Der Yandex-Geschwindigkeitsbefehl optimiert die Suchergebnisse manuell. Es blind zu machen ist schwierig und oft einfach nutzlos. Daher baute das Unternehmen eine Infrastruktur zum Sammeln von Metriken, Testen der Geschwindigkeit und Analysieren der Daten auf.
Der Entwickler der Yandex-Schnittstellen
Andrei Prokopyuk (
Andre_487 )
weiß, welche Metriken verwendet werden sollen und wie alles optimiert werden kann.

Das Material basiert auf
Andreys Rede auf der
HolyJS- Konferenz. Unter dem Schnitt - und Video und einer Textversion des Berichts.
Zusätzlich zu diesem Bericht über Online-Messungen gibt es einen Bericht von Alexei Kalmakov (ebenfalls von Yandex) über Offline-Messungen. In seinem Fall gibt es keine Textversion, aber ein Video ist verfügbar.
Yandex-Suchergebnisse bestehen aus vielen verschiedenen Blöcken, Klassen von Antworten auf Benutzeranfragen. Im Unternehmen arbeiten mehr als 50 Mitarbeiter an ihnen, und damit die Emissionsrate nicht sinkt, kümmern wir uns ständig um die Entwicklung.
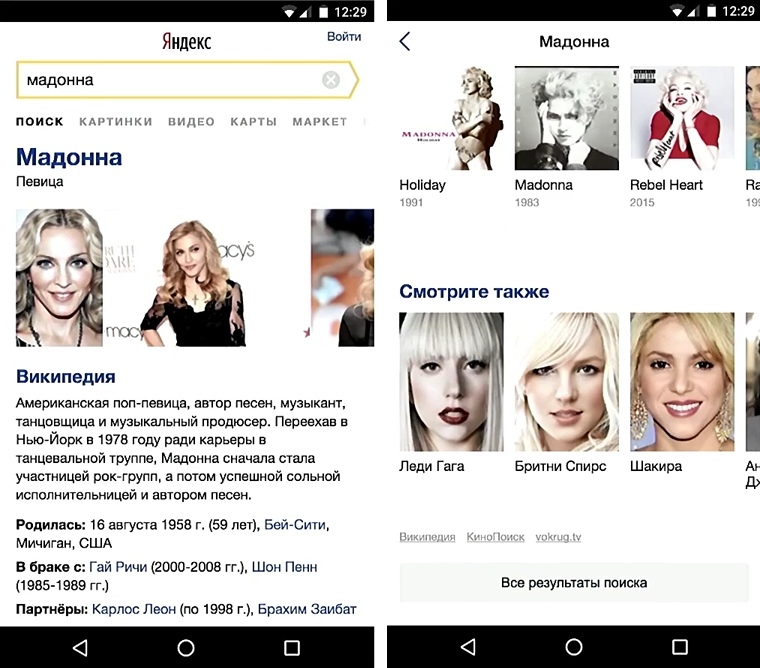
Niemand wird argumentieren, dass Benutzer die schnelle Oberfläche mehr mögen als die langsame. Bevor Sie jedoch mit der Optimierung beginnen, ist es wichtig zu verstehen, wie sich dies auf Ihr Unternehmen auswirkt. Müssen Entwickler Zeit damit verbringen, die Benutzeroberfläche zu beschleunigen, wenn dies keine Auswirkungen auf die Geschäftsmetriken hat?
Um diese Frage zu beantworten, werde ich zwei Geschichten erzählen.
Verlauf der Einführung einer bestimmten Webschriftart bei der Ausgabe
Nachdem wir ein Experiment mit Schriftarten durchgeführt hatten, stellten wir fest, dass sich die durchschnittliche Zeit für das Rendern von Inhalten um 3% und 62 Millisekunden verschlechterte. Nicht so sehr, wenn man es für ein Delta im Vakuum hält. Die mit bloßem Auge wahrnehmbare Verzögerung beginnt mit nur 100 Millisekunden - und dennoch erhöht sich die Zeit bis zum ersten Klick sofort um eineinhalb Prozent.

Benutzer begannen später mit der Seite zu interagieren. Die Anzahl der angeklickten Seiten verringerte sich um fast ein halbes Prozent. Die Anwesenheitszeit im Dienst wurde verkürzt und die Abwesenheitszeit verlängert.

