Zuletzt musste ich eine weitere triviale Trainingsaufgabe von meinem Lehrer lösen. Als ich es jedoch löste, gelang es mir, die Aufmerksamkeit auf Dinge zu lenken, an die ich vorher überhaupt nicht gedacht hatte, vielleicht haben Sie auch nicht darüber nachgedacht. Dieser Artikel wird eher für Studenten und für alle nützlich sein, die ihre Reise in die Welt der parallelen Programmierung mit MPI beginnen.

Unser "Gegeben:"
Die Essenz unserer im Wesentlichen rechnerischen Aufgabe besteht also darin, zu vergleichen, wie oft ein Programm, das nicht blockierende, verzögerte Punkt-zu-Punkt-Übertragungen verwendet, schneller ist als das Programm, das blockierende Punkt-zu-Punkt-Übertragungen verwendet. Wir werden Messungen für Eingabearrays der Dimensionen 64, 256, 1024, 4096, 8192, 16384, 65536, 262144, 1048576, 4194304, 16777216, 33554432 durchführen. Standardmäßig wird vorgeschlagen, es durch vier Prozesse zu lösen. Und hier ist in der Tat, was wir betrachten werden:
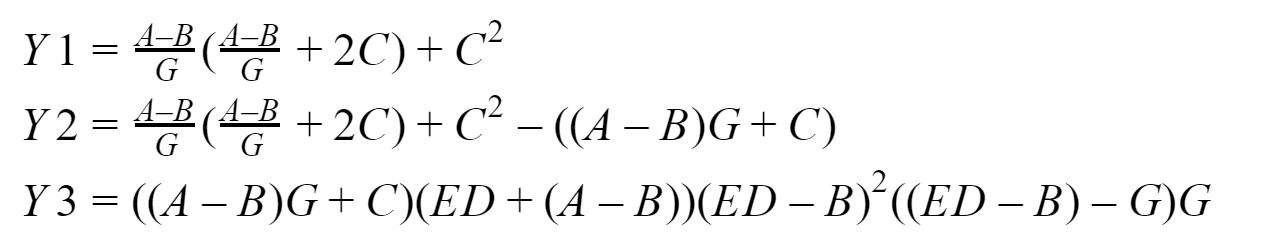
Am Ausgang sollten wir drei Vektoren erhalten: Y1, Y2 und Y3, die der Nullprozess sammelt. Ich werde das Ganze auf meinem System testen, das auf
einem Intel-Prozessor mit 16 GB RAM basiert. Für die Entwicklung von Programmen verwenden wir die Implementierung des
MPI- Standards
aus Microsoft Version 9.0.1 (zum Zeitpunkt des Schreibens ist dies relevant), Visual Studio Community 2017 und nicht Fortran.
Materiel
Ich möchte nicht im Detail beschreiben, wie die verwendeten MPI-Funktionen funktionieren. Sie können sich jederzeit
die Dokumentation dazu ansehen , daher werde ich nur einen kurzen Überblick darüber geben, was wir verwenden werden.
Austausch blockieren
Zum Blockieren von Punkt-zu-Punkt-Nachrichten verwenden wir die folgenden Funktionen:MPI_Send - implementiert das Blockieren des Sendens von Nachrichten, d. H. Nach dem Aufrufen der Funktion wird der Prozess blockiert, bis die an ihn gesendeten Daten aus seinem Speicher in den internen MPI-Systempuffer geschrieben wurden. Danach arbeitet der Prozess weiter.
MPI_Recv - führt einen blockierenden Nachrichtenempfang durch, d.h. Nach dem Aufruf der Funktion wird der Prozess blockiert, bis Daten aus dem Sendeprozess eintreffen und diese Daten von der MPI-Umgebung vollständig in den Puffer des Empfangsprozesses geschrieben werden.
Aufgeschobener nicht blockierender Austausch
Für verzögertes, nicht blockierendes Punkt-zu-Punkt-Messaging verwenden wir die folgenden Funktionen:MPI_Send_init - bereitet im Hintergrund die Umgebung für das Senden von Daten vor, die in Zukunft auftreten werden, und keine Sperren;
MPI_Recv_init - Diese Funktion funktioniert ähnlich wie die vorherige, nur diesmal, um Daten zu empfangen.
