Hallo allerseits!
Während
Leonid sich auf seine erste
offene Lektion in unserem
Linux-Administrator- Kurs vorbereitet, sprechen wir weiterhin über das Laden des Linux-Kernels.
Lass uns gehen!
Verstehen, wie ein System ohne Fehler funktioniert - Vorbereiten, um die unvermeidlichen Ausfälle zu beheben
Der älteste Witz im Open-Source-Bereich ist die Aussage, dass „der Code sich selbst dokumentiert“. Die Erfahrung hat gezeigt, dass das Lesen von Quellcode dem Abhören von Wettervorhersagen gleicht: Intelligente Menschen gehen immer noch nach draußen und schauen in den Himmel. Im Folgenden finden Sie Tipps zum Überprüfen und Untersuchen des Linux-Systemstarts mit bekannten Debugging-Tools. Eine Analyse des Startvorgangs eines gut funktionierenden Systems bereitet Benutzer und Entwickler auf die Lösung unvermeidlicher Abstürze vor.
Einerseits ist der Downloadvorgang überraschend einfach. Der Kernel des Betriebssystems (Kernel) läuft Single-Threaded und synchron auf einem Kern (Kern), was selbst für einen erbärmlichen menschlichen Verstand verständlich erscheint. Aber wie startet der Kernel des Betriebssystems? Welche Funktionen haben initrd (
eine RAM-Disk für die Erstinitialisierung ) und Bootloader? Und warten Sie, warum leuchtet die LED am Ethernet-Port immer?

Lesen Sie weiter, um Antworten auf diese und einige andere Fragen zu erhalten. Der Code für die beschriebenen Demos und Übungen ist auch auf
GitHub verfügbar.
Start des Startvorgangs: Status AUSWake-on-LANDer Status AUS bedeutet, dass das System nicht mit Strom versorgt wird, oder? Scheinbare Einfachheit täuscht. Beispielsweise leuchtet die Ethernet-LED auch in diesem Zustand, da Wake-on-LAN (WOL, Wake-up auf [Signal von] LAN) in Ihrem System eingeschaltet ist. Stellen Sie sicher, indem Sie schreiben:
$# sudo ethtool <interface name>
Wobei es stattdessen beispielsweise eth0 sein kann (ethtool befindet sich in gleichnamigen Linux-Paketen). Wenn das "Wake-on" in der Ausgabe g anzeigt, können Remote-Hosts das System durch Senden von
MagicPacket starten . Wenn Sie Ihr System nicht selbst aus der Ferne einschalten und anderen diese Möglichkeit geben möchten, deaktivieren Sie WOL im System-BIOS-Menü oder verwenden Sie:
$# sudo ethtool -s <interface name> wol d
Ein Prozessor, der auf MagicPacket reagiert, kann ein
Baseboard Management Controller (BMC) oder Teil einer Netzwerkschnittstelle sein.
Intel Management Engine, Platform Controller Hub und MinixBMC ist nicht der einzige Mikrocontroller (MCU), der ein nominell ausgeschaltetes System „abhören“ kann. X86_64-Systeme verfügen über das IME-Softwarepaket (Intel Management Engine) für die Remote-Systemverwaltung. Eine Vielzahl von Geräten, von Servern bis hin zu Laptops, verfügen über Technologien
mit Funktionen wie KVM Remote Control oder Intel Capability Licensing Service. Laut dem
eigenen Tool von
Inte l hat
IME nicht gepatchte Schwachstellen. Die schlechte Nachricht ist, dass das Deaktivieren von IME schwierig ist. Trammell Hudson hat
das me_cleaner-Projekt erstellt, das einige der ungeheuerlichsten IME-Komponenten wie den eingebetteten Webserver
löscht. Gleichzeitig besteht jedoch die Möglichkeit, dass die Verwendung des Projekts das System, auf dem es ausgeführt wird, in einen Baustein verwandelt.
