 Ein vollständiger Durchgang zum maschinellen Lernen in Python: Teil drei
Ein vollständiger Durchgang zum maschinellen Lernen in Python: Teil dreiVielen Menschen gefällt es nicht, dass Modelle für maschinelles Lernen
Black Boxes sind : Wir geben Daten ein und erhalten Antworten ohne Erklärung - oft sehr genaue Antworten. In diesem Artikel werden wir versuchen herauszufinden, wie das von uns erstellte Modell Prognosen erstellt und was es über das von uns gelöste Problem aussagen kann. Abschließend diskutieren wir den wichtigsten Teil des maschinellen Lernprojekts: Wir dokumentieren, was wir getan haben, und präsentieren die Ergebnisse.
Im
ersten Teil untersuchten wir die Datenbereinigung, explorative Analyse, das Design und die Auswahl von Features. Im
zweiten Teil untersuchten wir das Füllen fehlender Daten, die Implementierung und den Vergleich von Modellen für maschinelles Lernen, die hyperparametrische Abstimmung mithilfe der Zufallssuche mit Kreuzvalidierung und schließlich die Bewertung des resultierenden Modells.
Der gesamte
Projektcode befindet sich auf GitHub. Und das dritte Jupyter-Notizbuch zu diesem Artikel liegt
hier . Sie können es für Ihre Projekte verwenden!
Wir arbeiten also an einer Lösung des Problems durch maschinelles Lernen bzw. durch überwachte Regression. Basierend auf
Energiedaten von Gebäuden in New York haben wir ein Modell erstellt, das den Energy Star Score vorhersagt. Wir haben das auf
Gradientenverstärkung basierende Regressionsmodell erhalten , das auf der Grundlage von Testdaten Vorhersagen im Bereich von 9,1 Punkten (im Bereich von 1 bis 100) treffen kann.
Modellinterpretation
Die Gradientenverstärkungsregression befindet sich ungefähr in der Mitte
der Modellinterpretierbarkeitsskala : Das Modell selbst ist komplex, besteht jedoch aus Hunderten ziemlich einfacher
Entscheidungsbäume . Es gibt drei Möglichkeiten, um zu verstehen, wie unser Modell funktioniert:
- Bewerten Sie die Wichtigkeit der Symptome .
- Visualisieren Sie einen der Entscheidungsbäume.
- Wenden Sie die LIME- Methode an - Lokale interpretierbare modellunabhängige Erklärungen, lokal interpretierte modellunabhängige Erklärungen.
Die ersten beiden Methoden sind charakteristisch für Baumensembles, und die dritte Methode kann, wie Sie anhand ihres Namens verstehen, auf jedes maschinelle Lernmodell angewendet werden. LIME ist ein relativ neuer Ansatz, ein bedeutender Fortschritt bei dem Versuch
, die Funktionsweise des maschinellen Lernens zu
erklären .
Die Bedeutung der Symptome
Die Wichtigkeit von Zeichen ermöglicht es Ihnen, die Beziehung jedes Zeichens mit dem Ziel der Vorhersage zu sehen. Die technischen Details dieser Methode sind komplex (die mittlere Abnahme der Verunreinigung oder die
Abnahme des Fehlers aufgrund der Einbeziehung eines Merkmals wird gemessen ), aber wir können relative Werte verwenden, um zu verstehen, welche Merkmale relevanter sind. In Scikit-Learn können Sie
die Wichtigkeit von Attributen aus jedem baumbasierten „Schüler“ -Ensemble
extrahieren .