MPI_Start -
Startet den Prozess des Empfangens oder
Sendens einer Nachricht und wird auch im Hintergrund von a.k.a. ohne zu blockieren;
MPI_Wait - wird verwendet, um zu prüfen und gegebenenfalls auf den Abschluss des Sendens oder Empfangens einer Nachricht zu warten, blockiert jedoch nur den Prozess, falls erforderlich (wenn die Daten "nicht gesendet" oder "nicht empfangen" sind). Ein Prozess möchte beispielsweise Daten verwenden, die ihn noch nicht erreicht haben - nicht gut. Daher fügen wir MPI_Wait vor der Stelle ein, an der diese Daten benötigt werden (wir fügen sie auch dann ein, wenn lediglich die Gefahr einer Datenbeschädigung besteht). Ein weiteres Beispiel ist, dass der Prozess die Hintergrunddatenübertragung gestartet hat und nach dem Start der Datenübertragung sofort begonnen hat, diese Daten irgendwie zu ändern - nicht gut. Deshalb fügen wir MPI_Wait vor der Stelle im Programm ein, an der diese Daten geändert werden sollen (hier fügen wir sie auch ein, selbst wenn Es besteht lediglich die Gefahr einer Datenkorruption.
Somit ist
semantisch die Reihenfolge der Anrufe mit einem verzögerten nicht blockierenden Austausch wie folgt:
- MPI_Send_init / MPI_Recv_init - Vorbereitung der Umgebung für den Empfang oder das Senden
- MPI_Start - Startet den Empfangs- / Sendevorgang
- MPI_Wait - Wir nennen das Risiko einer Beschädigung (einschließlich "Unterschreiben" und "Unterberichterstattung") von gesendeten oder empfangenen Daten
Ich
habe in meinen Testprogrammen auch
MPI_Startall ,
MPI_Waitall verwendet. Ihre Bedeutung ist im Grunde dieselbe wie bei MPI_Start bzw. MPI_Wait, nur dass sie mit mehreren Paketen und / oder Übertragungen arbeiten. Dies ist jedoch nicht die gesamte Liste der Start- und Wartefunktionen. Es gibt mehrere weitere Funktionen zur Überprüfung der Vollständigkeit von Vorgängen.
Prozessübergreifende Architektur
