Fast alle neuen Yandex-Mitarbeiter sind erstaunt über das Ausmaß der Belastungen, denen unsere Produkte ausgesetzt sind. Tausende von Hosts mit Hunderttausenden von Anfragen pro Sekunde. Und dies ist nur eine der Dienstleistungen. Gleichzeitig müssen wir in Sekundenbruchteilen auf Anfragen reagieren. Selbst eine geringfügige Änderung des Produkts kann erhebliche Auswirkungen auf die Leistung haben. Daher ist es wichtig, die Auswirkungen Ihres Codes auf den Service zu testen und zu bewerten.
In unserem Service für Werbetechnologien werden Tests im Rahmen der Continuous-Integration-Methodik durchgeführt, die wir am 25. Oktober auf der Yandex- Veranstaltung von innen ausführlicher diskutieren werden. Heute werden wir den Lesern von Habr die Erfahrung der Automatisierung der Bewertung wichtiger Produktmetriken im Zusammenhang mit der Serviceleistung mitteilen. Sie lernen, wie Sie einer Maschine eine Analyse anvertrauen und diese nicht in Diagrammen verfolgen. Lass uns gehen!

Es geht nicht darum, wie man die Site testet. Hierfür gibt es viele Online-Tools. Heute werden wir über einen hoch ausgelasteten internen Backend-Service sprechen, der Teil eines großen Systems ist und Informationen für einen externen Service vorbereitet. In unserem Fall für Suchergebnisseiten und Partnerseiten. Wenn unsere Komponente keine Zeit hat zu antworten, werden die Informationen daraus einfach nicht an den Benutzer weitergegeben. Das Unternehmen wird also Geld verlieren. Daher ist es sehr wichtig, rechtzeitig zu reagieren.
Welche wichtigen Servermetriken können hervorgehoben werden?
- Anfrage pro Sekunde (RPS) . Das Glück eines Benutzers ist uns natürlich wichtig. Aber was ist, wenn nicht einer, sondern Tausende von Benutzern zu Ihnen kamen? Wie viele Anforderungen pro Sekunde kann Ihr Server standhalten und nicht fallen?
- Zeit pro Anfrage . Der Inhalt der Website sollte so schnell wie möglich gerendert werden, damit der Benutzer nicht müde wird zu warten und nicht in den Laden für Popcorn geht. In unserem Fall wird er keinen wichtigen Teil der Informationen auf der Seite sehen.
- Resident Set Size (RSS) . Stellen Sie sicher, dass Sie überwachen, wie viel Speicher Ihr Programm belegt. Wenn der Dienst den gesamten Speicher belegt, ist es kaum möglich, über Fehlertoleranz zu sprechen.
- HTTP-Fehler .
Also lasst es uns in Ordnung bringen.
Anfrage pro Sekunde
Unser Entwickler, der sich schon lange mit Lasttests beschäftigt, spricht gerne über die kritische Ressource des Systems. Mal sehen, was es ist.
Jedes System hat seine eigenen Konfigurationsmerkmale, die den Betrieb bestimmen. Zum Beispiel Warteschlangenlänge, Antwortzeitlimit, Threads-Worker-Pool usw. Daher kann es vorkommen, dass die Kapazität Ihres Dienstes auf einer dieser Ressourcen beruht. Sie können ein Experiment durchführen. Erhöhen Sie nacheinander jede Ressource. Eine Ressource, deren Erhöhung die Kapazität Ihres Dienstes erhöht, ist für Sie von entscheidender Bedeutung. In einem gut konfigurierten System müssen Sie nicht eine Ressource, sondern mehrere Ressourcen erhöhen, um die Kapazität zu erhöhen. Dies kann aber immer noch "gefühlt" werden. Es ist großartig, wenn Sie Ihr System so konfigurieren können, dass alle Ressourcen mit voller Stärke arbeiten und der Service in den vorgegebenen Zeitrahmen passt.
Um abzuschätzen, wie viele Anforderungen Ihr Server pro Sekunde aushält, müssen Sie einen Anforderungsstrom an ihn senden. Da wir diesen Prozess in das CI-System integriert haben, verwenden wir eine sehr einfache „Waffe“ mit eingeschränkter Funktionalität. Aber von Open Source Software ist Yandex.Tank perfekt für diese Aufgabe. Er hat detaillierte Unterlagen . Ein Geschenk an Tank ist ein Service zum Anzeigen der Ergebnisse.
