
Hallo nochmal, Alexey Pristavko ist in Kontakt und dies ist der zweite Teil meiner Geschichte über die S3-Objektspeicher-DataLine, die auf Cloudian HyperStore basiert.
Heute werde ich ausführlich darüber sprechen, wie unser S3-Speicher angeordnet ist und auf welche Schwierigkeiten wir bei der Erstellung gestoßen sind. Berühren Sie unbedingt das Thema „Eisen“ und analysieren Sie die Ausrüstung, auf der wir uns aufgehalten haben.
Lass uns gehen!
Wenn Sie während des Lesens die Anwendungsarchitektur der Cloudian-Lösung kennenlernen möchten, finden Sie deren detaillierte Analyse im
vorherigen Artikel . Dort haben wir das Cloudian-interne Gerät, die Fehlertoleranz und die Logik des eingebauten Sicherheitsdatenblatts ausführlich besprochen.
Das endgültige Schema der physischen Ausrüstung
Da wir später über unsere "Qual der Wahl" sprechen werden, werde ich sofort die endgültige Liste der Eisen geben, zu denen wir gekommen sind. Kleiner Haftungsausschluss: Die Wahl der Netzwerkausrüstung war größtenteils auf die Präsenz in unserem (übrigens sehr soliden) Lager zurückzuführen.
Auf der physischen Ebene des Speichers verfügen wir also über die folgenden Geräte:
Name
| Funktion
| Konfiguration
| Menge
|
Lenovo System x3650 M5 Server
| Arbeitsknoten
| 1x Xeon E5-2630v4 2,2 GHz,
4x 16 GB DDR4,
14 x 10 TB 7,2 K 6 Gbit / s SATA 3,5 ",
2x 480 GB SSD,
Intel x520 Dual Port 10 GbE SFP +,
2x750W HS-Netzteil
| 4
|
HP ProLiant DL360 G9 Server
| Load Balancer-Knoten
| 2 E5-2620 v3,
128 G RAM,
2 600 GB SSD,
4 SAS-Festplatte,
Intel x520 Dual Port 10 GbE SFP +
| 2
|
Cisco C4500 Switch
| Grenztor
| Katalysator WS-C4500X-16SFP +
| 2
|
Cisco C3750 Switch
| Port Extender
| Katalysator WS-C3750X-24T mit C3KX-NM-10G
| 2
|
Cisco C2960 Switch
| Steuerebene
| Katalysator WS-C2960 + 48PST-L
| 1
|
Zum besseren Verständnis der Architektur werden wir uns nacheinander alle Elemente ansehen und über ihre Merkmale und Aufgaben sprechen.
Beginnen wir mit den Servern. Lenovo Server verfügen über eine spezielle Konfiguration, die gemeinsam und in voller Übereinstimmung mit den Empfehlungen und Spezifikationen von Cloudian implementiert wird. Beispielsweise verwenden sie einen Controller mit direktem Festplattenzugriff. Da in unserem Fall RAID auf der Ebene der Anwendungssoftware organisiert ist, erhöht dieser Modus die Zuverlässigkeit und beschleunigt das Festplattensubsystem. Genau die gleichen Server können zusammen mit allen Lizenzen als Cloudian Appliance erworben werden.
Lastausgleichsserver mit Nginx für CentOS gewährleisten eine gleichmäßige Lastverteilung auf Arbeitsknoten und abstrahieren den Benutzer von der internen Verkehrsorganisation. Und als angenehmer Bonus - bei Bedarf können Sie einen Cache darauf organisieren.
Das Cisco 4500X 16 10 GB SFP + -Paar dient als Kern und Grenze unseres kleinen, aber stolzen Speichernetzwerks. Natürlich ist Eisen ein wenig altmodisch, aber es ist dem „Neuen“ in Sachen Zuverlässigkeit nicht unterlegen, es hat interne Redundanz und seine Funktionalität erfüllt alle unsere Anforderungen. C3750 spielt die Rolle des Factory-Extenders. Es ist nicht erforderlich, 1G-Transceiver in 10G-Steckplätze zu schieben. Und komplett auf 10GB Links umzusteigen macht auch noch nicht viel Sinn. Wie Tests gezeigt haben, stoßen wir früher auf den Prozessor und die Festplatten.
Das folgende Diagramm zeigt die von mir beschriebene physische Organisation hinreichend detailliert:
 1. Schema der physischen Speicherorganisation
1. Schema der physischen SpeicherorganisationLassen Sie uns das Schema durchgehen. Wie Sie sehen können, wird die Fehlertoleranz auf physikalischer Ebene durch Duplizieren und Verbinden jedes Geräts mit mindestens zwei optischen Verbindungen realisiert, eine für jedes Gerät in einem Paar. Dies gibt uns die Garantie, die physische Konnektivität in der Schaltung während eines Unfalls eines Netzwerkgeräts oder zweier Geräte aus verschiedenen Paaren gleichzeitig aufrechtzuerhalten.
Wir gehen unter das Schema. Beide Cisco-Paare (4500/4500, 3750/3750) werden mithilfe von Stack und VSS zu einem einzigen logischen Gerät kombiniert. Der Stapel wird mit zwei Stapelkabeln VSS über drei optische 10G-Verbindungen zusammengebaut. Auf diese Weise können Sie sicherstellen, dass beide Geräte in jedem Paar als Ganzes interagieren. Ein solches Clustering ermöglicht es uns, im Rahmen eines transparenten L2-Segments über beide Geräte eines Paares zu arbeiten und eine allgemeine Link-Aggregation mithilfe von LACP durchzuführen, da diese Technologie sowohl vom Server-Betriebssystem als auch von Cisco IOS nativ unterstützt wird. Auf der Serverseite sieht es so aus, als würde es mit einem Switch statt mit zwei arbeiten, und über der Anwendung befindet sich ein aggregierter Kanal mit doppelter Kapazität.