Aus Gründen der Übersichtlichkeit erstellen wir ein Diagramm zur Durchführung von Berechnungen nach vier Prozessen. In diesem Fall sollte versucht werden, alle Vektorarithmetikoperationen relativ gleichmäßig über die Prozesse zu verteilen. Folgendes habe ich bekommen:
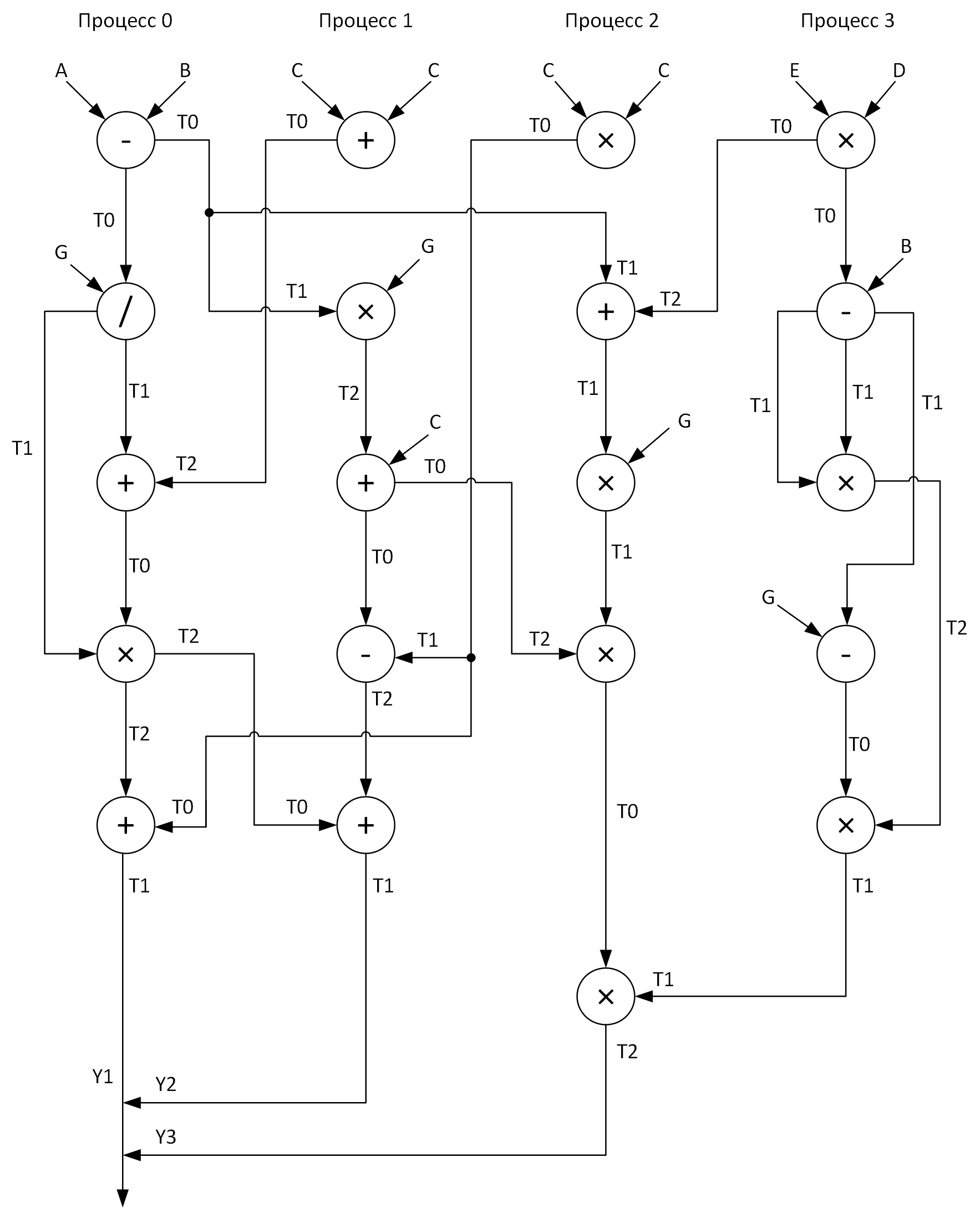
Sehen Sie diese Arrays T0-T2? Dies sind Puffer zum Speichern von Zwischenergebnissen von Operationen. In einem Diagramm befindet sich beim Senden von Nachrichten von einem Prozess zu einem anderen am Anfang des Pfeils der Name des Arrays, dessen Daten übertragen werden, und am Ende des Pfeils das Array, das diese Daten empfängt.
Wann haben wir endlich die Fragen beantwortet:
- Was für ein Problem lösen wir?
- Mit welchen Tools werden wir es lösen?
- Wie werden wir es lösen?
Es bleibt nur zu lösen ...
Unsere "Lösung":
Als nächstes werde ich die Codes der beiden oben diskutierten Programme vorstellen, aber zunächst werde ich einige weitere Erklärungen geben, was und wie.
Ich habe alle vektorarithmetischen Operationen in separaten Prozeduren (add, sub, mul, div) ausgeführt, um die Lesbarkeit des Codes zu verbessern. Alle Eingabearrays werden gemäß den Formeln initialisiert, die ich
fast zufällig angegeben habe. Da der Nullprozess die Arbeitsergebnisse aller anderen Prozesse sammelt, arbeitet er am längsten. Daher ist es logisch, die Arbeitszeit gleich der Laufzeit des Programms zu betrachten (wie wir uns erinnern, sind wir interessiert an: Arithmetik + Messaging) im ersten und zweiten Fall. Wir werden die Zeitintervalle mit der Funktion
MPI_Wtime messen und gleichzeitig habe ich beschlossen, die Auflösung der Uhren, die ich dort habe, mit
MPI_Wtick anzuzeigen (irgendwo in meiner Seele hoffe ich, dass sie in mein unveränderliches TSC passen. In diesem Fall bin ich sogar bereit, ihnen den Fehler zu verzeihen verbunden mit der Zeit, zu der die Funktion MPI_Wtime genannt wurde). Also werden wir alles zusammenstellen, was ich oben geschrieben habe, und gemäß der Grafik werden wir endlich diese Programme entwickeln (und natürlich auch debuggen).