Die IME-Firmware und das darauf folgende System Management Mode (SMM) -Programm basieren auf
dem Minix-Betriebssystem und werden auf einem separaten Platform Controller Hub-Prozessor ausgeführt, nicht auf der Haupt-CPU des Systems. Anschließend startet SMM das UEFI-Programm (Universal Extensible Firmware Interface) auf dem Hauptprozessor, über das bereits mehrmals
geschrieben wurde . Die Coreboot-Gruppe startete bei Google ein spektakulär ehrgeiziges
NERF- Projekt
(Non-Extensible Reduced Firmware) , das nicht nur UEFI, sondern auch frühe Komponenten des Linux-Benutzerbereichs wie systemd ersetzen soll. In der Zwischenzeit warten wir auf die Ergebnisse. Linux-Benutzer können Laptops von Purism, System76 oder Dell kaufen, auf denen
IME deaktiviert ist. Außerdem können wir auf Laptops mit einem
64-Bit-ARM-Prozessor hoffen.
Lader
Was macht die bootfähige Firmware neben dem Starten der verdächtigen Spyware? Die Aufgabe des Bootloaders besteht darin, dem gerade eingeschalteten Prozessor die erforderlichen Ressourcen zur Verfügung zu stellen, um ein Allzweckbetriebssystem wie Linux auszuführen. Während des Einschaltens gibt es nicht nur virtuellen Speicher, sondern auch DRAM, bis der Controller angehoben wird. Der Bootloader schaltet dann die Netzteile ein und durchsucht die Busse und Schnittstellen, um das Kernel-Image und das Root-Dateisystem zu finden. Beliebte Bootloader wie U-Boot und GRUB unterstützen sowohl gängige Schnittstellen wie USB, PCI und NFS als auch andere speziellere Embedded-Geräte wie NOR- und NAND-Flash. Loader interagieren auch mit Sicherheitshardwaregeräten wie dem
Trusted Platform Module (TPM) , um vom Beginn des Downloads an eine Vertrauenskette einzurichten.
 Ausführen des U-Boot-Loaders in der Sandbox auf dem Build-Server.
Ausführen des U-Boot-Loaders in der Sandbox auf dem Build-Server.Der beliebte Open-Source-
U-Boot- Bootloader wird von Systemen vom Raspberry Pi bis zu Nintendo-Geräten, Autokarten und Chromebooks unterstützt. Es gibt kein Systemprotokoll, und wenn etwas schief geht, wird möglicherweise nicht einmal die Konsole ausgegeben. Um das Debuggen zu erleichtern, bietet das U-Boot-Team eine Sandbox zum Testen von Patches auf dem Build-Host oder sogar im Continuous Integration-System. Auf einem System mit gängigen Entwicklungstools wie Git und der installierten GNU Compiler Collection (GCC) ist das Verständnis der U-Boot-Sandbox einfach.
$# git clone git://git.denx.de/u-boot; cd u-boot $# make ARCH=sandbox defconfig $# make; ./u-boot => printenv => help
Das ist alles: Sie haben U-Boot auf x86_64 gestartet und können knifflige Funktionen testen, z. B. die Neupartitionierung
fiktiver Speichergeräte , die TPM-basierte Manipulation geheimer Schlüssel und den Hotplug von USB-Geräten. Die U-Boot-Sandbox kann innerhalb des GDB-Debuggers einstufig sein. Die Entwicklung mit der Sandbox ist zehnmal schneller als das Testen durch Überschreiben des Bootloaders auf der Platine. Außerdem kann die Sandstein-Sandbox durch Drücken von Strg + C wiederhergestellt werden.
