Spam in sozialen Netzwerken und Instant Messenger ist ein Schmerz. Schmerz für ehrliche Benutzer und Entwickler. Wie sie es in Badoo bekämpfen, sagte Mikhail Ovchinnikov auf Highload ++, dann die Textversion dieses Berichts.
Über den Sprecher: Mikhail Ovchinnikov arbeitet bei Badoo und ist seit fünf Jahren gegen Spam.
Badoo hat 390 Millionen registrierte Benutzer (Daten für Oktober 2017). Wenn wir die Größe des Publikums des Dienstes mit der Bevölkerung Russlands vergleichen, können wir sagen, dass laut Statistik alle 100 Millionen Menschen von 500.000 Polizisten geschützt werden und in Badoo nur ein Antispam-Mitarbeiter alle 100 Millionen Benutzer vor Spam schützt. Aber selbst eine so kleine Anzahl von Programmierern kann Benutzer vor verschiedenen Problemen im Internet schützen.
Wir haben ein großes Publikum und es kann verschiedene Benutzer haben:
- Gut und sehr gut, unsere bevorzugten zahlenden Kunden;
- Die schlechten sind diejenigen, die im Gegenteil versuchen, mit uns Geld zu verdienen: Sie senden Spam, betrügen Geld und begehen Betrug.
Wer muss kämpfen
Spam kann unterschiedlich sein, oft kann er überhaupt nicht vom Verhalten eines normalen Benutzers unterschieden werden. Es kann manuell oder automatisch sein - Bots, die sich mit automatischem Mailing beschäftigen, möchten uns ebenfalls erreichen.
Vielleicht haben Sie auch einmal Bots geschrieben - haben Skripte für die automatische Veröffentlichung erstellt. Wenn Sie dies jetzt tun, ist es besser, nicht weiter zu lesen - Sie sollten auf keinen Fall herausfinden, was ich Ihnen jetzt sagen werde.
Das ist natürlich ein Witz. Der Artikel enthält keine Informationen, die das Leben von Spammern vereinfachen.

Mit wem müssen wir also kämpfen? Dies sind Spammer und Betrüger.
Spam trat vor langer Zeit auf, von Beginn der Entwicklung des Internets an. In unserem Service versuchen Spammer in der Regel, ein Konto zu registrieren, indem sie dort ein
Foto eines attraktiven Mädchens hochladen. In der einfachsten Form beginnen sie, die offensichtlichsten Arten von Spam-Links zu versenden.
Eine kompliziertere Option ist, wenn
Benutzer nichts explizites senden, keine Links senden, keine Werbung machen, sondern
den Benutzer an einen für sie günstigeren Ort locken, z. B. Instant Messenger : Skype, Viber, WhatsApp. Dort können sie ohne unsere Kontrolle alles an den Benutzer verkaufen, Werbung machen usw.
Aber
Spammer sind nicht das größte Problem . Sie sind offensichtlich und leicht zu bekämpfen. Viel komplexere und interessantere Charaktere sind
Betrüger, die sich als eine andere Person
ausgeben und versuchen, Benutzer auf alle Arten im Internet zu täuschen.
Natürlich unterscheiden sich die Aktionen von Spammern und Betrügern nicht immer stark vom Verhalten gewöhnlicher Benutzer, die dies manchmal auch tun. In beiden Fällen gibt es viele formale Zeichen, die es nicht erlauben, eine klare Linie zwischen ihnen zu ziehen. Das ist so gut wie nie möglich.
Umgang mit Spam im Mesozoikum
- Das Einfachste, was getan werden konnte, war, separate reguläre Ausdrücke für jede Art von Spam zu schreiben und jedes schlechte Wort und jede separate Domain in diese reguläre einzugeben. All dies wurde manuell durchgeführt und war natürlich so unpraktisch und ineffizient wie möglich.
- Sie können zweifelhafte IP-Adressen manuell finden und in die Serverkonfiguration eingeben, damit verdächtige Benutzer nie wieder auf Ihre Ressource zugreifen. Dies ist ineffizient, da IP-Adressen ständig neu zugewiesen und verteilt werden.
- Schreiben Sie einmalige Skripte für jeden Spammer- oder Bot-Typ, kratzen Sie ihre Protokolle und suchen Sie manuell nach Mustern. Wenn sich etwas am Verhalten des Spammers ändert, funktioniert alles nicht mehr - auch völlig ineffektiv.

Zunächst zeige ich Ihnen die einfachsten Methoden zur Bekämpfung von Spam, die jeder für sich selbst implementieren kann. Dann werde ich Ihnen ausführlich über die komplexeren Systeme berichten, die wir mithilfe von maschinellem Lernen und anderer schwerer Artillerie entwickelt haben.
Der einfachste Weg, um mit Spam umzugehen
Manuelle Moderation
In jedem Dienst können Sie Moderatoren einstellen, die den Inhalt und das Profil des Benutzers manuell anzeigen und entscheiden, was mit diesem Benutzer geschehen soll. In der Regel sieht dieser Vorgang so aus, als würde man eine Nadel im Heuhaufen finden. Wir haben eine große Anzahl von Benutzern, Moderatoren weniger.

Neben der Tatsache, dass Moderatoren offensichtlich viel benötigen, benötigen Sie viel Infrastruktur. Tatsächlich ist das Schwierigste jedoch ein anderes - es entsteht ein Problem: Wie können Benutzer im Gegenteil vor Moderatoren geschützt werden?
Es muss sichergestellt werden, dass Moderatoren keinen Zugriff auf personenbezogene Daten erhalten. Dies ist wichtig, da Moderatoren theoretisch auch versuchen können, Schaden anzurichten. Das heißt, wir brauchen Antispam für Antispam, damit die Moderatoren unter strenger Kontrolle sind.
Natürlich können Sie nicht alle Benutzer auf diese Weise überprüfen. Trotzdem
ist in jedem Fall eine Moderation erforderlich , da jedes System in Zukunft eine Schulung und eine menschliche Hand benötigt, die bestimmt, was mit dem Benutzer zu tun ist.
Statistiksammlung
Sie können versuchen, Statistiken zu verwenden, um verschiedene Parameter für jeden Benutzer zu erfassen.
