
In diesem Sommer haben wir dem neuronalen Netzwerk beigebracht, festzustellen, ob und welches Dokument auf dem Bild vorhanden ist.
Warum wird es gebraucht?
Mitarbeiter entladen und Personen vor Betrügern schützen. Wir verwenden das neue neuronale Netzwerk in zwei Bereichen: Wenn der Benutzer wieder Zugriff auf die Seite hat und um persönliche Dokumente vor der allgemeinen Suche zu verbergen.
Wiederherstellen des Zugriffs auf Seiten. Fotos von Dokumenten helfen dabei, Konten an ihre wahren Besitzer zurückzugeben. Beispielsweise hat ein Benutzer möglicherweise den Zugriff auf seine Telefonnummer verloren oder die zweistufige Authentifizierung wurde auf der Seite aktiviert, und es besteht keine Möglichkeit mehr, einen einmaligen Code zur Bestätigung der Eingabe zu erhalten. Die neue Entwicklung beschleunigt die Berücksichtigung von Anwendungen: Moderatoren müssen nicht mehr jedes Mal falsch ausgefüllte Anwendungen zurückgeben. Das System erlaubt dem Besucher einfach nicht, das Formular ohne die erforderlichen Bilder einzureichen, und fordert ihn auf, das zufällige Bild durch ein Dokument zu ersetzen. Natürlich können wir den Zugriff auf die Seite selbst nur dann zurückgeben, wenn sie echte Fotos des Eigentümers enthält. Wir sprechen über die Sicherheit von Konten und die Aufbewahrung personenbezogener Daten - was bedeutet, dass es einfach keine Fehler und Unfälle geben kann.
Filtern von Suchergebnissen im Abschnitt " Dokumente ". Alle Dokumente, die Benutzer in diesen Bereich hochladen oder über private Nachrichten senden, sind standardmäßig vor neugierigen Blicken verborgen und fallen nicht in die Suchergebnisse. Der Datenschutz kann jedoch manuell selbst konfiguriert werden - für jede einzelne Datei. Vor dem Aufkommen des neuronalen Netzwerks konnte man eine anständige Menge von Dokumenten mit sensiblen Daten unter Verwendung von Schlüsselwörtern finden. Die Eigentümer dieser Dateien haben die Datenschutzeinstellungen selbst geändert. Wir haben Benutzer gesichert und begonnen
, Fotos
aus einer öffentlichen Suche zu entfernen, in der wir das Vorhandensein eines Dokuments feststellen können.
Wie wir das Problem gelöst haben
Es scheint, dass der einfachste Weg, Dokumente in einem Bild zu identifizieren, darin besteht, ein neuronales Netzwerk einzurichten oder es in einer großen Stichprobe von Grund auf neu zu trainieren. Aber nicht so einfach.
Die Stichprobe sollte repräsentativ sein. Es ist schwierig, für jede Option eine ausreichende Anzahl realer Stichproben zu finden: Es gibt keine öffentlichen Datenbanken mit diesen Dokumenten im öffentlichen Bereich.
Es gibt viele Systeme, die Dokumente erkennen und analysieren. Normalerweise zielen sie darauf ab, bestimmte Informationen von einem Foto zu erhalten und die ideale Qualität des Originalbildes vorzuschlagen. Beispielsweise kann ein Benutzer aufgefordert werden, den Pass an den Rändern der Vorlage auszurichten, da dies im State Services-Portal funktioniert.
Solche Systeme sind für unsere Aufgaben nicht geeignet. Wir stellen separat klar, dass der Benutzer bei der Kontaktaufnahme zur Wiederherstellung des Zugriffs alle Daten im Dokument schließen kann, mit Ausnahme von Fotos, Vorname, Nachname und Druck. Gleichzeitig müssen wir das Dokument noch bestimmen - auch wenn die Serie und die Nummer darauf versteckt sind, wenn der Reisepass mit der Umgebung aufgenommen wurde oder umgekehrt nur ein Teil des Dokuments mit dem Foto auf dem Bild erschien. Müssen noch unterschiedliche Beleuchtung und Winkel berücksichtigen. Das neuronale Netzwerk muss alle derartigen Materialien akzeptieren. Die Frage ist, wie man ihr das beibringt.

Es gibt andere Schwierigkeiten. Beispielsweise ist es schwierig, den Reisepass von anderen Arten von Dokumenten sowie von verschiedenen handgeschriebenen und gedruckten Papieren zu trennen.
Der Versuch, den einfachen Weg zu gehen, war nicht sehr erfolgreich. Der resultierende Klassifikator erwies sich als schwach mit einem kleinen Fehler der ersten Art und einem großen Fehler der zweiten Art. Zum Beispiel gab es interessante Fälle, in denen eine Person einen Vor- und Nachnamen von Hand schrieb, ein Foto zeichnete, den Umschlag eines Passes - und das System dieses Dokument munter akzeptierte.
Zu was sind wir gekommen?
In unserer Situation bestand die beste Lösung für das Problem darin, ein Ensemble von Gittern und Gesichtsdetektoren zu verwenden, um ein Dokument zu erkennen und seinen Typ zu bestimmen. Wir haben außerdem einen Differenzialklassifizierer hinzugefügt, der einen Encoder zum Hervorheben charakteristischer Merkmale und einen Formularklassifizierer enthält, mit dem Sie Dokumentbilder von irrelevanten Dateien unterscheiden können. Zusätzlich wird ein vorläufiges Clustering des Trainingssatzes durchgeführt, um den Datensatz zu normalisieren. Von den Architekturen haben sich
VGG und
ResNet bewährt.
