Die Spieltheorie ist eine mathematische Disziplin, die die Modellierung der Aktionen von Spielern in Betracht zieht, die ein Ziel haben, nämlich die Auswahl der optimalen Strategien für das Verhalten in einem Konflikt. Auf Habré wurde dieses Thema bereits
behandelt , aber heute werden wir einige seiner Aspekte genauer besprechen und Beispiele für Kotlin betrachten.
Eine Strategie besteht also aus einer Reihe von Regeln, die je nach Situation die Wahl einer Vorgehensweise für jeden persönlichen Schritt bestimmen. Die optimale Spielerstrategie ist die Strategie, die die beste Position in einem gegebenen Spiel sicherstellt, d. H. maximale Verstärkung. Wenn das Spiel mehrmals wiederholt wird und zusätzlich zu persönlichen, zufälligen Zügen enthält, liefert die optimale Strategie den maximalen durchschnittlichen Gewinn.
Die Aufgabe der Spieltheorie ist es, die optimalen Strategien für die Spieler zu identifizieren. Die Hauptannahme, auf deren Grundlage optimale Strategien gefunden werden, ist, dass der Gegner (oder die Gegner) nicht weniger intelligent ist als der Spieler selbst und alles tut, um sein Ziel zu erreichen. Die Berechnung eines vernünftigen Gegners ist nur eine der möglichen Positionen im Konflikt, aber in der Spieltheorie ist es das, was in den Grundstein gelegt wird.
Es gibt Spiele mit der Natur, bei denen nur ein Teilnehmer seinen Gewinn maximiert. Spiele mit der Natur sind mathematische Modelle, bei denen die Wahl der Lösung von der objektiven Realität abhängt. Zum Beispiel Verbrauchernachfrage, Naturzustand usw. "Natur" ist ein verallgemeinertes Konzept eines Gegners, der seine eigenen Ziele nicht verfolgt. In diesem Fall werden mehrere Kriterien verwendet, um die optimale Strategie auszuwählen.
In Spielen mit der Natur gibt es zwei Arten von Aufgaben:
- die Aufgabe, Entscheidungen unter Risikobedingungen zu treffen, wenn die Wahrscheinlichkeiten bekannt sind, mit denen die Natur jeden der möglichen Zustände akzeptiert;
- Entscheidungsaufgaben unter unsicheren Bedingungen, wenn es nicht möglich ist, Informationen über die Wahrscheinlichkeiten des Auftretens von Naturzuständen zu erhalten.
Hier wird kurz auf diese Kriterien eingegangen.
Jetzt werden wir die Entscheidungskriterien in reinen Strategien betrachten und am Ende des Artikels das Spiel in gemischten Strategien durch die analytische Methode lösen.
ReservierungIch bin kein Spezialist für Spieltheorie, aber in dieser Arbeit habe ich Kotlin zum ersten Mal verwendet. Ich beschloss jedoch, meine Ergebnisse zu teilen. Wenn Sie Fehler im Artikel bemerken oder Ratschläge geben möchten, wenden Sie sich bitte an PM.
Erklärung des Problems
Wir werden alle Entscheidungskriterien anhand eines durchgehenden Beispiels analysieren. Die Aufgabe ist folgende: Der Landwirt muss bestimmen, in welchen Anteilen er sein Feld mit drei Kulturen säen soll, ob der Ertrag dieser Kulturen und damit der Gewinn davon abhängt, wie der Sommer sein wird: kühl und regnerisch, normal oder heiß und trocken. Der Landwirt berechnete je nach Wetterlage einen Nettogewinn von 1 Hektar aus verschiedenen Kulturen. Das Spiel wird durch die folgende Matrix bestimmt:

Weiter werden wir diese Matrix in Form von Strategien präsentieren:
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1)
Die gewünschte optimale Strategie wird mit bezeichnet
uopt . Wir werden das Spiel anhand der Kriterien Wald, Optimismus, Pessimismus, Savage und Hurwitz unter Unsicherheitsbedingungen und der Kriterien Bayes und Laplace unter Risikobedingungen lösen.