Alle Netzwerkgeräte, die zwischen sich und den eingehenden Kanälen umschalten, werden über optische 10G-Verbindungen umgeschaltet. Die Servergeräte werden über 10G Twinax Cisco-Kabel und 1G Kupfer angeschlossen.
BGP wird für die Fehlertoleranz des eingehenden Kanals verwendet, und Round Robin DNS wird zum Ausgleichen zwischen externen IP-Adressen verwendet. Externe Adressen selbst werden auf Lastausgleichsservern geparkt und bei Bedarf mithilfe des Pacemaker / Corosync-Bundles zwischen Knoten migriert.
Die Überwachung und Steuerung über IPMI erfolgt über eine direkte interne Verbindung. Alle Verwaltungsschnittstellen (sowohl Server als auch Cisco) sind über separate Switches auf der Steuerebene verbunden. Sie sind wiederum im Steuerungsnetzwerk des Rechenzentrums enthalten. Dies garantiert uns die Unmöglichkeit, die Kommunikation mit Geräten während der Arbeit oder infolge eines Unfalls in einem externen Netzwerk zu verlieren. Für den extremsten Fall gibt es Begleiter bei KVM.
Logisches Netzwerk
Um zu verstehen, wie das logische S3-Netzwerk des DataLine-Speichers funktioniert, wenden wir uns einem anderen Schema zu:
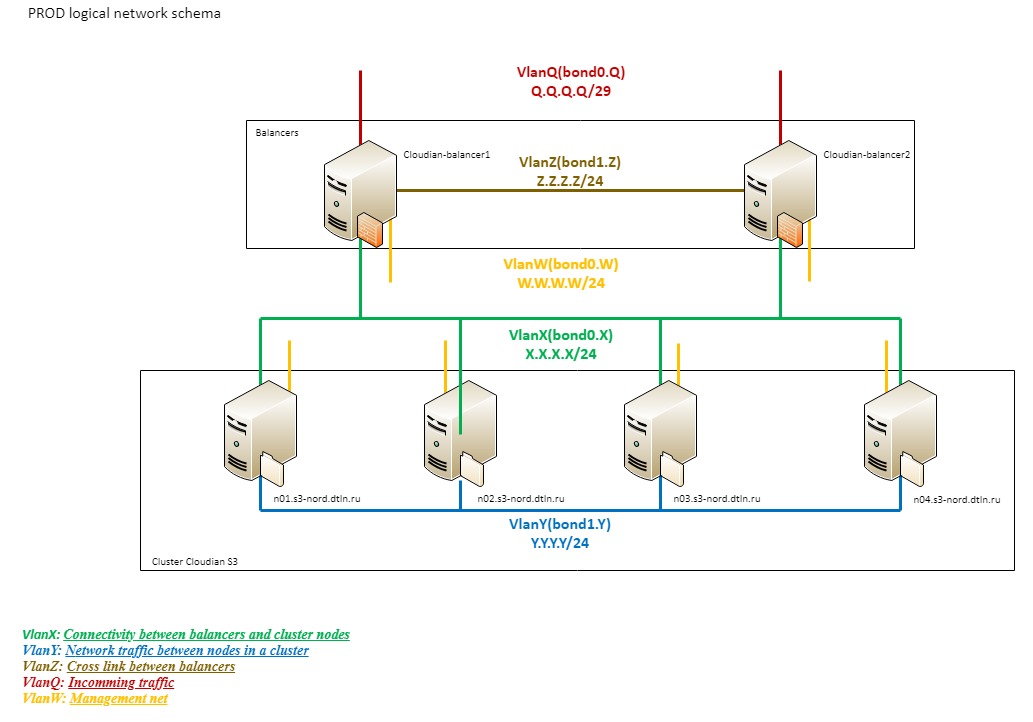 2. Logisches Netzwerkdiagramm für den Speicher
2. Logisches Netzwerkdiagramm für den SpeicherWie Sie sehen können, besteht die Netzwerklogik aus mehreren Segmenten.
Ein externes Netzwerk (Q) mit einer Gesamtkapazität von 20 G ist direkt mit Provider Edge verbunden. Darauf folgen der Cisco 4500 und Balancer.
Der nächste logische Block (X) ist das VLAN zwischen den Balancern und den Arbeitsknoten. Die Balancer verwenden dieselbe Verbindung wie für eingehenden Datenverkehr. Arbeitsknoten sind über den 3750-Stapel mit 4 1G-Verbindungen verbunden (zwei für jede 3750). Alle physischen Verbindungen werden auch mit LACP zu einer einzigen logischen Verbindung zusammengefügt. Dieses Netzwerk wird nur zur Verarbeitung des Clientverkehrs verwendet.
Alle Verbindungen innerhalb des Cloudian (Y) -Clusters durchlaufen ein drittes logisches Segment, das auf 10G basiert. Eine solche Organisation hilft, Probleme auf dem externen Kanal aufgrund des internen Datenverkehrs zu vermeiden und umgekehrt. Dies ist ein extrem belastetes und wichtiges Segment für den Betrieb des Clusters. Dadurch werden Daten und Metadaten repliziert, sie werden von allen Neuausgleichsverfahren usw. verwendet. Daher haben wir ihre „Unsinkbarkeit“ als separate Aufgabe unterschieden.
