Hallo an alle. Wie Sie vielleicht wissen, habe ich früher mehr über Speicher, Vertica, Big Data-Speicher und andere analytische Dinge geschrieben und gesprochen. Jetzt sind alle anderen Datenbanken in meinen Verantwortungsbereich gefallen, nicht nur analytische, sondern auch OLTP (PostgreSQL) und NOSQL (MongoDB, Redis, Tarantool).
In dieser Situation konnte ich eine Organisation mit mehreren Datenbanken als eine Organisation mit einer verteilten heterogenen (heterogenen) Datenbank betrachten. Eine einzelne verteilte heterogene Datenbank, bestehend aus einer Reihe von PostgreSQL, Redis und Mong ... und möglicherweise einer oder zwei Vertica-Datenbanken.
Die Arbeit dieser einzelnen verteilten Basis generiert eine Reihe interessanter Aufgaben. Zunächst ist es aus geschäftlicher Sicht wichtig, dass bei Daten, die sich auf einer solchen Basis bewegen, alles normal ist. Ich verwende den Begriff Integrität, Konsistenz nicht speziell, weil Der Begriff ist komplex und hat in verschiedenen Nuancen der Betrachtung eines DBMS (A C ID- und C AP-Theorem) eine andere Bedeutung.
Die Situation mit einer verteilten Basis wird verschärft, wenn ein Unternehmen versucht, auf eine Microservice-Architektur umzusteigen. Unter der Katze spreche ich darüber, wie die Datenintegrität in einer Microservice-Architektur ohne verteilte Transaktionen und enge Konnektivität sichergestellt werden kann. (Und ganz am Ende erkläre ich, warum ich diese Illustration für den Artikel gewählt habe).

Laut Chris Richardson (einer der bekanntesten Evangelisten der Microservice-Architektur) hat diese Architektur zwei Ansätze für die Arbeit mit Datenbanken: Shared Database und Database-per-Service.

Die gemeinsame Datenbank ist ein guter erster Schritt, eine großartige Lösung für ein kleines Unternehmen ohne ehrgeizige Wachstumspläne. Darüber hinaus ist dieses Muster an sich aus Sicht der Microservice-Architektur ein Anti-Muster Zwei Dienste, die sich eine gemeinsame Basis teilen, können nicht unabhängig voneinander getestet und skaliert werden. Das heißt, Vielmehr sind diese Dienste ein Dienst, der dazu neigt, ein Monolith zu werden.
Das Datenbank-pro-Dienst-Muster setzt voraus, dass jeder Dienst eine eigene Datenbank hat. Ein Dienst kann nur über die API (im weiteren Sinne) auf die Daten eines anderen Dienstes zugreifen, ohne eine direkte Verbindung zu seiner Datenbank herzustellen.
Das Datenbank-pro-Dienst-Muster ermöglicht es den Teams der entsprechenden Dienste, die Datenbanken nach Belieben auszuwählen. Jemand ist in der Lage, MongoDB zu verwenden, jemand glaubt an PostgreSQL, jemand benötigt Redis (das Risiko eines Datenverlusts beim Herunterfahren ist für diesen Dienst akzeptabel) und jemand speichert Daten im Allgemeinen in CSV-Dateien auf der Festplatte (und warum eigentlich und nein?).
Die Arbeit mit einem solchen „Zoo“ von Datenbanken erhöht die Aufgabe, die Ordnung in den Daten auf ein völlig neues Maß an Komplexität wiederherzustellen.
ACID- und Microservice-Architektur
Schauen wir uns die Aufgabe an, die Dinge durch das Prisma des klassischen DBMS-basierten Satzes von ACID-Anforderungen in Ordnung zu bringen: Wir werden das Wesentliche jedes Buchstabens der Abkürzung erweitern und die Schwierigkeiten mit diesem Buchstaben in der Microservice-Architektur veranschaulichen.
