Ich lade weiterhin Berichte mit Pixonic DevGAMM Talks hoch, unserem September-Treffen für Entwickler hoch geladener Systeme. Sie haben viele Erfahrungen und Fälle geteilt, und heute veröffentliche ich eine Abschrift der Rede des Backend-Entwicklers von Sabre Interactive Roman Rogozin. Er sprach über die Praxis der Anwendung des Akteurmodells am Beispiel der Verwaltung von Spielern und deren Status (andere Berichte finden Sie am Ende des Artikels, die Liste wird ergänzt).
Unser Team arbeitet an einem Backend für das Spiel Quake Champions, und ich werde darüber sprechen, was das Schauspielermodell ist und wie es im Projekt verwendet wird.
Ein bisschen über Technologie-Stack. Wir schreiben Code in C #, alle Technologien sind daran gebunden. Ich möchte darauf hinweisen, dass es einige spezifische Dinge geben wird, die ich am Beispiel dieser Sprache zeigen werde, aber die allgemeinen Prinzipien bleiben unverändert.

Derzeit hosten wir unsere Dienste in Azure. Es gibt einige sehr interessante Grundelemente, die wir nicht aufgeben möchten, wie z. B. Table Storage und Cosmos DB (aber wir versuchen, sie für das plattformübergreifende Projekt nicht zu eng zu machen).
Jetzt möchte ich ein wenig darüber erzählen, was ein Schauspielermodell ist. Und zunächst erschien es grundsätzlich vor mehr als 40 Jahren.
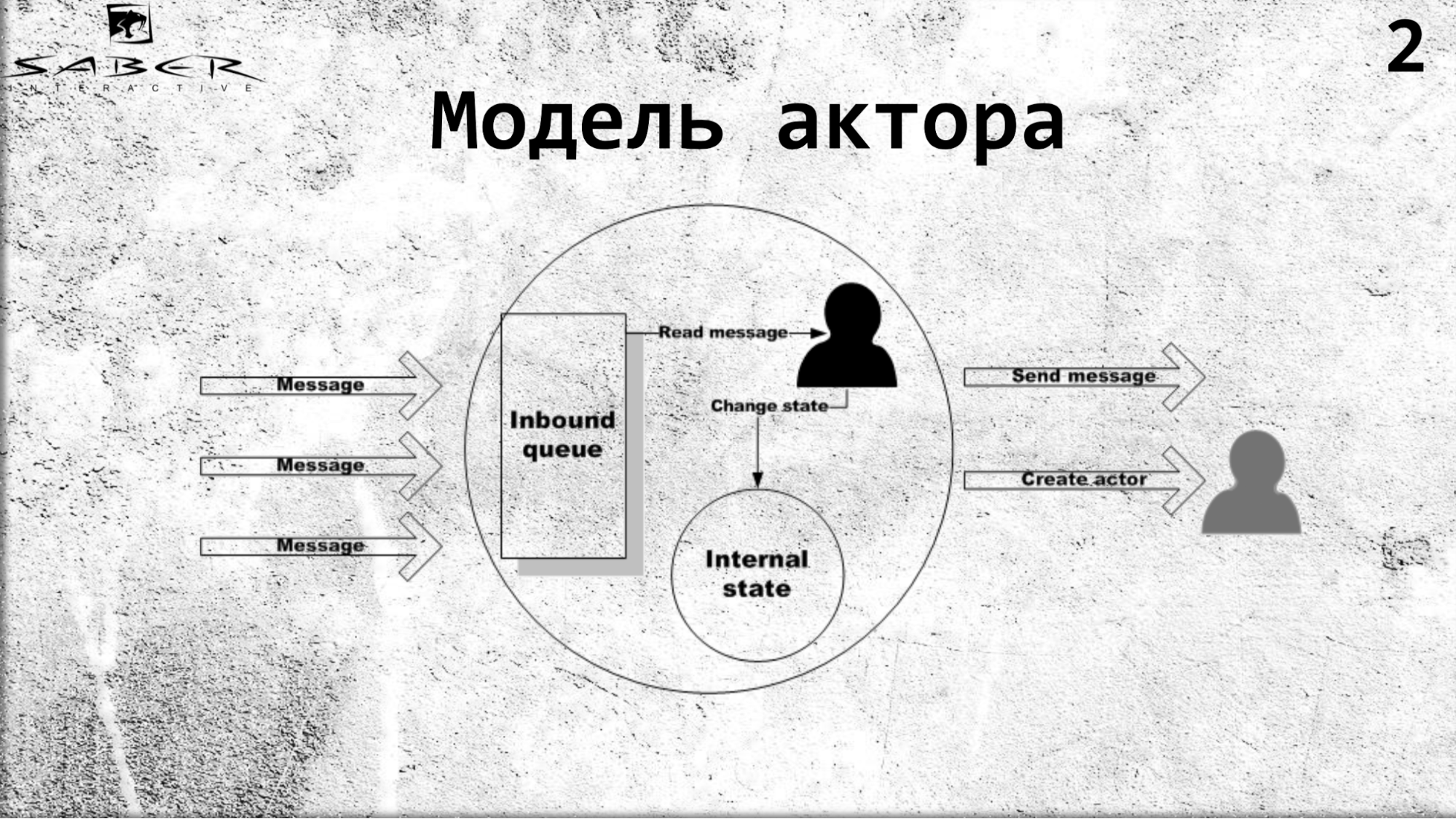
Ein Akteur ist ein Modell für paralleles Rechnen, das angibt, dass es ein bestimmtes isoliertes Objekt gibt, das über einen eigenen internen Status und exklusiven Zugriff zum Ändern dieses Status verfügt. Ein Akteur kann Nachrichten lesen und darüber hinaus nacheinander eine Art Geschäftslogik ausführen, wenn er seinen internen Status ändern und Nachrichten an externe Dienste, einschließlich anderer Akteure, senden möchte. Und er weiß, wie man andere Schauspieler erschafft.
Akteure kommunizieren asynchron miteinander, sodass Sie hoch ausgelastete verteilte Cloud-Systeme erstellen können. In dieser Hinsicht ist das Akteurmodell in letzter Zeit weit verbreitet.
Zusammenfassend stellen wir uns vor, wir haben eine Cloud, in der es eine Art Servercluster gibt, und unsere Akteure drehen sich um diesen Cluster.