Ein bisschen Schönheit
So sieht alles aus:
 3. Netzwerkgeräte und Balancer mit vollem Gesicht
3. Netzwerkgeräte und Balancer mit vollem Gesicht 4. Die gleiche Rückansicht
4. Die gleiche RückansichtAchten Sie auf das Umschalten. In früheren Artikeln haben meine Kollegen über die Bedeutung von Farbmarkierungskabeln geschrieben, aber es wird nicht unangebracht sein, dieses Thema hier anzusprechen.
Wir verwenden die Farbumschaltung nicht nur für das Netzwerk, sondern auch für die Stromversorgung. Dies ermöglicht unseren Ingenieuren eine schnelle Navigation im Rack und reduziert den Einfluss des menschlichen Faktors beim Umschalten.
 5. Arbeitsknoten
5. Arbeitsknoten 6. Rückansicht
6. RückansichtAuf diesem Foto können Sie deutlich sehen, wie dicht die Arbeitsserver mit Festplatten gefüllt sind - selbst auf der Rückseite befinden sich praktisch keine leeren Steckplätze. Übrigens erfüllt eine solche Organisation von Kabeln zu kompakten Bündeln nicht nur eine ästhetische Funktion, sondern vermeidet auch überlappende Lüfter von Netzteilen, wodurch Eisen vor Überhitzung geschützt wird.
Whitelisting
In den Kommentaren zum letzten Artikel habe ich versprochen, mehr über das Whitelisting-Gerät zu sprechen.
Wenn wir uns aus irgendeinem Grund mit dem Kunden darauf geeinigt haben, alle Arbeiten mit dem Speicher von der Innenseite des Rechenzentrums oder über direkte Kanäle zu seinen Geräten auszuschließen, müssen wir eine private Verbindung zum Speicher herstellen.
Erinnern Sie sich, im ersten Diagramm gab es einen Zweig auf DIST und Cloud? Zusätzlich zum Haupt-Internetkanal mit 20 GB verwenden wir einen aggregierten Kanal für Switches, mit dem wir alle Clients auf Rechenzentrumsebene verbinden. Wenn der Client eine direkte Verbindung zum Speicher wünscht, können wir das VLAN vom Client zu unserem 4500X mit der Erstellung einer separaten Route (oder ohne diese) konfigurieren und L3 starten. Danach wird die Bindung an den Tarifplan an die Adressen des Kunden konfiguriert, die bereits in Cloudian selbst vorhanden sind. Für alle, die mit diesem Tarif verbunden sind, wird die Verwendung von S3 aus Whitelist-Adressen nicht berücksichtigt.
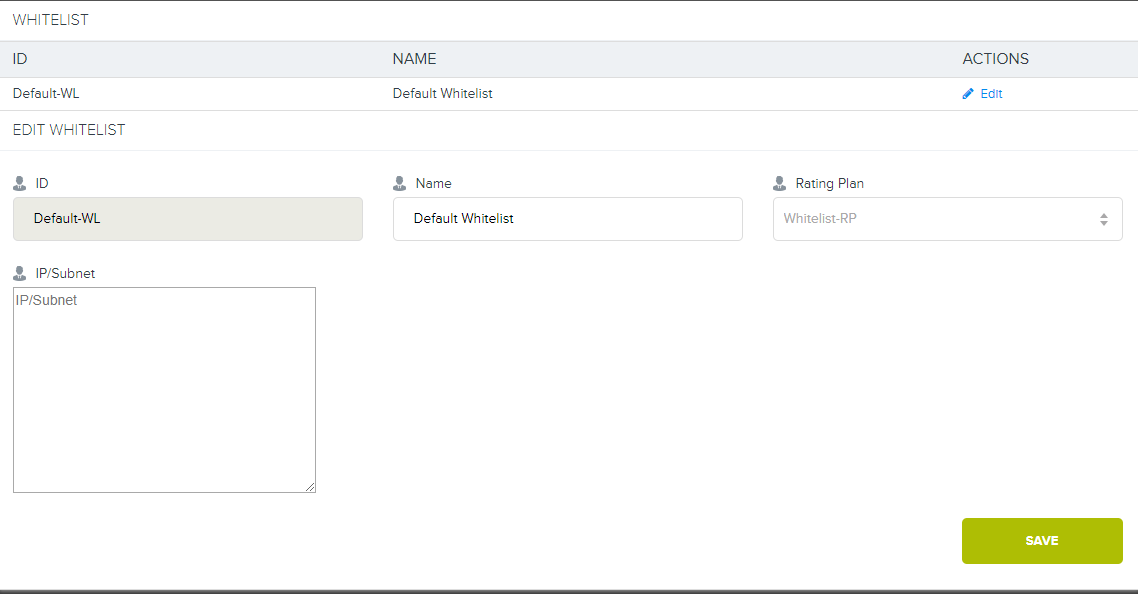 7. Und hier ist eine spezielle Oberfläche in Cloudian.
7. Und hier ist eine spezielle Oberfläche in Cloudian.Jetzt haben wir keinen solchen Tarif im Netz, aber wenn Sie es wirklich wollen, können wir ihn bereitstellen.