Im folgenden Code ist
model unser trainiertes Modell. Mithilfe von
model.feature_importances_ Sie die Wichtigkeit von Attributen bestimmen. Dann senden wir sie an den Pandas-Datenrahmen und zeigen die 10 wichtigsten Attribute an:
import pandas as pd
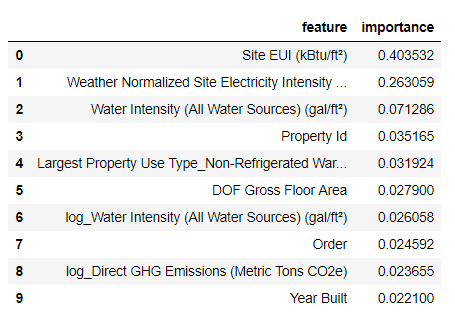
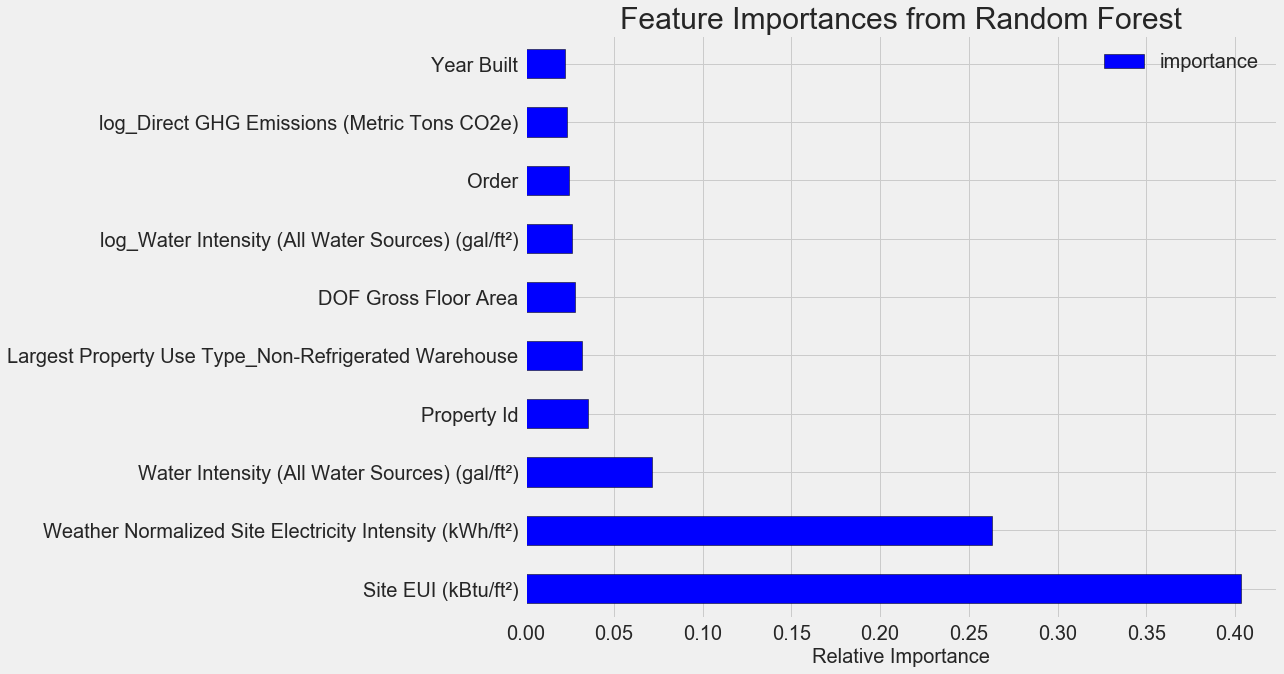
Die wichtigsten Merkmale sind
Site EUI (
Energieverbrauchsintensität ) und
Weather Normalized Site Electricity Intensity , die mehr als 66% der Gesamtbedeutung ausmachen. Bereits beim dritten Attribut ist die Wichtigkeit stark reduziert, was
darauf hindeutet, dass wir nicht alle 64 Attribute verwenden müssen, um eine hohe Prognosegenauigkeit zu erzielen (im
Jupyter-Notizbuch wird diese Theorie nur mit den 10 wichtigsten Attributen getestet, und das Modell war nicht sehr genau).
Basierend auf diesen Ergebnissen kann eine der ersten Fragen endlich beantwortet werden: Die wichtigsten Indikatoren für den Energy Star Score sind Site EUI und Weather Normalized Site Electricity Intensity. Wir werden nicht
zu tief in den Dschungel der Bedeutung von Attributen eintauchen , wir werden nur sagen, dass Sie mit ihnen beginnen können, den Prognosemechanismus anhand des Modells zu verstehen.
