Viele der regelmäßigen Teilnehmer an
ML-Schulungen sind der Meinung, dass die Teilnahme an Wettbewerben der schnellste Weg ist, um in den Beruf einzusteigen. Wir hatten sogar
einen Artikel zu diesem Thema. Der Autor des heutigen Vortrags Arthur Kuzin hat anhand seines eigenen Beispiels gezeigt, wie es in ein paar Jahren möglich ist, sich von einem Bereich, der überhaupt nichts mit Programmierung zu tun hat, zu einem Spezialisten für Datenanalyse umzubilden.
- Hallo allerseits. Mein Name ist Arthur Cousin, ich bin ein leitender Datenwissenschaftler bei Dbrain.
Emil hatte einen ziemlich umfassenden Bericht, der über so viele Aspekte berichtete. Ich werde mich auf das konzentrieren, was ich für das Wichtigste und Lustigste halte. Bevor ich zum Thema des Berichts komme, möchte ich mich vorstellen. Im Allgemeinen habe ich mein Physikstudium abgeschlossen und ab dem dritten Jahr etwa 8 Jahre lang im Labor gearbeitet, das sich auf dem Boden des NK befindet. Dieses Labor befasst sich mit der Schaffung von Mikro- und Nanostrukturen.

Die ganze Zeit habe ich als Forscher gearbeitet, und das hatte weder mit ML noch mit Programmierung zu tun. Dies zeigt, wie niedrig der Schwellenwert für den Einstieg in das maschinelle Lernen ist und wie schnell Sie sich darin entwickeln können. In der Region 2013 riefen mich meine Freunde zu einem Startup, das sich mit ML beschäftigte. Und im Laufe von 2-3 Jahren habe ich gleichzeitig Programmieren und ML studiert. Mein Fortschritt war ziemlich langsam - ich habe Materialien studiert, mich damit befasst, aber es war nicht so schnell wie jetzt. Für mich änderte sich alles, als ich anfing, an ML-Wettbewerben teilzunehmen. Der erste Wettbewerb war von Avito über die Klassifizierung von Autos. Ich wusste nicht wirklich, wie ich daran teilnehmen sollte, konnte aber den dritten Platz belegen. Unmittelbar danach startete ein weiterer Wettbewerb, der sich bereits der Klassifizierung von Anzeigen widmete. Es gab Bilder, Text, Beschreibung, Preis - es war ein komplexer Wettbewerb. Darin belegte ich den ersten Platz, danach erhielt ich fast sofort ein Angebot und sie brachten mich nach Avito. Dann gab es keine Juniorposition, ich wurde sofort von der Mitte übernommen - fast ohne einschlägige Erfahrung.
