Was ist der Schlüssel zum erfolgreichen Einrichten von Continuous Delivery für Projekte? Gut koordinierte Arbeit von Entwicklungs-, Test- und Infrastrukturingenieuren. Danke, Mütze, wie sie sagen :) Aber wie kann man es in die Praxis umsetzen? In diesem Artikel werden wir unsere Best Practices zur Organisation und Implementierung all dessen vorstellen.
Wir haben die grundlegenden Grundlagen für uns in einem Spickzettel zusammengefasst und mit Ihnen geteilt:
Erfahrene Ingenieure werden wahrscheinlich nichts Neues aus dem Artikel lernen, aber wir hoffen, dass diese Informationen für Anfänger nützlich sind.

Was sind die Anforderungen und wie werden sie charakterisiert?
Jedes Projekt hat eine Reihe von Anforderungen. Es ist wichtig, alle zu verstehen und nicht zu verwirren.
Geschäftsanforderungen bestimmen, was ein System aus geschäftlicher Sicht tun soll.
Beispiel: Die Anwendung sollte es dem Benutzer ermöglichen, Tickets und zusätzliche Dienste zu verkaufen, um den Verkauf von Agenten zu steigern.Benutzeranforderungen beschreiben die Ziele und
Vorgaben von Benutzern, die im System arbeiten, um Geschäftsanforderungen zu implementieren. Benutzeranforderungen werden häufig als Benutzerfälle dargestellt.
Zum Beispiel: Als Benutzer muss ich Dienste für Meilen verkaufen.Funktionale Anforderungen - was das System tun soll. Bestimmen Sie die Funktionalität (das Verhalten) des Systems, die von Entwicklern erstellt werden muss, damit Benutzer die Benutzeranforderungen erfüllen können.
Nicht funktionale Anforderungen - wie das System funktionieren soll. Dies umfasst Anforderungen an Leistung, Qualität, Einschränkungen, Benutzerfreundlichkeit usw.
Aufgabentypen und die Reihenfolge ihrer Beschreibung im Issue-Tracker
Daher haben wir die Arten von Anforderungen beschrieben. Jetzt werden wir sie in Aufgabentypen aufteilen, jeden Typ entschlüsseln und erklären, wie man ihn richtig beschreibt.

Beginnen wir mit dem epischsten, dh mit dem epischsten.
Epic ist eine häufige Aufgabe, bei der alle User Stories unter Berücksichtigung der Entwicklungszeit des Dienstes gesammelt werden. Es beschreibt den Hauptzweck eines Produkts oder einer Dienstleistung. Das Hauptziel von Epic ist es, Aufgaben zu sammeln und an einem Ort zu speichern, unabhängig davon, welche neuen Anforderungen an das Produkt gestellt werden. Epic ist immer mehr als eine User Story und passt möglicherweise nicht einmal in eine Iteration.
Mit der Lösung des epischen Problems können Sie
MVP (Minimal Viable Product) erstellen - das Minimum Viable Product. Mit anderen Worten, was muss freigegeben werden, um das Produkt basierend auf dem Feedback der Endbenutzer zu lernen und anzupassen.
Wie unterscheidet sich Epic von User Story?
- Epic ist nur eine große User Story, deren Kennzeichen das Vorhandensein eines klaren Werts für den User ist.
- Wenn wir anfangen, User Stories zu erstellen, d. H. Anforderungen für ein Projekt zu sammeln, wechseln wir normalerweise von allgemein zu speziell - zuerst bestimmen wir das Konzept des Projekts, wählen die Hauptpersonen (Benutzer des Systems) aus, erstellen eine Liste der Hauptfunktionen, und dann werden diese Funktionen in separaten Wünschen detailliert beschrieben. User Story.
Die Beschreibung von Epic lautet wie folgt:
- Titel / Zusammenfassung Titel - Der Name der neuen Funktionalität.
- Beschreibung / Beschreibung - wird nach dem Muster geschrieben:
Die Rolle des Benutzers (als solcher Benutzer, ich ...) / Benutzeraktion (ich möchte etwas tun ...) / Das Ergebnis der Aktion (um ein solches Ergebnis zu erzielen, dass ...) / Interesse oder Nutzen (ermöglicht es mir, solche und solche Vorteile zu erhalten ...). - Ein Beispiel für einen Implementierungsplan oder eine kurze Beschreibung der wichtigsten User Stories, die als Teil von Epic mit MVP implementiert werden.