Ein kleines Stück. Yandex.Tank verfügt über eine ziemlich umfangreiche Funktionalität, die nicht nur auf die Automatisierung von Beschussanforderungen beschränkt ist. Es wird auch helfen, Metriken Ihres Dienstes zu sammeln, Diagramme zu erstellen und das Modul mit der Logik zu verbinden, die Sie benötigen. Generell empfehlen wir dringend, ihn kennenzulernen.
Jetzt müssen Sie Anfragen an den Tank weiterleiten, damit diese bei uns ausgelöst werden können. Die Anforderungen, mit denen Sie den Server schälen, können vom gleichen Typ sein, künstlich erstellt und weitergegeben werden. Messungen sind jedoch viel genauer, wenn Sie für einen bestimmten Zeitraum einen echten Pool von Anfragen von Benutzern erfassen können.
Die Kapazität kann auf zwei Arten gemessen werden.
Offenes Lastmodell (Stresstest)
Machen Sie "Benutzer", dh mehrere Threads, die eine Anfrage an Ihr System senden. Die Last, die wir nicht geben werden, ist konstant, sondern baut sie auf oder speist sie sogar in Wellen. Dann bringt es uns dem wirklichen Leben näher. Wir erhöhen den RPS und erfassen den Punkt, an dem der geschälte Dienst die SLA „durchbricht“. So können Sie die Grenzen des Systems finden.
Um die Anzahl der Benutzer zu berechnen, können Sie die Little-Formel verwenden (Sie können hier darüber lesen). Ohne die Theorie sieht die Formel folgendermaßen aus:
RPS = 1000 / T * Arbeiter, wobei
• T - durchschnittliche Zeit der Anforderungsverarbeitung (in Millisekunden);
• Arbeiter - die Anzahl der Fäden;
• 1000 / T-Anforderungen pro Sekunde - Dieser Wert wird von einem Single-Threaded-Generator generiert.
Modell mit geschlossener Last (Lastprüfung)
Wir nehmen eine feste Anzahl von "Benutzern". Sie müssen es so konfigurieren, dass die Eingabewarteschlange, die der Konfiguration Ihres Dienstes entspricht, immer verstopft ist. Gleichzeitig macht es keinen Sinn, die Anzahl der Threads über das Warteschlangenlimit zu setzen, da wir uns auf dieser Anzahl ausruhen und die verbleibenden Anforderungen vom Server mit einem 5xx-Fehler verworfen werden. Wir prüfen, wie viele Anfragen pro Sekunde das Design ausgeben kann. Ein solches Schema ähnelt im allgemeinen Fall nicht dem tatsächlichen Anforderungsfluss, hilft jedoch dabei, das Verhalten des Systems bei maximaler Last darzustellen und seinen Durchsatz zum aktuellen Zeitpunkt abzuschätzen.
Für die überwiegende Mehrheit der Systeme (bei denen die kritische Ressource nicht mit der Verarbeitung von Verbindungen zusammenhängt) ist das Ergebnis dasselbe. Gleichzeitig ist das geschlossene Modell geräuschärmer, da sich das System während des gesamten Tests im für uns interessanten Lastbereich befindet.
Beim Testen unseres Service verwenden wir ein geschlossenes Modell. Nach dem Schießen gibt uns die Waffe an, wie viele Anfragen pro Sekunde unser Service stellen konnte. Yandex.Tank dieser Indikator ist auch leicht zu erkennen.
Zeit pro Anfrage
Wenn wir zum vorherigen Absatz zurückkehren, wird deutlich, dass es bei einem solchen Schema keinen Sinn macht, die Antwortzeit auf eine Anfrage zu bewerten. Je stärker wir das System laden, desto mehr verschlechtert es sich und desto länger reagiert es. Um die Antwortzeit zu testen, sollte der Ansatz daher unterschiedlich sein.
Um die durchschnittliche Antwortzeit zu erhalten, verwenden wir denselben Yandex.Tank. Erst jetzt setzen wir den RPS entsprechend dem Durchschnittsindikator Ihres Systems in der Produktion. Nach dem Beschuss erhalten wir Antwortzeiten für jede Anfrage. Basierend auf den gesammelten Daten können Perzentile der Antwortzeiten berechnet werden.
Als nächstes müssen Sie verstehen, welches Perzentil wir für wichtig halten. Zum Beispiel bauen wir auf der Produktion auf. Wir können 1% der Anfragen nach Fehlern, Nichtantworten, Debugging-Anfragen, die lange Zeit funktionieren, Problemen mit dem Netzwerk usw. hinterlassen. Daher halten wir die Antwortzeit für signifikant, die 99% der Anfragen berücksichtigt.
