"Einige Leute nennen uns" Plyushkins "- ich möchte sagen, dass wir Archivare sind."
Mark Graham, Director von Wayback Machine, skizziert den Umfang des Lieblingsarchivs aller
 Schauen Sie sich Wayback Machine bei der Online News Association 2018 anAustin, Texas.
Schauen Sie sich Wayback Machine bei der Online News Association 2018 anAustin, Texas. Egal wie sehr die Abonnentendienste Sie nicht davon überzeugen möchten, aber nicht alles ist auf Amazon oder Netflix zu finden. Möchten Sie zum Beispiel
das Buch von Richter Brett Cavanaugh (oder sogar deren
berüchtigtes Jahrbuch )
lesen ? Neugierig auf ein paar
Vintage-Werbeplakate ? Wie wäre es mit
der größten Sammlung tibetisch-buddhistischer Literatur der Welt ? Heute gibt es einen Ort, an dem Sie all dies tun können, und es sind nicht Google oder einige Piratenseiten, die Sie (oft) besuchen.
"Ich habe ein Regierungsvideo darüber, wie wir uns die Hände waschen oder uns auf einen Atomkrieg vorbereiten können", sagt Mark Graham, Direktor von Wayback Machine im Internetarchiv. "Mit der .mil-Domain" Military Industrial PowerPoint Complex "können wir problemlos eine Liste von PPT-Dateien auf allen Websites erstellen."
Graham sprach kürzlich mit mehreren kleinen Gruppen von Teilnehmern an der Konferenz der Online News Association 2018, und Ars Technica hatte das Glück, dort zu sein. Später präsentierte er die Konferenz vollständig, die jetzt
im Audioformat verfügbar ist . Und die Grundidee ist, dass der Umfang des Internetarchivs heute genauso schwer zu verstehen sein kann wie der Umfang des Internets selbst.
Der gemeinnützige physische Raum ist immer noch leicht zu verstehen, zumindest wollte Graham das so. Heute werden alle Aktivitäten des Internetarchivs von einer alten Kirche (sogar die Bänke wurden nicht entfernt) in San Francisco von ungefähr zweihundert Personen ausgeführt. Das Archiv enthält auch das nächstgelegene Lager für die Aufbewahrung physischer Medien, nicht nur Bücher, sondern auch Dinge wie Schallplatten. Graham scherzt, dass dort die Hauptmaßeinheit der "Container für die Lieferung" ist. Das Archiv erhält diese Materialmenge alle zwei Wochen.
Das Unternehmen ist derzeit nach Google der zweitgrößte Buchscanner der Welt. Graham hat dafür gesorgt, dass die aktuelle Anzahl der Scans mehr als vier Millionen betrug. Das Archiv hat sogar eine Wunschliste für die nächsten 1,5 Millionen Scans, einschließlich allem, was auf Wikipedia zitiert wird. Die Wayback-Maschine versucht, Sie davor zu schützen, dass beim Klicken auf Links aus Wikipedia ein
404-Fehler auftritt (Graham teilte der BBC kürzlich mit, dass Wayback-Bots fast sechs Millionen Seiten wiederhergestellt haben, die aufgrund eines Linkfehlers verloren gegangen sind). Heute können Bücher, die vor 1923 veröffentlicht wurden, kostenlos über das Internetarchiv heruntergeladen werden. Sie können später eine digitale Kopie vieler dieser Bücher ausleihen.
Tweet Übersetzung:
Internetarchiv: Über 9 Millionen Wikipedia Falsche Links behoben
WikiResearch: So dankbar für die außergewöhnliche Arbeit, die unsere Freunde bei @internetarchive leisten, um den 404-Fehler zu beheben und Millionen von Links zu Websites und Quellen, die von Wikipedianern zitiert werden, digital zu speichern, während sie die weltweit größte Enzyklopädie erstellen.
