Dieser Artikel ist eine Übersetzung von Kevin Goldbergs Artikel "Eine Leistungsanalyse von Python-WSGI-Servern: Teil 2" dzone.com/articles/a-performance-analysis-of-python-wsgi-servers-part mit einigen Ergänzungen des Übersetzers.
Einführung
Im
ersten Teil dieser Serie haben Sie
WSGI und die sechs beliebtesten Server kennengelernt, so der Autor von
WSGI . In diesem Teil wird das Ergebnis der Analyse der Leistung dieser Server angezeigt. Zu diesem Zweck wurde eine spezielle Testsandbox erstellt.
Teilnehmer
Aus zeitlichen Gründen war die Forschung auf sechs WSGI-Server beschränkt. Alle Startanweisungen für dieses Projekt
werden auf GitHub gehostet . Vielleicht wird das Projekt im Laufe der Zeit erweitert und Leistungsanalysen für andere WSGI-Server werden vorgestellt. Im Moment werden wir jedoch über sechs Server sprechen:
- Bjoern bezeichnet sich selbst als "ultraschnellen WSGI-Server" und rühmt sich, "der schnellste, kleinste und leichteste WSGI-Server" zu sein. Wir haben eine kleine Anwendung erstellt , die die meisten Standardbibliothekseinstellungen verwendet.
- CherryPy ist ein äußerst beliebtes und stabiles Framework und ein WSGI-Server. Dieses kleine Skript wurde verwendet, um unsere Beispielanwendung über CherryPy bereitzustellen .
- Gunicorn wurde von Rubys Unicorn- Server inspiriert (daher der Name). Er behauptet bescheiden, dass es "einfach implementiert, einfach zu bedienen und ziemlich schnell" ist. Im Gegensatz zu Bjoern und CherryPy ist Gunicorn ein eigenständiger Server. Wir haben es mit diesem Befehl erstellt . Der Parameter "WORKER_COUNT" wurde auf die doppelte Anzahl verfügbarer Prozessorkerne plus eins gesetzt. Dies erfolgte auf der Grundlage von Empfehlungen aus der Gunicorn-Dokumentation .
- Meinheld ist ein leistungsstarker WSGI-kompatibler Webserver, der behauptet, leicht zu sein. Basierend auf dem auf der Server-Site gezeigten Beispiel haben wir unsere Anwendung erstellt .
- mod_wsgi wurde vom selben Ersteller wie mod_python erstellt . Wie mod_python ist es nur für Apache verfügbar. Es enthält jedoch ein Tool namens "mod_wsgi express" , das die kleinstmögliche Apache-Instanz erstellt. Wir haben mod_wsgi express mit diesem Befehl konfiguriert und verwendet. Um Gunicorn zu entsprechen , haben wir mod_wsgi so optimiert , dass doppelt so viele Worker wie Prozessorkerne erstellt werden.
- uWSGI ist ein Anwendungsserver mit vollem Funktionsumfang. In der Regel wird uWSGI mit einem Proxyserver gekoppelt (z. B. Nginx). Um die Leistung jedes Servers besser bewerten zu können, haben wir versucht, nur nackte Server zu verwenden, und zwei Worker für jeden verfügbaren Prozessorkern erstellt.
Benchmark
Um den Test so objektiv wie möglich zu gestalten, wurde ein
Docker- Container erstellt, um den zu testenden Server vom Rest des Systems zu isolieren. Durch die Verwendung des Docker-Containers wurde außerdem sichergestellt, dass jeder Start von vorne beginnt.
Server:
- In einem Docker-Container isoliert.
- 2 Prozessorkerne zugeordnet.
- Der RAM des Containers war auf 512 MB begrenzt.
Testen:
- wrk , ein modernes HTTP-Benchmarking-Tool, führte Tests durch.
- Die Server wurden in zufälliger Reihenfolge getestet, wobei die Anzahl der gleichzeitigen Verbindungen im Bereich von 100 bis 10.000 zunahm.
- wrk war auf zwei CPU-Kerne beschränkt, die von Docker nicht verwendet wurden.
- Jeder Test dauerte 30 Sekunden und wurde viermal wiederholt.
Metrik:
- Die durchschnittliche Anzahl persistenter Anforderungen, Fehler und Verzögerungen wurde von wrk bereitgestellt.