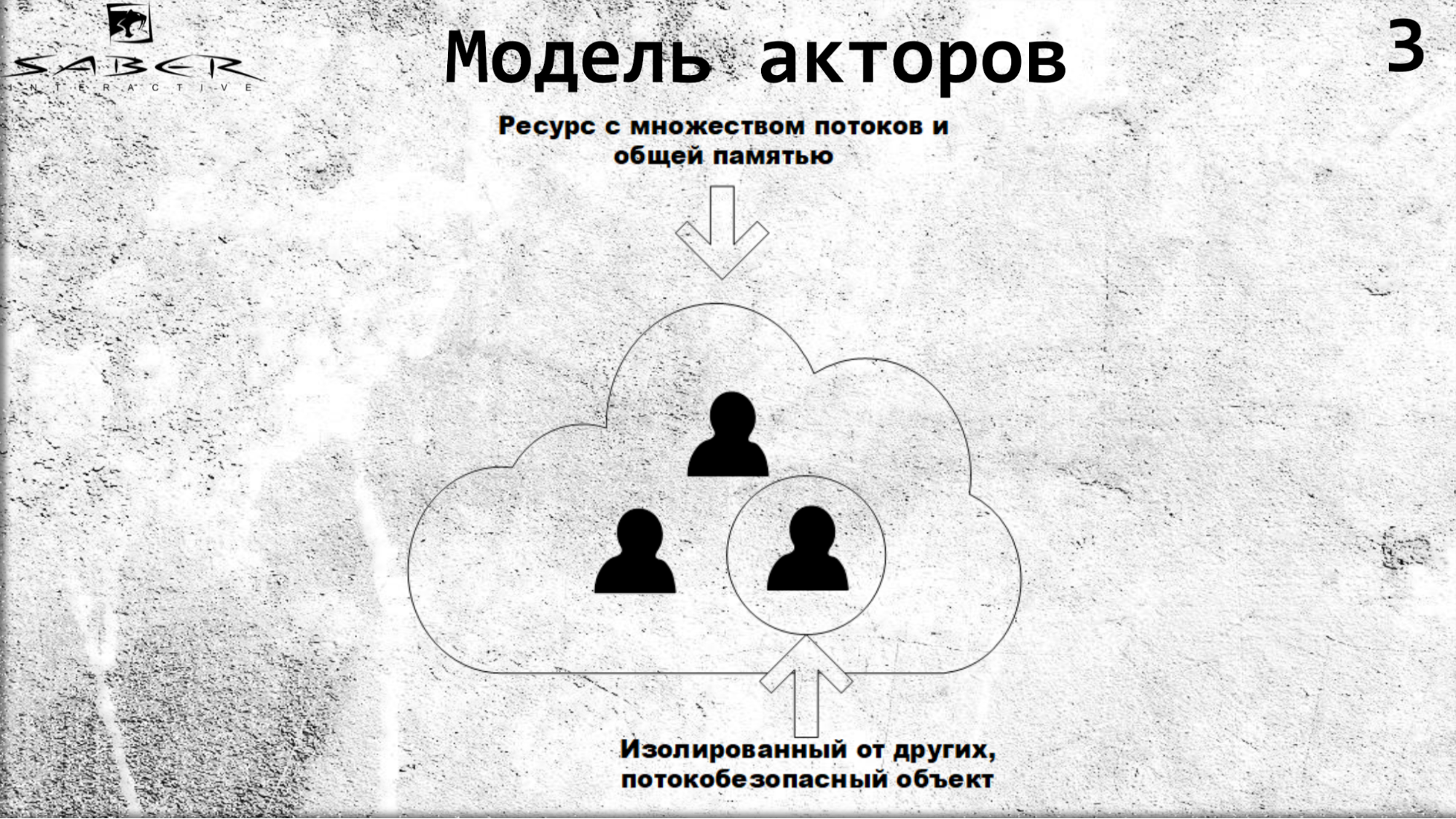
Akteure sind voneinander isoliert, kommunizieren über asynchrone Aufrufe und in sich selbst sind die Akteure threadsicher.
Wie es aussehen könnte. Angenommen, wir haben mehrere Benutzer (keine sehr große Last), und irgendwann verstehen wir, dass es einen Zustrom von Spielern gibt, und wir müssen dringend eine Hochskalierung durchführen.
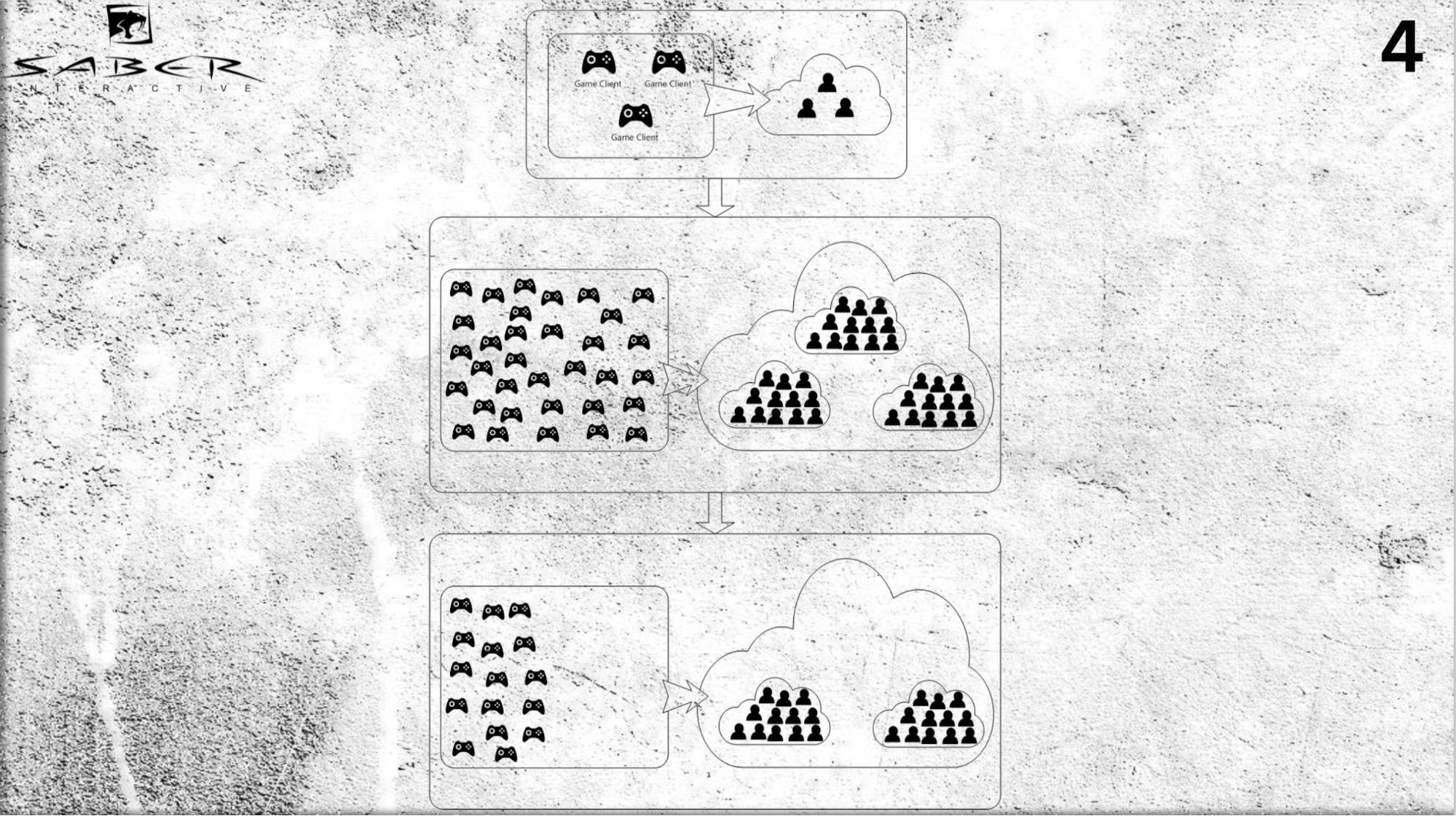
Wir können unserer Cloud Server hinzufügen und mithilfe des Akteurmodells einzelne Benutzer pushen - weisen Sie jedem einzelnen Akteur zu und weisen Sie diesem Akteur in der Cloud Speicherplatz für Speicher und Prozessorzeit zu.
Somit spielt der Akteur zum einen die Rolle eines Caches, und zum anderen handelt es sich um einen „intelligenten Cache“, der einige Nachrichten verarbeiten und Geschäftslogik ausführen kann. Auch hier gilt: Wenn Sie eine Verkleinerung vornehmen müssen (z. B. die Spieler sind gegangen), ist es auch kein Problem, diese Akteure aus dem System zu entfernen.