Baugeschichte
Wir nähern uns allmählich dem interessantesten Teil der Geschichte - dem Bau eines Lagers. Es wird viele Fotos geben, bis zu drei Versuche, den Verkehrsausgleich zu organisieren, und einige schlechte Tipps. Ich hoffe, dass die Analyse der Probleme, auf die wir unterwegs gestoßen sind, für diejenigen nützlich sein wird, die sich darauf vorbereiten, mit einer Geschwindigkeit von 10 Gbit + im Web zu arbeiten.
Experimentieren mit 10G
Bevor ich direkt zum Kern dieses Abschnitts gehe, erlaube ich mir, einen weiteren kleinen Haftungsausschluss zu machen.
Nach einer etablierten Tradition gehen wir vor dem Kauf neuer Zusatzgeräte ins Lager und wählen mehr oder weniger geeignete Komponenten aus. So können Sie schnell Tests durchführen und sich für eine zukünftige Einkaufsliste entscheiden. Obwohl wir kein 100% zuverlässiges Ergebnis erzielen, wird natürlich nichts für die Produktivität ausgegeben.
So war es diesmal. Und wenn Cisco keine Überraschungen warf, dann hat uns die „Gier“ der Load Balancer fast ruiniert.
Die erste Erfahrung. Supermicro Server
Hier hat uns der Wunsch enttäuscht, einen Schnelltest mit minimalen Kosten durchzuführen. Im Lager fanden wir Supermicro-Server, auf denen bis auf das Fehlen von SFP-Schnittstellen alles in Ordnung war. Wir haben uns entschlossen, unseren geliebten Intel 520DA2 auf ihnen zu installieren, und standen sofort vor dem ersten Problem: Die Maschinen sind Einzelgeräte, aber es gibt keine Riser. Gleichzeitig war unser Korps aus irgendeinem Grund nicht in den Kompatibilitätslisten enthalten, aber es gab viele einheimische Riser.
Auf Anraten des Direktors für innovative Entwicklung, Misha Solovyov, haben wir alles mit flexiblen Steigleitungen für Bergbaubetriebe verbunden. Das Ergebnis war so ein "Kadaver":
 8. Prototyp Nr. 1
8. Prototyp Nr. 1Ich musste an einigen Stellen das berühmte blaue Isolierband verwenden, um, Gott bewahre, etwas Kurzes zu tun. Ja, die Kollektivfarm. Ja, beschämt. Eine solche „Konfiguration“ ist jedoch für den Zeitraum des Experiments durchaus akzeptabel.
 9. Rückansicht
9. RückansichtWas dabei herauskam, ist im Screenshot des iperf deutlich zu sehen:
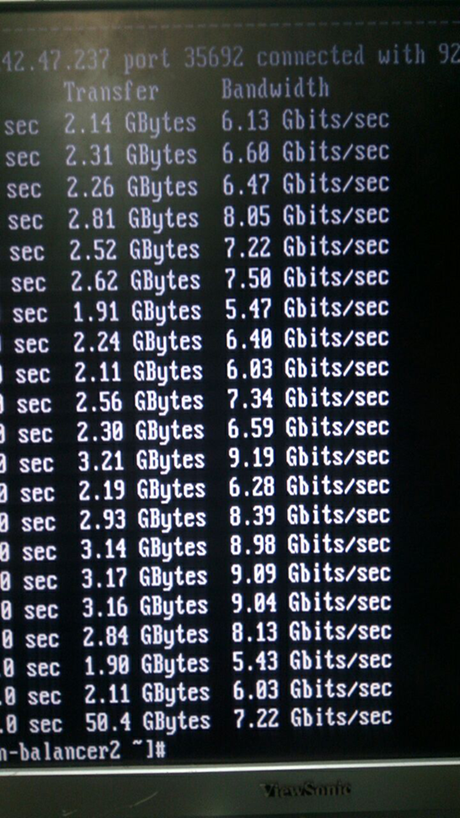 10. Eigentlich ist das kein Screenshot :)
10. Eigentlich ist das kein Screenshot :)Die Metriken sind sehr interessant, oder? Wir waren also traurig. Zuerst haben wir an Spionage-Chips gedacht, wir haben alles auseinander genommen und begradigt.
 11. Auf den ersten Blick gibt es hier keine Spionagechips
11. Auf den ersten Blick gibt es hier keine SpionagechipsSie erinnerten an den Verlauf der Physik: elektromagnetische Interferenzen, hochfrequente Signale usw. ... Natürlich machte es keinen Sinn, das Experiment mit einer solchen Quantität und Qualität der "Kollektivfarm" fortzusetzen. Also haben wir endlich das System auseinander genommen und die Server wieder installiert.
Die zweite Erfahrung. Citrix Netscaler MPX8005
Bei der Rückkehr der Server an den Ort haben wir neue Helden gefunden: Citrix Netscaler MPX8005. Dies ist ein wunderbares Markeneisen, das außerdem fast nie verwendet wird. Sie sehen so aus:
 12. Der Schlitten im Rack passte nicht in die Länge, aber wir Visionär beschlossen, ihn auf später zu verschieben
12. Der Schlitten im Rack passte nicht in die Länge, aber wir Visionär beschlossen, ihn auf später zu verschiebenGeräte in ein Rack stellen, umschalten und konfigurieren. Dies sind wirklich ausgezeichnete "erwachsene" Eisenstücke, 2 SFP-Steckplätze für jeweils 10 GB, HA, fortschrittliche Algorithmen, es gibt sogar L7. Zwar bis zu 5 Gigabit unter Lizenz, aber wir haben immer noch L3 verwendet, aber es gibt keine solchen Einschränkungen.
