
Ansichten oder Ansichten sind eines der Konzepte der CUBA-Plattform, die in der Welt der Web-Frameworks nicht am häufigsten verwendet werden. Um dies zu verstehen, müssen Sie sich vor dummen Fehlern schützen, wenn die Anwendung aufgrund unvollständigen Datenladens plötzlich nicht mehr funktioniert. Mal sehen, was Darstellungen (Wortspiel beabsichtigt) sind und warum es eigentlich praktisch ist.
Das Problem der entladenen Daten
Nehmen wir einen Themenbereich einfacher und betrachten das Problem anhand seines Beispiels. Angenommen, wir haben eine Kundenentität , die sich auf eine CustomerType- Entität in einer Eins-zu-Eins-Beziehung bezieht. Mit anderen Worten, der Käufer hat einen Link zu einem bestimmten Typ, der dies beschreibt: z. B. "Cash Cow", "Snapper" usw. Die CustomerType- Entität verfügt über ein Namensattribut, in dem der Typname gespeichert ist.
Und wahrscheinlich haben alle Neulinge (und sogar fortgeschrittene Benutzer) in CUBA früher oder später diesen Fehler erhalten:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
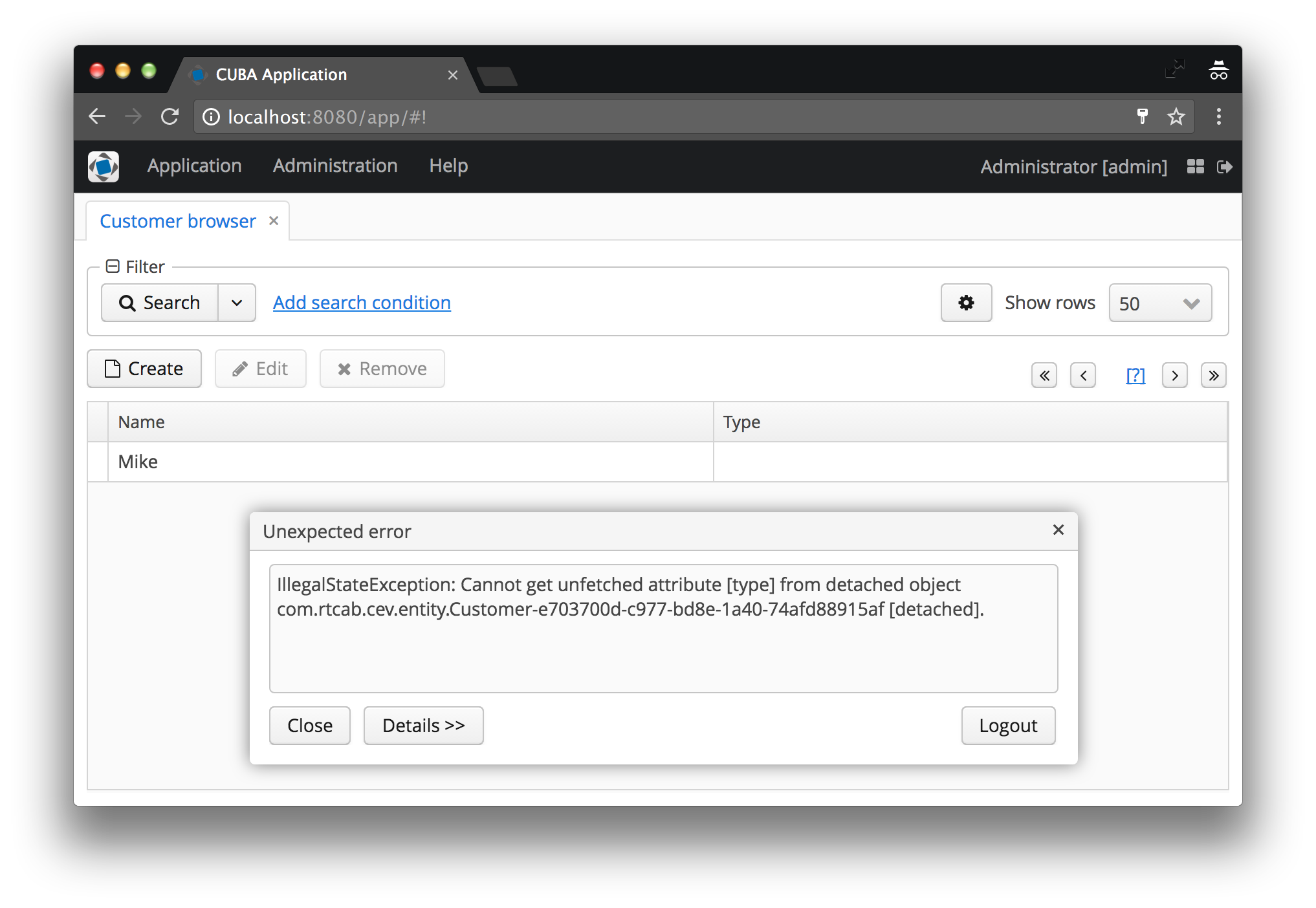
Gib es zu, du hast es auch mit eigenen Augen gesehen? Ich - ja, in hundert verschiedenen Situationen. In diesem Artikel untersuchen wir die Ursache dieses Problems, warum es überhaupt existiert und wie es gelöst werden kann.
Für den Anfang eine kleine Einführung in das Konzept der Ansichten.
Was ist eine Ansicht?
Eine Ansicht in CUBA ist im Wesentlichen eine Sammlung von Spalten in einer Datenbank, die in einer einzigen Abfrage zusammen geladen werden müssen.
Angenommen, wir möchten eine Benutzeroberfläche mit einer Kundentabelle erstellen, wobei die erste Spalte der Name des Kunden und die zweite der Typname aus dem Attribut customerType ist (wie im obigen Screenshot). Es ist logisch anzunehmen, dass in diesem Datenmodell zwei separate Tabellen in der Datenbank vorhanden sind, eine für die Kundenentität und die andere für CustomerType . Die SELECT * from CEV_CUSTOMER gibt nur Daten aus einer Tabelle (Attributname usw.) zurück. Um Daten auch aus anderen Tabellen zu erhalten, verwenden wir natürlich JOINs.