Visualisierung eines einzelnen Entscheidungsbaums
Es ist schwierig, das gesamte Regressionsmodell auf der Grundlage der Gradientenverstärkung zu verstehen, was nicht über einzelne Entscheidungsbäume gesagt werden kann. Sie können jeden Baum mit der
Scikit-Learn- export_graphviz . Extrahieren Sie zuerst den Baum aus dem Ensemble und speichern Sie ihn dann als Punktdatei:
from sklearn import tree
Konvertieren Sie mit dem
Graphviz-Visualizer die
Punktdatei in PNG, indem Sie Folgendes eingeben:
dot -Tpng images/tree.dot -o images/tree.pngErhalten Sie einen vollständigen Entscheidungsbaum:

Ein bisschen umständlich! Obwohl dieser Baum nur 6 Schichten tief ist, ist es schwierig, alle Übergänge zu verfolgen. Lassen Sie uns den Funktionsaufruf
export_graphviz ändern und die Tiefe des Baums auf zwei Ebenen beschränken:
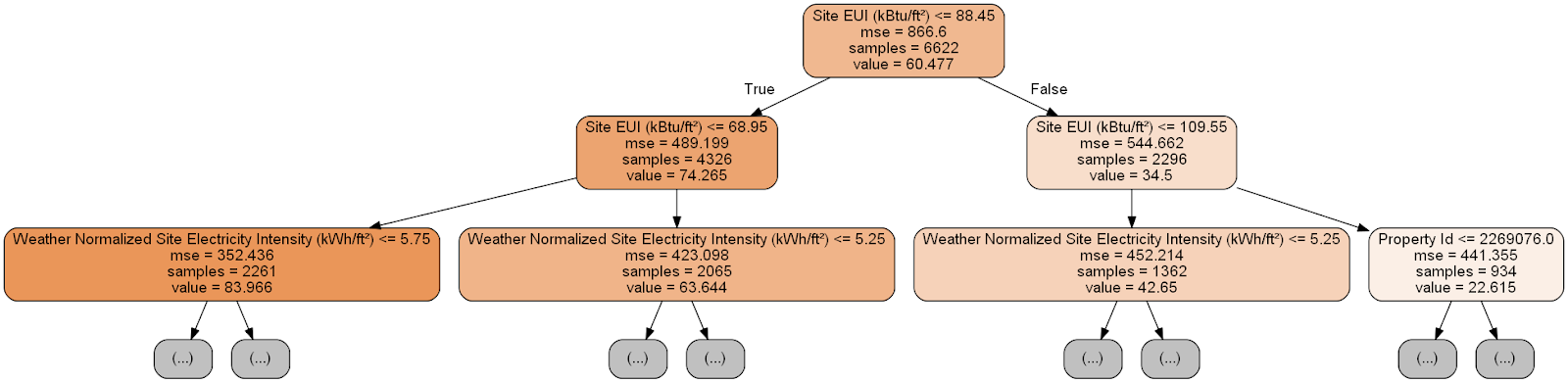
Jeder Knoten (Rechteck) des Baums enthält vier Zeilen:
- Gestellte Frage zum Wert eines der Zeichen einer bestimmten Dimension: Es hängt davon ab, in welche Richtung wir diesen Knoten verlassen.
Mse ist ein Maß für den Fehler in einem Knoten.Samples - Die Anzahl der Datenproben (Messungen) im Knoten.Value - Zielbewertung für alle Datenproben im Knoten.
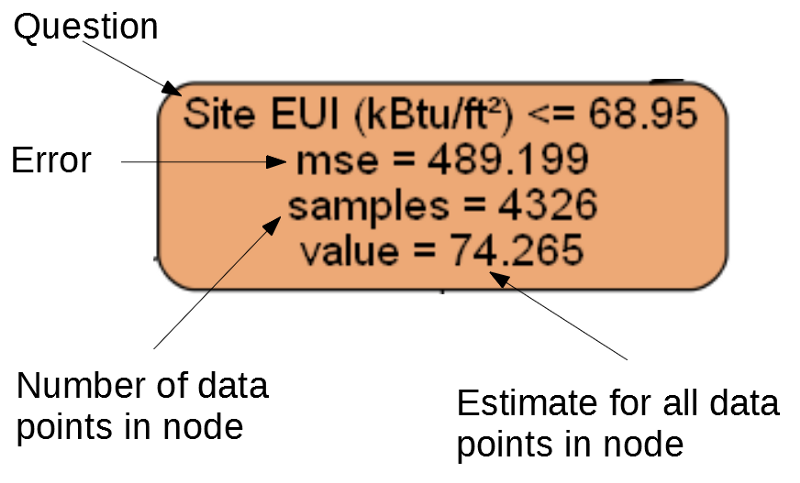 Separater Knoten.