Daumen drücken, testen. Es gibt keine Geschwindigkeit. Auf den Schnittstellen - solide Fehler bei ungeeigneten Transceivern, Geschwindigkeit von ca. 5 Gigabit, konstante Abfälle. Sie erinnerten sich an die flexiblen Tragegurte und waren wieder traurig. Auch dort war die Geschwindigkeit höher und weniger Fehler. Wir beginnen zu verstehen:
show channel LA/1 1) Interface LA/1 (802.3ad Link Aggregate) #10 flags=0x4100c020 <ENABLED, UP, AGGREGATE, UP, HAMON, HEARTBEAT, 802.1q> MTU=9000, native vlan=1, MAC=XXX, uptime 0h03m23s Requested: media NONE, speed AUTO, duplex NONE, fctl NONE, throughput 160000 Link Redundancy Throughput 80000 Actual: throughput 20000 LLDP Mode: NONE RX: Pkts(9388) Bytes(557582) Errs(0) Drops(1225) Stalls(0) TX: Pkts(10514) Bytes(574232) Errs(0) Drops(0) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) bandwidthHigh: 160000 Mbits/sec, bandwidthNormal: 160000 Mbits/sec. LA mode: AUTO > show interface 10/1 1) Interface 10/1 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #1 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m44s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8921) Bytes(517626) Errs(0) Drops(585) Stalls(0) TX: Pkts(9884) Bytes(545408) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set. > show interface 10/2 1) Interface 10/2 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #0 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m58s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8944) Bytes(530975) Errs(0) Drops(911) Stalls(0) TX: Pkts(10819) Bytes(785347) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set.
Wir haben native Cisco-Transceiver verwendet, mit denen theoretisch keine Probleme auftreten sollten. Sie überprüften sogar die Optik und wechselten für alle Fälle die Transceiver - das gleiche Bild. Unser Auto fährt nicht und das wars! Wir schauen genauer hin.
"Schöne" Cisco-Transceiver:
ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CISCO-AVAGO , part number XXX , 10G 0x10 1G 0x00 CT 0x00 *** Unsupported SFP+/SFP type!
Transceiver werden nicht normal erkannt, nicht unterstützt!
Ich musste die meisten "Verwandten" finden:
 13. Die heimischsten Transceiver im Wilden Westen
13. Die heimischsten Transceiver im Wilden Westen ix0: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe020-0xe03f mem 0xf7820000-0xf783ffff,0xf7844000-0xf7847fff irq 16 at device 0.0 on pci1 platform: Manufacturer Citrix Inc. platform: NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 675320 (28), manufactured at 8/10/2015 platform: serial 4NP602H7H0 platform: sysid 675320 - NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 ix0: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00 ix0: [ITHREAD] 10/2: Ethernet address: 00:e0:ed:45:39:f8 ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00
Diese Transceiver wurden ohne Probleme bestimmt, aber dies rettete die Situation nicht. Firmware aktualisiert - das Gleiche. Der Citrix-Support hat beschlossen, taktvoll still zu bleiben (nein, nicht wegen des Stammbaums des Transceivers).
Wir holten tief Luft und vergruben uns in Hardware-Spezifikationen. Es stellte sich heraus, dass die Antwort die ganze Zeit vor unseren Augen lag:
ixgbe Busgeschwindigkeit = 5,0 Gbit / s und PCIe-Fahrspurbreite = 8. Dies ist ein Problem mit der Karte. Ihr selbst fehlt die PCIe-Geschwindigkeit. Unser Citrix hat die maximale Leistung des PCI-e-Steckplatzes für eine Karte mit Transceivern von
5,0 Gbit / s, die er uns die ganze Zeit gerufen hat. Wie Citrix auf MPX8015 (es ist genau das gleiche in der Hardware!) Sie wollten 15 Gigabit ausgeben, es ist nicht klar. Aber wir haben verstanden, warum solche "coolen" Balancer die ganze Zeit in einem Lagerhaus lagen. Sie können mit 10G-Links im Prinzip nicht richtig funktionieren.
Die letzte Erfahrung. Wir verwenden das richtige Eisen und machen es schön
Hier endete unsere Geduld mit unserem Vertrauen in die Menschlichkeit, und wir mussten die "Ersatz" -Technologie verwenden, um die normale Hardware in Form des HP ProLiant DL360 G9 aus den obigen Fotos zu erhalten. Sie haben keine Überraschungen für uns arrangiert, sie laden 10G herunter und beschweren sich nicht. :) :)
Lasttest
Da wir den Hujak-Hujak-and-Production-Ansatz nicht akzeptieren und aus Erfahrung wissen, dass ein nicht getestetes System nach der Montage mit einer fast 100% igen Garantie nicht funktionsfähig ist, haben wir beschlossen, Lasttests durchzuführen. Darüber hinaus können Sie mit seiner Hilfe einige Optimierungen für die Zukunft vornehmen.
