Die Entwicklung tiefer neuronaler Netze zur Bilderkennung haucht den bereits bekannten Forschungsgebieten des maschinellen Lernens neues Leben ein. Ein solcher Bereich ist die Domänenanpassung. Das Wesentliche dieser Anpassung besteht darin, das Modell anhand von Daten aus der Quelldomäne (Quelldomäne) so zu trainieren, dass es in der Zieldomäne (Zieldomäne) eine vergleichbare Qualität aufweist. Beispielsweise kann eine Quelldomäne synthetische Daten sein, die kostengünstig generiert werden können, und eine Zieldomäne können Benutzerfotos sein. Dann besteht die Aufgabe der Domänenanpassung darin, das Modell auf synthetischen Daten zu trainieren, die mit "realen" Objekten gut funktionieren.
In der Bildverarbeitungsgruppe Vision.BIZ.Ru arbeiten wir an verschiedenen angewandten Problemen, darunter häufig solche, für die nur wenige Trainingsdaten vorliegen. In diesen Fällen kann die Generierung synthetischer Daten und die Anpassung des darauf trainierten Modells sehr hilfreich sein. Ein gutes Beispiel für diesen Ansatz ist die Erkennung und Erkennung von Waren in Regalen eines Geschäfts. Es ist ziemlich mühsam, Fotos von solchen Regalen zu bekommen und sie zu markieren, aber sie können ganz einfach erstellt werden. Aus diesem Grund haben wir uns entschlossen, uns eingehender mit dem Thema Domänenanpassung zu befassen.

Studien zur Domänenanpassung wirken sich auf die Nutzung früherer Erfahrungen eines neuronalen Netzwerks bei einer neuen Aufgabe aus. Kann das Netzwerk einige Funktionen aus der Quelldomäne extrahieren und in der Zieldomäne verwenden? Obwohl ein neuronales Netzwerk beim maschinellen Lernen nur entfernt mit neuronalen Netzwerken im menschlichen Gehirn verwandt ist, besteht der heilige Gral der Forscher der künstlichen Intelligenz darin, neuronalen Netzwerken die Fähigkeiten einer Person beizubringen. Und die Menschen können frühere Erfahrungen und gesammelte Kenntnisse nutzen, um neue Konzepte zu verstehen.
Darüber hinaus kann die Domänenanpassung dazu beitragen, eines der grundlegenden Probleme des Deep Learning zu lösen: Um große Netzwerke mit hoher Erkennungsqualität zu trainieren, wird eine sehr große Datenmenge benötigt, die in der Praxis nicht immer verfügbar ist. Eine Lösung könnte darin bestehen, Domänenanpassungsmethoden für synthetische Daten zu verwenden, die in praktisch unbegrenzten Mengen generiert werden können.
Sehr oft gibt es bei angewandten Problemen einen Fall, in dem Daten von nur einer Domäne für das Training verfügbar sind und das Modell auf eine andere Domäne angewendet werden muss. Zum Beispiel kann das Netzwerk, das die ästhetische Qualität der Fotografie bestimmt, in einer Datenbank trainiert werden, die im Netzwerk verfügbar ist und auf der Amateur-Website gesammelt wird. Es ist geplant, dieses Netzwerk für normale Fotos zu verwenden, deren Qualitätsniveau sich im Durchschnitt vom Niveau eines Fotos von einer speziellen Foto-Site unterscheidet. Als Lösung können wir erwägen, das Modell an gewöhnliche unbeschriftete Fotos anzupassen.
Solche theoretischen und angewandten Fragen liegen im Bereich der Anpassung. In diesem Artikel werde ich über die wichtigsten Forschungsergebnisse in diesem Bereich sprechen, die auf Deep Learning basieren, sowie über Datensätze zum Vergleich verschiedener Methoden. Die Hauptidee der Anpassung an tiefe Domänen besteht darin, ein tiefes neuronales Netzwerk in der Quelldomäne zu trainieren, wodurch das Bild in eine solche Einbettung (normalerweise die letzte Schicht des Netzwerks) übersetzt wird, dass bei Verwendung in der Zieldomäne eine hohe Qualität erzielt wird.
Kernbenchmarks
Wie in jedem Bereich des maschinellen Lernens wird in der Domänenanpassung im Laufe der Zeit ein gewisser Forschungsaufwand angehäuft, der miteinander verglichen werden muss. Zu diesem Zweck entwickelt die Community Datensätze, auf deren Trainingsteil die Modelle trainiert und auf deren Testteil sie verglichen werden. Trotz der Tatsache, dass der Forschungsbereich der tiefen Domänenanpassung noch relativ jung ist, gibt es bereits eine relativ große Anzahl von Artikeln und Datenbanken, die in diesen Artikeln verwendet werden. Ich werde die wichtigsten auflisten und mich darauf konzentrieren, den Bereich der synthetischen Daten an „real“ anzupassen.
