Das Überprüfen eines Servers ist kein Problem. Sie nehmen die Checkliste und überprüfen in der Reihenfolge: Prozessor, Speicher, Festplatten. Bei hundert Servern ist es jedoch unwahrscheinlich, dass diese Methode gut funktioniert. Um den menschlichen Faktor zu eliminieren, Überprüfungen zuverlässiger und schneller zu machen, ist es notwendig, den Prozess zu automatisieren. Wer muss wissen, wie man das besser macht als ein Hosting-Anbieter. Artyom Artemyev unter HighLoad ++ Siberia erklärte, welche Methoden verwendet werden können, was besser mit den Händen zu laufen ist und was gut zu automatisieren ist. Als nächstes folgt eine Textversion des Berichts mit Tipps, die jeder wiederholen kann, der mit Eisen arbeitet und dessen Leistung regelmäßig überprüfen muss.
 Über den Sprecher:
Über den Sprecher: Artyom
Artemyev (
Artemirk ), technischer Direktor bei einem großen Hosting-Anbieter FirstVDS, arbeitet mit Eisen.
FirstVDS verfügt über zwei Rechenzentren. Die erste ist ihre eigene, sie bauten ihr eigenes Gebäude, brachten und installierten ihre Racks, sie selbst warten, sorgen sich um den Strom und die Kühlung des Rechenzentrums. Das zweite Rechenzentrum ist ein großer Raum in einem großen vermieteten Rechenzentrum, alles ist einfacher damit, aber es existiert auch. Insgesamt sind es 60 Racks und ca. 3000 Eisenserver. Es gab etwas zu trainieren und verschiedene Ansätze zu testen, was bedeutet, dass wir auf praktisch bestätigte Empfehlungen warten. Beginnen wir mit dem Anzeigen oder Lesen des Berichts.
Vor ungefähr 6-7 Jahren haben wir festgestellt, dass es nicht ausreicht, das Betriebssystem einfach auf den Server zu stellen. Das Betriebssystem ist eingeschaltet, der Server ist wach und bereit für den Kampf. Wir starten es in der Produktion - unverständliche Neustarts und Einfrierungen beginnen. Was zu tun ist, ist nicht klar - der Prozess ist im Gange. Die Übertragung des gesamten Arbeitsentwurfs auf ein neues Metallstück ist hart, teuer und schmerzhaft. Wo laufen?
Moderne Bereitstellungsmethoden ermöglichen es uns, dies zu vermeiden und den Server in 5 Sekunden zu transportieren, aber unsere Kunden (insbesondere vor 6 Jahren) flogen einfach nicht in den Wolken, gingen auf dem Boden und verwendeten gewöhnliche Eisenstücke.