Um die Last zu erzeugen, wurde das übliche Werkzeug gewählt - Apache Jmetr. Es allein ist ziemlich gut, da ich
vor ein paar Artikeln geschrieben habe, und dies ist eine der flexibelsten Lösungen auf dem Markt, obwohl Java gerne isst. Für die Arbeit mit S3 haben wir ein selbstgeschriebenes Modul mit dem AWS SDK verwendet, ebenfalls in Java. In den Tests konnten wir eine Geschwindigkeit von 12,5 Gbit / s für das Schreiben von Dateien über 250 Megabyte bei parallelem Laden durch Blöcke von 5 Megabyte und für Dateien von weniger als 5 Megabyte erreichen - bei der Verarbeitung von etwa 3000 HTTP-Anforderungen pro Sekunde. Wenn beide Tests parallel ausgeführt wurden, stellte sich heraus, dass etwa 11 Gigabit und 2200 Anforderungen pro Sekunde erforderlich waren. Gleichzeitig besteht die Möglichkeit, die Arbeit mit einer gemischten Last und mit kleinen Gegenständen zu verbessern. Wir haben in der CPU "vergraben" und der zweite Sockel ist frei. Auf dem Lastgenerator wurden Testdateien aus dem RAM entnommen, um den Einfluss auf die Ergebnisse des Platten-Subsystems des Generators selbst auszuschließen. Für Tests haben wir den HP DL980 g7-Server als Generator verwendet, um uns an die Liebe zu Java für RAM und die Notwendigkeit zu erinnern, beim parallelen Laden mit einer großen Anzahl von Threads zu arbeiten. Dies ist ein Server mit acht Einheiten, 8 Intel E7-4870-Prozessoren und 512 GB RAM an Bord.
Innerhalb des Teams blieb ihm der liebevolle Spitzname Behemoth erhalten.
 14. Unser Nilpferd. Stimmt etwas Ähnliches?
14. Unser Nilpferd. Stimmt etwas Ähnliches? 15. Rückansicht. Die beängstigenden Kabel in der unteren Mitte sind eine Querverbindung des internen Brückenbusses
15. Rückansicht. Die beängstigenden Kabel in der unteren Mitte sind eine Querverbindung des internen Brückenbusses 16. Dies ist eines der beiden Serverziele. Jeder hat 4 Prozessoren und 16 Steckplätze mit 16 Gigabyte RAM
16. Dies ist eines der beiden Serverziele. Jeder hat 4 Prozessoren und 16 Steckplätze mit 16 Gigabyte RAM 17. Um Htop bequem in der Konsole eines solchen Servers verwenden zu können, benötigen Sie einen großen Monitor :)
17. Um Htop bequem in der Konsole eines solchen Servers verwenden zu können, benötigen Sie einen großen Monitor :)In der Praxis hat ein gemischter Test sogar einen so leistungsstarken Server spürbar belastet.
Um zu den erzielten Leistungsergebnissen zu gelangen, mussten wir das interne Netzwerk des Clusters auf 9k Jumbo-Frames übertragen und den Netzwerkstapel aus Balancern und Arbeitsknoten (wir verwenden CentOS Linux) leicht optimieren sowie eine Reihe anderer Kernelparameter auf Arbeitsknoten optimieren:
cat /etc/sysctl.conf … kernel.printk = 3 4 1 7 read_ahead_kb = 1024 write_expire = 250 read_expire = 250 fifo_batch = 128 front_merges = 0 net.core.wmem_default = 16777216 net.core.wmem_max = 16777216 net.core.rmem_default = 16777216 net.core.rmem_max = 16777216 net.core.somaxconn = 5120 net.core.netdev_max_backlog = 50000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_max_syn_backlog = 30000 net.ipv4.tcp_max_tw_buckets = 2000000 fs.file-max = 196608 vm.overcommit_memory = 1 vm.overcommit_ratio = 100 vm.max_map_count = 65536 vm.dirty_ratio = 40 vm.dirty_background_ratio = 5 vm.dirty_expire_centisecs = 100 vm.dirty_writeback_centisecs = 100 net.ipv4.tcp_fin_timeout=10 net.ipv4.tcp_congestion_control=htcp net.ipv4.netfilter.ip_conntrack_max=1048576 net.core.rmem_default=65536 net.core.wmem_default=65536 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.ipv4.ip_local_port_range=1024 65535
Die wichtigsten Einstellungen, die optimiert wurden, sind die Größe der Puffer, die Anzahl der Netzwerkverbindungen, die Anzahl der Verbindungen zum Port und die von Firewalls überwachten Verbindungen sowie Zeitüberschreitungen.
Cisco C3750 + LACP = SchmerzEin weiterer Nachteil der Netzwerkleistung ist der Lastausgleich bei Verwendung von LACP / LAGp. Leider kann der Cisco 3750 die Last nicht über Ports verteilen, sondern nur an Quell- und Zieladressen. Um den richtigen Verkehrsausgleich zu erreichen, musste ich 12 IP-Adressen an die Bond-Schnittstellen der Arbeitsknoten hängen und auf die Clients "schauen". Bedingt 3 für jede physische Verbindung. Mit dieser Konfiguration war es möglich, auf LACP auf den „externen“ Schnittstellen der Arbeitsknoten zu verzichten, da alle Adressen in der Nginx-Konfiguration angegeben sind. Wenn jedoch die Verbindung verloren geht, wird das Gewicht des Knotens beim Ausgleich automatisch reduziert. Mit dem "Dump" können Sie über die LACP-Verbindung den vollständigen Zugriff auf alle Adressen aufrechterhalten.
bond0.10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 RX packets:2390824140 errors:0 dropped:0 overruns:0 frame:0 TX packets:947068357 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:18794424755066 (17.0 TiB) TX bytes:246433289523 (229.5 GiB) bond0.10:0 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:1 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:2 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:3 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:4 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:5 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:6 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:7 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:8 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:9 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XXMask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
Funktionsprüfung
Nachdem wir die Arbeit am Repository beendet hatten, trafen wir uns mit dem Dienst flexify.io. Sie erleichtern die Migration zwischen verschiedenen Objektspeichern. Um jedoch ein Flexify-Partner zu werden, müssen Sie ernsthafte Tests bestehen. "Warum nicht?" - Wir dachten. Tests von Drittanbietern sind immer eine lohnende Erfahrung.