Wen interessiert es, den Code zu sehen:
Programm mit blockierenden Datenübertragungen#include "pch.h" #include <iostream> #include <iomanip> #include <fstream> #include <mpi.h> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main(int argc, char **argv) { if (argc < 2) { return 1; } int n = atoi(argv[1]); int rank; double start_time, end_time; MPI_Status status; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; double *D = new double[n]; double *E = new double[n]; double *G = new double[n]; double *T0 = new double[n]; double *T1 = new double[n]; double *T2 = new double[n]; for (int i = 0; i < n; i++) { A[i] = double (2 * i + 1); B[i] = double(2 * i); C[i] = double(0.003 * (i + 1)); D[i] = A[i] * 0.001; E[i] = B[i]; G[i] = C[i]; } cout.setf(ios::fixed); cout << fixed << setprecision(9); MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0) { start_time = MPI_Wtime(); sub(A, B, T0, n); MPI_Send(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); div(T0, G, T1, n); MPI_Recv(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); add(T1, T2, T0, n); mul(T0, T1, T2, n); MPI_Recv(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); MPI_Send(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); add(T0, T2, T1, n); MPI_Recv(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); MPI_Recv(T2, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); end_time = MPI_Wtime(); cout << "Clock resolution: " << MPI_Wtick() << " secs" << endl; cout << "Thread " << rank << " execution time: " << end_time - start_time << endl; } if (rank == 1) { add(C, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); mul(T1, G, T2, n); add(T2, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); sub(T1, T0, T2, n); MPI_Recv(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); add(T0, T2, T1, n); MPI_Send(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } if (rank == 2) { mul(C, C, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &status); MPI_Recv(T2, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &status); MPI_Send(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD); MPI_Send(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); add(T1, T2, T0, n); mul(T0, G, T1, n); MPI_Recv(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &status); mul(T1, T2, T0, n); MPI_Recv(T1, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &status); mul(T0, T1, T2, n); MPI_Send(T2, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } if (rank == 3) { mul(E, D, T0, n); MPI_Send(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); sub(T0, B, T1, n); mul(T1, T1, T2, n); sub(T1, G, T0, n); mul(T0, T2, T1, n); MPI_Send(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD); } MPI_Finalize(); delete[] A; delete[] B; delete[] C; delete[] D; delete[] E; delete[] G; delete[] T0; delete[] T1; delete[] T2; return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
Programm mit verzögerten nicht blockierenden Datenübertragungen #include "pch.h" #include <iostream> #include <iomanip> #include <fstream> #include <mpi.h> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main(int argc, char **argv) { if (argc < 2) { return 1; } int n = atoi(argv[1]); int rank; double start_time, end_time; MPI_Request request[7]; MPI_Status statuses[4]; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; double *D = new double[n]; double *E = new double[n]; double *G = new double[n]; double *T0 = new double[n]; double *T1 = new double[n]; double *T2 = new double[n]; for (int i = 0; i < n; i++) { A[i] = double(2 * i + 1); B[i] = double(2 * i); C[i] = double(0.003 * (i + 1)); D[i] = A[i] * 0.001; E[i] = B[i]; G[i] = C[i]; } cout.setf(ios::fixed); cout << fixed << setprecision(9); MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0) { start_time = MPI_Wtime(); MPI_Send_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[0]);// MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[1]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[2]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[3]);// MPI_Send_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[4]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[5]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[6]);// MPI_Start(&request[2]); sub(A, B, T0, n); MPI_Startall(2, &request[0]); div(T0, G, T1, n); MPI_Waitall(3, &request[0], statuses); add(T1, T2, T0, n); mul(T0, T1, T2, n); MPI_Startall(2, &request[3]); MPI_Wait(&request[3], &statuses[0]); add(T0, T2, T1, n); MPI_Startall(2, &request[5]); MPI_Wait(&request[4], &statuses[0]); MPI_Waitall(2, &request[5], statuses); end_time = MPI_Wtime(); cout << "Clock resolution: " << MPI_Wtick() << " secs" << endl; cout << "Thread " << rank << " execution time: " << end_time - start_time << endl; } if (rank == 1) { MPI_Recv_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[0]);// MPI_Send_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[1]);// MPI_Recv_init(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[2]);// MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[3]);// MPI_Recv_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[4]);// MPI_Send_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[5]);// MPI_Start(&request[0]); add(C, C, T0, n); MPI_Start(&request[1]); MPI_Wait(&request[0], &statuses[0]); mul(T1, G, T2, n); MPI_Start(&request[2]); MPI_Wait(&request[1], &statuses[0]); add(T2, C, T0, n); MPI_Start(&request[3]); MPI_Wait(&request[2], &statuses[0]); sub(T1, T0, T2, n); MPI_Wait(&request[3], &statuses[0]); MPI_Start(&request[4]); MPI_Wait(&request[4], &statuses[0]); add(T0, T2, T1, n); MPI_Start(&request[5]); MPI_Wait(&request[5], &statuses[0]); } if (rank == 2) { MPI_Recv_init(T1, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[0]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &request[1]);// MPI_Send_init(T0, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[2]);// MPI_Send_init(T0, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[3]);// MPI_Recv_init(T2, n, MPI_DOUBLE, 1, 0, MPI_COMM_WORLD, &request[4]);// MPI_Recv_init(T1, n, MPI_DOUBLE, 3, 0, MPI_COMM_WORLD, &request[5]);// MPI_Send_init(T2, n, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &request[6]);// MPI_Startall(2, &request[0]); mul(C, C, T0, n); MPI_Startall(2, &request[2]); MPI_Waitall(4, &request[0], statuses); add(T1, T2, T0, n); MPI_Start(&request[4]); mul(T0, G, T1, n); MPI_Wait(&request[4], &statuses[0]); mul(T1, T2, T0, n); MPI_Start(&request[5]); MPI_Wait(&request[5], &statuses[0]); mul(T0, T1, T2, n); MPI_Start(&request[6]); MPI_Wait(&request[6], &statuses[0]); } if (rank == 3) { MPI_Send_init(T0, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[0]); MPI_Send_init(T1, n, MPI_DOUBLE, 2, 0, MPI_COMM_WORLD, &request[1]); mul(E, D, T0, n); MPI_Start(&request[0]); sub(T0, B, T1, n); mul(T1, T1, T2, n); MPI_Wait(&request[0], &statuses[0]); sub(T1, G, T0, n); mul(T0, T2, T1, n); MPI_Start(&request[1]); MPI_Wait(&request[1], &statuses[0]); } MPI_Finalize(); delete[] A; delete[] B; delete[] C; delete[] D; delete[] E; delete[] G; delete[] T0; delete[] T1; delete[] T2; return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
Testen und Analysieren
Lassen Sie uns unsere Programme für Arrays unterschiedlicher Größe ausführen und sehen, was passiert. Die Testergebnisse sind in der Tabelle zusammengefasst, in deren letzter Spalte wir den Beschleunigungskoeffizienten berechnen und schreiben, den wir wie folgt definieren: K
accele = T
ex. nicht blockieren. / T-
Block.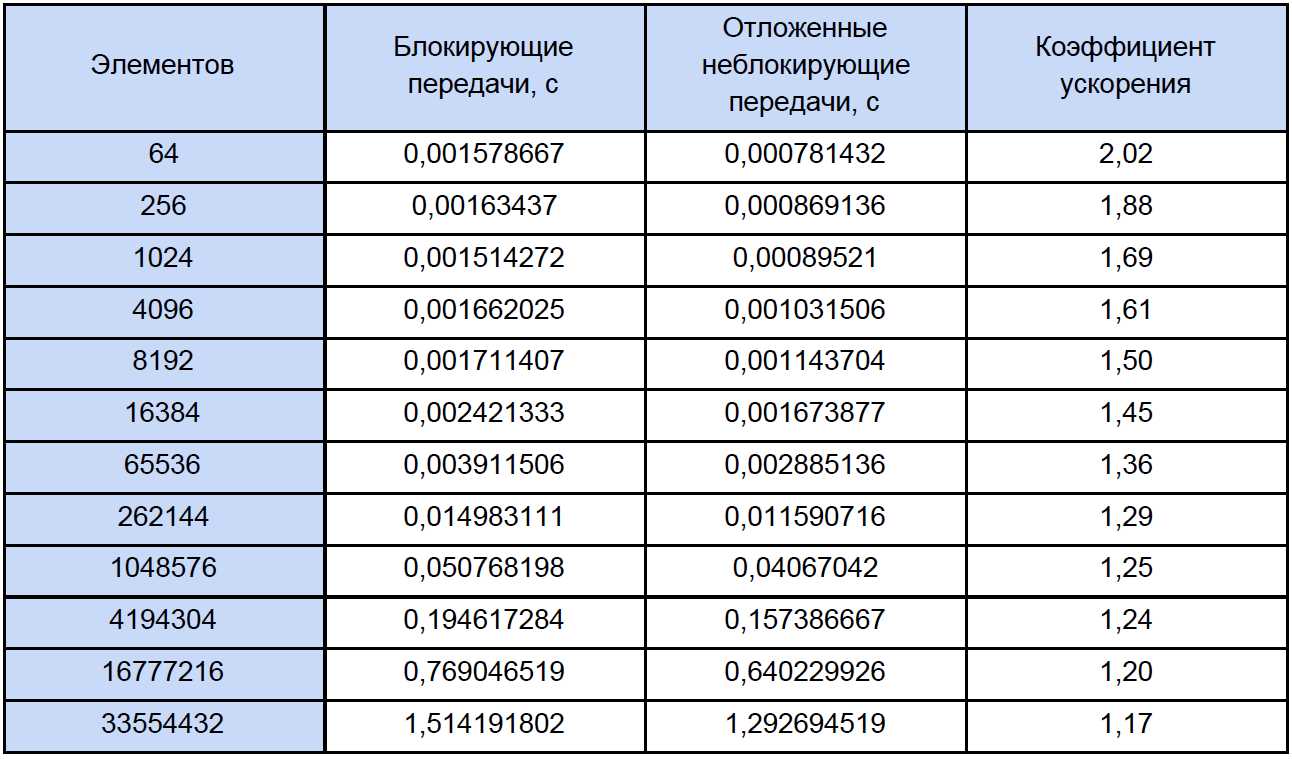
Wenn Sie sich diese Tabelle etwas genauer als gewöhnlich ansehen, werden Sie feststellen, dass mit zunehmender Anzahl verarbeiteter Elemente der Beschleunigungskoeffizient folgendermaßen abnimmt:

Versuchen wir herauszufinden, was los ist. Zu diesem Zweck schlage ich vor, ein kleines Testprogramm zu schreiben, das die Zeit jeder Vektorarithmetikoperation misst und die Ergebnisse sorgfältig auf eine normale Textdatei reduziert.