Zahlen
Nach der Tradition von Yann LeCun (einem der Pioniere des Deep Learning, Direktor von Facebook AI Research) sind die einfachsten Datensätze in der Computer Vision offenbar mit handgeschriebenen Zahlen oder Buchstaben verbunden. Es gibt mehrere Datensätze mit Zahlen, die ursprünglich zum Experimentieren mit Bilderkennungsmodellen erschienen sind. In Artikeln zur Domänenanpassung finden sich verschiedene Kombinationen in Quell-Ziel-Domänenpaaren. Unter diesen Datensätzen:
- MNIST - handschriftliche Zahlen, benötigt keine zusätzliche Präsentation;
- USPS - handschriftliche Zahlen in niedriger Auflösung;
- SVHN - Hausnummern mit Google Street View;
- Synth Numbers sind synthetische Zahlen, wie der Name schon sagt.
Unter dem Gesichtspunkt der Aufgabe, synthetische Daten für die Verwendung in der "realen" Welt zu trainieren, sind die Paare am interessantesten:
- Quelle: MNIST, Ziel: SVHN;
- Quelle: USPS, Ziel: MNIST;
- Quelle: Synth Numbers, Ziel: SVHN.

Die meisten Methoden haben Benchmarks für "digitale" Datensätze. Die anderen Arten von Domains finden sich jedoch weit entfernt von allen Artikeln.
Büro
Dieser Datensatz enthält 31 Kategorien verschiedener Elemente, von denen jedes in drei Domänen dargestellt wird: ein Bild von Amazon, ein Foto von einer Webcam und ein Foto von einer Digitalkamera.

Es ist nützlich, um zu überprüfen, wie das Modell auf das Hinzufügen von Hintergrund und Qualität zur Zieldomäne reagiert.
Verkehrszeichen
Ein weiteres Datensatzpaar zum Trainieren des Modells auf synthetische Daten und zum Anwenden auf "echte" Daten:
- Quelle: Synth Signs - Bilder von Verkehrszeichen, die so erzeugt wurden, dass sie wie echte Zeichen auf der Straße aussehen.
- Ziel: GTSRB ist eine ziemlich bekannte Erkennungsbasis mit Schildern von deutschen Straßen.

Ein Merkmal dieses Datenbankpaares ist, dass die Daten von Synth Signs den „echten“ Daten ziemlich ähnlich sind, sodass die Domänen ziemlich nahe beieinander liegen.
Aus dem Autofenster
Datensätze zur Segmentierung. Ein ziemlich interessantes Paar, das den realen Bedingungen am nächsten kommt. Die Quelldaten werden mit der Game Engine (GTA 5) abgerufen, und die Zieldaten stammen aus dem realen Leben. Ähnliche Ansätze werden verwendet, um Modelle zu trainieren, die in autonomen Autos verwendet werden.
- SYNTHIA- oder GTA 5-Engine - Bilder einer Stadtansicht aus einem Autofenster, die mit einer Game-Engine erstellt wurden;
- Stadtlandschaften - Bilder eines Autos aus 50 verschiedenen Städten.

VisDA
Dieser Datensatz wird in der Visual Domain Adaptation Challenge verwendet , die Teil eines Workshops zu ECCV und ICCV ist. Die Quelldomäne enthält 12 Kategorien von mit CAD generierten beschrifteten Objekten, z. B. ein Flugzeug, ein Pferd, eine Person usw. Die Zieldomäne enthält unbeschriftete Bilder aus denselben 12 Kategorien, die aus ImageNet stammen. In dem Wettbewerb, der 2018 stattfand, wurde die 13. Kategorie hinzugefügt: Unbekannt.
Wie Sie aus all dem sehen können, gibt es eine Menge interessanter und vielfältiger Datensätze für die Domänenanpassung. Sie können Modelle für verschiedene Aufgaben (Klassifizierung, Segmentierung, Erkennung) und verschiedene Bedingungen (synthetische Daten, Fotos, Straßenansichten) trainieren und testen.
Deep Domain Anpassung
Es gibt eine ziemlich umfangreiche und vielfältige Klassifizierung von Domänenanpassungsmethoden (siehe hier ). Ich werde in diesem Artikel eine vereinfachte Unterteilung der Methoden nach ihren Hauptmerkmalen geben. Moderne Methoden zur Anpassung tiefer Domänen lassen sich in drei große Gruppen einteilen:
- Diskrepanzbasiert : Ansätze, die auf der Minimierung des Abstands zwischen Vektordarstellungen in der Quell- und Zieldomäne basieren, indem dieser Abstand in die Verlustfunktion eingeführt wird.