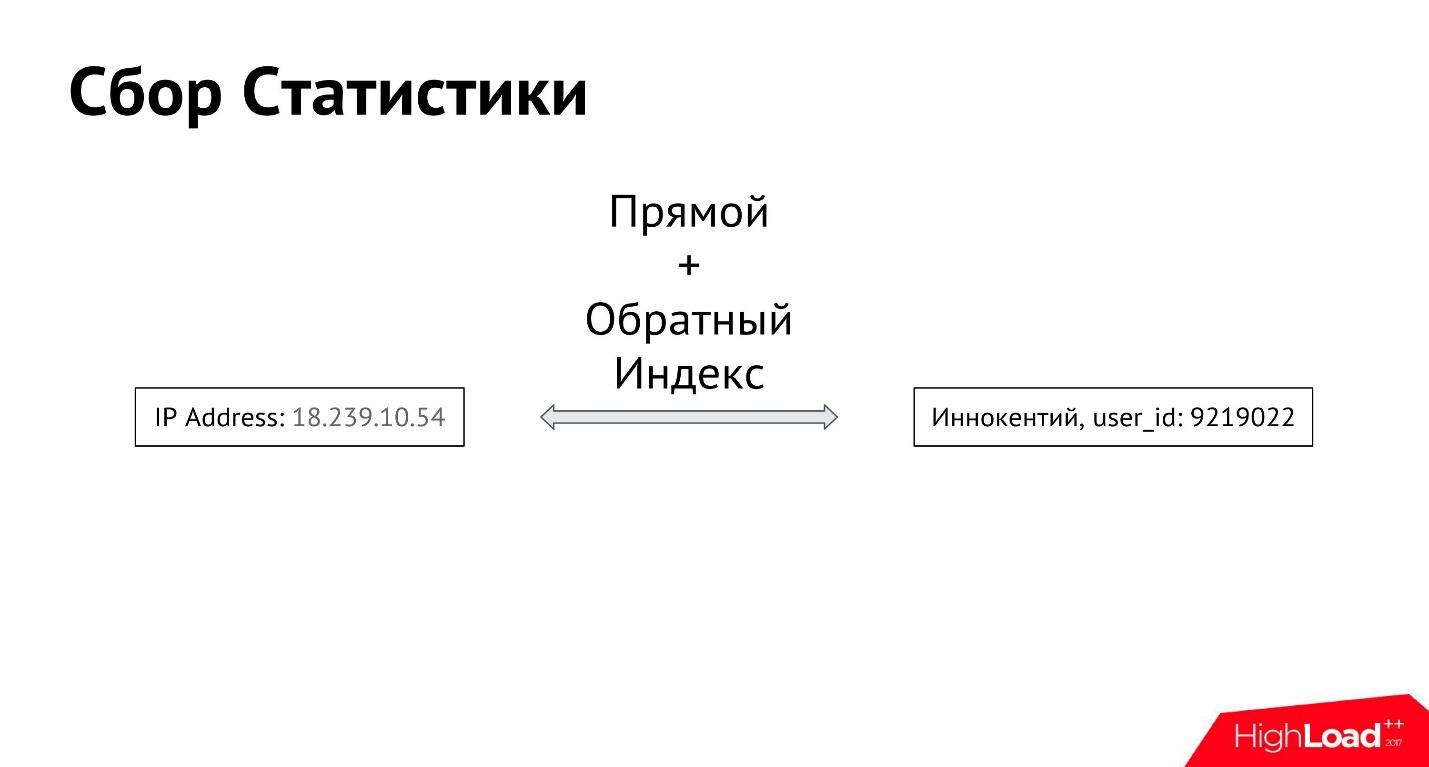
Benutzer Innokenty meldet sich von seiner IP-Adresse aus an. Als erstes melden wir uns an, welche IP-Adresse eingegeben wurde. Als Nächstes erstellen wir einen Vorwärts- und Rückwärtsindex zwischen allen IP-Adressen und allen Benutzern, sodass Sie alle IP-Adressen abrufen können, von denen sich ein bestimmter Benutzer anmeldet, sowie alle Benutzer, die sich von einer bestimmten IP-Adresse aus anmelden.
Auf diese Weise erhalten wir die Verbindung zwischen dem Attribut und dem Benutzer. Es kann viele solcher Attribute geben. Wir können anfangen, Informationen nicht nur über IP-Adressen zu sammeln, sondern auch über Fotos, Geräte, von denen der Benutzer hereingekommen ist - über alles, was wir bestimmen können.
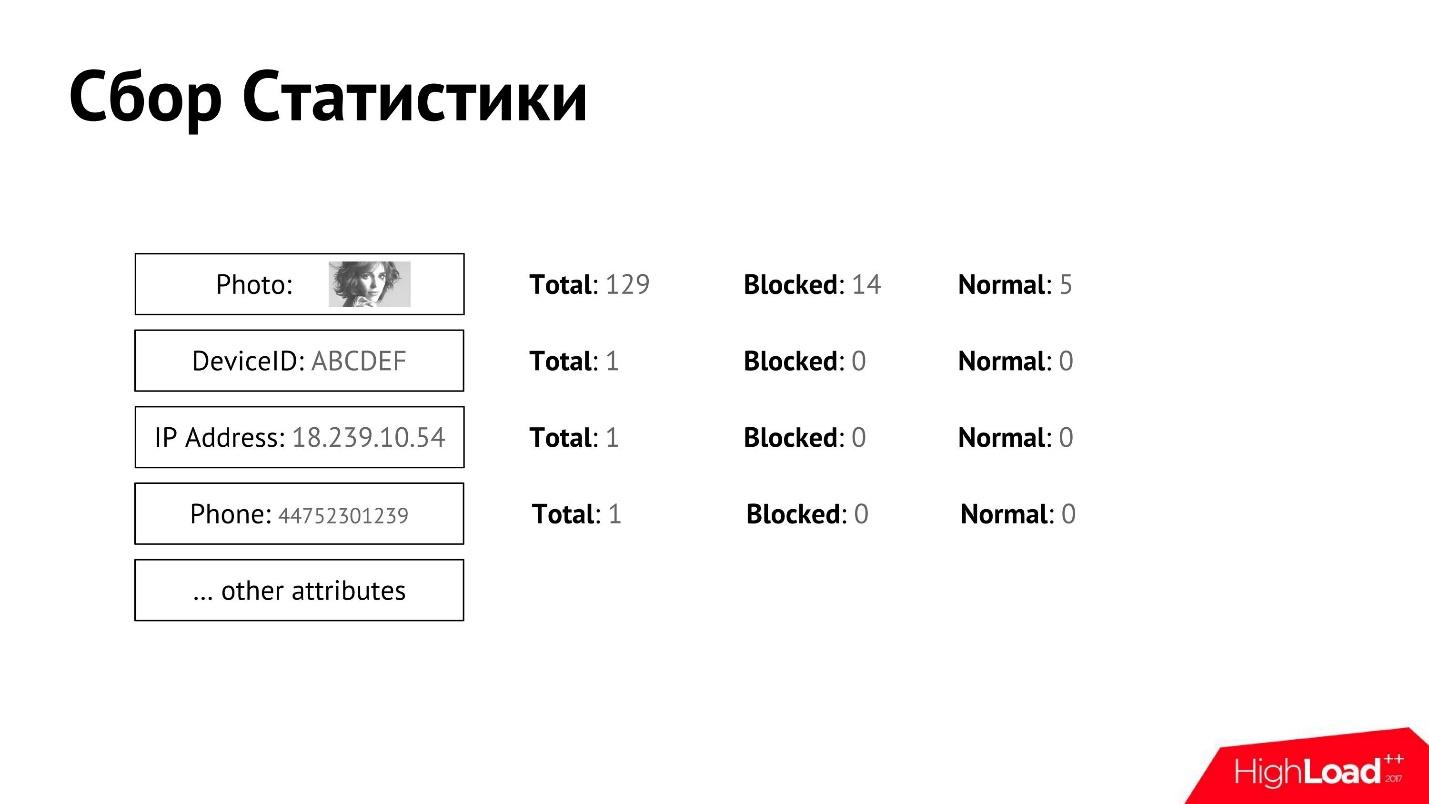
Wir sammeln solche Statistiken und ordnen sie dem Benutzer zu. Für jedes der Attribute können wir detaillierte Zähler sammeln.