In diesem Artikel werde ich Ihnen sagen, welche Methoden wir ausprobiert haben, welche wir verwurzelt haben, welche nicht verwurzelt sind, welche gut mit Ihren Händen zu laufen sind und wie Sie all dies automatisieren können. Ich werde Ihnen Ratschläge geben, und Sie können ihn in Ihrer Firma wiederholen, wenn Sie mit Eisen arbeiten und ein solches Bedürfnis haben.
Was ist das Problem?
Theoretisch ist die Überprüfung des Servers kein Problem. Anfangs hatten wir einen Prozess wie im Bild unten. Ein Mann setzt sich, nimmt eine Checkliste, prüft: Prozessor, Speicher, Festplatten, runzelt die Stirn, trifft eine Entscheidung.
Dann wurden 3 Server pro Monat installiert. Aber wenn es immer mehr Server gibt, fängt diese Person an zu weinen und sich zu beschweren, dass sie bei der Arbeit stirbt. Eine Person irrt sich zunehmend, weil die Überprüfung zur Routine geworden ist.
Wir haben eine Entscheidung getroffen: Wir automatisieren! Eine Person wird nützlichere Dinge tun.
Kurzer Ausflug
Ich werde klarstellen, was ich meine, wenn ich heute über den Server spreche. Wir sparen wie alle anderen Rack-Platz und verwenden Server mit hoher Dichte. Heute sind es 2 Einheiten, die entweder 12 Knoten von Einzelprozessorservern oder 4 Knoten von Doppelprozessorservern aufnehmen können. Das heißt, jeder Server erhält 4 Festplatten - alles ehrlich. Außerdem befinden sich zwei Netzteile im Rack, dh alles ist redundant und jeder mag es.
Woher kommt das Eisen?
Eisen wird von unseren Lieferanten - normalerweise Supermicro und Intel - in unser Rechenzentrum gebracht. Im Rechenzentrum installieren unsere Mitarbeiter Server in einem leeren Raum im Rack und verbinden zwei Kabel, ein Netzwerk und Strom. Es liegt auch in der Verantwortung der Bediener, das BIOS auf dem Server zu konfigurieren. Schließen Sie also die Tastatur an, überwachen Sie und konfigurieren Sie zwei Parameter:
Restore on AC/Power Loss — [Power On] Stromausfall
Restore on AC/Power Loss — [Power On] Einschalten
Restore on AC/Power Loss — [Power On] , sodass der Server immer eingeschaltet wird, sobald die Stromversorgung angezeigt wird. Es sollte ohne Unterbrechung funktionieren. Das zweite
First boot device — [PXE] ,
First boot device — [PXE] wir stellen das erste Startgerät in das Netzwerk, andernfalls können wir den Server nicht erreichen, da es keine Tatsache ist, dass es sofort über Festplatten usw. verfügt.

Danach öffnet der Bediener das Abrechnungsfeld für Eisenserver, in dem Sie die Tatsache der Installation des Servers aufzeichnen müssen, für die Folgendes angegeben ist:
- Gestell;
- Aufkleber
- Netzwerkanschlüsse
- Stromanschlüsse
- Einheitennummer.
Danach wird der Netzwerkport, an dem der Betreiber den neuen Server aus Sicherheitsgründen installiert hat, in ein spezielles Quarantäne-VLAN verschoben, in dem auch DHCP, Pxe, TFtp hängen. Als nächstes lädt der Server unser Lieblings-Linux, das über alle erforderlichen Dienstprogramme verfügt, und der Diagnoseprozess beginnt.
Da der Server immer noch das erste Startgerät im Netzwerk hat, wechselt der Port für Server, die in Produktion gehen, zu einem anderen VLAN. In einem anderen VLAN befindet sich kein DHCP, und wir haben keine Angst, dass wir unseren Produktionsserver versehentlich neu installieren. Dafür haben wir ein separates VLAN.
Es kommt vor, dass der Server installiert wurde, alles in Ordnung ist, aber das Diagnosesystem nicht gestartet wurde. Dies geschieht in der Regel aufgrund der Tatsache, dass nicht alle Netzwerk-Switches mit einer Verzögerung beim Wechseln von VLANs schnell VLANs usw. wechseln.

Dann erhält der Bediener die Aufgabe, den Server mit seinen Händen neu zu starten. Bisher gab es kein IPMI, wir haben Remote-Sockets eingerichtet und festgelegt, an welchem Port die Server-Sockets vorhanden sind, den Socket über das Netzwerk gezogen und den Server neu gestartet.
Verwaltete Steckdosen funktionieren jedoch auch nicht immer gut. Daher verwalten wir jetzt die Serverleistung über IPMI. Wenn der Server neu ist und IPMI nicht konfiguriert ist, kann er nur durch Hochfahren und Drücken der Taste neu gestartet werden. Deshalb sitzt ein Mann, wartet - das Licht geht an - rennt und drückt den Knopf. So ist sein Job.
Wenn der Server danach nicht mehr gestartet wurde, wird er zur Reparatur in eine spezielle Liste eingetragen. Diese Liste enthält Server, auf denen die Diagnose nicht gestartet wurde oder deren Ergebnisse nicht zufriedenstellend waren. Eine einzelne Person - die Eisen liebt - sitzt und zerlegt jeden Tag - sammelt, schaut, warum funktioniert das nicht.
CPU
Alles ist in Ordnung, der Server hat gestartet, wir fangen an zu testen. Zuerst testen wir den Prozessor als eines der wichtigsten Elemente.