- Adversarial-Based : Diese Ansätze verwenden die in GANs eingeführte Adversarial- Loss-Funktion, um ein domäneninvariantes Netzwerk zu trainieren. Die Methoden dieser Familie wurden in den letzten Jahren aktiv entwickelt.
- Gemischte Methoden , die keinen kontroversen Verlust verwenden, sondern Ideen aus der auf Diskrepanzen basierenden Familie sowie die neuesten Entwicklungen aus dem Deep Learning anwenden: Selbstsemblierung, neue Ebenen, Verlustfunktionen usw. Diese Ansätze zeigen die besten Ergebnisse im VisDA-Wettbewerb.
In jedem Abschnitt werden meiner Meinung nach einige grundlegende Ergebnisse der letzten 1-3 Jahre berücksichtigt.
Diskrepanzbasiert
Wenn das Problem der Anpassung eines Modells an neue Daten auftritt, fällt als Erstes die Verwendung der Feinabstimmung ein, d. H. Umschulung des Modells auf neue Daten. Berücksichtigen Sie dazu die Diskrepanz zwischen den Domänen. Diese Art der Domänenanpassung kann in drei Ansätze unterteilt werden: Klassenkriterium, statistisches Kriterium und Architekturkriterium.
Klassenkriterium
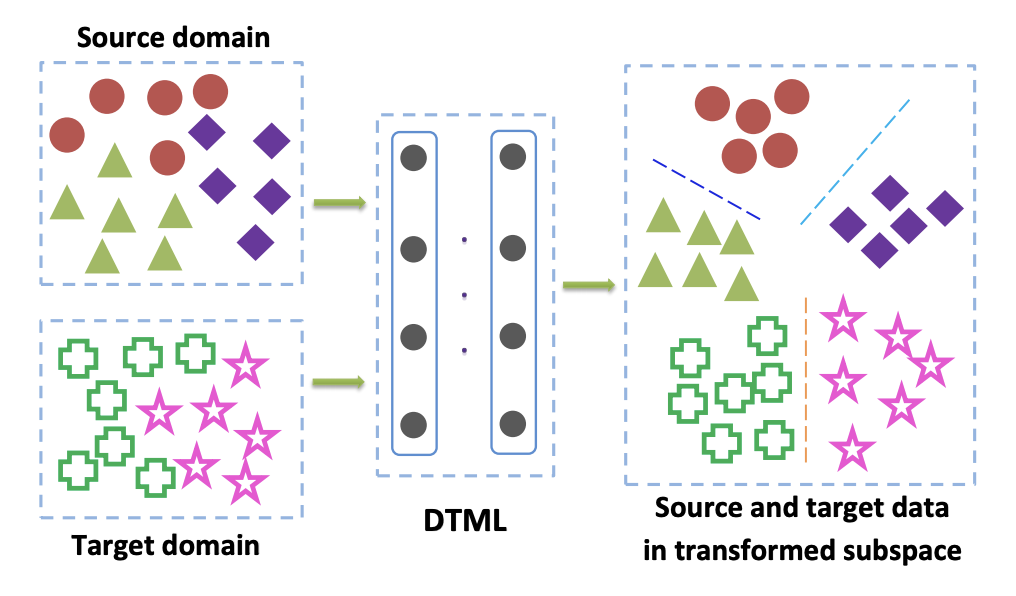
Methoden aus dieser Familie werden hauptsächlich verwendet, wenn wir Zugriff auf markierte Daten aus der Zieldomäne haben. Eine der beliebtesten Optionen für Klassenkriterien ist der Lernansatz für Deep-Transfer-Metriken . Wie der Name schon sagt, basiert es auf metrischem Lernen, dessen Kern darin besteht, eine solche Vektordarstellung zu trainieren, die aus einem neuronalen Netzwerk erhalten wird, dass Vertreter einer Klasse in dieser Darstellung gemäß einer bestimmten Metrik nahe beieinander liegen (am häufigsten verwendet) L 2 oder Kosinusmetriken). In dem Artikel Deep Transfer Metric Learning (DTML) wird ein Verlust, der aus der Summe der Begriffe besteht, verwendet, um diesen Ansatz zu implementieren:
- Die Nähe von Vertretern einer Klasse zueinander (Kompaktheit innerhalb der Klasse);
- Erhöhter Abstand zwischen Vertretern verschiedener Klassen (Trennbarkeit zwischen Klassen);
- MMD-Metrik (Maximum Mean Discrepancy) zwischen Domänen. Diese Metrik gehört zur Familie der statistischen Kriterien (siehe unten), wird jedoch auch im Klassenkriterium verwendet.