Wir haben nicht damit begonnen, Funktionen mit Schriftarten einzuführen. Immerhin scheinen diese Zahlen klein zu sein, bis Sie sich an den Umfang des Dienstes erinnern. In Wirklichkeit eineinhalb Prozent - Hunderttausende von Menschen.
Darüber hinaus wirkt sich die Geschwindigkeit kumulativ aus. Für ein Update mit einem Anteil von nicht beanspruchten - 0,4% werden immer mehr folgen. In Yandex werden solche Funktionen in Dutzenden pro Tag eingeführt. Wenn Sie nicht um jede Aktie kämpfen, hält sie nicht lange an und erreicht 10%.
LS Caching-Verlauf
Diese Geschichte hängt mit der Tatsache zusammen, dass wir viele statische Inhalte in die Seite einbinden.
Aufgrund seiner hohen Variabilität können wir es nicht zu einem Bundle zusammenstellen oder mit externen Ressourcen ausliefern. Die Praxis hat gezeigt, dass bei der Inline-Bereitstellung das Rendern und Initialisieren von JavaScript am schnellsten ist.
Einmal entschieden wir, dass die Verwendung eines Browser-Repositorys eine gute Idee wäre. Fügen Sie alles in localStorage ein und laden Sie es bei nachfolgenden Einträgen auf der Seite von dort und übertragen Sie es nicht über das Netzwerk.
Dann haben wir uns hauptsächlich auf die Metriken „HTML-Größe“ und „HTML-Lieferzeit“ konzentriert und gute Ergebnisse erzielt. Im Laufe der Zeit haben wir neue Methoden zur Geschwindigkeitsmessung erfunden, Erfahrungen gesammelt und beschlossen, diese zu überprüfen, ein umgekehrtes Experiment durchzuführen und die Optimierung auszuschalten.

Die durchschnittliche HTML-Lieferzeit (die Schlüsselmetrik zum Zeitpunkt der Optimierungsentwicklung) stieg um 12%, was sehr viel ist. Gleichzeitig jedoch die Zeit bis zum Zeichnen des Headers, bevor das Parsen des Inhalts begann und bevor JavaScript initialisiert wurde. Reduzierte auch die Zeit bis zum ersten Klick. Der Prozentsatz ist klein - 0,6, aber wenn Sie sich an die Skala erinnern ...

Durch das Deaktivieren der Optimierung wurde eine Verschlechterung der Metrik erzielt, die nur für Spezialisten spürbar ist, und gleichzeitig eine Verbesserung, die für den Benutzer spürbar ist.
Daraus lassen sich folgende Schlussfolgerungen ziehen:
Erstens wirkt sich die Geschwindigkeit wirklich auf das Geschäft und die Geschäftsmetriken aus.
Zweitens müssen Optimierungen Messungen vorausgehen. Wenn Sie etwas implementieren, nachdem Sie schlechte Messungen durchgeführt haben, werden Sie wahrscheinlich nichts Nützliches tun. Die Zusammensetzung des Publikums, die Geräteflotte, Interaktionsszenarien und Netzwerke sind überall unterschiedlich, und Sie müssen überprüfen, was genau für Sie funktioniert.
Einmal lehrte uns Ash von den finsteren Toten, zuerst zu schießen, dann zu denken oder überhaupt nicht zu denken. Bei der Geschwindigkeit müssen Sie dies nicht tun.
Und der dritte Punkt: Messungen sollten die Benutzererfahrung widerspiegeln. Beispielsweise sind HTML-Größe und Lieferzeit schlechte Geschwindigkeitsmetriken, da der Benutzer nicht mit devTools zusammenarbeitet und keinen Dienst mit weniger Verzögerung auswählt. Aber welche Metriken gut und richtig sind - wir werden weiter erzählen.
Was und wie messen?
Messungen sollten mit einigen wichtigen Metriken beginnen, die im Gegensatz zur HTML-Größe der Benutzererfahrung nahe kommen.

Wenn TTFCP (Zeit bis zum ersten inhaltlichen Malen) und TTFMP (Zeit bis zum ersten sinnvollen Malen) die Zeit bis zum ersten Rendern des Inhalts und die Zeit vor dem Rendern des signifikanten Inhalts angeben, ist die dritte Zeit die Zeit vor dem Initialisieren des Frameworks.
Dies ist die Zeit, in der das Framework die Seite bereits durchlaufen, alle erforderlichen Daten gesammelt und die Handler aufgehängt hat. Wenn der Benutzer in diesem Moment irgendwo klickt, erhält er eine dynamische Antwort.
Und die letzte, vierte Metrik, die Zeit bis zur ersten Interaktivität, wird normalerweise als Zeit bis zur Interaktivität (TTI) bezeichnet.
Diese Metriken liegen im Gegensatz zur HTML-Größe oder Lieferzeit nahe an der Benutzererfahrung.
Zeit, zuerst zufrieden zu malen
Um die Zeit zu messen, zu der der Benutzer den ersten Inhalt der Seite gesehen hat, gibt es eine Paint Timing-API, die bisher nur in Chrom verfügbar ist. Daten daraus können auf folgende Weise erhalten werden.