Wir im Backend verwenden nicht das klassische Schauspielermodell, sondern basieren auf dem Orleans-Framework. Was ist der Unterschied? Ich werde versuchen, es Ihnen jetzt zu sagen.

Zunächst führt Orleans das Konzept des virtuellen Schauspielers oder, wie es auch genannt wird, des Getreides ein. Im Gegensatz zum klassischen Darstellermodell, bei dem ein Dienst dafür verantwortlich ist, diesen Darsteller zu erstellen und auf einigen Servern zu platzieren, übernimmt Orleans die Arbeit. Das heißt, Wenn ein bestimmter Benutzerdienst eine bestimmte Note anfordert, versteht Orleans, welcher der Server jetzt weniger ausgelastet ist, platziert den Akteur dort und gibt das Ergebnis an den Benutzerdienst zurück.
Ein Beispiel. Für Körner ist es wichtig, nur den Typ des Akteurs zu kennen, z. B. Benutzerstatus und ID. Angenommen, Benutzer-ID 777, wir erhalten die Körnung dieses Benutzers und denken nicht darüber nach, wie diese Körnung gespeichert werden soll. Wir steuern nicht den Lebenszyklus der Körnung. Orleans jedoch speichert die Wege aller Schauspieler auf sehr listige Weise in sich. Wenn es keinen Schauspieler gibt, erstellt er sie, wenn der Schauspieler lebt, gibt er sie zurück, und für Benutzerdienste sieht alles so aus, dass alle Schauspieler immer am Leben sind.
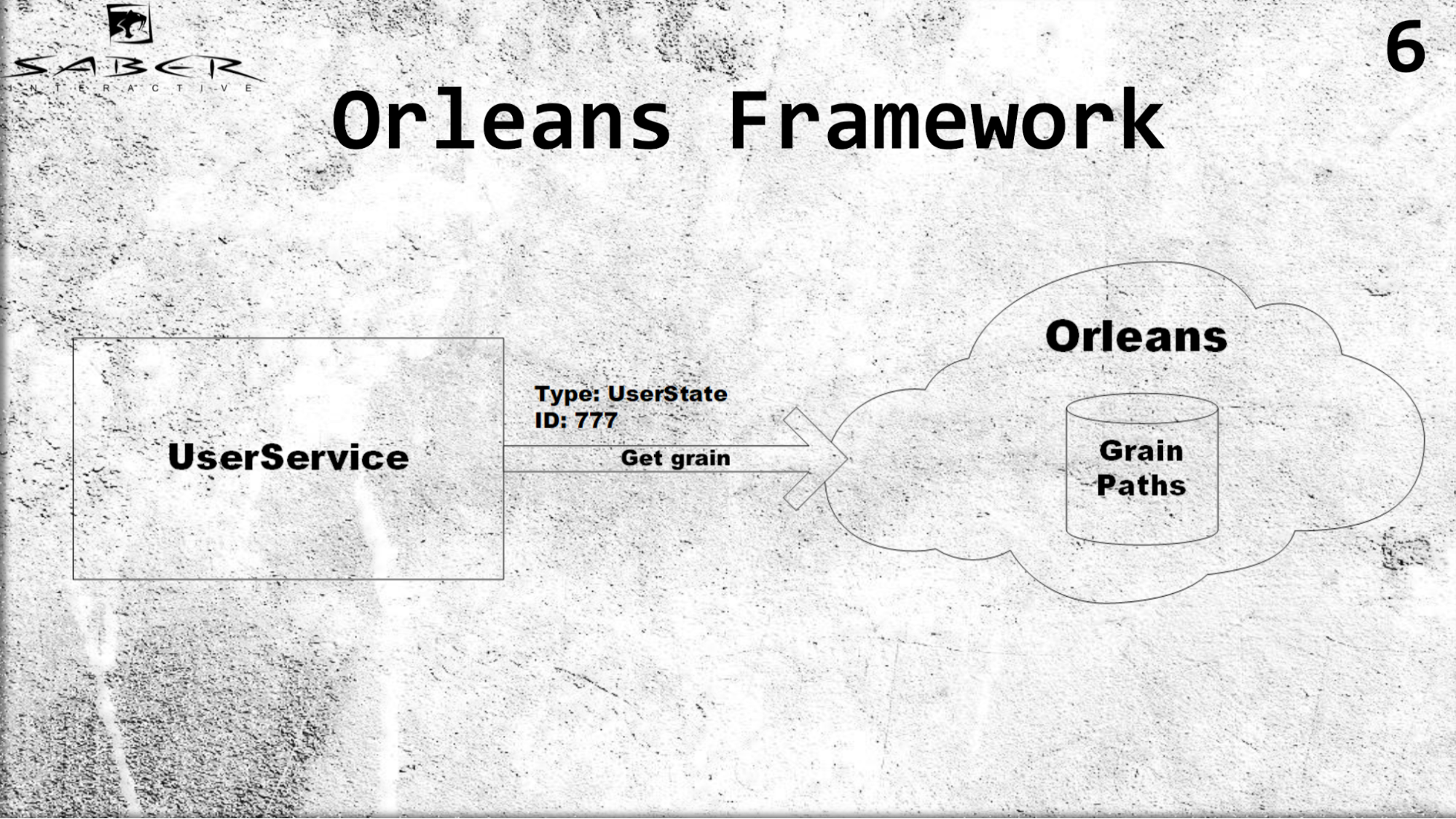
Welche Vorteile bringt uns das? Erstens transparenter Lastausgleich aufgrund der Tatsache, dass der Programmierer den Standort des Akteurs nicht selbst verwalten muss. Er sagt einfach Orleans, das auf mehreren Servern bereitgestellt wird: Geben Sie mir einen solchen Schauspieler von Ihren Servern.
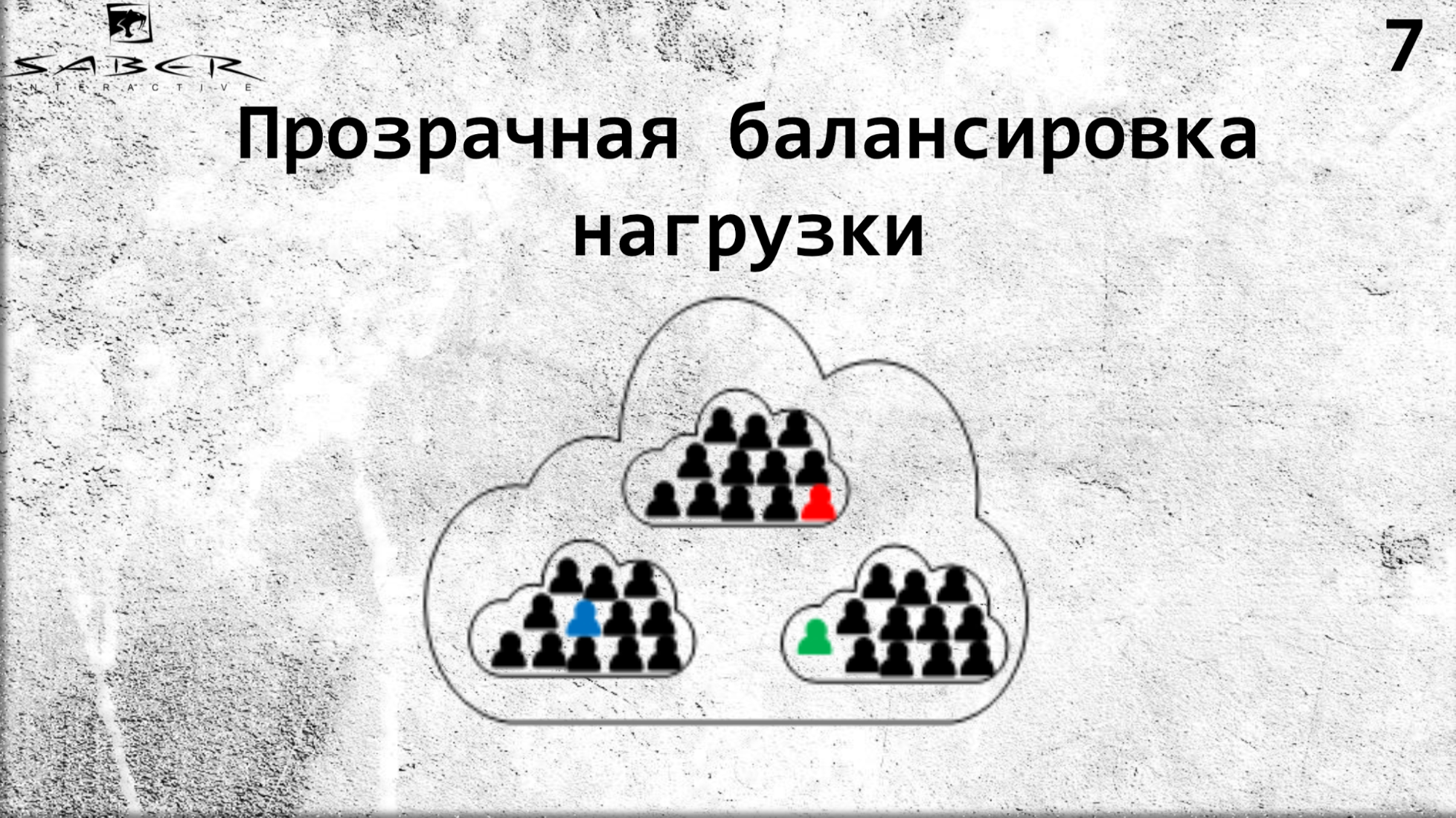
Falls gewünscht, können Sie eine Verkleinerung vornehmen, wenn die Belastung des Prozessors und des Speichers gering ist. Auch hier können Sie die Hochskalierung in die entgegengesetzte Richtung durchführen. Aber der Dienst weiß nichts darüber, er bittet um die Körnung, und Orleans gibt ihm diese Körnung. So übernimmt Orleans die infrastrukturelle Versorgung für den Lebenszyklus der Körner.
Zweitens behandelt Orleans Serverabstürze.