Wir haben eine manuelle Moderation, die entscheidet, welcher Benutzer gut und welcher schlecht ist, und irgendwann wird der Benutzer blockiert oder als normal erkannt. Wir können Daten für jedes Attribut separat abrufen, wie viele Benutzer insgesamt, wie viele von ihnen blockiert sind, wie viele als normal erkannt werden.
Mit solchen Statistiken für jedes der Attribute können wir grob bestimmen, wer der Spammer ist und wer nicht.

Angenommen, wir haben zwei IP-Adressen - 80% der Spammer auf einer und 1% auf der zweiten. Offensichtlich ist der erste viel mehr Spam, Sie müssen etwas damit anfangen und irgendeine Art von Sanktionen anwenden.
Am einfachsten ist es,
heuristische Regeln zu schreiben. Wenn beispielsweise blockierte Benutzer mehr als 80% und diejenigen, die als normal gelten, weniger als 5% sind, wird diese IP-Adresse als schlecht angesehen. Dann verbieten oder tun wir etwas anderes mit allen Benutzern mit dieser IP-Adresse.
Sammlung von Statistiken aus Texten
Zusätzlich zu den offensichtlichen Attributen, über die Benutzer verfügen, können Sie auch eine Textanalyse durchführen. Sie können Benutzernachrichten automatisch analysieren, alles, was mit Spam zu tun hat, von ihnen isolieren: Messenger, Telefone, E-Mails, Links, Domains usw. erwähnen und genau dieselben Statistiken von ihnen sammeln.

Wenn beispielsweise ein Domänenname in Nachrichten von 100 Benutzern gesendet wurde, von denen 50 blockiert wurden, ist dieser Domänenname fehlerhaft. Es kann auf die schwarze Liste gesetzt werden.
Wir erhalten eine große Menge zusätzlicher Statistiken für jeden Benutzer basierend auf Nachrichtentexten. Hierfür ist kein maschinelles Lernen erforderlich.
Hör auf mit Worten
Zusätzlich zu den offensichtlichen Dingen - Telefone und Links - können Sie Phrasen oder Wörter aus dem Text extrahieren, die besonders für Spammer üblich sind. Sie können diese Liste der Stoppwörter manuell pflegen.
Zum Beispiel wird in den Berichten von Spammern und Betrügern häufig der Satz "Es gibt viele Fälschungen" gefunden. Sie schreiben, dass sie im Allgemeinen die einzigen hier sind, die auf etwas Ernstes eingestellt sind, all die anderen Fälschungen, denen man auf keinen Fall vertrauen kann.
Laut Statistik verwenden Spammer auf Dating-Sites häufiger als normale Menschen den Satz: "Ich suche eine ernsthafte Beziehung." Es ist unwahrscheinlich, dass ein gewöhnlicher Mensch dies auf einer Dating-Site schreibt - mit einer Wahrscheinlichkeit von 70% ist dies ein Spammer, der versucht, jemanden zu locken.
Suchen Sie nach ähnlichen Konten
Mit Statistiken zu Attributen und Stoppwörtern in Texten können Sie ein System zur Suche nach ähnlichen Konten erstellen. Dies ist erforderlich, um alle von derselben Person erstellten Konten zu finden und zu sperren. Ein gesperrter Spammer kann sofort ein neues Konto registrieren.
Beispielsweise meldet sich ein Benutzer Harold an, meldet sich auf der Site an und gibt seine ziemlich eindeutigen Attribute an: IP-Adresse, Foto, Stoppwort, das er verwendet hat. Vielleicht hat er sich sogar mit einem gefälschten Facebook-Account angemeldet.