Mit diesem Aufruf erhalten wir eine Reihe von Rendering-Ereignissen. Bisher werden zwei Arten von Ereignissen unterstützt: Erstes Malen - ein beliebiges Rendern und ein erstes inhaltliches Malen - ein beliebiges Rendern von Inhalten außer dem weißen Hintergrund der leeren Registerkarte und dem Hintergrundinhalt der Seite.
So erhalten wir eine Reihe von Ereignissen, filtern zuerst die gesamte Farbe und senden sie mit einer bestimmten ID.
Zeit für die erste sinnvolle Farbe
In der Paint Timing-API gibt es kein Ereignis, das signalisiert, dass auf der Seite signifikante Inhalte gerendert wurden. Dies liegt an der Tatsache, dass solche Inhalte auf jeder Seite unterschiedlich sind. Wenn es sich um einen Videodienst handelt, ist der Player in den Suchergebnissen die Hauptsache - das erste nicht werbliche Ergebnis. Es gibt viele Dienste, und eine universelle API wurde noch nicht entwickelt. Aber hier kommen gute, bewährte Krücken ins Spiel.
In Yandex gibt es zwei Krückenschulen zum Messen dieser Metrik: Verwenden von RequestAnimationFrame und Messen mit InterceptionObserver.
In RequestAnimationFrame wird das Rendern anhand eines Intervalls gemessen.

Angenommen, es gibt einige wichtige Inhalte. Hier ist ein Div mit Hauptinhalt der Klasse. Davor wird ein Skript platziert, in dem RequestAnimationFrame zweimal aufgerufen wird.
Schreiben Sie im Rückruf des ersten Aufrufs die untere Grenze des Intervalls. Im Rückruf des zweiten - der Spitze. Dies liegt an der Rahmenstruktur, die der Browser rendert.

Das erste ist die Ausführung von JavaScript, dann die Analyse von Stilen, dann die Berechnung von Layout, Rendering und Komposition.
Callback, das RequestAnimationFrame aufruft, wird im selben Stadium wie JavaScript aktiviert und der Inhalt wird während der Komposition im letzten Abschnitt des Frames gerendert. Daher erhalten wir beim ersten Aufruf nur die untere Grenze, die zeitlich merklich von der Ausgabe der Pixel auf dem Bildschirm entfernt wird.
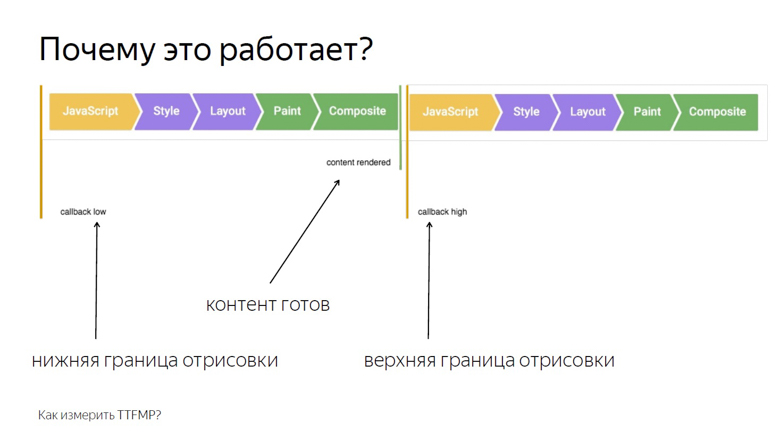
Platzieren Sie zwei Rahmen nebeneinander. Es ist zu sehen, dass am Ende des ersten der Inhalt gerendert wurde. Wir schreiben den unteren Rand von RequestAnimationFrame auf, der im ersten Rückruf aufgerufen wird, und rufen den Rückruf im zweiten Rahmen auf. Somit erhalten wir das Intervall von JavaScript, das in dem Frame aufgerufen wird, in dem der Inhalt im zweiten Frame in JavaScript gerendert wurde.
InterceptionObserver
Unsere zweite Krücke mit dem gleichen Inhalt funktioniert anders. Dieses Mal ist das Skript unten platziert. Darin erstellen wir InterceptionObserver und abonnieren domNode.