- Anhänge / Anhänge - Korrespondenz, Technologie und andere notwendige Informationen anhängen.
Wie man User Story und Tech Story macht
Der Unterschied zwischen User Story und Tech Story besteht darin, dass sich Tech Story auf funktionale Anforderungen bezieht, die bei der Entwicklung des Produkts in der Aufgabe berücksichtigt und beschrieben werden müssen. Und in der Rolle der Verbraucher sind hier Teile des Systems.
Sie zu beschreiben ist einfach. Die Hauptsache ist, warum all dies getan wird.

Die Reihenfolge der Beschreibung der User Storys ist ziemlich normal:
- Titel / Zusammenfassung / Titel - eine kurze Beschreibung der neuen Funktionen oder Verbesserungen in einer Sprache, die für den Kunden verständlich ist.
- Beschreibung / Beschreibung enthält das Hauptziel und das gewünschte Ergebnis. Wie <Benutzerrolle> möchte ich <erhalten> mit dem Ziel <Ergebnis von Aktionen>.
- Akzeptanzkriterien sind eine Liste vorrangiger Produktkriterien. Das heißt, eine messbare Definition dessen, was mit dem Produkt getan werden soll, damit es von den Projektbeteiligten akzeptiert wird.
- Technische Hinweise, Modelle, Layouts, Seitenlayouts.
- Anhänge / Anhänge - alle notwendigen Technologien, Dokumente, Korrespondenz mit dem Kunden.
Wie man Fehler beschreibt
Welche Informationen sollten bei der Meldung eines Fehlers angegeben werden:
1.
Titel / Zusammenfassung / Titel beschreibt kurz das Wesentliche des Fehlers und gibt den Ort des Problems an.
2. Die Beschreibung enthält die folgenden Schritte:
• wie die Fehler- / Wiedergabeschritte reproduziert werden,
• aktuelles Ergebnis,
• erwartetes Ergebnis.
3.
Anhänge / Anhänge - alle erforderlichen Protokolle, Screenshots, Links zu Kibana und anderen Dateien.
4.
Umgebung - Eine Marke, in der der Fehler reproduziert wird, und die Kategorie, zu der das Problem gehört. Zum Beispiel ein UI-Fehler, ein CORE-Fehler, ein SWS-Fehler usw.
5. Mit
Priorität kann jedes Mitglied des Teams die Schwere des Problems beurteilen und der Manager kann es in der Liste der ersten Kandidaten für den Sprint sehen.
Und vergessen Sie nicht, die richtige Prioritätsstufe einzustellen :)
Nachdem wir die allgemeinen Arbeitsprinzipien verstanden haben, erklären wir Ihnen, wie Sie die Bereitstellungspipeline organisieren.
Konfiguration der Bereitstellungspipeline
Um die Bereitstellung unserer Services für die Produktion zu beschleunigen, führen wir eine neue Bereitstellungspipeline ein und verwenden GitFlow, um mit Code zu arbeiten.
Um dies schnell und dynamisch zu tun, haben wir mehrere GitLab-Läufer bereitgestellt, die alle Push-Aufgaben der Entwickler ausgeführt haben. Dank des Ansatzes von GitLab Flow verfügen wir über mehrere Server: Entwickeln, Qualitätssicherung, Release-Kandidat und Produktion.
Die kontinuierliche Integration begann mit dem Sammeln und Ausführen von Tests für jedes Commit, dem Ausführen von Komponententests und Integrationstests sowie dem Hinzufügen von Artefakten zur Anwendungsbereitstellung.

Die Entwicklung erfolgt folgendermaßen:
- Der Entwickler fügt neue Funktionen in einem separaten Zweig (Feature-Zweig) hinzu. Danach erstellt er eine Anforderung zum Zusammenführen seines Zweigs mit dem Hauptentwicklungszweig (Zusammenführungsanforderung zum Entwickeln des Zweigs).
- Andere Entwickler sehen sich die Zusammenführungsanforderung an, akzeptieren sie (oder nicht) und korrigieren die Kommentare. Nach dem Zusammenführen entfaltet sich im Trunk-Zweig eine spezielle Umgebung, an der Tests zum Erhöhen der Umgebung durchgeführt werden.