Bei Verwendung klassischer SQL-Abfragen mit JOIN wird die Zuordnungshierarchie (Referenzattribute) aus dem Diagramm in eine flache Liste erweitert.
Anmerkung des Übersetzers: Mit anderen Worten, die Beziehungen zwischen den Tabellen werden gelöscht, und das Ergebnis wird in einem einzelnen Datenarray dargestellt, das die Vereinigung der Tabellen darstellt.
Im Fall von CUBA wird ORM verwendet, das keine Informationen über Beziehungen zwischen Entitäten verliert und das Ergebnis von Abfragen in Form eines integralen Diagramms der angeforderten Daten darstellt. In diesem Fall wird JPQL, ein Objektanalogon von SQL, als Abfragesprache verwendet.
Trotzdem müssen die Daten noch irgendwie aus der Datenbank entladen und in ein Entitätsdiagramm umgewandelt werden. Zu diesem Zweck hat der objektrelationale Zuordnungsmechanismus (der JPA ist) zwei Hauptansätze für Abfragen an die Datenbank.
Faules Laden vs. eifriges holen
Lazy Loading und Greedy Loading sind zwei mögliche Strategien, um Daten aus der Datenbank abzurufen. Der grundlegende Unterschied zwischen den beiden besteht darin, dass die Daten aus den verknüpften Tabellen geladen werden. Ein kleines Beispiel zum besseren Verständnis:
Erinnern Sie sich an die Szene aus dem Buch "Der Hobbit oder Round Trip", in der eine Gruppe von Gnomen in Begleitung von Gandalf und Bilbo versucht, um eine Übernachtung in Beorns Haus zu bitten? Gandalf befahl den Zwergen, streng abwechselnd zu erscheinen, und zwar erst, nachdem er Beorn sorgfältig zugestimmt und begonnen hatte, sie einzeln vorzustellen, um den Besitzer nicht durch die Notwendigkeit zu schockieren, 15 Gäste gleichzeitig unterzubringen.

