 Übersetzung eines vollständigen maschinellen Lernprojekts in Python: Teil 1 .
Übersetzung eines vollständigen maschinellen Lernprojekts in Python: Teil 1 .Wenn Sie ein Buch lesen oder eine Schulung zur Datenanalyse anhören, haben Sie häufig das Gefühl, dass Sie mit einigen separaten Teilen eines Bildes konfrontiert sind, die nicht zusammengesetzt werden können. Sie haben vielleicht Angst vor der Aussicht, den nächsten Schritt zu tun und ein Problem mithilfe des maschinellen Lernens vollständig zu lösen, aber mithilfe dieser Artikelserie gewinnen Sie Vertrauen in die Fähigkeit, jedes Problem auf dem Gebiet der Datenwissenschaft zu lösen.
Damit Sie endlich ein vollständiges Bild im Kopf haben, schlagen wir vor, das Projekt der Verwendung von maschinellem Lernen unter Verwendung realer Daten von Anfang bis Ende zu analysieren.
Gehen Sie nacheinander die folgenden Schritte durch:
- Daten bereinigen und formatieren.
- Explorative Datenanalyse.
- Design und Auswahl der Funktionen.
- Vergleich der Metriken mehrerer Modelle für maschinelles Lernen.
- Hyperparametrische Abstimmung des besten Modells.
- Bewertung des besten Modells anhand eines Testdatensatzes.
- Interpretation der Ergebnisse des Modells.
- Schlussfolgerungen und Arbeit mit Dokumenten.
Sie erfahren, wie die Schritte ineinander übergehen und wie Sie sie in Python implementieren.
Das ganze Projekt ist auf GitHub verfügbar, der erste Teil liegt
hier. In diesem Artikel werden wir die ersten drei Stufen betrachten.
Aufgabenbeschreibung
Bevor Sie Code schreiben, müssen Sie das zu lösende Problem und die verfügbaren Daten verstehen. In diesem Projekt werden wir mit öffentlich verfügbaren
Energieeffizienzdaten für Gebäude in New York arbeiten.
Unser Ziel: Aus den verfügbaren Daten ein Modell zu erstellen, das die Anzahl der Energy Star-Punkte für ein bestimmtes Gebäude vorhersagt, und die Ergebnisse zu interpretieren, um Faktoren zu finden, die den endgültigen Wert beeinflussen.
Die Daten enthalten bereits den zugewiesenen Energy Star Score. Unsere Aufgabe ist also maschinelles Lernen mit kontrollierter Regression:
- Betreut: Wir kennen die Zeichen und den Zweck und haben die Aufgabe, ein Modell zu trainieren, das das erste mit dem zweiten vergleichen kann.
- Regression: Der Energy Star Score ist eine kontinuierliche Variable.
Unser Modell muss genau sein - damit es den Wert des Energy Star Score nahezu wahr und interpretierbar vorhersagen kann, damit wir seine Vorhersagen verstehen können. Wenn wir die Zieldaten kennen, können wir sie verwenden, um Entscheidungen zu treffen, wenn wir tiefer in die Daten eintauchen und das Modell erstellen.
Datenbereinigung
Nicht jeder Datensatz ist ein perfekt aufeinander abgestimmter Beobachtungssatz ohne Anomalien und fehlende Werte (ein Hinweis auf die
MTCAR- und
Iris- Datensätze ). In realen Daten gibt es wenig Ordnung. Bevor Sie mit der Analyse beginnen, müssen Sie sie
löschen und in ein akzeptables Format bringen. Die Datenbereinigung ist ein unangenehmes, aber obligatorisches Verfahren zur Lösung der meisten Datenanalyseaufgaben.
Zunächst können Sie die Daten in Form eines Pandas-Datenrahmens laden und untersuchen:
import pandas as pd import numpy as np # Read in data into a dataframe data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') # Display top of dataframe data.head()
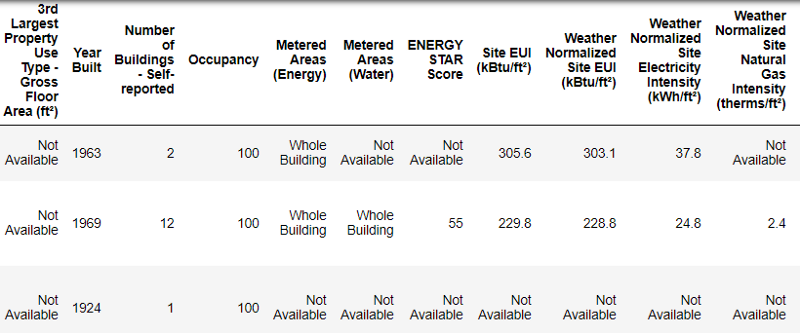 So sehen echte Daten aus.
