Was passiert, wenn Ihr Produkt in einem anderen Land mit eigenen sprachlichen und kulturellen Merkmalen verkauft wird? Höchstwahrscheinlich erwartet ihn die Lokalisierung. In den meisten Fällen müssen die Ressourcendateien nur so übersetzt werden, dass die Menüs und Schnittstellenelemente in der dem Benutzer vertrauten Sprache vorliegen. Was ist jedoch zu tun, wenn die Grundlage Ihres Verkaufs Daten sind, von denen es viele gibt? Sie kommen ständig in großen Mengen an und erfordern eine regelmäßige Übersetzung. Und nicht nur eine Sprache, sondern mehrere Sprachen gleichzeitig.
Unter dem Schnitt finden Sie eine Geschichte darüber, wie dieses Problem in 2GIS gelöst wurde. Ich werde es Ihnen am Beispiel des letzten Falles mit Dubai erzählen, aber die Praktiken sind für jede Sprache anwendbar.
Über Arabisch
Diese ganze Geschichte begann mit der Tatsache, dass 2GIS in Dubai gestartet wurde, wo zwei Sprachen verwendet werden: Arabisch und Englisch.
Hohe Datengenauigkeit ist der wichtigste Wert des Unternehmens. Dies wird durch Handarbeit von Kartographen und Spezialisten vor Ort erreicht. In Dubai, wo sowohl lokale Spezialisten als auch Endbenutzer Englisch sprechen, wurden die Daten zunächst nur darin eingegeben. Während des Wachstumsprozesses beschlossen sie, nicht dort anzuhalten und die arabische Sprache hinzuzufügen.
Fidschi
Für die Arbeit der Kartographen haben wir unsere eigene Software. Dieses Ding heißt Fidschi und dient als Master-System zum Sammeln von Kartendaten.
Wir haben bereits geschrieben, wie Fidschi Kartographen hilft, Häuser zu bearbeiten und Straßen zu zeichnen. Die nach der Verarbeitung und Vorbereitung aus Fidschi hochgeladenen Daten gehen an das Endprodukt, um den Benutzern zu gefallen. In dem Artikel spreche ich genau darüber, was wir in Fidschi zum Bearbeiten / Speichern / Anzeigen mehrsprachiger Daten implementiert haben.
Bedingungen
Im Team verwenden wir spezifisches Vokabular. Nachfolgend finden Sie vier Beispiele ↓
Das System unterstützt die Arbeit mit zwei Arten von Sprachen:
Metadatensprache - Die Sprache, in der alle Benutzersteuerelemente angezeigt werden: Benutzeroberfläche, Metadaten.
Datensprache - Eine Sprache, in der die Werte der Attribute von Geoobjekten, einigen Verzeichnissen und Klassifizierern angezeigt werden.
Sprachen sind an Gebiete gebunden. Ein Gebiet kann zwei Arten von Sprachen haben:
Die Hauptsprache des Gebiets ist die in diesem Gebiet offiziell angenommene Sprache.
Die zusätzliche Sprache des Gebiets ist die Sprache, in der wir das Produkt veröffentlichen möchten. Es kommt zusätzlich zum Haupt.
Sprachen und Dialekte
Dialekte, die in verschiedenen Regionen des Landes verwendet werden, können erheblich variieren. Daher werden in einigen Systemen der Kern der Sprache (= die Basisversion) und die Dialekte separat gespeichert und dann beim Entladen ihrer Merjats. Dieser Ansatz schien uns sehr kompliziert zu sein, daher haben wir beschlossen, jeden Dialekt als eigenständige Sprache zu betrachten.
Nuancen in Bezug auf arabische Sprachen und Dialekte. Für jede Sprache müssen Sie ein Wagenrichtungsflag mit zwei Werten eingeben: von links nach rechts und von rechts nach links. Standardmäßig sollte sich der Wagen von links nach rechts bewegen. Wenn der Wert von rechts nach links eingestellt ist, müssen Sie die Richtung des Wagens für alle bearbeitbaren mehrsprachigen Felder ändern. Wie dies in den Endprodukten gemacht wurde, wurde
hier geschrieben. Wir mussten ungefähr das Gleiche tun.
An Territorien ausrichten
Unsere ganze Welt ist in bestimmte Gebiete unterteilt - dies können Länder, Regionen, Regionen sein. Für jedes Gebiet geben wir mehrere Sprachen an, von denen eine als die Hauptsprache und die andere als zusätzliche Sprache betrachtet wird. Die Übersetzung erfolgt von der Primärsprache in weitere Sprachen.
Im Fall von Dubai haben wir beispielsweise Englisch als Hauptsprache beibehalten, da es viele Daten enthielt. Arabisch wurde optional gemacht.