MMD zwischen Domains wird geschrieben als
MMD2(Ds,Dt)= Vert frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Vert2H,
wo phi(x) - Dies ist in unserem Fall ein Kern - eine Vektordarstellung des Netzwerks, xsi,i in1 ldotsM - Daten aus der Quelldomäne, xti,i in1 ldotsN - Daten aus der Zieldomäne. Wenn also die MMD-Metrik während des Trainings minimiert wird, wird ein solches Netzwerk ausgewählt phi(x) so dass seine durchschnittlichen Vektordarstellungen in beiden Domänen nahe beieinander liegen. Die Hauptidee von DTML:
Wenn die Daten in der Zieldomäne nicht gekennzeichnet sind (unbeaufsichtigte Domänenanpassung), bietet die in Mind the Class Weight Bias: Gewichtete maximale mittlere Diskrepanz für die unbeaufsichtigte Domänenanpassung beschriebene Methode an, das Modell in der Quelldomäne zu trainieren und es zum Abrufen von Pseudo-Labels (Pseudo-) zu verwenden Labels) in der Zieldomäne. Das heißt, Daten aus der Zieldomäne werden über das Netzwerk ausgeführt und das Ergebnis wird als Pseudo-Labels bezeichnet. Dann werden sie als Markup für die Zieldomäne verwendet, wodurch das MMD-Kriterium in der Verlustfunktion angewendet werden kann (mit unterschiedlichen Gewichten für die Komponenten, die für verschiedene Domänen verantwortlich sind).
Statistisches Kriterium
Mit dieser Familie verwandte Methoden werden verwendet, um das Problem der unbeaufsichtigten Domänenanpassung zu lösen. Der Fall, dass die Zieldomäne nicht zugewiesen ist, tritt bei vielen Problemen auf, und alle Methoden der Domänenanpassung, die später in diesem Artikel erläutert werden, lösen genau dieses Problem.
Auf statistischen Kriterien basierende Ansätze versuchen, den Unterschied zwischen den Verteilungen der Vektordarstellung des Netzwerks zu messen, die aus den Daten der Quell- und Zieldomäne erhalten werden. Sie verwenden dann die berechnete Differenz, um diese beiden Verteilungen zusammenzuführen.
Eines dieser Kriterien ist die oben bereits beschriebene maximale mittlere Diskrepanz (MMD) . Seine Varianten werden auf verschiedene Arten verwendet:
Die Diagramme dieser drei Methoden sind unten dargestellt. In ihnen werden die MMD-Varianten verwendet, um den Unterschied zwischen den Verteilungen auf den Schichten des Faltungsnetzwerks zu bestimmen, die auf die Quell- und Zieldomäne angewendet werden. Bitte beachten Sie, dass jeder von ihnen die MMD-Modifikation als Verlust zwischen Schichten von Faltungsnetzwerken verwendet (gelbe Zahlen im Diagramm).

Das CORAL- Kriterium (CORrelation ALignment) und seine Erweiterung mit Hilfe von Deep CORAL- Netzwerken zielen darauf ab, eine solche Darstellung von Daten zu lernen, damit Statistiken zweiter Ordnung zwischen Domänen maximal übereinstimmen. Hierzu werden Kovarianzmatrizen von Vektordarstellungen des Netzwerks verwendet. Die Konvergenz von Statistiken zweiter Ordnung in beiden Bereichen ermöglicht es in einigen Fällen, bessere Anpassungsergebnisse als bei MMD zu erzielen.
LCORAL= frac14d2 VertCS−CT Vert2F,
wo ||∗||2F Ist das Quadrat der Frobenius-Matrixnorm und Cs und Ct - Kovarianzmatrixdaten aus der Quell- bzw. Zieldomäne d - die Dimension der Vektordarstellung.
Im Office-Dataset beträgt die durchschnittliche Qualität der Anpassung mit Deep CORAL für Paare von Amazon- und Webcam-Domänen 72,1%. Bei Synth Signs -> GTSRB-Verkehrszeichendomänen ist das Ergebnis ebenfalls sehr durchschnittlich: 86,9% Genauigkeit in der Zieldomäne.
Die Entwicklung der Ideen von MMD und CORAL ist das CMD- Kriterium (Central Moment Discrepancy) , das die zentralen Momente der Daten aus den Quell- und Zieldomänen aller Aufträge bis vergleicht K inklusive ( K - Parameter des Algorithmus). Im Office-Dataset beträgt die durchschnittliche CMD-Anpassungsqualität für Paare von Amazon- und Webcam-Domänen 77,0%.