Natürlich bietet das Internetarchiv heutzutage viel mehr als nur Text. Seine Nachrichtensammlung umfasst mehr als 1,6 Millionen Nachrichtensendungen mit Tools wie der Suche nach Wörtern in Bildunterschriften und dem Zugriff auf die neuesten Nachrichten (Sendungen sind nach 24 Stunden verfügbar und werden den Besuchern in Form von zweiminütigen durchsuchbaren Passagen zur Verfügung gestellt). Der wachsende Audio- und Musikanteil des Internetarchivs umfasst Radio-Nachrichten, Podcasts und physische Medien (z. B. eine Sammlung von
200.000 Exemplaren der 78er, die kürzlich von der Bostoner Bibliothek gespendet wurden). Und wie Ars schreibt, verfügt die Organisation über
eine umfangreiche klassische Sammlung von Videospielen , die jeder zur Recherche oder Entspannung in einen browserbasierten Emulator hochladen kann. Offiziell enthält dieser Abschnitt mehr als 300.000 Titel. „Sie können also Oregon Trail jetzt auf Ihrem alten Apple C-Computer in Ihrem Browser spielen - keine Werbung, keine Benutzerverfolgung“, sagt Graham.
"Einige nennen uns vielleicht Plyushkins", sagt er. "Ich möchte sagen, dass wir Archivare sind."
Im Allgemeinen werden laut Graham vier Petabyte an Informationen pro Jahr zum Internetarchiv hinzugefügt (das sind vier Millionen Gigabyte für den Kontext). Die aktuellen Organisationsdaten sind 22 Petabyte, aber das Internetarchiv besitzt tatsächlich 44 Petabyte. "Weil wir paranoid sind", sagt Graham. "Autos können versagen, und wir haben einen guten Ruf." Dieses von der
NASA inspirierte Credo half einer gemeinnützigen Organisation, den durch Feuer verursachten Schaden zu überleben, der
fast 600.000 US-Dollar kostete - alles ohne Verlust von Archivdaten.
 30.000 Input? Nicht schlecht, und es scheint, dass Wayback Machine-Bots ihre Zuneigung zu Ars sicherlich erhöht haben.
30.000 Input? Nicht schlecht, und es scheint, dass Wayback Machine-Bots ihre Zuneigung zu Ars sicherlich erhöht haben. Mit der Wayback-Maschine können Sie sich daran erinnern und darüber nachdenken, wie Ars den Tod von Steve Jobs im Oktober 2011 versteckt hat.
Mit der Wayback-Maschine können Sie sich daran erinnern und darüber nachdenken, wie Ars den Tod von Steve Jobs im Oktober 2011 versteckt hat.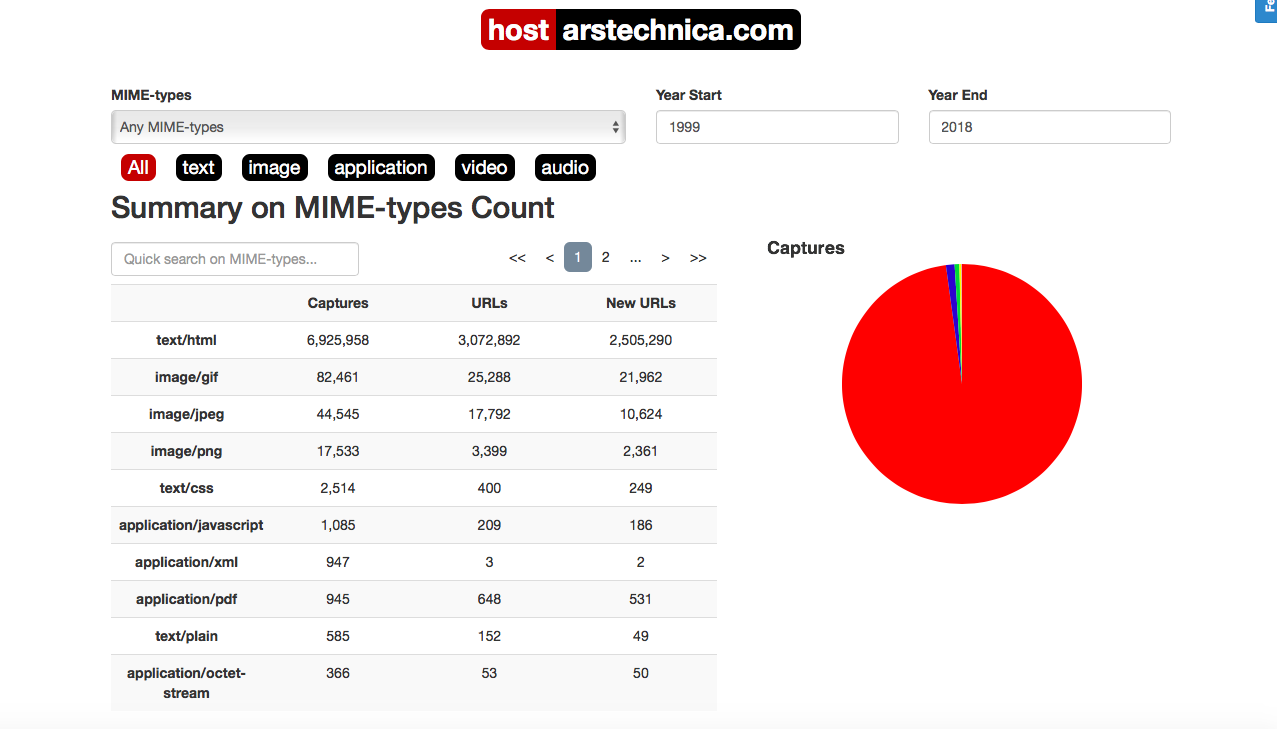 Hmm ... vielleicht habe ich noch die Chance, Arsianer / Arsianer zu werden, um das 1000. PDF herunterzuladen, das vom Internetarchiv erfasst wurde.