Der erste Impuls war, die Anwendung des Anbieters zu verwenden. Wir haben fast alle Intel-Prozessoren - wir sind auf die Website gegangen und haben das Intel Processor Diagnostic Tool heruntergeladen - alles ist in Ordnung, es enthält viele interessante Informationen, einschließlich der Betriebsstunden des Servers in Stunden und der grafischen Darstellung des Stromverbrauchs.
Das Problem ist jedoch, dass Intel PTD unter Windows funktioniert, was uns nicht mehr gefallen hat. Um einen Test darin zu starten, müssen Sie nur die Maus bewegen, die "START" -Taste drücken und der Test beginnt. Das Ergebnis wird auf dem Bildschirm angezeigt, es kann jedoch nirgendwo exportiert werden. Dies passt nicht zu uns, da der Prozess nicht automatisiert ist.

Wir haben die Foren gelesen und die zwei einfachsten Wege gefunden.
- Die ewige Schleife cat / dev / zero> / dev / null . Sie können oben einchecken - 100% ein Kern wird verbraucht. Wir zählen die Anzahl der Kerne, führen die erforderliche Anzahl von cat / dev / zero aus, multipliziert mit der gewünschten Anzahl von Kernen. Alles funktioniert super!
- Dienstprogramm / Behälter / Stress . Sie baut Matrizen im Gedächtnis auf und beginnt sie ständig umzudrehen. Alles ist auch in Ordnung - der Prozessor erwärmt sich, es gibt eine Last.
Wir geben die Server in Produktion, Benutzer kommen zurück und sagen, dass der Prozessor instabil ist. Aktiviert - der Prozessor ist instabil. Sie begannen zu untersuchen, sie nahmen den Server, der die Prüfungen besteht, aber er stürzt im Kampf ab, schalteten den Debug-Kernel unter Linux ein und sammelten den Core-Dump. Der Server löscht vor dem Neustart alles, was sich vor dem Absturz im Speicher befand, in die Datei.

In Prozessoren sind verschiedene Optimierungen für häufige Operationen integriert. Wir können Flags sehen, die angeben, welche Optimierungen der Prozessor unterstützt, z. B. Optimierungen für die Arbeit mit Gleitkommazahlen, Multimedia-Optimierungen usw. Aber unser / bin / stress und der ewige Zyklus brennen den Prozessor nur in einem Arbeitsgang und verwenden keine zusätzlichen Funktionen. Die Untersuchung ergab, dass die CPU abstürzt, wenn versucht wird, die Funktionalität eines der integrierten Flags zu nutzen.
Der erste Impuls war, / bin / stress zu verlassen - den Prozessor erwärmen zu lassen. Dann laufen wir in einem Zyklus durch alle Flaggen und ziehen sie. Während wir darüber nachdenken, wie dies implementiert werden soll, welche Befehle aufgerufen werden müssen, um die Funktionen der einzelnen Flags aufzurufen, lesen wir die Foren.
Im Overclocker-Forum stießen wir auf ein interessantes Projekt zur Suche nach Primzahlen
Great Internet Mersenne Prime Search . Wissenschaftler haben ein verteiltes Netzwerk aufgebaut, mit dem sich jeder verbinden und eine Primzahl finden kann. Wissenschaftler glauben niemandem, deshalb funktioniert das Programm sehr geschickt: Zuerst führen Sie es aus, es berechnet die Primzahlen, die es bereits kennt, und vergleicht das Ergebnis mit dem, was es weiß. Wenn das Ergebnis nicht übereinstimmt, funktioniert der Prozessor nicht richtig. Diese Eigenschaft hat uns sehr gut gefallen: Bei jedem Unsinn ist es anfällig zu fallen.
Darüber hinaus ist es das Ziel des Projekts, so viele Primzahlen wie möglich zu finden. Daher wird das Programm ständig für die Eigenschaften neuer Prozessoren optimiert, wodurch viele Flags gezogen werden.
Mprime hat keine zeitliche Begrenzung. Wenn es nicht gestoppt wird, funktioniert es für immer. Wir lassen es 30 Minuten lang laufen.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
Nach Abschluss der Arbeit überprüfen wir, ob die Datei result.txt keine Fehler enthält, und überprüfen die Kernelprotokolle, insbesondere die Datei / proc / kmsg, in der wir nach Fehlern suchen.
Noch ein Ausflug

