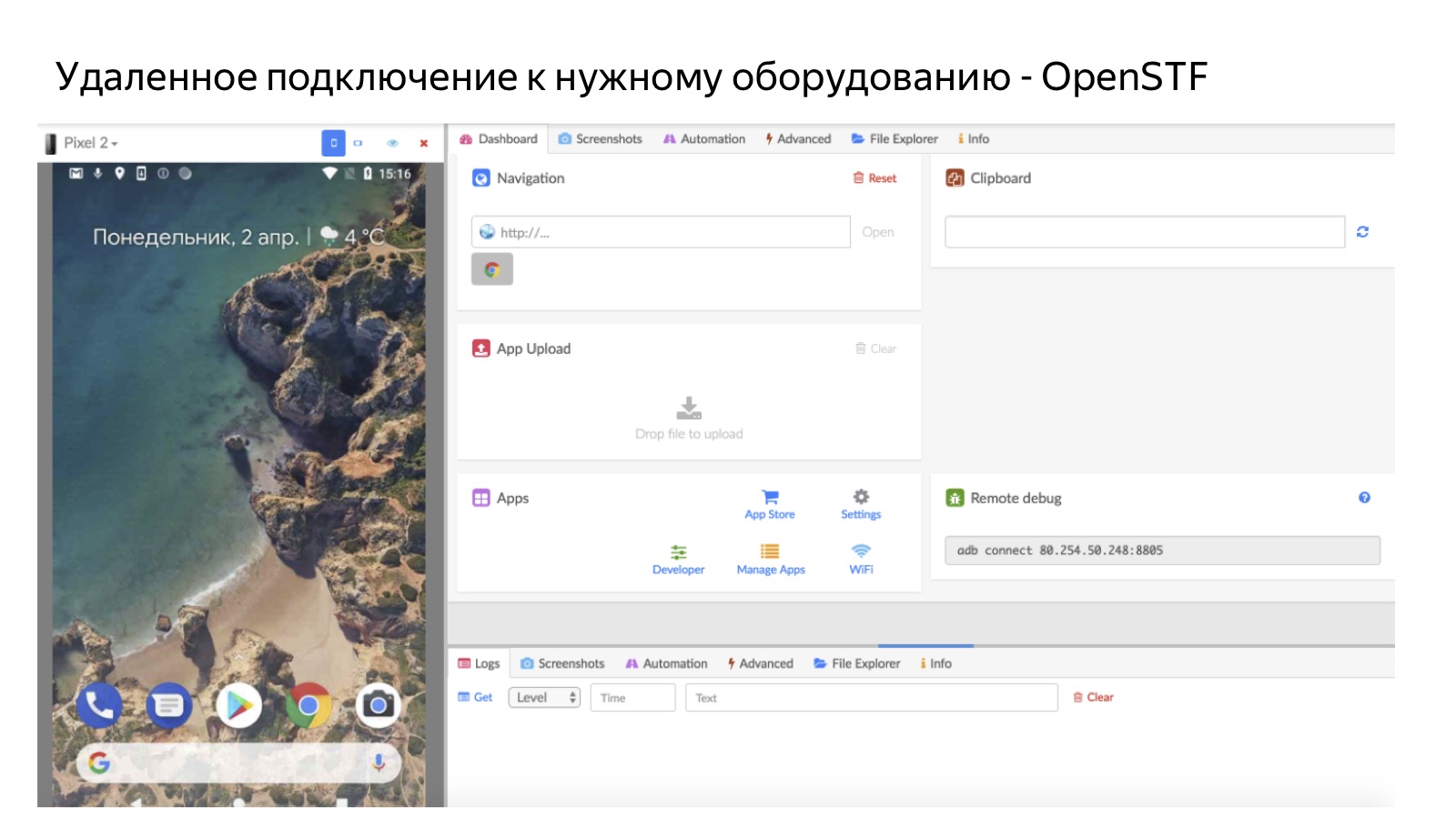
Das Bild zeigt am Beispiel einer mobilen Farm, wie es aussieht. Eine Person stellt also eine Remoteverbindung zu einem Mobiltelefon her, das in unserem Büro auf dem Bauernhof liegt. Für Android verwenden wir OpenSTF Open Source-Lösungen. Es gibt keine guten Lösungen für iOS - in dem Maße, wie wir es bereits selbst gemacht haben (aber wir werden das nächste Mal im Detail darüber sprechen), weil wir weder Open Source noch etwas finden konnten, dessen Kauf sinnvoll wäre. Es ist klar, dass die Farm in Fällen nützlich ist, in denen wir keine Leute haben, die die richtigen Geräte haben. Ein weiteres wichtiges Plus ist, dass die Farm eine sehr hohe Auslastung aufweist: Wann und egal welche Person hereinkommt, können wir sie jederzeit an die Farm senden. Dies ist besser als das persönliche Verteilen von Geräten, da Geräte, die an eine Person übergeben werden, nur dann für die Arbeit verfügbar sind, wenn diese Person bereit ist, zu arbeiten.
Wir haben ein wenig darüber gesprochen, wie es aus technischer Sicht für unsere Prüfer umgesetzt wurde, und jetzt der für mich interessanteste Teil: die Prinzipien, wie wir diese Produktion organisiert haben.
Die Prinzipien der Organisation der Produktion in der Menge
Für mich in diesem Projekt war es interessant, dass der Themenbereich sehr spezifisch zu sein scheint, aber alle Prinzipien der Organisation der Produktion sind ziemlich universell: die gleichen, die bei der Organisation der Massenproduktion in anderen Themenbereichen verwendet werden.
1. Formalisierung
Das erste Prinzip (nicht das wichtigste, aber eines der wichtigsten, einer unserer „Wale, Elefanten und Schildkröten“) ist die Formalisierung von Aufgaben. Ich denke, Sie alle wissen das alleine. Fast jede Aufgabe ist am einfachsten selbst zu erledigen. Es ist etwas schwieriger, Ihrem Kollegen, der neben Ihnen im Raum sitzt, zu erklären, dass er genau das tut, was Sie brauchen. Und die Aufgabe besteht darin, sicherzustellen, dass Hunderte von Künstlern, die Sie noch nie gesehen haben und die zu einem beliebigen Zeitpunkt remote arbeiten, genau das tun, was Sie von ihnen erwarten - diese Aufgabe ist um mehrere Größenordnungen komplizierter und impliziert eine ziemlich hohe Eintrittsschwelle um dies überhaupt zu tun. Im Zusammenhang mit Testaufgaben ist die Aufgabe bei uns natürlich ein Testfall, der bestanden und verarbeitet werden muss.
Und welche Testfälle sollten es sein, um sie bei Aufgaben wie Crowd-Tests einsetzen zu können?