So sehen echte Daten aus.Dies ist ein Fragment einer Tabelle mit 60 Spalten. Auch hier sind einige Probleme sichtbar: Wir müssen den
Energy Star Score vorhersagen, wissen aber nicht, was all diese Spalten bedeuten. Dies ist zwar nicht unbedingt ein Problem, da Sie häufig ein genaues Modell erstellen können, ohne etwas über Variablen zu wissen. Die Interpretierbarkeit ist uns jedoch wichtig, daher müssen wir die Bedeutung von mindestens einigen Spalten herausfinden.
Als wir diese Daten erhielten, fragten wir nicht nach den Werten, sondern sahen uns den Dateinamen an:
und beschlossen, nach "Local Law 84" zu suchen. Wir haben
diese Seite gefunden , auf der steht, dass es sich um das in New York geltende Gesetz handelt, wonach die Eigentümer aller Gebäude einer bestimmten Größe über den Energieverbrauch berichten sollten. Eine weitere Suche half dabei,
alle Spaltenwerte zu finden . Vernachlässigen Sie also nicht die Dateinamen, sie können ein guter Ausgangspunkt sein. Darüber hinaus ist dies eine Erinnerung daran, dass Sie nicht eilen und etwas Wichtiges nicht verpassen!
Wir werden nicht alle Spalten studieren, aber wir werden uns definitiv mit dem Energy Star Score befassen, der wie folgt beschrieben wird:
Das Perzentil-Ranking liegt zwischen 1 und 100 und wird auf der Grundlage von Jahresberichten über den Energieverbrauch der Bauherren selbst berechnet. Der Energy Star Score ist ein relatives Maß für den Vergleich der Energieeffizienz von Gebäuden.
Das erste Problem wurde gelöst, das zweite blieb jedoch bestehen - fehlende Werte, markiert als "Nicht verfügbar". Dies ist ein Zeichenfolgenwert in Python. Dies bedeutet, dass auch Zeichenfolgen mit Zahlen als
object gespeichert werden. Wenn die Spalte eine Zeichenfolge enthält, konvertiert Pandas diese in eine Spalte, die vollständig aus einer Zeichenfolge besteht. Die
dataframe.info() können mit der Methode
dataframe.info() ermittelt werden:
# See the column data types and non-missing values data.info()
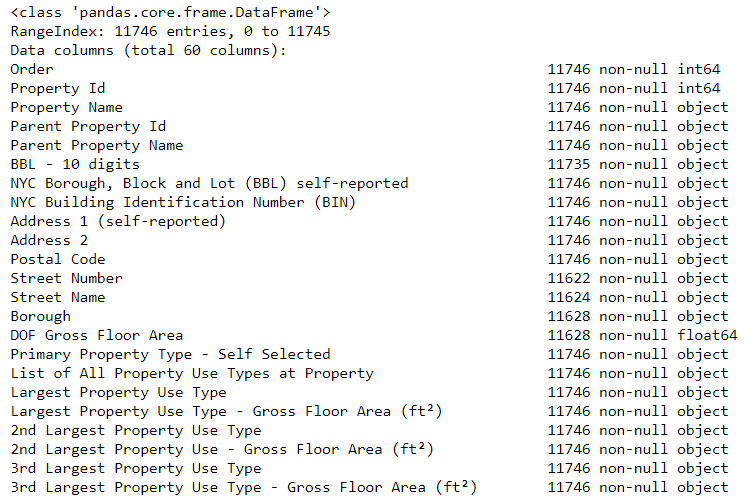
Sicherlich werden einige Spalten, die explizit Zahlen enthalten (wie z. B. ft²), als Objekte gespeichert. Wir können keine numerische Analyse auf Zeichenfolgenwerte anwenden, daher konvertieren wir sie in numerische Datentypen (insbesondere
float )!
Dieser Code ersetzt zunächst alle "Nicht verfügbar" durch
keine Zahl (
np.nan ), die als Zahlen interpretiert werden kann, und konvertiert dann den Inhalt bestimmter Spalten in einen
float Typ:
# Replace all occurrences of Not Available with numpy not a number data = data.replace({'Not Available': np.nan}) # Iterate through the columns for col in list(data.columns): # Select columns that should be numeric if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): # Convert the data type to float data[col] = data[col].astype(float)
Wenn die Werte in den entsprechenden Spalten bei uns zu Zahlen werden, können wir beginnen, die Daten zu untersuchen.
Fehlende und abnormale Daten
Neben falschen Datentypen ist das Fehlen von Werten eines der häufigsten Probleme. Sie können aus verschiedenen Gründen fehlen, und vor dem Training des Modells müssen diese Werte entweder ausgefüllt oder gelöscht werden. Lassen Sie uns zunächst herausfinden, wie viele Werte wir in jeder Spalte haben (
Code ist hier ).