Am 3. Januar 2018 fanden sie die 50. Mersenne-Primzahl (2
p -1). Von dieser Zahl nur 23 Millionen Ziffern. Sie können es herunterladen, um es anzuzeigen -
dies ist
ein 12-MB-Zip-Archiv .
Warum brauchen wir Primzahlen? Erstens verwendet jede RSA-Verschlüsselung Primzahlen. Je mehr Primzahlen wir kennen, desto zuverlässiger ist Ihr SSH-Schlüssel. Zweitens testen Wissenschaftler ihre Hypothesen und mathematischen Theoreme, und es macht uns nichts aus, Wissenschaftlern zu helfen - es kostet uns nichts. Es stellt sich heraus, Win-Win-Geschichte.

Der Prozessor funktioniert also, alles ist in Ordnung. Es bleibt abzuwarten, um welche Art von Prozessor es sich handelt. Wir verwenden den Prozessor dmidecode -t und sehen alle Steckplätze auf dem Motherboard und welche Prozessoren sich in diesen Steckplätzen befinden. Diese Informationen werden in unser Buchhaltungssystem eingegeben und später interpretiert.
Fang
So können überraschenderweise gebrochene Beine gefunden werden. / bin / stress und der ewige Zyklus funktionierten und Mprime fiel. Sie fuhren lange, suchten, entdeckten - das Ergebnis im Bild unten - hier ist alles klar.

Ein solcher Prozessor hat einfach nicht gestartet. Der Bediener war sehr stark, nahm den falschen Prozessor - konnte aber liefern.

Ein weiterer schöner Fall. Die schwarze Reihe auf dem Foto unten zeigt die Lüfter. Der Pfeil zeigt, wie die Luft weht. Wir sehen: Der Kühler steht über dem Strom. Natürlich ist alles überhitzt und ausgeschaltet.

Die Erinnerung
Mit dem Gedächtnis ist alles ziemlich einfach. Dies sind Zellen, in die wir Informationen schreiben und nach einer Weile wieder lesen. Wenn es dasselbe bleibt, das wir aufgeschrieben haben, funktioniert diese Zelle.

Jeder kennt das gute, direkt klassische
Memtest86 + -Programm, das von jedem Medium, über das Netzwerk oder sogar von einer Diskette ausgeführt wird. Es wird gemacht, um so viele Speicherzellen wie möglich zu überprüfen. Besetzte Zellen können nicht mehr überprüft werden. Daher hat memtest86 + eine Mindestgröße, um keinen Speicher zu belegen. Leider zeigt
memtest86 + seine Statistiken nur auf dem Bildschirm an . Wir haben versucht, es irgendwie zu erweitern, aber es kam alles darauf an, dass es im Programm nicht einmal einen Netzwerkstapel gab. Um es zu erweitern, müsste man den Linux-Kernel und alles andere mitbringen.
Es gibt eine kostenpflichtige Version dieses Programms, die bereits weiß, wie Informationen auf die Festplatte gelegt werden. Unsere Server verfügen jedoch nicht immer über eine Festplatte, und auf diesen Festplatten befindet sich nicht immer ein Dateisystem. Wie wir bereits herausgefunden haben, kann das Netzwerklaufwerk jedoch nicht verbunden werden.
Wir begannen weiter zu graben und fanden ein ähnliches
Memtester- Programm. Dieses Programm funktioniert auf Betriebssystemebene unter Linux. Das größte Minus ist, dass das Betriebssystem selbst und Memtester einige Speicherzellen belegen und diese Zellen nicht überprüft werden.
Memtester wird mit dem folgenden Befehl gestartet: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'k 5
Hier übertragen wir die Menge an freiem Speicher minus 1 MB. Dies geschieht, weil der Memtester sonst den gesamten Speicher belegt und der Down-Killer ihn tötet. Wir fahren diesen Test für 5 Zyklen, am Ausgang haben wir eine Platte mit entweder OK oder Fail.
| Festgefahrene Adresse | ok |
| Zufälliger Wert | ok |
| Vergleiche XOR | ok |
| Vergleiche SUB | ok |
| Vergleiche MUL | ok |
| Vergleiche DIV | ok |
| Vergleiche OR | ok |
| Vergleiche AND | ok |
Wir speichern das Endergebnis und analysieren es weiter auf Fehler.