Als ich bereits bei Avito arbeitete, nahm ich an Wettbewerben bei Kaggle teil und erhielt in etwa einem Jahr Großmeister. Jetzt bin ich auf dem 58. Platz in der Gesamtwertung. Das ist mein Profil. Nachdem ich anderthalb Jahre bei Avito gearbeitet habe, bin ich nach Dbrain gezogen und jetzt bin ich ein bisschen ein Data Science Director. Ich koordiniere die Arbeit von sieben Data Scientists. Alles, was ich in meiner Arbeit verwende, habe ich aus Wettbewerben gelernt. Daher glaube ich, dass dies ein sehr cooles Thema ist, und ich befürworte in jeder Hinsicht die Teilnahme an Wettbewerben und die Entwicklung.
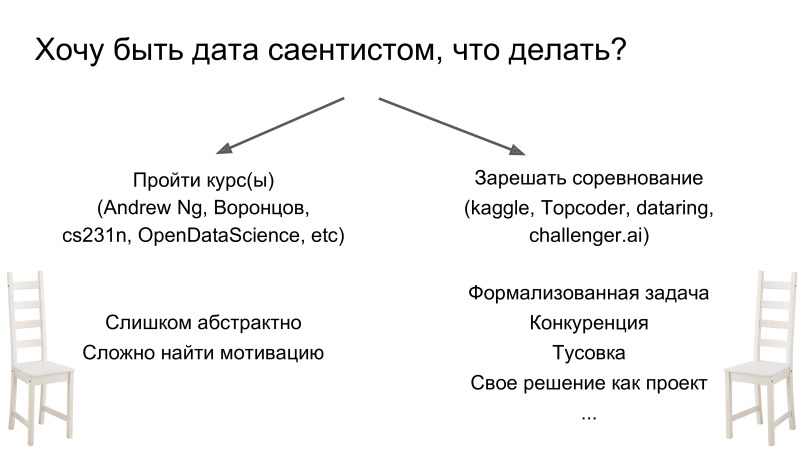
Manchmal fragen sie mich, was zu tun ist, wenn Sie Datenwissenschaftler werden möchten. Es gibt zwei Möglichkeiten. Hören Sie sich zuerst einen Kurs an. Es gibt viele von ihnen, sie sind alle von ziemlich hoher Qualität. Aber für mich persönlich funktioniert es überhaupt nicht. Alle Menschen sind unterschiedlich, aber ich mag es nicht, einfach weil die Kurse in der Regel sehr abstrakte Aufgaben sind und wenn ich einen Abschnitt durchlaufe, verstehe ich nicht immer, warum ich es wissen muss. Im Gegensatz zu diesem Ansatz können Sie einfach die Konkurrenz lösen. Und dies ist ein völlig anderer Ansatz. Es unterscheidet sich darin, dass Sie sofort eine bestimmte Menge an Wissen erwerben und ein neues Thema studieren, wenn Sie auf ein Unbekanntes stoßen. Das heißt, Sie beginnen zu entscheiden und zu verstehen, dass Ihnen das Wissen zum Trainieren eines neuronalen Netzwerks fehlt. Sie nehmen, googeln und studieren - nur wenn Sie es brauchen. Es ist sehr einfach in Bezug auf Motivation und Fortschritt, da Sie bereits eine Aufgabe haben, die streng im Rahmen des Wettbewerbs formuliert ist, eine Zielmetrik und viel Unterstützung in Bezug auf den Open Data Science-Chat. Und als entfernter Bonus ist, dass Ihre Entscheidung ein Projekt sein wird, das noch nicht da ist.