Erstens - und es stellte sich heraus, dass dies überhaupt keine Tatsache ist - sollten Testfälle im Allgemeinen vorliegen. , , , : «, -, !» , , . , , , . - , , -. , .
, - , , . , , , . - , .
: , , , .
.
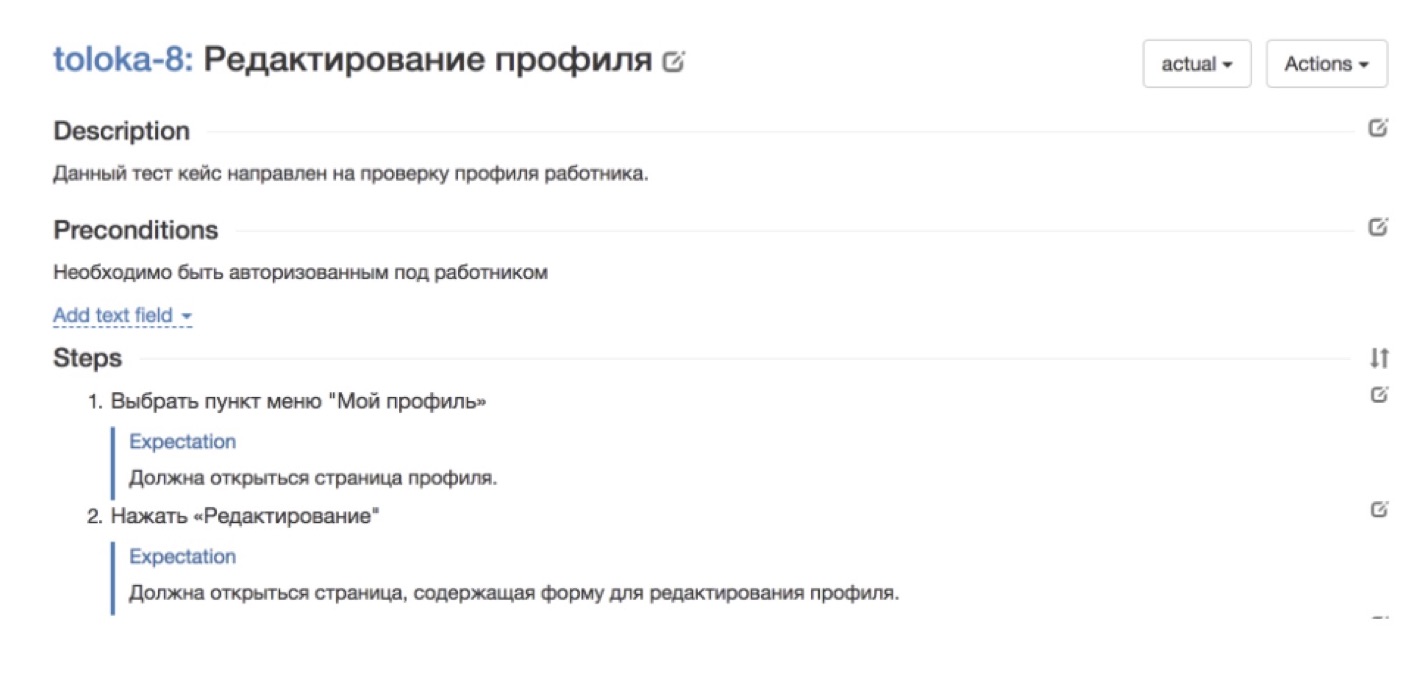
, , , . . , . , . .
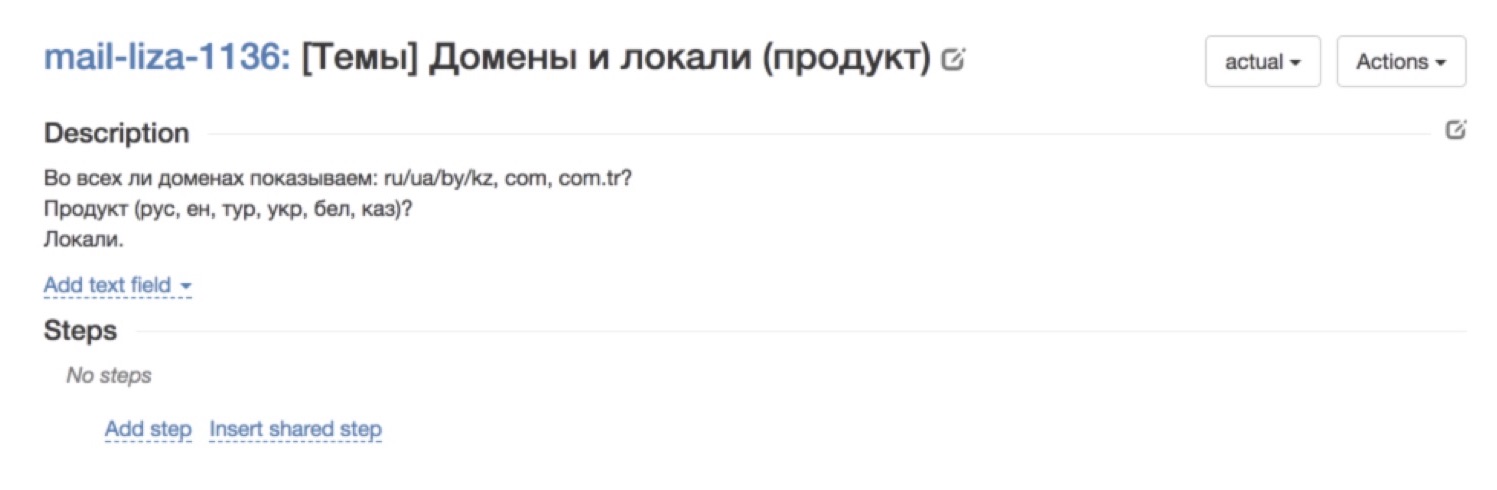
. , . , — , ? — , .
-, , -, , , , -, ?