Um das Ausmaß des Problems zu verstehen: Unser kleinster Server verfügt über 32 GB Arbeitsspeicher, unser Linux-Image mit Memtester nimmt 60 MB ein,
wir überprüfen nicht 2% des Arbeitsspeichers . Laut Statistiken der letzten 6 Jahre gab es jedoch nicht so etwas, dass offen geschlagene Erinnerungen in Produktion gingen. Dies ist der Kompromiss, dem wir zustimmen und dessen Behebung teuer ist und mit dem wir leben.
Unterwegs sammeln wir auch dmidecode -t Speicher, der alle Speicherbänke enthält, die wir auf dem Motherboard haben (normalerweise bis zu 24 Teile), und die sich in jeder Bank befinden. Diese Informationen sind nützlich, wenn wir den Server aktualisieren möchten. Wir wissen, wo was hinzugefügt werden muss, wie viele Streifen benötigt werden und zu welchem Server.
Speichergeräte
Vor 6 Jahren waren alle Scheiben mit Pfannkuchen, die sich drehten. Eine separate Geschichte bestand darin, nur eine Liste aller Festplatten zusammenzustellen. Es gab verschiedene Ansätze, da nicht angenommen wurde, dass man sich nur ls / dev / sd ansehen könnte. Aber am Ende haben wir aufgehört, uns ls / dev / sd * und ls / dev / cciss / c0d * anzusehen. Im ersten Fall handelt es sich um ein SATA-Gerät, im zweiten um SCSI und SAS.