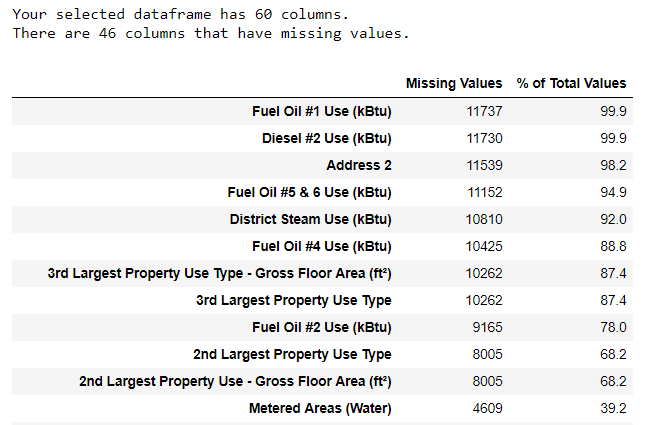 Zum Erstellen einer Tabelle wurde eine Funktion aus einem Zweig in StackOverflow verwendet .
Zum Erstellen einer Tabelle wurde eine Funktion aus einem Zweig in StackOverflow verwendet .Informationen sollten immer mit Vorsicht entfernt werden. Wenn die Spalte viele Werte enthält, wird dies unserem Modell wahrscheinlich nicht zugute kommen. Der Schwellenwert, nach dem es besser ist, die Spalten wegzuwerfen, hängt von Ihrer Aufgabe ab (
hier eine Diskussion ). In unserem Projekt werden Spalten gelöscht, die mehr als halb leer sind.
Auch in diesem Stadium ist es besser, die abnormalen Werte zu entfernen. Sie können aufgrund von Tippfehlern bei der Dateneingabe oder aufgrund von Fehlern in den Maßeinheiten auftreten oder sie können korrekte, aber extreme Werte sein. In diesem Fall werden wir die "zusätzlichen" Werte entfernen, die sich an der
Definition extremer Anomalien orientieren :
- Unterhalb des ersten Quartils befindet sich ein 3 ∗ Interquartilbereich.
- Oberhalb des dritten Quartils + 3 ∗ Interquartilbereich.
Der Code, der Spalten und Anomalien entfernt, wird im Editor auf Github aufgelistet. Nach Abschluss des Datenbereinigungsprozesses und der Beseitigung von Anomalien verfügen wir über mehr als 11.000 Gebäude und 49 Schilder.
Explorative Datenanalyse
Die langweilige, aber notwendige Phase der Datenbereinigung ist abgeschlossen, Sie können zur Studie gehen!
Die explorative Datenanalyse (RAD) ist ein unbegrenzter Zeitprozess, in dem wir Statistiken berechnen und nach Trends, Anomalien, Mustern oder Beziehungen in den Daten suchen.
Kurz gesagt, RAD ist ein Versuch herauszufinden, welche Daten uns sagen können. Normalerweise beginnt die Analyse mit einer oberflächlichen Überprüfung, dann finden wir interessante Fragmente und analysieren sie genauer. Die Ergebnisse können für sich genommen interessant sein oder zur Auswahl des Modells beitragen und bei der Entscheidung helfen, welche Funktionen wir verwenden werden.
Diagramme mit einer Variablen
Unser Ziel ist es, den Wert des Energy Star-Scores (in unseren Daten in unseren Score umbenannt) vorherzusagen. Daher ist es sinnvoll, zunächst die Verteilung dieser Variablen zu untersuchen. Ein Histogramm ist eine einfache, aber effektive Methode zur Visualisierung der Verteilung einer einzelnen Variablen und kann mithilfe von
matplotlib einfach
matplotlib .
import matplotlib.pyplot as plt # Histogram of the Energy Star Score plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution');
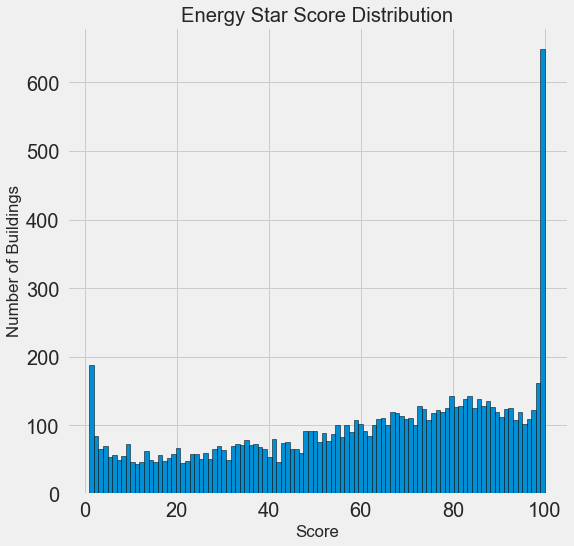
Sieht verdächtig aus! Der Energy Star Score ist ein Perzentil, daher sollten Sie eine gleichmäßige Verteilung erwarten, wenn jeder Punkt der gleichen Anzahl von Gebäuden zugewiesen wird. Eine unverhältnismäßig große Anzahl von Gebäuden erzielte jedoch die höchsten und niedrigsten Ergebnisse (für den Energy Star Score gilt: Je größer, desto besser).