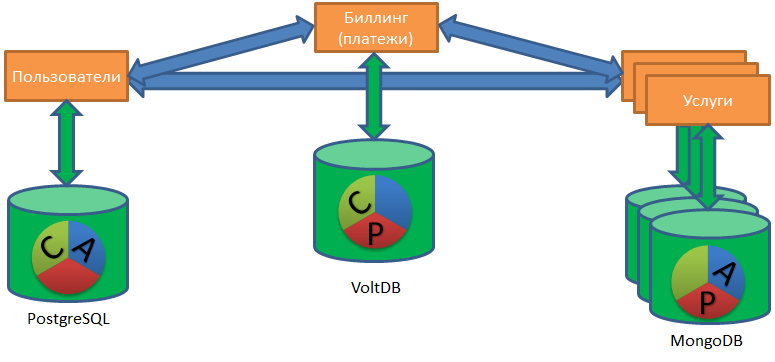
(A) CID - Atomizität. Atomizität - alles oder nichts.
Gemäß der Atomicity-Anforderung müssen unbedingt alle Schritte (mit möglichen Wiederholungen) ausgeführt werden. Wenn ein wichtiger Schritt fehlschlägt, brechen Sie die abgeschlossenen Schritte ab.
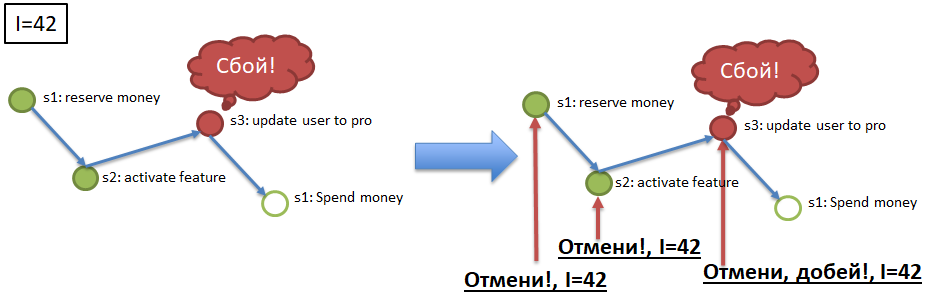
Die obige Abbildung zeigt den Testprozess beim Kauf eines VIP-Dienstes: Geld wird bei der Abrechnung reserviert (1), ein Bonusdienst (2) wird für einen Benutzer aktiviert, der Benutzertyp wird in Pro (3) geändert, reserviertes Geld bei der Abrechnung wird abgebucht (4). Alle vier Schritte müssen entweder abgeschlossen oder nicht abgeschlossen sein.
In diesem Fall können Sie nicht mitten im Prozess hängen bleiben. Daher ist Asynchronität vorzuziehen. In extremen Fällen ist die Synchronität mit dem integrierten Zeitlimit vorzuziehen.
A (C) ID - Konsistenz. Konsistenz - Jeder Schritt sollte den Randbedingungen nicht widersprechen.
Klassische Beispiele für Bedingungen zum Beispiel für das Senden von Geld von Client A in Service 1 an Client B in Service 2: Durch das Senden von Geld sollte nicht weniger (Geld sollte während der Überweisung nicht verloren gehen) oder mehr (es ist nicht akzeptabel, dasselbe Geld an zwei Benutzer zu senden) zur gleichen Zeit). Um diese Anforderung zu erfüllen, müssen Sie die Bedingungen irgendwo codieren und die Daten auf die Bedingungen überprüfen (idealerweise ohne zusätzliche Anrufe).

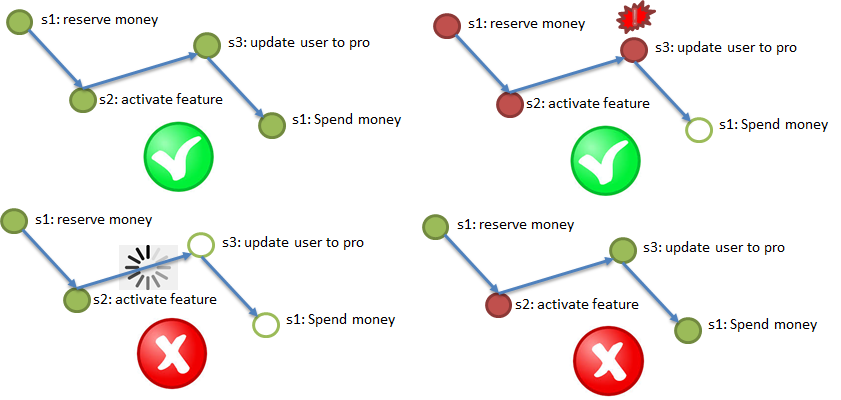
ACI (D) - Haltbarkeit. Die Haltbarkeitsanforderung bedeutet, dass die Auswirkungen von Operationen nicht verschwinden.