Buchstäblich in diesem Jahr haben sie angefangen, NVME-Festplatten zu verkaufen und hier eine NVME-Liste hinzugefügt.
Nachdem die Liste der Festplatten kompiliert wurde, versuchen wir, 0 Bytes daraus zu lesen, um zu verstehen, dass dies ein Blockgerät ist und alles in Ordnung ist. Wenn Sie es nicht lesen konnten, glauben wir, dass dies eine Art Geist ist, und wir haben und hatten noch nie eine solche Festplatte.
Der erste Ansatz zum Überprüfen von Datenträgern war der offensichtliche: „Schreiben wir zufällige Daten auf den Datenträger und sehen die Geschwindigkeit“ -
dd -o nocache -o direct if=/dev/urandom of=${disk} . Pfannkuchenscheiben geben in der Regel 130-150 Mb / s ab. Wir kniff die Augen zusammen und entschieden für uns, dass 90 MB / s die Zahl sind, nach der es wartungsfähige Festplatten gibt, alle kleineren sind fehlerhaft.
Aber wieder kehrten Benutzer zurück und sagten, dass die Laufwerke schlecht sind. Es stellte sich heraus, dass die heimtückische Physik wieder mit uns scherzte.
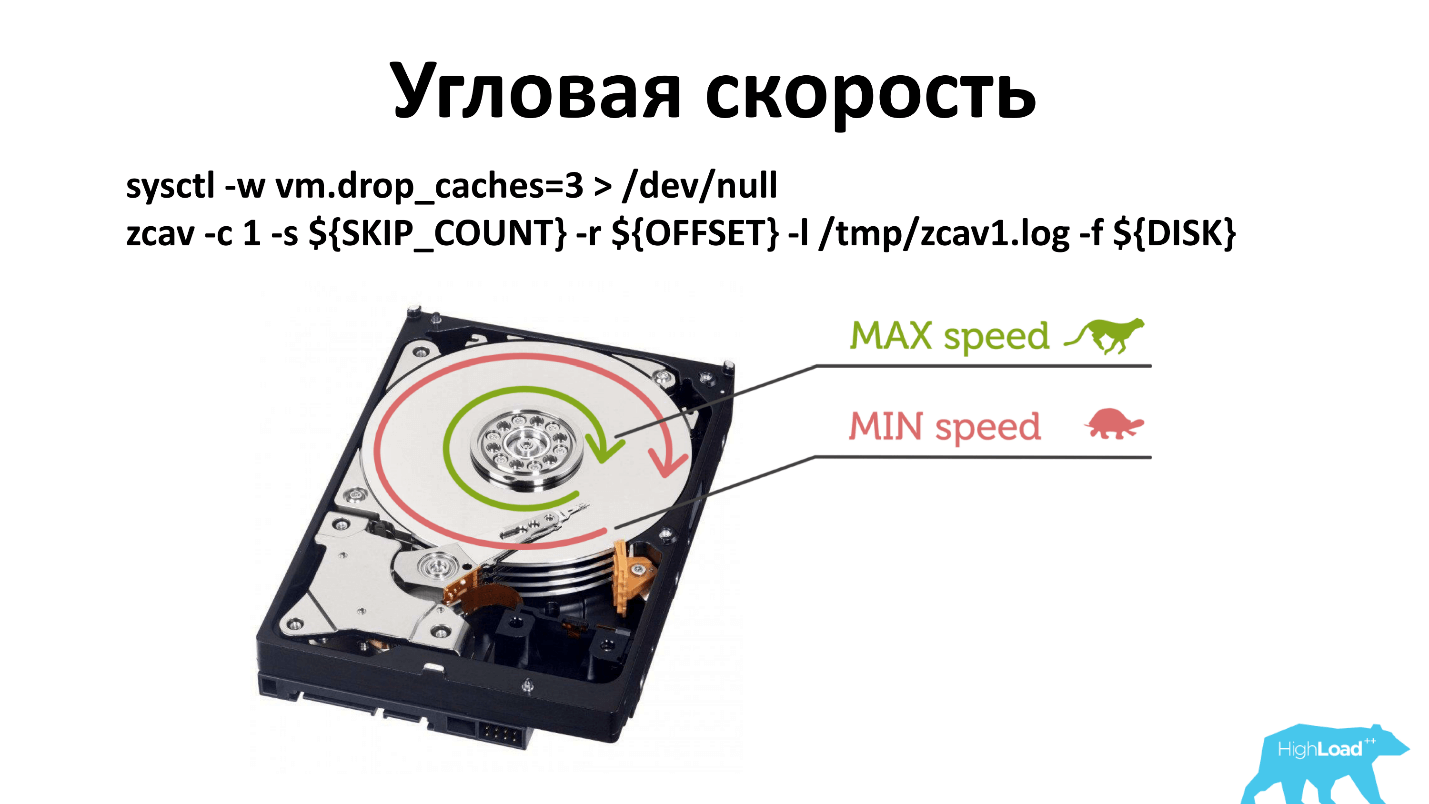
Es gibt eine Winkelgeschwindigkeit, und wenn Sie -dd ausführen, wird in der Regel in der Nähe der Spindel geschrieben. Wenn sich die Spindeldrehzahl aus irgendeinem Grund verschlechtert hat, ist dies weniger auffällig als wenn Sie vom Rand der Disc aus schreiben.
Ich musste das Prinzip der Überprüfung ändern. Jetzt checken wir an drei Stellen ein: in der Nähe der Spindel, in der Mitte und draußen. Wahrscheinlich kann es nur von außen überprüft werden, aber so ist es historisch geschehen. Und was funktioniert, nicht anfassen.
Sie können
smartctl verwenden , um die Festplatte zu fragen, wie es funktioniert. Wir glauben, dass eine gute Fahrt:
- Es gibt keine neu zugewiesenen Sektoren ( Anzahl der neu zugewiesenen Sektoren = 0) , dh alle Sektoren, die die Fabrik verlassen haben.
- Wir verwenden keine Discs, die älter als 4 Jahre sind , obwohl sie ziemlich gut funktionieren. Bevor wir diese Praxis einführten, hatten wir 7 Jahre lang Scheiben. Jetzt glauben wir, dass sich die Festplatte nach 4 Jahren ausgezahlt hat und wir nicht bereit sind, das Verschleißrisiko zu akzeptieren.
- Es gibt keine Sektoren, die neu zugewiesen werden sollen ( Current_Pending_Sector = 0 ).
- UltraDMA CRC Error Count = 0 - Dies sind Fehler am SATA-Kabel. Wenn ein Fehler auftritt, müssen Sie nur das Kabel wechseln, Sie müssen die Festplatte nicht wechseln.