- Wenn alle diese Schritte abgeschlossen sind, nimmt der QS-Techniker die Änderungen in seiner QA-Niederlassung vor und führt Tests durch.
- Wenn der QS-Techniker mit der geleisteten Arbeit einverstanden ist, werden die Änderungen in den Zweig Release-Candidate übernommen und in einer Umgebung bereitgestellt, auf die externe Benutzer zugreifen können. In dieser Umgebung akzeptiert und überprüft der Kunde Technologien. Dann destillieren wir alles in die Produktion.
Wenn irgendwann Fehler auftreten, lösen wir diese in diesem Zweig und veröffentlichen das Ergebnis in Develop.
Wir haben auch ein kleines Plugin erstellt, damit Redmine uns mitteilen kann, in welchem Stadium sich die Funktion befindet. Auf diese Weise können Tester bewerten, in welcher Phase Sie eine Verbindung zur Aufgabe herstellen müssen, und Entwickler können Fehler korrigieren. Sie sehen also, zu welchem Zeitpunkt der Fehler aufgetreten ist, können zu einem bestimmten Zweig gehen und ihn dort spielen.
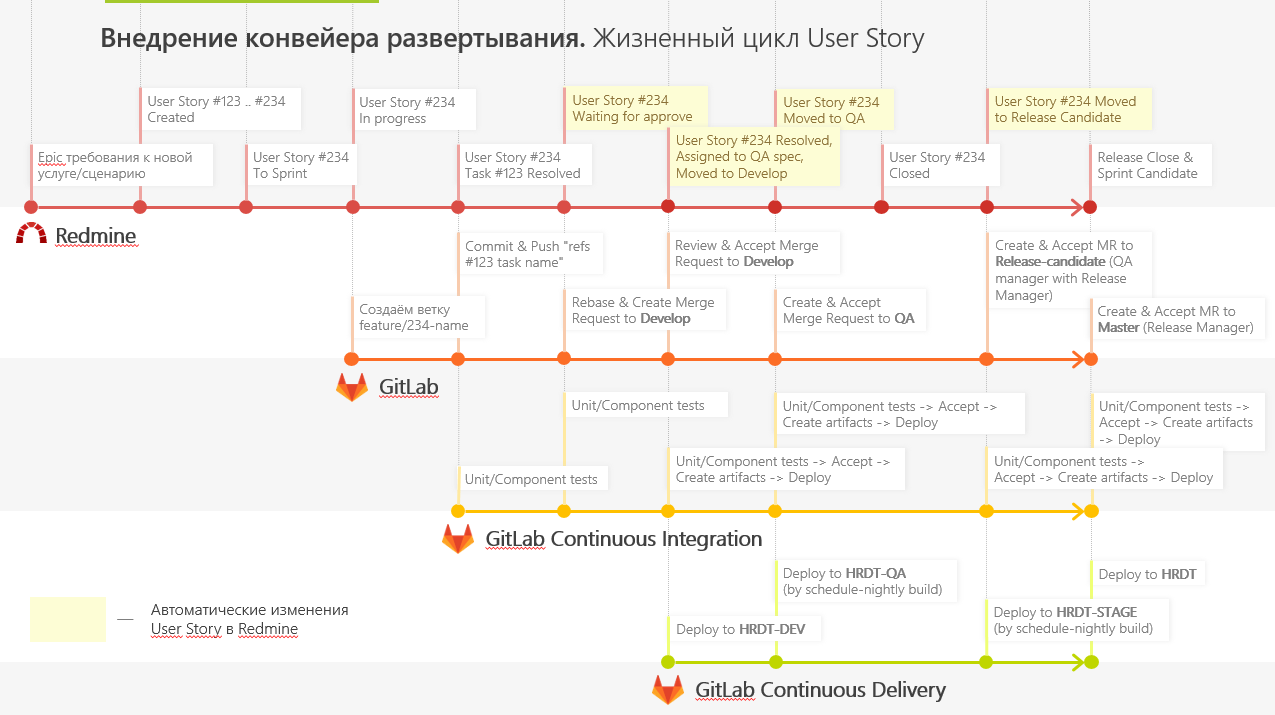
Wir hoffen, Sie finden es hilfreich.