Die Hauptaufgabe der Tests besteht darin, die Funktionsweise der S3-Protokollmethoden über ihre Proxys in Bezug auf verschiedene Konfigurationen zu überprüfen, unter denen sich jeder Satz von S3-kompatiblen Buckets befinden kann, die vom Dienstanbieter unterstützt werden.
Zunächst werden Methoden überprüft, die mit Objekten im Bucket arbeiten. Unser Speicher wurde unter Verwendung einer Vielzahl von Testdaten getestet. Das Verhalten der Methoden wurde für Objekte unterschiedlicher Größe und Inhalt sowie für Schlüssel getestet, die alle Arten von Kombinationen von Unicode-Zeichen enthalten.
In negativen Tests haben sie versucht, ungültige Daten zu übertragen, wo immer dies möglich war. Besonderes Augenmerk wurde dabei auf die Sicherheit der Daten gelegt.
Methoden, die mit Eimern arbeiten, wurden ebenfalls getestet, jedoch hauptsächlich in positiven Szenarien. Ziel dieser Tests war es zu überprüfen, ob die Verwendung von Methoden über einen Proxy keine ernsthaften Probleme mit sich bringt, z. B. Datenkorruption oder Abstürze.
Die Breite der Abdeckung kann anhand der Tests beurteilt werden, die sowohl über Proxies als auch direkt durchgeführt wurden. Die meisten Tests, insbesondere diejenigen, die mit Objekten arbeiten, sind parametrisiert und testen eine große Anzahl verschiedener Objekte, Bereiche usw.
Implementierte Tests für ObjekteGET Objektanforderung ohne optionale Parameter
GET Objektanforderungs-Multithread
GET-Objektanforderung an ein verschlüsseltes Objekt mit den angegebenen sse-Parametern
GET-Objektanforderung an ein verschlüsseltes Objekt ohne angegebene sse-Parameter
GET-Objektanforderung mit einem Bereich, der den Bytebereich der Datei schneidet
GET Objektanforderung mit einem Bereich außerhalb des Bereichs des Bytebereichs der Datei
GET Objektanforderung mit einem Suffixbereichsparameter
GET-Objektanforderung mit einem Suffixbereichsparameter außerhalb des Bereichs des Bytebereichs der Datei
GET Objektanforderung mit ungültigem Bereichsparameter
Kopfobjektanforderung an ein vorhandenes Objekt
Kopfobjektanforderung an ein kürzlich gelöschtes Objekt
Kopfobjektanforderung mit einem Schlüssel, der in einem Bucket nie vorhanden war
Kopfobjektanforderung an ein verschlüsseltes Objekt mit den angegebenen sse-Parametern
Kopfobjektanforderung an ein verschlüsseltes Objekt ohne angegebene sse-Parameter
Objektanforderung auflisten
List Objects v2-Anforderung
Listenobjektanforderung mit dem angegebenen Marker-Parameter
Listenobjektanforderung mit angegebenem Präfixparameter
Listenobjektanforderung mit den angegebenen Markierungs- und Präfixparametern
Empfangen Sie alle Objekte auf dem Endpunkt mit Listenobjekten mit den angegebenen Markierungs- und Präfixparametern
Listenobjektanforderung mit übersprungenem Begrenzerparameter
Listenobjektanforderung mit übergebenem Marker-Parameter, jedoch mit übersprungenem Delimiter-Parameter
Listenobjektanforderung mit übergebenem nicht vorhandenem Präfix
Listenobjektanforderung mit übergebenem nicht vorhandenem Marker
Mehrteiliger Upload mit der nativen Methode upload_file ()
Mehrteiliger Upload mit der nativen Methode upload_fileobj ()
Mehrteiliger Upload mit benutzerdefinierter Methode
Stoppen des mehrteiligen Uploads mit der Methode abort_multipart_upload ()
Durchführen der Methode abort_multipart_upload () mit falscher uploadId
Durchführen der Methode abort_multipart_upload () mit falschem Schlüssel und falscher uploadId
Mehrteiliger Upload von 2 Dateien mit demselben Schlüssel gleichzeitig. 2. Datei vor dem 1. hochgeladen
Mehrteiliger Upload von 2 Dateien mit demselben Schlüssel gleichzeitig. 1. Datei vor dem 2. hochgeladen
Mehrteiliges Hochladen von 2 Dateien mit unterschiedlichen Schlüsseln gleichzeitig. 1. Datei vor dem 2. hochgeladen
Mehrteiliger Upload mit einer Teilegröße von 512 KB
Mehrteiliger Upload mit einer Teilegröße, die größer als die maximal zulässige Größe ist
Mehrteiliger Upload einer Datei mit Teilen unterschiedlicher Größe
Mehrteilige Upload-Anfrage auflisten
ACL-Anforderung für PUT-Objekt an ein Objekt mit der angegebenen Berechtigungsnachweis-ID
GET Object ACL-Anforderung an ein Objekt mit gewährten zusätzlichen Zugriffsberechtigungen
PUT Object Tagging-Methode
GET Object Tagging-Methode
DELETE Object Tagging-Methode