Verteilte SSDs sind im Allgemeinen ausgezeichnete Laufwerke, sie arbeiten schnell, machen keine Geräusche und heizen sich nicht auf. Wir glauben, dass eine gute SSD eine Schreibgeschwindigkeit von mehr als 200 MB / s hat. Unsere Kunden lieben niedrige Preise, und Servermodelle mit 320-350 MB / s erreichen uns nicht immer.
Für SSDs sehen wir auch smartctl aus. Dieselbe Neuzuweisung, Power_On_Hours, Current_Pending_Sector. Alle SSDs können den Verschleißgrad anzeigen, es wird der Parameter Media_Wearout_Indicator angezeigt. Wir wischen die Discs bis zu 5% der Lebensdauer ab und nehmen sie erst dann heraus. Solche Discs finden manchmal ein zweites Leben in den persönlichen Bedürfnissen der Mitarbeiter. Zum Beispiel habe ich kürzlich herausgefunden, dass eine solche Festplatte in 2 Jahren im Laptop eines Mitarbeiters um weitere 1% abgenutzt ist, obwohl sie in unserem Land unter dem SSD-Cache in etwa 10 Monaten um 95% erschöpft ist.
Das Problem ist jedoch, dass sich nicht alle Festplattenhersteller auf die Parameternamen geeinigt haben und dieser Media_Wearout_Indicator beispielsweise als Percent_Lifetime_Used für Toshiba, andere Wear Leveling Count, Percent Lifetime Remaining für andere Hersteller oder nur. * Wear. * Bezeichnet wird.
Crucial hat diese Option überhaupt nicht. Dann betrachten wir nur den Umfang des Umschreibens der Disc - "Byte geschrieben" - wie viele Bytes wir bereits auf diese Disc geschrieben haben. Ferner versuchen wir gemäß der Spezifikation herauszufinden, wie viele Umschreibungen diese Platte vom Hersteller berechnet wird. Durch elementare Mathematik bestimmen wir, wie viel mehr er leben wird. Wenn es Zeit ist, sich zu ändern - ändern Sie sich.
RAID
Ich weiß nicht, warum unsere Kunden in der modernen Welt immer noch RAIDs wollen. Die Leute kaufen RAID und legen dort 4 SSDs ab, die viel schneller sind als dieses RAID (6 GB). Sie haben irgendeine Art von Anweisung und sammeln sie. Ich denke, das ist eine fast unnötige Sache.
Früher gab es 3 Hersteller: Adaptec; 3ware; Intel Wir hatten 3 Dienstprogramme, wir haben uns die Mühe gemacht, aber wir haben Diagnosen für alle durchgeführt. Jetzt hat LSI alle gekauft - es gibt nur noch ein Dienstprogramm.
Wenn unser Diagnosesystem RAID erkennt, analysiert es das logische Volume in separate Datenträger, sodass Sie die Geschwindigkeit jedes Datenträgers messen und dessen Smart lesen können. Danach muss das RAID den Akku überprüfen. Wer weiß nicht - es gibt genug Batterien im RAID, um alle Festplatten für weitere 2 Stunden zu drehen. Das heißt, Sie schalten den Server aus, nehmen ihn heraus und drehen die Festplatte für weitere 2 Stunden, um alle Aufzeichnungen abzuschließen.
Netzwerk
Mit dem Netzwerk ist alles ganz einfach - im Rechenzentrum sollten weniger als 300 Mbit vorhanden sein. Wenn weniger, müssen Sie es beheben. Wir betrachten auch Fehler auf der Schnittstelle.
Fehler auf der Netzwerkschnittstelle sollten überhaupt nicht auftreten , und wenn
dies der Fall ist, ist alles schlecht.
Wir versuchen dabei, die BIOS- und IPMI-Firmware zu aktualisieren. Es stellte sich heraus, dass wir nicht alle BIOS mögen. Wir haben immer noch BIOSes, die nicht wissen, wie man UEFI und andere von uns verwendete Funktionen verwendet. Wir versuchen es automatisch zu aktualisieren, aber das funktioniert nicht immer, da ist dort nicht alles sehr einfach. Wenn es nicht funktioniert, geht die Person und aktualisiert mit ihren Händen.
Wir geben IPMI Supermicro nicht an die Welt weiter, wir haben es auf grauen Adressen über OpenVPN. Trotzdem befürchten wir, dass eines Tages eine weitere Verwundbarkeit herauskommt und wir leiden werden. Daher versuchen wir, die IPMI-Firmware immer auf dem neuesten Stand zu halten. Wenn dies nicht der Fall ist, aktualisieren Sie.
Aus einer seltsamen Sache wurde kürzlich bekannt, dass Intel auf 10- und 40-Gigabit-Netzwerkkarten keinen PXE-Start enthält. Es stellt sich heraus, dass es unmöglich ist, über das Netzwerk zu booten, wenn sich der Server in einem Rack befindet, in dem sich nur eine 40-Gigabit-Karte befindet, da Sie eine Gigabit-Karte booten müssen. Wir flashen Netzwerkkarten separat auf 40G, damit sie PXE haben und weiterleben können.
Nachdem alles überprüft wurde, wird der Server sofort zum Verkauf angeboten . Der Preis wird berechnet, zu dem er auf die Website gestellt und verkauft wird.