Hmm ... vielleicht habe ich noch die Chance, Arsianer / Arsianer zu werden, um das 1000. PDF herunterzuladen, das vom Internetarchiv erfasst wurde.Universeller Zugang zu Wissen (und zu Fakten, zu einer Vielzahl von Fakten)
Das allgemeine Konzept des Internetarchivs war in den letzten 22 Jahren einfach:
"Universeller Zugang zu allem Wissen". Im Zeitalter des Internets bedeutet dies natürlich die Einführung einer kleinen Armee von Bots, und Graham stellt fest, dass das Internetarchiv immer über Software verfügt, die Inhalte sammelt. Ungefähr 7.000 gleichzeitige Prozesse erstrecken sich über das gesamte Netzwerk, um letztendlich 1,5 Milliarden verschiedene Artikel pro Woche zu erhalten. Einige Dinge, wie die Google-Startseite oder die New York Times, können mehrmals am Tag angezeigt werden. andere können weniger häufig angezeigt werden.
"Wir versuchen, alles zu bekommen, aber es ist schwer", bemerkt Graham. "Einbettungen, Javascripts, interaktive Anwendungen - wir können einige dieser Materialien nicht bekommen, aber wir arbeiten daran."
Der Cache der Dinge, an denen wir arbeiten, umfasst kurzlebige Medien wie öffentliche Gruppen wie Snapchat oder Telegramm, und die Wayback-Maschine unterhält lokale Kontakte an Orten, an denen einige Medienarchive oder Server gefährdet sein könnten (Graham stellt kürzlich fest, dass Partner in Ägypten zum Beispiel).
Das Ergebnis all dessen ist, dass die Wayback-Maschine zu etwas viel Nützlicherem geworden ist als nur die lustigen vergangenen Reisen zu LiveJournals. Ars hat es viele Male für eine Vielzahl von Zwecken verwendet, von der
Erfassung von Änderungen in der Netzneutralität von
Comcast bis zur Tatsache, dass sich die Organisationsbeschreibung von Defense Distributed weiterentwickelt hat. Und Graham weist auf eine jüngste
Kontroverse im Jahr 2018 hin, als Präsident Trump auf seiner Homepage (wie in der Vergangenheit) twitterte, dass Google keine guten Beziehungen zu den Vereinigten Staaten von Amerika fördert. Bevor Google dies beantworten konnte, wandte sich das Unternehmen mit einer einfachen Frage an das Internetarchiv. Gibt es eine Kopie?
"Ich liebe Google, aber ihre Aufgabe ist es nicht, alle 10 Minuten Kopien der Startseite zu erstellen", sagt Graham. "Das ist unser Job."