Also, Gandalf und die Zwerge in Beorns Haus ... Dies ist wahrscheinlich nicht das erste, was mir einfällt, wenn ich über faule und gierige Downloads nachdenke, aber es gibt definitiv Ähnlichkeiten. Gandalf handelte hier mit Bedacht, da er sich der Einschränkungen bewusst war. Man kann sagen, dass er sich bewusst für das verzögerte Laden der Gnome entscheidet, da er verstanden hat, dass das gleichzeitige Herunterladen aller Daten für diese Datenbank zu schwer wäre. Nach dem 8. Gnom wechselte Gandalf jedoch zum gierigen Laden und lud ein paar der verbleibenden Gnome, weil er bemerkte, dass zu häufige Zugriffe auf die Datenbank sie nicht weniger nervös machten.
Die Moral ist, dass sowohl faules als auch gieriges Laden ihre Vor- und Nachteile haben. Was in jeder spezifischen Situation anzuwenden ist, entscheiden Sie.
Problem N + 1 anfordern
Das N + 1-Abfrageproblem tritt häufig auf, wenn Sie gedankenlos faul laden, wohin Sie auch gehen. Schauen wir uns zur Veranschaulichung einen Teil des Grails-Codes an. Dies bedeutet nicht, dass in Grails alles träge geladen wird (tatsächlich wählen Sie die Boot-Methode selbst). In Grails gibt eine Abfrage an die Datenbank standardmäßig Entitätsinstanzen mit allen Attributen aus ihrer Tabelle zurück. Im Wesentlichen wird SELECT * FROM Pet ausgeführt.
Wenn Sie tiefer in die Beziehungen zwischen Entitäten einsteigen möchten, müssen Sie dies post factum tun. Hier ist ein Beispiel:
function getPetOwnerNamesForPets(String nameOfPet) { def pets = Pet.findAll(sort:"name") { name == nameOfPet } def ownerNames = [] pets.each { ownerNames << it.owner.name } return ownerNames.join(", ") }
Das Diagramm wird hier durch eine einzelne Zeile it.owner.name : it.owner.name . Eigentümer ist eine Beziehung, die in der ursprünglichen Anforderung ( Pet.findAll ) nicht geladen wurde. Jedes Mal, wenn diese Zeile aufgerufen wird, führt GORM so etwas wie SELECT * FROM Person WHERE id='…' . Faules Laden mit reinem Wasser.
Wenn Sie die Gesamtzahl der SQL-Abfragen berechnen, erhalten Sie N (ein Eigentümer für jeden Aufruf von it.owner ) + 1 (für das ursprüngliche Pet.findAll ). Wenn Sie tiefer in das Diagramm verwandter Entitäten einsteigen möchten, wird Ihre Datenbank wahrscheinlich schnell an ihre Grenzen stoßen.
Als Entwickler ist es unwahrscheinlich, dass Sie dies bemerken, da Sie aus Ihrer Sicht nur die Grafik von Objekten umgehen. Diese versteckte Verschachtelung in einer kurzen Zeile verursacht der Datenbank echte Schmerzen und macht das verzögerte Laden manchmal gefährlich.
Bei der Entwicklung einer Hobby-Analogie könnte sich das Problem von N + 1 wie folgt manifestieren: Stellen Sie sich vor, Gandalf kann die Namen von Gnomen nicht in seinem Gedächtnis speichern. Daher muss er, indem er die Zwerge einzeln vorstellt, zu seiner Gruppe zurücktreten und den Zwerg nach seinem Namen fragen. Mit diesen Informationen kehrt er zu Beorn zurück und vertritt Thorin. Dann wiederholt er dieses Manöver für Bifur, Bofur, Fili, Kili, Dori, Nori, Ori, Oin, Gloyn, Balin, Dvalin und Bombur.

