Ein weiteres Gespräch mit
Pixonic DevGAMM Talks - diesmal von unseren Kollegen bei PanzerDog. Der leitende Software-Ingenieur des Unternehmens, Pavel Platto, zerlegte den Metaserver des Spiels mit einer serviceorientierten Architektur und erklärte, welche Lösungen und Technologien ausgewählt wurden, welche und wie sie skaliert wurden und mit welchen Schwierigkeiten sie konfrontiert waren. Der Text des Berichts, Folien und Links zu anderen Reden aus dem Mitap, wie immer, unter dem Schnitt.
Zunächst möchte ich einen kleinen Trailer für unser Spiel demonstrieren:
Der Bericht besteht aus 3 Teilen. Im ersten werde ich darüber sprechen, welche Technologien wir ausgewählt haben und warum, im zweiten - wie unser Metaserver angeordnet ist, und im dritten werde ich über die verschiedenen unterstützenden Infrastrukturen sprechen, die wir verwenden, und wie wir das Update ohne Ausfallzeiten implementiert haben .
 Technologischer Stapel
Technologischer StapelDer Metaserver wird auf Amazon gehostet und in Elixir geschrieben. Es ist eine funktionale Programmiersprache mit einem Akteurmodell der Berechnung. Da wir keine Ops haben, sind Programmierer an der Operation beteiligt, und der größte Teil der Infrastruktur wird mithilfe der HashiCorp Terraform als Code beschrieben.
Tacticool befindet sich derzeit in der offenen Beta, der Metaserver befindet sich seit etwas mehr als einem Jahr in der Entwicklung und ist seit fast einem Jahr in Betrieb. Mal sehen, wie alles begann.

Als ich in das Unternehmen eintrat, hatten wir bereits grundlegende Funktionen als Monolith auf einem C / C ++ - Mix und PostageSQL-Speicher implementiert. Diese Implementierung hatte bestimmte Probleme.
Erstens gab es aufgrund des niedrigen C-Spiegels einige schwer fassbare Fehler. Bei einigen Spielern hängt das Matchmaking beispielsweise aufgrund einer falschen Nullstellung des Arrays vor seiner Wiederverwendung fest. Natürlich war es ziemlich schwierig, die Beziehung zwischen diesen beiden Ereignissen zu finden. Und da der Status mehrerer Threads im Code allgemein geändert wurde, waren die Race-Bedingungen nicht ohne.
Die parallele Verarbeitung einer großen Anzahl von Aufgaben kam ebenfalls nicht in Frage, da der Server zu Beginn von etwa 10 Arbeitsprozessen gestartet wurde, die durch Abfragen an Amazon oder die Datenbank blockiert wurden. Und selbst wenn wir diese Blockierungsanforderungen vergessen, begann der Dienst bei ein paar Hundert Verbindungen zusammenzubrechen, die außer Ping keine Operationen ausführten. Außerdem konnte der Dienst nicht horizontal skaliert werden.
Nachdem wir einige Wochen damit verbracht hatten, die kritischsten Fehler zu finden und zu beheben, entschieden wir, dass es einfacher war, alles von Grund auf neu zu schreiben, als zu versuchen, alle Mängel der aktuellen Lösung zu beheben.
Wenn Sie bei Null anfangen, ist es sinnvoll, eine Sprache auszuwählen, mit der Sie einige der vorherigen Probleme vermeiden können. Wir hatten drei Kandidaten:

C # war auf der Bekanntschaftsliste, as Der Client und der Spieleserver sind in Unity geschrieben, und die meiste Erfahrung im Team wurde mit dieser Programmiersprache gemacht. Go und Elixir wurden in Betracht gezogen, da dies moderne und recht beliebte Sprachen sind, die für die Entwicklung von Serveranwendungen entwickelt wurden.
Die Probleme der vorherigen Iteration haben uns geholfen, die Kriterien für die Bewertung von Kandidaten zu bestimmen.
Das erste Kriterium war die Bequemlichkeit der Arbeit mit asynchronen Operationen. In C # wurde beim ersten Versuch keine bequeme Arbeit mit asynchronen Operationen angezeigt. Dies führte dazu, dass wir einen „Zoo“ von Lösungen haben, die meiner Meinung nach immer noch ein wenig auf der Seite stehen. In Go und Elixir wurde dieses Problem beim Entwerfen dieser Sprachen berücksichtigt. Beide verwenden leichtgewichtige Threads (in Go sind sie Goroutinen, in Elixir Prozesse). Diese Streams haben einen viel geringeren Overhead als System-Threads, und da wir sie in Zehntausenden und Hunderttausenden erstellen können, tut es uns nicht leid, sie zu blockieren.