Kernel-StartBooten der KernelversorgungNach Abschluss seiner Aufgaben wechselt der Bootloader zu dem Kernel-Code, den er in den Hauptspeicher geladen hat, und beginnt mit der Ausführung, wobei alle vom Benutzer angegebenen Befehlszeilenparameter übergeben werden. Welches Programm ist der Kernel? file / boot / vmlinuz zeigt, dass dies bzImage ist. Der Linux
-Quellbaum verfügt über
ein Tool zum Extrahieren von
vmlinux , mit dem Sie die Datei extrahieren können:
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux $# file vmlinux vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
Der Kernel ist eine
ELF- Binärdatei
(Executable and Linking Format) , wie Linux-User-Space-Programme. Dies bedeutet, dass wir binutils-Befehle wie readelf verwenden können, um es zu lernen. Vergleichen Sie zum Beispiel die folgenden Schlussfolgerungen:
$# readelf -S /bin/date $# readelf -S vmlinux
Die Liste der Partitionen in Binärdateien ist größtenteils ähnlich.
Der Kernel sollte also andere ELF Linux-Binärdateien starten ... Aber wie werden User Space-Programme ausgeführt? In der
main() Funktion, richtig? Nicht wirklich.
Vor dem Ausführen der Funktion
main() benötigen Programme einen Ausführungskontext, einschließlich Heap- (Heap) und Stack- (Stack) Speicher sowie Dateideskriptoren für
stdio ,
stdout und
stderr . User Space-Programme beziehen diese Ressourcen aus der Standardbibliothek (
glibc für die meisten Linux-Systeme). Beachten Sie Folgendes:
$# file /bin/date /bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a, stripped
ELF-Binärdateien haben einen Interpreter, genau wie Bash- und Python-Skripte. Es muss jedoch nicht durch
#! angegeben werden
#! wie in Skripten, da ELF ein natives Linux-Format ist. Der ELF-Interpreter versorgt die Binärdatei mit allen erforderlichen Ressourcen, indem er
_start() , eine Funktion, die im
glibc _start() verfügbar ist und über
GDB gelernt werden kann. Der Kernel hat offensichtlich keinen Interpreter und sollte sich selbstständig versorgen, aber wie?
Eine Studie zum Starten eines Kernels mit GDB liefert eine Antwort auf diese Frage. Installieren Sie zunächst das Kernel-Debugging-Paket, das die ungeschnittene Version von
vmlinux , z. B.
apt-get install linux-image-amd64-dbg . Oder kompilieren und installieren Sie Ihren eigenen Kernel aus einer Quelle, zum Beispiel gemäß den Anweisungen aus dem hervorragenden
Debian-Kernel-Handbuch .
gdb vmlinux gefolgt von
info files zeigt den ELF-Abschnitt
init.text .
init.text den Start der Programmausführung in
init.text mit
l *(address) , wobei address der hexadezimale Start von
init.text . GDB gibt an, dass der x86_64-Kernel in der
arch/x86/kernel/head_64.S gestartet wird. Dort finden wir die Build-Funktion
start_cpu0() und den Code, der den Stack explizit erstellt und zImage dekomprimiert, bevor
x86_64 start_kernel() . 32-Bit-ARM-Kerne haben einen ähnlichen
arch/arm/kernel/head.S. start_kernel() arch/arm/kernel/head.S. start_kernel() ist architekturunabhängig, daher befindet sich die Funktion im Kernel
init/main.c Wir können sagen, dass
start_kernel() eine echte
main() Linux-Funktion ist.
Von start_kernel () zu PID 1Kernel-Hardware-Manifest: ACPI-Tabellen und GerätebäumeBeim Booten benötigt der Kernel zusätzlich zum Prozessortyp, für den er kompiliert wurde, Informationen zur Hardware. Die Anweisungen im Code werden durch Konfigurationsdaten ergänzt, die separat gespeichert werden. Es gibt zwei Hauptmethoden zum Speichern von Daten: Gerätebäume und
ACPI-Tabellen . Aus diesen Dateien ermittelt der Kernel, welche Geräte bei jedem Start ausgeführt werden müssen.