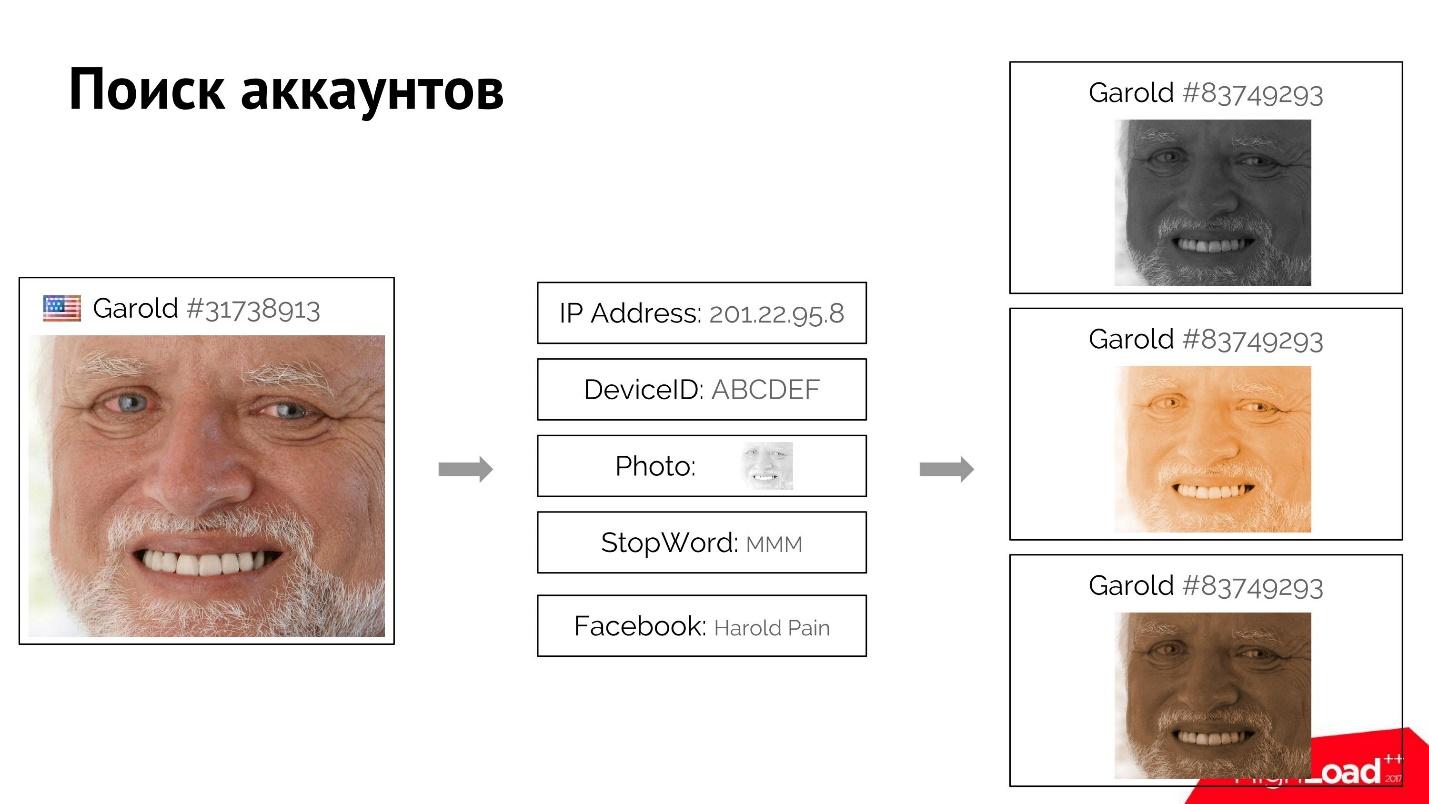
Wir können alle ihm ähnlichen Benutzer finden, bei denen eines oder mehrere dieser Attribute übereinstimmen. Wenn wir sicher sind, dass diese Benutzer verbunden sind, finden wir anhand des Vorwärts- und Rückwärtsindex die Attribute und nach ihnen aller Benutzer und ordnen sie. Wenn wir zum Beispiel den ersten Harold blockieren, ist der Rest mit diesem System auch leicht zu "töten".
Alle Methoden, die ich gerade beschrieben habe, sind sehr einfach: Es ist einfach, Statistiken zu sammeln und dann mit diesen Attributen einfach nach Benutzern zu suchen. Aber trotz der Leichtigkeit schaffen sie es mit Hilfe solch einfacher Dinge - einfache Moderation, einfache Statistiken, einfache Stoppwörter -,
50% des Spam zu besiegen .
In unserem Unternehmen hat die Antispam-Abteilung in den ersten sechs Monaten ihrer Arbeit 50% der Spam-Mails besiegt. Die restlichen 50% sind, wie Sie wissen, viel komplizierter.
Wie man Spammern das Leben schwer macht
Spammer erfinden etwas, versuchen unser Leben zu komplizieren und wir versuchen, sie zu bekämpfen. Dies ist ein endloser Krieg. Es gibt viel mehr von ihnen als wir, und bei jedem Schritt entwickeln wir ihren eigenen Mehrweg.
Ich bin sicher, dass Spammer-Konferenzen irgendwo stattfinden, wo Redner darüber sprechen, wie sie Badoo Antispam besiegt haben, über ihre KPIs oder darüber, wie mit der neuesten Technologie skalierbarer fehlertoleranter Spam erstellt werden kann.
Leider sind wir nicht zu solchen Konferenzen eingeladen.
Aber wir können Spammern das Leben schwer machen. Anstatt dem Benutzer direkt das Fenster "Sie sind gesperrt" anzuzeigen, können Sie beispielsweise das sogenannte
Stealth-Verbot verwenden. In diesem
Fall sagen wir dem Benutzer nicht, dass er gesperrt ist. Er sollte es nicht einmal ahnen.

Der Benutzer gelangt in die Sandbox (Silent Hill), in der alles real zu sein scheint: Sie können Nachrichten senden, abstimmen, aber tatsächlich geht alles ins Leere, in den Nebel. Niemand wird jemals sehen und hören, niemand wird seine Nachrichten und Stimmen erhalten.
Wir hatten einen Fall, in dem ein Spammer lange Zeit Spam verschickte, für seine schlechten Waren und Dienstleistungen wirbte und sechs Monate später beschloss, den Dienst wie beabsichtigt zu nutzen. Er hat seinen echten Account registriert: echte Fotos, Namen usw. Natürlich hat unsere Suchmaschine für ähnliche Konten es schnell herausgefunden und es in das Stealth-Verbot aufgenommen. Danach schrieb er sechs Monate lang in der Leere, dass er sehr einsam sei, niemand antwortete. Im Allgemeinen schüttete er seine ganze Seele in den Nebel von Silent Hill aus, erhielt aber keine Antwort.
Spammer sind natürlich keine Dummköpfe. Sie versuchen irgendwie festzustellen, dass sie in den Sandkasten gekommen sind und blockiert wurden, verlassen das alte Konto und finden ein neues. Manchmal kommt uns sogar die Idee, dass es schön wäre, mehrere dieser Spammer zusammen in den Sandkasten zu schicken, damit sie sich dort alles verkaufen, was sie wollen, und Spaß haben, wie Sie möchten. Obwohl wir diesen Punkt noch nicht erreicht haben, entwickeln wir andere Methoden, zum Beispiel die Foto- und Telefonüberprüfung.

Wie Sie wissen, ist es für einen Spammer, der ein Bot und keine Person ist, schwierig, die Überprüfung per Telefon oder Foto zu bestehen.