Wenn wir uns die Definition dieser Punktzahl noch einmal ansehen, werden wir sehen, dass sie auf der Grundlage von „Berichten, die von den Bauherren unabhängig ausgefüllt wurden“ berechnet wird, was den Überschuss an sehr großen Werten erklären kann. Das Auffordern von Bauherren, ihren Energieverbrauch zu melden, ist wie das Auffordern von Schülern, ihre Noten in Prüfungen anzugeben. Dies ist vielleicht nicht das objektivste Kriterium für die Beurteilung der Energieeffizienz von Immobilien.
Wenn wir unbegrenzt Zeit hätten, könnten wir herausfinden, warum so viele Gebäude sehr hohe und sehr niedrige Punkte haben. Dazu müssten wir die geeigneten Gebäude auswählen und sorgfältig analysieren. Wir müssen jedoch nur lernen, wie man Punktzahlen vorhersagt, und keine genauere Bewertungsmethode entwickeln. Sie können sich selbst markieren, dass die Punkte eine verdächtige Verteilung haben, aber wir werden uns auf die Prognose konzentrieren.
Beziehungssuche
Der Hauptteil der AHFR ist die Suche nach der Beziehung zwischen Zeichen und unserem Ziel. Mit ihm korrelierende Variablen sind für die Verwendung im Modell nützlich, da sie für Prognosen verwendet werden können. Eine Möglichkeit, die Auswirkung einer kategorialen Variablen (die nur einen begrenzten Satz von Werten annimmt) auf das Ziel zu untersuchen, besteht darin, die Dichte mithilfe der Seaborn-Bibliothek zu zeichnen.
Das Dichtediagramm kann als geglättetes Histogramm betrachtet werden, da es die Verteilung einer einzelnen Variablen zeigt. Sie können einzelne Klassen im Diagramm einfärben, um zu sehen, wie eine kategoriale Variable die Verteilung ändert. Dieser Code zeigt das Energy Star Score-Dichtediagramm, das nach Gebäudetyp gefärbt ist (für eine Liste von Gebäuden mit mehr als 100 Dimensionen):
# Create a list of buildings with more than 100 measurements types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot of distribution of scores for building categories figsize(12, 10) # Plot each building for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star Scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # label the plot plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
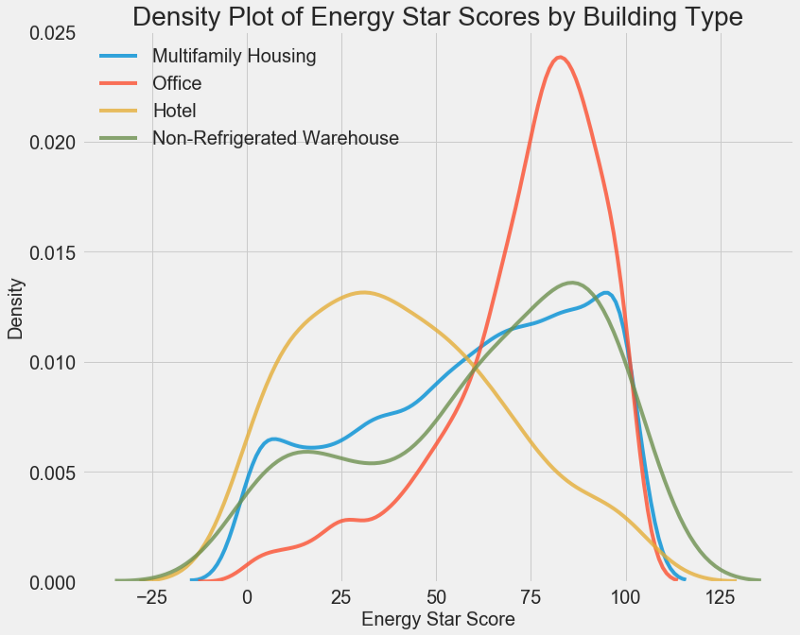
Wie Sie sehen können, wirkt sich die Art des Gebäudes stark auf die Anzahl der Punkte aus. Bürogebäude haben normalerweise eine höhere Punktzahl und Hotels eine niedrigere. Sie müssen also den Gebäudetyp in das Modell aufnehmen, da dieses Zeichen unser Ziel beeinflusst. Als kategoriale Variable müssen wir eine One-Hot-Codierung des Gebäudetyps durchführen.
