
Jeder von uns nimmt die Texte auf seine Weise wahr, sei es Nachrichten im Internet, Gedichte oder klassische Romane. Gleiches gilt für Algorithmen und Methoden des maschinellen Lernens, die in der Regel Texte in mathematischer Form in Form eines mehrdimensionalen Vektorraums wahrnehmen.
Der Artikel widmet sich der Visualisierung mit t-SNE, berechnet durch mehrdimensionale Word2Vec-Vektordarstellungen von Wörtern. Die Visualisierung hilft dabei, das Prinzip von Word2Vec besser zu verstehen und die Beziehung zwischen den Wortvektoren zu interpretieren, bevor sie in neuronalen Netzen und anderen Algorithmen für maschinelles Lernen weiter verwendet wird. Der Artikel konzentriert sich auf Visualisierung, weitere Forschung und Datenanalyse werden nicht berücksichtigt. Als Datenquelle verwenden wir Artikel aus Google News und klassische Werke von L.N. Tolstoi. Wir werden den Code in Python in das Jupyter-Notizbuch schreiben.
T-verteilte stochastische Nachbareinbettung
T-SNE ist ein Algorithmus für maschinelles Lernen zur Datenvisualisierung, der auf der nichtlinearen Dimensionsreduktionsmethode basiert, die im Originalartikel [1] und in
Habré ausführlich beschrieben wird. Das Grundprinzip des t-SNE-Betriebs besteht darin, paarweise Abstände zwischen Punkten zu verringern, während ihre relative Position beibehalten wird. Mit anderen Worten, der Algorithmus ordnet mehrdimensionale Daten einem Raum niedrigerer Dimension zu, während die Struktur der Nachbarschaft von Punkten beibehalten wird.
Vektordarstellungen von Wörtern und Word2Vec
Zunächst müssen wir die Wörter in Vektorform präsentieren. Für diese Aufgabe habe ich das Dienstprogramm für die Semantik der Word2Vec-Verteilung ausgewählt, mit dem die semantische Bedeutung von Wörtern im Vektorraum angezeigt werden soll. Word2Vec findet Beziehungen zwischen Wörtern, indem angenommen wird, dass semantisch verwandte Wörter in ähnlichen Kontexten gefunden werden. Weitere Informationen zu Word2Vec finden Sie im Originalartikel [2] sowie
