Ich
poste den zweiten Bericht von unserem
ersten Mitap , der im September stattfand. Das letzte Mal, dass Sie lesen (und sehen) konnten, wie Sie
mit Consul Stateful Services von Ivan Bubnov von BIT.GAMES skalieren, und heute werden wir über CICD sprechen. Genauer gesagt wird unser Systemadministrator Egor Panov darüber berichten, der für die Verfügbarkeit von Infrastruktur und Diensten in Pixonic verantwortlich ist. Unter der Cut-Decodierung der Performance.
Zunächst ist die Spielebranche riskanter - man weiß nie, was genau im Herzen des Spielers versinkt. Und so schaffen wir viele Prototypen. Natürlich erstellen wir Prototypen auf dem Knie von Stöcken, Seilen und anderen improvisierten Materialien.
Es scheint, dass es mit diesem Ansatz im Allgemeinen unmöglich ist, etwas zu tun, das dann unterstützt werden kann. Aber auch in dieser Phase halten wir fest. Wir halten an drei Säulen fest:
- ausgezeichnete Expertise von Testern;
- enge Interaktion mit ihnen;
- die Zeit, die wir zum Testen geben.
Wenn wir also unsere Prozesse nicht aufbauen, z. B. Bereitstellung oder CI (kontinuierliche Integration), werden wir früher oder später zu dem Schluss kommen, dass die Testdauer immer länger wird. Und wir werden entweder alles langsam machen und den Markt verlieren, oder wir werden einfach bei jedem Einsatz explodieren.
Der Aufbau eines CICD-Prozesses ist jedoch nicht so einfach. Einige werden sagen, nun ja, ich werde Jenkins setzen, ich werde schnell etwas anrufen, jetzt habe ich CICD fertig. Nein, dies ist nicht nur ein Werkzeug, sondern auch eine Übung. Beginnen wir in der richtigen Reihenfolge.

Der erste. In vielen Artikeln wird geschrieben, dass alles in einem Repository aufbewahrt werden muss: Code, Tests, Bereitstellung und sogar das Datenbankschema sowie IDE-Einstellungen, die allen gemeinsam sind. Wir sind unseren eigenen Weg gegangen.
Wir haben verschiedene Repositorys zugewiesen: Bereitstellung in unserem Repository, Tests in einem anderen. Es funktioniert schneller. Es passt vielleicht nicht zu Ihnen, aber für uns ist es viel bequemer. Da es an dieser Stelle einen wichtigen Punkt gibt: Sie müssen einen einfachen und transparenten Punkt für alle Trefferflüsse erstellen. Natürlich können Sie das fertige irgendwo herunterladen, aber in jedem Fall müssen Sie es selbst optimieren und verbessern. Für uns lebt eine Bereitstellung beispielsweise von einem eigenen Gitflow, der eher einem GitHub-Flow ähnelt, und die Serverentwicklung lebt von einem eigenen Gitflow.
Der nächste Absatz. Sie müssen einen vollautomatischen Build konfigurieren. Es ist klar, dass der Entwickler das Projekt in der ersten Phase persönlich sammelt, es dann mithilfe von SCP persönlich bereitstellt, selbst startet und an jeden sendet, der es benötigt. Diese Option hielt nicht lange an, ein Bash-Skript wurde angezeigt. Nun, da sich die Umgebung der Entwickler ständig ändert, ist ein spezieller dedizierter Build-Server erschienen. Er lebte sehr lange. Während dieser Zeit gelang es uns, die Anzahl der Server auf bis zu 500 zu erhöhen, Serverkonfigurationen auf Puppet zu konfigurieren, Legacy auf Puppet zu sammeln, Puppet abzulehnen, zu Ansible zu wechseln, und dieser Buildserver lebte weiter.
Sie beschlossen, nach zwei Anrufen alles zu ändern, sie warteten nicht auf einen dritten. Die Geschichte ist klar: Der Buildserver ist ein einzelner Fehlerpunkt, und wenn wir etwas bereitstellen mussten, fiel das Rechenzentrum natürlich vollständig mit unserem Buildserver zusammen. Und der zweite Aufruf: Wir mussten die Java-Version aktualisieren - wir haben sie auf dem Build-Server aktualisiert, auf der Bühne installiert, alles ist cool, alles ist großartig, und wir mussten sofort einen kleinen Bugfix auf dem Produkt starten. Natürlich haben wir vergessen zurückzurollen und alles ist einfach auseinander gefallen.
Danach haben sie alles neu geschrieben, sodass der gesamte Build auf absolut jedem TeamCity-Agenten ausgeführt werden kann, und ihn auf Ansible neu geschrieben, da er auf Ansible konfiguriert wurde. Warum nicht dasselbe Tool auch für die Bereitstellung verwenden?
Die folgende Regel: Je öfter Sie sich verpflichten, desto besser. Und warum? Weil es ein viertes gibt: Jedes Commit wird gesammelt. Und in der Tat noch mehr als jedes Commit. Ich habe bereits gesagt, dass wir TeamCity haben, und es ermöglicht Ihnen, ein Commit von Ihrer Lieblings-IDE aus auszuführen (Sie raten, was ich meine). Eigentlich schnelles Feedback, alles ist super.
Ein defekter Build wird sofort repariert. Sobald Sie die automatische Bereitstellung eingerichtet haben, müssen Sie die automatische Benachrichtigung in Slack einrichten. Wir alle wissen sehr gut, dass ein Entwickler nur in dem Moment weiß, wie sein Code funktioniert, wenn er ihn schreibt. Deshalb: die Person hat es herausgefunden - sofort repariert.