Resident Set Größe
Unser Server arbeitet direkt mit Dateien über mmap . Wenn wir den RSS-Index messen, möchten wir wissen, wie viel Speicher das Programm während des Betriebs vom Betriebssystem benötigt hat.
Unter Linux wird die Datei / proc / PID / smaps geschrieben - dies ist eine kartenbasierte Erweiterung, die den Speicherverbrauch für jede der Prozesszuordnungen anzeigt. Wenn Ihr Prozess tmpfs verwendet, werden sowohl anonymer als auch nicht anonymer Speicher in Smaps geraten. Nicht anonymer Speicher umfasst beispielsweise Dateien, die in den Speicher geladen werden. Hier ist ein Beispieleintrag in smaps. Eine bestimmte Datei wird angegeben und ihr Parameter Anonym = 0 KB.
7fea65a60000-7fea65a61000 r--s 00000000 09:03 79169191 /place/home/.../some.yabs Size: 4 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr me ms
Dies ist ein Beispiel für eine anonyme Speicherzuweisung. Wenn ein Prozess (dieselbe mmap) das Betriebssystem auffordert, eine bestimmte Speichergröße zuzuweisen, wird ihm eine Adresse zugewiesen. Während des Prozesses wird nur virtueller Speicher belegt. Zu diesem Zeitpunkt wissen wir noch nicht, welcher physische Speicherplatz zugewiesen wird. Wir sehen eine namenlose Aufzeichnung. Dies ist ein Beispiel für die Zuweisung von anonymem Speicher. Das System wurde mit einer Größe von 24572 kB angefordert, aber sie verwendeten es nicht und tatsächlich wurde nur RSS = 4 kB genommen.
7fea67264000-7fea68a63000 rw-p 00000000 00:00 0 Size: 24572 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 4 kB Referenced: 4 kB Anonymous: 4 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac
Da der zugewiesene nicht anonyme Speicher nach dem Stoppen des Prozesses nirgendwo hingeht, wird die Datei nicht gelöscht. Wir sind nicht an einem solchen RSS interessiert.
Bevor Sie mit dem Aufnehmen auf dem Server beginnen, fassen wir das RSS aus / proc / PID / smaps zusammen, das für anonymen Speicher reserviert ist, und merken es sich. Wir führen Schalen durch, ähnlich der Testzeit pro Anfrage. Betrachten Sie RSS nach Abschluss erneut. Der Unterschied zwischen dem Anfangs- und dem Endzustand ist die Speichermenge, die Ihr Prozess während des Betriebs verwendet hat.
HTTP-Fehler
Vergessen Sie nicht, die Antwortcodes zu befolgen, die der Service während des Tests zurückgibt. Wenn beim Einrichten eines Tests oder einer Umgebung ein Fehler aufgetreten ist und der Server für alle Ihre Anforderungen 5xx- und 4xx-Fehler zurückgegeben hat, war ein solcher Test nicht sinnvoll. Wir überwachen den Anteil der schlechten Antworten. Wenn viele Fehler vorliegen, wird der Test als ungültig betrachtet.
Ein bisschen über Messgenauigkeit
Und jetzt das Wichtigste. Kehren wir zu den vorherigen Absätzen zurück. Die absoluten Werte der von uns berechneten Metriken sind für uns nicht so wichtig. Nein, natürlich können Sie unter Berücksichtigung aller Faktoren, Fehler und Schwankungen eine Stabilität der Indikatoren erreichen. Schreiben Sie parallel eine wissenschaftliche Arbeit zu diesem Thema (übrigens, wenn jemand nach einer suchte, könnte dies eine gute Option sein). Das interessiert uns aber nicht.
Es ist wichtig, dass wir das spezifische Commit für den Code in Bezug auf den vorherigen Status des Systems beeinflussen. Das heißt, der Unterschied zwischen Metriken von Commit zu Commit ist wichtig. Und hier ist es notwendig, einen Prozess einzurichten, der diese Differenz vergleicht und gleichzeitig die Stabilität des Absolutwerts in diesem Intervall sicherstellt.