Wir übergeben keine zusätzlichen Parameter und messen daher den Schnittpunkt mit dem Ansichtsfenster. Diese Zeit wird als genaue Zeit des Renderns aufgezeichnet.
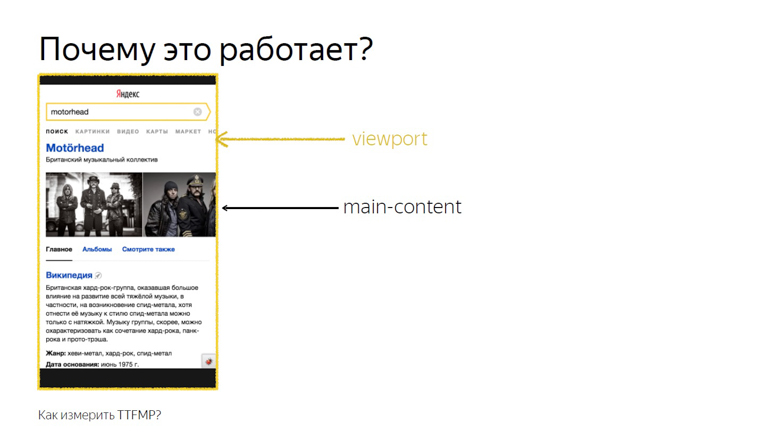
Dies funktioniert, da der Schnittpunkt des Hauptinhalts und des Ansichtsfensters genau der Schnittpunkt ist, den der Benutzer sieht. Diese API wurde entwickelt, um genau zu wissen, wann ein Nutzer eine Anzeige gesehen hat. Unsere Untersuchungen haben jedoch gezeigt, dass dies auch für Nicht-Anzeigenblöcke funktioniert.
Von diesen beiden Methoden ist es immer noch besser, RequestAnimationFrame zu verwenden: Die Unterstützung ist breiter und es wird von uns in der Praxis besser getestet.
Js inited
Stellen Sie sich ein Framework vor, das eine Art „Init“ -Ereignis enthält, das Sie abonnieren können. Denken Sie jedoch daran, dass JS Inited in der Praxis sowohl eine einfache als auch eine komplexe Metrik ist.

Einfach - weil Sie nur den Moment finden müssen, in dem das Framework die Anordnung der Ereignisse abgeschlossen hat. Komplex - weil Sie diesen Punkt für jedes Framework selbst suchen müssen.
Zeit für interaktive
TTI wird oft mit der vorherigen Metrik verwechselt, ist jedoch ein Indikator für den Moment, in dem der Hauptstrom des Browsers freigegeben wird. Während des Ladens von Seiten werden viele Aufgaben ausgeführt: vom Rendern verschiedener Elemente bis zur Initialisierung des Frameworks. Erst wenn es entladen ist, kommt die Zeit für die erste Interaktivität.
Das Konzept der langen Aufgaben und die API für lange Aufgaben helfen dabei, dies zu messen.
Zunächst zu den langen Aufgaben.

Zwischen den kurzen Aufgaben, die durch Pfeile angezeigt werden, kann der Browser die Verarbeitung eines Benutzerereignisses, z. B. der Eingabe, leicht überfüllen, da es eine hohe Priorität hat. Bei den langen Aufgaben, die durch die roten Pfeile angezeigt werden, funktioniert dies jedoch nicht.
Der Benutzer muss warten, bis er aufgebraucht ist, und erst, nachdem der Browser die Verarbeitung seiner Eingabe aktiviert hat. Gleichzeitig kann das Framework bereits initialisiert werden und die Schaltflächen funktionieren langsam. Eine solche verzögerte Antwort ist eine ziemlich unangenehme Benutzererfahrung. In dem Moment, in dem die letzte lange Aufgabe abgeschlossen ist und der Thread lange Zeit leer ist, beträgt die Abbildung 7 Sekunden und 300 Millisekunden.
Wie messe ich dieses Intervall in JavaScript?

Der erste Schritt wird bedingt als öffnendes Body-Tag bezeichnet, worauf das Skript folgt. Dadurch wird ein PerformanceObserver erstellt, der das Long Task-Ereignis abonniert. Innerhalb des Callback PerformanceObservers werden Ereignisinformationen in einem Array gesammelt.