Wir testen die Umgebung, indem wir Produkte wiederholen. Es ist ganz einfach, wir haben Ansible und AWX gewählt. Jemand könnte fragen, aber was ist mit Docker, Kubernetes, OpenShift, wo alle Probleme, die sofort einsatzbereit sind, schon lange gelöst sind? Ich habe vergessen zu sagen, dass wir Komponenten von Linux und Windows haben. Und zum Beispiel den Photon-Server, der unter Windows läuft, konnten wir erst kürzlich mehr oder weniger normal in einen 10-GB-Docker-Container packen. Dementsprechend haben wir eine Windows-Anwendung, die nicht gut in einen Container gepackt werden kann. Es gibt eine Anwendung unter Linux (in Java), die perfekt verpackt ist, aber es gibt keinen Grund dafür. Sie funktioniert überall dort, wo Sie sie ausführen. Das ist Java.
Als nächstes wählten wir zwischen Ansible und Chef. Beide funktionieren gut mit Windows, aber Ansible hat sich für uns als viel einfacher herausgestellt. Als wir AWX bereits installiert hatten, wurde im Allgemeinen alles Feuer. AWX hat Geheimnisse, Grafiken, Geschichte. Sie können einem Menschen weit davon entfernt zeigen, dass er sofort alles sieht und alles klar wird.
Und Sie müssen den Build immer schnell halten. Ich weiß nicht warum, aber wenn Sie ein neues Projekt starten, vergessen Sie den Buildserver, die Agenten und wählen einen Computer aus, der herumlag - dies ist unser Buildserver. Es ist unerwünscht, diesen Fehler zu wiederholen, da alles, worüber ich spreche (schnelles Feedback, Pluspunkte) - alles ist nicht so relevant, wenn die Montage auf Ihrem eigenen Laptop viel schneller beginnt als auf einer Art Server-Farm.

7 Punkte - und wir haben bereits eine Art CI-Prozess aufgebaut. Großartig Das folgende Diagramm ist nicht sichtbar, aber auf der Seite befindet sich noch Graylog. Wer liest unsere Artikel über Habré, der hat schon gesehen,
wie wir Graylog gewählt haben und
wie man es installiert . In jedem Fall hilft es, abzulenken, wenn noch ein Problem aufgetreten ist.
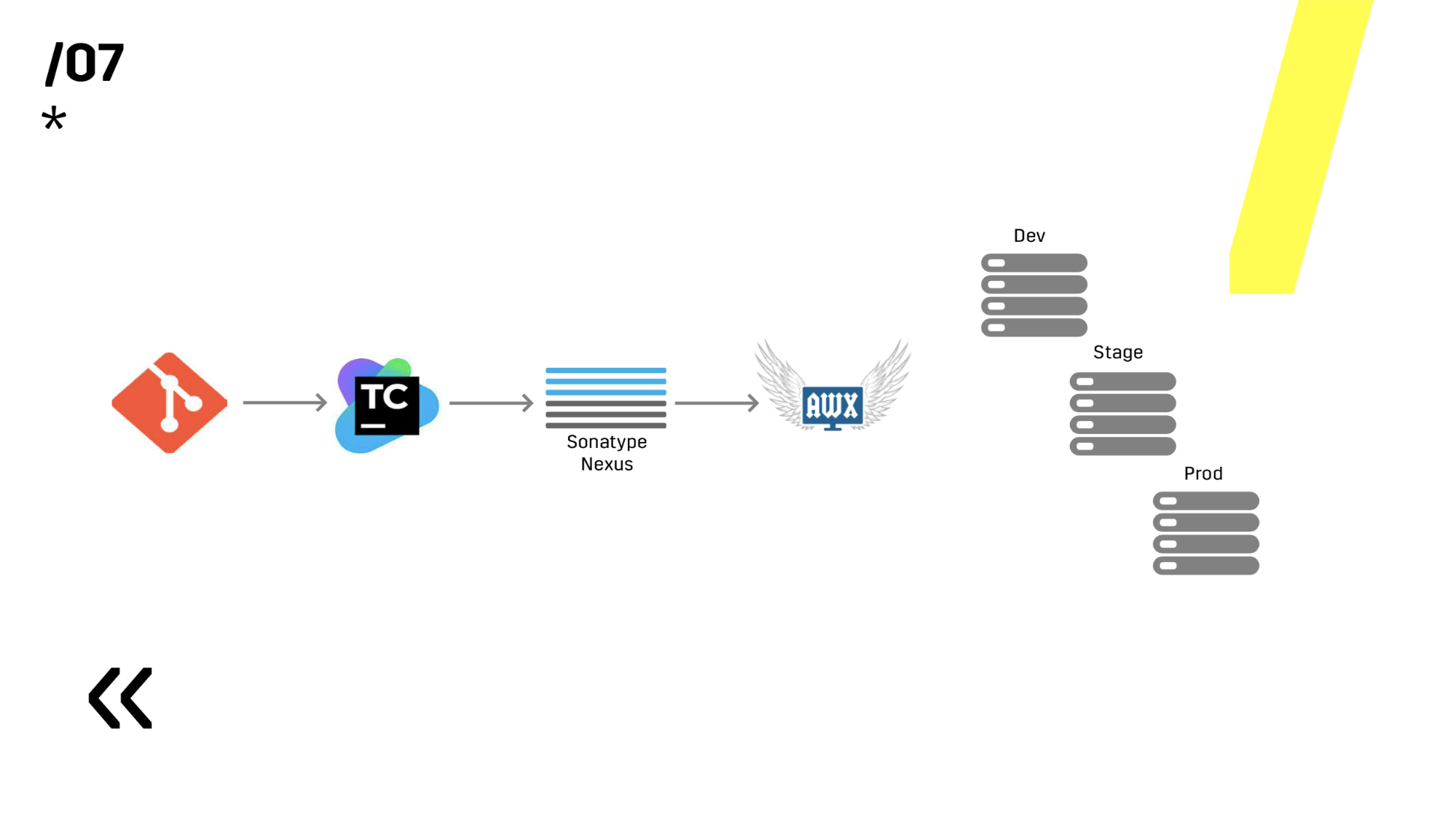
Auf dieser Basis ist es bereits möglich, mit der Bereitstellung fortzufahren.