hier und
hier .
Als Input nehmen wir Artikel aus Google News und Romane von L.N. Tolstoi. Im ersten Fall verwenden wir die Vektoren, die für den von Google
auf der Projektseite veröffentlichten Google News-Datensatz (ca. 100 Milliarden Wörter) vorab trainiert wurden.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Zusätzlich zu vorab trainierten Vektoren, die die Gensim-Bibliothek verwenden [3], werden wir ein weiteres Modell in den Texten von L.N. Tolstoi. Da Word2Vec ein Array von Sätzen als Eingabe akzeptiert, verwenden wir das vorab trainierte Punkt-Satz-Tokenizer-Modell aus dem NLTK-Paket, um Text automatisch in Sätze aufzuteilen. Das Modell für die russische Sprache kann hier heruntergeladen
werden .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Als Nächstes trainieren wir mithilfe der Gensim-Bibliothek das Word2Vec-Modell mit den folgenden Parametern:
- Größe = 200 - Dimension des Attributraums;
- window = 5 - die Anzahl der Wörter aus dem Kontext, den der Algorithmus analysiert;
- min_count = 5 - Das Wort muss mindestens fünfmal vorkommen, damit das Modell es berücksichtigt.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisierung von Vektordarstellungen von Wörtern mit t-SNE
T-SNE ist äußerst nützlich, um Ähnlichkeiten zwischen Objekten in einem mehrdimensionalen Raum zu visualisieren. Mit zunehmender Datenmenge wird es immer schwieriger, ein visuelles Diagramm zu erstellen. In der Praxis werden verwandte Wörter zur weiteren Visualisierung zu Gruppen zusammengefasst. Nehmen Sie zum Beispiel einige Wörter aus einem Wörterbuch des Word2Vec-Modells, das zuvor in Google News geschult wurde.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
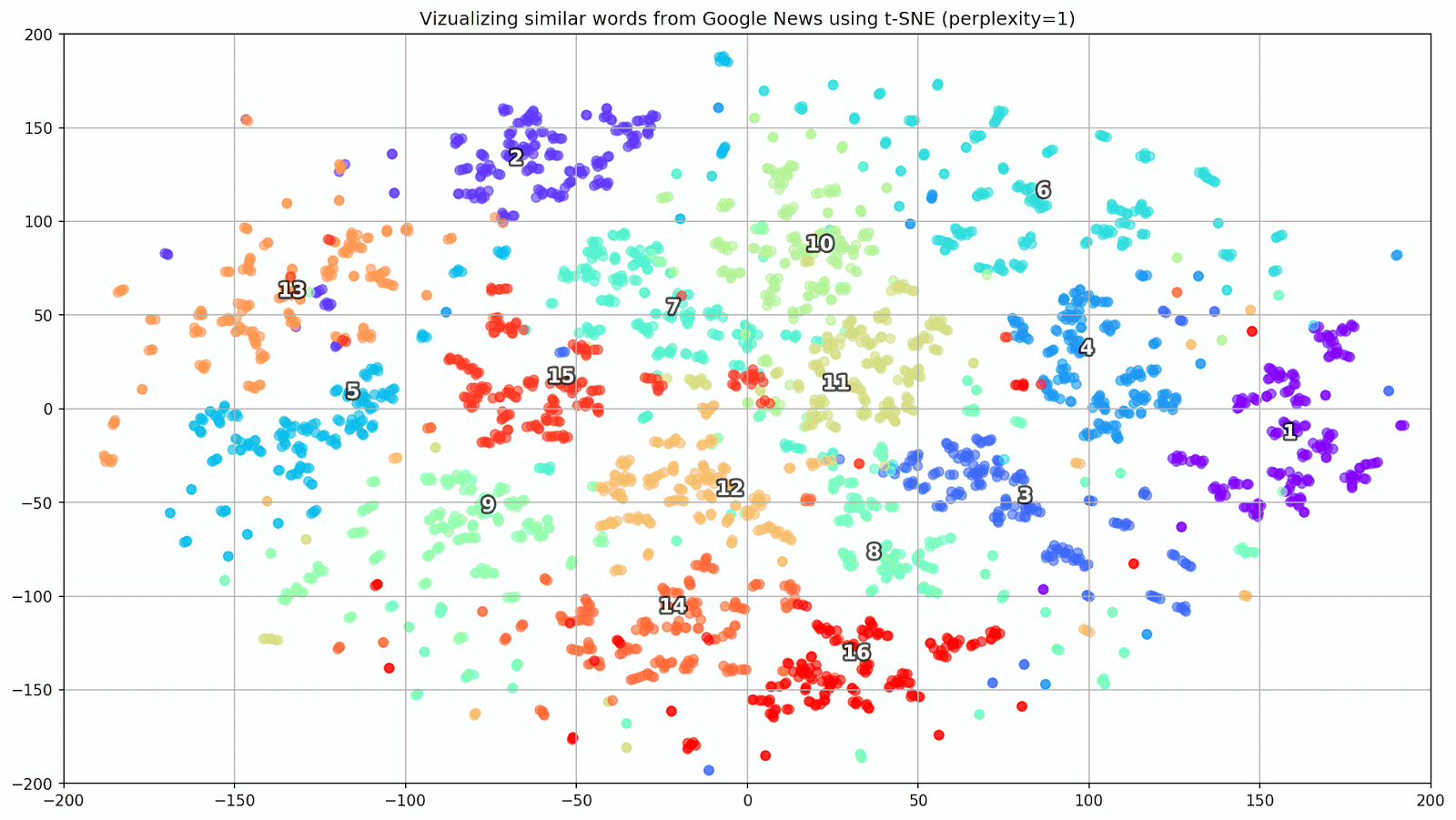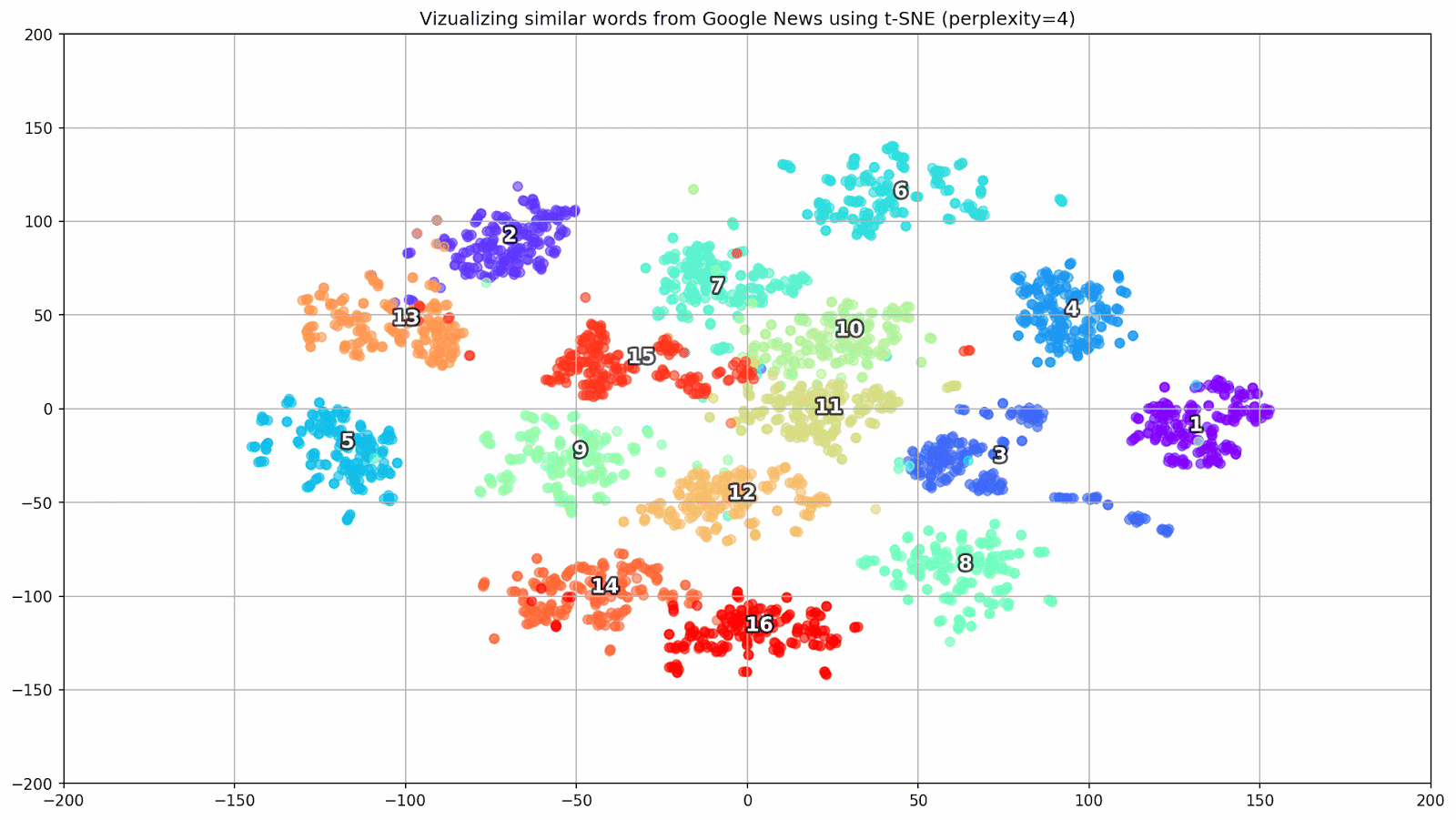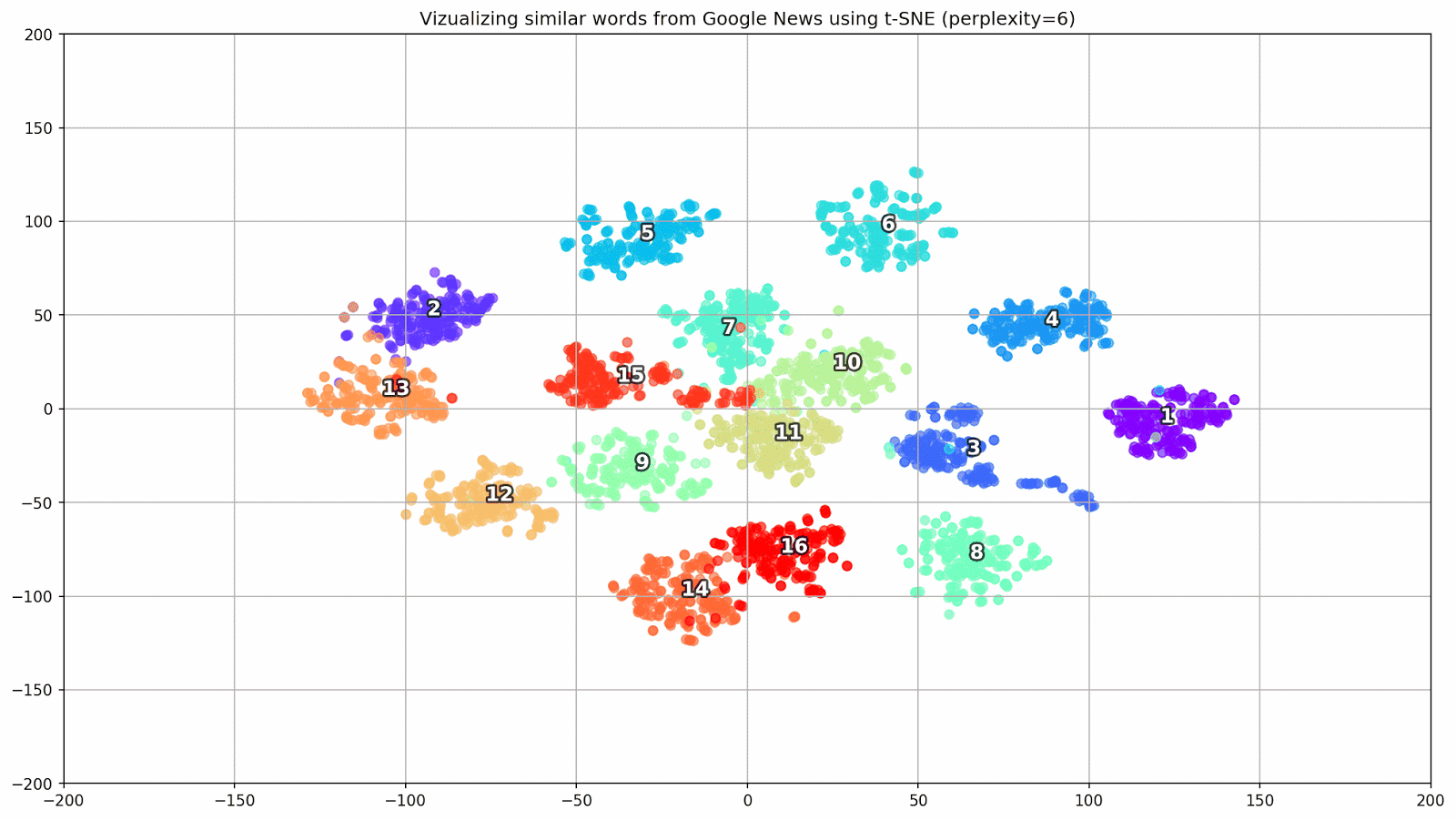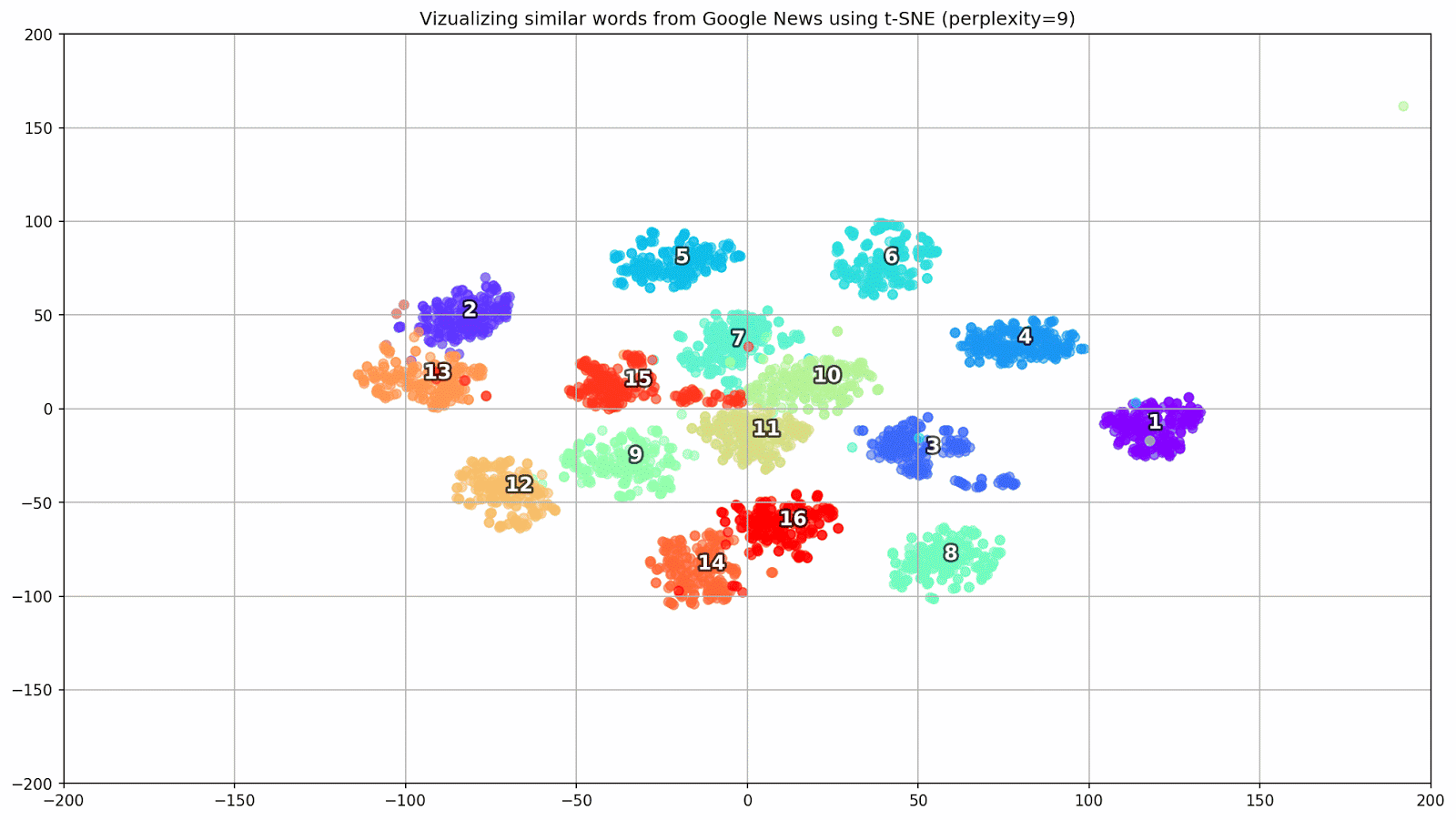 Abbildung 1. Gruppen ähnlicher Wörter aus Google News mit unterschiedlichen Präplexitätswerten.
Abbildung 1. Gruppen ähnlicher Wörter aus Google News mit unterschiedlichen Präplexitätswerten.Als nächstes wenden wir uns dem bemerkenswertesten Fragment des Artikels zu, der t-SNE-Konfiguration. Hier sollten Sie zunächst die folgenden Hyperparameter beachten:
- n_Komponenten - die Anzahl der Komponenten, d. h. die Dimension des Werteraums ;
- Ratlosigkeit - Ratlosigkeit, deren Wert in t-SNE der effektiven Anzahl von Nachbarn gleichgesetzt werden kann. Es hängt mit der Anzahl der nächsten Nachbarn zusammen, die in anderen Modellen verwendet wird, die anhand von Sorten lernen (siehe Abbildung oben). Es wird empfohlen, den Wert [1] im Bereich von 5 bis 50 einzustellen.
- init - Typ der anfänglichen Initialisierung von Vektoren.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Unten finden Sie ein Skript zum Erstellen eines zweidimensionalen Diagramms mit Matplotlib, einer der beliebtesten Bibliotheken zur Visualisierung von Daten in Python.