Dies bedeutet, dass im klassischen Modell der Programmierer für die eigenständige Behandlung eines solchen Falls verantwortlich ist (er hat den Akteur auf einem Server platziert und dieser Server ist abgestürzt, und wir müssen diesen Akteur selbst auf einem der Live-Server erhöhen), was mehr Mechanik hinzufügt oder komplexe Netzwerkarbeit für einen Programmierer, dann sieht es in Orleans transparent aus. Wir fordern eine Körnung an, Orleans sieht, dass sie nicht verfügbar ist, holt sie ab (platziert sie auf einigen Live-Servern) und gibt sie an den Dienst zurück.
Schauen wir uns zur Verdeutlichung ein kleines Beispiel an, wie ein Benutzer einen Teil seines Status liest.
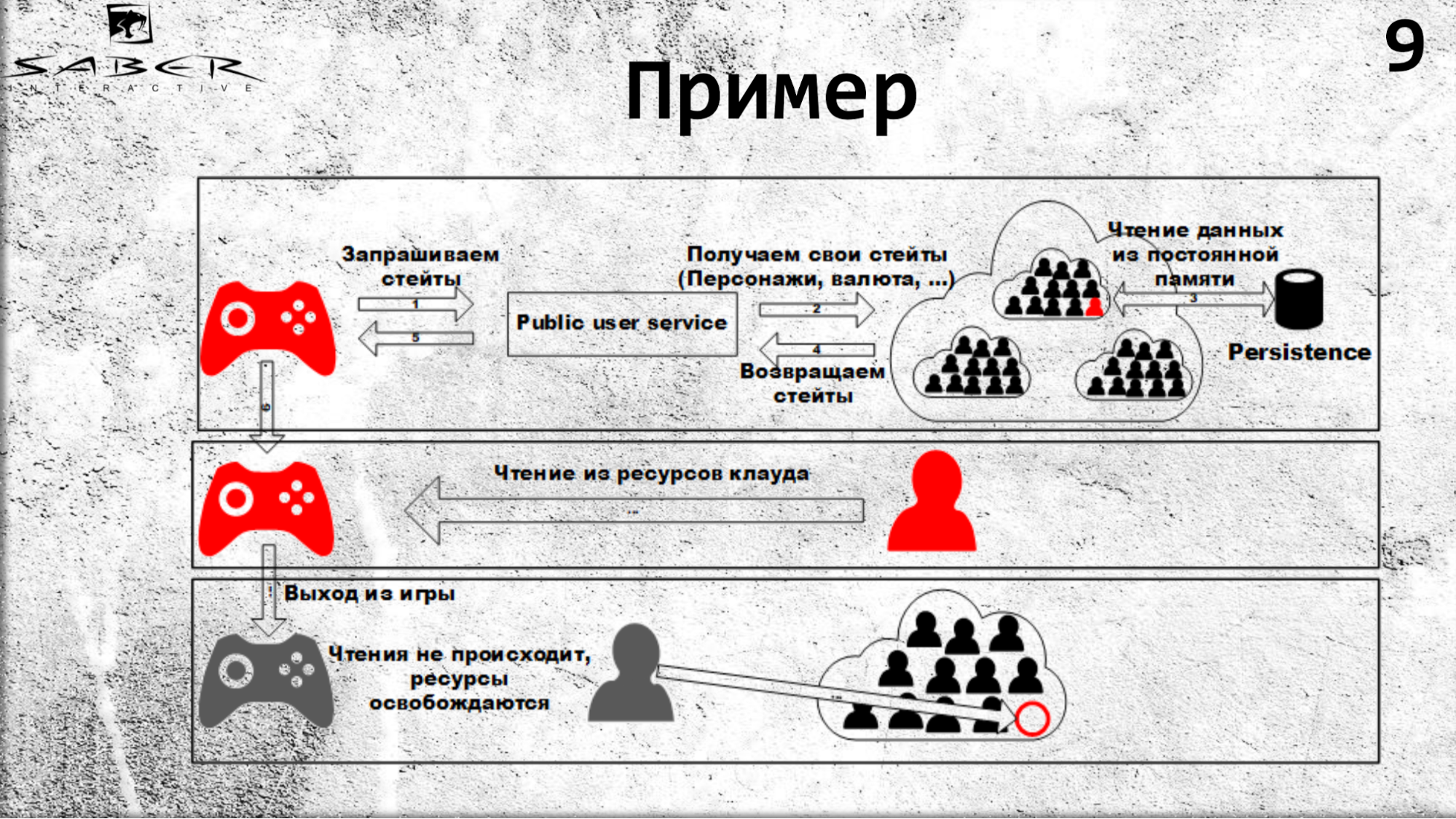
Ein Staat kann sein wirtschaftlicher Zustand sein, in dem die Rüstung, Waffen, Währung oder Champions dieses Benutzers aufbewahrt werden. Um diese Zustände zu erhalten, ruft er den PublicUserService auf, der sich für den Zustand an Orleans wendet. Was passiert: Orleans sieht, dass es noch keinen solchen Akteur (d. H. Getreide) gibt, er erstellt es auf einem freien Server und das Getreide liest seinen Zustand aus einem Persistenzspeicher.
Wenn Sie also das nächste Mal Ressourcen aus der Cloud lesen, wie auf der Folie gezeigt, werden alle Lesevorgänge aus dem Cache-Cache stammen. Für den Fall, dass der Benutzer das Spiel verlässt, werden keine Ressourcen gelesen, sodass Orleans versteht, dass das Getreide von niemandem mehr verwendet wird und deaktiviert werden kann.
Wenn wir mehrere Clients haben (Spielclient, Spielserver), können sie Benutzerstatus anfordern, und einer von ihnen erhöht diese Körnung. Genauer gesagt, Orleans wird es abholen, und dann werden alle Anrufe, wie wir bereits wissen, nacheinander threadsicher ausgeführt. Zuerst erhält der Client den Status und dann den Spieleserver.