Architekturkriterium
Algorithmen dieses Typs basieren auf der Annahme, dass die Basisinformationen, die für die Anpassung an eine neue Domäne verantwortlich sind, in die Parameter eines neuronalen Netzwerks eingebettet sind.
In einer Reihe von Veröffentlichungen [1] , [2] werden beim Trainieren von Netzwerken für die Quell- und Zieldomäne unter Verwendung von Verlustfunktionen für jedes Schichtpaar Informationen, die in Bezug auf die Domäne unveränderlich sind, auf die Gewichte dieser Schichten untersucht. Ein Beispiel für solche Architekturen ist unten angegeben.
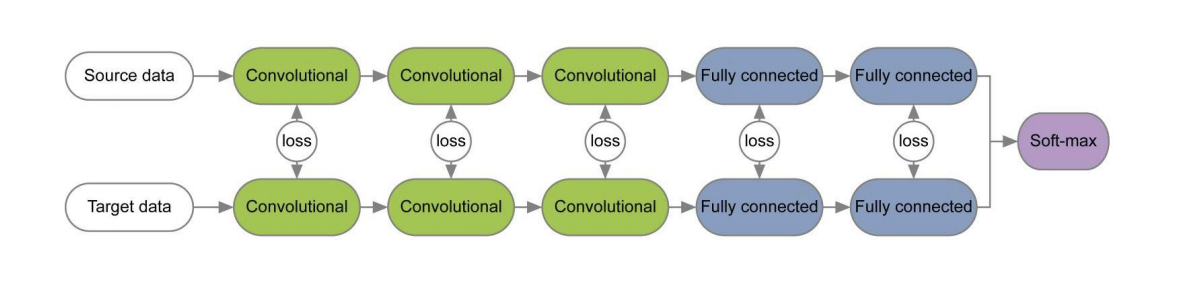
In dem Artikel „ Überprüfung der Chargennormalisierung zur praktischen Domänenanpassung“ wurde die Idee vertreten, dass die Netzwerkskalen Informationen zu den Klassen enthalten, in denen das Netzwerk studiert, und die Domäneninformationen in die Statistiken (Mittelwert und Standardabweichung) der Batch-Normalisierungsschichten (BN) eingebettet sind. Zur Anpassung ist es daher erforderlich, diese Statistiken für die Daten aus der Zieldomäne neu zu berechnen. Die Verwendung dieser Technik zusammen mit CORAL kann die Anpassungsqualität des Office-Datasets für Paare von Amazon- und Webcam-Domänen um bis zu 75,0% verbessern. Es wurde dann gezeigt, dass die Verwendung der Instance Normalization (IN) -Schicht anstelle von BN die Anpassungsqualität weiter verbessert. Im Gegensatz zu BN, das den Eingangstensor chargenweise normalisiert, berechnet IN Statistiken für die Normalisierung nach Kanälen und ist daher unabhängig von der Charge.
Widersprüchliche Ansätze
In den letzten 1-2 Jahren hängen die meisten Ergebnisse bei der Anpassung an tiefe Domänen mit dem kontradiktorischen Ansatz zusammen. Dies ist hauptsächlich auf die rasche Entwicklung und Popularität der generativen kontradiktorischen Netzwerke (GAN) zurückzuführen , da der kontradiktorische Ansatz zur Domänenanpassung im Training dieselbe kontradiktorische Zielfunktion verwendet wie das GAN. Durch die Optimierung minimieren solche Methoden zur Anpassung tiefer Domänen den Abstand zwischen den empirischen Verteilungen von Vektordatendarstellungen auf den Quell- und Zieldomänen. Indem sie das Netzwerk auf diese Weise trainieren, versuchen sie, es in Bezug auf die Domäne unveränderlich zu machen.
GAN besteht aus zwei Modellen: Generator G , an dessen Ausgabe Daten von einer bestimmten Zielverteilung erhalten werden; und Diskriminator D , der bestimmt, ob die Daten aus dem Trainingssatz oder mit generiert werden G . Diese beiden Modelle werden mit der gegnerischen Zielfunktion trainiert:
minG maxDV(D,G)= mathbbEx simpdata(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))].
Mit einem solchen Training lernt der Generator, den Diskriminator zu „betrügen“, wodurch Sie die Verteilung der Ziel- und Quelldomänen näher bringen können.
Bei der kontradiktorischen Domänenanpassung gibt es zwei große Ansätze, die sich darin unterscheiden, ob ein Generator verwendet wird oder nicht. G .