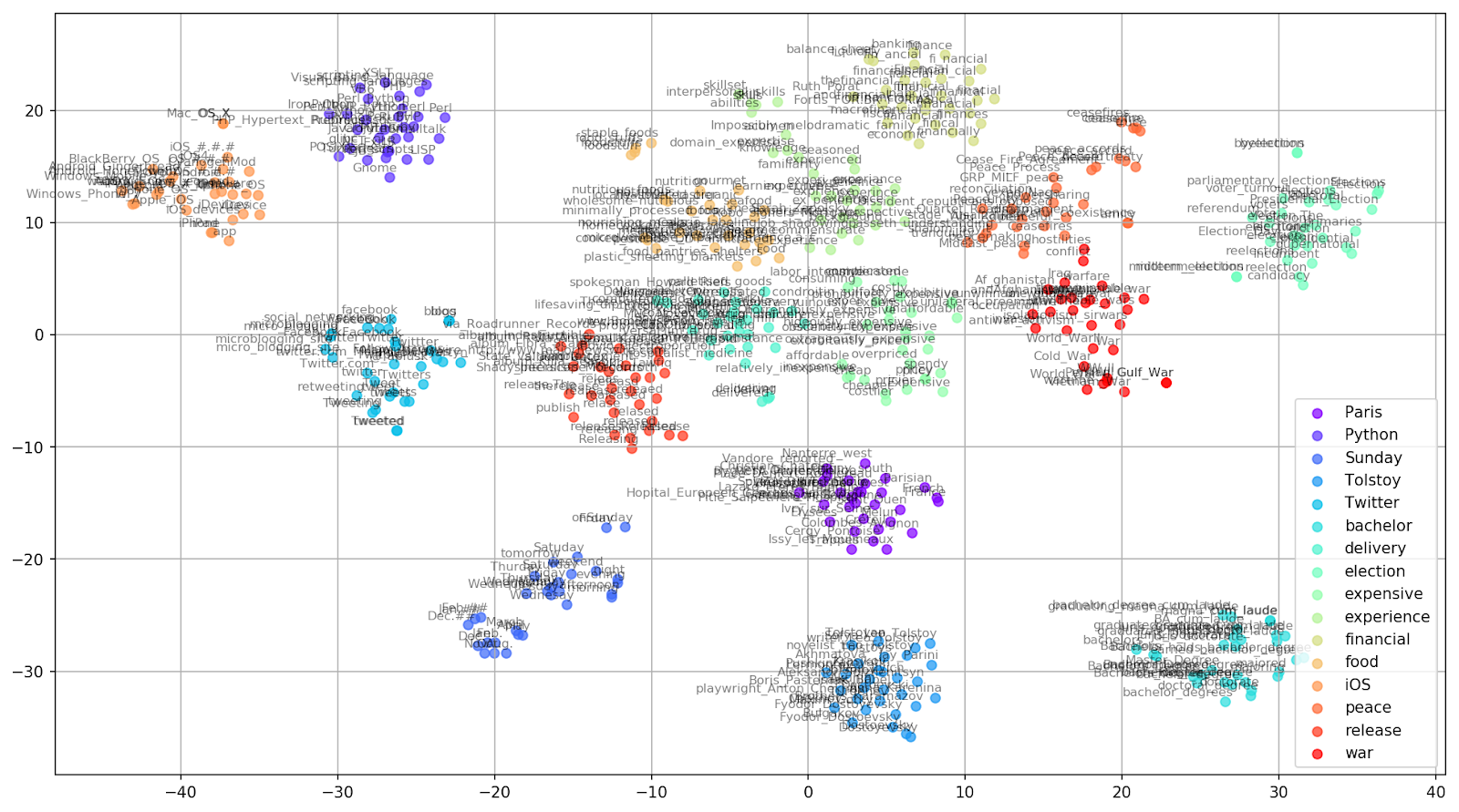 Abbildung 2. Gruppen ähnlicher Wörter aus Google News (Präplexität = 15).
Abbildung 2. Gruppen ähnlicher Wörter aus Google News (Präplexität = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Manchmal ist es notwendig, nicht separate Wortgruppen zu erstellen, sondern das gesamte Wörterbuch. Lassen Sie uns zu diesem Zweck Anna Karenina analysieren, die große Geschichte von Leidenschaft, Verrat, Tragödie und Sühne.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
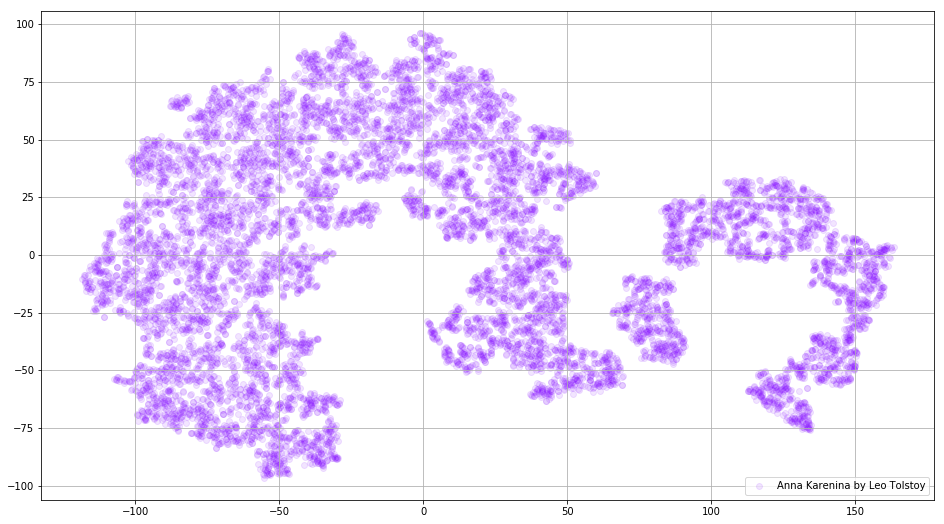
 Abbildung 3. Visualisierung des Wörterbuchs des Word2Vec-Modells, das auf dem Roman "Anna Karenina" trainiert wurde.