Ein ähnliches Diagramm kann verwendet werden, um den Energy Star Score nach Stadtbezirken zu schätzen:
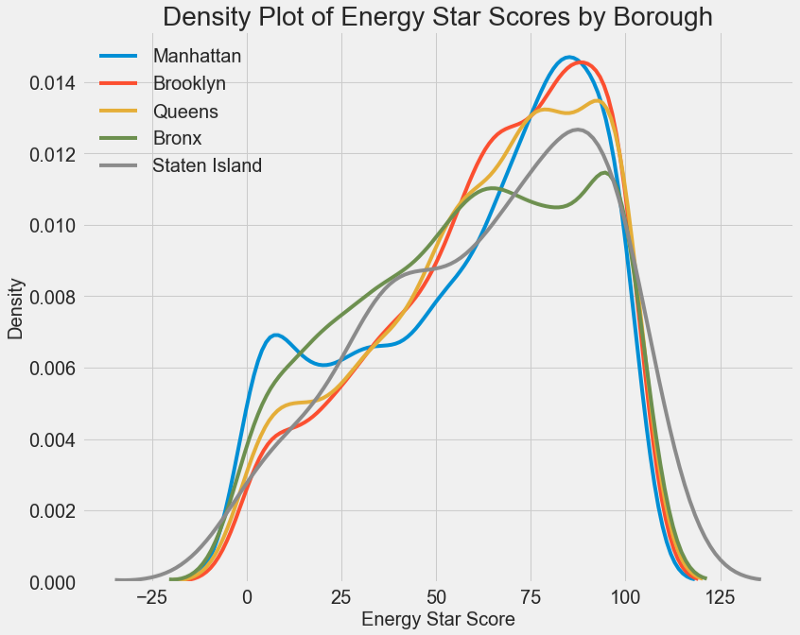
Der Bereich beeinflusst die Punktzahl nicht so sehr wie die Art des Gebäudes. Trotzdem werden wir es in das Modell aufnehmen, da es einen kleinen Unterschied zwischen den Regionen gibt.
Um die Beziehung zwischen den Variablen zu berechnen, können Sie
den Pearson-Korrelationskoeffizienten verwenden . Dies ist ein Maß für die Intensität und Richtung einer linearen Beziehung zwischen zwei Variablen. Ein Wert von +1 bedeutet eine perfekt lineare positive Beziehung und -1 bedeutet eine perfekt lineare negative Beziehung. Hier einige Beispiele für
Pearson-Korrelationskoeffizientenwerte :

Obwohl dieser Koeffizient nichtlineare Abhängigkeiten nicht widerspiegeln kann, ist es möglich, damit zu beginnen, um die Beziehungen von Variablen zu bewerten. In Pandas können Sie auf einfache Weise Korrelationen zwischen beliebigen Spalten in einem Datenrahmen berechnen:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
Die negativsten Korrelationen mit dem Ziel:

und das positivste:

Es gibt mehrere starke negative Korrelationen zwischen den Attributen und dem Ziel, von denen die größten verschiedenen EUI-Kategorien angehören (die Methoden zur Berechnung dieser Indikatoren unterscheiden sich geringfügig).
EUI (Energy Use Intensity ) ist die Menge an Energie, die von einem Gebäude verbraucht wird, geteilt durch einen Quadratfuß Fläche. Dieser spezifische Wert wird zur Bewertung der Energieeffizienz verwendet. Je kleiner er ist, desto besser. Die Logik legt nahe, dass diese Korrelationen gerechtfertigt sind: Wenn der EUI steigt, sollte der Energy Star Score sinken.