Warum macht es so viel Spaß? Woher kommen die positiven Emotionen? Die Idee ist, dass wenn Sie eine Einreichung senden und diese etwas besser ist als die vorherige, sie sagen - Sie haben die Metrik verbessert, es ist cool. Sie klettern die Rangliste hoch. Wenn Sie dagegen nichts tun und keine Einsendungen senden, gehen Sie nach unten. Und es gibt ein Feedback: Sie fühlen sich gut, wenn Sie Fortschritte machen, und umgekehrt. Dies ist ein cooler Mechanismus, der anscheinend nur Kaggle ausnutzt. Und noch ein Punkt: Kaggle nutzt den gleichen Abhängigkeitsmechanismus wie Spielautomaten und Tinder. Sie wissen nicht, ob Ihre Einreichung besser oder schlechter ist. Dies führt zu der Erwartung eines Ihnen unbekannten Ergebnisses. Kaggle macht also süchtig, aber es ist ziemlich konstruktiv: Sie entwickeln und versuchen, Ihre Entscheidung zu verbessern.
Wie bekomme ich die erste Dosis? Sie müssen in den Kernel-Bereich gelangen. Sie legen einige Rohrleitungsstücke oder die gesamte Lösung aus. Eine andere Frage ist, warum Menschen dies tun. Ein Mann hat Zeit damit verbracht, sich zu entwickeln - was bringt es, es öffentlich zu machen? Sie können den Autor ausnutzen und umgehen.
Die Idee ist, dass erstens die besten Lösungen nicht dargelegt werden. In der Regel sind diese Lösungen aus Sicht der Trainingsmodelle nicht optimal, sie haben nicht alle Nuancen, aber es gibt eine ganze Pipeline von Anfang bis Ende, so dass Sie keine Routineaufgaben im Zusammenhang mit Datenverarbeitung, Nachbearbeitung, Übermittlungssammlung usw. lösen. Dies senkt die Eintrittsschwelle, um neue Marktteilnehmer anzuziehen. Sie müssen verstehen, dass die Community der Datenwissenschaftler sehr offen für Diskussionen und im Allgemeinen recht positiv ist. Ich habe das in der wissenschaftlichen Gemeinschaft nicht gesehen. Die Hauptmotivation ist, dass neue Leute mit neuen Ideen kommen. Dies entwickelt eine Diskussion über das Problem, den Wettbewerb und ermöglicht es der gesamten Gemeinschaft, sich zu entwickeln.
Wenn Sie die Entscheidung eines anderen getroffen, sie gestartet und mit dem Training begonnen haben, empfehle ich als Nächstes, die Daten zu untersuchen. Banaler Rat, aber Sie werden nicht glauben, wie viele Leute von oben ihn nicht benutzen. Um zu verstehen, warum dies wichtig ist, empfehle ich Ihnen, den Bericht von Eugene Nizhibitsky zu lesen. Er spricht über die
Gesichter in den Filmwettbewerben und über das
Gesicht in Airbus , was man auch einfach anhand der Daten sehen kann. Dies nimmt nicht viel Zeit in Anspruch und hilft, das Problem zu verstehen. Und die Gesichter auf den Bildern handelten von der Tatsache, dass es auf verschiedenen Plattformen und in verschiedenen Wettbewerben möglich war, Testantworten vom Zug zu erhalten. Das heißt, Sie konnten kein Modell trainieren, sondern sich nur die Daten ansehen und verstehen, wie Sie die Antworten für Ihren Test teilweise oder vollständig sammeln können. Dies ist eine Gewohnheit, die nicht nur bei Wettbewerben wichtig ist, sondern auch in der Praxis, wenn Sie mit Datenwissenschaftlern zusammenarbeiten. Im wirklichen Leben wird die Aufgabe höchstwahrscheinlich schlecht formuliert sein. Sie formulieren es nicht, aber Sie müssen verstehen, was seine Essenz und Essenz von Daten sind. Die Gewohnheit, Daten zu betrachten, ist sehr wichtig, verbringen Sie Zeit damit.
Als nächstes müssen Sie verstehen, was die Aufgabe ist. Wenn Sie sich die Daten angesehen haben und verstehen, was das Ziel ist ... Wenn ich das richtig verstehe, sind Sie größtenteils aus Fiztekh. Sie müssen kritisch denken, was Sie zu der Frage aufwirft: Warum haben die Leute, die den Wettbewerb entworfen haben, alles richtig gemacht? Warum nicht zum Beispiel die Zielmetrik ändern, nach etwas anderem suchen und die richtigen Dinge aus der neuen Metrik sammeln? Meiner Meinung nach ist es jetzt, da es eine Reihe von Tutorials und den Code anderer Leute gibt, kein Problem, Feeds vorherzusagen. Ein Modell zu trainieren, ein neuronales Netzwerk zu trainieren ist eine sehr einfache Aufgabe, die einem sehr breiten Personenkreis zugänglich ist. Es ist jedoch wichtig zu verstehen, was Ihr Ziel ist, was Sie vorhersagen und wie Sie Ihre Zielmetrik zusammenstellen. Wenn Sie etwas vorhersagen, das in der objektiven Realität irrelevant ist, lernt das Modell einfach nicht und Sie erhalten eine sehr schlechte Geschwindigkeit.
Beispiele. Beim Topcoder Konica-Minolta fand ein Wettbewerb statt.