:
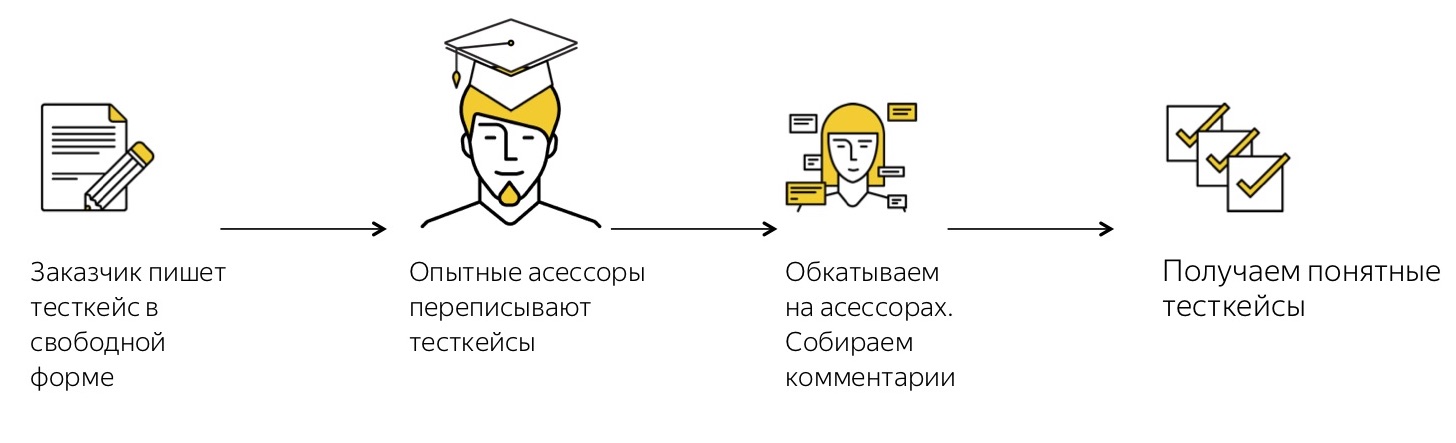
, - , , , -, .
-, -. , ? , - , , -, .
: . , , -, . , . , -, , . — , — . , , , , , , -. , -, .
side effect. -, , killer feature. : « , -?» , . , — - . , , , - . , , , -.
.

- , : , description, « » .
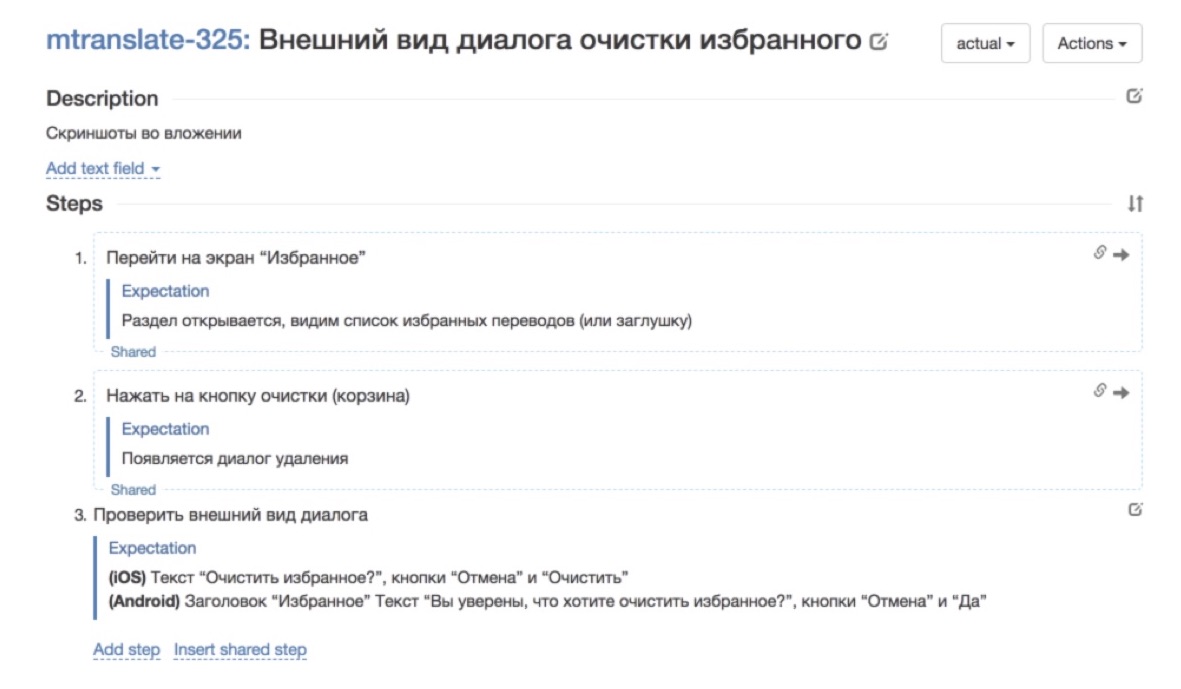
, — . . - .
2.
Die nächste Aufgabe ist meine Lieblingsaufgabe, die mir am kreativsten erscheint. Dies ist eine skalierbare Lernaufgabe. Damit wir mit solchen Zahlen arbeiten können - „hier haben wir 200 Prüfer, hier sind 1.000, und hier arbeiten im Allgemeinen täglich 17.000 Token“ - ist es wichtig, Menschen schnell und skalierbar ausbilden zu können.
Es ist sehr wichtig, zu einem solchen System zu kommen, wenn Sie nicht mehr Zeit für die Ausbildung einer beliebigen Anzahl von Personen als für die Ausbildung eines bestimmten Spezialisten aufwenden. Dies ist zum Beispiel bei der Arbeit mit Outsourcing der Fall. Die Spezialisten sind sehr cool, aber um sie in den Kontext der Arbeit einzutauchen, hat der Service viel Zeit in Anspruch genommen, und am Ausgang haben wir immer noch eine Person, die sechs Monate lang in den Kontext eingetaucht ist. Und das ist so ein sehr skalierbares Schema. Es stellt sich heraus, dass jede nächste Person für weitere sechs Monate in den Kontext der Aufgabe eingetaucht werden muss. Und es war notwendig, diesen Engpass zu vergrößern.
Für alle offenen Stellen, nicht nur für Tests, rekrutieren wir Mitarbeiter über mehrere Kanäle. Zum Testen machen wir das. Erstens ziehen wir Leute an, die im Prinzip an Testaufgaben interessiert sind, Leute irgendwo auf der Ebene der Junior-Tester. Für sie ist dies ein guter Anfang, ein Eintauchen in das Fachgebiet. Aber es gibt immer noch eine begrenzte Anzahl solcher Leute auf dem Markt, und wir brauchen keine Einschränkungen bei der Einstellung von Leuten, damit wir uns nie auf die Anzahl der Künstler ausruhen.
Daher suchen wir nicht nur Tester speziell für diese Aufgaben, sondern führen auch eine Reihe von Personen durch, die lediglich auf die allgemeine Position des Prüfers reagiert haben. Wir fördern diesen Ansatz: Unabhängig davon, welche Personen Sie nehmen, wenn es viele von ihnen gibt, können Sie einen Prozess erstellen, in dem Sie die fähigsten auswählen und sie anweisen, das von Ihnen verfolgte Problem zu lösen. Im Rahmen des Testens bauen wir Schulungen auf, damit beliebige Personen, die noch nicht einmal etwas über das Testen wussten, zumindest die Mindestgrundlagen vermitteln können, damit sie anfangen, etwas zu verstehen. Dank dieses Ansatzes kommt es nie zu einem Mangel an Darstellern und der Anzahl der Mitarbeiter, die für uns bei diesen Aufgaben arbeiten. Es kommt darauf an, wie viel Geld wir bereit sind, dafür auszugeben.