Sprache eingeben und ändern
Damit die Kartografen bequem arbeiten können, haben wir unsere Benutzeroberfläche an den Stellen neu gestaltet, an denen mehrsprachige Eingaben gemeint sind.

In diesem Bild sehen Sie, dass wir die Sprachen in Registerkarten unterteilt haben, wobei die Hauptsprache ganz links ist und es dann weitere gibt.
Auf den Registerkarten weiterer Sprachen stehen nur die Felder zur Bearbeitung zur Verfügung, die ein Flag für die Notwendigkeit einer Übersetzung in der Datenbank aufweisen. Dies dient als Schutzmaßnahme und hilft, die Aufmerksamkeit des Benutzers auf die Übersetzung der erforderlichen Daten zu lenken. Alles andere wird in der Hauptsprache bearbeitet.

Das Bearbeiten von Daten in einer zusätzlichen Sprache ist möglicherweise nur erforderlich, wenn der Kartograf selbst mehrere Sprachen beherrscht und nicht auf die Hilfe eines Übersetzers zurückgreifen möchte. Für alle anderen gibt es CrowdIn.
Crowdin oder Stream-Transfer
Daher haben wir unseren Kartographen ermöglicht, Daten in verschiedenen Sprachen einzugeben. Es ist jedoch viel besser, die Übersetzungsaufgabe an Profis zu übergeben.
Das erste, was Ihnen beim Übersetzen der Anwendung einfällt, ist, die Ressourcendateien den Übersetzern zu übergeben und sie nach dem Übertragen wieder herunterzuladen.
In dieser Hinsicht hat uns die CrowdIn-Plattform sehr geholfen. Sie können Ihre Dateien an professionelle Übersetzer weiterleiten. Das einzige, was noch übrig war, war die Integration der übersetzten Daten in unser System.
Die Situation wird durch die Tatsache kompliziert, dass die Daten in einem kontinuierlichen Strom zu uns kommen, daher möchten wir kontinuierlich Übersetzungen erhalten.
Wir haben das System wie folgt optimiert: Wenn Änderungen in der Hauptsprache des Gebiets vorgenommen werden, laden wir die Änderungen zur Übersetzung in alle weiteren Sprachen dieses Gebiets hoch. Wir machen Ausnahmen für Fälle, in denen der Kartograf die Übersetzung selbst gemacht hat. Hier glauben wir, dass er versteht, was er tut, und dass es nicht notwendig ist, einen Dolmetscher anzuschließen.
Für jedes Verzeichnis oder Kartenobjekt haben wir eine End-to-End-Version, die mit jeder Datenaktualisierung erhöht wird. So können wir schnell alle Änderungen von einer bestimmten Version erhalten.
Das Versionsverwaltungssystem ist sehr einfach und effizient, hat jedoch einen erheblichen Nachteil: Tatsächlich haben wir eine einzige Warteschlange und können sie in keiner Weise verwalten. Unser Maximum ist es, die Version zu überspringen. Es besteht die Notwendigkeit, zu einer normalen Warteschlange zu wechseln, z. B. zu RabitMQ oder Kafka, aber die Hände sind noch nicht erreicht.