Es bestand aus Folgendem: Sie haben zwei Bilder, das obere, und eines davon hat Schmutz, einen kleinen Punkt rechts. Es war notwendig, es hervorzuheben und zu segmentieren. Es scheint eine sehr einfache Aufgabe zu sein, und neuronale Netze sollten sie jeweils lösen. Das Problem ist jedoch, dass dies zwei Bilder sind, die entweder mit einem Zeitunterschied oder von verschiedenen Kameras aufgenommen wurden. Infolgedessen bewegte sich ein Bild ein wenig relativ zu einem anderen. Die Skala war wirklich sehr klein. Aber es gab noch ein anderes Merkmal dieser Aufgabe, dass Masken auch klein sind. Es gibt ein Bild, das sich relativ zu einem anderen bewegt hat, während sich die Maske noch relativ dazu bewegt hat. Es ist ungefähr klar, was die Schwierigkeit ist.

Aleksey Buslaev belegte auf dem dritten Platz das siamesische neuronale Netz mit zwei Eingaben, so dass diese siamesischen Köpfe einige Transformationen in Bezug auf dieses verzerrte Bild lernten. Danach kombinierte er diese Merkmale, hatte eine Reihe von Windungen und bekam eine Art Vorhersage. Um diese Neigung in den Daten auszugleichen, stellte er ein ziemlich kompliziertes Netzwerk zusammen. Zum Beispiel habe ich noch nie ein siamesisches Netzwerk trainiert, ich musste dies nicht tun. Er hat es geschafft, es ist sehr cool, er hat den dritten Platz belegt. An erster Stelle stand Evgeny (nrzb.), Der das Bild einfach in der Größe veränderte. Er sah dies als eine Überhöhung in den Daten an, weil er sie ansah, die Größe der Bilder änderte und das Vanille-UNet trainierte. Dies ist ein sehr einfaches neuronales Netzwerk, es steht nur im Lehrbuch, in Artikeln. Dies zeigt, dass Sie mit einer einfachen Lösung ganz oben stehen können, wenn Sie sich die Daten ansehen und das richtige Ziel auswählen.
Ich bin auf dem zweiten Platz gelandet, weil ich mit Zhenya befreundet bin. Danach waren die Topcoder aus irgendeinem Grund beleidigt und haben mich nicht zum Kaggle-Team gebracht. Aber sie sind sehr coole Typen, Topcoder belegte 5-6 Platz, dies (NRZB.) Und Victor Durnov. Alexander Buslaev belegte den dritten Platz. Sie schlossen sich weiter zusammen und zeigten die Klasse in einem Wettbewerb, der in Kaggle stattfand. Dies ist auch ein Beispiel für eine sehr schöne Lösung, bei der die Jungs nicht nur eine monströse Architektur entwickelten, sondern auch das richtige Ziel auswählten.

Die Aufgabe bestand hier darin, die Zellen zu segmentieren und nicht nur zu sagen, wo sich die Zelle befindet und wo nicht, sondern es war notwendig, einzelne Zellen zu isolieren, beispielsweise die Segmentierung jeder unabhängigen Zelle. Darüber hinaus gab es vor diesem Wettbewerb viele Segmentierungswettbewerbe, und es wurde behauptet, dass das Segmentierungsproblem von der ODS-Community auf dem Stand des Handwerks recht gut gelöst wurde, ein gewisser Spitzenwert der Wissenschaft, der es uns ermöglicht, dieses Problem gut zu lösen.
Gleichzeitig wurde die Aufgabe der inst-Segmentierung, wenn Sie die Zellen trennen müssen, sehr schlecht gelöst. Stand der Technik vor diesem Wettbewerb war MacrCNN, eine Art Detektor, ein Merkmalsextraktor, dann ein Block, der die Segmentierung von Masken durchführt, und es ist alles ziemlich schwierig zu trainieren. Sie müssen jedes Stück der Pipeline einzeln trainieren, es ist ein ganzes Lied.
Stattdessen hat Topcoder eine Pipeline entwickelt, wenn Sie nur Zellen und Grenzen vorhersagen. Die Pipeline-Segmentierung ist geringfügig und ermöglicht eine sehr schöne Segmentierung, bei der Ränder von Zellen subtrahiert werden. Danach haben sie die Messlatte in Bezug auf die Genauigkeit dieses Algorithmus höher gelegt, während ihr separates neuronales Netzwerk Zellen besser vorhersagt als alles, was Wissenschaftler zuvor in diesem Bereich getan haben. Das ist cool für Topcoder und sehr schlecht für Akademiker. Soweit ich weiß, haben Akademiker kürzlich versucht, einen Artikel zu diesem Datensatz zu veröffentlichen. Sie haben ihn abgelehnt, weil sie das Ergebnis bei Kaggle nicht übertreffen konnten. Für Akademiker sind schwierige Zeiten gekommen, jetzt müssen wir etwas Normales tun und nicht nur verschlüsseln auf ihrem Gebiet.

Das nächste, wofür ich nicht nur bei Kaggle, sondern auch bei der Arbeit sehr ertrinke, ist Pfeifentraining. Ich sehe nicht viele Werte darin, eine monströse neuronale Netzwerkarchitektur zu erstellen, die coole Teile mit Dämpfung und Funktionsverkettungen liefert. Es funktioniert alles, aber es ist viel wichtiger, nur ein neuronales Netzwerk trainieren zu können. Und es gibt keine Sinnesrakete, es ist eine ziemlich einfache Sache, wenn man bedenkt, dass es jetzt eine Reihe von Artikeln, Tutorials und so weiter gibt. Ich sehe viele Werte in der Tatsache, dass Sie nur ein Pipeline-Training hatten. Ich verstehe dies als einen Code, der auf einer Konfiguration ausgeführt wird und Ihnen ein neuronales Netzwerk auf kontrollierte, vorhersehbare und ziemlich schnelle Weise beibringt.
Diese Folie zeigt die Trainingsprotokolle des Wettbewerbs, der gerade stattfindet, Kaggle Salt. Ich habe noch ein paar Grafikkarten, das ist auch ein Bonus. Die Idee ist, dass ich mit Hilfe der Pipeline eine Rastersuche nach Architekturen durchgeführt habe, die mir am interessantesten erschien. Ich habe nur eine Startkonfiguration für alle Architekturen erstellt, ein Forum zum Zoo neuronaler Netze, bin über alle neuronalen Netze gegangen und habe sie ohne Anstrengung trainiert. Dies ist ein sehr großer Bonus, und das verwende ich von Wettbewerb zu Wettbewerb und bei der Arbeit. Daher bin ich äußerst aufgeregt, nicht nur neuronale Netze zu trainieren, sondern auch darüber nachzudenken, was Sie unterrichten und was Sie in Bezug auf die Pipeline schreiben, dass Sie es wiederverwenden sollten.

Hier habe ich einige wichtige Dinge hervorgehoben, die in der Trainingspipeline sein sollten. Dies ist eine Startkonfiguration, die den Lernprozess vollständig definiert. Wo Sie alle Parameter zu Daten, zu neuronalen Netzen, zu Verlusten angeben, sollte sich alles in der Startkonfiguration befinden. Dies sollte steuerbar sein. Weitere Protokollierung. Die schönen Protokolle, die ich gezeigt habe, sind das Ergebnis der Tatsache, dass ich jeden Schritt aufzeichne, den ich mache.
Modularität bedeutet, dass Sie nicht viel Zeit benötigen, um ein neues neuronales Netzwerk, eine neue Erweiterung oder einen neuen Datensatz hinzuzufügen. Dies sollte alles sehr einfach und wartbar sein.
Die Reproduzierbarkeit repariert nur die Samen, während es in NumPy und Random nicht nur zufällige gibt, sondern es gibt immer noch einige Paiterchiks, ich werde Ihnen mehr erzählen. Und Wiederverwendbarkeit. Sobald Sie eine Pipeline entwickelt haben, kann sie für andere Aufgaben verwendet werden. Und dies ist ein großer Bonus. Wer früh an Wettbewerben teilnimmt, kann diese Pipelines weiterhin in Wettbewerben und bei der Arbeit nutzen. Dies alles gibt anderen Teilnehmern einen großen Bonus.
Einige fragen sich vielleicht: Ich weiß nicht, wie man codiert, was zu tun ist, wie man eine Pipeline entwickelt? Es gibt eine Lösung.

Sergey Kolesnikov ist mein Kollege, der in Dbrain arbeitet, er hat so etwas schon lange entwickelt. Zuerst nannte er sie PyTorch Common, dann Prometheus, jetzt heißt es Katalanisch. Höchstwahrscheinlich wird der Name in einer Woche anders sein, aber der Link wird zum nächsten Namen führen. Folgen Sie dem Link "Katalanisch".
Die Idee ist, dass Sergey eine Art Bibliothek entwickelt hat, die eine Zugschleife ist. Und es hat in der aktuellen Version fast alle Eigenschaften, die ich beschrieben habe. Es gibt immer noch eine Reihe von Beispielen für die Klassifizierung, Segmentierung und eine Reihe anderer cooler Dinge, die er entwickelt hat.
Hier ist eine Liste der Funktionen, die vorhanden sind und sich entwickeln. Sie können diese Bibliothek verwenden, um Ihre Algorithmen und Ihre neuronalen Netze im Wettbewerb zu trainieren, der derzeit stattfindet. Ich empfehle jedem, es zu tun.
Im Gegensatz dazu gibt es eine andere FastAI, kürzlich veröffentlichte Version 1.0, aber es gibt ekelhaften Code und nichts ist klar.
Sie können es beherrschen, es wird Ihnen etwas Wachstum geben, aber aufgrund der Tatsache, dass es in Bezug auf Code sehr schlecht geschrieben ist, haben sie ihren eigenen Fluss in Bezug darauf, wie es geschrieben werden sollte. Ab einem bestimmten Zeitpunkt werden Sie nicht verstehen, was passiert. Daher empfehle ich FastAI nicht, ich empfehle die Verwendung eines "Katalisten".

Angenommen, Sie haben das alles durchlaufen, Sie haben Ihre eigene Pipeline, Ihre eigene Entscheidung, und jetzt können Sie am Team teilnehmen. Emil wurde nur gefragt, wie gerechtfertigt es ist, einem Team beizutreten, wenn Sie daran teilnehmen, wie dies geschieht. Es scheint mir, dass es sich trotzdem lohnt, sich zusammenzuschließen, auch wenn Sie nicht oben, sondern irgendwo in der Mitte sind. Wenn Sie Ihre Lösung selbst entwickelt haben, unterscheidet sie sich in einigen Details immer von der Entscheidung anderer Personen. Und wenn es kombiniert wird, gibt es fast immer Auftrieb bei anderen Teilnehmern.
Außerdem macht es Spaß, es ist Teamwork in Bezug auf die Tatsache, dass Sie jetzt ein gemeinsames Repository haben, in dem Sie den Code des anderen sehen können, ein gemeinsames Format für Einreichungen und einen Chatraum, in dem der ganze Spaß passiert. Soziale Interaktion und Soft Skills sind auch in der Arbeit sehr wichtig, was ebenfalls eine Entwicklung wert ist.
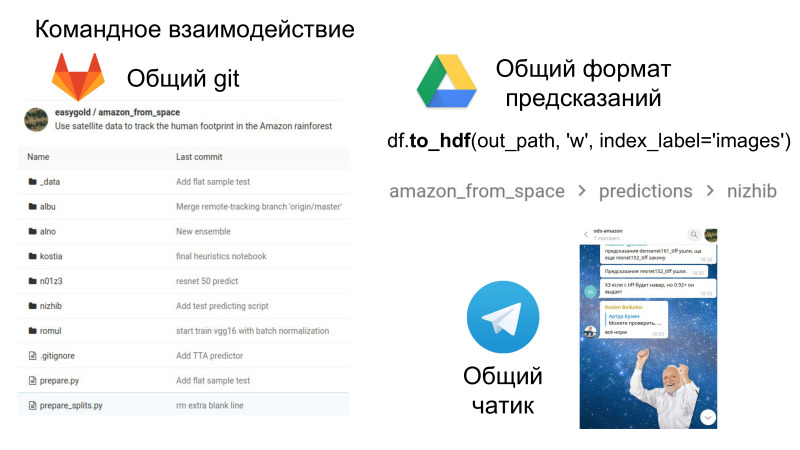
Dies ist ein großer Bonus in dem Sinne, dass Sie jetzt den Code anderer Leute sehen, wie sie diese oder jene Entscheidung treffen. Und ziemlich oft schaue ich mit meinen vorherigen Befehlen in das Repository und finde dort coole Lösungen in Bezug auf den Code selbst. Dies kann in Form von Teamarbeit aus dem Wettbewerb herausgenommen werden.
Angenommen, Sie sind die ganze Runde gegangen. Was hast du ertragen?

Höchstwahrscheinlich haben Sie gelernt, den Code eines anderen auszuführen. Ich hoffe wirklich, dass Sie sich angewöhnt haben, Daten zu betrachten. Sie verstehen das Problem, haben gelernt, Experimente durchzuführen, haben eine eigene Lösung und können es jetzt in Form eines Projekts entwerfen. Wenn Sie abstrakt schauen, ist es der normalen Arbeit in einem IT-Unternehmen sehr ähnlich. Wenn Sie einen Wettbewerb durchlaufen haben und ein gutes Ergebnis gezeigt haben, ist dies zumindest für mich eine Stärke im Lebenslauf. Irgendwann zwischen 20 und 25 wurde ich interviewt, als ich bei Dbrain rekrutierte. Dort konnten einige Grenzfälle identifiziert werden. Es gab einen Typen, der gerade den öffentlichen Kernel betrieben hat und es nicht wirklich herausgefunden hat. Es sah schlecht für mich aus, ich wollte nur, dass der Typ das Problem versteht, ich habe es nicht angenommen.
Ein anderer Typ, der ehrlich gesagt hat, dass er in der Rangliste überfordert war, aber gleichzeitig alle Details seiner Entscheidung, die auf dem Datascience Bowl stand, erzählt hat, haben wir getroffen, ich arbeite wirklich gerne mit ihm. Kaggle und Ihre Entscheidung Es gibt eine ziemlich starke Stelle in Ihrem Lebenslauf. Wenn Sie ihn in Form einer Präsentation richtig formatieren können, ist dies eine gute Show für den zukünftigen Arbeitgeber.
Wenn ich Fragen zum persönlichen Gewinn habe, hoffe ich, dass ich geschlossen habe, warum brauchen Unternehmen das?

Ich habe bei Avito gearbeitet, sie veranstalteten regelmäßig Wettbewerbe zur Datenanalyse. Dafür gibt es mehrere Gründe. Wenn der Wettbewerb stattfindet, müssen Sie mindestens einen Datensatz sammeln und die Aufgabe sehr gut formulieren, was etwas schmerzhaft ist.

Das heißt, die Erklärung des Problems plus des Datensatzes ist bereits viel für das Unternehmen. , «» , , , , . — , , .
, , , , . , , . - , , , .
, , — . , . , «» , . «» — , .

, — . , - . , — , . , , , . — importance XGBoost . , , . . , . , . , .
, , - , , , . , , , .

—
Coursera , . —
ML- ODS- . Ich habe alles