Die Umgebung, Anforderungen, Daten, Servicestatus - alle uns zur Verfügung stehenden Faktoren sollten festgelegt werden. Es ist dieses System, das im Rahmen der kontinuierlichen Integration für uns funktioniert und uns Informationen über alle Arten von Änderungen liefert, die bei jedem Commit aufgetreten sind. Trotzdem wird es nicht möglich sein, alles zu reparieren, es wird Lärm geben. Wir können das Rauschen natürlich reduzieren, indem wir das Sample erhöhen, dh mehrere Iterationen der Aufnahme durchführen. Nach dem Aufnehmen von beispielsweise 15 Iterationen können wir den Median der resultierenden Stichprobe berechnen. Außerdem muss ein Gleichgewicht zwischen Rauschen und Aufnahmedauer gefunden werden. Zum Beispiel haben wir uns auf einen Fehler von 1% geeinigt. Wenn Sie eine komplexere und genauere statistische Methode gemäß Ihren Anforderungen auswählen möchten, empfehlen wir ein Buch , in dem Optionen mit einer Beschreibung, wann und welche verwendet werden, aufgeführt sind.
Was kann man sonst noch mit Lärm machen?
Beachten Sie, dass die Umgebung, in der Sie Tests durchführen, bei solchen Tests eine wichtige Rolle spielt. Der Prüfstand sollte zuverlässig sein und keine anderen Programme ausführen, da dies zu einer Verschlechterung Ihres Dienstes führen kann. Darüber hinaus können und werden die Ergebnisse vom Lastprofil, der Umgebung, der Datenbank und verschiedenen „magnetischen Stürmen“ abhängen.
Im Rahmen eines einzelnen Commit-Tests führen wir mehrere Iterationen auf verschiedenen Hosts durch. Erstens, wenn Sie die Cloud verwenden, kann dort alles passieren. Auch wenn die Cloud wie unsere spezialisiert ist, funktionieren Serviceprozesse dort immer noch. Daher können Sie sich nicht auf das Ergebnis eines Hosts verlassen. Und wenn Sie einen eisernen Wirt haben, in dem es wie in der Cloud keinen Standardmechanismus zum Erhöhen der Umgebung gibt, können Sie ihn sogar versehentlich einmal zerbrechen und so belassen. Und er wird dich immer anlügen. Deshalb fahren wir unsere Tests in der Cloud.
Daraus ergibt sich zwar eine andere Frage. Wenn Ihre Messungen jedes Mal auf verschiedenen Hosts durchgeführt werden, können die Ergebnisse ein wenig Rauschen verursachen und aus diesem Grund auch. Dann können Sie die Messwerte für den Host normalisieren. Das heißt, nach historischen Daten den „Wirtskoeffizienten“ erfassen und bei der Analyse der Ergebnisse berücksichtigen.
Die Analyse historischer Daten zeigt, dass die Hardware unterschiedlich ist. Das Wort "Hardware" umfasst hier die Kernel-Version und die Folgen der Verfügbarkeit (anscheinend keine beweglichen Kernel-Objekte im Speicher).
Daher ordnen wir jedem "Host" (beim Neustart "stirbt" der Host und ein "neues" erscheint die Änderung zu, mit der wir den RPS vor der Aggregation multiplizieren.
Wir prüfen und aktualisieren die Änderungen auf äußerst ungeschickte Weise, was verdächtig an eine Option für ein Verstärkungstraining erinnert.
Für einen gegebenen Vektor von Posthost-Korrekturen betrachten wir die Zielfunktion:
- In jedem Test berücksichtigen wir die Standardabweichung der erhaltenen „korrigierten“ RPS-Ergebnisse
- Nehmen Sie den Durchschnitt von ihnen mit gleichen Gewichten ,
- Wir haben Tau = 1 Woche.
Dann setzen wir eine Korrektur (für den Host mit der größten Summe dieser Gewichte) auf 1,0 und suchen nach den Werten aller anderen Korrekturen, die ein Minimum der Zielfunktion ergeben.
Um die Ergebnisse für historische Daten zu validieren, berücksichtigen wir die Korrekturen für die alten Daten. Wir betrachten das korrigierte Ergebnis für die frischen Daten und vergleichen sie mit den nicht korrigierten.
Eine weitere Option zum Anpassen der Ergebnisse und zum Reduzieren des Rauschens ist die Normalisierung auf "Kunststoffe". Führen Sie vor dem Starten des zu testenden Dienstes ein „synthetisches Programm“ auf dem Host aus, mit dem Sie den Status des Hosts auswerten und den Korrekturfaktor berechnen können. In unserem Fall verwenden wir jedoch hostbasierte Korrekturen, und diese Idee ist eine Idee geblieben. Vielleicht wird einer von euch sie mögen.