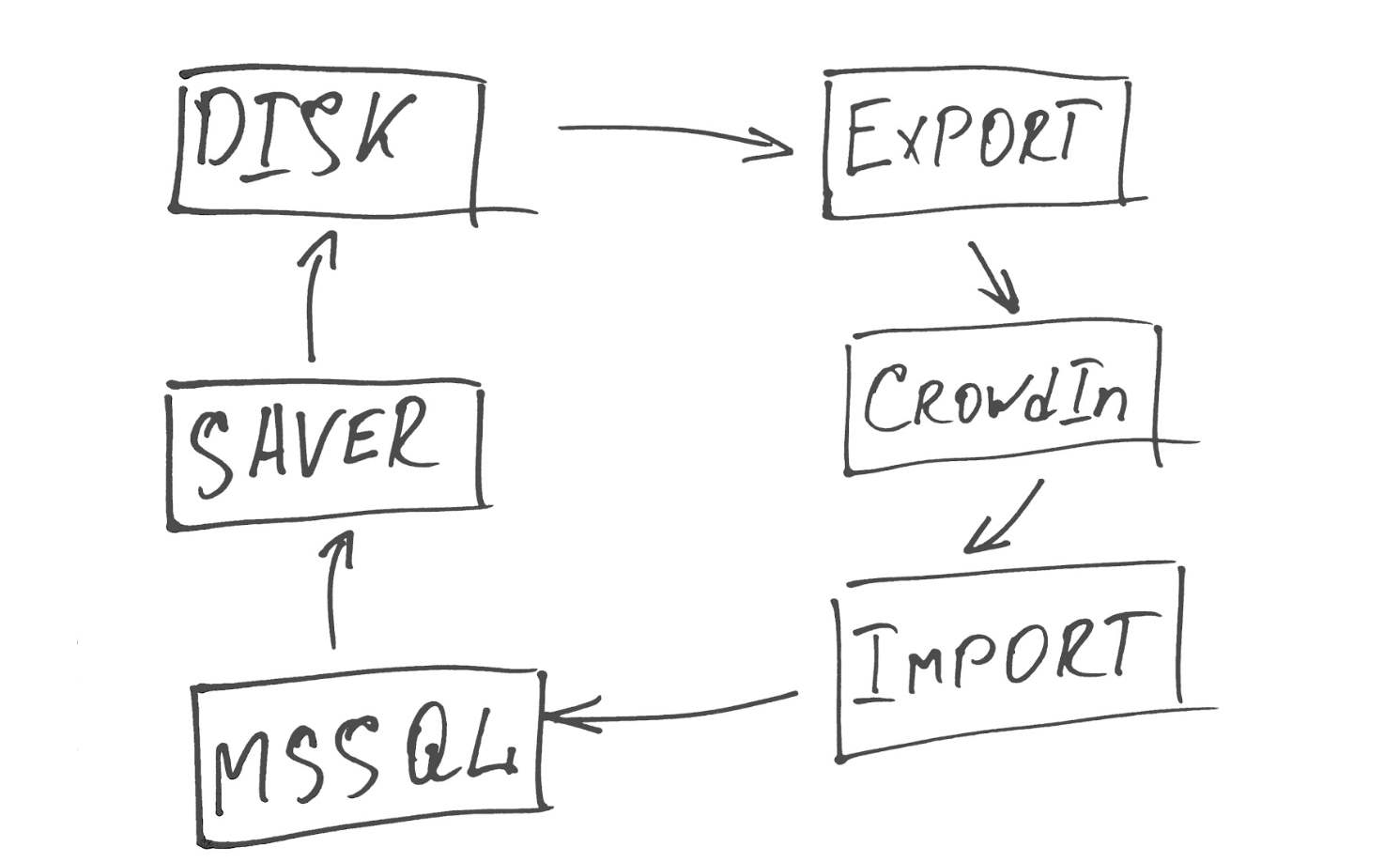
Um den Inhalt schnell zu aktualisieren, haben wir einen kleinen Dienst geschrieben, der in drei Streams funktioniert.
Der erste Stream (Saver) löscht alle Daten, die übersetzt werden müssen, und generiert daraus XML-Dateien.
Der zweite (Export) sendet sie an CrowdIn und fügt sie in das gewünschte Projekt ein, das die Hauptsprache angibt, aus der wir übersetzen, sowie eine Liste der Sprachen, in die übersetzt werden soll.
Der dritte (Import) fragt die CrowdIn-API regelmäßig nach Dateien ab, deren Übersetzung zu 100% vorgenommen und installiert wurde, und importiert die fertigen Dateien in unsere Datenbank.
Ohne Rechen geht das nicht. Wir sind über unser Datenversionierungssystem gestolpert.
Als wir die Übersetzung des Wortes heruntergeladen haben, wurde die Version der Daten aktualisiert und das Wort fiel erneut in die Übersetzung.
Um eine endlose Übersetzungsschleife zu vermeiden, haben wir begonnen, Daten aufzuzeichnen. Jedes übersetzte Wort ist markiert, wodurch das wiederholte Senden an CrowdIn entfällt.
Tutorial
Jetzt erzähle ich Ihnen, wie die Arbeit mit CrowdIn abläuft. Es gibt verschiedene Möglichkeiten, mit der Plattform zu arbeiten. Sie können beispielsweise Dateien in das Git-Repository hochladen und CrowdIn selbst saugt sie auf. Wir dachten jedoch, dass das Durcharbeiten der API bequemer aussieht.
CrowdIn hat ein ziemlich detailliertes
Tutorial , aber unten werde ich schreiben, wie wir es gemacht haben.
Wir benötigen einen API-Schlüssel, den wir jeder unserer Anforderungen hinzufügen, damit das System uns überprüft. Wir gehen in den Projekteinstellungen zur Registerkarte API und sehen uns an, was in der API-Schlüsselspalte geschrieben steht.

Dieser Schlüssel muss am Ende jeder Ihrer Plattformanforderungen hinzugefügt werden. Zum Beispiel so:
GET:
https://api.crowdin.com/api/project/{myLitleProject}/download/all.zip?key={project-key}2. Erstellen Sie einen Ordner, in den wir Dateien innerhalb des Projekts hochladen.
var uri = $"project/{_projectName}/add-directory?key={apiKey}"; var content = new MultipartFormDataContent { { new StringContent(crowdInDirectoryPath), "name" } }; return PostAsync(uri, content);
Es gibt einen kleinen ungeschickten Moment. Wir schreiben einen Dienst. Es wäre schön, wenn er zuerst prüft, ob der von uns benötigte Ordner vorhanden ist, bevor er versucht, ihn zu erstellen. CrowdIn bietet keine normale Möglichkeit, nach einem Ordner zu suchen. Daher senden wir eine Anfrage zur Erstellung. Wenn es nicht vorhanden ist, erstellt CrowdIn es und gibt den Code 200 zurück. Wenn ein Ordner vorhanden war, wird nichts erstellt und der Code 500 zurückgegeben.