Hier in der Tat das Programm selbst:
Zeitmessung #include "pch.h" #include <iostream> #include <iomanip> #include <Windows.h> #include <fstream> using namespace std; void add(double *A, double *B, double *C, int n); void sub(double *A, double *B, double *C, int n); void mul(double *A, double *B, double *C, int n); void div(double *A, double *B, double *C, int n); int main() { struct res { double add; double sub; double mul; double div; }; int i, j, k, n, loop; LARGE_INTEGER start_time, end_time, freq; ofstream fout("test_measuring.txt"); int N[12] = { 64, 256, 1024, 4096, 8192, 16384, 65536, 262144, 1048576, 4194304, 16777216, 33554432 }; SetConsoleOutputCP(1251); cout << " loop: "; cin >> loop; fout << setiosflags(ios::fixed) << setiosflags(ios::right) << setprecision(9); fout << " : " << loop << endl; fout << setw(10) << "\n " << setw(30) << ". (c)" << setw(30) << ". (c)" << setw(30) << ". (c)" << setw(30) << ". (c)" << endl; QueryPerformanceFrequency(&freq); cout << "\n : " << freq.QuadPart << " " << endl; for (k = 0; k < sizeof(N) / sizeof(int); k++) { res output = {}; n = N[k]; double *A = new double[n]; double *B = new double[n]; double *C = new double[n]; for (i = 0; i < n; i++) { A[i] = 2.0 * i; B[i] = 2.0 * i + 1; C[i] = 0; } for (j = 0; j < loop; j++) { QueryPerformanceCounter(&start_time); add(A, B, C, n); QueryPerformanceCounter(&end_time); output.add += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); sub(A, B, C, n); QueryPerformanceCounter(&end_time); output.sub += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); mul(A, B, C, n); QueryPerformanceCounter(&end_time); output.mul += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); QueryPerformanceCounter(&start_time); div(A, B, C, n); QueryPerformanceCounter(&end_time); output.div += double(end_time.QuadPart - start_time.QuadPart) / double(freq.QuadPart); } fout << setw(10) << n << setw(30) << output.add / loop << setw(30) << output.sub / loop << setw(30) << output.mul / loop << setw(30) << output.div / loop << endl; delete[] A; delete[] B; delete[] C; } fout.close(); cout << endl; system("pause"); return 0; } void add(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] + B[i]; } } void sub(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] - B[i]; } } void mul(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] * B[i]; } } void div(double *A, double *B, double *C, int n) { for (size_t i = 0; i < n; i++) { C[i] = A[i] / B[i]; } }
Beim Start werden Sie aufgefordert, die Anzahl der Messzyklen einzugeben, die ich für 10.000 Zyklen getestet habe. Am Ausgang erhalten wir das durchschnittliche Ergebnis für jede Operation:
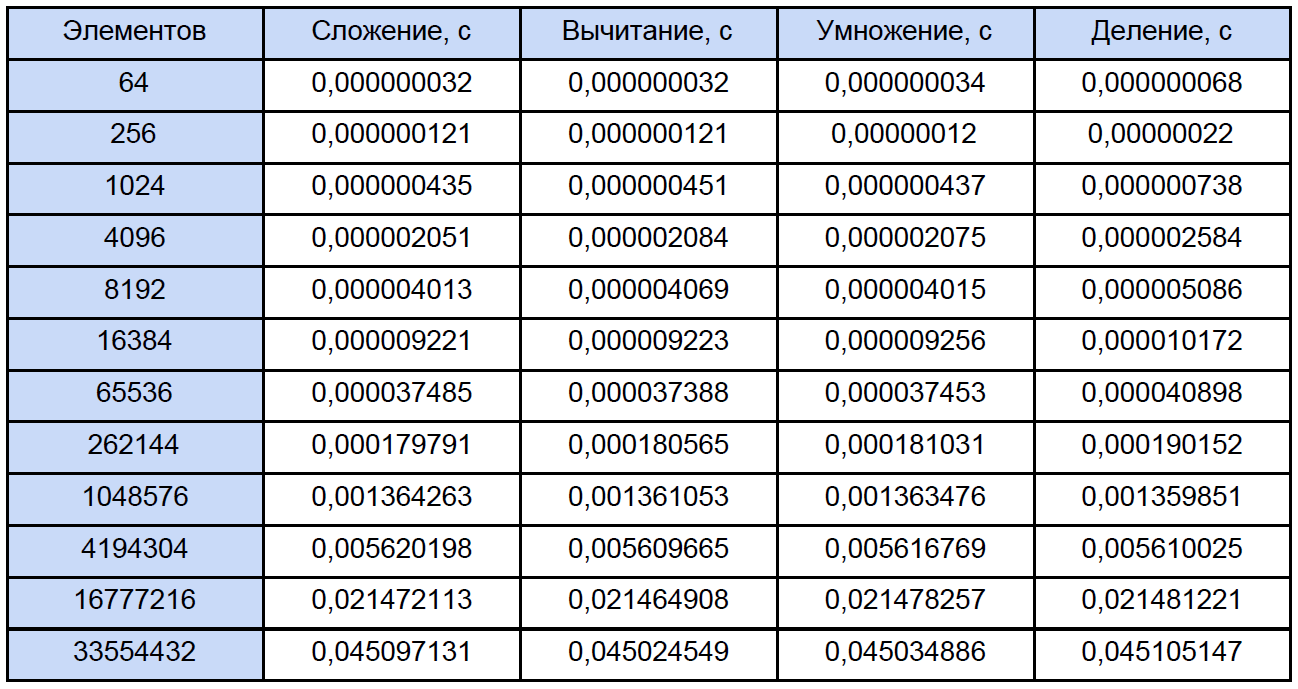
Um die Zeit zu messen, habe ich den
übergeordneten QueryPerformanceCounter verwendet . Ich empfehle dringend,
diese FAQ zu lesen, damit die meisten Fragen zur Zeitmessung mit dieser Funktion von selbst verschwinden. Nach meinen Beobachtungen klammert es sich an die TSC (aber theoretisch mag es nicht dafür sein), gibt aber laut Hilfe die aktuelle Anzahl der Ticks des Zählers zurück. Tatsache ist jedoch, dass mein Zähler das Zeitintervall von 32 ns physisch nicht messen kann (siehe die erste Zeile der Ergebnistabelle). Dieses Ergebnis ist darauf zurückzuführen, dass zwischen den beiden Aufrufen des QueryPerformanceCounter 0 Ticks oder 1 Ticks vergehen. Für die erste Zeile in der Tabelle können wir nur den Schluss ziehen, dass ungefähr ein Drittel der 10.000 Ergebnisse 1 Tick entspricht.