In unserem Fall sieht die Überprüfung durch ein Foto folgendermaßen aus: Der Benutzer wird aufgefordert, ein Bild mit einer bestimmten Geste aufzunehmen. Das resultierende Foto wird mit Fotos verglichen, die bereits in das Profil geladen wurden. Wenn die Gesichter gleich sind, ist die Person höchstwahrscheinlich echt, hat ihre echten Fotos hochgeladen und kann für einige Zeit zurückgelassen werden.
Für Spammer ist es nicht einfach, diesen Test zu bestehen. Wir haben sogar ein kleines Spiel in der Firma namens Guess Who the Spammer. Bei vier Fotos müssen Sie verstehen, welches davon ein Spammer ist.
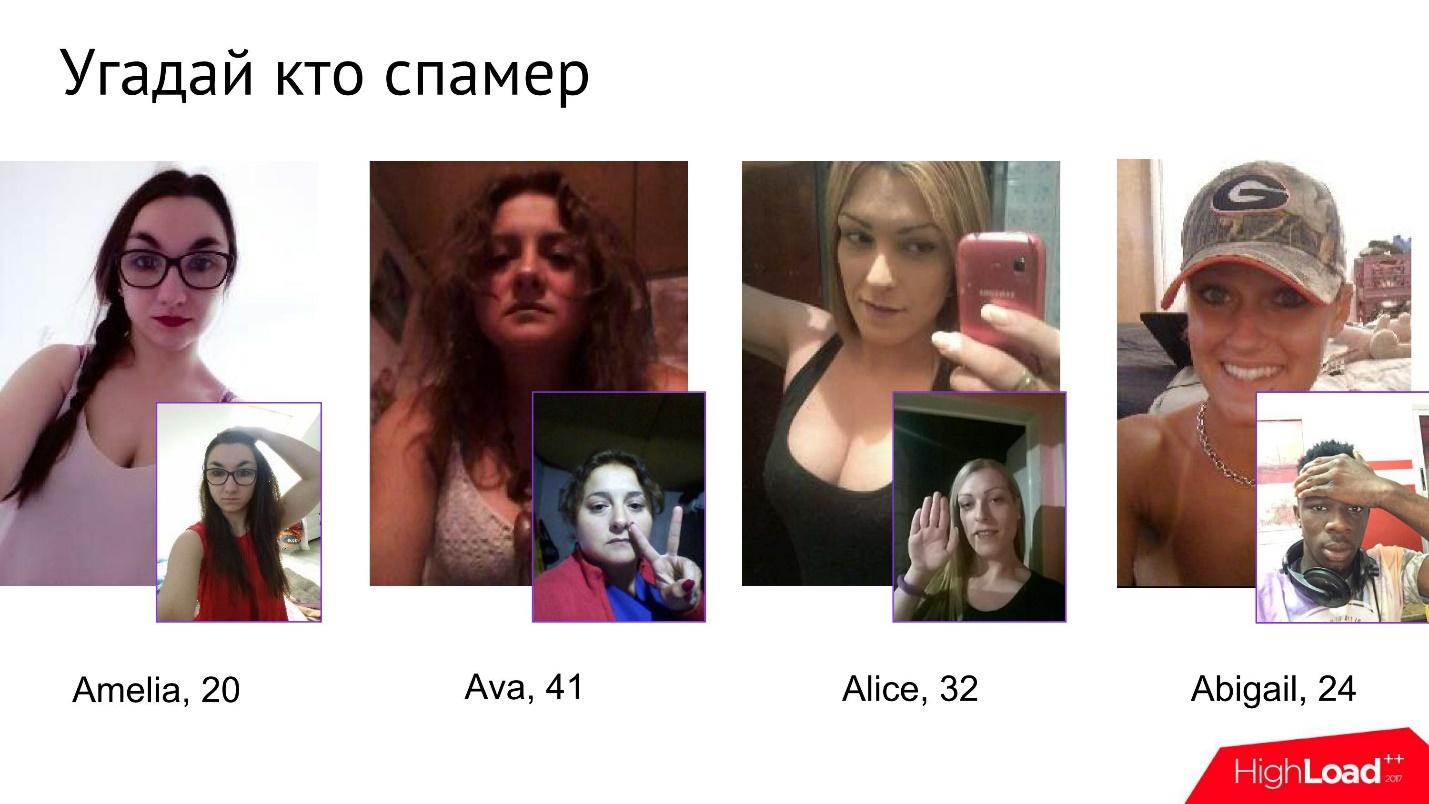
Auf den ersten Blick sehen diese Mädchen völlig harmlos aus, aber sobald sie sich einer Fotoverifizierung unterziehen, wird irgendwann klar, dass eines von ihnen völlig nicht das ist, was sie behauptet zu sein.
In jedem Fall fällt es Spammern schwer, die Fotoüberprüfung zu bekämpfen. Sie leiden wirklich, versuchen es irgendwie zu umgehen, täuschen und demonstrieren all ihre Photoshop-Fähigkeiten.

Spammer tun alles, was sie können, und manchmal denken sie wahrscheinlich, dass all dies vollständig von einigen unglaublichen modernen Technologien verarbeitet wird, die so schlecht konstruiert sind, dass sie so leicht zu täuschen sind.
Sie wissen nicht, dass jedes Foto dann erneut manuell von Moderatoren überprüft wird.
Es gibt keine Zeit!
Trotz der Tatsache, dass wir verschiedene Möglichkeiten gefunden haben, um Spammern das Leben zu erschweren, bleibt normalerweise nicht genügend Zeit, da Anti-Spam sofort funktionieren sollte. Er muss den Benutzer finden und neutralisieren, bevor er seine negative Aktivität beginnt.
Das Beste, was getan werden kann, ist, bei der Registrierung festzustellen, dass der Benutzer nicht sehr gut ist. Dies kann beispielsweise mithilfe von Clustering erfolgen.
Benutzerclustering
Wir können alle möglichen Informationen direkt nach der Registrierung sammeln. Wir haben noch keine Geräte, mit denen sich der Benutzer anmeldet, noch Fotos, es gibt keine Statistiken. Wir haben ihm nichts zur Überprüfung zu schicken, er hat nichts Verdächtiges getan. Aber wir haben bereits primäre Informationen:
- Geschlecht
- Alter
- Land der Registrierung;
- Land und IP-Anbieter;
- E-Mail-Domain
- Telefonist (falls vorhanden);
- Daten von fb (falls vorhanden) - wie viele Freunde er hat, wie viele Fotos er hochgeladen hat, wie lange er sich dort registriert hat usw.