Separater Knoten.(Blätter enthalten nur 2. –4., Da sie die endgültige Punktzahl darstellen und keine untergeordneten Knoten haben).
Die Prognose für eine bestimmte Messung im Entscheidungsbaum beginnt am obersten Knoten - der Wurzel - und steigt dann im Baum ab. In jedem Knoten müssen Sie die gestellte Frage mit „Ja“ oder „Nein“ beantworten. In der vorherigen Abbildung wird beispielsweise gefragt: "Ist das Site-EUI-Gebäude kleiner oder gleich 68,95?" Wenn ja, geht der Algorithmus zum rechten untergeordneten Knoten, wenn nicht, dann zum linken.
Dieser Vorgang wird auf jeder Schicht des Baums wiederholt, bis der Algorithmus den Blattknoten auf der letzten Schicht erreicht (diese Knoten sind in der Abbildung mit dem reduzierten Baum nicht dargestellt). Die Prognose für jede Dimension im Arbeitsblatt ist
value . Wenn mehrere Messungen auf dem Blatt eingehen, erhält jede von ihnen dieselbe Prognose. Mit zunehmender Tiefe des Baums nimmt der Fehler in den Trainingsdaten ab, da mehr Blätter vorhanden sind und die Proben sorgfältiger aufgeteilt werden. Ein zu tiefer Baum führt jedoch zu einer
Umschulung der Trainingsdaten und kann keine Testdaten verallgemeinern.
Im
zweiten Artikel legen wir die Anzahl der Modellhyperparameter fest, die jeden Baum steuern, z. B. die maximale Tiefe des Baums und die minimale Anzahl von Proben, die für jedes Blatt benötigt werden. Diese beiden Parameter wirken sich stark auf das Gleichgewicht zwischen Über- und Unterlernen aus. Durch die Visualisierung des Entscheidungsbaums können wir verstehen, wie diese Einstellungen funktionieren.
Obwohl wir nicht alle Bäume im Modell untersuchen können, hilft eine Analyse eines von ihnen zu verstehen, wie jeder „Schüler“ vorhersagt. Diese auf Flussdiagrammen basierende Methode ist sehr ähnlich der Art und Weise, wie eine Person eine Entscheidung trifft.
Ensembles von Entscheidungsbäumen kombinieren Vorhersagen zahlreicher einzelner Bäume, sodass Sie genauere Modelle mit weniger Variabilität erstellen können. Solche Ensembles sind
sehr genau und leicht zu erklären.
Lokale interpretierbare modellabhängige Erklärungen (LIME)
Das letzte Werkzeug, mit dem Sie herausfinden können, wie unser Modell „denkt“. Mit LIME können Sie erklären,
wie eine einzelne Prognose für jedes maschinelle Lernmodell generiert wird . Zu diesem Zweck wird lokal neben einigen Messungen ein vereinfachtes Modell auf der Grundlage eines einfachen Modells wie der linearen Regression erstellt (Details werden in dieser Arbeit beschrieben:
https://arxiv.org/pdf/1602.04938.pdf ).
Wir werden die LIME-Methode verwenden, um die völlig fehlerhafte Vorhersage unseres Modells zu untersuchen und zu verstehen, warum es falsch ist.