Diagramme mit zwei Variablen
Wir verwenden Streudiagramme, um die Beziehungen zwischen zwei kontinuierlichen Variablen zu visualisieren. Sie können den Farben der Punkte zusätzliche Informationen hinzufügen, z. B. eine kategoriale Variable. Die Beziehung zwischen dem Energy Star Score und dem EUI ist unten dargestellt. Die Farben zeigen verschiedene Gebäudetypen an:
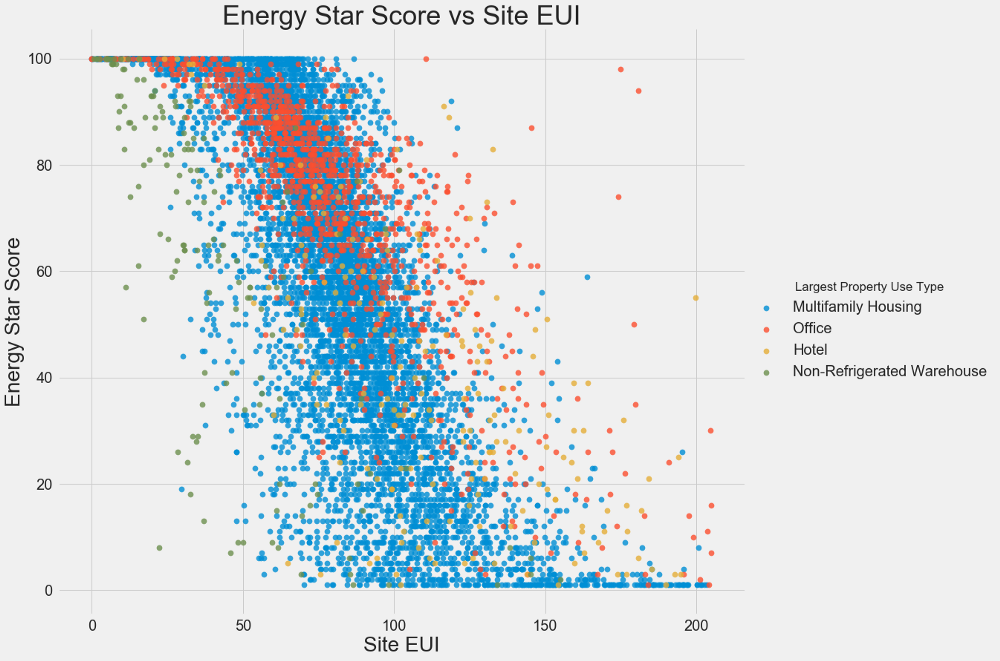
In diesem Diagramm können Sie einen Korrelationskoeffizienten von -0,7 visualisieren. Wenn der EUI abnimmt, steigt der Energy Star Score. Diese Beziehung wird bei verschiedenen Gebäudetypen beobachtet.
Unsere neueste Forschungskarte heißt
Pairs Plot . Dies ist ein großartiges Werkzeug, um die Beziehungen zwischen verschiedenen Variablenpaaren und die Verteilung einzelner Variablen zu sehen. Wir werden die Seaborn-Bibliothek und die PairGrid-Funktion verwenden, um ein Paardiagramm mit einem Streudiagramm im oberen Dreieck, einem diagonalen Histogramm, einem zweidimensionalen Kerndichtediagramm und Korrelationskoeffizienten im unteren Dreieck zu erstellen.
# Extract the columns to plot plot_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)', 'log_Total GHG Emissions (Metric Tons CO2e)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI', 'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object grid = sns.PairGrid(data = plot_data, size = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
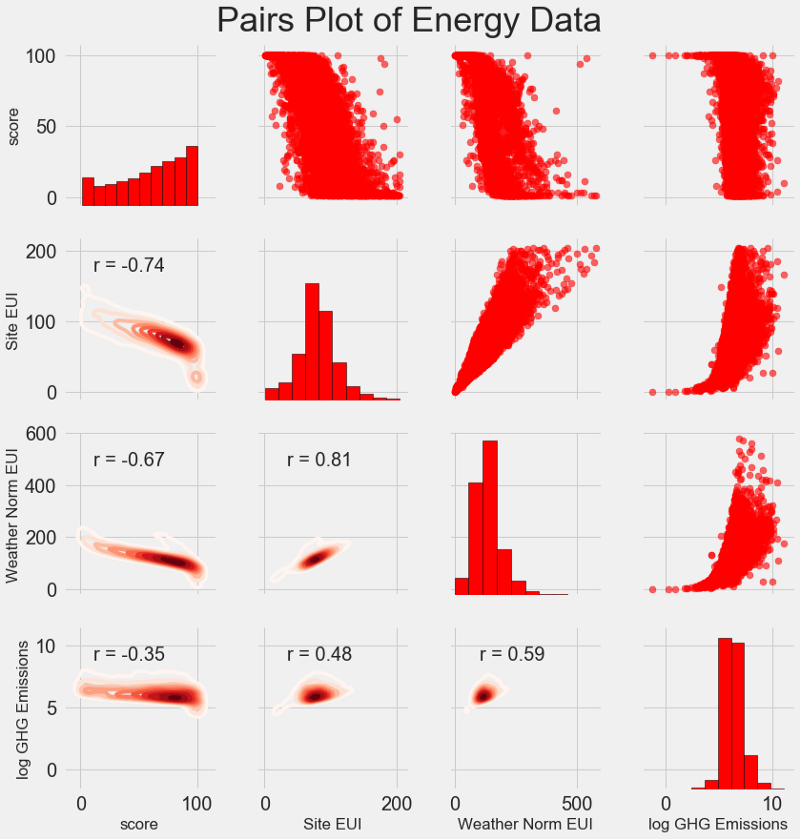
Suchen Sie nach dem Schnittpunkt von Zeilen und Spalten, um die Beziehung zwischen Variablen anzuzeigen. Angenommen, Sie möchten die Korrelation zwischen
Weather Norm EUI und
score , dann suchen wir nach der
Weather Norm EUI Reihe und der
score Spalte, an deren Schnittpunkt ein Korrelationskoeffizient von -0,67 liegt. Diese Grafiken sehen nicht nur cool aus, sondern helfen auch bei der Auswahl von Variablen für das Modell.