Aber ich habe bereits im zweiten Absatz über den Einsatz gesprochen, daher werde ich nicht viel darauf eingehen. Ich werde eines über das Leben sagen: Wenn Sie Ansible verwenden, fügen Sie unbedingt diese Serie hinzu, die sich auf der Folie befindet. Es ist mehr als einmal passiert, dass Sie etwas gestartet haben und dann verstehen Sie, aber ich habe es entweder falsch oder falsch oder falsch gestartet, und dann sehen Sie, dass dies nur ein Server ist. Und wir können leicht einen Server verlieren und Sie laden ihn einfach erneut hoch, niemand hat es bemerkt.
Außerdem haben sie das Artefakt-Repository auf Nexus installiert - es ist ein einziger Einstiegspunkt für absolut jeden, nicht nur für CI.
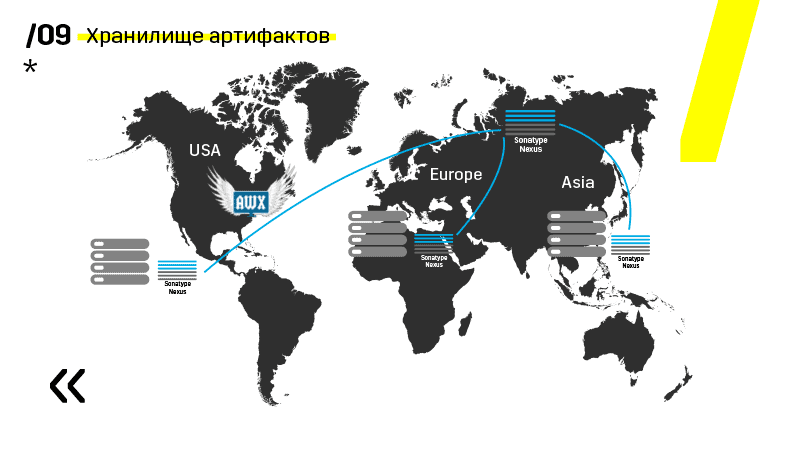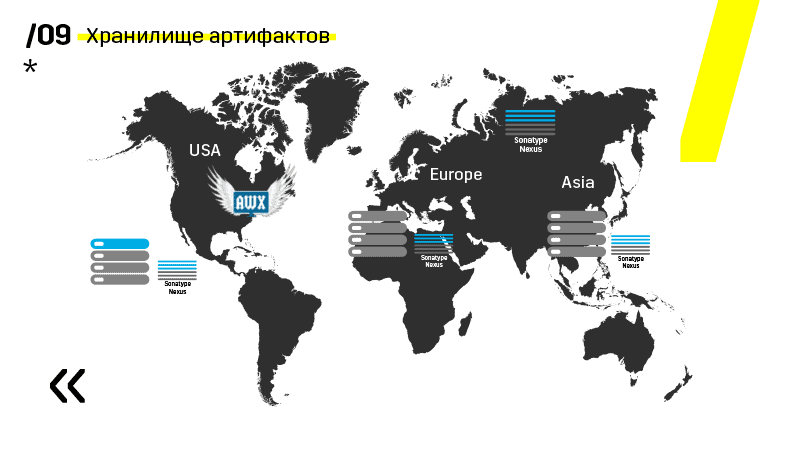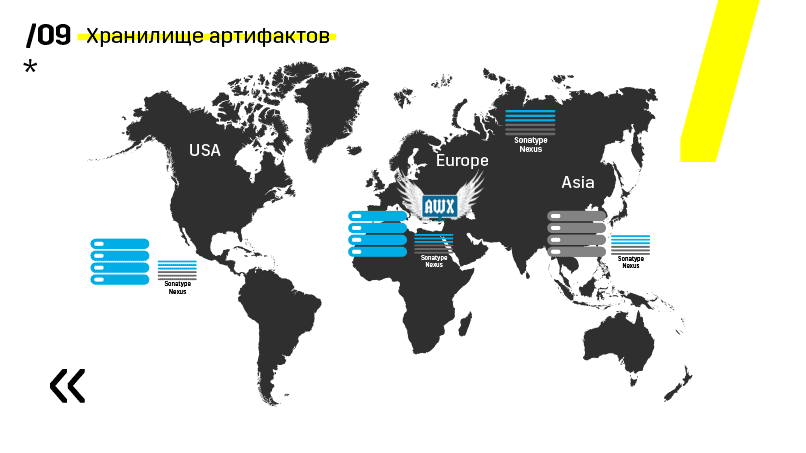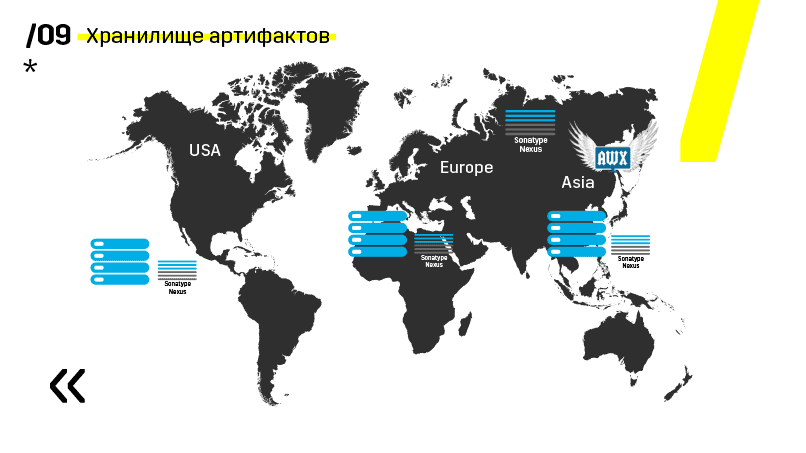
Und es hilft uns sehr, die Wiederholbarkeit sicherzustellen. Da nexus in verschiedenen Regionen als Proxy-Dienste fungieren kann, beschleunigen sie die Bereitstellung, Installation von RPM-Paketen, Docker-Images usw.
