Das Thema der heutigen Konversation ist das, was Python in all den Jahren seines Bestehens in der Arbeit mit Bildern gelernt hat. Zusätzlich zu den Oldies von ImageMagick und GraphicsMagick aus dem Jahr 1990 gibt es moderne effektive Bibliotheken. Zum Beispiel Pillow und produktiveres Pillow-SIMD. Ihr aktiver Entwickler Alexander Karpinsky (
homm ) von MoscowPython verglich verschiedene Bibliotheken für die Arbeit mit Bildern in Python, präsentierte Benchmarks und sprach über nicht offensichtliche Funktionen, die immer ausreichen. In diesem Artikel hilft Ihnen eine Abschrift des Berichts dabei, eine Bibliothek für Ihre Anwendung auszuwählen und sie so effizient wie möglich zu gestalten.
Über den Sprecher: Alexander Karpinsky arbeitet bei
Uploadcare und beschäftigt sich mit der schnellen Bildänderung im
laufenden Betrieb. Er ist an der Entwicklung von
Pillow beteiligt , einer beliebten Bibliothek für die Arbeit mit Bildern in Python, und entwickelt einen eigenen Zweig dieser Bibliothek,
Pillow-SIMD , der moderne Prozessoranweisungen für maximale Leistung verwendet.
Hintergrund
Der Image-Änderungsdienst von Uploadcare ist ein Server, der eine HTTP-Anforderung mit einer Image-ID und einigen Vorgängen empfängt, die ein Client ausführen muss. Der Server muss die Vorgänge abschließen und so schnell wie möglich reagieren. Der Client fungiert meistens als Browser.
Der gesamte Dienst kann als Wrapper um die Grafikbibliothek beschrieben werden. Die Qualität des gesamten Projekts hängt von der Qualität, Leistung und Benutzerfreundlichkeit der Grafikbibliothek ab. Es ist leicht zu erraten, dass Uploadcare Pillow als Grafikbibliothek verwendet.
Bibliotheken
Wir werden kurz untersuchen, welche Art von Grafikbibliotheken in Python im Allgemeinen vorhanden sind, um besser zu verstehen, was später erläutert wird.
Kissen
Kissengabel von PIL (Python Imaging Library). Dies ist ein sehr altes Projekt, das 1995 für Python 1.2 veröffentlicht wurde. Sie können sich vorstellen, wie alt er ist! Irgendwann wurde die Python Imaging Library aufgegeben und ihre Entwicklung gestoppt. Eine Gabel aus Kissen wurde hergestellt, um die Python Imaging Library auf modernen Systemen zu installieren und zu erstellen. Allmählich wuchs die Anzahl der Änderungen, die in der Python Imaging Library benötigt wurden, und Pillow 2.0 wurde veröffentlicht, wodurch Python 3 unterstützt wurde. Dies kann als Beginn eines separaten Lebens des Pillow-Projekts angesehen werden.
Pillow ist ein natives Modul für Python. Die Hälfte des Codes ist in C geschrieben, die andere Hälfte in Python. Die unterschiedlichsten Versionen von Python werden unterstützt: 2.7, 3.3+, PP, .
Pillow-SIMD
Dies ist meine Gabel aus Kissen, die im Mai 2016 herauskommt. SIMD steht für Single Instruction, Multiple Data
- Ein Ansatz, bei dem der Prozessor mit modernen Anweisungen eine größere Anzahl von Aktionen pro Zyklus ausführen kann.
Pillow-SIMD ist keine Gabel im klassischen Sinne, wenn ein Projekt beginnt, sein eigenes Leben zu führen. Dies ist ein Ersatz für Pillow, dh Sie installieren eine Bibliothek anstelle einer anderen, ändern keine Zeile in Ihrem Quellcode und erzielen mehr Leistung.
Pillow-SIMD kann mit SSE4-Anweisungen zusammengebaut werden (Standard). Dies ist eine Reihe von Anweisungen, die in fast allen modernen x86-Prozessoren enthalten sind. Pillow-SIMD kann auch mit dem AVX2-Befehlssatz zusammengebaut werden. Diese Anleitung beginnt mit der Haswell-Architektur, dh ungefähr ab 2013.
Opencv
Eine weitere Bibliothek für die Arbeit mit Bildern in Python, von der Sie wahrscheinlich gehört haben, ist
OpenCV (Open Computer Vision). Es funktioniert seit 2000. Python-Bindung ist enthalten. Dies bedeutet, dass die Bindung ständig relevant ist und keine Synchronität zwischen der Bibliothek selbst und der Bindung besteht.
Leider wird diese Bibliothek in PyPy noch nicht unterstützt, da OpenCV auf numpy basiert und numpy erst kürzlich unter PyPy funktioniert und in OpenCV PyPy immer noch nicht unterstützt wird.
VIPS
Eine weitere Bibliothek, die es wert ist, beachtet zu werden, ist VIPS. Die Hauptidee von
VIPS ist, dass Sie nicht das gesamte Bild in den Speicher laden müssen, um mit dem Bild zu arbeiten. Die Bibliothek kann einige kleine Teile laden, verarbeiten und speichern. Um Gigapixel-Bilder zu verarbeiten, müssen Sie also keine Gigabyte Speicherplatz aufwenden.