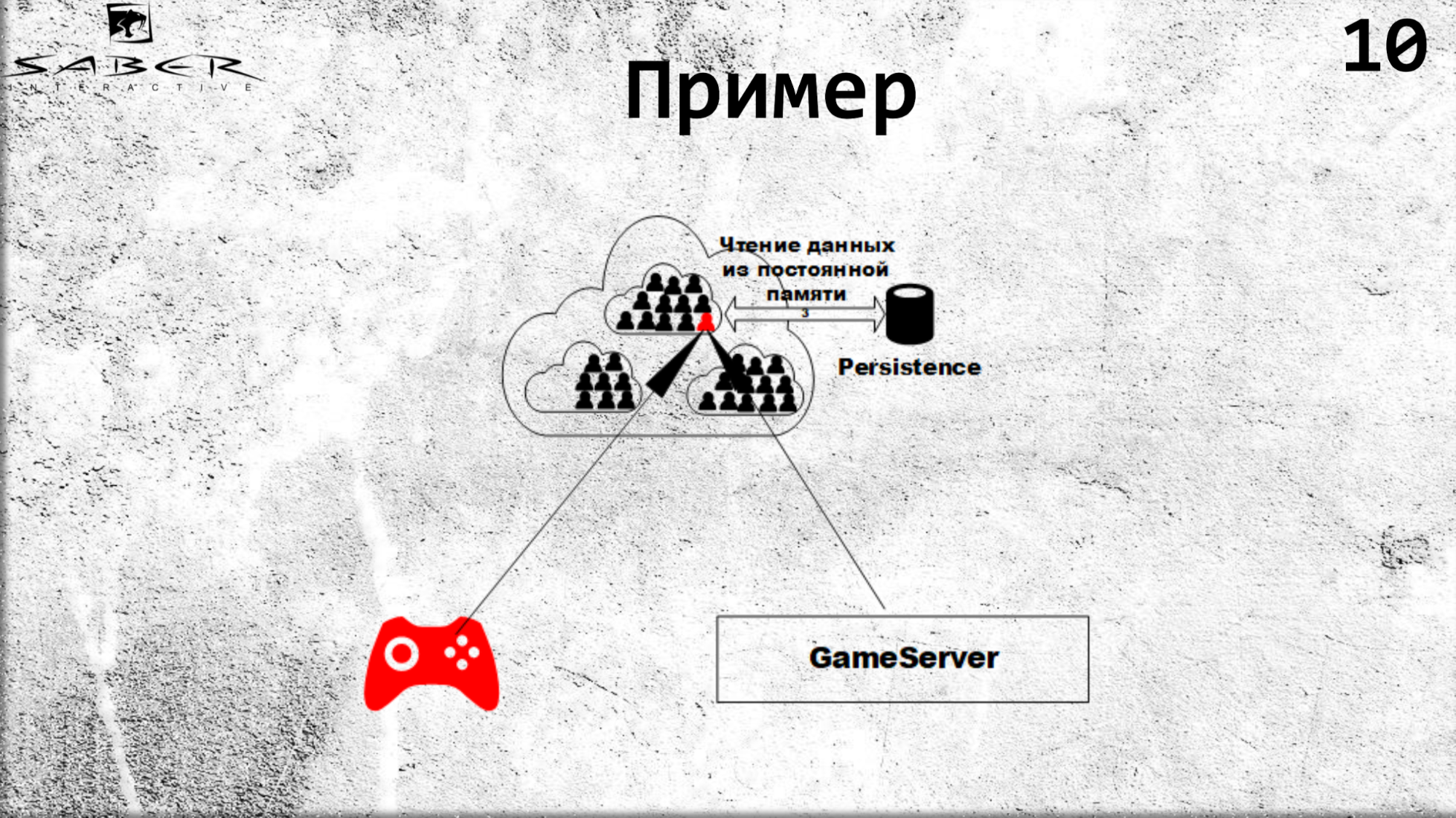
Der gleiche Ablauf beim Update. Wenn ein Client einen Status aktualisieren möchte, überträgt er diese Verantwortung auf das Korn, d. H. wird ihm sagen: "Gib diesem Benutzer 10 Gold", und das Korn steigt, es verarbeitet diesen Zustand mit einer Art Geschäftslogik innerhalb des Korns. Und dann kommt die Aktualisierung des Cache-Cache und, falls gewünscht, die Persistenz in der Persistenz.

Warum ist hier Ausdauer erforderlich? Dies ist ein separates Thema und es liegt in der Tatsache, dass es für uns manchmal nicht besonders wichtig ist, dass das Getreide seine Zustände ständig in der Persistenz beibehält. Wenn dies der Zustand des Online-Spielers ist, sind wir bereit, ihn aus Gründen der Produktivität zu verlieren. Wenn es um die Wirtschaft geht, müssen wir sicher sein, dass seine Zustände erhalten bleiben.
Der einfachste Fall: Schreiben Sie dieses Update für jeden Aufruf des Sicherungsstatus in Persistence. Wenn der Grayn plötzlich unerwartet abfällt, führt das nächste Anheben des Grayn auf einigen anderen Servern zu einer Cache-Aktualisierung mit den aktuellen Daten.
Ein kleines Beispiel, wie es aussieht.

Wie ich bereits sagte, besteht ein Korn aus einem Typ und einem Schlüssel (in diesem Fall ist der Typ IPlayerState, der Schlüssel ist IGrainWithGuidKey, was bedeutet, dass es Guid ist). Und wir haben eine Schnittstelle, die wir implementieren, d. H. GetStates gibt eine Liste von Status und ApplyState zurück, für die ein Status gilt. Orleans-Methoden geben Task zurück. Was dies bedeutet: Aufgabe ist ein Versprechen, das uns sagt, dass sich das Versprechen in einem aufgelösten Zustand befindet, wenn der Staat zurückkehrt. Wir haben auch einige PlayerState, die wir mit GrainFactory bekommen. Das heißt, Hier erhalten wir einen Link und wissen nichts über den physischen Standort dieses Getreides. Wenn Sie GetStates aufrufen, erhöht Orleans unser Korn, liest den Status aus dem Persistenzspeicher in seinen Speicher und wenn ApplyState einen neuen Status anwendet, aktualisiert es diesen Status sowohl im Speicher als auch in der Persistenz.
Ich möchte ein etwas komplexeres Beispiel für die High-Level-Architektur unseres UserStates-Dienstes ausarbeiten.