Bei der Erstellung eines neuen Projekts ist es ratsam, Komponenten auszuwählen, die einfach zu automatisieren sind. Zum Beispiel war der Photon-Server nicht erfolgreich. In jedem Fall war es die beste Lösung. Aber Cassandra zum Beispiel ist sehr bequem zu aktualisieren und zu automatisieren.
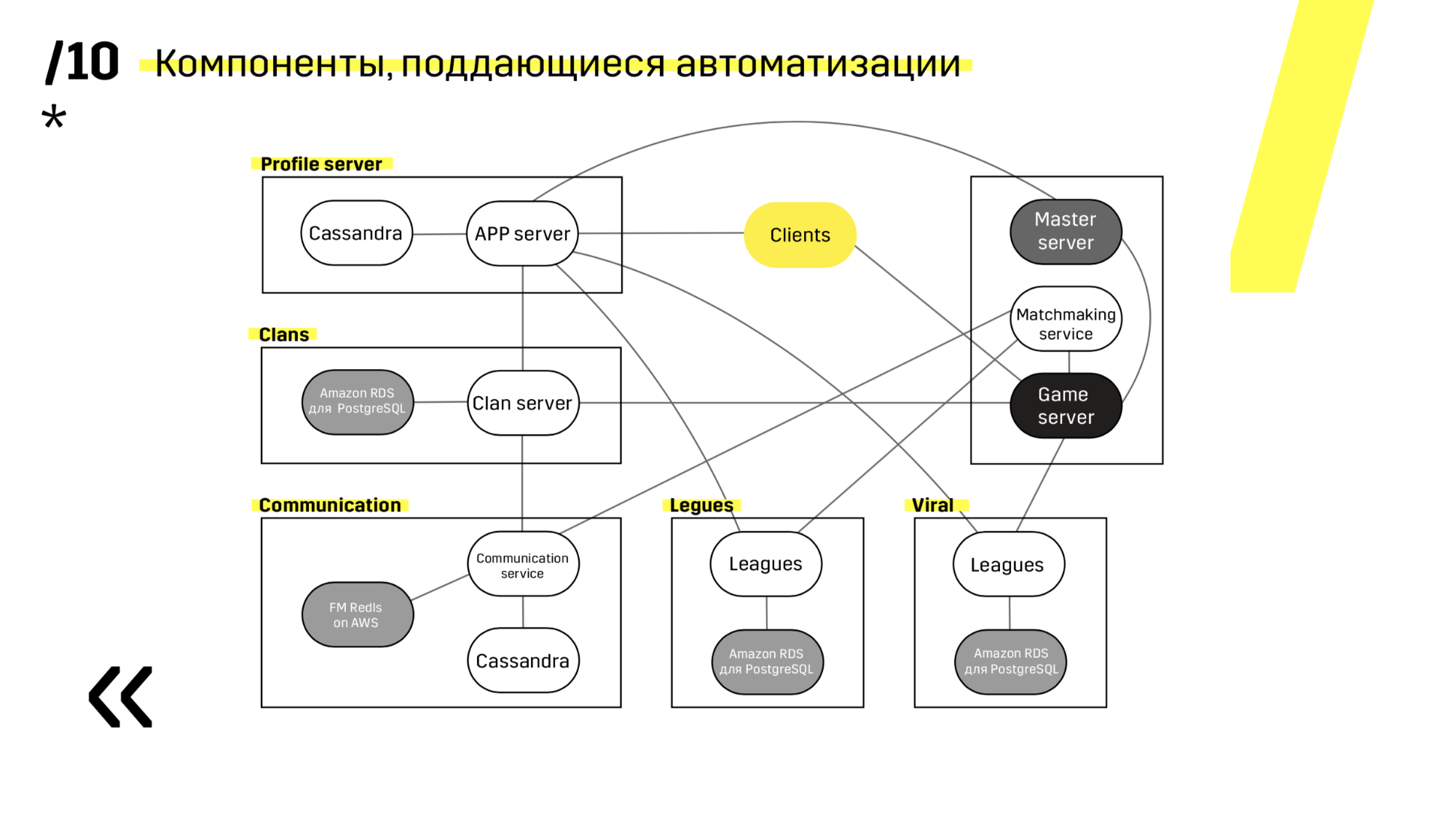
Hier ist ein Beispiel für eines unserer Projekte. Der Client kommt zum APP-Server, wo er ein Profil in der Cassandra-Datenbank hat, und geht dann zum Master-Server, der ihm mithilfe von Matchmaking einen Spieleserver mit einer Art Raum gibt. Alle anderen Dienste werden in Form einer „Anwendungsdatenbank“ erbracht und genauso aktualisiert.