Ich weiß nicht, wie oft Sie auf dieses Thema stoßen, aber in allen populärwissenschaftlichen Artikeln, insbesondere über maschinelles Lernen und neuronale Netze, wird oft geschrieben, dass maschinelles Lernen dem menschlichen Training sehr ähnlich ist. Wir zeigen dem Kind 10 Karten mit dem Bild des Balls und zum 11. Mal wird es verstehen und sagen: „Oh! Das ist ein Ball! " Tatsächlich funktionieren auch Computer Vision und andere Technologien für maschinelles Lernen im Wesentlichen.
Ich möchte über die gegenteilige Situation sprechen: Das Trainieren von Menschen kann auf die gleiche formale Weise wie das Trainieren von Maschinen aufgebaut werden. Was brauchen wir dafür? Wir brauchen ein Trainingsset - ein Set vormarkierter Beispiele, an denen eine Person geschult wird. Wir brauchen ein Kontrollset, mit dem wir überprüfen können, ob er gut gelernt hat oder nicht. Wie beim maschinellen Lernen benötigen Sie einen Testsatz, an dem wir verstehen, wie unsere Funktion im Allgemeinen funktioniert. Und wir brauchen eine formale Metrik, die die Qualität der geleisteten Arbeit misst. Auf diesen Prinzipien haben wir Schulungen für die Aufgaben der einfachsten Regressionstests aufgebaut.
Das Bild zeigt, wie dieses Training bei uns aussieht. Es besteht aus mehreren Teilen. Zuerst gibt es eine Theorie, dann eine Praxis, und dann findet eine Prüfung statt, bei der wir prüfen, ob eine Person die Essenz des Problems verstanden hat oder nicht.
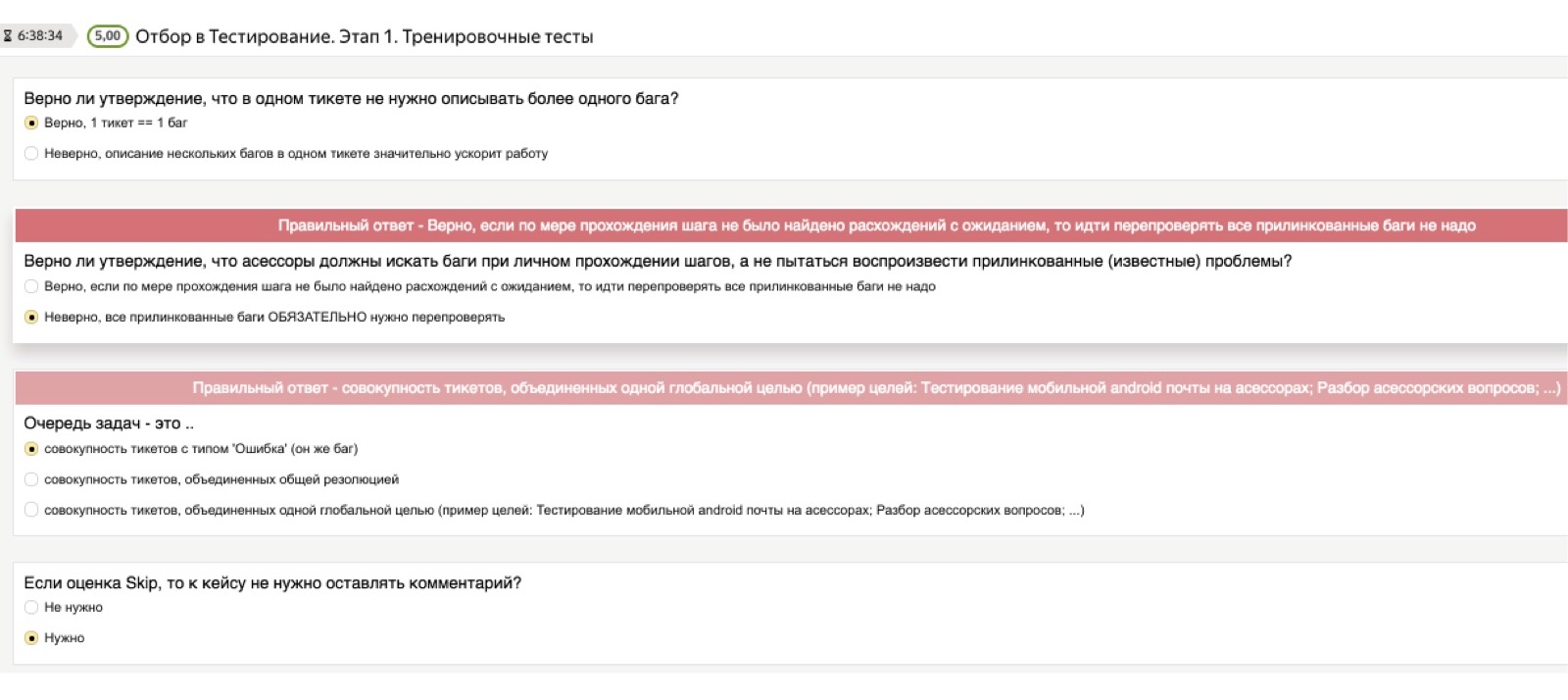
Beginnen wir mit der Theorie. Es ist klar, dass wir für jede Aufgabe, die der Prüfer ausführt, eine große, gewichtige, vollwertige Anweisung mit einer großen Anzahl von Beispielen haben, in der alles sehr detailliert beschrieben wird. Aber niemand liest es.
Um zu überprüfen, ob sich das theoretische Wissen tatsächlich im Kopf einer Person niedergelassen hat, geben wir immer Zugang zu Anweisungen, verwenden danach jedoch einen so genannten „theoretischen Test“. Dies ist ein solcher Test, bei dem wir wichtige Fragen für uns und die richtigen Antworten vorab laden. Fragen können die dümmsten sein. Ich denke, dass dies für Sie komische Beispiele sein werden, aber für Menschen, die zum ersten Mal in ihrem Leben mit Testaufgaben konfrontiert sind, sind dies überhaupt keine offensichtlichen Dinge. Zum Beispiel: "Wenn ich mehrere Fehler festgestellt habe, muss ich mehrere Tickets starten - eines für jeden Fehler - oder alles auf einen Stapel werfen?" Oder: "Was ist, wenn ich einen Screenshot machen möchte, der Screenshot jedoch bei mir nicht funktioniert?"