Dies ist eine ziemlich alte Bibliothek - 1993, aber sie hat ihre Zeit überholt. Lange Zeit war wenig darüber zu hören, aber seit kurzem tauchen VIPS-Ordner für verschiedene Sprachen auf, darunter für Go, Node.js, Ruby.
Lange wollte ich diese Bibliothek ausprobieren, um sie zu fühlen, aber es gelang mir aus einem sehr dummen Grund nicht. Ich konnte nicht herausfinden, wie man VIPS installiert, da die Bindung sehr kompliziert war. Aber jetzt (im Jahr 2017) wurde die Pyvips-Bindung vom Autor des VIPS selbst freigegeben, mit dem es keine Probleme mehr gibt. Die Installation und Verwendung von VIPS ist jetzt sehr einfach. Unterstützt: Python 2.7, 3.3+, RuPu, RuPuZ.
ImageMagick & GraphicsMagick
Wenn wir über die Arbeit mit Grafiken sprechen, können wir die alten Leute erwähnen -
ImageMagick- und
GraphicsMagick- Bibliotheken. Letzteres war ursprünglich eine Abzweigung von ImageMagick mit höherer Leistung, aber jetzt scheint ihre Leistung gleich zu sein. Soweit ich weiß, gibt es keine weiteren grundlegenden Unterschiede zwischen ihnen. Daher können Sie genau das verwenden, das Sie bevorzugen.
Dies sind die ältesten Bibliotheken, die ich heute (1990) erwähnt habe. Während dieser ganzen Zeit gab es mehrere Ordner für Python, und fast alle von ihnen sind inzwischen sicher gestorben. Von denen, die verwendet werden können, gibt es:
- Zauberstabbindung, die auf ctypes basiert, aber auch nicht mehr aktualisiert wird.
- Die pgmagick-Bindung verwendet Boost.Python, wird also sehr lange kompiliert und funktioniert in PyPy nicht. Aber trotzdem kannst du es benutzen, ich würde sagen, dass es Wand vorzuziehen ist.
Leistung
Wenn wir über die Arbeit mit Bildern sprechen, interessiert uns (zumindest für mich) als erstes die Leistung, da wir sonst mit unseren Händen etwas in Python schreiben könnten.
Leistung ist nicht so einfach. Sie können nicht einfach sagen, dass eine Bibliothek schneller ist als eine andere. Jede Bibliothek verfügt über eine Reihe von Funktionen, und jede Funktion arbeitet mit einer anderen Geschwindigkeit.
Dementsprechend ist es richtig, nur zu sagen, dass die Leistung einer Funktion in einer bestimmten Bibliothek höher oder niedriger ist. Oder Sie haben eine Anwendung, die bestimmte Funktionen benötigt, und Sie setzen einen Benchmark speziell für diese Funktionalität und sagen, dass diese und jene Bibliothek für Ihre Anwendung schneller (langsamer) funktioniert.
Es ist wichtig, das Ergebnis zu überprüfen.
Wenn Sie Benchmarks erstellen, ist es sehr wichtig, das erzielte Ergebnis zu betrachten. Auch wenn Sie auf den ersten Blick denselben Code geschrieben haben, bedeutet dies nicht, dass er derselbe ist.
Kürzlich bin ich in einem Artikel zum Vergleich der Leistung von Pillow und OpenCV auf diesen Code gestoßen:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
Es scheint dort und dort zu sein, BoxBlur, und dort und dort, Argument 3, aber tatsächlich ist das Ergebnis anders. Denn in Pillow (3) ist dies der Unschärferadius und in OpenCV ksize = (3, 3) die Kerngröße, dh grob gesagt der Durchmesser. In diesem Fall wäre der korrekte Wert für OpenCV 3 · 2 + 1, d. H. (7, 7).
Was ist das Problem?
Warum ist die Leistung bei der Arbeit mit Grafiken im Allgemeinen ein Problem? Da die Komplexität einer Operation von mehreren Parametern abhängt und die Komplexität meistens linear mit jedem von ihnen zunimmt. Und wenn es zum Beispiel drei dieser Faktoren gibt und die Komplexität linear von jedem abhängt, wird die Komplexität im Würfel erhalten.
Beispiel: Gaußsche Unschärfe in OpenCV.

Links ist der Radius 3, rechts - 30. Wie Sie sehen können, beträgt der Geschwindigkeitsunterschied mehr als das Zehnfache.
Als ich vor der Aufgabe stand, meiner Anwendung Gaußsche Unschärfe hinzuzufügen, war ich nicht glücklich, dass hypothetisch 900 ms für eine Operation aufgewendet werden konnten. Die Anwendung enthält Tausende solcher Vorgänge pro Minute, und es ist unpraktisch, so viel Zeit für einen Vorgang aufzuwenden. Daher habe ich das Problem untersucht und die Gaußsche Unschärfe in Pillow implementiert, die in Bezug auf den Radius in konstanter Zeit arbeitet. Das heißt, nur die Bildgröße beeinflusst die Leistung der Gaußschen Unschärfe.
Hauptsache hier ist aber nicht, dass etwas schneller oder langsamer funktioniert.