Bei eingebetteten Geräten ist der Gerätebaum (DU) ein Manifest der installierten Geräte. DU ist eine Datei, die gleichzeitig mit der
vmlinux kompiliert wird und sich normalerweise zusammen mit
vmlinux in / boot
vmlinux . Um zu sehen, was sich im binären Gerätebaum auf dem ARM-Gerät befindet, verwenden Sie einfach den Befehl
strings aus dem binutils-Paket in der Datei, deren Name
/boot/*.dtb , da
dtb die Binärdatei des Gerätebaums (Device-Tree Binary) bedeutet. Sie können die Fernbedienung ändern, indem Sie die JSON-ähnlichen Dateien bearbeiten, aus denen sie besteht, und den speziellen dtc-Compiler neu starten, der mit der Kernelquelle bereitgestellt wird. DU ist eine statische Datei, deren Pfad normalerweise von Bootloadern in der Befehlszeile an den Kernel übergeben wird. In den letzten Jahren wurde jedoch eine
Gerätebaumüberlagerung hinzugefügt, in der der Kernel nach dem Laden dynamisch zusätzliche Fragmente als Reaktion auf Hotplug-Ereignisse laden kann.
Die x86-Familie und viele ARM64-Geräte auf Unternehmensebene verwenden den alternativen
ACPI- Mechanismus (Advanced Configuration and Power Interface
) . Im Gegensatz zur Fernbedienung werden ACPI-Informationen im virtuellen Dateisystem
/sys/firmware/acpi/tables , das vom Kernel beim Start durch Zugriff auf das interne ROM erstellt wird. Verwenden
acpidump zum Lesen von ACPI-Tabellen den Befehl
acpidump aus dem Paket
acpica-tools . Hier ist ein Beispiel:
 ACPI-Tabellen auf Lenovo Laptops sind für Windows 2001 bereit.
ACPI-Tabellen auf Lenovo Laptops sind für Windows 2001 bereit.Ja, Ihr Linux-System ist für Windows 2001 bereit, wenn Sie es installieren möchten. ACPI verfügt sowohl über Methoden als auch über Daten, im Gegensatz zur Fernbedienung, die eher einer Hardwarebeschreibungssprache ähnelt. ACPI-Methoden sind nach dem Start weiterhin aktiv. Wenn Sie beispielsweise den Befehl acpi_listen (aus dem apcid-Paket) ausführen und dann den Deckel des Laptops schließen und öffnen, werden Sie feststellen, dass die ACPI-Funktionalität die ganze Zeit über funktioniert hat. Temporäres und dynamisches
Umschreiben von ACPI-Tabellen ist möglich, aber eine permanente Änderung erfordert eine Interaktion mit dem BIOS-Menü beim Booten oder Flashen des ROM. Anstelle dieser Komplexität sollten Sie möglicherweise nur
coreboot installieren , einen Ersatz für Open Source-Firmware.
Von start_kernel () zum User Space
Der Code in
init/main.c ist überraschend leicht zu lesen und trägt seltsamerweise immer noch das ursprüngliche Copyright von Linus Torvalds von 1991-1992. Linien gefunden in
dmesg | head dmesg | head laufenden Systems stammt im Wesentlichen aus dieser Quelldatei. Die erste CPU wird vom System registriert, die globalen Datenstrukturen werden initialisiert, nacheinander werden der Scheduler, die Interrupt-Handler (IRQs), die Timer und die Konsole ausgelöst. Alle Zeitstempel vor dem Ausführen von
timekeeping_init() sind Null. Dieser Teil der Kernelinitialisierung ist synchron, dh die Ausführung erfolgt nur in einem Thread. Funktionen werden erst ausgeführt, wenn die letzte abgeschlossen und zurückgegeben ist. Infolgedessen ist die
dmesg Ausgabe auch zwischen den beiden Systemen vollständig reproduzierbar, sofern sie über dieselbe Fernbedienungs- oder ACPI-
dmesg verfügen. Linux verhält sich auch wie ein Echtzeitbetriebssystem (RTOS), das auf einer MCU wie QNX oder VxWorks ausgeführt wird. Diese Situation wird in der Funktion
rest_init() gespeichert, die zum Zeitpunkt ihrer Fertigstellung von
start_kernel() aufgerufen wird.