Wie oben erwähnt, werden die Beispiele auf Kotlin sein. Ich stelle fest, dass es im Allgemeinen Lösungen wie Gambit (geschrieben in C), Axelrod und PyNFG (geschrieben in Python) gibt, aber wir werden unser eigenes Fahrrad fahren, das auf dem Knie montiert ist, nur um ein wenig stilvoll, modisch und modisch zu stoßen Jugendprogrammiersprache.
Um die Lösung des Spiels programmgesteuert umzusetzen, werden wir mehrere Klassen einführen. Zunächst benötigen wir eine Klasse, mit der wir eine Zeile oder Spalte einer Spielmatrix beschreiben können. Die Klasse ist äußerst einfach und enthält eine Liste möglicher Werte (Alternativen oder Naturzustände) und den entsprechenden Namen. Das
key wird sowohl zur Identifizierung als auch zum Vergleich verwendet, und bei der Implementierung der Dominanz wird ein Vergleich erforderlich sein.
Spielmatrix Zeile oder Spalte import java.text.DecimalFormat import java.text.NumberFormat open class GameVector(name: String, values: List<Double>, key: Int = -1) : Comparable<GameVector> { val name: String val values: List<Double> val key: Int private val formatter:NumberFormat = DecimalFormat("#0.00") init { this.name = name; this.values = values; this.key = key; } public fun max(): Double? { return values.max(); } public fun min(): Double? { return values.min(); } override fun toString(): String{ return name + ": " + values .map { v -> formatter.format(v) } .reduce( {f1: String, f2: String -> "$f1 $f2"}) } override fun compareTo(other: GameVector): Int { var compare = 0 if (this.key == other.key){ return compare } var great = true for (i in 0..this.values.lastIndex){ great = great && this.values[i] >= other.values[i] } if (great){ compare = 1 }else{ var less = true for (i in 0..this.values.lastIndex){ less = less && this.values[i] <= other.values[i] } if (less){ compare = -1 } } return compare } }
Die Spielmatrix enthält Informationen zu Alternativen und Naturzuständen. Darüber hinaus werden einige Methoden implementiert, z. B. das Ermitteln der dominanten Menge und des Nettopreises des Spiels.
Spielmatrix open class GameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>) { val matrix: List<List<Double>> val alternativeNames: List<String> val natureStateNames: List<String> val alternatives: List<GameVector> val natureStates: List<GameVector> init { this.matrix = matrix; this.alternativeNames = alternativeNames this.natureStateNames = natureStateNames var alts: MutableList<GameVector> = mutableListOf() for (i in 0..matrix.lastIndex) { val currAlternative = alternativeNames[i] val gameVector = GameVector(currAlternative, matrix[i], i) alts.add(gameVector) } alternatives = alts.toList() var nss: MutableList<GameVector> = mutableListOf() val lastIndex = matrix[0].lastIndex // , for (j in 0..lastIndex) { val currState = natureStateNames[j] var states: MutableList<Double> = mutableListOf() for (i in 0..matrix.lastIndex) { states.add(matrix[i][j]) } val gameVector = GameVector(currState, states.toList(), j) nss.add(gameVector) } natureStates = nss.toList() } open fun change (i : Int, j : Int, value : Double) : GameMatrix{ var mml = this.matrix.toMutableList() var rowi = mml[i].toMutableList() rowi.set(j, value) mml.set(i, rowi) return GameMatrix(mml.toList(), alternativeNames, natureStateNames) } open fun changeAlternativeName (i : Int, value : String) : GameMatrix{ var list = alternativeNames.toMutableList() list.set(i, value) return GameMatrix(matrix, list.toList(), natureStateNames) } open fun changeNatureStateName (j : Int, value : String) : GameMatrix{ var list = natureStateNames.toMutableList() list.set(j, value) return GameMatrix(matrix, alternativeNames, list.toList()) } fun