Essenz
Es stellt sich heraus, dass es ausreicht, nur einen solchen Befehlssatz auszuführen:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
und dann ein wenig mit einem Skript für die Nachbearbeitung polieren
python3 process_wikipedia.py
Das Ergebnis ist eine fertige .csv Datei mit Ihrem Körper.
Es ist klar, dass:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 kann in die gewünschte Sprache geändert werden, weitere Details hier [4] ;- Alle Informationen zu den
wikiextractor Parametern finden Sie im Handbuch (im Gegensatz zu Mana wurde anscheinend sogar das offizielle Dock nicht aktualisiert).
Ein Nachbearbeitungsskript konvertiert Wiki-Dateien in eine Tabelle wie die folgende:
| idx | article_uuid | Satz | gereinigter Satz | gereinigte Satzlänge |
|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Graf von Pentevre) Jean I de ... | jean i de châtillon count de pentevre jean i de cha ... | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | War unter dem Schutz von Robert de Vera, Graf O ... | wurde von robert de vera graph oxford bewacht ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Henry de Gromont, gr ... | Henry de Gromon Gras war jedoch dagegen ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Der König bot ihm ein weiteres wichtiges Merkmal als Ehefrau an ... | der könig bot seiner frau eine weitere wichtige person von fili ... | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean wurde freigelassen und kehrte 138 nach Frankreich zurück ... | Jean befreit Frankreich Jahr Hochzeit m ... | 52 |
article_uuid - ein pseudo-eindeutiger Schlüssel, dessen Ideenreihenfolge nach einer solchen Vorverarbeitung beibehalten werden sollte.
Warum
Vielleicht hat die Entwicklung von ML-Tools im Moment ein solches Niveau erreicht [8], dass buchstäblich ein paar Tage ausreichen, um ein funktionierendes NLP-Modell / eine funktionierende Pipeline zu erstellen. Probleme treten nur auf, wenn keine zuverlässigen Datensätze / fertigen Einbettungen / fertigen Sprachmodelle vorhanden sind. Der Zweck dieses Artikels ist es, Ihre Schmerzen ein wenig zu lindern, indem gezeigt wird, dass ein paar Stunden ausreichen, um die gesamte Wikipedia zu verarbeiten (theoretisch das beliebteste Korpus zum Trainieren von Worteinbettungen in NLP). Wenn ein paar Tage ausreichen, um ein einfaches Modell zu erstellen, warum sollten Sie dann viel mehr Zeit damit verbringen, Daten für dieses Modell abzurufen?
Das Prinzip des Skripts
wikiExtractor speichert Wiki-Artikel als durch <doc> wikiExtractor getrennten Text. Tatsächlich basiert das Skript auf der folgenden Logik:
- Erstellen Sie eine Liste aller Dateien in der Ausgabe.
- Wir teilen Dateien in Artikel;
- Entfernen Sie alle verbleibenden HTML-Tags und Sonderzeichen.
- Mit
nltk.sent_tokenize teilen nltk.sent_tokenize in Sätze; - Damit der Code nicht zu groß wird und lesbar bleibt, wird jedem Artikel eine eigene UUID zugewiesen.
Als Textvorverarbeitung ist es einfach (Sie können es leicht selbst schneiden):
- Nicht-Buchstaben-Zeichen löschen;
- Stoppwörter löschen;
Datensatz ist, was jetzt?
Hauptanwendung
In der Praxis muss man sich in NLP meistens mit der Aufgabe befassen, Einbettungen zu erstellen.
Verwenden Sie zur Lösung normalerweise eines der folgenden Tools:
- Fertige Vektoren / Einbettungen von Wörtern [6];
- Die internen Zustände von CNN, die auf Aufgaben wie das Definieren gefälschter Sätze / Sprachmodellierung / Klassifizierung trainiert wurden [7];
- Eine Kombination der obigen Methoden;
Darüber hinaus wurde mehrfach gezeigt [9], dass man als gute Basis für das Einbetten von Sätzen auch einfach gemittelte (mit ein paar kleinen Details, die wir jetzt weglassen werden) Wortvektoren verwenden kann.
Andere Anwendungsfälle
- Wir verwenden zufällige Sätze aus dem Wiki als negative Beispiele für den Triplettverlust.
- Wir trainieren Encoder für Sätze unter Verwendung der Definition von falschen Phrasen [10];
Ein paar Grafiken für das russische Wiki
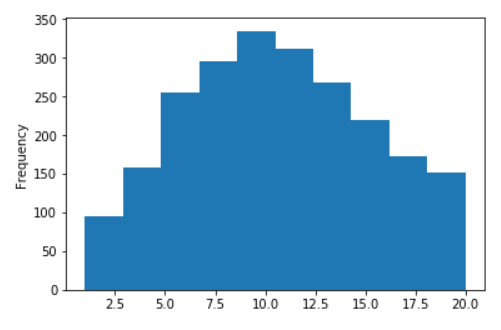
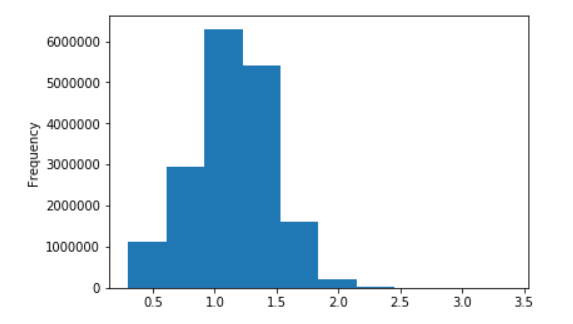
Längenverteilung von Sätzen für russische Wikipedia
Keine Logarithmen (auf der X-Achse sind die Werte auf 20 begrenzt)
In dezimalen Logarithmen
Referenzen
- Fast-Text- Wortvektoren, die in einem Wiki trainiert wurden;
- Fast-Text- und Word2Vec- Modelle für die russische Sprache;
- Fantastische Wiki-Extraktionsbibliothek für Python;
- Die offizielle Seite mit Links für Wiki;
- Unser Skript zur Nachbearbeitung;
- Hauptartikel über Worteinbettungen : Word2Vec , Fast-Text , Tuning ;
- Mehrere aktuelle SOTA-Ansätze:
- InferSent ;
- Generatives CNN vor dem Training ;
- ULMFiT ;
- Kontextuelle Ansätze zur Darstellung von Wörtern (Elmo);
- Imagenet Moment in NLP ?
- Grundlagen für die Einbettung der Vorschläge 1 , 2 , 3 , 4 ;
- Definition von gefälschten Phrasen für Angebotscodierer;