Nicht generative Modelle
Ein Schlüsselmerkmal der Methoden aus dieser Familie ist das Training eines neuronalen Netzwerks mit einer Vektordarstellung, die in Bezug auf die Quell- und Zieldomäne unveränderlich ist. Dann kann das in der markierten Quelldomäne trainierte Netzwerk idealerweise in der Zieldomäne verwendet werden - praktisch ohne Verlust der Klassifizierungsqualität.
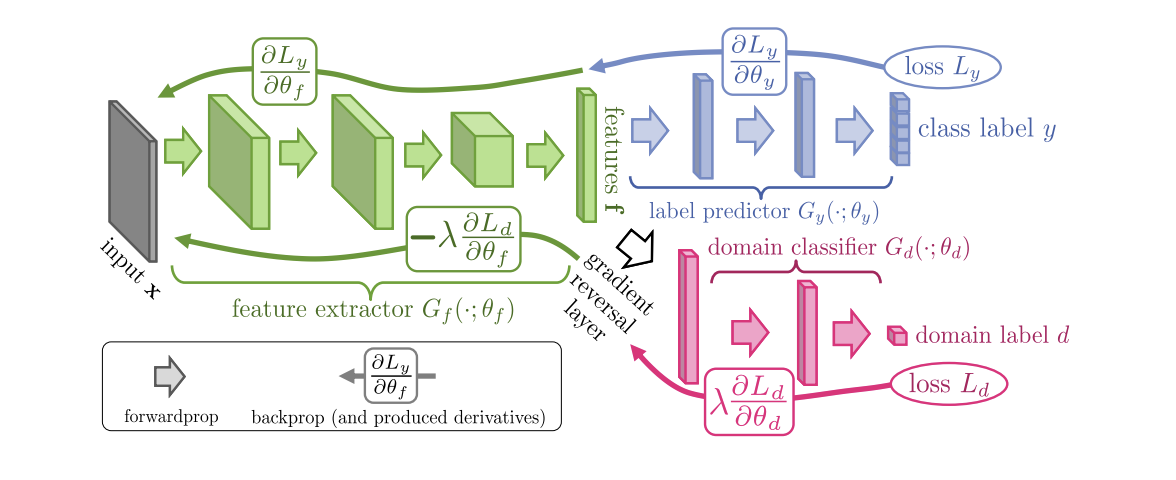
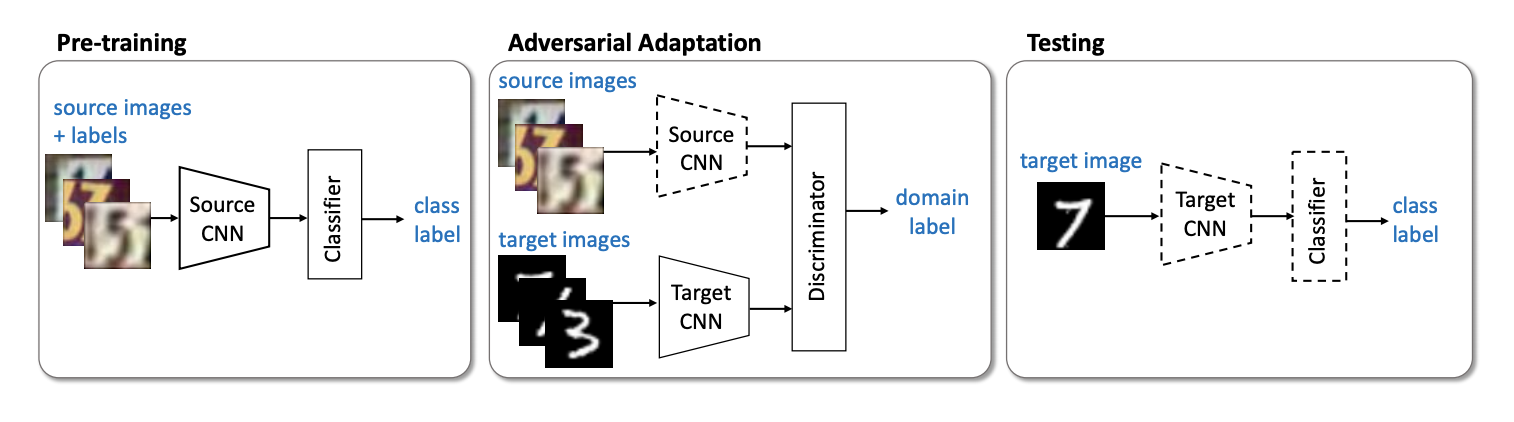
Der 2015 eingeführte DANN-Algorithmus ( Code ) (Domain-Adversarial Training of Neural Networks ) besteht aus drei Teilen:
- Das Hauptnetzwerk, mit dessen Hilfe eine Vektordarstellung (Merkmalsextraktor) erhalten wird (der grüne Teil in der folgenden Abbildung);
- "Köpfe", die für die Klassifizierung in der Quelldomäne verantwortlich sind (blauer Teil in der Abbildung);
- Ein „Kopf“, der lernt, Daten von der Quelldomäne von der Zieldomäne zu unterscheiden (der rote Teil in der Abbildung).