Dies können sehr unterschiedliche, willkürlich niedrige Fragen sein, und es ist für uns wichtig, dass eine Person sie im Stadium des Studiums der Theorie unabhängig durcharbeitet. Daher besteht der theoretische Test aus Fragen dieser Art: "Ich habe mehrere Fehler gefunden, sollte ich ein Ticket oder mehrere haben?" Wenn eine Person die falsche Antwort wählt, fällt ein roter Würfel heraus, der sagt: "Nein, warte, die richtige Antwort ist anders, achte darauf." Selbst wenn eine Person die Anweisungen nicht gelesen hat, kann sie diesen Test nicht bestehen.

Der nächste Punkt ist die Übung. Wie kann sichergestellt werden, dass Personen, die überhaupt nichts über das Testen wussten und nicht speziell auf die Vakanz des Testers reagierten, verstanden, was als Nächstes zu tun ist? Hier kommen wir zu genau diesem Trainingsset. Ich denke, dass Sie sofort eine große Anzahl von Fehlern finden werden, die auf diesem Bild zu sehen sind. So sieht die Trainingsaufgabe für den Assessor aus: Hier ist ein Screenshot vor Ihnen, in dem Sie alle Fehler finden. Was ist hier falsch? Der Rechner ragt heraus. Was sonst? Layout ging.

Oder hier ist ein komplexeres Beispiel mit einem Sternchen. Die Mailbox des Hauptempfängers ist offen, ich bin derjenige, an den dieser Brief gesendet wurde. Also sehe ich so ein Bild vor mir. Was ist der Fehler hier? Das größte Problem hierbei ist, dass eine Blindkopie angezeigt wird und ich als Empfänger des Briefes sehe, wer es in der Blindkopie war.
Nach ein paar Dutzend solcher Beispiele beginnt bereits eine Person, die unendlich weit vom Testen entfernt ist, zu verstehen, was es ist und was von ihr weiter verlangt wird, wenn sie Testfälle besteht. Der praktische Teil besteht aus einer Reihe von Beispielen, in denen wir bereits Fehler kennen. Wir bitten die Person, sie zu finden, und am Ende zeigen wir ihr: „Schau, der Fehler war hier“, damit er seine Vermutungen mit unseren richtigen Antworten korreliert.
Und der letzte Teil ist das, was wir eine Prüfung nennen. Wir haben eine spezielle Testanordnung, deren Fehler uns bereits bekannt sind, und wir bitten die Person, diese durchzugehen. Hier zeigen wir ihm nicht mehr die richtigen und falschen Antworten, sondern schauen uns nur an, was er finden konnte.
Das Schöne an diesem System und seiner Skalierbarkeit liegt darin, dass alle diese Prozesse ohne Beteiligung eines Managers absolut autonom ablaufen. Wir führen so viele Leute, wie Sie möchten: Jeder, der die Anweisungen lesen möchte, jeder, der den theoretischen Test ablegen möchte, jeder, der die Übung ablegen möchte - all dies geschieht automatisch auf Knopfdruck, und wir haben überhaupt keine Bedenken.
Der letzte Teil - die Prüfung - wird auch von allen bestanden, die es wollen, und schließlich beginnen wir, sie sorgfältig zu betrachten. Da es sich um eine Testanordnung handelt und wir alle Fehler im Voraus kennen, können wir automatisch bestimmen, wie viel Prozent der Fehler eine Person gefunden hat. Wenn es sehr niedrig ist, dann schauen wir nicht weiter, wir schreiben einen automatischen Beat: "Vielen Dank für Ihre Bemühungen!" - und dieser Person keinen Zugang zu Kampfmissionen gewähren. Wenn wir sehen, dass fast alle Fehler gefunden wurden, verbindet sich in diesem Moment bereits eine Person, die prüft, wie korrekt Tickets ausgestellt wurden, wie viel alles gemäß dem Verfahren aus Sicht unserer Anweisungen korrekt ausgeführt wurde.
Wenn wir sehen, dass eine Person sowohl Theorie als auch Praxis unabhängig beherrscht und die Prüfung gut bestanden hat, lassen wir diese Personen in unsere Produktionsprozesse ein. Dieses Schema ist insofern gut, als es nicht davon abhängt, wie viele Personen wir durchlaufen. Wenn wir mehr Leute brauchen, überfluten wir einfach mehr Leute am Eingang und bekommen mehr am Ausgang.
Dies ist ein cooles System, aber es wäre natürlich naiv zu glauben, dass Sie danach bereits einen vorgefertigten Tester haben können. Sogar die Jungs, die unser Training erfolgreich abgeschlossen haben, haben viele Fragen, die sie brauchen, um schnell zu helfen. Und hier stehen wir vor vielen unerwarteten Problemen.
Die Leute stellen viele Fragen. Darüber hinaus können diese Fragen so seltsam sein, dass Sie niemals in Ihrem Leben gedacht hätten, dass die Antworten auf diese Fragen zu den Anweisungen hinzugefügt werden sollten, die in einem Test oder ähnlichem beschrieben wurden. Wenn Sie darüber nachdenken, ist dies eine normale Situation. Wenn wir uns in einem uns unbekannten Gebiet befinden, ist es unwahrscheinlich, dass jeder von uns eine Frage stellt, die einem Spezialisten albern erscheint.
Hier wird die Situation durch die Tatsache verschärft, dass wir mehrere hundert dieser Leute haben, und selbst wenn jeder von uns eine bestimmte Person fragt, ist die Wahrscheinlichkeit, eine dumme Frage zu stellen, gering, insgesamt stellt sich heraus: „Ahhh! Oh Gott Was ist los? Es überwältigt uns! "
Manchmal scheinen die Fragen seltsam. Zum Beispiel schreibt eine Person: „Ich verstehe nicht, was es bedeutet, auf„ Rückgängig “zu tippen. Sie sagen zu ihm: „Freund! Dies entspricht dem Klicken auf die Schaltfläche "Abbrechen". " Er: „Oh! Vielen Dank! Jetzt verstehe ich alles. "
Oder eine andere Person sagt: "Alles scheint in Ordnung zu sein, aber etwas ist ein bisschen kaputt. Ich kann nicht verstehen, ob dies ein Fehler ist oder nicht." Aber nach einer Minute versteht er selbst, wo er in die Testaufgabe gekommen ist; wahrscheinlich ist ein kaputtes Foto nicht sehr normal. Hier verstand er und okay.
Oder hier ist ein interessantes Beispiel, das uns lange Zeit wirklich in den Abgrund der Forschung gestürzt hat. Ein Mann kommt und sagt:

Jeder versteht nicht, was passiert, woher er kommt - wir haben uns so sehr bemüht, Testfälle beschrieben -, bis wir herausfinden, dass er eine spezielle Browser-Erweiterung hat, die vom Russischen ins Englische und dann vom Englischen ins Russische übersetzt und am Ende bekommen wir eine Häresie.