Es ist leicht vorstellbar, dass ein solches Szenario wahrscheinlich nicht geboren wird: Welcher Empfänger möchte so lange auf die angeforderten Informationen warten? Daher sollten Sie diesen Ansatz nicht gedankenlos verwenden und sich blind auf die Standardeinstellungen Ihres Persistenz-Mappers verlassen.
Lösen des Problems von N + 1-Abfragen mithilfe von CUBA-Ansichten
In CUBA wird das Problem der N + 1-Abfrage höchstwahrscheinlich nie auftreten, da die Plattform entschieden hat, das versteckte verzögerte Laden überhaupt nicht zu verwenden. Stattdessen führte CUBA das Konzept der Repräsentation ein. Ansichten beschreiben, welche Attribute ausgewählt und zusammen mit Entitätsinstanzen geladen werden sollen. So etwas wie
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.id
In der Ansicht werden einerseits die Spalten beschrieben, die aus der Haupttabelle ( Pet ) geladen werden müssen (anstatt alle Attribute über * zu laden), andererseits werden die Spalten beschrieben, die aus c-JOIN-Tabellen geladen werden sollen.
Sie können sich die CUBA-Ansicht als SQL-Ansicht für OR-Mapper vorstellen: Das Funktionsprinzip ist ungefähr dasselbe.
In der CUBA-Plattform können Sie keine Abfrage über den DataManager aufrufen, ohne die Ansicht zu verwenden. Die Dokumentation enthält ein Beispiel:
@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); }
Hier möchten wir das Buch anhand seiner ID herunterladen. Die Methode setView("book.edit") gibt beim Erstellen eines setView("book.edit") , mit welcher Ansicht das Buch aus der Datenbank geladen werden soll. Falls Sie keine Ansicht übergeben, verwendet der Datenmanager eine der drei Standardansichten, über die jede Entität verfügt: die _local-Ansicht . Lokal bezieht sich hier auf Attribute, die nicht auf andere Tabellen verweisen, alles ist einfach.
Lösen des Problems mit IllegalStateException durch Ansichten
Nachdem wir das Konzept der Darstellungen ein wenig verstanden haben, kehren wir zum ersten Beispiel vom Anfang des Artikels zurück und versuchen, das Auslösen einer Ausnahme zu verhindern.
Die Meldung IllegalStateException: Nicht abgerufenes Attribut [] von getrenntem Objekt kann nicht abgerufen werden bedeutet nur, dass Sie versuchen, ein Attribut anzuzeigen, das nicht in der Ansicht enthalten ist, mit der die Entität geladen wird.