Der zweite Punkt: Sie müssen eine einfache, lose gekoppelte Bereitstellungsarchitektur bereitstellen. Wir haben es geschafft.
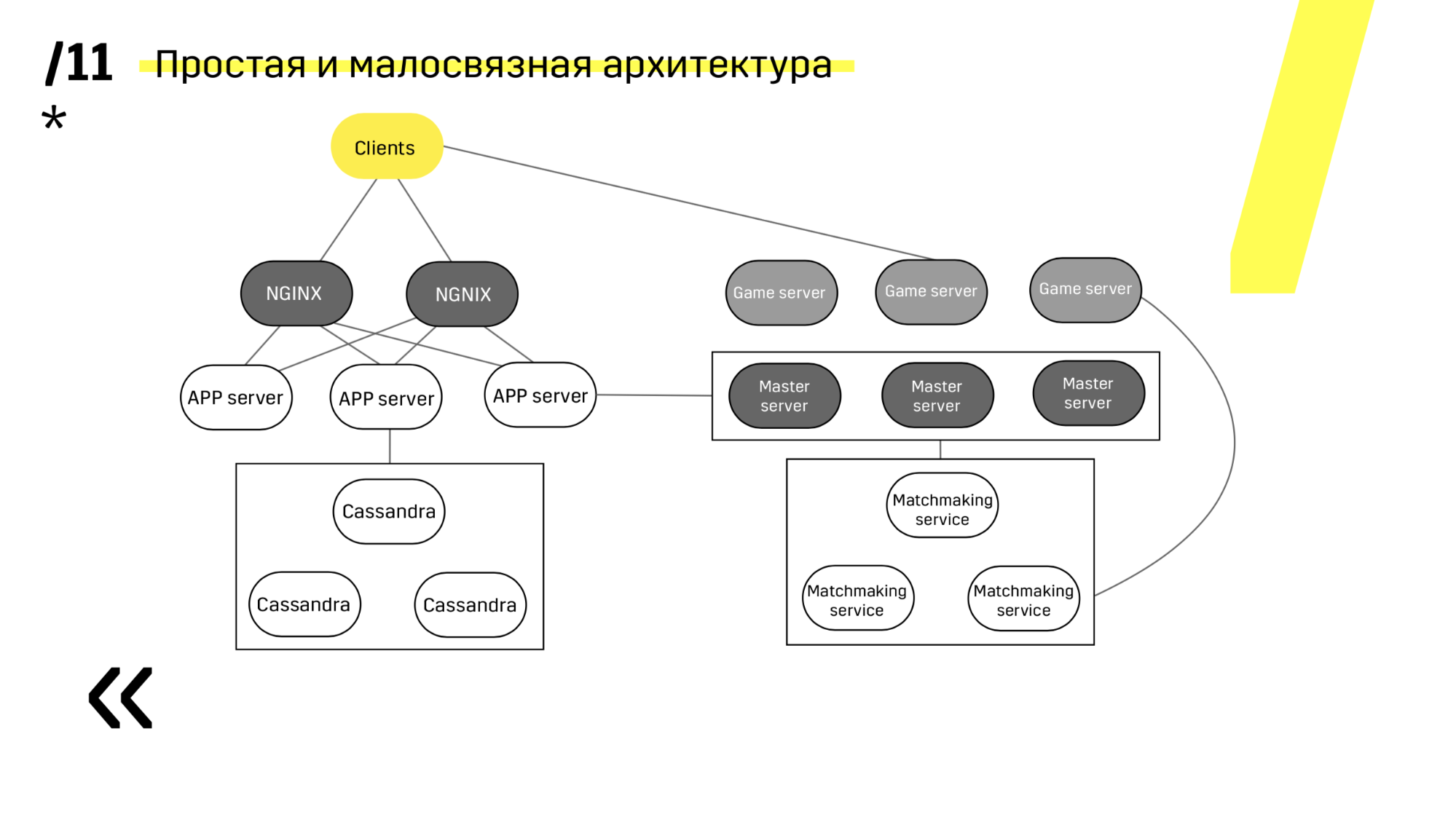
Siehe zum Beispiel das Aktualisieren des App-Servers. Wir haben dedizierte Erkennungsdienste, die den Balancer neu konfigurieren. Wir gehen also einfach zum App-Server, löschen ihn, er stürzt beim Balancing ab und wir aktualisieren alles. Und so mit jedem einzeln.
Master-Server werden fast identisch aktualisiert. Der Client pingt jeden Master-Server in der Region an und wechselt zu dem, auf dem der Ping besser ist. Wenn wir den Master-Server aktualisieren, wird das Spiel möglicherweise etwas langsamer, aber es wird einfach und unkompliziert aktualisiert.
Spieleserver werden etwas anders aktualisiert, da noch ein Spiel läuft. Wir gehen zum Matchmaking, bitten ihn, einen bestimmten Server aus dem Gleichgewicht zu bringen, kommen zum Spieleserver, warten, bis die Spiele genau Null werden, und aktualisieren. Dann kehren wir zum Balancieren zurück.