PUT-Objektanforderung ohne optionale Parameter
PUT-Objekt fordert Multithread an
PUT-Objektanforderungen mit übergebenen optionalen Verschlüsselungsparametern
PUT-Objektanforderungen mit übergebenem leeren Body-Parameter
GET-Objekt mit nativer Methode download_file ()
GET-Objekt mit der nativen Methode download_fileobj ()
GET-Objekt mit benutzerdefinierter Methode unter Verwendung von Bereichen
GET-Objekt mit Präfix mit der nativen Methode download_file ()
GET-Objekt mit Präfix mit der nativen Methode download_fileobj ()
GET Objekt mit Präfix mit benutzerdefinierter Methode unter Verwendung von Bereichen
DELETE Objektanforderung an ein vorhandenes Objekt
DELETE Objektanforderung an ein nicht vorhandenes Objekt
DELETE-Objektanforderung an eine Gruppe mit vorhandenen Objekten
Realisierte Tests für EimerSetzen Sie die Bucket-Verschlüsselung ein
GET Bucket-Verschlüsselung
Bucket-Verschlüsselung LÖSCHEN
PUT-Bucket-Richtlinienanforderung
GET Bucket Policy-Anforderung an einen Bucket mit Policy
DELETE Bucket Policy-Anforderung an einen Bucket mit Policy
GET Bucket-Richtlinienanforderung an einen Bucket ohne Richtlinie
Löschen der Bucket-Richtlinienanforderung an einen Bucket ohne Richtlinie
Setzen Sie die Eimerkennzeichnung
Holen Sie sich Bucket Tagging
Eimer-Markierung LÖSCHEN
Erstellen Sie eine Bucket-Anfrage mit dem vorhandenen Bucket-Namen
Erstellen Sie eine Bucket-Anfrage mit einem eindeutigen Bucket-Namen
Bucket-Anfrage mit vorhandenem Bucket-Namen löschen
Löschen Sie die Bucket-Anfrage mit dem eindeutigen Bucket-Namen
ACL-Anforderung für PUT-Bucket an einen Bucket mit der angegebenen ID des Berechtigten
GET Object ACL-Anforderung an ein Objekt mit gewährten zusätzlichen Zugriffsberechtigungen
Wie Sie vielleicht erraten haben, ist dies ein ziemlich harter Test, aber wir haben ihn im Allgemeinen positiv bestanden. Einige Probleme ergaben sich aus der mangelnden Unterstützung für SSE und kleine Schulen mit Unicode-Unterstützung zu diesem Zeitpunkt:
Fehler beim Laden mit Schlüsseln, die Folgendes enthalten:
- U + 0000-U + 001F - die ersten 32 unlesbaren Steuerzeichen. Bei Amazon wird beispielsweise nur das erste U + 0000 nicht direkt gegossen.
- Und auch U + 18D7C, U + 18DA8, U + 18DB4, U + 18DBA, U + 18DC4, U + 18DCE. Dies sind ebenfalls unlesbare Zeichen, aber Amazon akzeptiert sie als Schlüssel. Es gab keine Probleme mit allen anderen Charakteren.
Beim Lesen des Bucket-Inhalts tritt ein Problem mit dem 66.675-Schlüssel auf, der das Symbol U + FFFE enthält. Es ist nicht möglich, eine vollständige Liste der Schlüssel in einem Bucket zu erhalten, der ein Objekt mit einem solchen Schlüssel enthält.
Ansonsten waren die Tests erfolgreich und Ende September erschienen wir in der Liste der verfügbaren Lieferanten!
Ein kurzes Nachwort und ein Bonus für die Leser
Zuvor habe ich geschrieben, dass Cloudian HyperStore trotz seiner vielen Vorteile im russischsprachigen Segment des Internets praktisch nicht behandelt wird.
Der erste Artikel befasste sich mit den Grundlagen der Arbeit mit Cloudian. Wir haben die interne Struktur und die architektonischen Nuancen zerlegt und die Übersetzung der offiziellen Dokumentation gelesen.
Heute habe ich erzählt, wie wir unser eigenes Lager gebaut haben und auf welche Nuancen und Fallstricke wir gestoßen sind.
Diejenigen unter Ihnen, die mit Stiften fühlen möchten, worüber wir in zwei Artikeln hintereinander sprechen, können das Feedback-Formular
auf dieser Seite verwenden und persönlich herausfinden, was das Salz ist. Standardmäßig geben wir 15 GB für 2 Wochen kostenlos, natürlich mit Benutzerzugriff. Wenn Sie Ihre Eindrücke von der Arbeit mit dem Repository teilen möchten, schreiben Sie mir in PM. :) :)
Und für diejenigen, die nicht genug 15 GB für 2 Wochen sind, haben wir eine
kleine Suche! Auf den Fotos im Artikel haben wir drei Flusspferde platziert. Die ersten 50 Personen, die sie finden, erhalten 4 Wochen lang 30 GB. Um einen vergrößerten Test zu erhalten, schreiben Sie in die Kommentare die Nummern der Bilder, auf denen sich die Flusspferde versteckt haben, und beantragen Sie den obigen Link. Vergessen Sie nicht, einen Link zu Ihrem Kommentar in die Anwendung aufzunehmen.
Wenn Sie Fragen haben, stellen Sie diese traditionell in den Kommentaren.
Ich werde sie gerne beantworten.