size() : Pair<Int, Int>{ return Pair(alternatives.size, natureStates.size) } override fun toString(): String { return " :\n" + natureStateNames.reduce { n1: String, n2: String -> "$n1;\n$n2" } + "\n :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } protected fun dominateSet(gvl: List<GameVector>, list: MutableList<String>, dvv: Int) : MutableSet<GameVector>{ var dSet: MutableSet<GameVector> = mutableSetOf() for (gv in gvl){ for (gvv in gvl){ if (!dSet.contains(gv) && !dSet.contains(gvv)) { if (gv.compareTo(gvv) == dvv) { dSet.add(gv) list.add("[$gvv] [$gv]") } } } } return dSet } open fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return GameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList()) } fun dominateMatrix(): Pair<GameMatrix, List<String>>{ var list: MutableList<String> = mutableListOf() var dCol: MutableSet<GameVector> = dominateSet(this.natureStates, list, 1) var dRow: MutableSet<GameVector> = dominateSet(this.alternatives, list, -1) val newMatrix = newMatrix(dCol, dRow) var ddgm = Pair(newMatrix, list.toList()) val ret = iterate(ddgm, list) return ret; } protected fun iterate(ddgm: Pair<GameMatrix, List<String>>, list: MutableList<String>) : Pair<GameMatrix, List<String>>{ var dgm = this var lddgm = ddgm while (dgm.size() != lddgm.first.size()){ dgm = lddgm.first list.addAll(lddgm.second) lddgm = dgm.dominateMatrix() } return Pair(dgm,list.toList().distinct()) } fun minClearPrice(): Double{ val map: List<Double> = this.alternatives.map { a -> a?.min() ?: 0.0 } return map?.max() ?: 0.0 } fun maxClearPrice(): Double{ val map: List<Double> = this.natureStates.map { a -> a?.max() ?: 0.0 } return map?.min() ?: 0.0 } fun existsClearStrategy() : Boolean{ return minClearPrice() >= maxClearPrice() } }
Wir beschreiben die Schnittstelle, die die Kriterien erfüllt
Kriterium interface ICriteria { fun optimum(): List<GameVector> }
Entscheidungsfindung unter Unsicherheit
Entscheidungen angesichts von Unsicherheit zu treffen, deutet darauf hin, dass der Spieler nicht von einem vernünftigen Gegner abgelehnt wird.
Wald-Kriterium
Das Wald-Kriterium maximiert das schlechtestmögliche Ergebnis:
uopt=maximinj[U]
Die Verwendung des Kriteriums versichert gegen das schlechteste Ergebnis, aber der Preis einer solchen Strategie ist der Verlust der Möglichkeit, das bestmögliche Ergebnis zu erzielen.
Betrachten Sie ein Beispiel. Für Strategien
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) Finde die Tiefs und hol dir die nächsten drei
S=(0,1,−1) . Das Maximum für das angegebene Tripel ist der Wert 1, daher ist nach dem Wald-Kriterium die Gewinnstrategie die Strategie
U2=(2,3,1) entsprechend der Pflanzkultur 2.
Die Software-Implementierung des Wald-Kriteriums ist einfach:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Aus Gründen der Klarheit werde ich zum ersten Mal zeigen, wie die Lösung wie ein Test aussehen würde:
Test private fun matrix(): GameMatrix { val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ") val matrix: List<List<Double>> = listOf( listOf(0.0, 2.0, 5.0), listOf(2.0, 3.0, 1.0), listOf(4.0, 3.0, -1.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) return gm; } } private fun testCriteria(gameMatrix: GameMatrix, criteria: ICriteria, name: String){ println(gameMatrix.toString()) val optimum = criteria.optimum() println("$name. : ") optimum.forEach { o -> println(o.toString()) } } @Test fun testWaldCriteria() { val matrix = matrix(); val criteria = WaldCriteria(matrix) testCriteria(matrix, criteria, " ") }
Es ist leicht zu erraten, dass bei anderen Kriterien der Unterschied nur in der Erstellung des
criteria .