- Die in Docker integrierte Überwachung zeigte die CPU- und RAM-Auslastung.
- Die höchsten und niedrigsten Messwerte wurden verworfen und die verbleibenden Werte wurden gemittelt.
- Für die Neugierigen haben wir das komplette Skript an GitHub geschickt .
Ergebnisse
Alle anfänglichen Leistungsindikatoren
wurden in das Projekt-Repository aufgenommen , und eine zusammenfassende
CSV-Datei wurde ebenfalls bereitgestellt. Zur Visualisierung wurden außerdem Grafiken in der
Google-Doc- Umgebung erstellt.
RPS versus Anzahl gleichzeitiger Verbindungen
Dieses Diagramm zeigt die durchschnittliche Anzahl gleichzeitiger Anforderungen. Je höher die Zahl, desto besser.
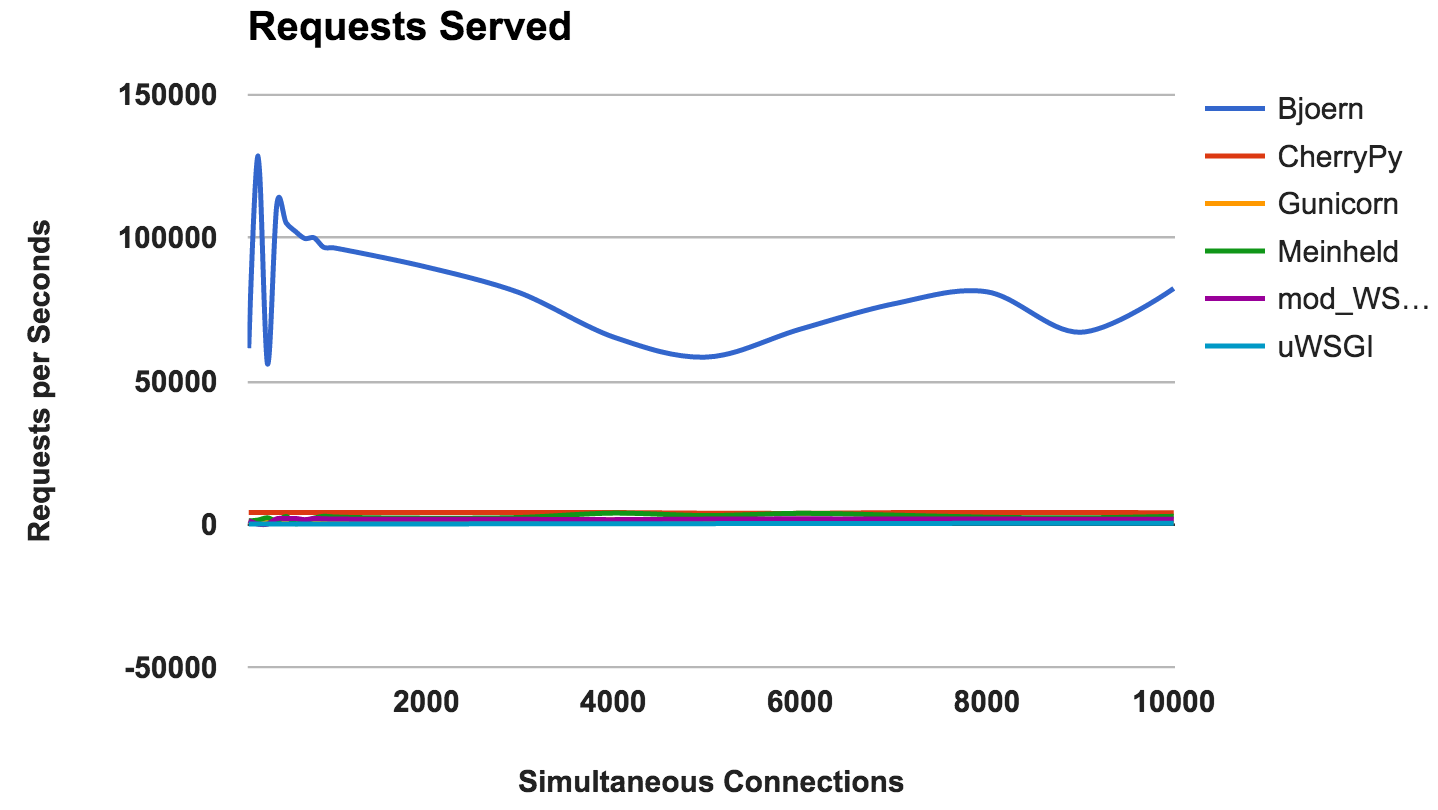
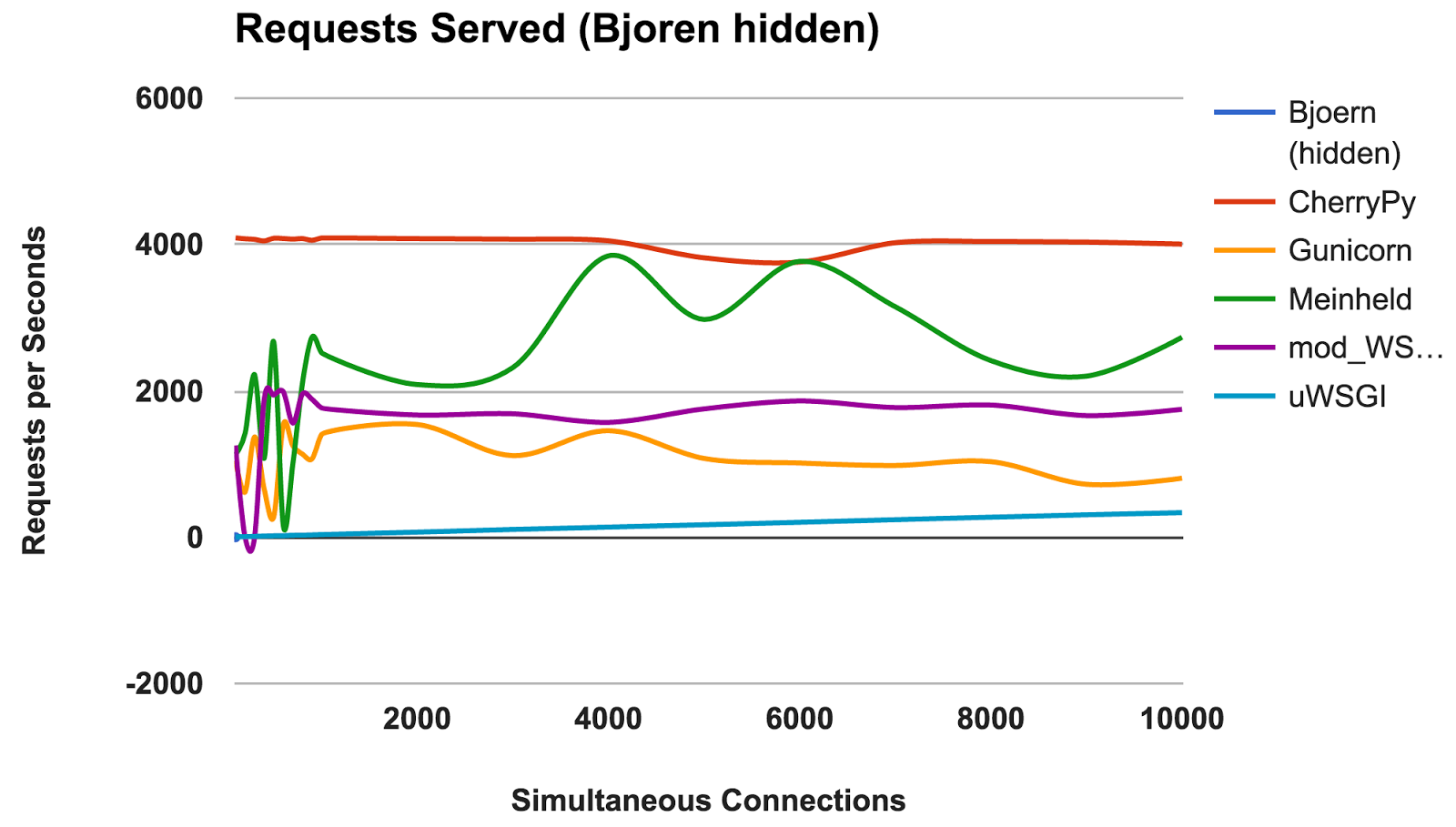
- Björn: Ein klarer Gewinner.