Wie Sie sehen können, habe ich im Bildschirmdeskriptor die lokale Ansicht verwendet , und dies ist das ganze Problem:
<dsContext> <groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="_local"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource> </dsContext>
Um den Fehler zu beheben, müssen Sie zuerst den Kundentyp in die Ansicht aufnehmen. Da wir die Standardansicht von _local nicht ändern können , können wir unsere eigene erstellen. In Studio kann dies beispielsweise wie folgt erfolgen (Rechtsklick auf Entitäten> Ansicht erstellen):
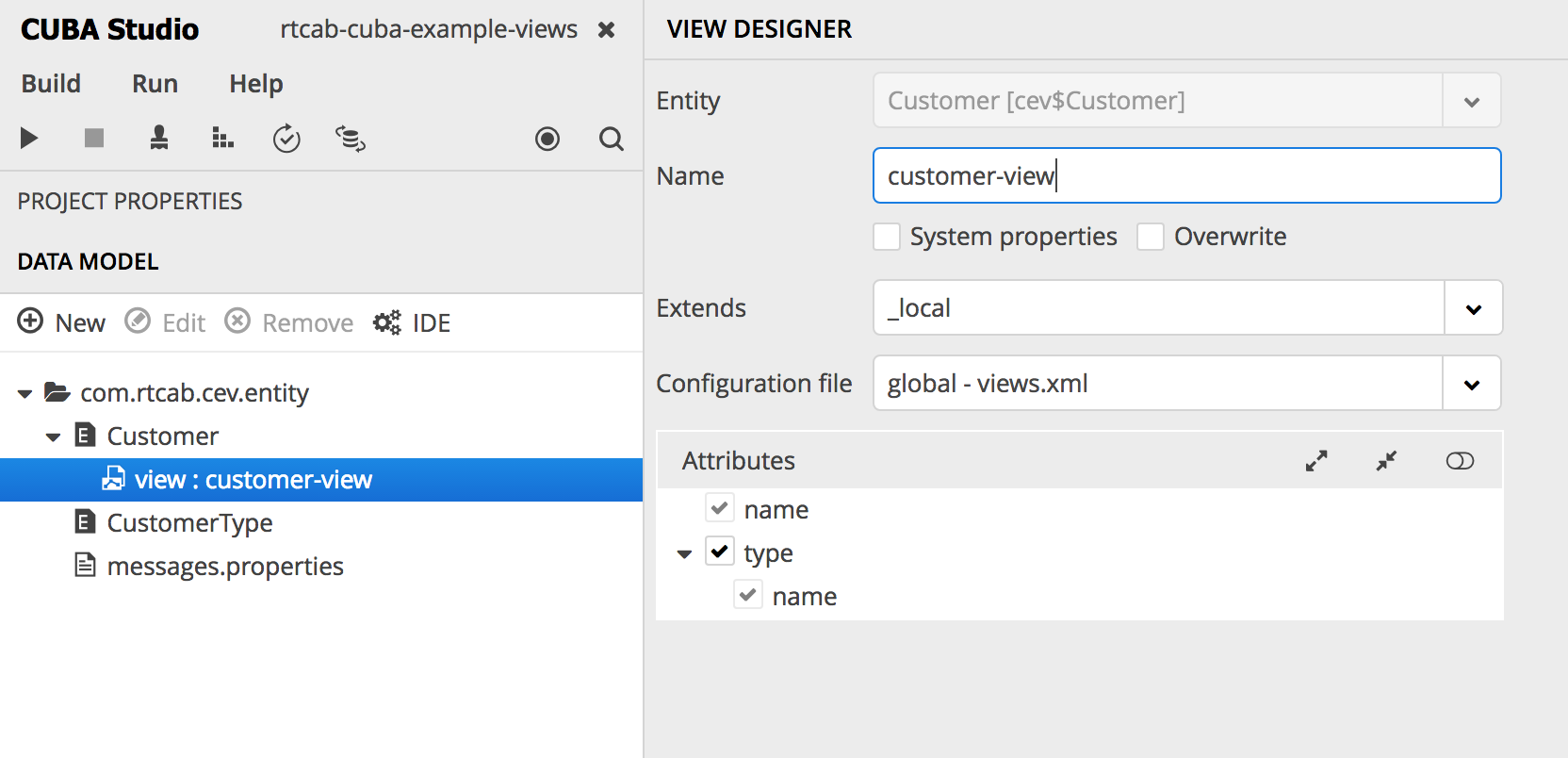
entweder direkt im views.xml- Deskriptor unserer Anwendung:
<view class="com.rtcab.cev.entity.Customer" extends="_local" name="customer-view"> <property name="type" view="_minimal"/> </view>
Danach ändern wir den Link zur Ansicht im Suchbildschirm wie folgt:
<groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="customer-view"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource>
Dies löst das Problem vollständig und jetzt werden die Linkdaten auf dem Kundenbildschirm angezeigt.