Nach dem Sammeln der Daten ist die Zeit für den zweiten Schritt gekommen. Es wird bedingt als schließende Körpermarke bezeichnet. Wir nehmen das letzte Element des Arrays, die letzte lange Aufgabe, schauen uns den Moment seiner Fertigstellung an und prüfen, ob genügend Zeit vergangen ist.
In der ursprünglichen Arbeit an dieser Metrik wurden 5 Sekunden als Konstante angenommen, aber die Auswahl wurde in keiner Weise begründet. Es stellte sich heraus, dass es für 3 Sekunden ausreichte. Wenn 3 Sekunden vergehen, zählen wir die Zeit bis zur ersten Interaktivität. Wenn nicht, setzen wir Timeout und überprüfen diese Konstante erneut.
Wie verarbeite ich die Daten?
Daten müssen von Kunden empfangen, verarbeitet und auf bequeme Weise präsentiert werden. Unser Konzept, Daten zu senden, ist recht einfach. Es wird ein Zähler genannt.
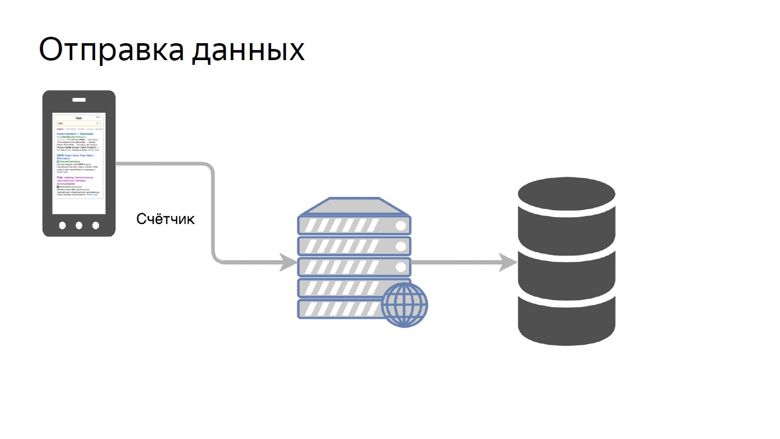
Wir übertragen die Daten einer bestimmten Metrik auf einen speziellen Stift im Backend und sammeln sie im Repository.

Hier wird die Datenaggregation üblicherweise als SQL-Abfrage bezeichnet. Hier sind die Hauptaggregationen, die wir normalerweise anhand von Geschwindigkeitsmetriken berücksichtigen: arithmetisches Mittel und Perzentilgruppe (50., 75., 95., 99.).

Der arithmetische Durchschnitt in unserer numerischen Reihe beträgt fast 1900. Er ist deutlich größer als die meisten Elemente der Menge, da diese Aggregation sehr empfindlich gegenüber Ausreißern ist. Diese Eigenschaft ist für uns immer noch nützlich.

Um Perzentile für denselben Satz zu berechnen, sortieren Sie ihn und setzen Sie den Zeiger auf den Perzentilindex. Nehmen wir den 50., der auch als Median bezeichnet wird. Wir fallen zwischen die Elemente. In diesem Fall können Sie auf unterschiedliche Weise aus der Situation herauskommen. Wir berechnen den Durchschnitt zwischen ihnen. Wir erhalten 150. Im Vergleich zum arithmetischen Durchschnitt ist deutlich zu erkennen, dass die Perzentile unempfindlich gegenüber Ausreißern sind.
Wir berücksichtigen und nutzen diese Merkmale von Aggregationen. Die arithmetische Empfindlichkeit von Emissionen ist ein Nachteil, wenn Sie versuchen, die Benutzererfahrung damit zu bewerten. In der Tat kann ein Benutzer immer eine Verbindung zum Netzwerk herstellen, beispielsweise von einem Zug aus, und die Auswahl verderben.
Die gleiche Empfindlichkeit ist jedoch ein Vorteil bei der Überwachung. Um ein wichtiges Problem nicht zu übersehen, verwenden wir das arithmetische Mittel. Es verschiebt sich leicht, aber das Risiko eines falschen Positivs ist in diesem Fall kein so großes Problem. Besser zu übersehen als zu übersehen.