Design und Auswahl der Funktionen
Das Entwerfen und Auswählen von Funktionen bringt häufig die größte Rendite in Bezug auf die Zeit, die für maschinelles Lernen aufgewendet wird. Zuerst geben wir die Definitionen:
- Merkmalskonstruktion: Der Prozess des Extrahierens oder Erstellens neuer Merkmale aus Rohdaten. Um Variablen im Modell zu verwenden, müssen Sie sie möglicherweise transformieren, z. B. den natürlichen Logarithmus verwenden oder die Quadratwurzel extrahieren oder eine einmalige Codierung kategorialer Variablen anwenden. Beim charakteristischen Design können zusätzliche Features aus Rohdaten erstellt werden.
- Merkmalsauswahl: Der Prozess der Auswahl der relevantesten Merkmale aus Daten, bei dem einige Merkmale entfernt werden, damit das Modell neue Daten besser verallgemeinern kann, um ein besser interpretierbares Modell zu erhalten. Die Wahl der Zeichen kann als Entfernung von „überflüssig“ betrachtet werden, so dass nur das Wichtigste übrig bleibt.
Das Modell des maschinellen Lernens kann nur aus den von uns bereitgestellten Daten lernen. Daher ist es äußerst wichtig sicherzustellen, dass wir alle für unsere Aufgabe relevanten Informationen enthalten. Wenn Sie dem Modell nicht die richtigen Daten zur Verfügung stellen, kann es nicht lernen und liefert keine genauen Vorhersagen!
Wir werden Folgendes tun:
- Anwendbar auf kategoriale Variablen (Quartal und Art des Eigentums) One-Hot-Codierung.
- Addieren Sie den natürlichen Logarithmus aller numerischen Variablen.
One-Hot-Codierung ist erforderlich, um kategoriale Variablen in das Modell aufzunehmen. Der Algorithmus für maschinelles Lernen kann die Art des "Büros" nicht verstehen. Wenn es sich bei dem Gebäude also um ein Büro handelt, weisen wir ihm das Zeichen 1 zu, und wenn kein Büro, dann 0.
Durch Hinzufügen transformierter Features kann das Modell nichtlineare Beziehungen innerhalb der Daten kennenlernen. Bei der Analyse von Daten ist es üblich
, Quadratwurzeln zu extrahieren, natürliche Logarithmen zu verwenden oder die Zeichen irgendwie zu transformieren. Dies hängt von der spezifischen Aufgabe oder Ihrem Wissen über die besten Techniken ab. In diesem Fall addieren wir den natürlichen Logarithmus aller numerischen Zeichen.
Dieser Code wählt numerische Zeichen aus, berechnet ihre Logarithmen, wählt zwei kategoriale Zeichen aus, wendet eine Hot-Codierung auf sie an und kombiniert beide Sätze zu einem. Nach der Beschreibung zu urteilen, bleibt noch viel zu tun, aber in Pandas ist alles ziemlich einfach!
# Copy the original data features = data.copy() # Select the numeric columns numeric_subset = data.select_dtypes('number') # Create columns with log of numeric columns for col in numeric_subset.columns: # Skip the Energy Star Score column if col == 'score': next else: numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Select the categorical columns categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode categorical_subset = pd.get_dummies(categorical_subset) # Join the two dataframes using concat # Make sure to use axis = 1 to perform a column bind features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Jetzt haben wir mehr als 11.000 Beobachtungen (Gebäude) mit 110 Spalten (Tags). Nicht alle Zeichen sind nützlich, um den Energy Star Score vorherzusagen. Daher werden wir die Auswahl der Zeichen übernehmen und einige der Variablen entfernen.
Funktionsauswahl
Viele der 110 verfügbaren Zeichen sind redundant, da sie stark miteinander korrelieren. Hier ist beispielsweise ein Diagramm des EUI und des wetternormalisierten Standorts EUI mit einem Korrelationskoeffizienten von 0,997.