Unter den Bedingungen der Polyglot-Persistenz kann ein Dienst mit einer Datenbank arbeiten, die regelmäßig die darin aufgezeichneten Daten „verlieren“ kann. Ein ähnlicher Trick kann auch aus soliden Datenbanken wie PostgreSQL erhalten werden, wenn dort die asynchrone Replikation aktiviert ist. Die Abbildung zeigt, wie Änderungen, die im Master aufgezeichnet wurden, aber nicht über die asynchrone Replikation den Slave erreichten, durch Brennen des Master-Servers zerstört werden können. Um die Anforderungen an die Haltbarkeit zu gewährleisten, müssen solche Verluste ordnungsgemäß diagnostiziert und behoben werden können.
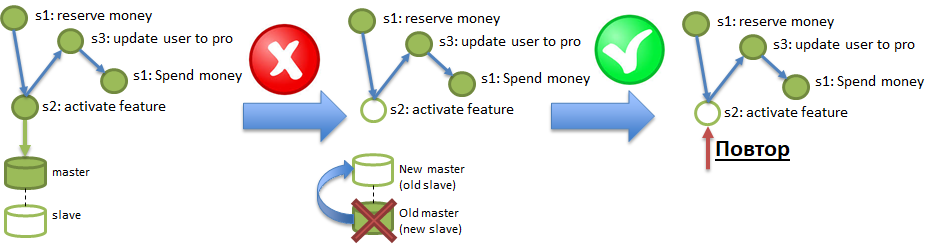
Und wo bin ich, fragst du?
Und nirgendwo. Die Isolierung mehrerer unabhängiger asynchroner Dienste in einer Umgebung ist eine technische Anforderung. Moderne Forschungen haben gezeigt, dass reale Geschäftsprozesse ohne Isolation implementiert werden können. Die Isolation vereinfacht das Denken durch Minimierung der Parallelität (die Entwicklung von Parallel-Computing ist für einen Programmierer schwieriger), aber die Microservice-Architektur ist von Natur aus massiv parallel, die Isolation in einer solchen Umgebung ist redundant.
Es gibt viele Ansätze, um die oben genannten Anforderungen zu erfüllen. Der bekannteste Algorithmus für verteilte Transaktionen, der durch das sogenannte Two-Phase-Commit (2PC) bereitgestellt wird. Leider erfordert die Implementierung von zweiphasigen Commits das Umschreiben aller beteiligten Dienste. Und das Ernsteste: Dieser Algorithmus ist nicht sehr produktiv. Die Abbildungen aus jüngsten Studien zeigen, dass dieser Algorithmus eine bestimmte Leistung auf einer verteilten Basis von zwei Servern zeigt, aber mit zunehmender Anzahl von Servern wächst die Produktivität nicht linear ... oder vielmehr überhaupt nicht.

Einer der Hauptvorteile der Microservice-Architektur ist die Möglichkeit, die Leistung durch einfaches Hinzufügen von immer mehr Servern linear zu steigern. Es stellt sich heraus, dass dieser Prozess, wenn wir ein zweiphasiges Commit verwenden, um die verteilte Integrität sicherzustellen, trotz der zunehmenden Anzahl von Servern zu einem Engpass wird, der das Produktivitätswachstum einschränkt.
Wie können Sie eine verteilte Integrität (ACiD-Anforderungen) ohne zweiphasige Festschreibungen sicherstellen und die Leistung linear skalieren?