Zuerst finden wir diese falsche Prognose. Dazu trainieren wir das Modell, generieren eine Prognose und wählen den Wert mit dem größten Fehler aus:
from sklearn.ensemble import GradientBoostingRegressor
Vorhersage: 12.8615
Istwert: 100.0000Dann erstellen wir einen Erklärer und geben ihm die Trainingsdaten, Modusinformationen, Beschriftungen für die Trainingsdaten und die Namen der Attribute. Jetzt können Sie die Beobachtungsdaten und die Prognosefunktion an den Erklärenden weitergeben und ihn dann bitten, den Grund für den Prognosefehler zu erläutern.
import lime
Prognoseerklärungstabelle:
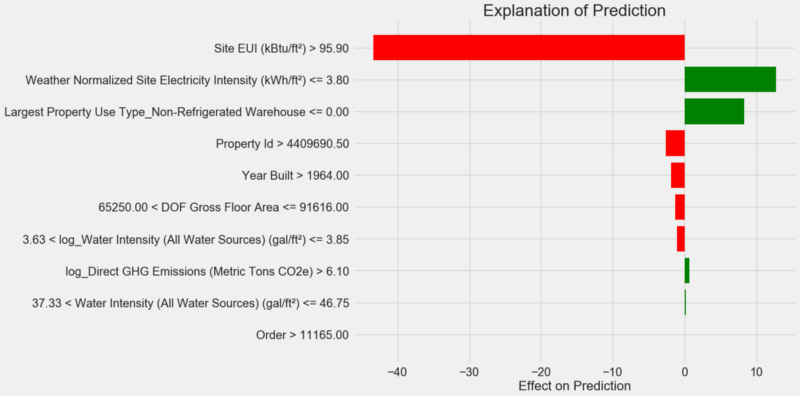
So interpretieren Sie das Diagramm: Jeder Datensatz entlang der Y-Achse gibt einen Wert der Variablen an, und die roten und grünen Balken geben den Einfluss dieses Werts auf die Prognose wieder. Zum Beispiel
Site EUI der Einfluss des
Site EUI laut oberem Datensatz mehr als 95,90, sodass etwa 40 Punkte von der Prognose abgezogen werden. Gemäß dem zweiten Datensatz
Weather Normalized Site Electricity Intensity der Einfluss der
Weather Normalized Site Electricity Intensity weniger als 3,80, und daher werden der Vorhersage etwa 10 Punkte hinzugefügt. Die endgültige Prognose ist die Summe des Abschnitts und der Auswirkungen jedes der aufgelisteten Werte.
Schauen wir es uns anders an und rufen die Methode
.show_in_notebook() :

Der Entscheidungsprozess des Modells wird links angezeigt: Die Auswirkung jeder Variablen auf die Prognose wird visuell angezeigt. Die Tabelle rechts zeigt die tatsächlichen Werte der Variablen für eine bestimmte Messung.
In diesem Fall hat das Modell ungefähr 12 Punkte vorhergesagt, aber tatsächlich waren es 100. Zunächst fragen Sie sich vielleicht, warum dies passiert ist. Wenn Sie jedoch die Erklärung analysieren, stellt sich heraus, dass dies keine äußerst kühne Annahme ist, sondern das Berechnungsergebnis auf bestimmten Werten basiert.
Site EUI war relativ hoch und man konnte einen niedrigen Energy Star Score erwarten (da er stark vom EUI beeinflusst wird), was unser Modell tat. In diesem Fall stellte sich diese Logik jedoch als falsch heraus, da das Gebäude tatsächlich den höchsten Energy Star Score erhielt - 100.
Modellfehler können Sie verärgern, aber solche Erklärungen helfen Ihnen zu verstehen, warum das Modell falsch war. Darüber hinaus können Sie dank der Erklärungen herausfinden, warum das Gebäude trotz des hohen EUI-Werts die höchste Punktzahl erzielt hat. Vielleicht lernen wir etwas Neues über unsere Aufgabe, das sich unserer Aufmerksamkeit entziehen würde, wenn wir nicht anfangen würden, Modellfehler zu analysieren. Solche Tools sind nicht ideal, können jedoch das Verständnis des Modells erheblich erleichtern und
bessere Entscheidungen treffen .
Dokumentation der Arbeit und Präsentation der Ergebnisse
Viele Projekte widmen Dokumentation und Berichten wenig Aufmerksamkeit. Sie können die beste Analyse der Welt durchführen, aber wenn Sie
die Ergebnisse nicht richtig präsentieren , spielen sie keine Rolle!