Tatsächlich gibt es viele solcher Fragen, deren Untersuchung jeweils eine Zeit ungleich Null dauert. Und irgendwann fingen unsere Kunden - Yandex-Teamdienste, die Tests durch Prüfer verwendeten - an, sich die Haare auszureißen und zu sagen: „Hören Sie, wir würden viel weniger Zeit damit verbringen, wenn wir dies alles selbst testen würden, als in diesen Chatrooms zu sitzen und zu antworten zu diesen seltsamen Fragen. "
Deshalb sind wir zu einem zweistufigen Chat-System gekommen. Es gibt eine bedingte Flut, in der unsere Gutachter mit ihren Kuratoren, diesen „Jungs in Hüten“, kommunizieren - 90% der Probleme werden hier gelöst. Und nur die wichtigsten und komplexesten Themen werden zu einem dedizierten Chat eskaliert, in dem das Serviceteam sitzt. Dies erleichterte das Leben aller Teams erheblich, alle seufzten ruhig.
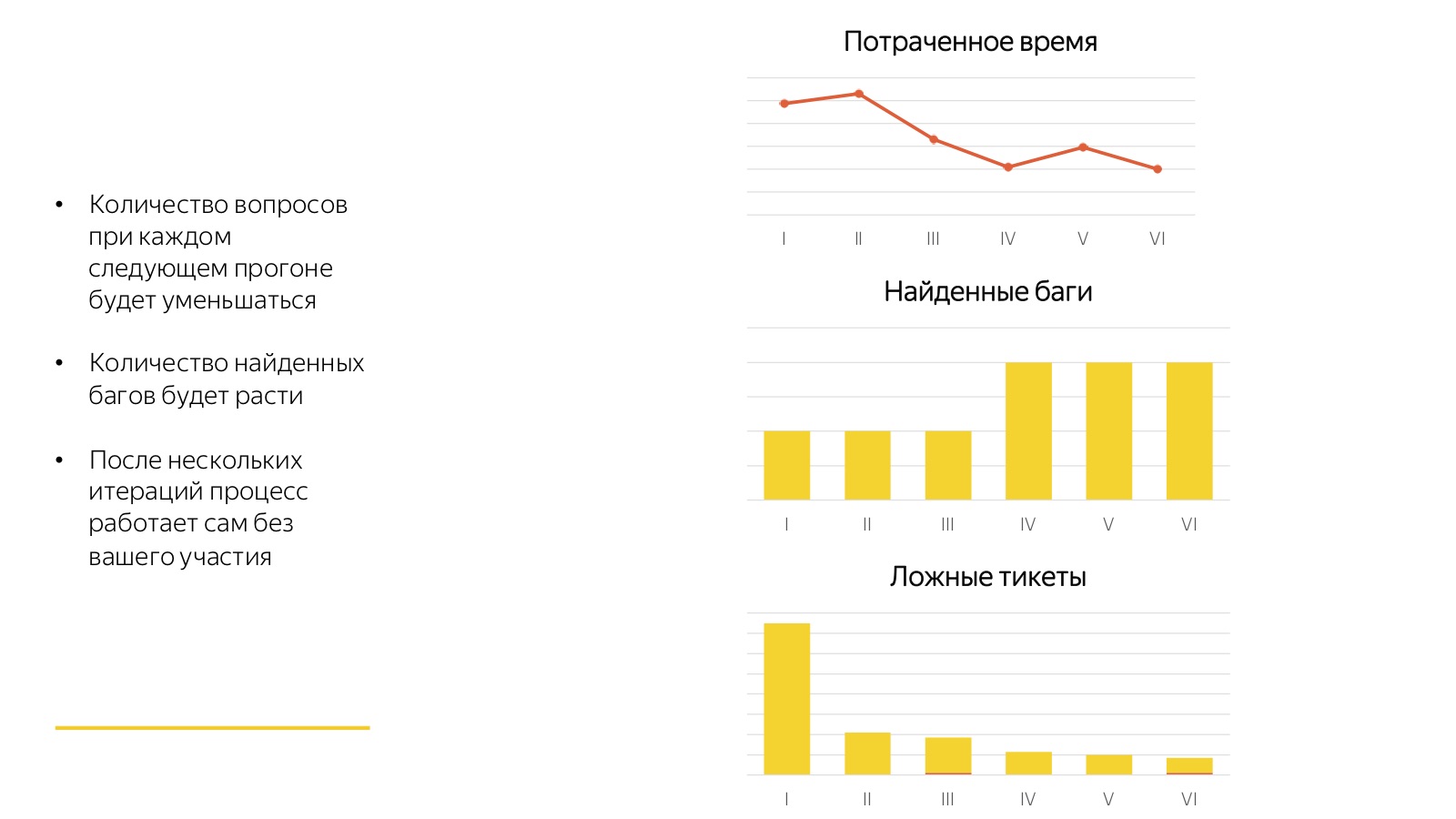
Diese Schrecken, von denen ich spreche, sind nicht so schrecklich. Die gute Nachricht ist, dass all diese Prozesse sehr schnell zusammenlaufen. Jeder erste Start ist immer sehr schlecht. Im obigen Bild sind 6 aufeinanderfolgende Starts derselben Regression sichtbar.
Sehen Sie sich an, wie viel Zeit die Mitarbeiter für die Beantwortung von Fragen aufgewendet haben, als die Prüfer zum ersten Mal nicht verstanden haben, worüber sie gesprochen haben und was sie von ihnen wollten. Sie fanden nur wenige Fehler, sie begannen eine Menge Tickets über gar nichts. Daher ist das erste Mal Horror-Horror-Horror, das zweite Mal Horror-Horror, und beim dritten Mal konvergieren 80 Prozent aller Prozesse. Und dann kommt der coole Prozess: Die Prüfer gewöhnen sich an die neue Aufgabe, und nach jedem Start sammeln wir Feedback, ergänzen Testfälle und klären etwas. Und es stellt sich heraus, dass es sich um eine coole Fabrik handelt, die auf Knopfdruck funktioniert und keine Beteiligung eines Vollzeitspezialisten erfordert.
3. Qualitätskontrolle
Ein sehr wichtiger Punkt, ohne den dies alles nicht funktioniert, ist die Qualitätskontrolle.