Moderne Forschungen (z. B. Eine Bewertung der verteilten Parallelitätskontrolle. VLDB 2017 ) argumentieren, dass der sogenannte „optimistische Ansatz“ helfen kann. Der Unterschied zwischen dem Zwei-Phasen-Commit und dem allgemeinen „optimistischen Ansatz“ kann durch den Unterschied zwischen dem alten sowjetischen Geschäft (mit Theke) und einem modernen Supermarkt wie Auchan veranschaulicht werden. In einem Geschäft mit Schalter gilt jeder Kunde als verdächtig und wird mit maximaler Kontrolle bedient. Daher die Linien und Konflikte. Und im Supermarkt gilt der Käufer standardmäßig als ehrlich, er gibt ihm die Möglichkeit, sich den Regalen zu nähern und die Karren zu füllen. Natürlich gibt es Überwachungsinstrumente zum Fangen von Gaunern (Kameras, Sicherheit), aber die meisten Käufer müssen sich nie damit befassen.
Daher kann der Supermarkt einfach durch Platzieren weiterer Kassen skaliert und erweitert werden. Ähnlich verhält es sich mit der Microservice-Architektur: Wenn die verteilte Integrität durch einen „optimistischen Ansatz“ sichergestellt wird, werden zusätzlich nur Prozesse geladen, bei denen ein Fehler aufgetreten ist. Und normale Prozesse gehen ohne zusätzliche Prüfungen.
Es ist wichtig. Der „optimistische Ansatz“ umfasst mehrere Algorithmen. Ich möchte Ihnen etwas über die Saga erzählen - den von Chris Richardson empfohlenen Algorithmus zur Aufrechterhaltung der verteilten Integrität.
Sagas - Elemente des Algorithmus
Der Durchhang-Algorithmus hat zwei Optionen. Daher möchte ich zunächst die erforderlichen Elemente des Algorithmus universell beschreiben, damit die Beschreibung für beide Optionen geeignet ist.
Element 1. Zuverlässiger, beständiger Kanal für die Ereignisübermittlung zwischen Diensten, der "mindestens einmalige Übermittlung" garantiert. Das heißt, Wenn Schritt 2 des Prozesses erfolgreich abgeschlossen wurde, sollte eine Benachrichtigung (ein Ereignis) darüber mindestens einmal Schritt 3 erreichen. Wiederholte Lieferungen sind akzeptabel, aber es sollte nichts verloren gehen. "Persistent" bedeutet, dass der Kanal Benachrichtigungen für einige Zeit (2-3 Tage, eine Woche) speichern muss, damit ein Dienst, der die letzten Änderungen aufgrund des Verlusts der Datenbank verloren hat (siehe Beispiel für die Haltbarkeit in der Abbildung, Schritt 2 ist). Diese Änderungen werden durch Wiedergabe von Ereignissen aus dem Kanal vorgenommen.
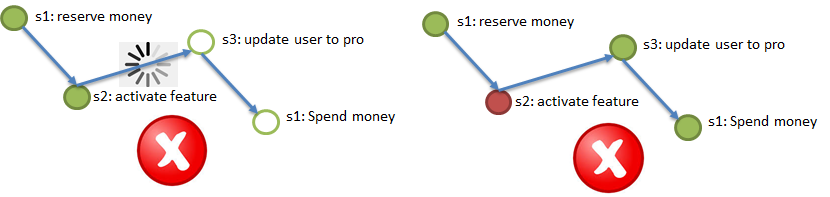
Element 2. Idempotenz von Dienstanrufen durch Verwendung eines eindeutigen Idempotenzschlüssels. Stellen Sie sich vor, ich (der Benutzer) initiiere den Kauf eines VIP-Pakets (siehe Beispiel für Atomicity). Zu Beginn des Prozesses erhalte ich einen eindeutigen Schlüssel, den Idempotenzschlüssel, z. B. 42. Als nächstes sollte der Aufruf jedes der Schritte (1 → 2 → 3 → 4) mit dem angegebenen Idempotenzschlüssel ausgeführt werden. Im obigen Absatz wird die Möglichkeit des wiederholten Eintreffens derselben Nachricht an den Dienst (in Schritt) erwähnt. Der Dienst (Schritt) sollte automatisch in der Lage sein, das wiederholte Eintreffen des verarbeiteten Ereignisses zu ignorieren und die Wiederholung durch den Idempotenzschlüssel zu überprüfen. Das heißt, wenn alle Dienste (Prozessschritte) idempotent sind, reicht es aus, um die Anforderungen von Atomicity and Durability zu erfüllen, zu den Schritten umzuleiten, die Ereignissen aus den Kanälen entsprechen. Die Schritte, bei denen Ereignisse übersprungen wurden, führen sie aus, und die Schritte, bei denen Ereignisse bereits abgeschlossen wurden, ignorieren sie aufgrund von Idempotenz.