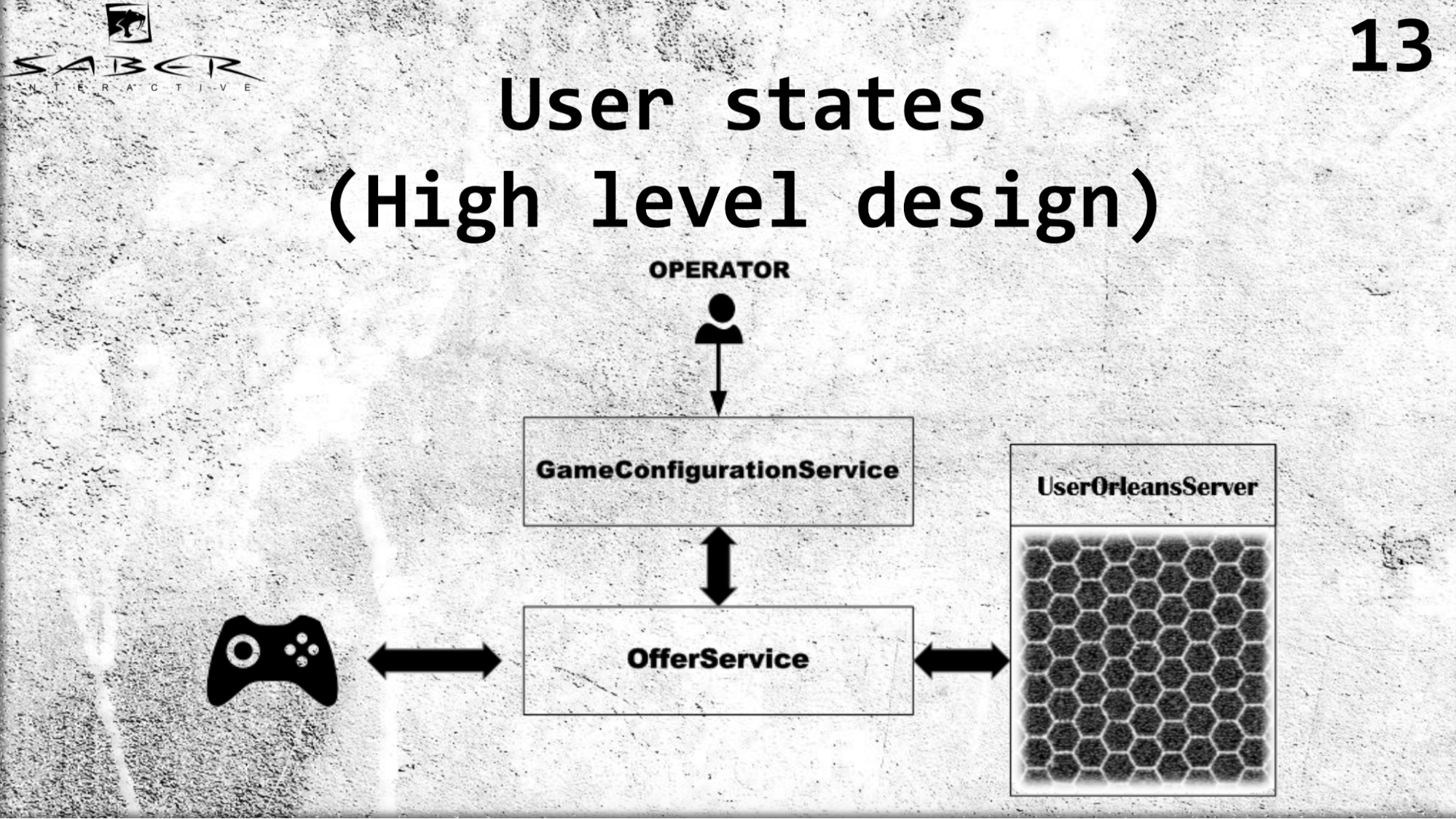
Wir haben eine Art Spieleclient, der seine Zustände über OfferSevice erhält. Wir haben einen GameConfigurationService, der für das Wirtschaftsmodell einer Benutzergruppe verantwortlich ist, in diesem Fall unseres Benutzers. Und wir haben einen Betreiber, der dieses Wirtschaftsmodell ändert. Dementsprechend fordert der Benutzer ein OfferSevice an, seinen Status zu erhalten. Und OfferSevice greift bereits auf den UserOrleans-Dienst zu, der aus diesen Körnern besteht. Es erhöht diesen Status des Benutzers in seinem Speicher, führt möglicherweise eine Art Geschäftslogik aus und gibt die Daten über OfferService an den Benutzer zurück.
Im Allgemeinen möchte ich darauf hinweisen, dass Orleans aufgrund der Tatsache, dass Körner unabhängig voneinander sind, für seine hohe Parallelitätsfähigkeit gut ist. Andererseits müssen wir innerhalb der Körnung keine Synchronisationsprimitive verwenden, da wir wissen, dass jeder Aufruf dieser Körnung irgendwie konsistent ist.
Hier möchte ich einige der Fallstricke dieses Modells erkennen.

Das erste ist zu viel Körnung. Da alle Aufrufe in der Greine nacheinander threadsicher sind und wir eine fettige Logik auf der Greine haben, müssen wir zu lange warten. Wiederum wird zu viel Speicher für ein solches Korn zugewiesen. Es gibt keinen genauen Algorithmus für die Größe des Korns, da ein zu kleines Korn auch schlecht ist. Hier ist es eher notwendig, vom optimalen Wert auszugehen. Ich werde nicht genau sagen, welches, es liegt am Programmierer zu entscheiden.
Das zweite Problem ist nicht so offensichtlich - dies ist die sogenannte Kettenreaktion. Wenn ein Benutzer einige Körner erhöht, kann er implizit andere Körner im System erhöhen. So geschieht dies: Der Benutzer erhält seinen Status, der Benutzer hat Freunde und er erhält den Status seiner Freunde. Somit behält das gesamte System alle seine Körner im Speicher, und wenn wir 1000 Benutzer haben und jeder 100 Freunde hat, können 100.000 Körner einfach so aktiv sein. Dieser Fall muss auch vermieden werden - irgendwie speichern Sie die Zustände von Freunden in einer Art gemeinsamem Speicher.

Nun, welche Technologien gibt es, um das Akteurmodell zu implementieren? Das vielleicht berühmteste ist Akka, das mit Java zu uns kam. Es gibt eine Abzweigung namens Akka.NET für .NET. Es gibt Orleans, das Open Source ist und in anderen Sprachen als Implementierung verfügbar ist. Es gibt Azure-Grundelemente wie Service Fabric Actor - es gibt viele Technologien.