Ich möchte vermitteln, dass es beim Aufbau eines Systems wichtig ist, zu verstehen, von welchen Parametern die Komplexität der Ausgabe abhängt. Dann können Sie diese Parameter einschränken oder auf andere Weise mit dieser Komplexität umgehen.
Die wahrscheinlich häufigste Operation, die wir mit Bildern nach dem Öffnen ausführen, ist die Größenänderung.
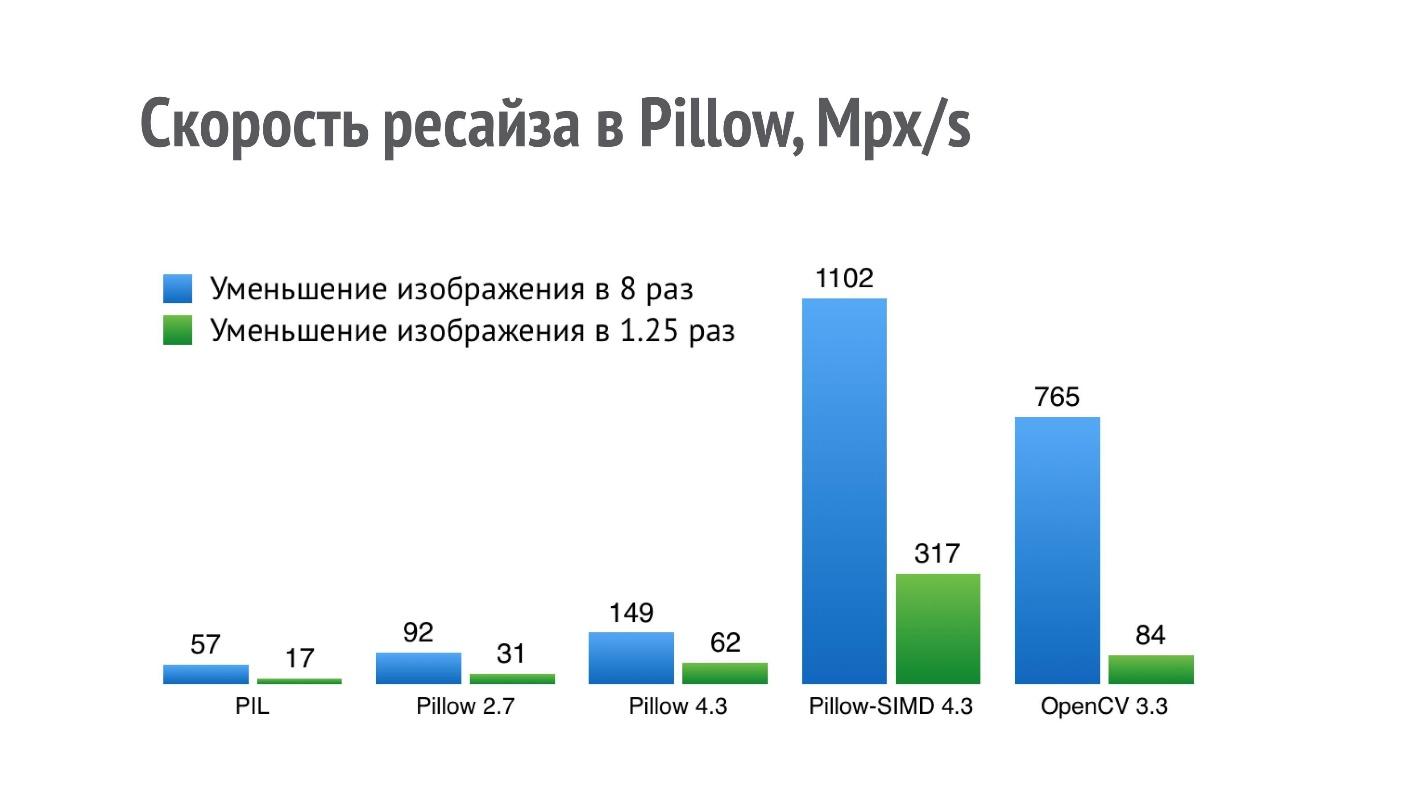
Die Grafik zeigt die Leistung (mehr ist besser) verschiedener Bibliotheken für den Vorgang, das Bild um das 8- und 1,25-fache zu reduzieren.
Für PIL bedeutet ein Ergebnis von 17 Mpx / s, dass das Foto von einem iPhone (12 Mpx) in weniger als einer Sekunde um das 1,25-fache reduziert werden kann. Eine solche Leistung reicht für eine seriöse Anwendung, die viele dieser Vorgänge ausführt, nicht aus.
Ich begann, die Leistung der Größenänderung zu optimieren, und in Pillow 2.7 gelang es mir, die Produktivität um das Doppelte und in Pillow 4.3 um das Dreifache zu steigern (die Version von Pillow 5.3 ist derzeit relevant, aber die Größenänderungsleistung ist dieselbe).
Die Größenänderung ist jedoch eine Sache, die sehr gut auf SIMD passt. Es nähert sich einer einzelnen Anweisung, mehreren Daten, und daher konnte ich in der aktuellen Version von Pillow-SIMD
die Größenänderungsgeschwindigkeit im Vergleich zur ursprünglichen Python Imaging Library mit denselben Ressourcen
um das 19-fache erhöhen .
Dies ist deutlich höher als die OpenCV-Größenänderungsleistung. Der Vergleich ist jedoch nicht ganz korrekt, da OpenCV eine etwas weniger hochwertige Methode zur Größenänderung mit einem Boxfilter verwendet und in Pillow-SIMD die Größenänderung mithilfe von Windungen implementiert wird.
Dies ist eine unvollständige Liste der Vorgänge, die in Pillow-SIMD im Vergleich zu normalem Pillow beschleunigt werden.
- Größe ändern: 4 bis 7 mal.
- Unschärfe: 2,8 mal.
- 3 × 3 oder 5 × 5: 11 maliges Aufbringen des Kerns.
- Multiplikation und Division durch Alpha-Kanal: 4 und 10 mal.
- Alpha-Zusammensetzung: 5 mal.
Ich habe bereits gesagt, dass man nicht sagen kann, dass eine Bibliothek schneller arbeitet als eine andere, aber Sie können einige Operationen zusammenstellen, die für Sie von Interesse sind. Ich habe eine Reihe von Operationen ausgewählt, die für meine Anwendung interessant sind, einen Benchmark erstellt und solche Ergebnisse erzielt.

Es stellte sich heraus, dass Pillow-SIMD bei diesem Set zweimal schneller funktioniert als Pillow. Ganz am Ende steht Wand (denken Sie daran, dass dies ImageMagick ist).
Aber ich war an etwas anderem interessiert - warum sind OpenCV und VIPS so ergebnisarm, weil es sich um Bibliotheken handelt, die auch im Hinblick auf die Leistung entwickelt wurden? Es stellte sich heraus, dass im Fall von OpenCV die mit pip installierte binäre OpenCV-Assembly mit einem langsamen JPEG-Codec zusammengestellt wurde (der Autor der Assembly wurde benachrichtigt, dieses Problem wurde bereits für 2018 gelöst). Es wurde mit libjpeg erstellt, während die meisten Systeme, zumindest auf Debian-Basis, libjpeg-turbo verwenden, das um ein Vielfaches schneller ist. Wenn Sie OpenCV selbst aus der Quelle erstellen, ist die Leistung höher.
Bei VIPS ist die Situation anders. Ich habe den Autor des VIPS kontaktiert, ihm diesen Benchmark gezeigt, und wir haben lange und fruchtbar korrespondiert. Danach fand der VIPS-Autor mehrere Stellen im VIPS selbst, an denen die Ausführung nicht auf dem optimalen Weg war, und korrigierte sie.
Dies passiert mit der Leistung, wenn Sie OpenCV aus den Quellen der aktuellen Version und VIPS aus dem bereits vorhandenen Master erstellen.
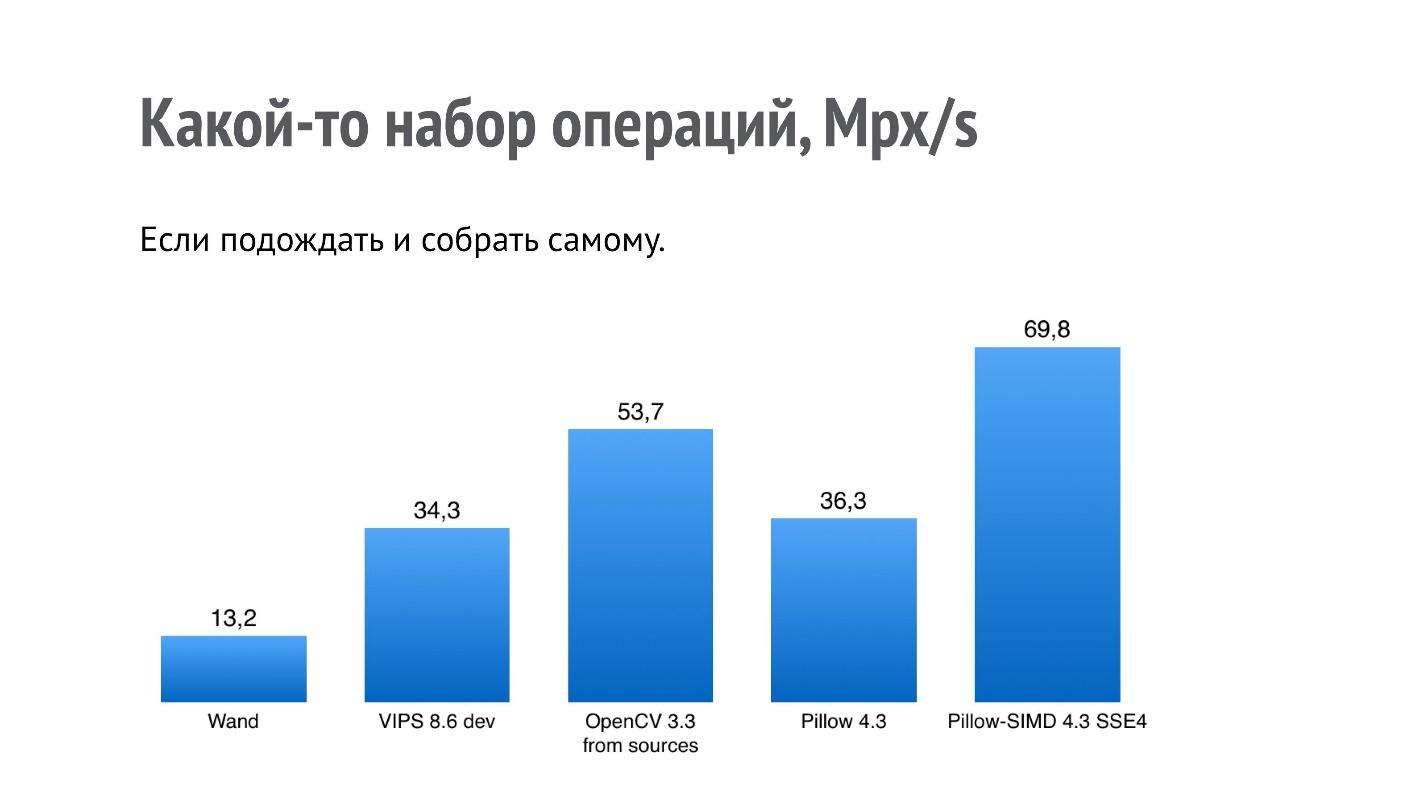
Selbst wenn Sie eine Art Benchmark finden, ist es nicht so, dass genau auf Ihrer Maschine alles mit dieser Geschwindigkeit funktioniert.
Reihe von Benchmarks
Alle Benchmarks, über die ich gesprochen habe, finden Sie auf
der Ergebnisseite . Dies ist ein separates Mini-Projekt, in dem ich Benchmarks schreibe, die ich selbst benötige, um Pillow-SIMD zu entwickeln, auszuführen und die Ergebnisse zu veröffentlichen.
GitHub hat ein
Projekt mit Test-Frameworks, in dem jeder seine eigenen Benchmarks anbieten oder vorhandene korrigieren kann.
Parallele Arbeit
Bisher habe ich über reine Leistung gesprochen, dh auf einem einzelnen Prozessorkern. Aber wir haben alle schon lange Zugang zu Systemen mit mehr Kernen, und ich würde sie gerne entsorgen. Hier muss ich sagen, dass Pillow tatsächlich die einzige Bibliothek von allen ist, die keine Aufgabenparallelisierung verwendet. Ich werde versuchen zu erklären, warum dies passiert. Alle anderen Bibliotheken in der einen oder anderen Form verwenden es.
Leistungsmetriken
In Bezug auf die Leistung interessieren uns 2 Parameter:
- Echtzeit der Ausführung einer Operation. Es gibt eine Operation (oder eine Folge von Operationen), und Sie fragen sich, zu welcher Echtzeit (Wanduhr) diese Folge ausgeführt wird. Dieser Parameter ist auf dem Desktop wichtig, auf dem sich ein Benutzer befindet, der den Befehl gegeben hat und auf das Ergebnis wartet.
- Durchsatz des gesamten Systems (Workflow). Wenn Sie eine Reihe von laufenden Vorgängen oder viele unabhängige Vorgänge haben und die Geschwindigkeit der Verarbeitung dieser Vorgänge auf Ihrer Hardware für Sie wichtig ist. Diese Metrik ist auf einem Server mit vielen Clients wichtiger, und Sie müssen sie alle bedienen. Die Zeit, die benötigt wird, um einen Client zu bedienen, ist natürlich wichtig, aber etwas geringer als die Gesamtbandbreite.
Basierend auf diesen beiden Metriken betrachten wir verschiedene Arten des Parallelbetriebs.
Parallele Arbeitsmethoden
1. Wenn Sie auf Anwendungsebene auf Anwendungsebene entscheiden, dass Vorgänge in verschiedenen Threads verarbeitet werden. Gleichzeitig ändert sich die tatsächliche Ausführungszeit einer Operation nicht, da wie zuvor ein Kern an einer Abfolge von Operationen beteiligt ist. Der Durchsatz des Systems wächst proportional zur Anzahl der Kerne, das heißt sehr gut.
2.
Auf der Ebene der Grafikoperationen - genau das ist in den meisten Grafikbibliotheken der Fall. Wenn eine Grafikbibliothek eine Operation empfängt, erstellt sie die erforderliche Anzahl von Threads in sich selbst, teilt eine Operation in mehrere kleinere auf und führt sie aus. Gleichzeitig wird die tatsächliche Ausführungszeit reduziert - eine Operation ist schneller. Der
Durchsatz wächst jedoch nicht linear mit der Anzahl der Kerne. Es gibt Operationen, die nicht parallel sind, und ein bemerkenswertes Beispiel ist die Dekodierung von PNG-Dateien - sie können in keiner Weise parallelisiert werden. Darüber hinaus entsteht ein Aufwand für das Erstellen von Threads und das Aufteilen von Aufgaben, bei denen die Bandbreite nicht linear wachsen kann.
3.
Auf der Ebene der Prozessorbefehle und -daten . Wir bereiten Daten auf spezielle Weise auf und verwenden spezielle Befehle, damit der Prozessor schneller mit ihnen arbeitet. Dies ist der SIMD-Ansatz, der tatsächlich in Pillow-SIMD verwendet wird. Die Laufzeit in Echtzeit nimmt ab, der Durchsatz steigt -
dies ist
eine Win-Win-Option .
Wie man Parallelarbeit kombiniert
Wenn wir irgendwie parallele Arbeit kombinieren möchten, funktioniert SIMD gut mit der Parallelisierung innerhalb einer Operation, und SIMD funktioniert gut mit der Parallelisierung innerhalb einer Anwendung.

Die Parallelisierung innerhalb der Anwendung und innerhalb des Vorgangs ist jedoch nicht miteinander kompatibel. Wenn Sie dies versuchen, erhalten Sie Nachteile aus beiden Ansätzen. Die Echtzeit des Vorgangs ist dieselbe wie auf einem Kern, und der Durchsatz des Systems steigt, jedoch nicht linear in Bezug auf die Anzahl der Kerne.
Multithreading
Wenn wir über Threads sprechen, schreiben wir alle in Python und wissen, dass es eine GIL hat, die verhindert, dass zwei Threads gleichzeitig ausgeführt werden. Python ist eine reine Single-Threaded-Sprache.
Dies ist natürlich nicht der Fall, da die GIL tatsächlich verhindert, dass zwei Threads in Python ausgeführt werden. Wenn der Code in einer anderen Sprache geschrieben ist und während des Betriebs keine internen Python-Strukturen verwendet, kann dieser Code die GIL freigeben und somit den Interpreter freigeben für andere Aufgaben.
Viele Grafikbibliotheken veröffentlichen GIL während ihrer Arbeit, darunter Pillow, OpenCV, Pyvips und Wand. Nur ein pgmagick ist nicht frei. Das heißt, Sie können sicher Threads erstellen, um einige Vorgänge auszuführen. Dies funktioniert parallel zum Rest des Codes.
Es stellt sich jedoch die Frage:
Wie viele Threads müssen erstellt werden?Wenn wir für jede Aufgabe, die wir haben, eine unendliche Anzahl von Threads erstellen, beanspruchen sie einfach den gesamten Speicher und den gesamten Prozessor - wir werden keine effektive Arbeit erhalten. Ich habe eine Sonderregel formuliert.
Regel N + 1
Für produktive Arbeit müssen Sie nicht mehr als N + 1 Worker erstellen, wobei N die Anzahl der Kerne oder Prozessorthreads auf dem Computer und der Worker der Prozess oder Thread ist, der an der Verarbeitung beteiligt ist.
Prozesse werden am besten verwendet, da selbst innerhalb desselben Interpreters Engpässe und Overhead auftreten.
In unserer Anwendung wird beispielsweise der N + 1-Instanz-Tornado verwendet, dessen Balance von ngnix ausgeführt wird. Wenn Tornado erwähnt wird, sprechen wir über den asynchronen Betrieb.
Asynchroner Betrieb
Die Zeit, in der die Grafikbibliothek tatsächlich nützliche Arbeit leistet - Bildverarbeitung - kann und sollte für die Eingabe / Ausgabe verwendet werden, wenn Sie sie in der Anwendung haben. Asynchrone Frameworks sind hier sehr relevant.
Aber es gibt ein Problem - wenn wir eine Art Verarbeitung aufrufen, wird sie synchron aufgerufen. Selbst wenn die Bibliothek in diesem Moment die GIL freigibt, ist die Ereignisschleife immer noch blockiert.
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
Glücklicherweise ist dieses Problem sehr einfach zu lösen, indem ein ThreadPoolExecutor mit einem einzelnen Thread erstellt wird, auf dem die Bildverarbeitung beginnt. Dieser Aufruf erfolgt bereits asynchron.
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
Im Wesentlichen wird hier eine Warteschlange mit einem Worker erstellt, die grafische Operationen ausführt, und die Ereignisschleife wird nicht blockiert und in einem anderen Thread leise parallel ausgeführt.
Eingabe / Ausgabe
Ein weiteres Thema, das ich in der Diskussion der grafischen Operationen ansprechen möchte, ist die Eingabe / Ausgabe. Tatsache ist, dass wir selten Bilder mit einer Grafikbibliothek erstellen. Meistens öffnen wir Bilder, die von Benutzern zu uns gekommen sind, in Form von codierten Dateien (JPEG, PNG, BMP, TIFF usw.).
Dementsprechend sollte die Grafikbibliothek zum Erstellen einer guten Anwendung einige Extras für die Eingabe / Ausgabe von Dateien enthalten.
Faules Laden
Das erste derartige Brötchen ist das faule Laden. Wenn Sie beispielsweise in Pillow ein Bild öffnen, erfolgt in diesem Moment keine Dekodierung des Bildes. Sie erhalten ein Objekt zurück, das so aussieht, als ob das Bild bereits geladen ist und funktioniert. Sie können sich die Eigenschaften ansehen und anhand der Eigenschaften dieses Bildes entscheiden, ob Sie bereit sind, weiter damit zu arbeiten, wenn der Benutzer beispielsweise ein Gigapixel-Bild heruntergeladen hat, um Ihren Dienst zu unterbrechen.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
Wenn Sie entscheiden, was als Nächstes zu tun ist, wird dieses Bild mithilfe des expliziten oder impliziten Aufrufs zum Laden dekodiert. Bereits zu diesem Zeitpunkt wird die erforderliche Speichermenge zugewiesen.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
Defekter Bildmodus
Das zweite Element, das für die Arbeit mit benutzergenerierten Inhalten benötigt wird, ist der Modus für fehlerhafte Bilder. Die Dateien, die wir von Benutzern erhalten, enthalten sehr häufig Inkonsistenzen mit dem Format, in dem sie codiert sind.
Diese Abweichungen treten aus verschiedenen Gründen auf. Manchmal handelt es sich um einen Übertragungsfehler über das Netzwerk, manchmal handelt es sich nur um eine Art krummen Codecs, der das Bild codiert. Standardmäßig löst Pillow nur eine Ausnahme aus, wenn Bilder angezeigt werden, die nicht zum Format passen.
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
Aber der Benutzer ist nicht dafür verantwortlich, dass sein Bild kaputt ist, er möchte immer noch das Ergebnis erhalten. Glücklicherweise hat Pillow einen defekten Bildmodus. Wir ändern eine Einstellung und Pillow versucht, alle im Bild enthaltenen Dekodierungsfehler maximal zu ignorieren. Dementsprechend sieht der Benutzer zumindest etwas.
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

Selbst ein zugeschnittenes Bild ist immer noch besser als nichts - nur eine Seite mit einem Fehler.
Übersichtstabelle
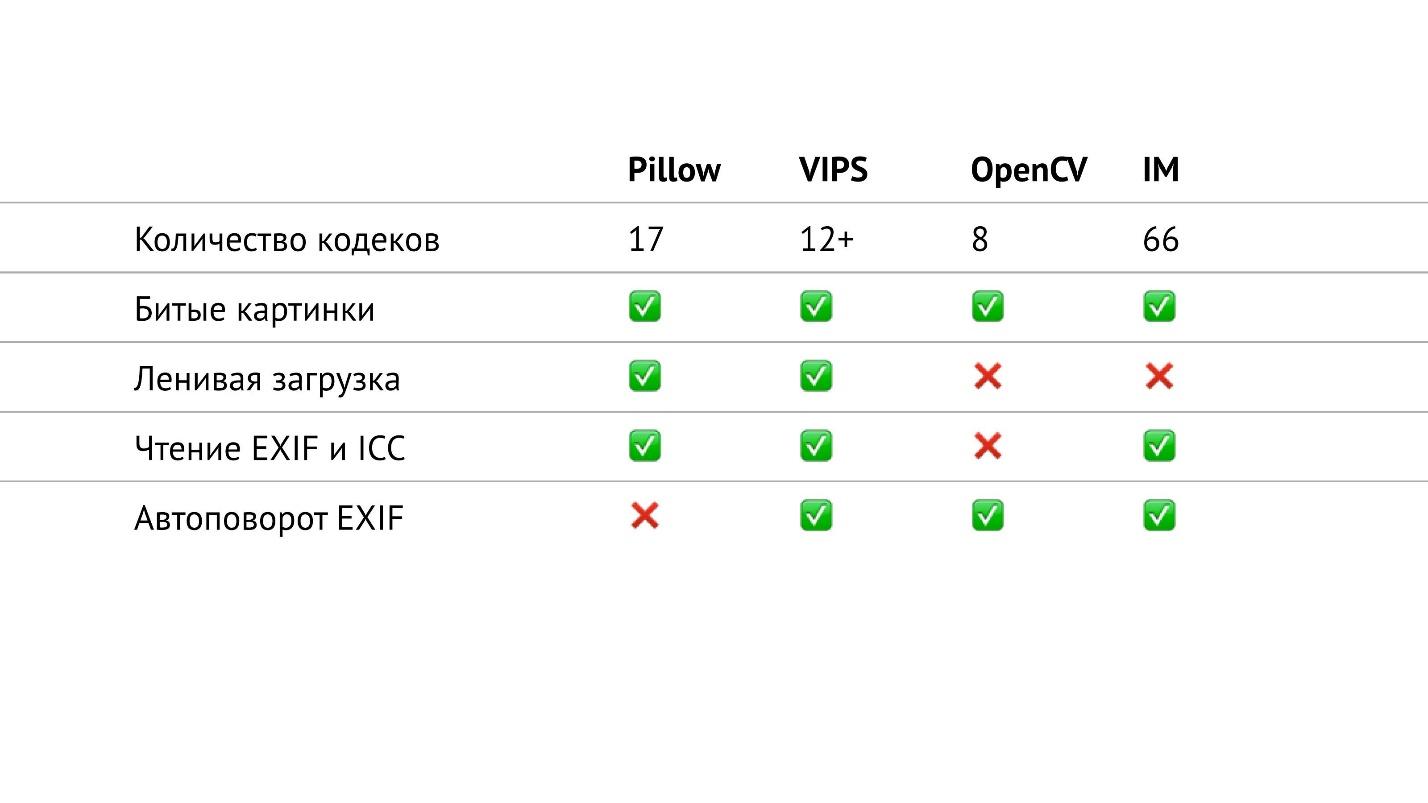
In der obigen Tabelle habe ich alles, was mit Eingabe / Ausgabe zu tun hat, in den Bibliotheken gesammelt, über die ich spreche. Insbesondere habe ich die Anzahl der Codecs in verschiedenen Formaten gezählt, die sich in den Bibliotheken befinden. Es stellte sich heraus, dass sie in OpenCV am wenigsten sind, in ImageMagick am meisten. Es scheint, dass Sie in ImageMagick jedes Bild öffnen können, auf das Sie stoßen. VIPS verfügt über 12 native Codecs, VIPS kann jedoch ImageMagick als Zwischenstufe verwenden. Ich habe nicht getestet, wie das funktioniert, hoffe es ist nahtlos.