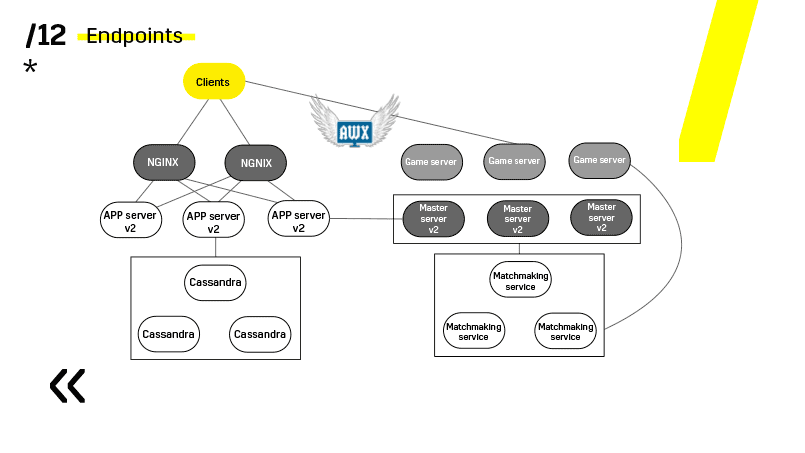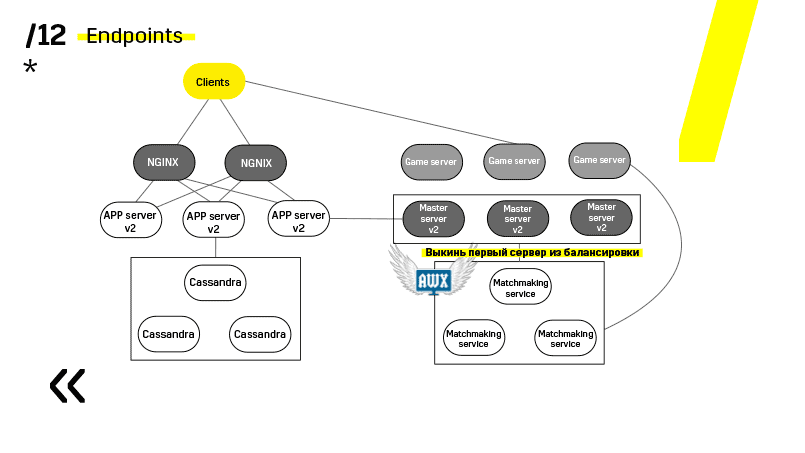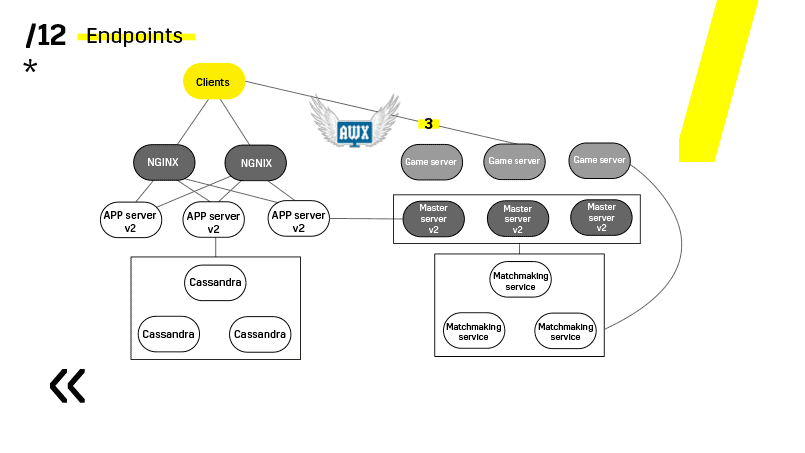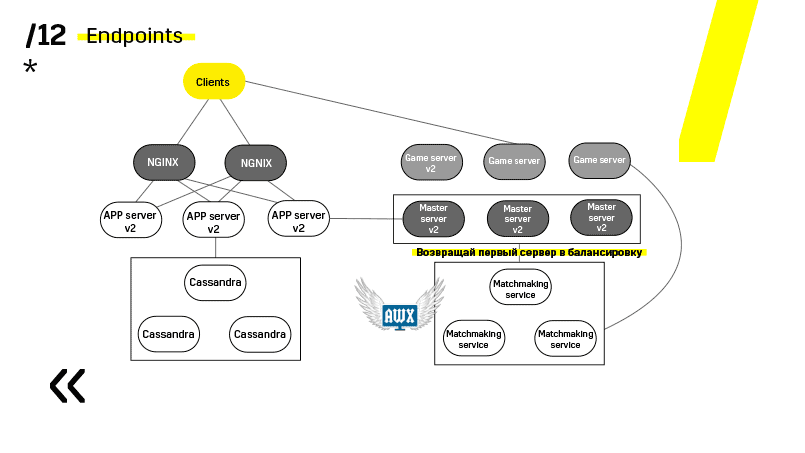
Der entscheidende Punkt hierbei sind die Endpunkte, über die jede der Komponenten verfügt und mit denen die Kommunikation einfach und unkompliziert ist. Wenn Sie ein Beispiel benötigen, gibt es einen Elasticsearch-Cluster. Mit regulären http-Anfragen in JSON können Sie problemlos mit ihm kommunizieren. Und er gibt sofort im selben JSON alle möglichen unterschiedlichen Metriken und allgemeinen Informationen über den Cluster an: grün, gelb, rot.
Nach Abschluss dieser 12 Schritte haben wir die Anzahl der Umgebungen erhöht, mehr Tests durchgeführt, die Bereitstellung wurde beschleunigt und die Mitarbeiter erhielten schnelles Feedback.

Was sehr wichtig ist, wir haben die Einfachheit und Geschwindigkeit der Experimente. Und das ist sehr wichtig, denn wenn es viele Experimente gibt, können wir leicht fehlerhafte Ideen herausfiltern und uns auf die richtigen konzentrieren. Und das nicht aufgrund subjektiver Einschätzungen, sondern anhand objektiver Indikatoren.