Alle diese Informationen können zum Auffinden von Benutzerclustern verwendet werden. Wir verwenden den einfachen und beliebten
K-Mittel- Clustering-Algorithmus. Es ist überall perfekt implementiert, wird in allen MachineLearning-Bibliotheken unterstützt, ist perfekt parallel und funktioniert schnell. Es gibt Streaming-Versionen dieses Algorithmus, mit denen Sie Benutzer im laufenden Betrieb auf Cluster verteilen können. Selbst in unseren Bänden funktioniert das alles ziemlich schnell.
Nachdem wir solche Benutzergruppen (Cluster) erhalten haben, können wir alle Aktionen ausführen. Wenn Benutzer sehr ähnlich sind (der Cluster ist stark verbunden), handelt es sich höchstwahrscheinlich um eine Massenregistrierung, die sofort gestoppt werden muss. Der Benutzer hatte noch keine Zeit, etwas zu tun. Klicken Sie einfach auf die Schaltfläche "Registrieren" - und das ist alles, er ist bereits in die Sandbox gelangt.
Statistiken können für Cluster gesammelt werden. Wenn 50% des Clusters blockiert sind, können die verbleibenden 50% zur Überprüfung gesendet oder alle Cluster manuell manuell moderiert werden. Überprüfen Sie die Attribute, nach denen sie übereinstimmen, und treffen Sie eine Entscheidung. Basierend auf solchen Daten können Analysten Muster identifizieren.
Muster
Muster sind Sätze der einfachsten Benutzerattribute, die wir sofort kennen. Einige der Muster wirken tatsächlich sehr effektiv gegen bestimmte Arten von Spammern.
Stellen Sie sich zum Beispiel eine Kombination von drei völlig unabhängigen, ziemlich gemeinsamen Attributen vor:
- Der Benutzer ist in den USA registriert.
- Ihr Anbieter ist Privax LTD (VPN-Betreiber);
- E-Mail-Domain: [mail.ru, list.ru, bk.ru, inbox.ru].
Diese drei Attribute, die scheinbar nichts von sich selbst darstellen, geben zusammen die Wahrscheinlichkeit an, dass es sich um einen Spammer handelt, fast 90%.
Sie können für jeden Spammer-Typ beliebig viele Muster extrahieren. Dies ist viel effizienter und einfacher als das manuelle Anzeigen aller Konten oder sogar Cluster.
Textclustering
Sie können Benutzer nicht nur nach Attributen gruppieren, sondern auch Benutzer finden, die dieselben Texte schreiben. Das ist natürlich nicht so einfach. Tatsache ist, dass unser Service in so vielen Sprachen funktioniert. Darüber hinaus schreiben Benutzer häufig mit Abkürzungen, Slang, manchmal mit Fehlern. Nun, die Nachrichten selbst sind normalerweise sehr kurz, buchstäblich 3-4 Wörter (ungefähr 25 Zeichen).
Wenn wir also unter den Milliarden von Nachrichten, die Benutzer schreiben, ähnliche Texte finden möchten, müssen wir uns etwas Ungewöhnliches einfallen lassen. Wenn Sie versuchen, klassische Methoden zu verwenden, die auf der Analyse der Morphologie und der ehrlichen Verarbeitung der Sprache basieren, ist dies mit all diesen Einschränkungen, Slangs, Abkürzungen und einer Reihe von Sprachen sehr schwierig.
Sie können etwas einfacher vorgehen - wenden Sie den
n-Gramm- Algorithmus an. Jede angezeigte Nachricht wird in n-Gramm unterteilt. Wenn n = 2, dann sind dies Bigramme (Buchstabenpaare). Allmählich wird die gesamte Nachricht in Buchstabenpaare unterteilt und Statistiken werden gesammelt, wie oft jedes Bigram im Text vorkommt.

Sie können nicht bei Bigrams anhalten, sondern Trigramme und Skipgramme hinzufügen (Statistiken zu Buchstaben nach 1, 2 usw. Buchstaben). Je mehr Informationen wir erhalten, desto besser. Aber auch Bigrams funktionieren schon ganz gut.
Dann erhalten wir einen Vektor aus den Bigrammen jeder Nachricht, deren Länge gleich dem Quadrat der Länge des Alphabets ist.
Es ist sehr praktisch, mit diesem Vektor zu arbeiten und ihn zu gruppieren, weil:
- besteht aus Zahlen;
- komprimiert gibt es keine Hohlräume;
- immer feste Größe.
- Der k-Mittelwert-Algorithmus mit solchen komprimierten Vektoren fester Größe ist sehr schnell. Unsere Milliarden von Nachrichten werden buchstäblich in wenigen Minuten zusammengefasst.
Das ist aber noch nicht alles. Wenn wir einfach alle Nachrichten sammeln, deren Häufigkeit den Bigrams ähnlich ist, erhalten wir leider Nachrichten, deren Häufigkeit den Bigrams ähnlich ist. Sie müssen jedoch in der Bedeutung nicht zumindest etwas ähnlich sein. Oft gibt es lange Texte, in denen die Vektoren sehr nahe beieinander liegen, fast gleich, aber die Texte selbst sind völlig unterschiedlich. Ab einer bestimmten Textlänge funktioniert diese Clustering-Methode im Allgemeinen nicht mehr, weil Die Frequenzen der Bigramme sind gleich.

Daher müssen Sie Filter hinzufügen. Da die Cluster bereits vorhanden sind, sind sie recht klein. Wir können problemlos innerhalb des Clusters mit Stemming oder Bag of Words filtern. In einem kleinen Cluster können Sie buchstäblich alle Nachrichten mit allen vergleichen und den Cluster abrufen, in dem garantiert dieselben Nachrichten vorhanden sind, die nicht nur in der Statistik, sondern auch in der Realität übereinstimmen.
Wir haben also Clustering durchgeführt - und dennoch ist es für uns (und für Clustering) sehr wichtig, die Wahrheit über den Benutzer zu wissen. Wenn er versucht, die Wahrheit vor uns zu verbergen, müssen wir etwas unternehmen.Informationen verstecken
Eine typische Art des Versteckens von Informationen ist VPN, TOR, Proxy, Anonymisierer. Der Benutzer verwendet sie und versucht vorzutäuschen, dass er aus Amerika stammt, obwohl er tatsächlich aus Nigeria stammt.Um dieses Problem zu lösen, haben wir das bekannteste Lehrbuch „Wie man nach IP berechnet“ genommen. Mithilfe dieses Tutorials haben wir einen VPN-Klassifizierer geschrieben, dh einen Klassifizierer, der eine IP-Adresse als Eingabe empfängt und angibt, ob diese IP-Adresse VPN, Proxy oder nicht ist.Um den Klassifikator zu implementieren, benötigen wir mehrere Zutaten:
Mithilfe dieses Tutorials haben wir einen VPN-Klassifizierer geschrieben, dh einen Klassifizierer, der eine IP-Adresse als Eingabe empfängt und angibt, ob diese IP-Adresse VPN, Proxy oder nicht ist.Um den Klassifikator zu implementieren, benötigen wir mehrere Zutaten:- ISP (Internet Service Provider), IP- . , .