_Minimale Ansicht und Instanzname
Was im Zusammenhang mit Ansichten noch erwähnenswert ist, ist die _minimale Ansicht. Die lokale Ansicht hat eine sehr klare Definition: Sie enthält alle Attribute der Entität, die direkte Attribute der Tabelle sind (die keine Fremdschlüssel sind).
Die Definition einer minimalen Darstellung ist nicht so offensichtlich, aber auch ganz klar.
CUBA hat das Konzept eines Entitätsinstanznamens - Instanzname. Der toString() entspricht der toString() -Methode in gutem alten Java. Dies ist eine Zeichenfolgendarstellung einer Entität zur Anzeige auf einer Benutzeroberfläche und zur Verwendung in Links. Der Instanzname wird mithilfe der Annotation der NamePattern- Entität festgelegt.
Es wird folgendermaßen verwendet: @NamePattern("%s (%s)|name,code") . Wir haben zwei Ergebnisse:
Der Instanzname definiert die Zuordnung der Entität zur Benutzeroberfläche
Zunächst bestimmt der Instanzname, welche und in welcher Reihenfolge in der Benutzeroberfläche angezeigt wird, wenn eine Entität auf eine andere Entität verweist (wie Customer auf CustomerType verweist).
In unserem Fall wird der Kundentyp als Name der CustomerType- Instanz angezeigt, zu der der Code in die Klammern eingefügt wird. Wenn der Instanzname nicht festgelegt ist, werden der Name der Entitätsklasse und die ID der jeweiligen Instanz angezeigt. Stimmen Sie zu, dass dies überhaupt nicht das ist, was der Benutzer sehen möchte. In den folgenden Vorher- und Nachher-Screenshots finden Sie Beispiele für beide Fälle.
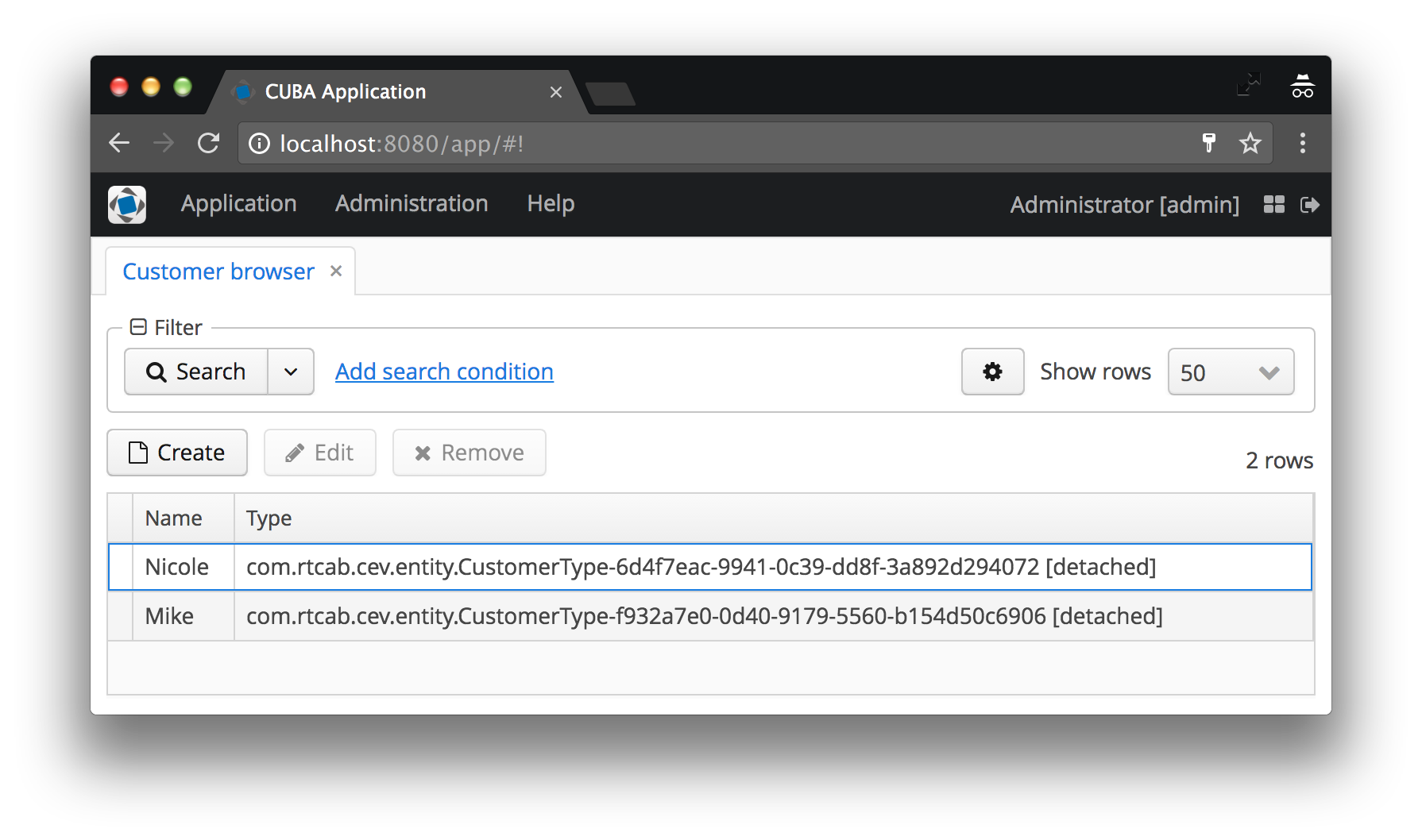
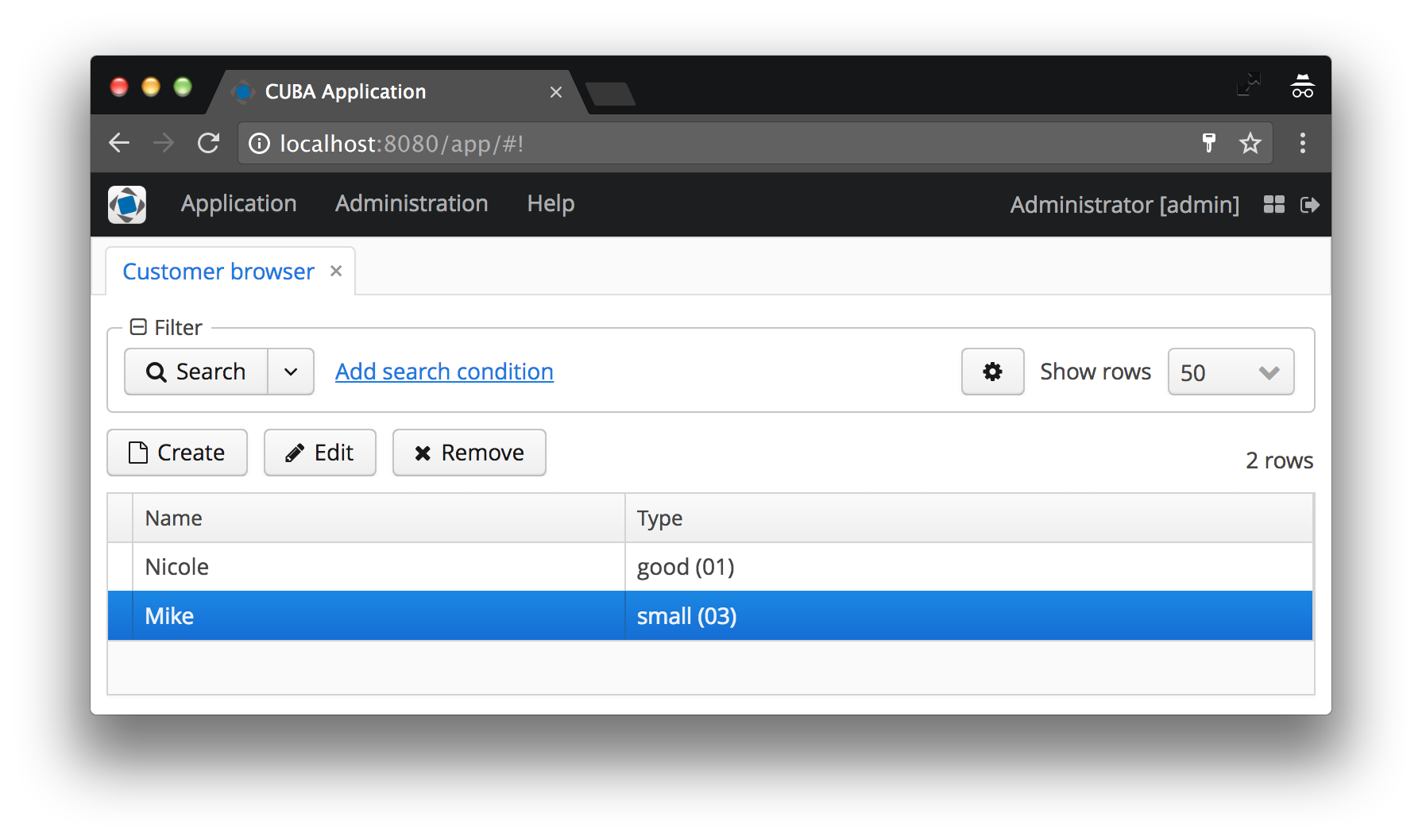
Der Instanzname definiert minimale Ansichtsattribute
Das zweite, was die Annotation von NamePattern beeinflusst, ist: Alle Attribute, die nach dem vertikalen Balken angegeben werden, bilden automatisch eine _minimale Ansicht. Auf den ersten Blick scheint dies offensichtlich, da die Daten in irgendeiner Form in der Benutzeroberfläche angezeigt werden müssen, was bedeutet, dass Sie sie zuerst aus der Datenbank herunterladen müssen. Obwohl ich ehrlich gesagt selten über diese Tatsache nachdenke.
Hierbei ist zu beachten, dass die minimale Darstellung im Vergleich zur lokalen möglicherweise Verweise auf andere Entitäten enthält. Für den Käufer aus dem obigen Beispiel habe ich beispielsweise einen Instanznamen festgelegt, der ein lokales Attribut der Kundenentität ( name ) und ein Referenzattribut ( type ) enthält:
@NamePattern("%s - %s|name,type")
Die Mindestdarstellung kann rekursiv verwendet werden: (Kunde [Instanzname] -> Kundentyp [Instanzname])
Anmerkung des Übersetzers: Seit der Veröffentlichung des Artikels ist eine andere Systemansicht erschienen - _base view, die alle lokalen Nicht-Systemattribute und Attribute enthält, die in der Annotation @NamePattern angegeben sind (d. _minimal _local _minimal + _local ).
Fazit
Abschließend fassen wir das wichtigste Thema zusammen. Dank der Ansichten können wir in CUBA explizit angeben, was aus der Datenbank geladen werden soll. Ansichten bestimmen, was gierig geladen wird, während die meisten anderen Frameworks verdeckt faul laden.
Darstellungen mögen wie ein umständlicher Mechanismus erscheinen, aber auf lange Sicht rechtfertigen sie sich.
Ich hoffe, ich habe es geschafft, auf zugängliche Weise zu erklären, was diese mysteriösen Ansichten tatsächlich sind. Natürlich gibt es fortgeschrittenere Szenarien für ihre Verwendung sowie Fallstricke bei der Arbeit mit Darstellungen im Allgemeinen und mit minimalen Darstellungen im Besonderen, aber ich werde irgendwie in einem separaten Beitrag darüber schreiben.