Fragen aus dem Publikum
- Wie lösen Sie klassische Probleme wie CICD, aktualisieren diese Akteure, verwenden Sie Docker und wird es überhaupt benötigt?- Wir verwenden Docker noch nicht. Im Allgemeinen ist DevOps an der Bereitstellung beteiligt und stellt unsere Dienste im Azure-Clouddienst bereit.
- Kontinuierliche Aktualisierung ohne Ausfallzeiten, wie geschieht dies? Orleans selbst entscheidet, auf welchen Server der Server geht, auf welchen Server die Anfrage geht und wie dieser Dienst aktualisiert wird. Das heißt, Eine neue Geschäftslogik ist erschienen, ein Update desselben Akteurs ist erschienen - wie werden diese Updates gerollt?- Wenn wir über die Aktualisierung des gesamten Dienstes sprechen und wenn wir eine Geschäftslogik des Schauspielers aktualisiert haben, können wir einen neuen Orleans-Dienst dafür einführen. Normalerweise wird dies mit unseren Grundelementen gelöst, die als Topologie bezeichnet werden. Wir haben einen Dienst in New Orleans eingeführt, der vorerst leer und ohne Schauspieler ist. Zeigen Sie den alten Dienst an und ersetzen Sie ihn durch einen neuen. Es werden überhaupt keine Akteure im System vorhanden sein, aber bei der nächsten Benutzeranforderung werden diese Akteure bereits erstellt. Am Anfang wird es wahrscheinlich eine Art Spitze geben. In solchen Fällen findet das Update normalerweise am Morgen statt, da wir am Morgen die geringste Anzahl von Spielern haben.
"Wie versteht Orleans, dass der Server abgestürzt ist?" Sie sagten, dass er die Schauspieler schnell auf einen anderen Server wirft ...- Er hat einen Pingator, der regelmäßig versteht, welche der Server am Leben sind.
- Pingt er einen Schauspieler oder Server speziell an?- Insbesondere der Server.
- Eine solche Frage: Ein Fehler ist innerhalb des Schauspielers aufgetreten, Sie sagen, er geht Schritt für Schritt, jede Anweisung. Aber ein Fehler ist aufgetreten und was passiert mit dem Schauspieler? Angenommen, ein Fehler wird nicht verarbeitet. Stirbt der Schauspieler gerade?- Nein, Orleans löst eine Ausnahme im Standard-.NET-Schema aus.
- Schauen Sie, wir haben keine Ausnahme behandelt, der Schauspieler ist anscheinend gestorben. Dem Spieler weiß ich nicht, wie es aussehen wird, aber was passiert dann? Versuchen Sie, diesen Schauspieler irgendwie neu zu starten oder etwas anderes zu tun?- Es kommt darauf an, in welchem Fall es auf welchen Fall ankommt. Zum Beispiel retriable oder nicht retriable.
- Das heißt. Ist das alles konfigurierbar?- Eher programmiert. Wir behandeln einige Ausnahmen. Das heißt, Wir sehen deutlich, dass ein solcher Fehlercode und einige, wie nicht behandelte Ausnahmen, bereits weiter vorangetrieben werden.
- Haben Sie mehrere Persistenzen - ist es wie eine Datenbank?- Persistenz, ja, eine Datenbank mit persistentem Speicher.
- Nehmen wir an, eine Datenbank hat festgelegt, in welcher (bedingten) Spielgeld. Was passiert, wenn ein Schauspieler sie nicht erreichen kann? Wie gehst du damit um?- Zuallererst ist es Speicher. Im Moment verwenden wir Azure Table Storage, und solche Probleme treten tatsächlich auf - Speicher stürzt ab. Normalerweise müssen Sie es in diesem Fall neu konfigurieren.
- Wenn der Schauspieler etwas nicht im Speicher haben konnte, wie sieht der Spieler aus? Er hat dieses Geld einfach nicht oder schließt er das Spiel sofort?- Dies sind wichtige Änderungen für den Benutzer. Da jeder Dienst seinen eigenen Schweregrad hat, ist der Benutzerdienst in diesem Fall ein Terminalstatus und der Client stürzt einfach ab.
- Es schien mir, dass die Nachrichten der Schauspieler durch asynchrone Warteschlangen auftreten. Wie ist diese optimierte Lösung? Schwillt es nicht an, lässt es den Spieler nicht auflegen? Ist es nicht besser, einen reaktiven Ansatz zu verwenden?- Das Problem der Warteschlangen bei Schauspielern ist ziemlich bekannt, da wir die Größe der Warteschlange so eindeutig nicht kontrollieren können, dass Sie Recht haben. Aber Orleans übernimmt erstens eine Art Managementarbeit und zweitens denke ich, dass der Zugang zum Schauspieler einfach durch Timeout sinken wird, d. H. Wir können zum Beispiel den Schauspieler nicht erreichen.
- Und wie wirkt sich das auf den Spieler aus?- Da der Benutzerdienst den Akteur kontaktiert, wird eine Ausnahme-Timeout-Ausnahme ausgelöst. Wenn es sich um einen „kritischen“ Dienst handelt, gibt der Client einen Fehler aus und schließt. Und wenn es weniger kritisch ist, wird es warten.
- Das heißt. Haben Sie eine DDoS-Bedrohung? Eine große Anzahl kleiner Aktionen kann einen Spieler setzen? Nehmen wir an, jemand lädt schnell Freunde usw. ein.- Nein, es gibt einen Anforderungsbegrenzer, mit dem Sie nicht zu oft auf Dienste zugreifen können.
- Wie gehen Sie mit Datenkonsistenz um? Angenommen, wir haben zwei Benutzer, wir müssen etwas von einem nehmen und dem anderen etwas in Rechnung stellen, damit es transaktional ist.- Gute Frage. Erstens unterstützt Orleans 2.0 die Distributed Actor Transaction - dies ist die erste Version. Genauer gesagt muss bereits über die Wirtschaft gesprochen werden. Und als einfachster Weg - im letzten Orleans werden Transaktionen zwischen Akteuren problemlos durchgeführt.
- Das heißt. Weiß es bereits, wie sichergestellt werden kann, dass die Daten integer bleiben?- Ja.
Weitere Gespräche mit Pixonic DevGAMM Talks