Element 3. Abbruch von Serviceabrufen (Schritten) durch Idempotenzschlüssel.
Um die Atomizität sicherzustellen (siehe Beispiel), muss beispielsweise die erfolgreiche Ausführung der Schritte 1 und 2 für Schlüssel 42 abgebrochen werden, wenn der Prozess mit dem Idempotenzschlüssel 42 beispielsweise in Schritt 3 gestoppt / abgefallen ist. Dazu muss jeder obligatorische Prozessschritt einen "Kompensations" -Schritt haben , Eine API-Methode, die die Ausführung des erforderlichen Schritts für den angegebenen Idempotenzschlüssel abbricht (42). Die Implementierung von Ausgleichsaufrufen ist ein schwieriges, aber notwendiges Element bei der Verfeinerung von Diensten als Teil der Implementierung des Durchhangalgorithmus.
Die drei oben aufgeführten Elemente sind für beide Versionen der Implementierung des "Sag" relevant: orchestriert und choreografisch.
Orchestrierte Sagen
Der einfachere und offensichtlichere Algorithmus für orchestrierte Sagen ist leichter zu verstehen und zu implementieren. In einem ausgezeichneten Artikel beschrieb kevteev den Algorithmus und den Implementierungsprozess des Mechanismus orchestrierter Sagen in Avito. Ihr Algorithmus setzt die Existenz eines steuernden Dienstes voraus, der Dienstaufrufe im Rahmen von betreuten Geschäftsprozessen "orchestriert". Derselbe Überwachungsdienst verfügt möglicherweise über eine eigene Datenbank (z. B. PostgreSQL), die als zuverlässiger Übermittlungskanal für persistente Ereignisse fungiert (Element 1).
Choreografische Sagen
Die choreografische Saga ist schwieriger. Hier sollte ein Datenbus, der die folgenden Anforderungen implementiert, als zuverlässiger dauerhafter Kanal fungieren: Fire-and-Forget-Veröffentlichung, Veröffentlichung von Publish-Subscribe-Ereignissen, mindestens einmalige Zustellung. Das heißt, Jeder Schritt jedes Prozesses sollte einen Befehl zum Bedienen vom Bus erhalten und dort die Nachricht über den erfolgreichen Abschluss, über den Beginn des nächsten Schritts, werfen, damit er sie auch vom Bus liest und den Prozess fortsetzt. Darüber hinaus kann es für jede Nachricht mehrere Teilnehmer geben.
Die choreografische Saga sollte auch einen Kontrolldienst haben, einen Dienst der Sagen, aber viel „leichter“. Der Service sollte über die im System registrierten Geschäftsprozesse und über die Zusammensetzung der in jedem Prozess enthaltenen Schritte informiert sein. Er sollte auch auf den Bus hören, die Ausführung jedes Prozesses überwachen (jeden Idempotenzschlüssel) und nur dann, wenn etwas schief gelaufen ist, entweder "Wiederholungen" bestimmter Schritte oder "Abbrüche", "Kompensationen" für die durchgeführten Schritte auslösen.
Nuancen
Eine der wichtigsten Nuancen von Sagen, die sie von klassischen Transaktionen unterscheiden, ist die Abweichung von der Linearität, Reihenfolge und Verpflichtung jedes Schritts. Eine Saga ist nicht unbedingt eine lineare Kette von Ereignissen, sondern kann ein gerichteter Graph sein: Ein neues Benutzerregistrierungsereignis kann mehrere Schritte parallel generieren (Senden von SMS, Registrieren eines Logins, Generieren eines Passworts, Senden einer E-Mail), von denen einige optional sein können. In erster Näherung scheint es, dass es in einer solchen „verzweigten“ Saga mit optionalen Schritten schwierig ist, den Abschluss der Saga (Prozess) zu bestimmen, aber tatsächlich ist alles einfach: Die Saga (Prozess) ist abgeschlossen, wenn alle erforderlichen Schritte in beliebiger Reihenfolge abgeschlossen sind.