Darüber hinaus berücksichtigen wir den Median (wenn wir dies an Zeitmetriken anhängen, ist der Median ein Indikator für den Zeitpunkt, zu dem 50% der Anforderungen passen) und das 75. Perzentil. 75% der Anfragen passen zu diesem Zeitpunkt, wir nehmen es als Schätzung der Gesamtgeschwindigkeit. Das 95. und 99. Perzentil messen den langen, langsamen Schwanz. Das sind sehr große Zahlen. 95. wird als die langsamste Anfrage angesehen. Das 99. Perzentil ist abnormal.
Es macht keinen Sinn, das Maximum zu zählen. Dies ist der Weg zum Wahnsinn. Nach der Berechnung des Maximums kann sich herausstellen, dass der Benutzer 20 Jahre lang auf das Laden der Seite gewartet hat.
Nachdem Aggregationen berücksichtigt wurden, müssen nur diese Zahlen angewendet werden, und das offensichtlichste, was mit ihnen getan werden kann, ist, sie in Diagrammen darzustellen.
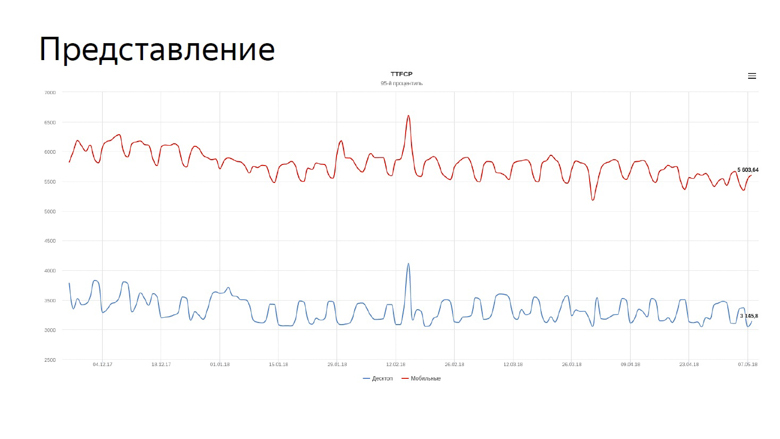
In der Grafik ist unsere Echtzeit, um zunächst inhaltliche Farbmetriken für die Suche zu malen. Die blaue Linie spiegelt die Dynamik für Desktops wider, die rote für mobile Geräte.
Wir müssen die Geschwindigkeitsgraphen ständig überwachen und haben diese Aufgabe dem Roboter anvertraut.
Überwachung
Da Geschwindigkeitsmetriken volatil sind und mit unterschiedlichen Zeiträumen ständig schwanken, muss die Überwachung genau abgestimmt werden. Dafür verwenden wir das Konzept der Frustrationen.
Das Debuggen ist der Moment, in dem ein zufälliger Prozess seine Eigenschaften wie Varianz oder mathematische Erwartung ändert. In unserem Fall ist dies die durchschnittliche Stichprobe. Wie bereits erwähnt, ist der Mittelwert emissionsempfindlich und für die Überwachung gut geeignet.
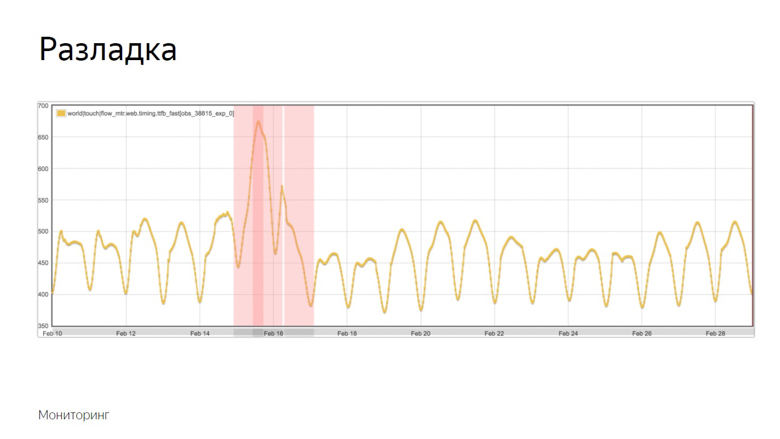
Hier ist ein Beispiel eines Diagramms, in dem die Ausrichtung erfolgte und der Roboter den Vorfall aufzeichnete. Wie hat er diesen Moment von einer Reihe anderer Zögern isoliert? Um dies zu verstehen, legen wir zusätzliche Daten fest.