Abbildung 3. Visualisierung des Wörterbuchs des Word2Vec-Modells, das auf dem Roman "Anna Karenina" trainiert wurde.Das Bild kann noch informativer werden, wenn wir den dreidimensionalen Raum verwenden. Schauen Sie sich Krieg und Frieden an, einen der wichtigsten Romane der Weltliteratur.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
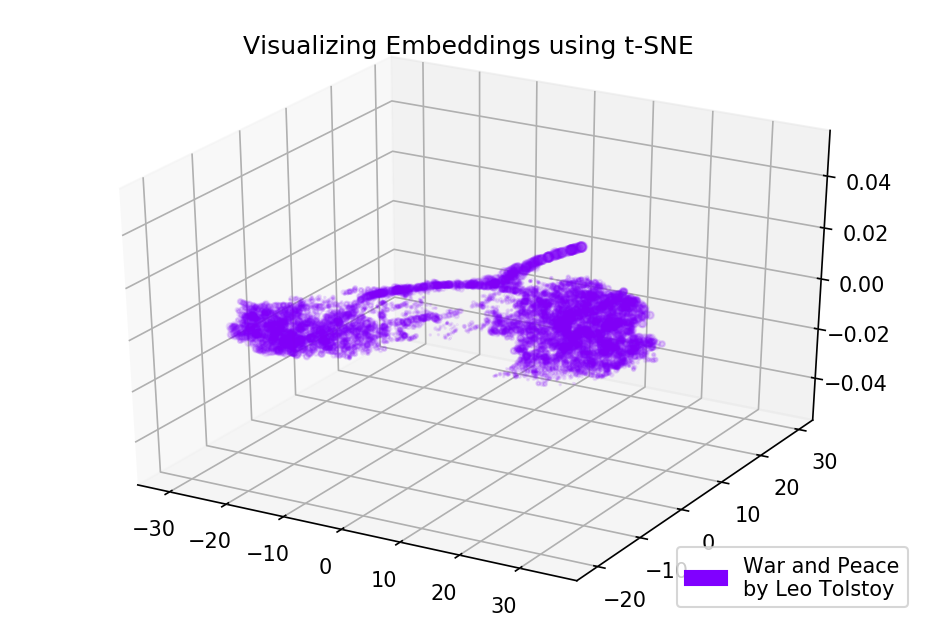 Abbildung 4. Visualisierung des Wörterbuchs des Word2Vec-Modells, das auf dem Roman "Krieg und Frieden" trainiert wurde.
Abbildung 4. Visualisierung des Wörterbuchs des Word2Vec-Modells, das auf dem Roman "Krieg und Frieden" trainiert wurde.Quellcode
Der Code ist auf
GitHub verfügbar. Dort finden Sie den Code zum Rendern von Animationen.
Quellen
- Maaten L., Hinton G. Visualisierung von Daten mit t-SNE // Journal of Machine Learning Research. - 2008. - T. 9. - S. 2579-2605.
- Verteilte Darstellungen von Wörtern und Phrasen und ihre Zusammensetzung // Fortschritte in neuronalen Informationsverarbeitungssystemen . - 2013 - S. 3111-3119.
- Rehurek R., Sojka P. Software-Framework für die Themenmodellierung mit großen Korpora // In Proceedings des LREC 2010-Workshops zu neuen Herausforderungen für NLP-Frameworks. - 2010.