- CherryPy: Obwohl er in reinem Python geschrieben wurde, war er der beste Performer.
- Meinheld: Hervorragende Leistung angesichts der knappen Containerressourcen.
- mod_wsgi: Nicht die schnellste, aber die Leistung war konstant und angemessen.
- Gunicorn: Gute Leistung bei geringerer Belastung, aber es gibt einen Kampf mit einer großen Anzahl von Verbindungen.
- uWSGI: Frustriert über schlechte Ergebnisse.
GEWINNER: BjörnBjörn
Durch die Anzahl der ständigen Anfragen ist
Björn der klare Gewinner. Angesichts der Tatsache, dass die Zahlen viel höher sind als die der Wettbewerber, sind wir jedoch etwas skeptisch. Wir sind uns nicht sicher, ob
Björn wirklich so erstaunlich schnell ist. Zuerst haben wir die Server alphabetisch getestet und wir dachten, dass
Björn einen unfairen Vorteil hat. Das Ergebnis bleibt jedoch auch nach dem Starten der Server in einer zufälligen Serverreihenfolge und dem erneuten Testen unverändert.
uWSGI
Wir waren von den schwachen Ergebnissen von
uWSGI enttäuscht. Wir haben erwartet, dass er an der Spitze steht. Während des Tests haben wir festgestellt, dass
uWSGI- Protokolle auf dem Bildschirm gedruckt werden, und zunächst haben wir die mangelnde Leistung durch die zusätzliche Arbeit des Servers erklärt.
UWSGI ist jedoch auch nach dem
Hinzufügen der Option "
--disable-logging " der langsamste Server.
Wie im
uWSGI- Handbuch erwähnt, ist es normalerweise mit einem Proxyserver wie Nginx verbunden. Wir sind uns jedoch nicht sicher, ob dies einen so großen Unterschied erklären kann.
Verzögerung
Verzögerung ist die Zeitspanne zwischen der Anforderung und ihrer Antwort. Niedrigere Zahlen sind besser.
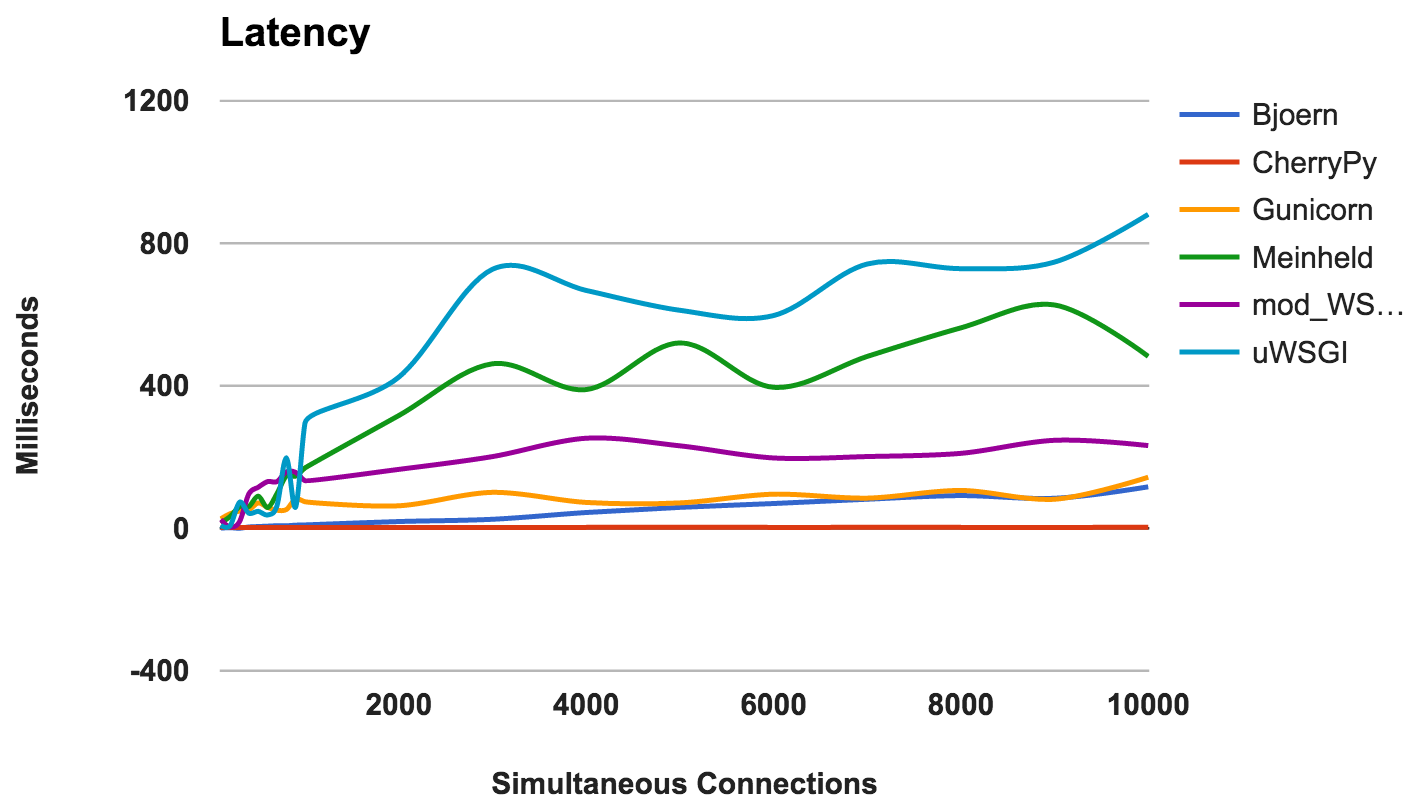
- CherryPy: Die Ladung gut gehandhabt.
- Bjoern: Im Allgemeinen geringe Latenz, funktioniert aber besser mit weniger gleichzeitigen Verbindungen.
- Gunicorn: gut und beständig.
- mod_wsgi: Durchschnittliche Leistung auch bei einer großen Anzahl gleichzeitiger Verbindungen.