Beim Training mit Gradientenabstieg (SGD) (Pfeile zur Eingabe in der Abbildung) werden Klassifizierung und Domänenverluste minimiert. Zusätzlich wird während der Rückwärtsausbreitung eines Lernfehlers für den für die Domänen verantwortlichen „Kopf“ die Gradientenumkehrschicht (der schwarze Teil in der Abbildung) verwendet, die den durch sie fließenden Gradienten mit einer negativen Konstante multipliziert und den Domänenverlust erhöht. Dies stellt sicher, dass die Verteilungen der Vektordarstellungen auf beiden Domänen nahe beieinander liegen.
DANN-Benchmark-Ergebnisse:
- Auf einem Paar digitaler Domänen Synth Numbers -> SVHN: 91,09%.
- Bei Synth Signs -> GTSRB-Verkehrszeichen übertrifft es CORAL mit einem Ergebnis von 88,7%.
- Im Office-Dataset beträgt die durchschnittliche Anpassungsqualität für Paare von Amazon- und Webcam-Domänen 73,0%.
Der nächste wichtige Vertreter der nicht generativen Modellfamilie ist die ADDA-Methode ( Adversarial Discriminative Domain Adaptation) ( Code ), bei der das Netzwerk für die Quelldomäne und das Netzwerk für die Zieldomäne getrennt werden. Der Algorithmus besteht aus folgenden Schritten:
- Zunächst trainieren wir das Klassifizierungsnetzwerk in der Quelldomäne. Wir bezeichnen seine Vektordarstellung Ms und mathbfXs - Quelldomäne.
- Initialisieren Sie nun das neuronale Netzwerk für die Zieldomäne mithilfe des trainierten Netzwerks aus dem vorherigen Schritt. Lass sie Mt und mathbfXt - Zieldomäne.
- Kommen wir zum kontradiktorischen Training: Wir werden den Diskriminator trainieren D bei fest Ms und Mt unter Verwendung der folgenden Zielfunktion:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt))]
- Diskriminator einfrieren und umschulten Mt auf der Zieldomäne:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[ logD(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K .
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
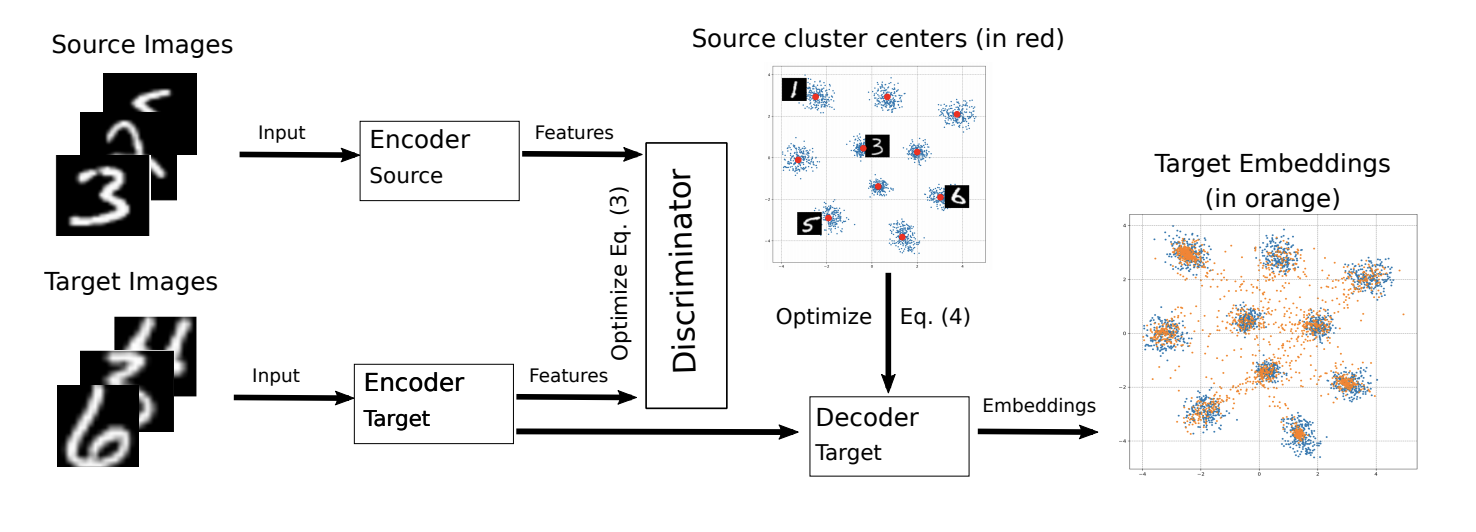
M-ADDA USPS -> MNIST 94,0 %.