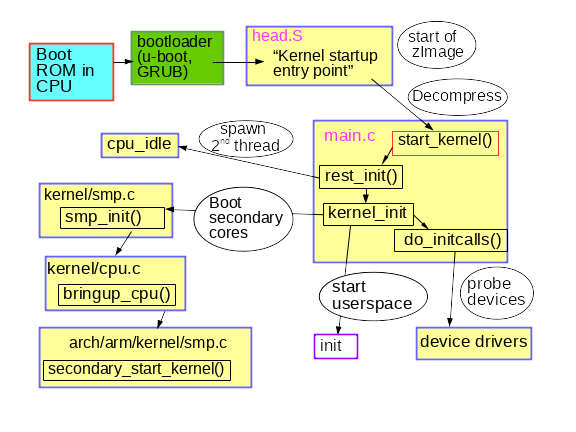 Eine kurze Beschreibung des frühen Kernel-Boot-Prozesses
Eine kurze Beschreibung des frühen Kernel-Boot-Prozesses
Der bescheidene Name
rest_init() erstellt einen neuen Thread, in dem
kernel_init() , der wiederum
do_initcalls() . Benutzer können den Betrieb von
initcalls überwachen, indem sie
initcalls_debug zur Kernel-Befehlszeile hinzufügen. Infolgedessen erhalten Sie die Entität
dmesg jedes Mal, wenn Sie die Funktion
initcall .
initcalls durchläuft sieben aufeinanderfolgende Ebenen: Early, Core, Postcore, Arch, Subsys, Fs, Device und Late. Der auffälligste Teil von
initcalls für Benutzer ist die Identifizierung und Installation von Peripheriegeräten des Prozessors: Busse, Netzwerk, Speicher, Anzeigen usw., begleitet vom Laden ihrer Kernelmodule.
rest_init() erstellt auch einen zweiten Thread im Bootprozessor, der zunächst
cpu_idle() während der Scheduler seine Arbeit verteilt.
kernel_init() richtet auch
symmetrisches Multiprocessing (SMP) ein. In modernen Kerneln finden Sie diesen Moment in der dmesg-Ausgabe in der Zeile "Sekundäre CPUs hochfahren ...". SMP stellt dann den CPU-Hot-Plug her, was bedeutet, dass er seinen Lebenszyklus mithilfe einer Zustandsmaschine verwaltet, die denen ähnelt, die in Geräten wie der automatischen Erkennung von USB-Speichersticks verwendet werden. Das Kernel-Energieverwaltungssystem fährt häufig einzelne Kerne (Kerne) herunter und weckt sie nach Bedarf, sodass auf einem nicht besetzten Computer wiederholt derselbe Hotplug-CPU-Code aufgerufen wird. Sehen Sie sich an, wie ein Energieverwaltungssystem einen CPU-Hotplug mit
einem BCC-Tool namens
offcputime.py .
Beachten Sie, dass der Code in
init/main.c fast ausgeführt wurde, als
smp_init() . Der Boot-Prozessor hat den größten Teil der einmaligen Initialisierung abgeschlossen, die andere Kernel nicht wiederholen müssen. Für jeden Kern müssen jedoch Threads erstellt werden, um Interrupts (IRQs), Workqueue, Timer und Energieereignisse auf jedem Kern zu steuern. Sehen Sie sich beispielsweise Prozessorthreads an, die Softirqs und Workqueues mit dem Befehl
ps -o psr. $\
wobei das PSR-Feld "Prozessor" bedeutet. Jeder Kern muss über eigene Timer und CPU-Hotplug-Handler verfügen.
Und schließlich, wie wird User Space gestartet? Gegen Ende sucht
kernel_init() nach einem
initrd , der den
init Prozess in seinem Namen starten kann. Wenn nicht, führt der Kernel
init selbst aus. Warum kann dann
initrd benötigt werden?