- Meinheld: Insgesamt akzeptable Leistung.
- uWSGI: uWSGI ist wieder auf dem letzten Platz.
GEWINNER: CherryPyRAM-Nutzung
Diese Metrik zeigt den Speicherbedarf und die „Leichtigkeit“ jedes Servers. Niedrigere Zahlen sind besser.
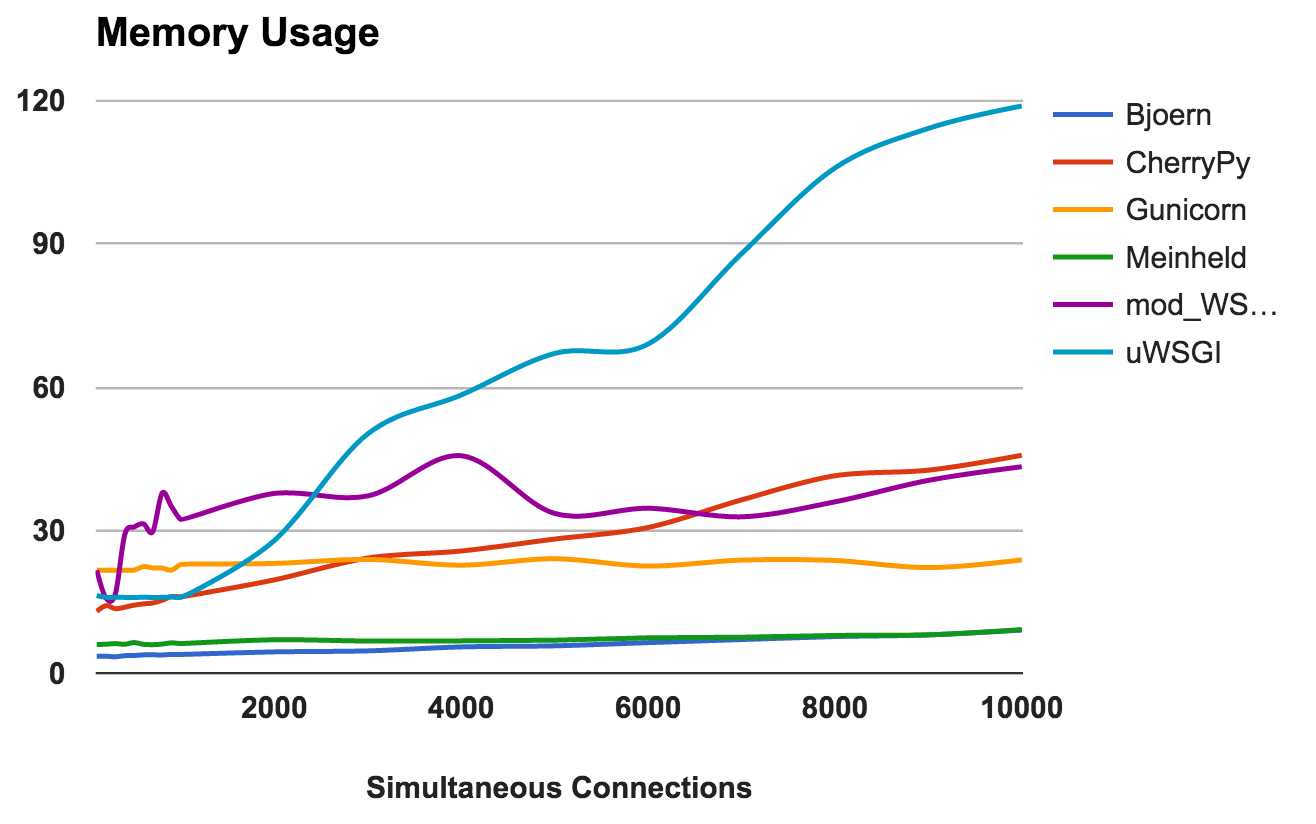
- Björn: Extrem leicht. Es werden nur 9 MB RAM verwendet, um 10.000 gleichzeitige Anforderungen zu verarbeiten.
- Meinheld: Wie Björn.
- Gunicorn: Bewältigt gekonnt hohe Lasten mit kaum wahrnehmbarem Speicherverbrauch.
- CherryPy: Anfangs wurde eine kleine Menge RAM benötigt, aber die Verwendung nahm mit zunehmender Last schnell zu.
- mod_wsgi: Auf niedrigeren Ebenen war es eines der intensivsten im Gedächtnis, blieb aber ziemlich konsistent.
- uWSGI: Offensichtlich hat die Version, die wir testen, Probleme mit der Menge des verbrauchten Speichers.
GEWINNER: Björn und MeinheldAnzahl der Fehler
Ein Fehler tritt auf, wenn der Server abstürzt, unterbrochen wird oder die Anforderung eine Zeitüberschreitung aufweist. Je niedriger desto besser.