Das gelbe Diagramm ist ein metrischer Indikator, und das blaue Diagramm ist ein gleitender Durchschnitt mit einer ausreichend großen Periode. Rot ist der Mittelwert plus drei Standardabweichungen. Grün ist das gleiche, nur mit einem Minuszeichen.
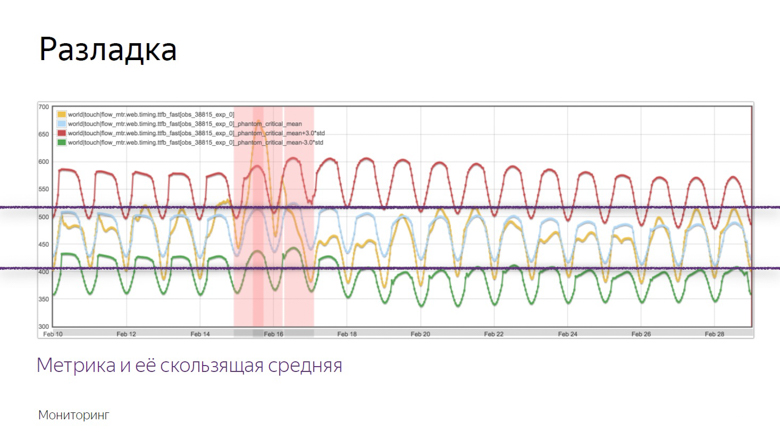
Rote und grüne Indikatoren bilden einen sicheren Korridor. Während die Metrik und der gleitende Durchschnitt zwischen ihnen schwanken - alles ist normal, sind dies gewöhnliche Schwankungen. Wenn sie jedoch die Sicherheitszone verlassen, wird die Überwachung ausgelöst.
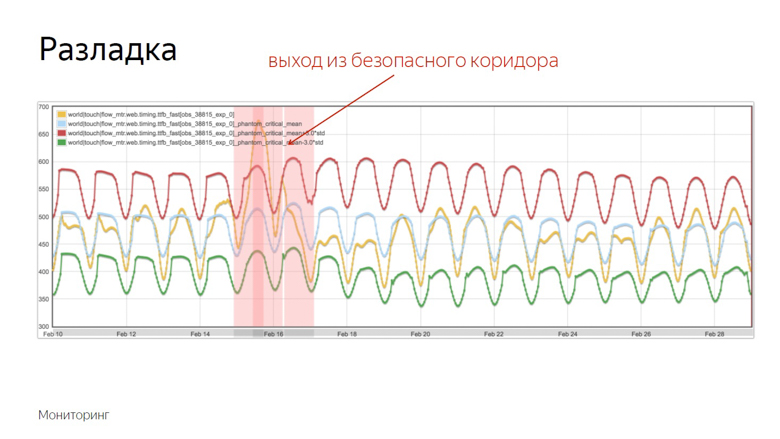
Überprüfen der Funktionen auf Geschwindigkeit
Alles, was besprochen wurde, war die Arbeit mit den Geschwindigkeitsdaten eines bereits gestarteten Projekts, aber ich möchte die Geschwindigkeit einzelner Features messen, bevor ich sie an eine große Produktion sende. Dazu verwenden wir A / B-Tests - einen Vergleich der Metriken für die Kontroll- und Versuchsgruppe.
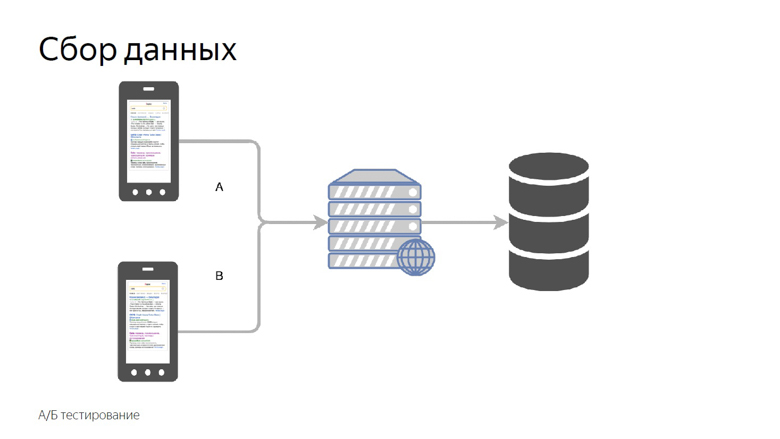
Wir unterteilen Benutzer in Kontroll- und Versuchsgruppen. Die Messwerte jedes Slots werden separat gesammelt, aggregiert und tabellarisch dargestellt.
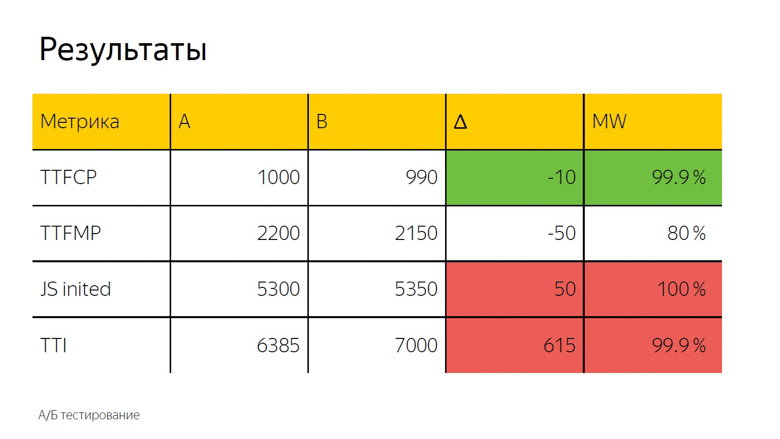
Bei A / B-Tests wird in der Regel auch das arithmetische Mittel verwendet. Hier sehen wir ein Delta und um genau zu bestimmen, ob es sich um einen Unfall oder ein signifikantes Ergebnis handelt, wird ein statistischer Test angewendet.