Optimismuskriterium
Wenn der Spieler das Kriterium eines Optimisten verwendet, wählt er eine Lösung, die das beste Ergebnis liefert, während der Optimist davon ausgeht, dass die Spielbedingungen für ihn am günstigsten sind:
uopt=maximaxj[U]
Die Strategie eines Optimisten kann zu negativen Konsequenzen führen, wenn das maximale Angebot mit der minimalen Nachfrage übereinstimmt. Das Unternehmen kann Verluste erleiden, wenn es nicht verkaufte Produkte abschreibt. Gleichzeitig hat die Strategie des Optimisten eine bestimmte Bedeutung. Sie müssen sich beispielsweise nicht um unzufriedene Kunden kümmern, da eine mögliche Nachfrage immer befriedigt wird und daher der Standort der Kunden nicht beibehalten werden muss. Wenn die maximale Nachfrage erreicht wird, können Sie mit der Strategie des Optimisten den größtmöglichen Nutzen erzielen, während andere Strategien zu entgangenen Gewinnen führen. Dies bietet gewisse Wettbewerbsvorteile.
Betrachten Sie ein Beispiel. Für Strategien
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) finde, finde das Maximum und erhalte die nächsten drei
S=(5,3,4) . Das Maximum für das angegebene Tripel ist der Wert 5, daher ist nach dem Kriterium des Optimismus die Gewinnstrategie die Strategie
U1=(0.2.5) entsprechend der Pflanzkultur 1.
Die Umsetzung des Optimismuskriteriums unterscheidet sich kaum vom Waldkriterium:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Kriterium des Pessimismus
Dieses Kriterium soll das kleinste Element der Spielmatrix aus den minimal möglichen Elementen auswählen:
uopt=miniminj[U]
Das Pessimismuskriterium deutet darauf hin, dass die Entwicklung von Ereignissen für den Entscheidungsträger ungünstig sein wird. Bei Verwendung dieses Kriteriums lässt sich der Entscheidungsträger vom möglichen Kontrollverlust über die Situation leiten und versucht daher, potenzielle Risiken auszuschließen, indem er die Option mit minimaler Rentabilität wählt.
Betrachten Sie ein Beispiel. Für Strategien
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) finde, finde das Minimum und erhalte die nächsten drei
S=(0,1,−1) . Das Minimum für das angegebene Tripel ist der Wert -1, daher ist gemäß dem Kriterium des Pessimismus die Gewinnstrategie die Strategie
U3=(4.3,−1) entsprechend der Pflanzkultur 3.
Nachdem Sie Walds Kriterien und Optimismus kennengelernt haben, können Sie leicht erraten, wie die Klasse des Pessimismus-Kriteriums aussehen wird:
class PessimismCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val min = mins.minWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == min!!.second } .map { m -> m.first } } }
Wildes Kriterium
Das Savage-Kriterium (Kriterium eines pessimistischen Pessimisten) beinhaltet die Minimierung der größten entgangenen Gewinne, mit anderen Worten, das größte Bedauern über die entgangenen Gewinne wird minimiert:
uopt=minimaxj[S]si,j=(max beginbmatrixu1,ju2,j...un,j endbmatrix−ui,j)
In diesem Fall ist S die Matrix der Reue.
Die optimale Lösung gemäß dem Savage-Kriterium sollte das geringste Bedauern gegenüber den im vorherigen Schritt festgestellten Bedauern hervorrufen. Die dem gefundenen Dienstprogramm entsprechende Lösung ist optimal.
Zu den Merkmalen der erhaltenen Lösung gehören das garantierte Fehlen der größten Enttäuschungen und das garantierte Verringern der maximal möglichen Gewinne anderer Spieler.
Betrachten Sie ein Beispiel. Für Strategien
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) eine Matrix des Bedauerns machen:
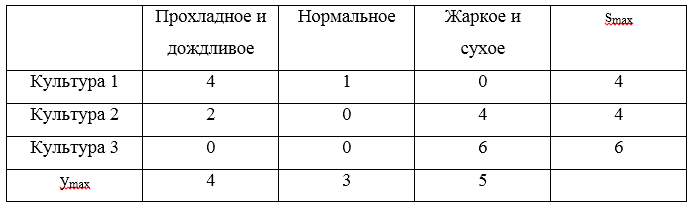
Drei maximale Bedauern
S=(4,4,6) . Der Mindestwert dieser Risiken beträgt 4, was den Strategien entspricht
U1 und
U2 .
