Unter den sozialen Netzwerken eignet sich Twitter besser als andere für die Extraktion von Textdaten, da die Länge der Nachricht, in die Benutzer gezwungen sind, alles Wesentliche zu platzieren, streng eingeschränkt ist.
Ich schlage vor zu erraten, welche Technologie dieses Wort Cloud Frames?
Mit der Twitter-API können Sie eine Vielzahl von Informationen extrahieren und analysieren. Ein Artikel dazu mit der Programmiersprache R.
Das Schreiben des Codes nimmt nicht so viel Zeit in Anspruch, es können Schwierigkeiten aufgrund von Änderungen und Verschärfungen der Twitter-API auftreten. Anscheinend war das Unternehmen ernsthaft besorgt über Sicherheitsprobleme, nachdem es nach der Untersuchung des Einflusses „russischer Hacker“ auf die US-Wahlen im Jahr 2016 auf dem US-Kongress herausgezogen worden war.
Zugriff auf API
Warum sollte jemand Industriedaten von Twitter abrufen müssen? Nun, zum Beispiel hilft es, genauere Vorhersagen über das Ergebnis von Sportereignissen zu treffen. Aber ich bin sicher, dass es andere Benutzerszenarien gibt.
Es ist klar, dass Sie ein Twitter-Konto mit einer Telefonnummer benötigen. Dies ist erforderlich, um eine Anwendung zu erstellen. Dieser Schritt ermöglicht den Zugriff auf die API.
Wir gehen zur Entwicklerseite und klicken auf die Schaltfläche App erstellen . Als nächstes sehen Sie die Seite, auf der Sie Informationen zur Anwendung ausfüllen müssen. Derzeit besteht die Seite aus den folgenden Feldern.
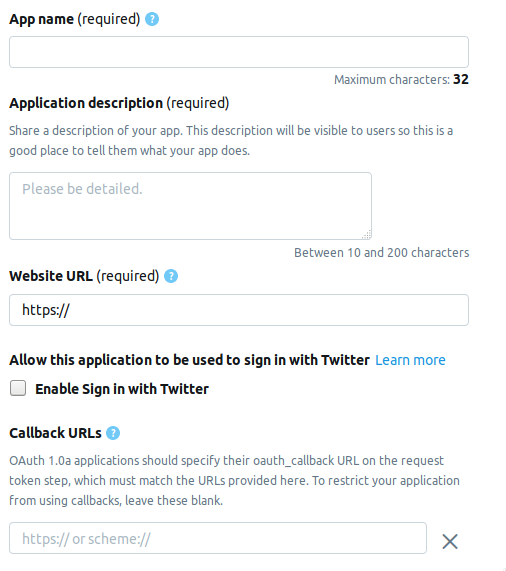
- AppName - Anwendungsname (erforderlich).
- Anwendungsbeschreibung - Anwendungsbeschreibung (erforderlich).
- Website-URL - Auf der Seite der Website der Anwendung (erforderlich) können Sie alles eingeben, was wie eine URL aussieht.
- Anmelden mit Twitter aktivieren (Kontrollkästchen) - Das Anmelden von der Seite der Anwendung auf Twitter kann weggelassen werden.
- Rückruf-URLs - Rückruf der Anwendung während der Authentifizierung (erforderlich) und erforderlich , können Sie
http://127.0.0.1:1410 verlassen.
Die folgenden Felder sind optional: die Adresse der Seite für die Nutzungsbedingungen, der Name der Organisation usw.
Wählen Sie beim Erstellen eines Entwicklerkontos eine von drei möglichen Optionen.
- Standard - In der Basisversion können Sie kostenlos nach Datensätzen bis zu einer Tiefe von ≤ 7 Tagen suchen.
- Premium - Eine erweiterte Option, mit der Sie nach Datensätzen mit einer Tiefe von ≤ 30 Tagen und seit 2006 suchen können. Kostenlos, aber nicht sofort verfügbar, wenn Sie eine Anwendung in Betracht ziehen.
- Enterprise - Business Class, bezahlter und zuverlässiger Tarif.
Ich habe mich für Premium entschieden. Es dauerte ungefähr eine Woche, bis ich auf die Genehmigung gewartet hatte. Ich kann nicht jedem sagen, ob er es mir hintereinander gibt, aber es lohnt sich trotzdem, es zu versuchen, und Standard wird nirgendwo hingehen.
Twitter-Verbindung
Nachdem Sie die Anwendung erstellt haben, wird auf der Registerkarte Schlüssel und Token ein Satz mit den folgenden Elementen angezeigt. Unten sind die Namen und entsprechenden Variablen von R.
Consumer-API-Schlüssel
- API-Schlüssel -
api_key - API geheimer Schlüssel -
api_secret
Zugriffstoken & Zugriffstoken geheim
- Zugriffstoken -
access_token - Zugriffstoken geheim -
access_token_secret
Installieren Sie die erforderlichen Pakete.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
Dieser Code sieht folgendermaßen aus.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
Nach der Authentifizierung werden Sie von R aufgefordert, OAuth Codes zur späteren Verwendung auf der Festplatte zu speichern.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
Beide Optionen sind akzeptabel, ich habe die 1. gewählt.
Ergebnisse suchen und filtern
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
Mit der Taste include_rts können Sie steuern, ob Retweets in die Suche einbezogen oder von der Suche ausgeschlossen werden. Am Ausgang erhalten wir eine Tabelle mit vielen Feldern, in denen Details und Details zu jedem Datensatz enthalten sind. Hier sind die ersten 20.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
Sie können eine komplexere Suchzeichenfolge erstellen.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
Suchergebnisse können in einer Textdatei gespeichert werden.
write.table(tweets$text, file="datamine.txt")
Wir verschmelzen mit dem Textkörper, filtern nach Servicewörtern, Satzzeichen und übersetzen alles in Kleinbuchstaben.
Es gibt eine weitere Suchfunktion - searchTwitter , für die die Bibliothek twitteR erforderlich ist. In mancher Hinsicht ist es bequemer als search_tweets , aber in mancher Hinsicht schlechter.
Plus - das Vorhandensein eines Filters nach Zeit.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
Minus - Die Ausgabe ist keine Tabelle, sondern ein Objekt vom Typ status . Um es in unserem Beispiel zu verwenden, müssen wir ein Textfeld aus der Ausgabe extrahieren. Dies macht sapply in der zweiten Zeile.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
In der zweiten Zeile wird die Funktion tm_map benötigt, um alle Arten von Emoji-Zeichen in Kleinbuchstaben umzuwandeln. Andernfalls tolower die Konvertierung in Kleinbuchstaben mit tolower fehl.
Eine Wortwolke bauen
Soweit ich weiß, tauchten Wortwolken zum ersten Mal auf Flickr- Fotohosting auf und haben seitdem an Popularität gewonnen. Für diese Aufgabe benötigen wir die wordcloud Bibliothek.
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Mit der Funktion search_string können Sie die Sprache als Parameter festlegen.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
Aufgrund der Tatsache, dass das NLP-Paket für R schlecht russifiziert ist, insbesondere weil es keine Liste von Service- oder Stoppwörtern gibt, ist es mir nicht gelungen, eine Wortwolke mit einer Suche auf Russisch zu erstellen. Ich würde mich freuen, wenn Sie in den Kommentaren eine bessere Lösung finden.
Nun, eigentlich ...
ganzes Skript library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Gebrauchte Materialien.
Kurze Links:
Ursprüngliche Links:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Hinweis, das Cloud-Schlüsselwort auf dem KDPV wird im Programm nicht verwendet, es ist mit meinem vorherigen Artikel verknüpft.