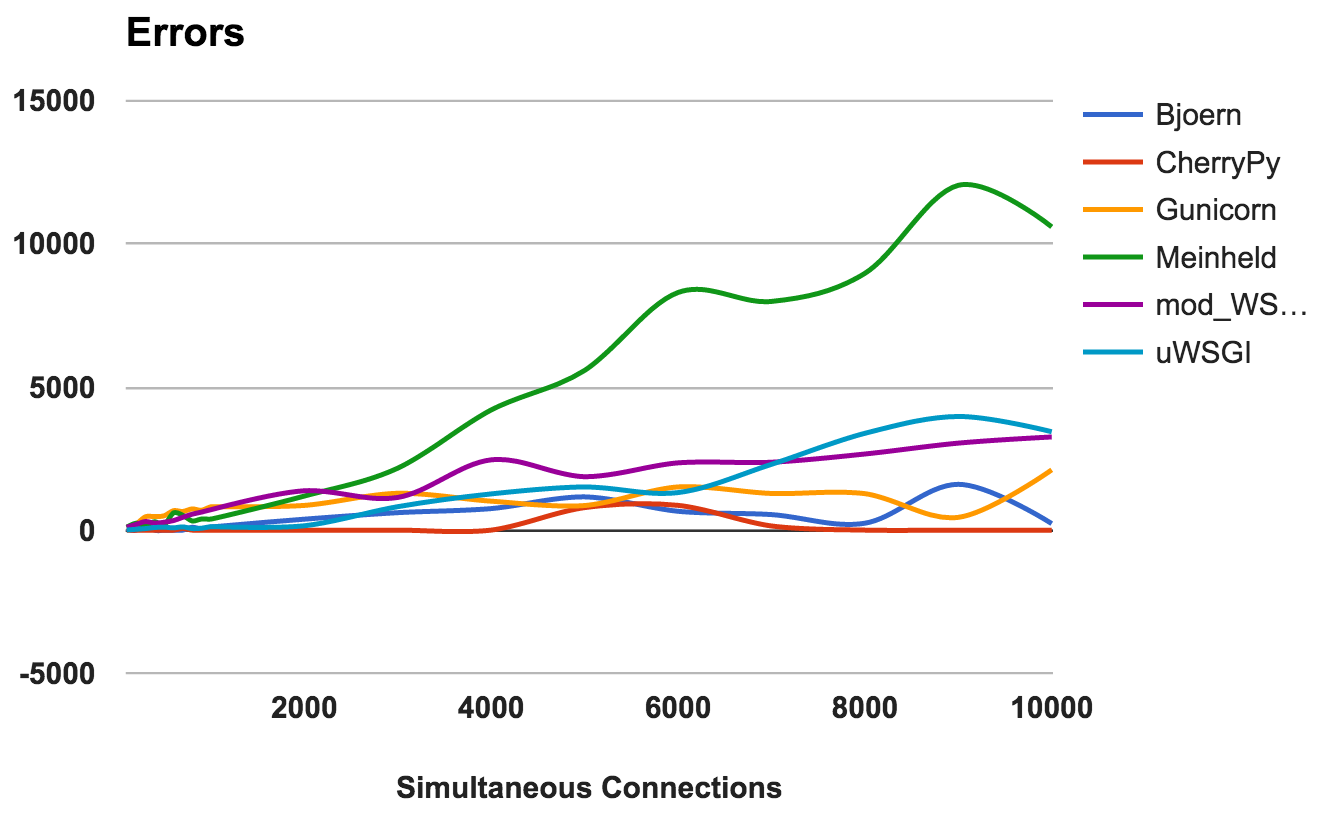
Für jeden Server haben wir das Verhältnis des Gesamtverhältnisses der Anzahl der Anforderungen zur Anzahl der Fehler berechnet:
- CherryPy: Fehlerrate um 0, auch bei einer hohen Anzahl von Verbindungen.
- Bjoern: Es sind Fehler aufgetreten, die jedoch durch die Anzahl der verarbeiteten Anforderungen ausgeglichen wurden.
- mod_wsgi: Funktioniert gut mit einer akzeptablen Fehlerrate von 6%.
- Gunicorn: Funktioniert mit einer Fehlerquote von 9 Prozent.
- uWSGI: Angesichts der geringen Anzahl der Anfragen wurde eine Fehlerquote von 34 Prozent festgestellt.
- Meinheld: Fiel bei höheren Belastungen und warf beim anspruchsvollsten Test mehr als 10.000 Fehler.
GEWINNER: CherryPyCPU-Auslastung
Eine hohe CPU-Auslastung ist nicht gut oder schlecht, wenn der Server gut funktioniert. Dies bietet jedoch einige interessante Informationen über den Server. Da zwei CPU-Kerne verwendet wurden, beträgt die maximal mögliche Nutzung 200 Prozent.