- Whois . IP- Whois : ; ; , IP-; , IP- .. , IP-.
- GeolP. , IP- , , IP- , , , IP- - .
- — IP- , GeolP, Whois, .
, , , IP- VPN .
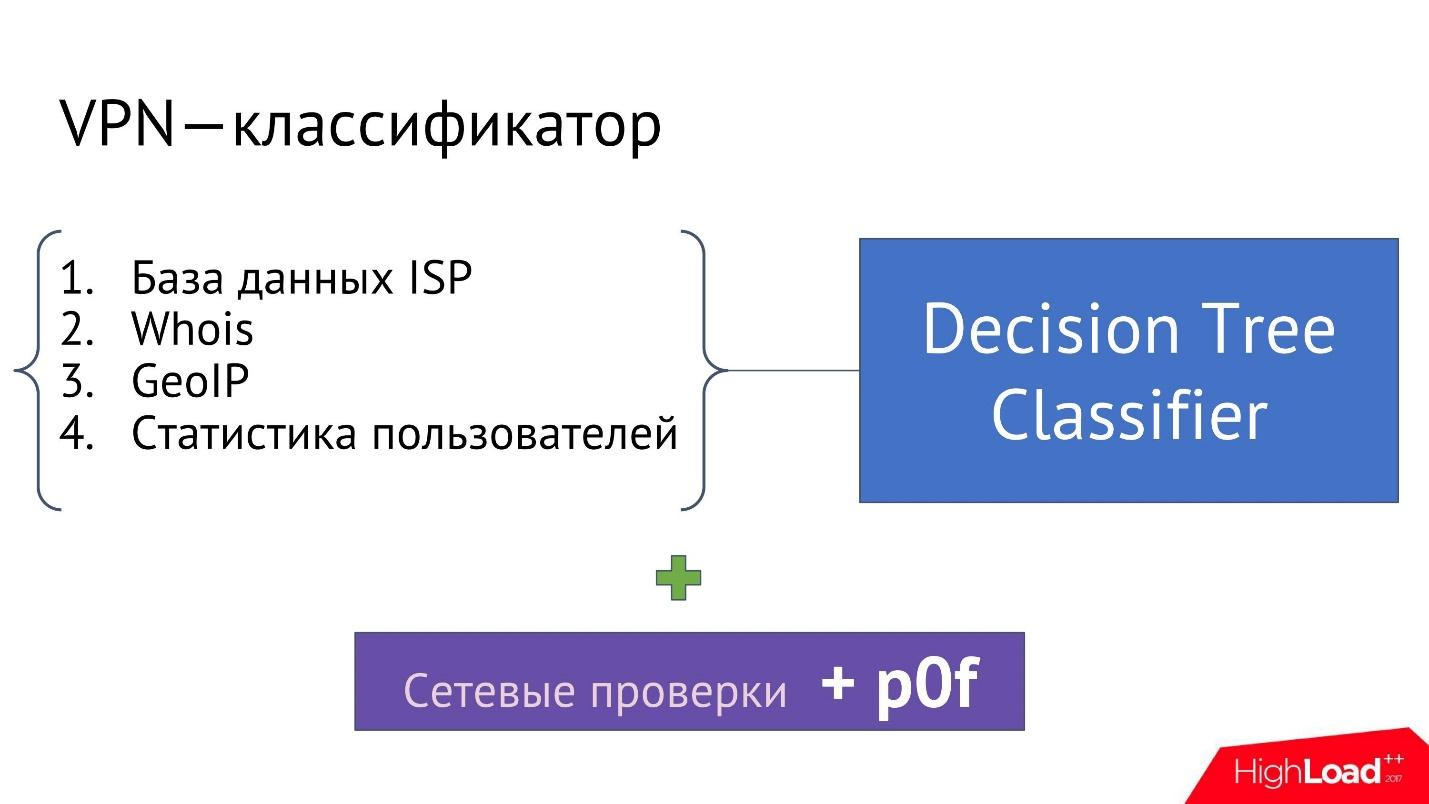
, — , , .., , IP- VPN.
, . , advanced-, 100% . .
, IP- VPN, , IP- . , , . SOCKS-proxy, IP- .
, , ,
p0f . , fingerprinting , : , VPN-, Proxy .. , .
, , , , , : ? — ! , , , .
— ? . 2 , .
, , , , , , , .

, , ?
«User Decency»
— , .
«» :
.
. , , , .
, , «
». , , , , . .
1, , , , — .