Insgesamt führen wir ungefähr 350 Überprüfungen pro Monat durch, 69% der Server sind wartungsfähig, 31% sind nicht wartungsfähig. Dies liegt an der Tatsache, dass wir eine reiche Geschichte haben, einige Server stehen seit 10 Jahren. Die meisten Server, die den Test nicht bestanden haben, werfen wir einfach.
Für Neugierige: Wir haben 3 Kunden, die noch auf dem Pentium IV leben und nirgendwo abreisen wollen. Sie haben 512 MB RAM.
Die Zukunft ist gekommen! Wenn ich dieses System heute umzäunen würde ...

Ein wunderbares Dienstprogramm,
Hardware Lister (lshw), wurde veröffentlicht, das mit dem Kernel kommunizieren kann und auf wunderbare Weise anzeigt, welche Art von Hardware sich im Kernel befindet und was der Kernel erkennen kann. Nicht alle diese Tänze werden benötigt. Wenn Sie wiederholen - Ich rate Ihnen dringend, sich dieses Dienstprogramm anzusehen und es zu verwenden. Alles wird viel einfacher.
Zusammenfassung:
- Kompromisse sind nicht schlecht, es ist nur eine Frage des Preises. Wenn die Lösung sehr teuer ist, müssen Sie nach einem Niveau suchen, bei dem sowohl Zuverlässigkeit als auch Preis akzeptabel sind.
- Nicht-Kernprogramme sind manchmal cool zum Testen. Es bleibt nur, sie zu finden.
- Testen Sie alles, was Sie erreichen!
Das nächste große HighLoad ++ findet bereits am 8. und 9. November in Moskau statt. Das Programm umfasst berühmte Spezialisten und neue Namen, traditionelle und neue Aufgaben. Im DevOps-Bereich werden beispielsweise bereits folgende akzeptiert:
Studieren Sie die Liste der Berichte und beeilen Sie sich, um beizutreten. Oder abonnieren Sie unseren Newsletter und Sie erhalten regelmäßig Bewertungen von Berichten, Berichten über neue Artikel und Videos.