Graham teilte mit, dass Wayback Machine im Januar 2018 tatsächlich 835 Exemplare der Google-Startseite beschlagnahmt habe. „Auf diese Weise konnten wir helfen, die Unterlagen aufzunehmen. Wir vertreten keine Partei, aber wir sind für die Wahrheit. “
Die Website spielte eine ähnliche Rolle, als das Weiße Haus kürzlich
alle Archive seiner Newsletter löschte und eine Reihe von Organisationen (nicht nur Nachrichtenorganisationen, sondern auch Umweltorganisationen oder ACLUs) diese benötigten. Und Materialien, die von Wayback Machine erhalten
wurden, wurden vor Gericht als Beweismittel verwendet . „Es gibt viele zeitliche Ereignisse“, fügt er hinzu. Als ehemaliger Vizepräsident von NBC News (daher vielleicht sein Wunsch, an der ONA teilzunehmen) weist Graham auch stolz darauf hin, dass die Medien etwa fünfmal täglich auf die Website verweisen.
Laut Graham arbeitet Wayback Machine hart daran, seine Benutzerwerkzeuge zu verbessern, um die Website zu verbessern. Unten links auf der Homepage von Wayback Machine finden Sie beispielsweise
öffentliche APIs . Graham weist darauf hin, dass die Leute sie verwenden, um Dinge wie ein
Unterscheidungsmerkmal zu erstellen, bei dem Sie zwei Scans durchführen, sie nebeneinander platzieren und die Änderungen sehen können. Mit einem anderen vom Benutzer erstellten Tool, das seine Aufmerksamkeit auf sich gezogen hat, können Sie die Site betrachten und ein
radiales Baumdiagramm erstellen, um zu sehen, wie sich ihre Struktur im Laufe der Zeit ändert .
Obwohl die Technologie direkt von Wayback Machine das einfachste und effektivste Tool für alle ist, ermöglicht die Website jemandem, manuell einen Link zum Internetarchiv zu senden, um sie direkt von seiner Homepage aus zu archivieren. „Wenn ich mit meiner Katze im Garten spazieren gehe und eine Geschichte in Google News sehe, können Sie sie ausdrucken. Heute können Sie es aber auch an das Internetarchiv senden “, sagt Graham. Nach seinen Schätzungen kann das Ergebnis etwa eine Million Schüsse pro Woche sein.
"Wir suchen Informationen in einem wirklich großen Netzwerk, ohne zu schummeln", sagt er. Und unabhängig davon, ob Bots oder ein engagierter Amateurbenutzer des Archivs etwas finden, kann jeder andere die Fähigkeit schätzen, Inhalte zu finden, was übrigens die
ursprüngliche Mission von Ars Technica ist . (Glücklicherweise hat uns nach 20 Jahren noch niemand über "
sehr schlechte Dinge wie NT-, Linux- und BeOS-Inhalte unter einem Dach" informiert.)
Übersetzung: Diana Sheremyova

Über #philtech#philtech (Technologien + Philanthropie) sind offene, öffentlich beschriebene Technologien, die den Lebensstandard so vieler Menschen wie möglich verbessern, indem sie transparente Plattformen für die Interaktion und den Zugang zu Daten und Wissen schaffen. Und die Prinzipien von Filtech erfüllen:
1. Offen und repliziert, nicht wettbewerbsfähig.
2. Aufbauend auf den Prinzipien der Selbstorganisation und der horizontalen Interaktion.
3. Nachhaltig und perspektivisch, anstatt lokale Vorteile zu verfolgen.
4. Aufbauend auf [offenen] Daten, nicht auf Traditionen und Überzeugungen
5. Gewaltfrei und nicht manipulativ.
6. Inklusive und nicht für eine Gruppe von Menschen auf Kosten anderer arbeiten.
PhilTech Accelerator of Social Technology Startups ist ein Programm zur intensiven Entwicklung von Frühphasenprojekten, die darauf abzielen, den Zugang zu Informationen, Ressourcen und Chancen auszugleichen. Der zweite Strom: März - Juni 2018.
Chatten Sie im TelegrammEine Gemeinschaft von Menschen, die Filtech-Projekte entwickeln oder sich einfach nur für das Thema Technologie für den sozialen Sektor interessieren.
#philtech NachrichtenTelegrammkanal mit Nachrichten über Projekte in der # Philtech-Ideologie und Links zu nützlichen Materialien.
Abonnieren Sie den wöchentlichen Newsletter