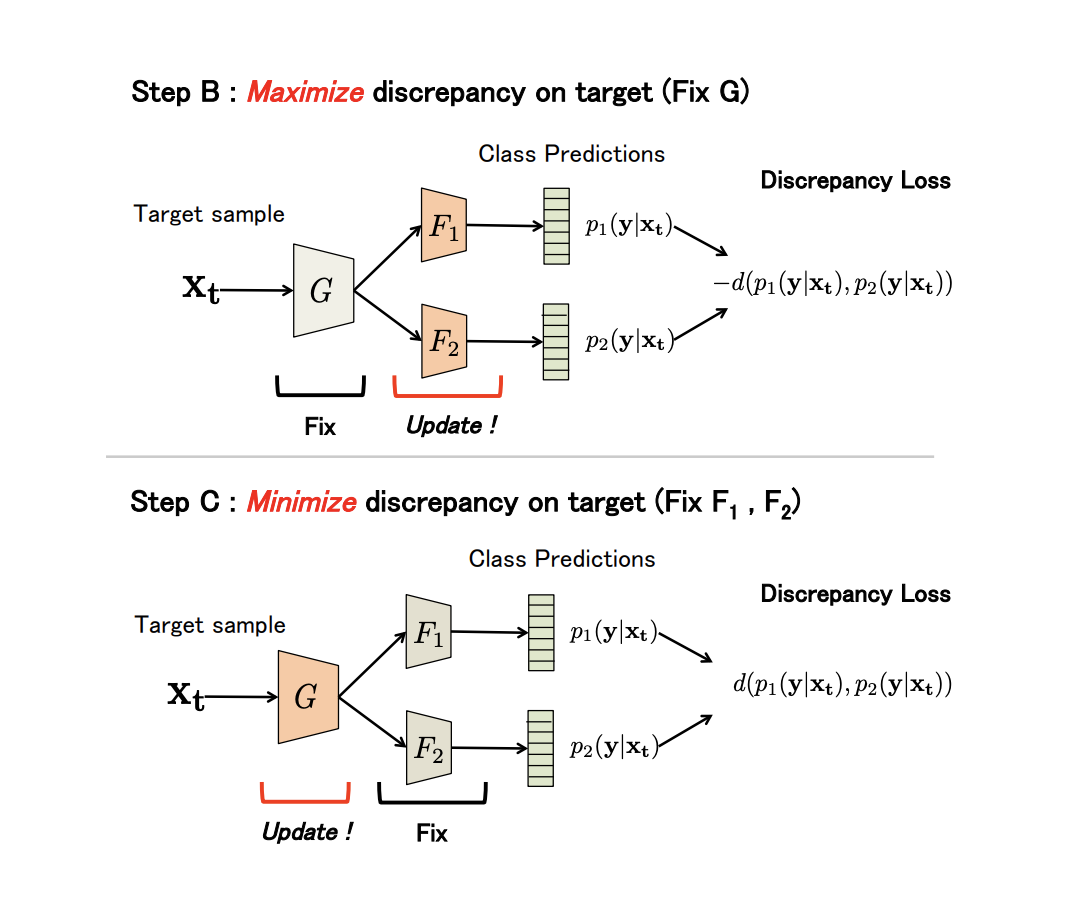
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 und F2 — , . , G , F1 und F2 -; , ; , ; F1 und F2 .
, adversarial-, G , .
(Discrepancy Loss)
d(p1,p2)=1KK∑k=1|p1k−p2k|,
K — , p1kp2k — softmax k - F1 und F2 entsprechend.
3 :
- A . G , F1 und F2 .
- B. B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
Wir untersuchten die Hauptdatensätze für Domänenanpassung, diskrepanzbasierte Ansätze: Klassenkriterium, statistisches Kriterium und Architekturkriterium sowie die erste nicht generative Familie von kontradiktorischen Methoden. Modelle aus diesen Ansätzen zeigen eine gute Leistung bei Benchmarks und sind auf viele Anpassungsaufgaben anwendbar. Im nächsten Teil werden wir die komplexesten und effektivsten Ansätze betrachten: generative Modelle und gemischte, nicht kontradiktorische Methoden.