Early User Space: Wer hat initrd bestellt?Zusätzlich zum Gerätebaum gehört ein weiterer Init-Pfad zur Datei, der optional vom Kernel beim Booten bereitgestellt wird, zu
initrd .
initrd häufig in / boot zusammen mit der Datei bzImage vmlinuz auf x86 oder mit einem ähnlichen uImage- und Gerätebaum für ARM. Eine Liste der
intrd Inhalte kann mit dem Tool
lsinitramfs angezeigt werden, das Teil des Pakets
initramfs-tools-core . Das initrd-Distributionsimage enthält die Mindestverzeichnisse
/bin ,
/sbin und
/etc sowie Kernelmodule und -dateien in
/scripts . Alles sollte mehr oder weniger vertraut aussehen, da
initrd größtenteils dem vereinfachten Linux-Root-Dateisystem ähnelt. Diese Ähnlichkeit ist etwas irreführend, da fast alle ausführbaren Dateien in
/bin und
/sbin in ramdisk Symlinks zur
BusyBox-Binärdatei sind , wodurch die Verzeichnisse / bin und / sbin zehnmal kleiner sind als in
glibc .
Warum sollten Sie versuchen, eine
initrd erstellen, wenn nur einige Module geladen und
init auf einem regulären Root-Dateisystem ausgeführt werden? Betrachten Sie ein verschlüsseltes Root-Dateisystem. Die Entschlüsselung kann vom Laden des in
/lib/modules Root-Dateisystems gespeicherten Kernelmoduls abhängen ... und erwartungsgemäß in
initrd . Das Kryptomodul kann statisch in den Kernel kompiliert und nicht aus einer Datei geladen werden. Es gibt jedoch mehrere Gründe, dies abzulehnen. Beispielsweise kann die statische Kompilierung eines Kernels mit Modulen zu groß werden, um in den verfügbaren Speicher zu passen, oder die statische Kompilierung kann gegen Softwarelizenzbestimmungen verstoßen. Es überrascht nicht, dass Speichertreiber, Netzwerke und HIDs (menschliche Eingabegeräte) auch in
initrd - im Wesentlichen jeder Code, der kein erforderlicher Bestandteil des Kernels ist, der zum Mounten des Root-Dateisystems benötigt wird. Auch in initrd können Benutzer
ihren eigenen ACPI-Code für Tabellen speichern.
 Spaß mit Rescue Shell und Custom Initrd.
Spaß mit Rescue Shell und Custom Initrd.initrd auch hervorragend zum Testen von Dateisystemen und Speichergeräten. Setzen Sie die Testtools in
initrd und führen Sie die Tests aus dem Speicher aus, nicht aus dem Testobjekt.
Wenn
init , wird das System ausgeführt! Da die sekundären Prozessoren bereits ausgeführt werden, ist die Maschine zu einer asynchronen, ausgelagerten, unvorhersehbaren und leistungsstarken Kreatur geworden, die wir alle kennen und lieben. In der Tat gibt
ps -o pid,psr,comm -p an, dass der
ps -o pid,psr,comm -p für den Benutzerbereich nicht mehr auf dem Bootprozessor ausgeführt wird.
ZusammenfassungDer Linux-Startvorgang klingt angesichts der Menge der betroffenen Software selbst auf einem einfachen eingebetteten Gerät verboten. Auf der anderen Seite ist der Startvorgang recht einfach, da es keine übermäßige Komplexität gibt, die durch Verdrängung von Multitasking-, RCU- und Rennbedingungen verursacht wird. Wenn man nur den Kernel und PID 1 berücksichtigt, kann man die großartige Arbeit übersehen, die Bootloader und Hilfsprozessoren geleistet haben, um die Plattform für den Kernelstart vorzubereiten. Der Kernel unterscheidet sich sicherlich von anderen Linux-Programmen, aber die Verwendung von Tools zur Arbeit mit anderen ELF-Binärdateien hilft, seine Struktur besser zu verstehen. Das Studium eines funktionsfähigen Startvorgangs bereitet sich auf zukünftige Abstürze vor.
DAS ENDE
Wir warten wie gewohnt auf Ihre Kommentare und Fragen, entweder hier oder in unserer
offenen Lektion, in der Leonid umgehauen wird.