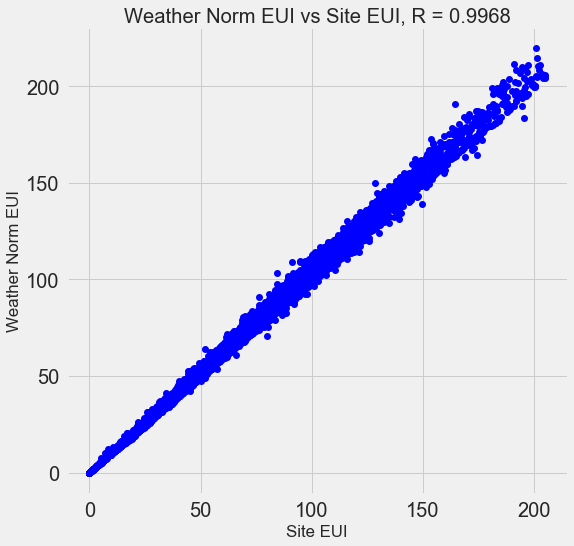
Zeichen, die stark miteinander korrelieren, werden als
kollinear bezeichnet . Das Entfernen einer Variablen in solchen Attributpaaren hilft dem
Modell häufig, sich
zu verallgemeinern und besser interpretierbar zu sein . Bitte beachten Sie, dass es sich um die Korrelation einiger Zeichen mit anderen handelt und nicht um die Korrelation mit dem Ziel, was unserem Modell nur helfen würde!
Es gibt eine Reihe von Methoden zur Berechnung der Kollinearität von Merkmalen, und eine der beliebtesten ist der
Varianzinflationsfaktor . Wir werden den Korrelationskoeffizienten verwenden, um kollineare Merkmale zu suchen und zu entfernen. Wir verwerfen ein Zeichenpaar, wenn der Korrelationskoeffizient zwischen ihnen mehr als 0,6 beträgt. Der Code befindet sich im Editor (und als Reaktion auf den
Stapelüberlauf ).
Dieser Wert sieht willkürlich aus, aber tatsächlich habe ich verschiedene Schwellenwerte ausprobiert, und oben konnte ich das beste Modell erstellen. Maschinelles Lernen ist
empirisch und muss oft experimentieren, um die beste Lösung zu finden. Nach der Auswahl haben wir 64 Attribute und ein Ziel.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Wählen Sie eine Basisebene
Wir haben die Daten gelöscht, eine explorative Analyse durchgeführt und die Schilder konstruiert. Bevor Sie mit der Erstellung des Modells fortfahren, müssen Sie die anfängliche Basisstufe (naive Basislinie) auswählen - eine Art Annahme, mit der wir die Ergebnisse der Modelle vergleichen. Wenn sie unter das Grundniveau fallen, gehen wir davon aus, dass maschinelles Lernen für diese Aufgabe nicht anwendbar ist oder dass ein anderer Ansatz versucht werden sollte.
Für Regressionsaufgaben ist es als Basisstufe sinnvoll, den Medianwert des Ziels im Trainingssatz für alle Beispiele im Testsatz zu erraten. Diese Kits stellen eine Barriere dar, die für jedes Modell relativ niedrig ist.
Als Metrik nehmen wir den
durchschnittlichen absoluten Fehler (mae) in den Prognosen. Es gibt viele andere Metriken für Regressionen, aber ich mag den
Rat , eine Metrik auszuwählen und sie zur Bewertung von Modellen zu verwenden. Und der durchschnittliche absolute Fehler ist leicht zu berechnen und zu interpretieren.
Bevor Sie das Basisniveau berechnen, müssen Sie die Daten in Trainings- und Testsätze aufteilen:
- Ein Trainingssatz von Attributen ist das, was wir unserem Modell zusammen mit den Antworten während des Trainings zur Verfügung stellen. Das Modell muss lernen, die Eigenschaften des Ziels zu erfüllen.
- Ein Testfeature-Set wird verwendet, um das trainierte Modell zu bewerten. Wenn sie die Testsuite verarbeitet, sieht sie nicht die richtigen Antworten und muss diese nur anhand der verfügbaren Funktionen vorhersagen. Wir kennen die Antworten für die Testdaten und können die Prognoseergebnisse mit ihnen vergleichen.
Für Schulungen verwenden wir 70% der Daten und für Tests - 30%:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Nun berechnen wir den Indikator für das anfängliche Basisniveau:
# Function to calculate mean absolute error def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred)) baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
Die Grundschätzung ist eine Punktzahl von 66,00
Basisleistung auf dem Testsatz: MAE = 24.5164Der durchschnittliche absolute Fehler am Testsatz betrug etwa 25 Punkte. Da wir im Bereich von 1 bis 100 auswerten, beträgt der Fehler 25% - eine eher niedrige Barriere für das Modell!
Fazit
In diesem Artikel haben wir die ersten drei Phasen der Problemlösung mithilfe von maschinellem Lernen durchlaufen. Nach dem Einstellen der Aufgabe haben wir:
- Gelöschte und formatierte Rohdaten.
- Durchführung einer explorativen Analyse zur Untersuchung der verfügbaren Daten.
- Wir haben eine Reihe von Funktionen entwickelt, die wir für unsere Modelle verwenden werden.
, , .
Scikit-Learn , .