Unsere Gutachter arbeiten mit Akkordlöhnen: Alle ihre Aufgaben sind sehr klar geregelt und quantifiziert, jede Arbeitseinheit hat ihren eigenen Standardtarif und sie erhalten eine Zahlung für die Anzahl der abgeschlossenen Einheiten. Toloka arbeitet genauso und im Allgemeinen jede Menge. Dieses System hat viele Vorteile, es ist sehr flexibel, hat aber auch seine Nachteile. In einem System mit Stücklohn wird jeder Auftragnehmer versuchen, seine Arbeit zu optimieren - so wenig Zeit und Mühe wie möglich für die Aufgabe aufwenden, um viel mehr Geld pro Zeiteinheit zu erhalten. Daher wird garantiert, dass ein solches auf Crowdsourcing basierendes System mit der von Ihnen zugelassenen Mindestqualität funktioniert. Wenn Sie keine Kontrolle über die Qualität haben, wird sie so niedrig wie möglich fallen.
Die gute Nachricht ist, dass man dagegen ankämpfen kann, es kann kontrolliert werden. Wenn wir die Qualität der Arbeit quantifizieren können, ist die Aufgabe ziemlich einfach. Das ist theoretisch. In der Praxis ist es gar nicht so einfach, insbesondere bei Testaufgaben. Weil das Testen im Gegensatz zu vielen anderen Massenaufgaben, die wir mit Hilfe von Assessoren gelöst haben, seltene Ereignisse behandelt und alle Arten von Statistiken dort ziemlich schlecht funktionieren. Es ist sehr schwer zu verstehen, wie oft eine Person tatsächlich Fehler findet, wenn es im Prinzip nur sehr wenige Fehler gibt. Daher müssen wir mehrere Methoden der Qualitätskontrolle gleichzeitig pervertieren und anwenden, die uns zusammen ein bestimmtes Bild davon geben, mit welcher Qualität der Darsteller arbeitet.
Das erste ist eine Überprüfung der Überlappung. "Überlappend" bedeutet, dass wir jede Aufgabe mehreren Personen zuweisen. Wir tun dies natürlich, da jeder Testfall in mehreren Umgebungen getestet werden muss. Es stellt sich also heraus, dass derselbe Testfall in den Umgebungen A, B und C überprüft wurde. Wir haben drei Ergebnisse von drei Personen - die denselben Testfall bestanden haben. Dann schauen wir uns an, ob die Ergebnisse auseinander gingen.
Manchmal kommt es vor, dass in einer Umgebung ein Fehler gefunden wurde, in zwei anderen jedoch nicht. Vielleicht ist es wirklich so, oder vielleicht hat jemand einen Fehler gemacht: Entweder hat eine Person einen zusätzlichen Fehler gefunden, oder diese beiden haben betrogen und nichts gefunden. In jedem Fall ist dies ein verdächtiger Fall. Wenn wir darauf stoßen, senden wir eine zusätzliche Überprüfung, um sicherzustellen und zu überprüfen, wer Recht hatte und wer schuld war. Ein solches Schema ermöglicht es uns, Leute zu fangen, die zum Beispiel zusätzliche Tickets dort gestartet haben, wo sie nicht gebraucht wurden, oder verpasst haben, wo sie gebraucht wurden. Gleichzeitig prüfen wir, wie korrekt das Ticket geöffnet wurde, ob alles dem Verfahren entspricht: Werden Screenshots hinzugefügt, wird bei Bedarf eine klare Beschreibung hinzugefügt und so weiter.
Darüber hinaus und insbesondere in Bezug auf die Richtigkeit des Ticketing ist es hilfreich und bequem, einige Dinge automatisch zu steuern, die einerseits Kleinigkeiten zu sein scheinen, andererseits den Workflow jedoch stark beeinflussen. Daher prüfen wir automatisch, ob das Ticket eine Anwendung enthält, ob Screenshots hinzugefügt wurden, ob das Ticket Kommentare enthält oder ob es einfach geschlossen wurde, ohne zu prüfen, wie viel Zeit dafür aufgewendet wurde, um verdächtige Fälle zu identifizieren. Hier können Sie viele verschiedene Heuristiken erstellen und anwenden. Der Prozess ist fast endlos.
Das Überprüfen auf Überlappungen ist eine gute Sache, gibt jedoch eine etwas voreingenommene Bewertung ab, da wir nur kontroverse Fälle prüfen. Manchmal möchten Sie eine ehrliche Stichprobe machen. Dazu verwenden wir Testläufe. In der Trainingsphase hatten wir speziell zusammengestellte Testbaugruppen, in denen wir im Voraus wissen, wo es Fehler gibt und wo nicht. Wir verwenden ähnliche Starts zur Qualitätskontrolle und prüfen, wie viele Fehler eine Person gefunden und wie viele übersehen hat. Dies ist eine coole Art und Weise, es gibt das vollständigste Bild der Welt. Die Verwendung ist jedoch recht teuer: Während wir noch eine neue Testbaugruppe sammeln ... verwenden wir diesen Ansatz ziemlich selten alle paar Monate.
Der letzte wichtige Punkt: Auch wenn wir bereits alles getan haben, müssen wir auf jeden Fall analysieren, warum die Fehler übersprungen wurden. Wir überprüfen anhand der Schritte des Testfalls, ob dieser Fehler gefunden werden konnte. Wenn es möglich war, aber die Person vermisst hat, dann ist die Person eine Tasse, und Sie müssen eine Wirkung auf sie haben. Und wenn dieser Fall nicht vorhanden war, müssen Sie die Testfälle irgendwie ergänzen und aktualisieren.
Infolgedessen reduzieren wir alle Qualitätsmetriken auf eine einzige Bewertung von Assessoren, was sich auf deren Karriere und Schicksal in unserem System auswirkt. Je höher die Bewertung einer Person ist, desto schwieriger werden Aufgaben und Ansprüche auf Preise. Je niedriger das Rating des Assessors ist, desto wahrscheinlicher ist es, dass es entlassen wird. Wenn eine Person stabil mit einer niedrigen Bewertung arbeitet, trennen wir uns schließlich von ihr.
4. Delegation
Die allerletzte Säule unseres skalierbaren Pyramidenschemas, über die ich sprechen möchte, sind Delegationsaufgaben.