Das Programmieren des Savage-Tests ist etwas schwieriger:
class SavageCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.risk(): List<Pair<GameVector, Double?>> { val maxStates = this.natureStates.map { n -> Pair(n, n.values.max()) } .map { n -> n.first.key to n.second }.toMap() var am: MutableList<Pair<GameVector, List<Double>>> = mutableListOf() for (a in this.alternatives) { var v: MutableList<Double> = mutableListOf() for (i in 0..a.values.lastIndex) { val mn = maxStates.get(i) v.add(mn!! - a.values[i]) } am.add(Pair(a, v.toList())) } return am.map { m -> Pair(m.first, m.second.max()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.risk() val minRisk = risk.minWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == minRisk!!.second } .map { m -> m.first } } }
Hurwitz-Kriterium
Das Hurwitz-Kriterium ist ein regulierter Kompromiss zwischen extremem Pessimismus und völligem Optimismus:
uopt=max( gamma×A(k)+A(0)×(1− gamma))
A (0) ist die Strategie des extremen Pessimisten, A (k) ist die Strategie des vollständigen Optimisten,
gamma=1 - Sollwert des Gewichtskoeffizienten:
0 leq gamma leq1 ;;
gamma=0 - extremer Pessimismus,
gamma=1 - voller Optimismus.
Mit einer kleinen Anzahl von diskreten Strategien den gewünschten Wert des Gewichtskoeffizienten einstellen
gamma und runden Sie das Ergebnis unter Berücksichtigung der durchgeführten Diskretisierung auf den nächstmöglichen Wert.
Betrachten Sie ein Beispiel. Für Strategien
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) . Wir gehen davon aus, dass der Optimismuskoeffizient
gamma=$0, . Machen Sie jetzt einen Tisch:
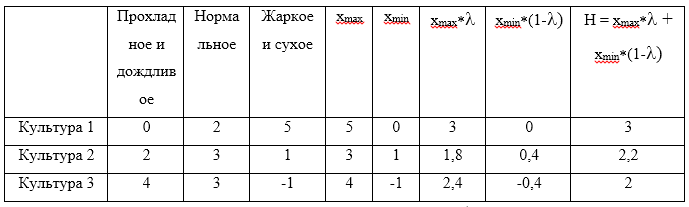
Der Maximalwert aus dem berechneten H ist der Wert 3, der der Strategie entspricht
U1 .
Das Hurwitz-Kriterium ist bereits umfangreicher:
class HurwitzCriteria(gameMatrix: GameMatrix, optimisticKoef: Double) : ICriteria { val gameMatrix: GameMatrix val optimisticKoef: Double init { this.gameMatrix = gameMatrix this.optimisticKoef = optimisticKoef } inner class HurwitzParam(xmax: Double, xmin: Double, optXmax: Double){ val xmax: Double val xmin: Double val optXmax: Double val value: Double init{ this.xmax = xmax this.xmin = xmin this.optXmax = optXmax value = xmax * optXmax + xmin * (1 - optXmax) } } fun GameMatrix.getHurwitzParams(): List<Pair<GameVector, HurwitzParam>> { return this.alternatives.map { a -> Pair(a, HurwitzParam(a.max()!!, a.min()!!, optimisticKoef)) } } override fun optimum(): List<GameVector> { val hpar = gameMatrix.getHurwitzParams() val maxHurw = hpar.maxWith(Comparator { o1, o2 -> o1.second.value.compareTo(o2.second.value) }) return hpar .filter { r -> r.second == maxHurw!!.second } .map { m -> m.first } } }
Entscheidungsfindung in Gefahr
Entscheidungsfindungsmethoden können sich auf Kriterien für die Entscheidungsfindung unter Risikobedingungen unter folgenden Bedingungen stützen:
- Mangel an verlässlichen Informationen über die möglichen Folgen;
- das Vorhandensein von Wahrscheinlichkeitsverteilungen;
- Kenntnis der Wahrscheinlichkeit von Ergebnissen oder Konsequenzen für jede Entscheidung.
Wenn eine Entscheidung unter Risikobedingungen getroffen wird, werden die Kosten alternativer Entscheidungen durch Wahrscheinlichkeitsverteilungen beschrieben. In dieser Hinsicht basiert die Entscheidung auf der Verwendung des Erwartungswertkriteriums, nach dem alternative Lösungen im Hinblick auf die Maximierung des erwarteten Gewinns oder die Minimierung der erwarteten Kosten verglichen werden.
Das Kriterium des erwarteten Wertes kann entweder reduziert werden, um den erwarteten (durchschnittlichen) Gewinn zu maximieren oder um die erwarteten Kosten zu minimieren. In diesem Fall wird angenommen, dass der mit jeder alternativen Lösung verbundene Gewinn (Kosten) eine Zufallsvariable ist.
Die Formulierung solcher Aufgaben lautet normalerweise wie folgt: Eine Person wählt eine Aktion in einer Situation aus, in der zufällige Ereignisse das Ergebnis der Aktion beeinflussen. Der Spieler hat jedoch einige Kenntnisse über die Wahrscheinlichkeiten dieser Ereignisse und kann die rentabelste Kombination und Abfolge seiner Aktionen berechnen.
Um weiterhin Beispiele zu nennen, ergänzen wir die Spielmatrix mit Wahrscheinlichkeiten:
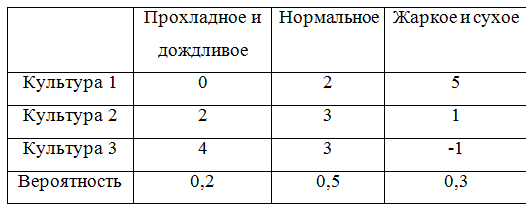
Um die Wahrscheinlichkeiten zu berücksichtigen, muss eine Klasse, die die Spielmatrix beschreibt, ein wenig überarbeitet werden. Es stellte sich in Wahrheit heraus, nicht sehr elegant, aber na ja.
Spielmatrix mit Wahrscheinlichkeiten open class ProbabilityGameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>, probabilities: List<Double>) : GameMatrix(matrix, alternativeNames, natureStateNames) { val probabilities: List<Double> init { this.probabilities = probabilities; } override fun change (i : Int, j : Int, value : Double) : GameMatrix{ val cm = super.change(i, j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeAlternativeName (i : Int, value : String) : GameMatrix{ val cm = super.changeAlternativeName(i, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeNatureStateName (j : Int, value : String) : GameMatrix{ val cm = super.changeNatureStateName(j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } fun changeProbability (j : Int, value : Double) : GameMatrix{ var list = probabilities.toMutableList() list.set(j, value) return ProbabilityGameMatrix(matrix, alternativeNames, natureStateNames, list.toList()) } override fun toString(): String { var s = "" val formatter: NumberFormat = DecimalFormat("#0.00") for (i in 0 .. natureStateNames.lastIndex){ s += natureStateNames[i] + " = " + formatter.format(probabilities[i]) + "\n" } return " :\n" + s + " :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } override fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() var rprobailities: MutableList<Double> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (i in 0 .. probabilities.lastIndex){ if (!dIndex.contains(i)){ rprobailities.add(probabilities[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return ProbabilityGameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList(), rprobailities.toList()) } } }
Bayes-Kriterium
Das Bayes-Kriterium (Erwartungskriterium) wird bei Entscheidungsproblemen unter Risikobedingungen als Bewertung der Strategie verwendet
ui Die mathematische Erwartung der entsprechenden Zufallsvariablen erscheint. Nach dieser Regel ist die optimale Spielerstrategie
uopt wird aus der Bedingung gefunden:
uopt=max1 leqi leqnM(ui)M(ui)=max1 leqi leqn summj=1ui,j cdoty0j
Mit anderen Worten, ein Indikator für die Ineffizienz der Strategie
ui Nach dem Bayes-Kriterium für Risiken ist der Durchschnittswert (Erwartung) der Risiken der i-ten Zeile der Matrix
U deren Wahrscheinlichkeiten mit den Wahrscheinlichkeiten der Natur übereinstimmen. Dann ist die Strategie das optimale unter den reinen Strategien nach dem Bayes-Kriterium bezüglich der Risiken
uopt mit minimaler Ineffizienz, dh minimalem Durchschnittsrisiko. Das Bayes'sche Kriterium ist in Bezug auf Gewinne und in Bezug auf Risiken äquivalent, d.h. wenn die Strategie
uopt ist nach dem Bayes-Kriterium in Bezug auf Siege optimal, dann ist es nach dem Bayes-Kriterium in Bezug auf Risiken optimal und umgekehrt.
Fahren wir mit dem Beispiel fort und berechnen die mathematischen Erwartungen:
M1=0 cdot0.2+2 cdot0.5+5 cdot0.3=2.5;M2=2 cdot0.2+3 cdot0.5+1 cdot0.3=2.2;M4=0 cdot0.2+3 cdot0.5+(−1) cdot0.3=2.0;
Die maximale mathematische Erwartung ist
M1 Daher ist eine Gewinnstrategie eine Strategie
U1 .
Software-Implementierung des Bayes-Kriteriums:
class BayesCriteria(gameMatrix: ProbabilityGameMatrix) : ICriteria { val gameMatrix: ProbabilityGameMatrix init { this.gameMatrix = gameMatrix } fun ProbabilityGameMatrix.bayesProbability(): List<Pair<GameVector, Double?>> { var am: MutableList<Pair<GameVector, Double>> = mutableListOf() for (a in this.alternatives) { var alprob: Double = 0.0 for (i in 0..a.values.lastIndex) { alprob += a.values[i] * this.probabilities[i] } am.add(Pair(a, alprob)) } return am.toList(); } override fun optimum(): List<GameVector> { val risk = gameMatrix.bayesProbability() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Laplace-Kriterium
Das Laplace-Kriterium bietet eine vereinfachte Maximierung der mathematischen Nützlichkeitserwartung, wenn die Annahme der gleichen Wahrscheinlichkeit von Nachfragestufen gültig ist, wodurch die Notwendigkeit entfällt, echte Statistiken zu sammeln.
Im allgemeinen Fall werden bei Verwendung des Laplace-Kriteriums die Matrix der erwarteten Dienstprogramme und das optimale Kriterium wie folgt bestimmt:
uopt=max[ overlineU] overlineU= beginbmatrix overlineu1 overlineu2... overlineun endbmatrix, overlineui= frac1n sumnj=1ui,j
Betrachten Sie das Beispiel der Entscheidungsfindung nach dem Laplace-Kriterium. Wir berechnen das arithmetische Mittel für jede Strategie:
overlineu1= frac13 cdot(0+2+5)=2.3 overlineu2= frac13 cdot(2+3+1)=2,0 o v e r l i n e u 3 = f r a c 1 3 C d O t ( 4 + 3 - 1 ) = $ 2 ,
Die Gewinnstrategie ist also die Strategie
U 1 .
Software-Implementierung des Laplace-Kriteriums:
class LaplaceCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.arithemicMean(): List<Pair<GameVector, Double>> { return this.alternatives.map { m -> Pair(m, m.values.average()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.arithemicMean() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second.compareTo(o2.second) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Gemischte Strategien. Analysemethode
Mit der Analysemethode können Sie das Spiel in gemischten Strategien lösen.
Um einen Algorithmus zum Finden einer Lösung für ein Spiel durch eine analytische Methode zu formulieren, betrachten wir einige zusätzliche Konzepte.StrategieU i dominiert die StrategieU i - 1 , wenn alleu 1 .. n ∈ U i ≥ u 1 .. n ∈ U i - 1 .
Mit anderen Worten, wenn in einer Zeile einer Zahlungsmatrix alle Elemente größer oder gleich den entsprechenden Elementen einer anderen Zeile sind, dominiert die erste Zeile die zweite und wird als dominante Zeile bezeichnet. Und auch wenn in einer Spalte der Zahlungsmatrix alle Elemente kleiner oder gleich den entsprechenden Elementen einer anderen Spalte sind, dominiert die erste Spalte die zweite und wird als dominante Spalte bezeichnet.Der niedrigste Preis des Spiels heißtα = m a x i m i n j u i j .
Der Spitzenpreis des Spiels heißt β = m i n j m a x i u i j .
Jetzt können Sie einen Algorithmus zum Lösen des Spiels mit der Analysemethode formulieren:- Berechnen Sie den Boden α und obenβ -Spielpreise. Wennα = β , dann schreibe die Antwort in reinen Strategien auf, wenn nicht, setze die Lösung weiter fort
- Löschen Sie dominante Zeilen dominante Spalten. Es kann mehrere geben. An ihrer Stelle in der optimalen Strategie sind die entsprechenden Komponenten 0
- Löse das Matrixspiel durch lineare Programmierung.
Um ein Beispiel zu geben, müssen Sie eine Klasse angeben, die die Lösung beschreibtLöse class Solve(gamePriceObr: Double, solutions: List<Double>, names: List<String>) { val gamePrice: Double val gamePriceObr: Double val solutions: List<Double> val names: List<String> private val formatter: NumberFormat = DecimalFormat("#0.00") init{ this.gamePrice = 1 / gamePriceObr this.gamePriceObr = gamePriceObr; this.solutions = solutions this.names = names } override fun toString(): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (i in 0..solutions.lastIndex){ s += "$i) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" } return s } fun itersect(matrix: GameMatrix): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (j in 0..matrix.alternativeNames.lastIndex) { var f = false val a = matrix.alternativeNames[j] for (i in 0..solutions.lastIndex) { if (a.equals(names[i])) { s += "$j) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" f = true break } } if (!f){ s += "$j) " + a + " = 0\n" } } return s } }
Und die Klasse, die die Lösung nach der Simplex-Methode ausführt. Da ich Mathematik nicht verstehe, habe ich die vorgefertigte Implementierung von Apache Commons Math verwendetLöser open class Solver (gameMatrix: GameMatrix) { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } fun solve(): Solve{ val goalf: List<Double> = gameMatrix.alternatives.map { a -> 1.0 } val f = LinearObjectiveFunction(goalf.toDoubleArray(), 0.0) val constraints = ArrayList<LinearConstraint>() for (alt in gameMatrix.alternatives){ constraints.add(LinearConstraint(alt.values.toDoubleArray(), Relationship.LEQ, 1.0)) } val solution = SimplexSolver().optimize(f, LinearConstraintSet(constraints), GoalType.MAXIMIZE, NonNegativeConstraint(true)) val sl: List<Double> = solution.getPoint().toList() val solve = Solve(solution.getValue(), sl, gameMatrix.alternativeNames) return solve } }
Jetzt führen wir die Lösung mit der Analysemethode aus. Zur Verdeutlichung nehmen wir eine andere Spielmatrix:( 2 4 8 5 6 2 4 6 3 2 5 4 )
In dieser Matrix gibt es eine dominante Menge:( 2 4 6 2 )
Lösung val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ", "") val matrix: List<List<Double>> = listOf( listOf(2.0, 4.0, 8.0, 5.0), listOf(6.0, 2.0, 4.0, 6.0), listOf(3.0, 2.0, 5.0, 4.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) val (dgm, list) = gm.dominateMatrix() println(dgm.toString()) println(list.reduce({s1, s2 -> s1 + "\n" + s2})) println() val s: Solver = Solver(dgm) val solve = s.solve() println(solve)
Spielelösung ( 0 , 33 ; 0 , 67 ; 0 ) mit einem Spielpreis von 3,33Anstelle einer Schlussfolgerung
Ich hoffe, dieser Artikel ist nützlich für diejenigen, die eine erste Annäherung an die Lösung von Spielen mit der Natur benötigen. Anstelle von Schlussfolgerungen ein Link zu GitHub .Für das konstruktive Feedback wäre ich dankbar!