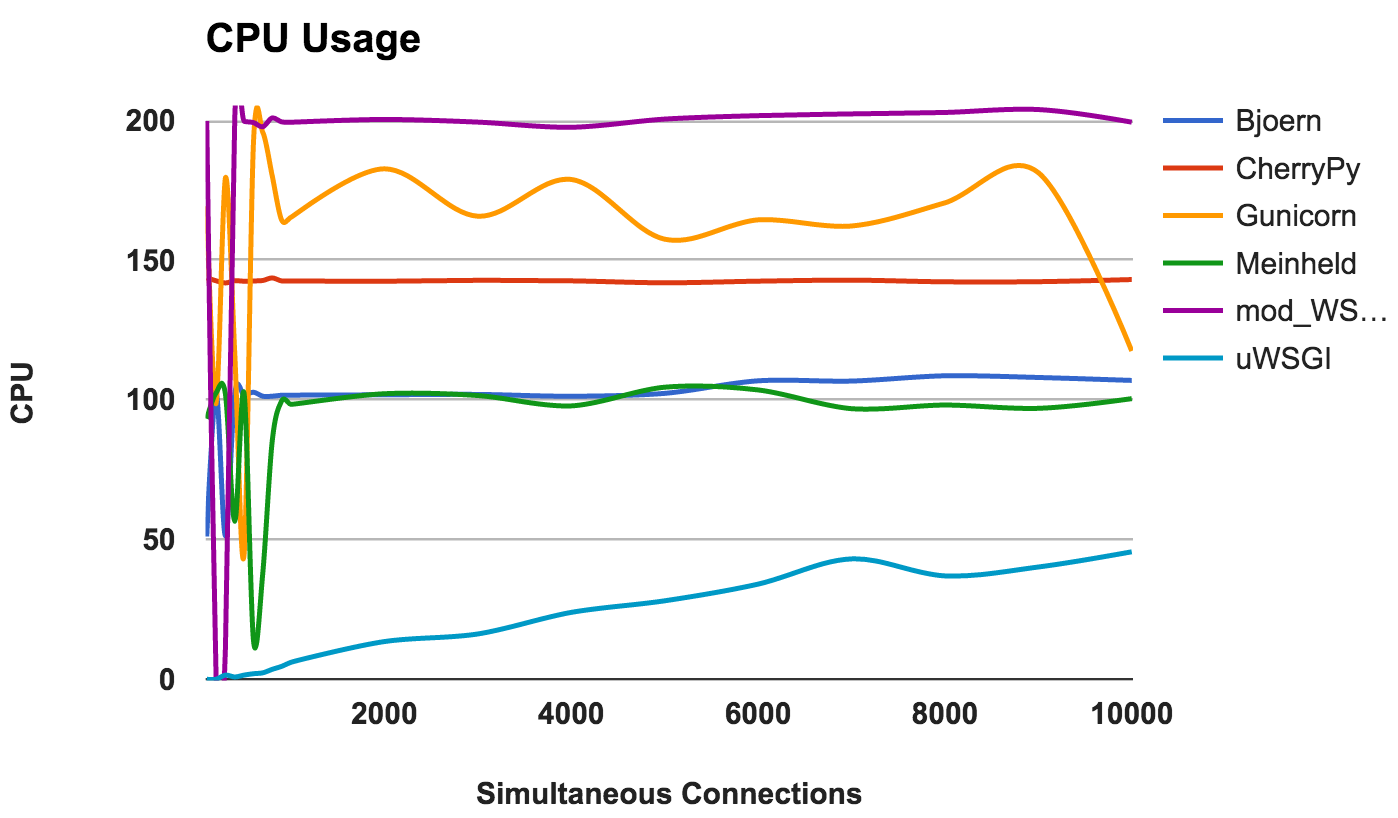
- Bjoern: Ein Single-Threaded-Server, was sich in der konsequenten Nutzung von 100% CPU zeigt.
- CherryPy: Multithread, aber bei 150 Prozent stecken. Dies kann an Python GIL liegen .
- Gunicorn: Verwendet mehrere Prozesse mit voller Auslastung der CPU-Ressourcen auf niedrigeren Ebenen.
- Meinheld: Ein Single-Threaded-Server mit CPU-Ressourcen wie Bjoern.
- mod_wsgi: Ein Multithread-Server, der bei allen Messungen alle CPU-Kerne verwendet
- uWSGI: sehr geringe CPU-Auslastung. Der CPU-Verbrauch beträgt höchstens 50 Prozent. Dies ist ein Beweis dafür, dass uWSGI nicht richtig konfiguriert ist.
GEWINNER: Nein, denn dies ist eher eine Beobachtung des Verhaltens als ein Vergleich der Leistung.Fazit
Zusammenfassend! Hier sind einige allgemeine Ideen, die Sie aus den Ergebnissen der einzelnen Server ziehen können:
- Bjoern: Rechtfertigt sich als "superschneller, ultraleichter WSGI-Server".
- CherryPy: Hohe Leistung, geringer Speicherverbrauch und niedrige Fehlerraten. Nicht schlecht für reines Python.
- Gunicorn: Ein guter Server für mittlere Lasten.
- Meinheld: Funktioniert gut und erfordert nur minimale Ressourcen. Allerdings mit höheren Lasten zu kämpfen.
- mod_wsgi: Integriert sich in Apache und funktioniert hervorragend.
- uWSGI: Sehr enttäuscht. Entweder haben wir uWSGI falsch konfiguriert oder die von uns installierte Version weist grundlegende Fehler auf.