3. Exportieren Sie Dateien. Die Funktion zum Hinzufügen von Dateien bietet viele Optionen und Parameter, wie und wo gelesen werden soll. Unten sehen Sie ein Beispiel dafür, wie wir Daten mit XML-Dateien laden.
BeispielWir speichern alle Daten, die wir übersetzen möchten, in XML-Dateien mit der folgenden Struktur.
<LocalizableDocument> <LocalizableValues> <LocalizableValue> … <Attributes> <LocalizableAttributeValue> <AttributeName/> <Value/> </LocalizableAttributeValue> </Attributes> </LocalizableValue> </LocalizableValues> </LocalizableDocument>
Damit CrowdIn analysieren kann, welche Daten aus der Datei übersetzt werden müssen, muss sie angegeben werden. Dazu müssen Sie ein Array von translatable_elements-Parametern mit den Pfaden zu den erforderlichen Elementen des Dokuments in den Inhalt schreiben. In unserem Fall sah es so aus:
var uri = $"project/{_projectName}/add-file?key={apiKey}"; var content = new MultipartFormDataContent { { new StringContent("/LocalizableDocument/LocalizableValues/LocalizableValue/Attributes/LocalizableAttributeValue/Value"), "translatable_elements[0]" } }; foreach (var filePath in filePaths) { var fileName = Path.GetFileName(filePath); var fileStream = File.OpenRead(filePath); var fileContent = new StreamContent(fileStream); content.Add(fileContent, $"files[{_crowdInDirectoryPath}/{fileName}]", fileName); } return PostAsync(uri, content);
Bitte beachten Sie: In der Dokumentation heißt es, dass CrowdIn maximal 20 Dateien gleichzeitig kauen kann, während die Größe einer Datei 100 MB nicht überschreiten sollte.
4. Wir finden heraus, welche Dateien wir vollständig übersetzt haben. Wir tun dies mit einem Befehl für eine bestimmte Sprache.
var uri = $"project/{_projectName}/language-status?key={apiKey}"; var content = new MultipartFormDataContent {{ new StringContent(langCode), "language" } }; return PostAsync(uri, content);
Die Plattform wird uns ungefähr so zurückgeben:
<item> <node_type>directory</node_type> <id>29812</id> <name>Version 1.0</name> <files> <item> <node_type>file</node_type> <id>29827</id> <name>strings.xml</name> <node_type>file</node_type> <phrases>7</phrases> <translated>0</translated> <approved>0</approved> <words>32</words> <words_translated>0</words_translated> <words_approved>0</words_approved> </item> </files> </item>
Hier interessieren uns die Werte <übersetzt /> und <genehmigt />. Der erste zeigt den Prozentsatz der übersetzten Zeilen in dieser Datei, der zweite den Prozentsatz der genehmigten Werte, wenn neben dem Übersetzer auch ein Prüfer am Workflow teilnimmt. Abhängig von unserem Workflow betrachten wir beispielsweise bei 100 das Dokument als übersetzt und genehmigt. Jetzt kann diese Datei wieder in uns importiert werden.
5. Importieren Sie die Datei zurück in unser System.
Dies erfolgt mit einer einfachen GET-Anfrage.
https://api.crowdin.com/api/project/{_projectName}/export-file?file={_crowdInDirectoryPath}/{fileName}&language={langCode}&key={project-key}
Die resultierende Datei wird deserialisiert und die Daten in unser System importiert.
Anstelle einer Schlussfolgerung
Im Allgemeinen ist das alles. Natürlich mussten wir die Anzeige der Signaturen auf der Fidschi-Karte noch verfeinern, damit sie in der richtigen Sprache angezeigt wurden, je nachdem, welches Gebiet der Kartograf jetzt regiert. Es war notwendig, mit anderen Systemen zu vereinbaren, wie wir sie mit mehrsprachigen Daten versorgen werden, aber dies ist eine andere Geschichte.
Infolgedessen erhielten wir den Service im Sinne von „eingeschaltet und vergessen“. Kartografen geben Daten ein, Übersetzer übersetzen, der Scheich ist zufrieden, der Dienst lädt die Daten bei Bedarf hoch und wir lösen dringendere Probleme, ohne darüber nachzudenken, wie unser System in mehreren Sprachen funktioniert.