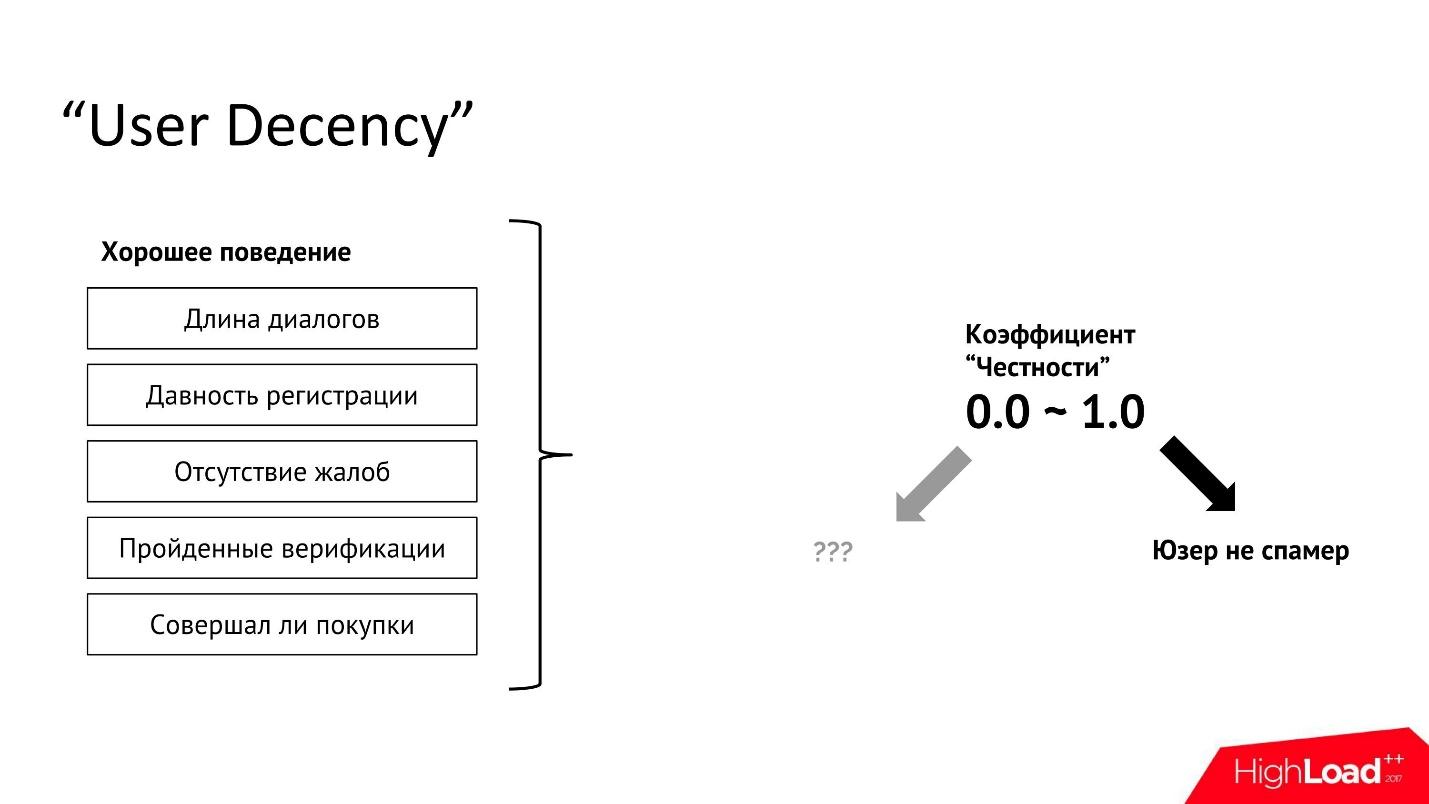
.
False positive
, — . , IP-. , -, . , fingerprint, , , — , , , , - .
: : «, — Pornhub — ?» , - , .
. , , , .
- «Pornhub». - , - .
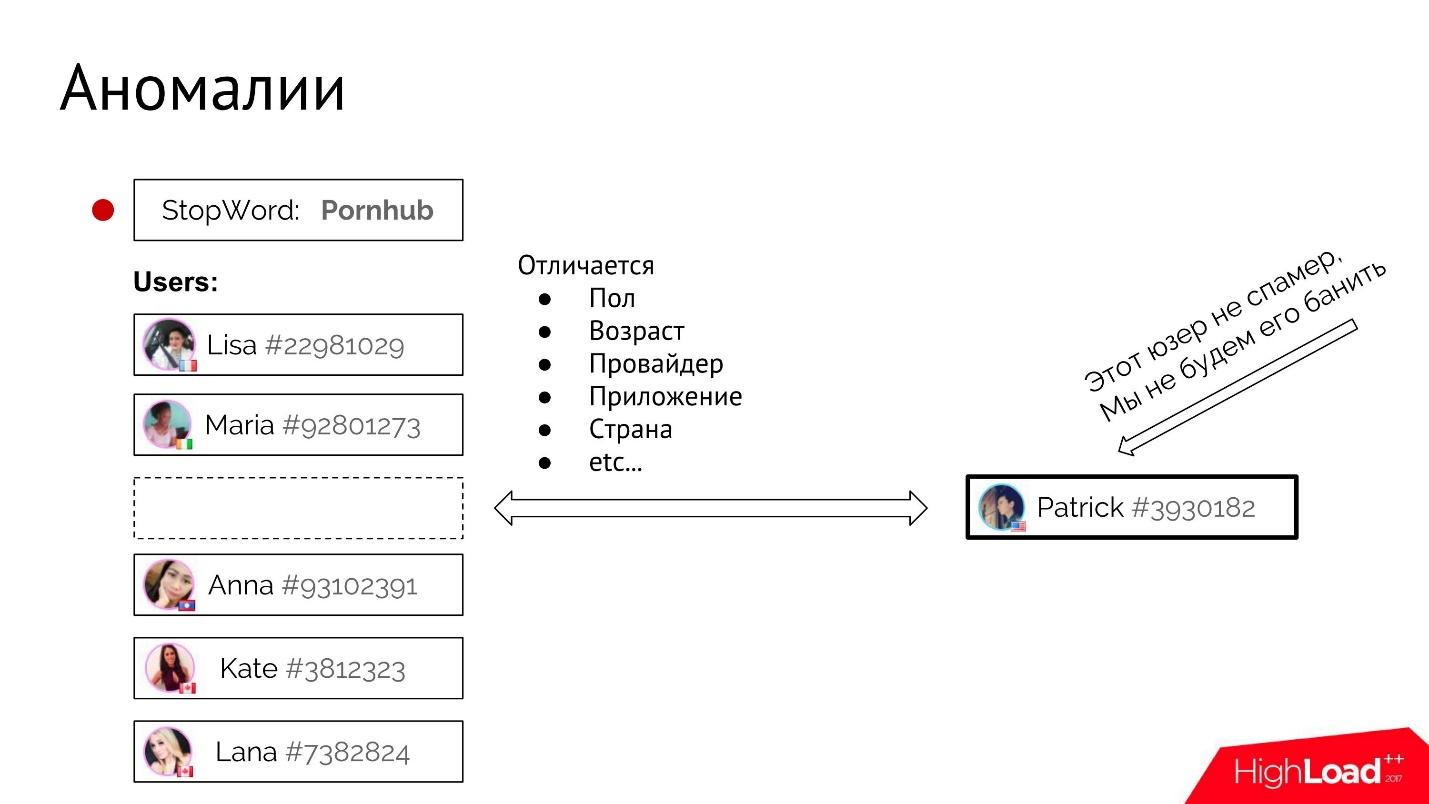
- -, .
, , . : , , , , .. , «» . , , , . , , .
, .
-
— MachineLearning, , 0 1 — .
, ,
, . , , . , - , .
, — . — , .
, ( ) , , . , , , : , , . .
HighLoad++ 2018 , , :
- ML- ,
- NVIDIA , .
- use case .
youtube- , — , .