Tatsächlich verfolge ich nicht mehr, wenn wir dort eine Bereitstellung haben, wenn die Veröffentlichung. Es gibt kein "Oh, Befreiung!" Gefühl, alles gesammelt und Gänsehaut. Nun, das ist so eine Routineoperation, dass ich regelmäßig in einem Chatroom sehe, dass etwas passiert ist, okay. Das ist wirklich cool. Ihre Systemadministratoren werden vor Freude brüllen, wenn Sie dies tun.
Aber die Welt steht nicht still, sie prallt manchmal ab. Wir müssen etwas verbessern. Zum Beispiel möchte ich die Protokolle des Builds auch in Graylog einfügen. Dies erfordert eine weitere Verfeinerung der Protokollierung, sodass es keine separate Story gibt, sondern eindeutig: Auf diese Weise wurde der Build zusammengestellt, also getestet, bereitgestellt und verhält sich auf dem Produkt. Und kontinuierliche Überwachung - das ist eine kompliziertere Geschichte.

Wir verwenden Zabbix, und er ist für solche Ansätze überhaupt nicht bereit. Die 4. Version wird bald veröffentlicht, wir werden herausfinden, was da ist und wenn alles schlecht ist, werden wir eine andere Lösung finden. Ich werde Ihnen sagen, wie es beim nächsten Treffen ausgehen wird.
Fragen aus dem Publikum
Und was passiert, wenn Sie Müll in die Produktion werfen? Sie haben beispielsweise nichts nach Leistung berechnet und bei der Integration ist alles in Ordnung. In der Produktion sehen Sie jedoch, dass Ihre Server abstürzen. Wie rollst du zurück? Gibt es einen Save Me Button?Wir haben versucht, eine Rollback-Automatisierung durchzuführen. Sie können dann in Berichten darüber sprechen, wie cool es funktioniert, wie wunderbar alles ist. Aber zuerst entwerfen wir so, dass die Versionen abwärtskompatibel sind, und testen dies. Und als wir dieses vollautomatische Ding machten, das etwas prüft und zurückrollt und dann anfängt, damit zu leben, stellten wir fest, dass wir uns viel mehr Mühe geben, als wenn wir nur die alte Version mit demselben Pedal nehmen .
In Bezug auf die automatische Aktualisierung der Bereitstellung: Warum nehmen Sie Änderungen am aktuellen Server vor und fügen keinen neuen hinzu und fügen ihn nur der Zielgruppe oder dem Balancer hinzu?Also schneller.
Wenn Sie beispielsweise die Java-Version aktualisieren müssen, ändern Sie den Instanzstatus bei Amazon, aktualisieren die Java-Version oder etwas anderes. Wie können Sie dann in diesem Fall ein Rollback durchführen? Nehmen Sie Änderungen am Produktionsserver vor?Ja, jede Komponente funktioniert gut mit der neuen und der alten Version. Ja, möglicherweise müssen Sie den Server neu laden.
Es gibt Zustandsänderungen, wenn große Probleme möglich sind ...Dann explodieren.
Es scheint mir nur, einen neuen Server hinzuzufügen und ihn einfach der Zielgruppe in der Zielgruppe zuzuordnen - eine kleine Aufgabe in Komplexität und eine ziemlich gute Praxis.Wir werden auf Hardware gehostet, nicht in den Clouds. Wir können einen Server hinzufügen - es ist möglich, aber etwas länger als nur in die Cloud zu klicken. Daher nehmen wir unseren aktuellen Server (wir haben keine solche Last, damit wir einige der Maschinen nicht herausnehmen können) - wir nehmen einige der Maschinen heraus, aktualisieren sie, setzen den Verkaufsverkehr dort ein, sehen, wie es funktioniert, wenn alles in Ordnung ist, werden wir weiterhin alles tun andere Autos.
Sie sagen, wenn jedes Commit gesammelt wird und wenn alles schlecht ist, regiert der Entwickler alles sofort. Verstehst du, dass alles schlecht ist? Welche Commits werden gemacht?Anfangs war es natürlich eine Art manueller Test, das Feedback ist langsam. Mit einer Art automatischer Tests auf Appium wird all dies abgedeckt, es funktioniert und gibt eine Art Feedback darüber, ob die Tests gefallen sind oder nicht.
Das heißt, Zuerst wird jedes Commit ausgerollt und beobachten die Tester es?Nun, nicht jeder, das ist Übung. Aus diesen 12 Punkten haben wir ein Training gemacht - beschleunigt. In der Tat ist dies eine lange und harte Arbeit, vielleicht im Laufe des Jahres. Aber im Idealfall kommen Sie dazu und alles funktioniert. Ja, wir brauchen eine Art Autotest, zumindest einen minimalen Satz, damit alles für Sie funktioniert.
Und die Frage ist kleiner: Es gibt einen App-Server auf dem Bild und so weiter. Interessiert mich das dort? Sie sagten, dass Sie anscheinend keinen Docker haben. Was ist ein Server? Nacktes Java oder was?Irgendwo ist dies Photon unter Windows (ein Spieleserver), der App-Server ist eine Java-Anwendung unter Tomcat.
Das heißt, Keine Virtualoks, keine Container, nichts?Java ist ein Container.
Und läuft alles mit Ansible?Ja Das heißt, Zu einem bestimmten Zeitpunkt haben wir einfach nicht in Orchestrierung investiert, denn warum? In jedem Fall muss das Windows auf die gleiche Weise separat verwaltet werden, und hier wird absolut alles mit einem Tool abgedeckt.