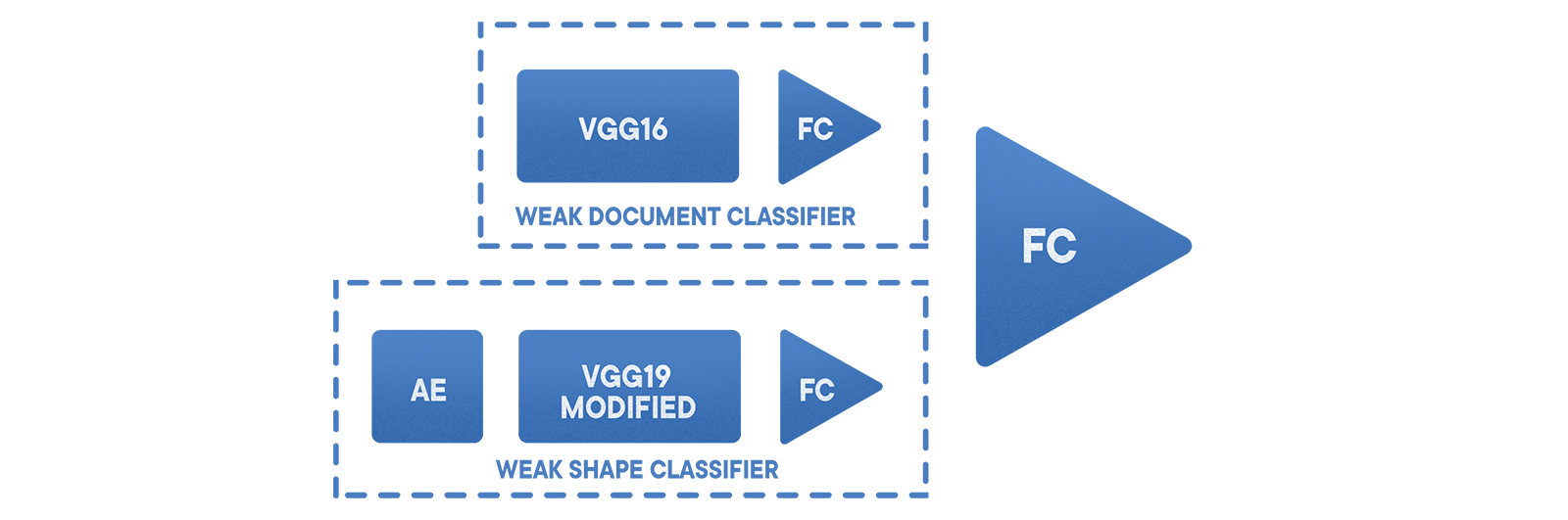
Der grundlegende Klassifikator „Dokument / Nicht-Dokument“ basiert auf einer abgestimmten VGG mit 19 Ebenen und einer in Zonen aufgeteilten Stichprobe. Darüber hinaus wird ein kombiniertes Ensemble von Klassifikatoren verwendet, die den Fehler der zweiten Art reduzieren und das Ergebnis differenzieren. Zuerst kommt eine
geschichtete Abtastung , dann ein Codierer zum Extrahieren von Informationen in der Nähe der Schleife, dann ein modifiziertes VGG und schließlich ein einzelnes Gitter. Dieser Ansatz ermöglichte es, Fehler der ersten Art auf ein Niveau von etwa 0,002 zu minimieren. Die Wahrscheinlichkeit eines falsch negativen Ergebnisses hängt in diesem Fall vom ausgewählten Datensatz und der spezifischen Anwendung ab.
Jetzt haben wir gelernt, wie das Vorhandensein von Pässen und Führerscheinen auf dem Bild automatisch erkannt wird. Die Erkennung erfolgt in jedem Winkel und mit jedem Hintergrund erfolgreich, auch bei schlechten Lichtverhältnissen. Hauptsache, das Bild enthält einen Teil des Dokuments mit einem Foto und einem Namen. Zur Identifizierung anderer Dokumenttypen sind jedoch nur relevante Datensätze erforderlich. Wir trainieren das Netzwerk anhand unserer eigenen Daten. Die Stichprobengröße der Dokumente liegt zwischen fünftausend und zehntausend (ist jedoch nicht repräsentativ). Für andere Bilder ist das Beispiel beliebig, aber es gibt sowohl dort als auch dort eine a priori-Clusterbildung.
Aus technischer Sicht ist das System in Python /
Keras /
Tensorflow /
Glib /
OpenCV geschrieben . Für die praktische Anwendung des neuen Systems reicht es aus, es in Python-Handler der Infrastruktur für maschinelles Lernen zu integrieren. Gleichzeitig wird ein Fotoänderungsdetektor in Grafikeditoren hinzugefügt, aber dieses Thema verdient einen separaten Artikel.
Was ist das Ergebnis?
Jetzt werden 6% der Anträge auf Wiederherstellung des Zugriffs automatisch an den Autor zurückgesandt, mit der Aufforderung, ein Foto des Dokuments hinzuzufügen oder zu ersetzen, und 2,5% der Anträge werden abgelehnt. Wenn Sie die Analyse von Bildern als Ganzes betrachten, einschließlich Heuristik und Gesichtssuche in einem Bild, werden
bis zu 20% der Arbeit der Abteilung automatisiert .
Nach dem Start des neuronalen Netzes konnten wir auch die Anzahl der Pässe berechnen, die in den Bereich „Dokumente“ hochgeladen wurden. Es stellte sich heraus, dass in den allgemeinen Suchergebnissen jeden Tag etwa zweitausend Ausweise vorhanden waren. Jetzt ist die Wahrscheinlichkeit, dass sie in fremde Hände fallen, minimal.
Neuronale Netze helfen uns bereits bei der Bekämpfung von Spam und Betrug aller Art. Wir stoppen die Experimente nicht und sprechen weiterhin in unserem Blog darüber.