Das zweite Kriterium war die Fähigkeit, mit wettbewerbsfähigen Prozessen zu arbeiten. C # out of the box bietet nichts anderes als Thread-Pools und gemeinsam genutzten Speicher, auf den der Zugriff mithilfe verschiedener Synchronisationsprimitive geschützt werden muss. Go hat ein weniger fehleranfälliges Modell in Form von Goroutinen und Kanälen. Elixir hingegen bietet ein Schauspieler-Modell ohne Shared Memory mit Messaging. Der Mangel an gemeinsam genutztem Speicher ermöglichte es uns, Technologien zu implementieren, die für eine wettbewerbsfähige Ausführungsumgebung zur Laufzeit nützlich sind, wie z. B. ehrliches Push-out-Multitasking und Garbage Collection ohne Unterbrechungen in der Welt.
Das dritte Kriterium war die Verfügbarkeit von Tools für die Arbeit mit unveränderlichen Datentypen. Alle meine Entwicklungserfahrungen haben gezeigt, dass ein ziemlich großer Teil der Fehler mit falschen Datenänderungen verbunden ist. Eine Lösung dafür gibt es schon vor langer Zeit - unveränderliche Datentypen. In C # können diese Datentypen erstellt werden, jedoch auf Kosten einer Tonne Boilerplate. In Go ist dies überhaupt nicht möglich. Und in Elixir sind alle Datentypen unveränderlich.
Und das letzte Kriterium war die Anzahl der Spezialisten. Hier sind die Ergebnisse offensichtlich. Am Ende haben wir uns für Elixir entschieden.
Mit der Wahl des Hostings war alles viel einfacher. Wir haben bereits Spieleserver in Amazon GameLift gehostet. Darüber hinaus bietet Amazon eine große Anzahl von Diensten an, mit denen wir die Entwicklungszeit verkürzen können.
Wir haben uns vollständig der Cloud ergeben und stellen selbst keine Lösungen von Drittanbietern bereit - Datenbanken, Nachrichtenwarteschlangen - all dies wird von Amazon für uns verwaltet. Meiner Meinung nach ist dies die einzige Lösung für ein kleines Team, das ein Online-Spiel entwickeln möchte, und nicht die Infrastruktur dafür.
Wir haben die Auswahl der Technologien herausgefunden. Kommen wir zur Funktionsweise des Metaservers.
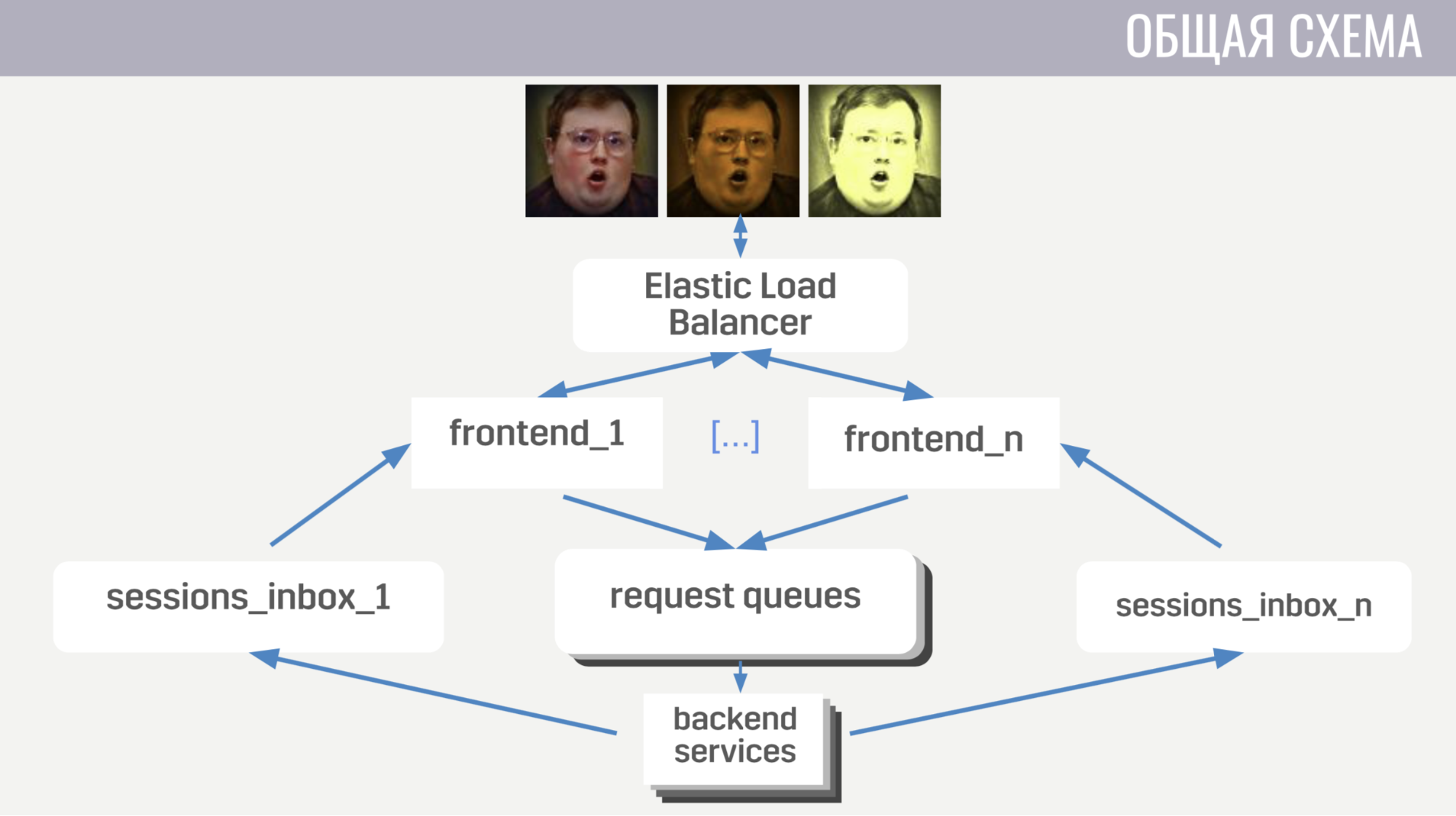
Im Allgemeinen: Clients stellen über Web-Socket-Verbindungen eine Verbindung zum Load Balancer von Amazon her. Der Balancer streut diese Verbindungen zwischen mehreren Front-End-Instanzen, das Front-End sendet Client-Anforderungen an Back-Ends. Das Front-End und das Back-End kommunizieren jedoch indirekt über Nachrichtenwarteschlangen. Für jeden Nachrichtentyp gibt es eine separate Warteschlange, und das Frontend bestimmt anhand des Nachrichtentyps, wo es geschrieben werden soll, und die Backends hören diese Warteschlangen ab.
Damit das Backend eine Antwort auf die Anfrage an den Client oder eine Art Ereignis senden kann, verfügt jedes Frontend über eine separate Warteschlange (speziell dafür zugewiesen). Bei jeder Anforderung erhält das Backend eine Frontend-ID, um zu bestimmen, in welche Warteschlange die Antwort geschrieben werden soll. Wenn er ein Ereignis senden muss, ruft er die Datenbank auf, um herauszufinden, mit welcher Frontend-Instanz der Client verbunden ist.
Kommen wir mit dem allgemeinen Schema zu den Details.

Zunächst werde ich auf einige Funktionen der Client-Server-Interaktion eingehen. Wir verwenden unser Binärprotokoll, weil es sehr effizient ist und es ermöglicht, Verkehr zu sparen. Zweitens sendet der Server bei Vorgängen mit einem Konto, das es ändert, diese Änderungen nicht an den Client, sondern an die vollständige (aktualisierte) Version dieses Kontos. Dies ist etwas weniger effizient, nimmt aber ohnehin nicht viel Platz ein und vereinfacht unser Leben sowohl auf dem Client als auch auf dem Server erheblich. Außerdem stellt das Frontend sicher, dass der Client nicht mehr als eine Anforderung gleichzeitig ausführt. Auf diese Weise können Sie Fehler auf dem Client erkennen, wenn er beispielsweise zu einem anderen Bildschirm wechselt, bevor der Player das Ergebnis der vorherigen Operation sieht.
Nun ein wenig darüber, wie das Frontend angeordnet ist.

Ein Frontend ist im Wesentlichen ein Webserver, der auf Web-Socket-Verbindungen wartet. Für jede Sitzung werden zwei Prozesse erstellt. Der erste Prozess dient der Web-Socket-Verbindung selbst, und der zweite ist eine Zustandsmaschine, die den aktuellen Status des Clients beschreibt. Basierend auf diesem Status wird die Gültigkeit von Anforderungen vom Client bestimmt. Beispielsweise können fast alle Anforderungen erst abgeschlossen werden, wenn die Autorisierung abgeschlossen ist. Da es neben diesen Sitzungen keinen Status im Frontend gibt, ist es sehr einfach, neue Frontend-Instanzen hinzuzufügen, aber es ist etwas schwieriger, die alten zu löschen. Vor der Deinstallation müssen Sie alle Clients ihre aktuellen Anforderungen ausführen lassen und sie bitten, die Verbindung zu einer anderen Instanz wiederherzustellen.
Nun dazu, wie das Backend aussieht. Derzeit besteht es aus fünf Diensten.
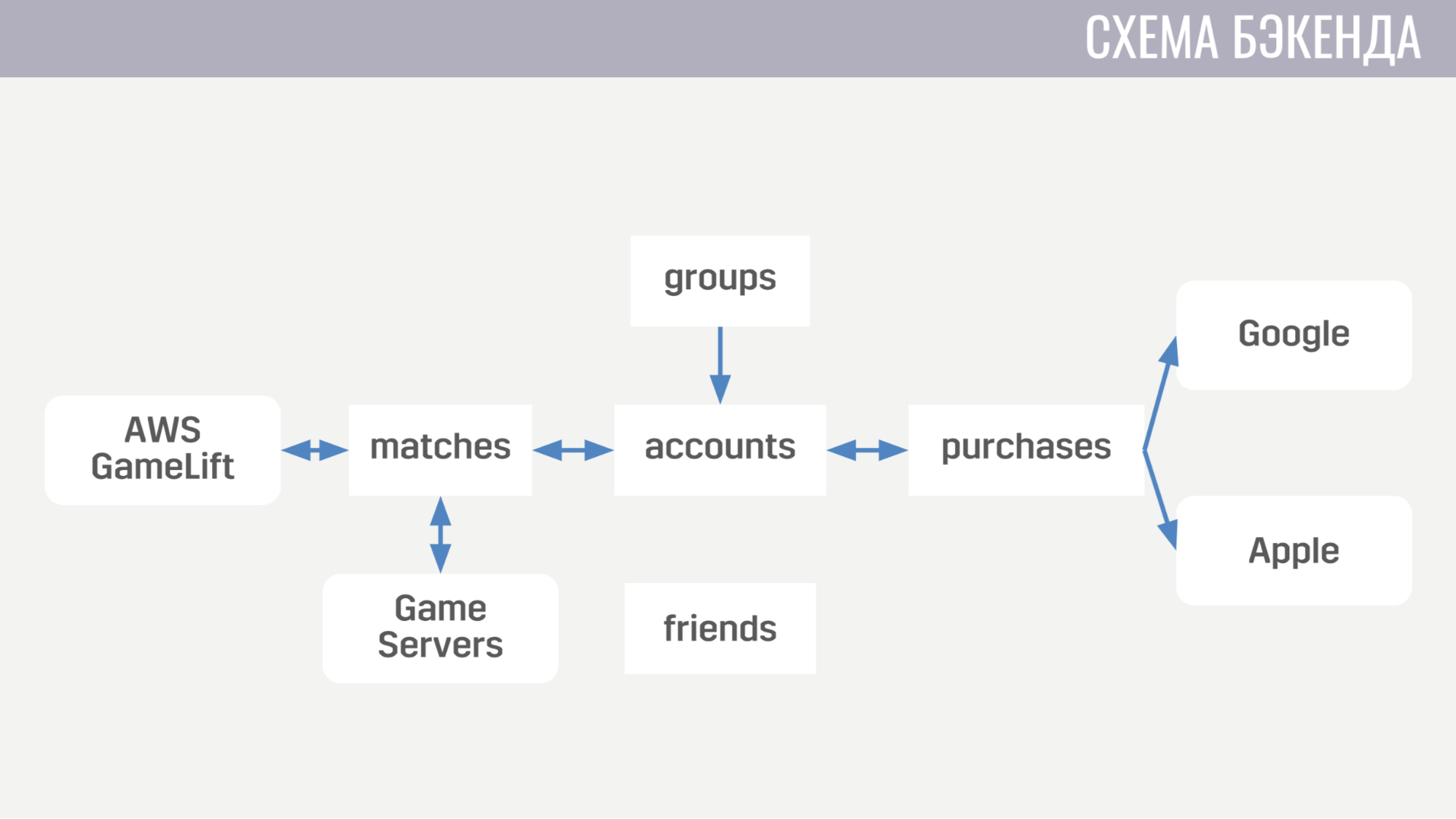
Der erste befasst sich mit allem, was mit Konten zu tun hat - von Einkäufen für Spielwährung bis zum Abschluss von Quests. Der zweite funktioniert mit allem, was mit Spielen zu tun hat - er interagiert direkt mit GameLift und Spieleservern. Der dritte Service ist das Einkaufen für echtes Geld. Der vierte und fünfte sind für soziale Interaktionen verantwortlich - einer für Freunde, der andere für ein Partyspiel.
Jeder der Backend-Services sieht aus architektonischer Sicht absolut identisch aus. Sie sind eine Reihe von Pipelines, von denen jede einen Nachrichtentyp verarbeitet. Die Pipeline besteht aus zwei Elementen: Produzent und Konsument.

Die einzige Aufgabe des Produzenten besteht darin, Nachrichten aus der Warteschlange zu lesen. Daher wird es in einer vollständig allgemeinen Form implementiert, und für jede Pipeline müssen wir nur angeben, wie viele Hersteller vorhanden sind, aus welcher Warteschlange gelesen werden soll und wie viele Verbraucher jeder Hersteller bedienen wird. Consumer hingegen wird für jede Pipeline separat implementiert und ist ein Modul mit der einzigen obligatorischen Funktion, die eine Nachricht akzeptiert, alle erforderlichen Arbeiten ausführt und eine Liste von Nachrichten zurückgibt, die an andere Dienste an den Client oder an den Spieleserver gesendet werden müssen. Der Produzent setzt auch Gegendruck ein, so dass bei einem starken Anstieg der Anzahl der Nachrichten keine Überlastung auftritt, und fordert nicht mehr Nachrichten an, als er freie Verbraucher hat.
Backend-Services enthalten keinen Status, daher können wir alte Instanzen problemlos hinzufügen und entfernen. Vor dem Löschen müssen Sie die Produzenten lediglich auffordern, keine neuen Nachrichten mehr zu lesen, und den Verbrauchern ein wenig Zeit geben, um die Verarbeitung aktiver Nachrichten abzuschließen.
Wie erfolgt die Interaktion mit GameLift? GameLift besteht aus mehreren Komponenten. Von denen, die wir verwenden, ist dies ein FlexMatch-Matchmaker, eine Platzierungswarteschlange, die bestimmt, in welcher bestimmten Region eine Spielsitzung mit diesen Spielern stattfinden soll, und die Flotten selbst, die aus Spielservern bestehen.
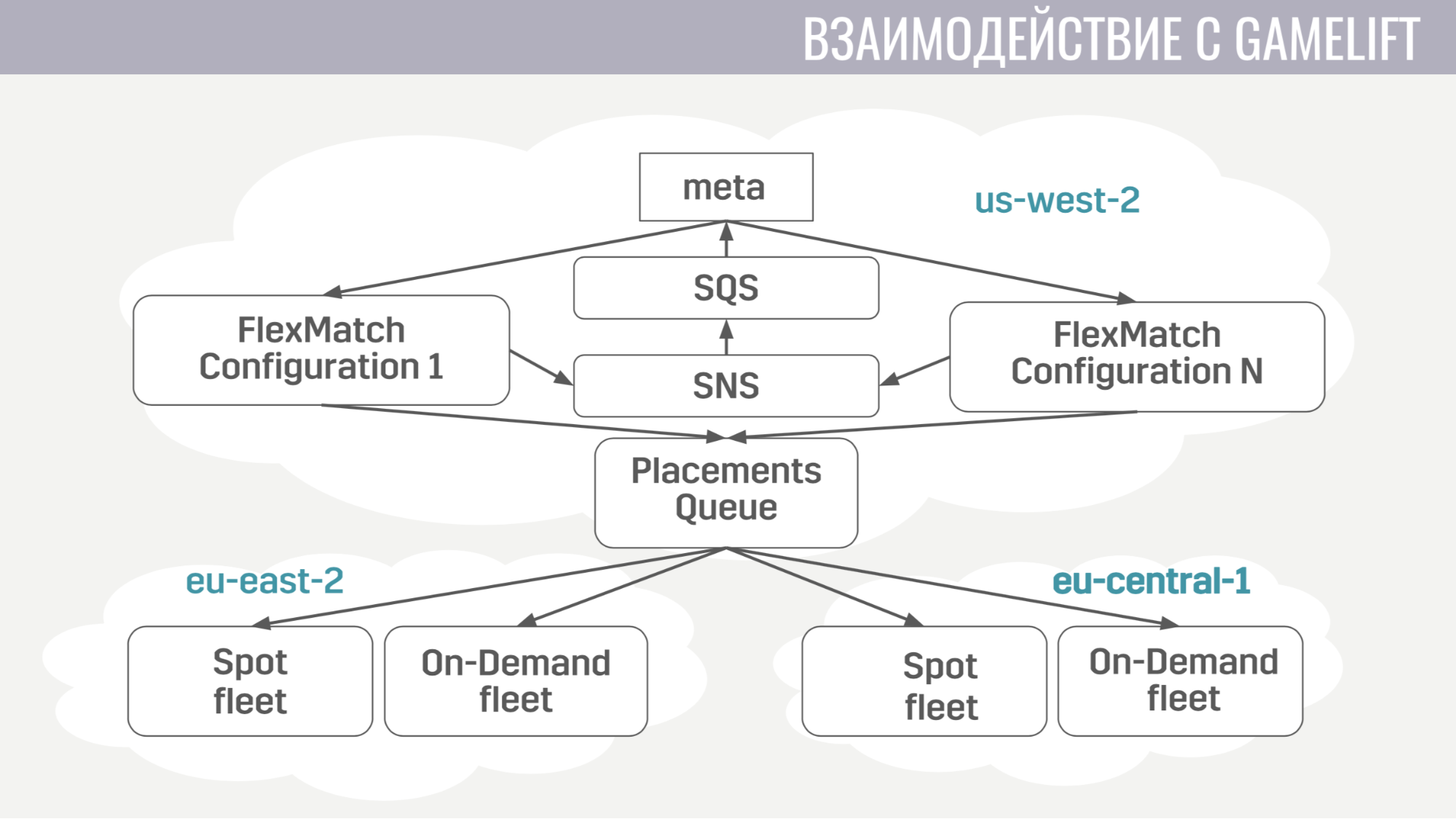
Wie läuft diese Interaktion? Meta kommuniziert nur direkt mit dem Matchmaker und sendet ihm Anfragen, um das Match zu finden. Und er benachrichtigt das Meta aller Ereignisse während des Matchmaking über dieselben Nachrichtenwarteschlangen. Und sobald er eine geeignete Gruppe von Spielern findet, um das Spiel zu starten, sendet er eine Anfrage an die Platzierungswarteschlange, die wiederum einen Server für sie auswählt.
Die Interaktion von Meta mit dem Spieleserver ist äußerst einfach. Der Spielserver benötigt Informationen zu Konten, Bots und einer Karte, und das Meta sendet alle diese Informationen in einer einzigen Nachricht an die Warteschlange, die speziell für dieses Spiel erstellt wurde.

Nach der Aktivierung hört der Spieleserver diese Warteschlange ab und empfängt alle benötigten Daten. Am Ende des Spiels sendet er seine Ergebnisse an die allgemeine Warteschlange, die das Meta abhört.
Kommen wir nun zu der zusätzlichen Infrastruktur, die wir verwenden.

Das Bereitstellen von Diensten ist recht einfach. Sie arbeiten alle in Docker-Containern, und wir verwenden Amazon ECS für die Orchestrierung. Es ist viel einfacher als Kubernetes, natürlich weniger ausgefeilt, aber es führt die Aufgaben aus, die wir von ihm benötigen. Nämlich: Skalierungsdienste und fortlaufende Releases, wenn wir eine Art Bugfix eingeben müssen.
Und der letzte Service, den wir auch nutzen, ist AWS Fargate. Dies erspart uns die unabhängige Verwaltung des Maschinenclusters, auf dem unsere Docker-Container ausgeführt werden.

Als Hauptspeicher verwenden wir DynamoDB. Zunächst haben wir uns dafür entschieden, weil es sehr einfach zu bedienen und zu skalieren ist. Wir verwenden Redis auch als zusätzlichen Speicher über den von Amazon ElasiCache verwalteten Dienst. Wir verwenden es für die globale Spielerbewertungsaufgabe und zum Zwischenspeichern grundlegender Kontoinformationen in Situationen, in denen wir Daten zu Hunderten von Spielkonten sofort an den Client zurückgeben müssen (z. B. in derselben Bewertungstabelle oder in der Freundesliste).
Zum Speichern von Konfigurationen, Metaspielmechaniken, Beschreibungen von Waffen, Helden usw. Wir verwenden eine JSON-Datei, die wir an die Images der Dienste anhängen, die sie benötigen. Weil es für uns viel einfacher ist, eine neue Version des Dienstes mit aktualisierten Daten bereitzustellen (wenn ein Fehler festgestellt wird), als eine Entscheidung zu treffen, die diese Daten zur Laufzeit dynamisch von einem externen Speicher aktualisiert.
Für die Protokollierung und Überwachung verwenden wir einige Dienste.
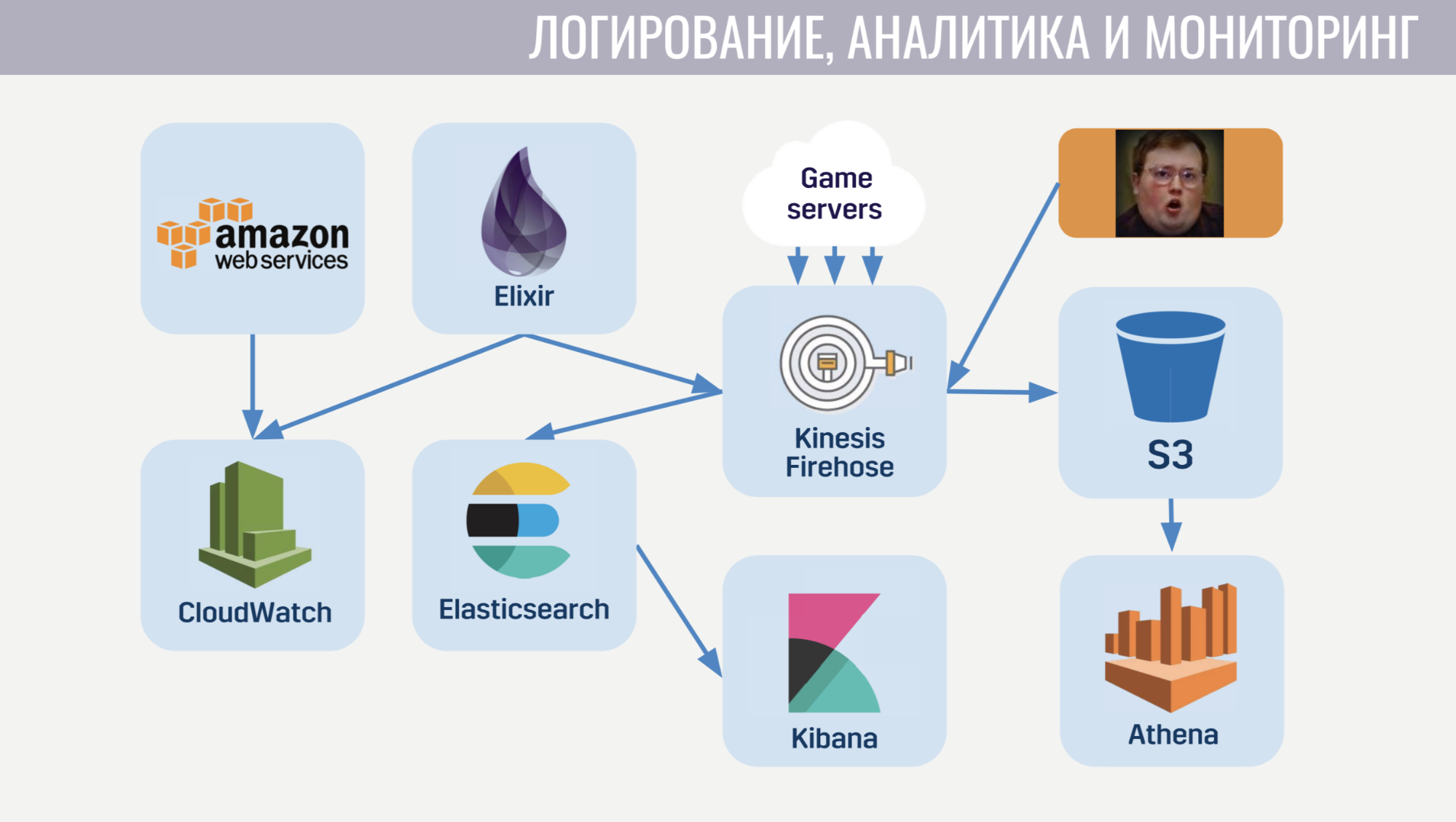
Beginnen wir mit CloudWatch. Dies ist ein Überwachungsdienst, bei dem sich Metriken aller Amazon-Dienste versammeln. Aus diesem Grund haben wir uns entschlossen, die Metriken auch von unserem Metaserver dorthin zu senden. Für die Protokollierung verwenden wir einen gemeinsamen Ansatz sowohl auf dem Client als auch auf dem Spieleserver und auf dem Metaserver. Wir senden alle Protokolle an den Amazonas-Dienst Kinesis Firehose, der sie wiederum an Elasticseach und S3 überträgt.
In Elasticseach speichern wir nur relativ aktuelle Daten und suchen mithilfe von Kibana nach Fehlern, lösen einige der Aufgaben der Spielanalyse und erstellen betriebliche Dashboards, beispielsweise mit einem CCU-Zeitplan und der Anzahl neuer Installationen. S3 enthält alle historischen Daten und wir verwenden sie über den Athena-Dienst, der zusätzlich zu den Daten in S3 eine SQL-Schnittstelle bereitstellt.
Nun ein wenig darüber, wie wir Terraform verwenden.

Terraform ist ein Tool, mit dem Sie die Infrastruktur deklarativ beschreiben können. Wenn sich die Beschreibung ändert, werden automatisch die Maßnahmen festgelegt, die Sie ergreifen müssen, um Ihre Infrastruktur auf ein aktualisiertes Erscheinungsbild zu bringen. Mit einer einzigen Beschreibung erhalten wir eine nahezu identische Umgebung für Inszenierung und Produktion. Außerdem sind diese Umgebungen vollständig isoliert, da sie unter verschiedenen Konten bereitgestellt werden. Der einzige wesentliche Nachteil von Terraform ist für uns die unvollständige Unterstützung von GameLift.
Ich werde auch darüber sprechen, wie wir das Update ohne Ausfallzeiten implementiert haben.

Wenn wir Updates veröffentlichen, erstellen wir eine Kopie der meisten Ressourcen: Dienste, Nachrichtenwarteschlangen, einige Bezeichnungen in der Datenbank. Und diejenigen Spieler, die die neue Version des Spiels herunterladen, werden eine Verbindung zu diesem aktualisierten Cluster herstellen. Spieler, die noch nicht aktualisiert wurden, können jedoch noch einige Zeit mit der alten Version des Spiels spielen und eine Verbindung zum alten Cluster herstellen.
Wie wir es umgesetzt haben. Verwenden Sie zunächst die Modul-Engine in Terraform. Wir haben ein Modul zugewiesen, in dem wir alle versionierten Ressourcen beschrieben haben. Und diese Module können mehrmals mit unterschiedlichen Parametern importiert werden. Dementsprechend importieren wir für jede Version dieses Modul unter Angabe der Nummer dieser Version. Das Fehlen eines Schemas in DynamoDB hat uns auch geholfen, wodurch es möglich ist, Datenmigrationen nicht während des Updates durchzuführen, sondern sie für jedes Konto zu verschieben, bis sich sein Besitzer bei der neuen Version des Spiels anmeldet. Und im Balancer geben wir einfach für jede Version der Regel an, damit sie weiß, wohin Spieler mit unterschiedlichen Versionen weitergeleitet werden sollen.
Zum Schluss noch ein paar Dinge, die wir gelernt haben. Zunächst muss die Konfiguration der gesamten Infrastruktur automatisiert werden. Das heißt, Wir haben einige Dinge mit unseren Händen für eine Weile eingerichtet, aber früher oder später haben wir einen Fehler in den Einstellungen gemacht, aufgrund dessen es Fakaps gab.

Und das Letzte: Sie benötigen entweder ein Replikat oder eine Sicherungskopie für jedes Element Ihrer Infrastruktur. Und wenn Sie es nicht für etwas tun, wird uns diese besondere Sache jemals im Stich lassen.
Fragen aus dem Publikum
- Aber stört es Sie nicht, dass die automatische Skalierung aufgrund eines Fehlers zu stark anhält und Sie viel Geld bekommen?- Für die automatische Skalierung sind noch Grenzwerte festgelegt. Wir werden kein zu großes Limit setzen, um nicht auf viel Geld hereinzufallen. Dies ist die Hauptlösung + Überwachung. Sie können Warnungen festlegen, wenn etwas zu stark ist.
- Was sind Ihre aktuellen Grenzen? Relativ zur aktuellen Infrastruktur in Prozent.- Jetzt haben wir eine offene Beta-Testphase in 11 Ländern, daher ist es keine so große CCU, zumindest irgendwie zu bewerten. Jetzt ist die Infrastruktur für die Anzahl der Menschen, die wir haben, zu überprovisioniert.
- Und es gibt noch keine Grenzen?- Ja, es ist nur so, dass sie 10-100 Mal höher sind als unsere CCU. Mach nicht weniger.
- Sie sagten, dass Sie Linien zwischen Front- und Backend haben - das ist sehr ungewöhnlich. Warum nicht direkt?- Wir wollten, dass zustandslose Dienste den Sicherungsmechanismus einfach implementieren, damit der Dienst nicht mehr Nachrichten anfordert als freie Handler. Wenn beispielsweise ein Handler ausfällt, gibt die Warteschlange dieselbe Nachricht an einen anderen Handler weiter - möglicherweise ist dies erfolgreich.
- Bleibt die Warteschlange irgendwie bestehen?- Ja. Dies ist ein Amazonian SQS-Dienst.
- In Bezug auf die Warteschlangen: Wie viele Kanäle werden während des Spiels erstellt? Haben Sie eine bestimmte Anzahl von Kanälen für jedes Spiel?- Es schafft relativ wenig. Die meisten Warteschlangen, z. B. Anforderungswarteschlangen, sind statisch. Es gibt eine Warteschlange mit Autorisierungsanforderungen, es gibt eine Warteschlange für den Beginn des Spiels. Von den dynamisch erstellten Warteschlangen haben wir nur Warteschlangen für jedes Frontend (es erstellt für eingehende Nachrichten für Clients beim Start) und für jede Übereinstimmung erstellen wir eine Warteschlange. Bei diesem Service kostet es fast nichts, sie haben jede Anfrage auf die gleiche Weise in Rechnung gestellt. Das heißt, Jede Anfrage an SQS (eine Warteschlange erstellen, etwas daraus lesen) kostet dasselbe und gleichzeitig löschen wir diese Warteschlangen nicht, um sie zu speichern. Sie werden später gelöscht. Und die Tatsache, dass sie existieren, kostet uns nichts.
- In dieser Architektur ist dies keine Grenze für Sie?- Nein.
Weitere Gespräche mit Pixonic DevGAMM Talks