Durch die Dokumentation eines Datenanalyseprojekts packen wir alle Versionen der Daten und des Codes, damit andere Personen das Projekt reproduzieren oder sammeln können. Denken Sie daran, dass Code häufiger gelesen als geschrieben wird. Daher sollte unsere Arbeit anderen Menschen und uns klar sein, wenn wir in einigen Monaten darauf zurückkommen. Fügen Sie daher nützliche Kommentare in den Code ein und erläutern Sie Ihre Entscheidungen.
Jupyter-Notizbücher sind ein großartiges Dokumentationswerkzeug, mit dem Sie zuerst Lösungen erklären und dann Code anzeigen können.
Jupyter Notebook ist auch eine gute Plattform für die Interaktion mit anderen Spezialisten. Mit den
Erweiterungen für Notizbücher können Sie
den Code aus dem Abschlussbericht ausblenden , denn egal wie schwer es zu glauben ist, nicht jeder möchte eine Menge Code im Dokument sehen!
Möglicherweise möchten Sie nicht drücken, sondern alle Details anzeigen. Es ist jedoch wichtig
, dass Sie Ihr Publikum verstehen, wenn Sie Ihr Projekt präsentieren, und
einen entsprechenden Bericht erstellen . Hier ist ein Beispiel für eine Zusammenfassung des Wesens unseres Projekts:
- Mithilfe von Daten zum Energieverbrauch von Gebäuden in New York können Sie ein Modell erstellen, das die Anzahl der Energy Star Points mit einem Fehler von 9,1 Punkten vorhersagt.
- Standort-EUI und wetternormalisierte Stromintensität sind die Hauptfaktoren, die die Prognose beeinflussen.
Wir haben eine detaillierte Beschreibung und Schlussfolgerungen in das Jupyter-Notizbuch geschrieben, aber anstelle von PDF haben wir die .tex-Datei in
Latex konvertiert, die wir dann in
texStudio bearbeitet
haben , und die
resultierende Version wurde in PDF konvertiert. Tatsache ist, dass das Standard-Exportergebnis von Jupyter nach PDF recht anständig aussieht, aber in nur wenigen Minuten der Bearbeitung erheblich verbessert werden kann. Darüber hinaus ist Latex ein leistungsstarkes Dokumentvorbereitungssystem, dessen Besitz nützlich ist.
Letztendlich wird der Wert unserer Arbeit durch die Entscheidungen bestimmt, die sie treffen, und es ist sehr wichtig, „die Waren persönlich liefern zu können“. Durch die korrekte Dokumentation helfen wir anderen Menschen, unsere Ergebnisse zu reproduzieren, und geben uns Feedback, damit wir erfahrener werden und uns auf die zukünftigen Ergebnisse verlassen können.
Schlussfolgerungen
In unserer Publikationsreihe haben wir ein Tutorial zum maschinellen Lernen von Anfang bis Ende behandelt. Wir haben zuerst die Daten gelöscht, dann ein Modell erstellt und am Ende gelernt, wie man sie interpretiert. Erinnern Sie sich an die allgemeine Struktur des maschinellen Lernprojekts:
- Daten bereinigen und formatieren.
- Explorative Datenanalyse.
- Design und Auswahl der Funktionen.
- Vergleich der Metriken mehrerer Modelle für maschinelles Lernen.
- Hyperparametrische Abstimmung des besten Modells.
- Bewertung des besten Modells anhand eines Testdatensatzes.
- Interpretation der Ergebnisse des Modells.
- Schlussfolgerungen und gut dokumentierter Bericht.
Die Anzahl der Schritte kann je nach Projekt variieren, und maschinelles Lernen ist häufig eher iterativ als linear. Daher hilft Ihnen dieser Leitfaden in Zukunft. Wir hoffen, dass Sie Ihre Projekte jetzt sicher umsetzen können, aber denken Sie daran: Niemand handelt alleine! Wenn Sie Hilfe benötigen, gibt es viele sehr nützliche Communities, in denen Sie beraten werden.
Diese Quellen können Ihnen helfen: