Hallo an alle.
Er schrieb eine Bibliothek zum Trainieren eines neuronalen Netzwerks. Wen interessiert das bitte?
Ich wollte mich schon lange zu einem Instrument dieser Stufe machen. Im Sommer machte er sich an die Arbeit. Folgendes ist passiert:
- Die Bibliothek wurde von Grund auf in C ++ (nur STL + OpenBLAS zur Berechnung), C-Interface, Win / Linux geschrieben.
- Die Netzwerkstruktur wird in JSON angegeben.
- Basisschichten: vollständig verbunden, Faltung, Pooling. Zusätzlich: Größe ändern, zuschneiden ..;
- Grundfunktionen: batchNorm, Dropout, Gewichtsoptimierer - Adam, Adagrad ..;
- OpenBLAS wird verwendet, um die CPU CUDA / cuDNN für die Grafikkarte zu berechnen. Er legte auch die Implementierung für die Zukunft auf OpenCL;
- Für jede Schicht besteht die Möglichkeit, separat festzulegen, was zu berücksichtigen ist - CPU oder GPU (und welche);
- Die Größe der Eingabedaten ist nicht starr festgelegt. Sie kann sich während der Arbeit / des Trainings ändern.
- Schnittstellen für C ++ und Python gemacht. C # wird auch später kommen.
Die Bibliothek hieß SkyNet. (Alles ist kompliziert mit Namen, andere waren Optionen, aber etwas stimmt nicht ..)
Vergleich mit PyTorch anhand des MNIST-Beispiels:
PyTorch: Genauigkeit: 98%, Zeit: 140 Sek
SkyNet: Genauigkeit: 95%, Zeit: 150 Sek
Maschine: i5-2300, GF1060. Testcode.
Softwarearchitektur
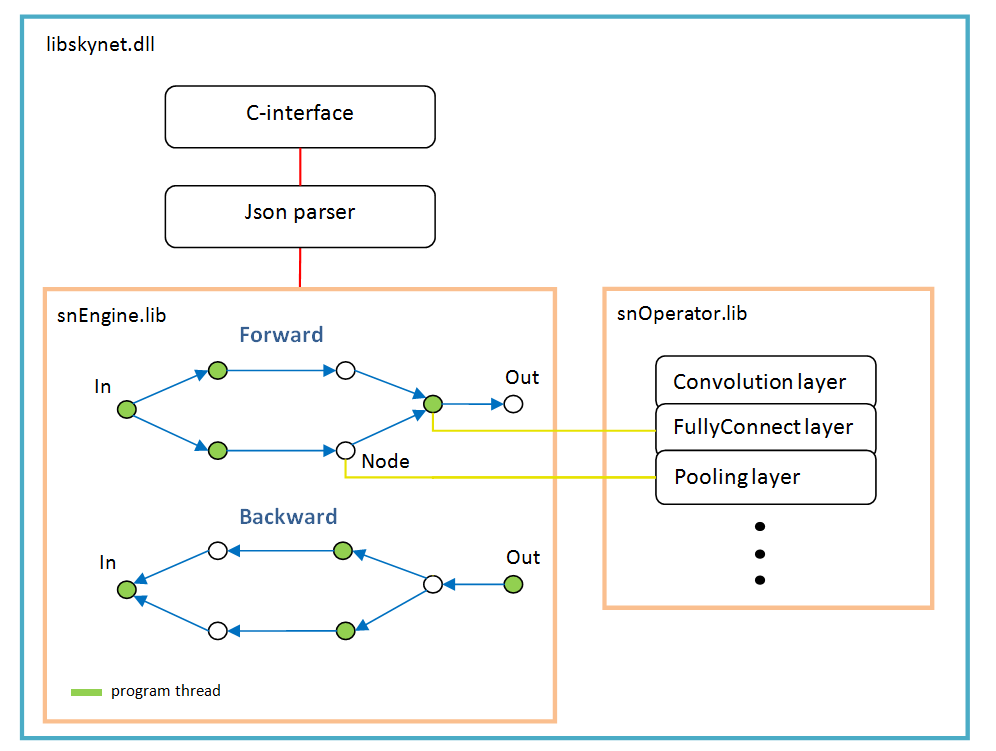
Es basiert auf einem Diagramm von Vorgängen, das nach dem Parsen der Netzwerkstruktur einmal dynamisch erstellt wird.
Für jeden Zweig ein neuer Thread. Jeder Knoten des Netzwerks (Knoten) ist eine Berechnungsebene.
Es gibt Merkmale der Arbeit:
- Aktivierungsfunktion, Normalisierung nach Batch, Dropout - alle werden als Parameter bestimmter Ebenen implementiert, dh diese Funktionen existieren nicht als separate Ebenen. Möglicherweise sollte batchNorm in Zukunft in einer separaten Ebene ausgewählt werden.
- softMax ist auch keine separate Ebene, sondern gehört zur speziellen LossFunction-Ebene. In dem es bei der Auswahl einer bestimmten Art der Fehlerberechnung verwendet wird;
- Die Ebene „LossFunction“ wird verwendet, um den Fehler automatisch zu berechnen. Sie können die Schritte vorwärts / rückwärts natürlich nicht verwenden (unten finden Sie ein Beispiel für die Arbeit mit dieser Ebene).
- Es gibt keine Ebene "Abflachen". Sie wird nicht benötigt, da die Ebene "FullyConnect" selbst das Eingabearray zeichnet.
- Das Gewichtsoptimierungsprogramm muss für jede Gewichtsschicht festgelegt werden. Standardmäßig wird "Adam" von allen verwendet.
Beispiele
Mnist

C ++ - Code sieht folgendermaßen aus: Den vollständigen Code finden Sie
hier . Dem Repository neben dem Beispiel wurden einige Bilder hinzugefügt. Ich habe opencv zum Lesen von Bildern verwendet und es nicht in das Kit aufgenommen.
Ein weiteres Netzwerk des gleichen Plans, komplizierter.

Code zum Erstellen eines solchen Netzwerks: In den Beispielen ist dies nicht der Fall, Sie können von hier kopieren.
In Python sieht der Code auch so aus // snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") \ .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") \ .addNode("P1", Pooling(calcMode.CUDA), "FC1") \ .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") \ .addNode("P2", Pooling(calcMode.CUDA), "FC3") \ .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") \ .addNode("P3", Pooling(calcMode.CUDA), "FC5") \ \ .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") \ .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") \ .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") \ .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") \ .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") \ .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") \ .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") .............
CIFAR-10

Hier musste ich bereits batchNorm aktivieren. Dieses Raster lernt bis zu 50% Genauigkeit über 1000 Iterationen, Batch 100.
Dieser Code stellte sich heraus sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Ich denke, es ist klar, dass alle Bildklassen ersetzt werden können.
U-net tyni
Letztes Beispiel. Vereinfachtes natives U-Net zur Demonstration.

Lassen Sie mich ein wenig erklären: Schichten DC1 ... - umgekehrte Faltung, Schichten Concat1 ... - Schichten der Addition von Kanälen,
Rsz1 ... - werden verwendet, um die Anzahl der Kanäle im entgegengesetzten Schritt zu vereinbaren, da der Fehler aus der Summe der Kanäle von der Concat-Schicht zurückgeht.
C ++ - Code. sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output");
Vollständiger Code und Bilder finden Sie
hier .
Open Source Mathe wie diese .
Ich habe alle Schichten auf MNIST getestet; TF diente als Standard für die Bewertung von Fehlern.
Was weiter
Die Bibliothek wird nicht breiter, dh nicht offen, keine Sockel usw., um sich nicht aufzublasen.
Die Bibliotheksschnittstelle wird sich nicht ändern / erweitern, das werde ich überhaupt nicht sagen und niemals, aber nicht zuletzt.
Nur im Detail: Ich werde die Berechnung auf OpenCL durchführen, die Schnittstelle für C #, das RNN-Netzwerk kann ...
MKL Ich denke, es macht keinen Sinn, etwas hinzuzufügen, da das Netzwerk etwas tiefer ist - es ist auf der Grafikkarte sowieso schneller und die durchschnittliche Leistungskarte ist überhaupt kein Mangel.
Import / Export von Gewichten mit anderen Frameworks - über Python (noch nicht implementiert). Die Roadmap wird sein, wenn Interesse an Menschen entsteht.
Wer kann den Code unterstützen, bitte. Es gibt jedoch Einschränkungen, damit die aktuelle Architektur nicht beschädigt wird.
Sie können die Schnittstelle für Python auf Unmöglichkeit erweitern, genau wie Docks und Beispiele benötigt werden.
So installieren Sie von Python:
* pip install libskynet - CPU
* pip install libskynet-cu - CUDA9.2 + cuDNN7.3.1
Wiki- Benutzerhandbuch .
Die Software ist frei verbreitet, MIT-Lizenz.
Vielen Dank.