Vergessen Sie trotz der Automatisierung und all ihrer Vorteile nicht die Dynamik Ihrer Indikatoren. Es ist wichtig sicherzustellen, dass sich der Service im Laufe der Zeit nicht verschlechtert. Möglicherweise bemerken Sie keine kleinen Drawdowns, sie können sich ansammeln, und über einen langen Zeitraum können Ihre Indikatoren durchhängen. Hier ist ein Beispiel unserer Grafiken, die wir bei RPS betrachten. Es zeigt den relativen Wert für jedes überprüfte Commit, seine Nummer und die Fähigkeit, zu sehen, woher die Freigabe zugewiesen wurde.
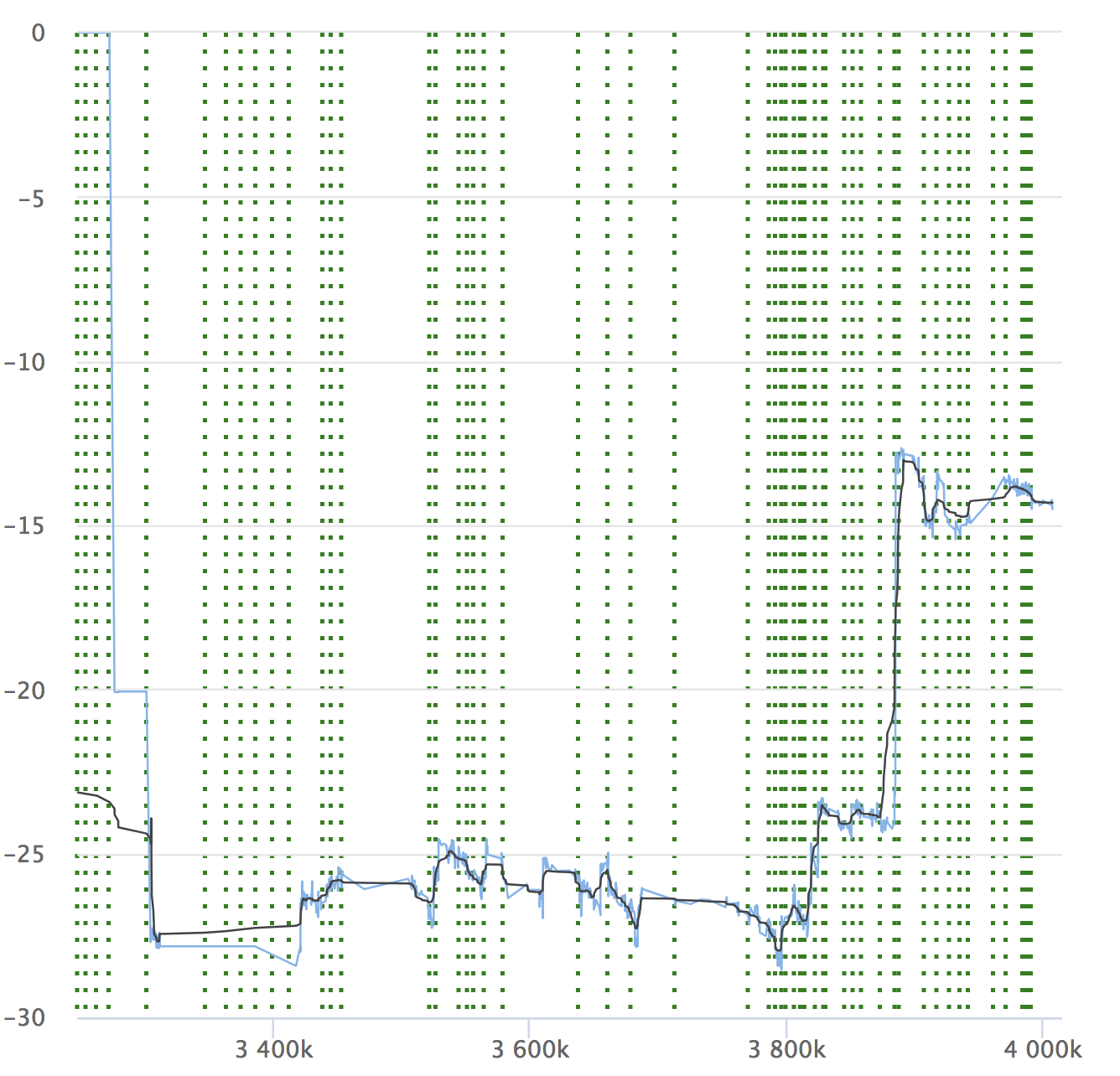
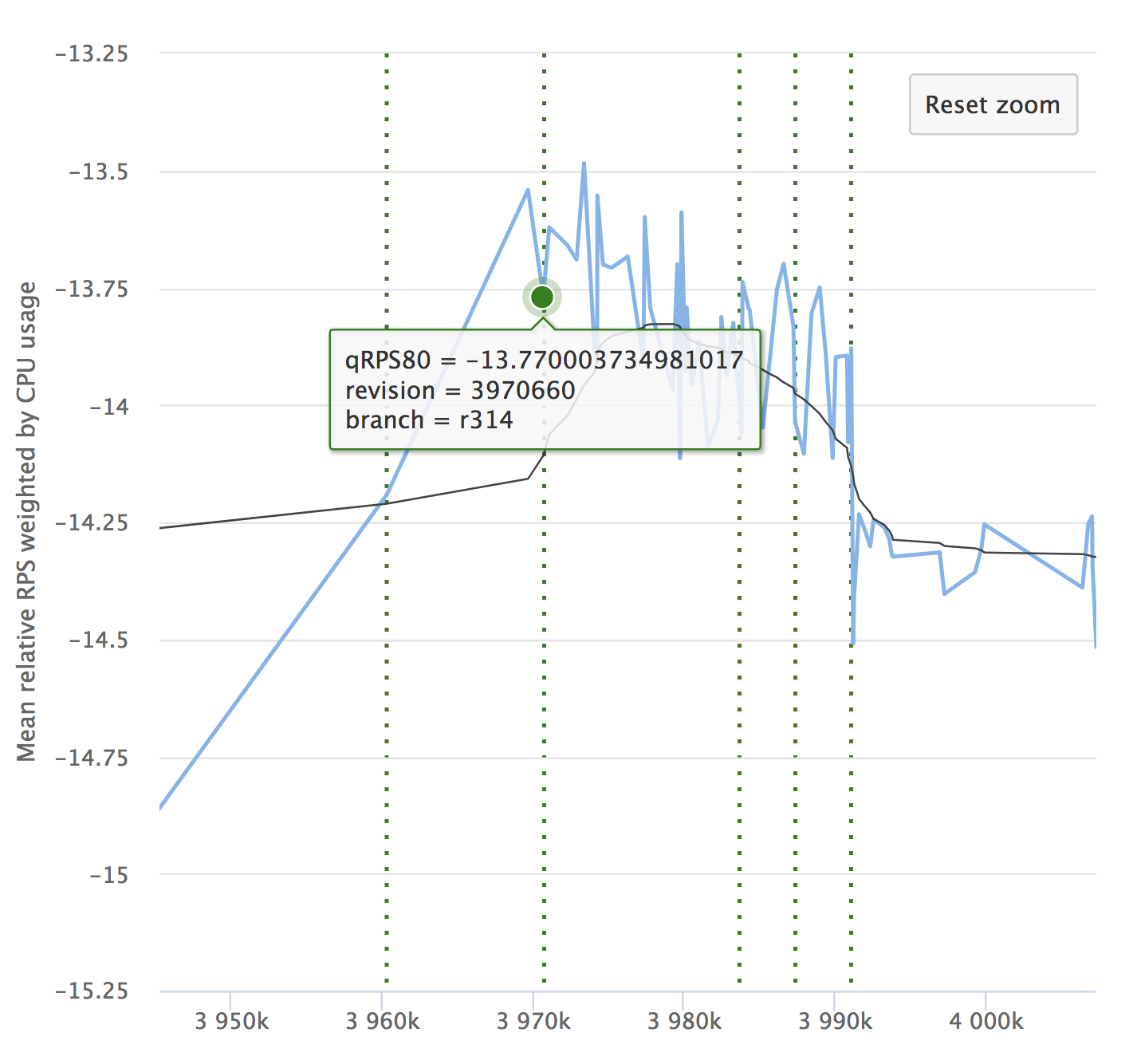
Wenn Sie den Artikel lesen, ist es auf jeden Fall interessant für Sie, einen Bericht über Yandex.Tank und eine Analyse der Ergebnisse von Lasttests zu sehen.
Wir erinnern Sie auch daran, dass wir im Rahmen der Yandex- Veranstaltung von innen ausführlicher über die Organisation der kontinuierlichen Integration sprechen werden. Komm zu Besuch!