Die zweite Nuance, die eher für choreografische als auch für orchestrierte Sagen möglich ist, besteht darin, einen Ansatz für die Registrierung von Geschäftsprozessen und Arten von Sagen im Sagas-Service zu wählen. Das Atomicity-Beispiel beschreibt einen Prozess von vier aufeinander folgenden erforderlichen Schritten.
Wer hat diesen Prozess registriert, alle Schritte angegeben, die Abhängigkeiten und obligatorischen Schritte platziert? Die offensichtliche, aber altmodische Antwort lautet, dass die Prozessregistrierung zentral im Sag-Service erfolgen sollte. Diese Antwort stimmt jedoch nicht sehr mit der Microservice-Architektur überein. In der Microservice-Architektur ist es vielversprechender, produktiver und schneller, Bottom-up-Prozesse zu registrieren. Das heißt, nicht alle Nuancen des Prozesses im Durchhangdienst aufzuschreiben, sondern einzelnen Diensten zu ermöglichen, sich selbst in bestehende Prozesse "einzufügen", wobei ihre Verbindlichkeit / optionale Natur und ihre obligatorischen Vorgänger angegeben werden.
Das heißt, Der Prozess der Registrierung eines Benutzers im Durchhangdienst kann anfänglich aus drei Schritten bestehen. Während der Entwicklung des Systems passen dann sieben weitere Schritte hinein, und ein Schritt wird ausgeschrieben, und es gibt neun davon. Ein solches "anarchistisches" und "dezentrales" Schema ist schwer zu testen, um einen strengen, koordinierten Prozess zu implementieren, aber es ist für agile Teams viel bequemer, eine kontinuierliche multidirektionale Produktentwicklung durchzuführen.
Eigentlich hier. Bei einer ernsthaften Präsentation halte ich es für sinnvoll, fertig zu werden, da sich der Artikel sonst als zu groß herausstellte.
Hier ist ein Link zur Präsentation dieses Materials. Ich habe auf der Highload Siberia 2018 einen Bericht zu diesem Thema erstellt.
UPD - und Video von der Konferenz:
Nachwort
Am Ende möchte ich versuchen, all das in einer bildlicheren Sprache zu erklären.
Was ist eine Saga von Anfang an? Diese Handlung, dieses Abenteuer aus dem Mittelalter ... oder aus dem Game of Thrones. Ein Ereignis findet statt (eine Schlacht, eine Hochzeit, jemand stirbt), die Nachricht davon fliegt um die Welt durch Boten, Brieftauben, durch Händler. Wenn die Nachrichten die Interessierten erreichen (in einer Woche, in einem Monat, in einem Jahr), reagieren sie: Sie senden Armeen, erklären den Krieg, sie exekutieren jemanden und neue Nachrichten fliegen.
Es gibt keine Regulierungsbehörde, die die Abfolge der Maßnahmen überwacht. Keine Transaktionen, kein Rollback im Sinne eines Rückgängigmachens der Aktion, als wäre es nie gewesen. Alles auf erwachsene Weise, jede Handlung findet für immer statt. Es kann entschädigt werden, aber es ist genau Handlung (Mord) und Entschädigung (Bezahlung für den Kopf, Vira) und nicht die Abschaffung des Todes.
Ereignisse dauern lange, stammen aus verschiedenen Quellen, Aktionen finden parallel und nicht streng nacheinander statt. Und ziemlich oft tauchen plötzlich neue Teilnehmer in der Handlung auf, die sich zur Teilnahme entschließen (Drachen kommen an;)) ... und einige der alten Teilnehmer sterben plötzlich.
Solche Dinge. Es scheint wie ein Chaos, aber alles funktioniert, die interne Koordination der Welt wird nicht verletzt, die Handlung entwickelt sich und ist konsistent ... Obwohl manchmal unvorhersehbar.