Es wird als "MW" bezeichnet, da bei der Berechnung der Mann-Whitney-Test verwendet wird. Mit seiner Hilfe wird der sogenannte "Prozentsatz der Korrektheit" berechnet. Dieser Indikator hat einen Schwellenwert, nach dem wir das Delta als wahr annehmen. Hier liegt sie bei 99,9%.
Wenn der Test diesen Wert erreicht, wird das Delta in der Schnittstelle hervorgehoben. Wir nennen es Färbung. Hier sehen wir Grün, das heißt eine gute Färbung rechtzeitig zum ersten zufriedenstellenden Malen. Die Zeit bis zur ersten sinnvollen Farbe erreicht diesen Wert nicht, dh das Delta ist ebenfalls gut, aber nicht 99,9%. Es ist völlig unmöglich, ihr zu vertrauen. Bei der Initialisierung des Frameworks und der Zeit bis zur Interaktion wird eine sicher schlechte rote Färbung beobachtet. Daraus können wir die gleiche Schlussfolgerung ziehen wie bei Schriftarten.

Wie geht das selbst?
Sie können Geschwindigkeitsmessungen auf zwei Arten durchführen. Das erste ist, alles selbst zu machen.

Ein Handle zum Empfangen von Daten von Clients, ein Backend, das all dies in eine Datenbank, MongoDB, PostgreSQL, MySQL, jedes DBMS (sie haben sofort einsatzbereite Aggregationen) sowie eine der vielen Open-Source-Lösungen - um Diagramme zu zeichnen und die Überwachung zu arrangieren.
Die zweite Lösung besteht in der Verwendung von Yandex Metric- oder Google Analytics-Analysesystemen. Am Beispiel von Yandex Metrics sieht es so aus.
Hier sind die Metriken, die die Metrik dem Benutzer sofort zur Verfügung stellt. Natürlich ist dies nicht alles, aber schon etwas. Der Rest kann manuell über Benutzereinstellungen hinzugefügt werden. A / B-Tests und -Überwachung sind ebenfalls verfügbar.
Fazit
Das Konzept der Online-Geschwindigkeitsmessung, über das wir gesprochen haben, ist als RUM - Real User Monitoring bekannt. Wir lieben sie so sehr, dass wir sogar ein Logo mit einem coolen Rock'n'Roll-Umlaut gezeichnet haben.

Dieser Ansatz ist gut, da er auf Zahlen aus der realen Welt basiert, den Indikatoren, die das Publikum Ihres Dienstes hat. Mithilfe von Metriken erhalten Sie anscheinend Feedback von jedem Benutzer. Beginnen Sie also mit der Optimierung und hören Sie nicht auf.
Die Ankündigung am Ende. Wenn Ihnen dieses Gespräch mit HolyJS 2018 Piter gefallen hat, werden Sie wahrscheinlich an der bevorstehenden HolyJS 2018 Moskau interessiert sein, die vom 24. bis 25. November stattfinden wird . Dort können Sie nicht nur viele andere JS-Berichte sehen, sondern auch jeden Redner im Diskussionsbereich nach dem Bericht fragen. Und morgen, ab dem 1. November, steigen die Ticketpreise bis zum Finale. Heute ist die letzte Gelegenheit, sie mit einem Rabatt zu kaufen!