Kissen hat 17 Codecs. Dies ist jetzt die einzige Bibliothek, in der EXIF nicht automatisch gedreht wird. Dies ist jedoch ein kleines Problem, da Sie EXIF selbst lesen und das Bild entsprechend drehen können. Dies ist eine Frage eines kleinen Ausschnitts, der leicht zu googeln ist und maximal 20 Zeilen benötigt.
Funktionen von OpenCV
Wenn Sie sich diese Tabelle genau ansehen, können Sie feststellen, dass in OpenCV tatsächlich nicht alles so gut mit Eingabe / Ausgabe ist. Es hat die geringste Anzahl von Codecs, kein verzögertes Laden, und Sie können EXIF und das Farbprofil nicht lesen.
Das ist aber noch nicht alles. In der Tat hat OpenCV mehr Funktionen. Wenn wir einfach ein Bild öffnen, dreht der Aufruf von
cv2.imread(filename) die JPEG-Dateien gemäß EXIF (siehe Tabelle), ignoriert jedoch den Alphakanal von PNG-Dateien - ein ziemlich seltsames Verhalten!
Glücklicherweise hat OpenCV ein Flag:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) .
Wenn Sie das IMREAD_UNCHANGED-Flag angeben, verlässt OpenCV den Alphakanal für PNG-Dateien, hört jedoch auf, JPEG-Dateien gemäß EXIF zu drehen. Das heißt, dasselbe Flag wirkt sich auf zwei völlig unterschiedliche Eigenschaften aus. Wie aus der Tabelle hervorgeht, kann OpenCV EXIF nicht lesen, und es stellt sich heraus, dass bei diesem Flag JPEG überhaupt nicht gedreht werden kann.
Was ist, wenn Sie nicht im Voraus wissen, welches Format Ihr Bild hat und Sie sowohl den Alphakanal für PNG als auch die automatische Drehung für JPEG benötigen? Nichts zu tun - OpenCV funktioniert so nicht.
Der Grund, warum OpenCV solche Probleme hat, liegt im Namen dieser Bibliothek. Es verfügt über zahlreiche Funktionen für Computer Vision und Bildanalyse. Tatsächlich ist OpenCV für die Arbeit mit verifizierten Quellen ausgelegt. Dies ist beispielsweise eine Überwachungskamera für den Außenbereich, die einmal pro Sekunde Bilder aufnimmt und dies 5 Jahre lang im gleichen Format und mit derselben Auflösung tut. Das E / A-Problem muss nicht variiert werden.
Personen, die OpenCV-Funktionen benötigen, benötigen Benutzerinhaltsfunktionen nicht wirklich.
Was aber, wenn Ihre Anwendung weiterhin Funktionen für die Arbeit mit Benutzerinhalten benötigt und Sie gleichzeitig die gesamte Leistung von OpenCV für die Verarbeitung und Statistik benötigen?

Die Lösung besteht darin, Bibliotheken zu kombinieren. Tatsache ist, dass OpenCV auf der Basis von Numpy erstellt wurde und Pillow über alle Mittel verfügt, um Bilder von Pillow in ein Numpy-Array zu exportieren. Das heißt, wir exportieren das numpy-Array, und OpenCV kann mit diesem Image wie mit seinem eigenen weiterarbeiten. Dies ist sehr einfach zu bewerkstelligen:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
Wenn wir mit OpenCV (Verarbeitung) zaubern, rufen wir eine andere Pillow-Methode auf und importieren das Bild von OpenCV zurück in das Pillow-Format. Dementsprechend kann wieder E / A verwendet werden.
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
Es stellt sich also heraus, dass wir die Eingabe / Ausgabe von Pillow und die Verarbeitung von OpenCV verwenden, dh wir nehmen das Beste aus den beiden Welten.
Ich hoffe, dies hilft Ihnen beim Erstellen einer geladenen Grafikanwendung.
Sie können einige andere Entwicklungsgeheimnisse in Python lernen, aus unschätzbaren und manchmal unerwarteten Erfahrungen lernen und vor allem Ihre Aufgaben sehr bald in Moscow Python Conf ++ besprechen. Achten Sie beispielsweise auf solche Namen und Themen im Zeitplan.
- Donald Whyte mit einer Geschichte darüber, wie man Mathematik mit gängigen Bibliotheken, Tricks und List zehnmal schneller macht, und der Code ist verständlich und wird unterstützt.
- Bei Andrei Popov geht es darum, eine große Datenmenge zu sammeln und auf Bedrohungen zu analysieren.
- Ephraim Matosyan erklärt Ihnen in seinem Bericht „Machen Sie Python wieder schnell“, wie Sie die Leistung des Dämons steigern können, der Nachrichten vom Bus verarbeitet.
Eine vollständige Liste der Themen, die am 22. und 23. Oktober hier besprochen werden , ist Zeit, sich anzumelden.