Und wie wird die Datenbank bereitgestellt? Abhängigkeit von Komponente oder Dienstleistung?Es gibt ein Schema im Dienst selbst, das bereitgestellt wird, wenn es angezeigt wird und entwickelt werden muss, damit nichts gelöscht wird, sondern nur etwas hinzugefügt wird und abwärtskompatibel ist.
Ist Ihre Basis auch Eisen oder befindet sich die Basis irgendwo in der Cloud bei Amazon?Die größte Basis ist Eisen, aber es gibt andere. Es gibt kleine, RDS ist nicht mehr eisern, virtuell. Diese kleinen Dienste, die ich gezeigt habe: Chats, Ligen, Chatten mit Facebook, Clans, einer davon ist RDS.
Master Server - wie ist das?Dies ist in der Tat der gleiche Spielserver, nur mit einem Zeichen des Meisters und er ist ein Balancer. Das heißt, Der Client pingt alle Master an, dann empfängt er denjenigen, an den der Ping geringer ist, und bereits sammelt der Master-Server mithilfe von Matchmaking Räume auf Spielservern und sendet den Spieler.
Ich verstehe richtig, dass Sie für jeden Rollout, den Sie schreiben (falls Funktionen angezeigt werden), eine Migration durchführen, um die Daten zu aktualisieren. Sie sagten, Sie nehmen alte Artefakte und füllen sie - was passiert mit den Daten? Schreiben Sie eine Migration, um die Basis zurückzusetzen?Dies ist eine sehr seltene Rollback-Operation. Ja, Sie schreiben die Migration von Stiften und was zu tun ist.
Wie wird ein Server-Update mit Client-Updates synchronisiert? Das heißt, Sie müssen eine neue Version des Spiels veröffentlichen. Aktualisieren Sie zuerst alle Server, dann werden die Clients aktualisiert? Unterstützt der Server sowohl die alte als auch die neue Version?Ja, wir entwickeln das Umschalten und Dimmen von Funktionen. Das heißt, Dies ist ein spezieller Griff, ein Hebel, mit dem Sie einige Funktionen später aktivieren können. Sie können absolut ruhig upgraden, um sicherzustellen, dass alles für Sie funktioniert, aber diese Funktion nicht einschließen. Und wenn Sie den Client bereits verteilt haben, können Sie durch Fiddimming um 10% straffen, sicherstellen, dass alles in Ordnung ist, und dann in vollem Umfang.
Sie sagen, dass Sie Teile des Projekts separat in verschiedenen Repositorys gespeichert haben, d. H. Hast du einen Entwicklungsprozess? Wenn Sie das Projekt selbst ändern, sollten Ihre Tests fallen, da Sie das Projekt geändert haben. Daher müssen die separat liegenden Tests so schnell wie möglich behoben werden.Ich habe dir von der "engen Interaktion der Wale mit den Testern" erzählt. Dieses Schema mit verschiedenen Repositorys funktioniert nur dann sehr gut, wenn eine sehr dichte Kommunikation besteht. Dies ist für uns kein Problem, jeder kommuniziert leicht miteinander, es gibt eine gute Kommunikation.
Das heißt, Unterstützen Tester das Test-Repository in Ihrem Team? Und Autotests liegen getrennt?Ja Sie haben eine Funktion erstellt und können genau die Autotests, die Sie benötigen, aus dem Tester-Repository erfassen und nicht alles andere überprüfen.
Solch ein Ansatz, wenn alles schnell läuft - Sie können es sich leisten, bei jedem Commit sofort zum Produkt zu gehen. Folgen Sie solchen Taktiken oder komponieren Sie einige Veröffentlichungen? Das heißt, Einmal in der Woche, nicht freitags, nicht am Wochenende. Haben Sie eine Veröffentlichungstaktik oder ist die Funktion bereit? Kann ich sie veröffentlichen? Denn wenn Sie aus kleinen Funktionen eine kleine Version machen, ist es weniger wahrscheinlich, dass alles kaputt geht, und wenn etwas kaputt geht, wissen Sie definitiv was.Es ist keine Eisidee, Client-Benutzer zu zwingen, alle fünf Minuten oder jeden Tag eine neue Version herunterzuladen. In jedem Fall werden Sie an den Kunden gebunden. Es ist großartig, wenn Sie ein Webprojekt haben, in dem Sie mindestens jeden Tag aktualisieren können und nichts tun müssen. Die Geschichte ist mit dem Kunden komplizierter, wir haben eine Art Release-Taktik und bleiben dabei.
Sie haben über die Einführung der Automatisierung auf Produktservern gesprochen, und (so wie ich es verstehe) gibt es auch die Einführung der Automatisierung für einen Test - was ist mit Entwicklungsumgebungen? Gibt es irgendeine Art von Automatisierung, die von den Entwicklern bereitgestellt wird?Fast das Gleiche. Das einzige, was nicht die Eisenserver sind, sondern in der virtuellen Maschine, aber das Wesentliche ist ungefähr dasselbe. Zur gleichen Zeit haben wir auf demselben Ansible (wir haben Ovirt) die Erstellung dieser virtuellen Maschine und die Rändelung darauf geschrieben.
Haben Sie die ganze Geschichte in einem Projekt zusammen mit den Ansible-Produkten und Testkonfigurationen gespeichert oder lebt und entwickelt sie sich separat?Wir können sagen, dass dies separate Projekte sind. Dev (wir nennen es devbox) ist eine Geschichte, wenn alles in einer Packung ist, und auf dem Produkt ist es eine verteilte Geschichte.
Weitere Gespräche mit Pixonic DevGAMM Talks