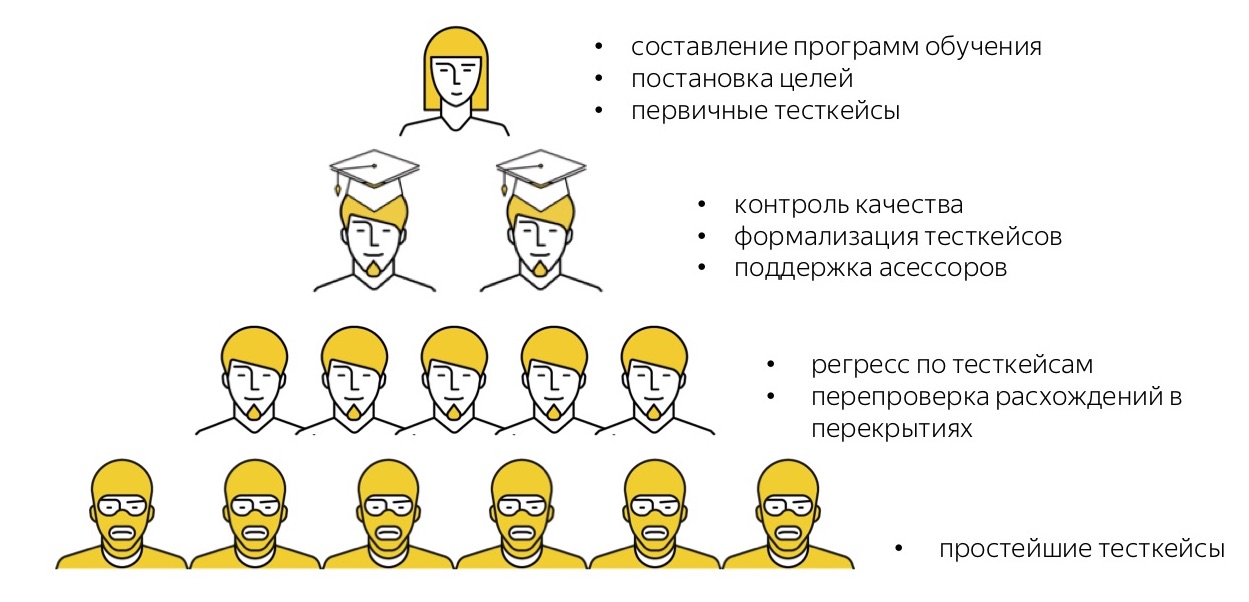
Ich werde noch einmal daran erinnern, wie unsere Pyramide für manuelle Testaufgaben aussieht. Wir haben „hochrangige“ Mitarbeiter - dies sind Vollzeit-Tester, Vertreter des Serviceteams, die Schulungsprogramme für den zu testenden Service erstellen, eine Strategie für die zu testenden Dienste entwickeln und primäre Testfälle in freier Form schreiben.
Darüber hinaus verfügen wir über die talentiertesten Prüfer, die Testfälle von der Freiform in die formalisierten übertragen, anderen Prüfern helfen, sie in Chatrooms unterstützen und Gegenprüfungen und selektive Qualitätskontrollen durchführen.
Darüber hinaus gibt es eine Wolke unserer vielen Darsteller, die Schritt für Schritt eine Regression durchführen.
Als nächstes haben wir Toloka, das wir nicht vergessen haben. : , . , . . - , , , .

. - ( , ), — , . , «», , , .
- — rocket science, : , . , , . , . , - «» , , .
: « , ». — , . , . , , , , , , .
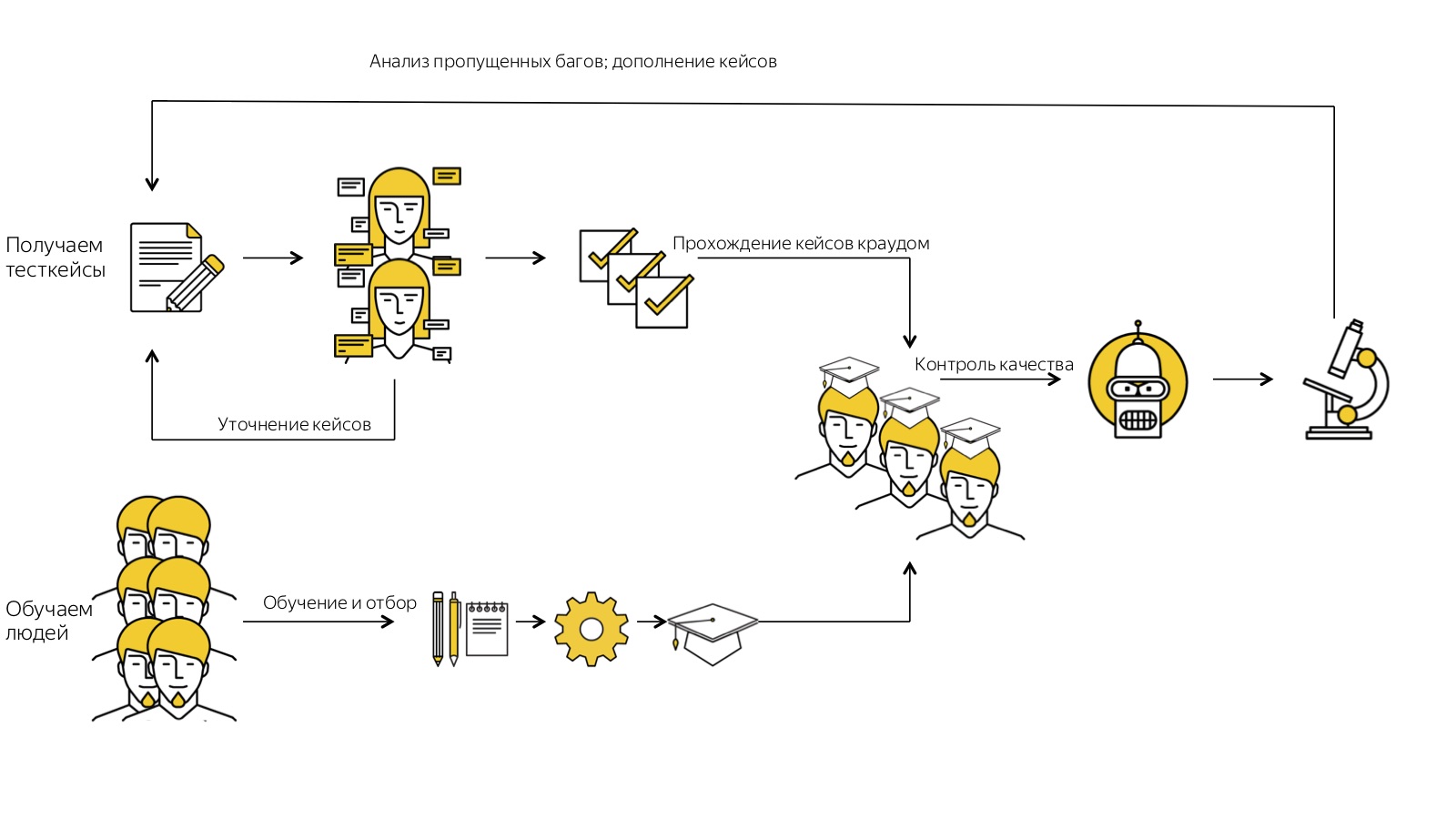
, . , - . , , . , -. - , , , . . -, : , , .
, . , - , , , - . — — - : «, , - , . , ». , , , , .
Heisenbug 2018 Piter , : 6-7 Heisenbug , , .