Die Daten in dieser Tabelle für 64, 256 und sogar für 1024 Elemente sind also ungefähr. Lassen Sie uns nun eines der Programme öffnen und berechnen, wie viele Gesamtoperationen jedes Typs insgesamt auftreten. Traditionell werden wir alles gemäß der folgenden Tabelle "verteilen":
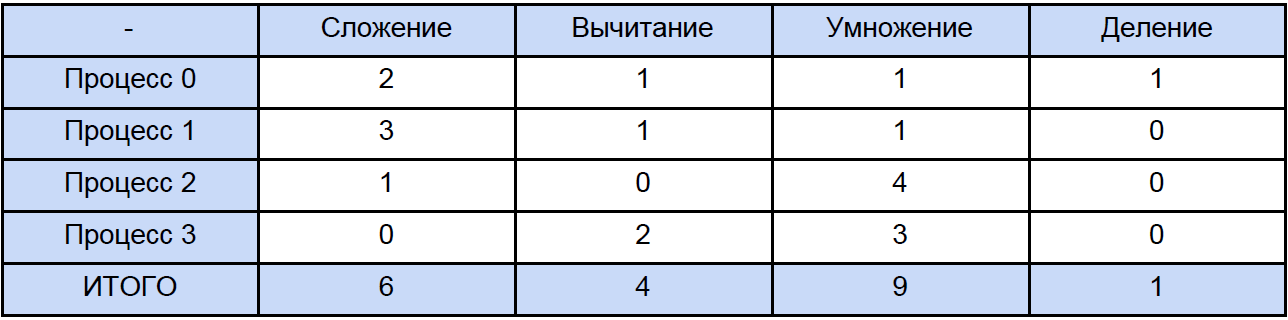
Schließlich kennen wir die Zeit jeder Vektorarithmetikoperation und wie viel Zeit sie in unserem Programm hat. Versuchen Sie herauszufinden, wie viel Zeit für diese Operationen in parallelen Programmen aufgewendet wird und wie viel Zeit für das Blockieren und den verzögerten nicht blockierenden Datenaustausch zwischen Prozessen aufgewendet wird. Aus Gründen der Klarheit werden wir dies auf reduzieren Tabelle:
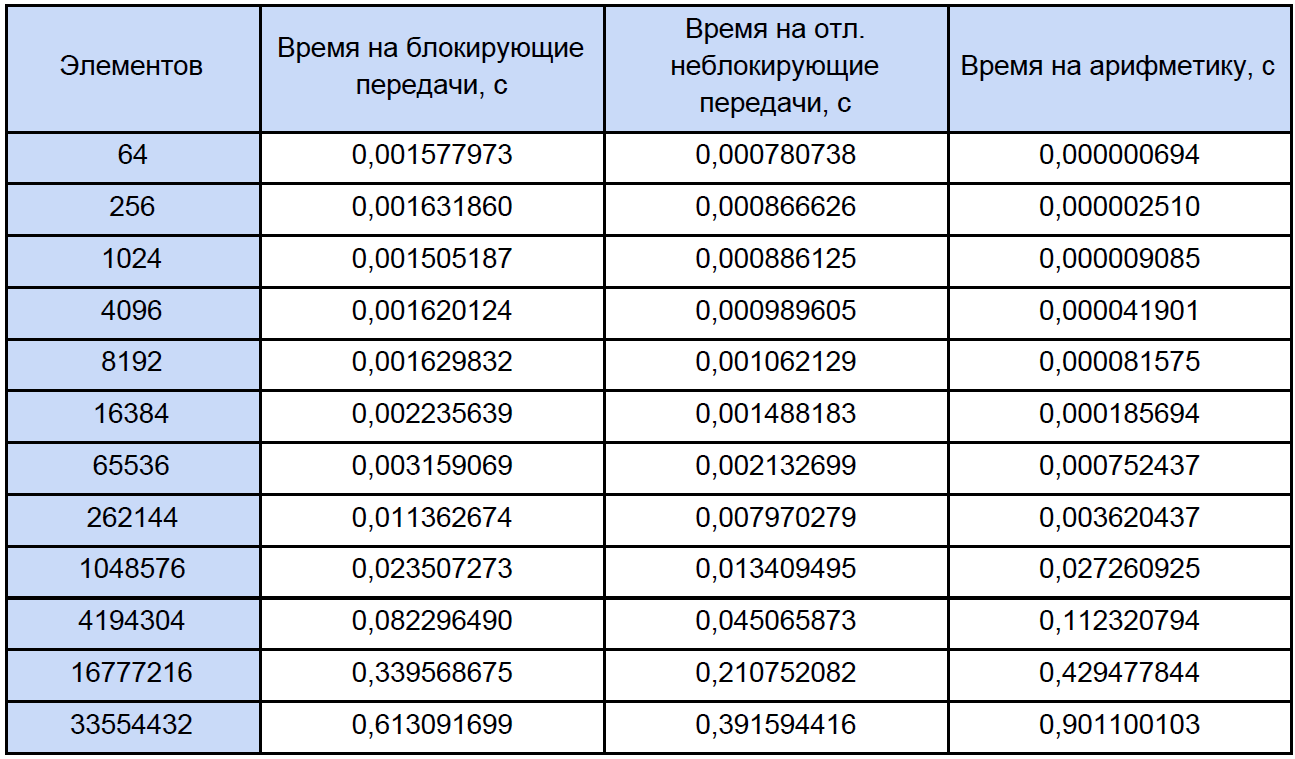
Basierend auf den Ergebnissen der Daten erstellen wir ein Diagramm mit drei Funktionen: Die erste beschreibt die Änderung der Zeit, die zum Blockieren von Übertragungen zwischen Prozessen aufgewendet wird, anhand der Anzahl der Elemente von Arrays, die zweite beschreibt die Änderung der Zeit, die für verzögerte nicht blockierende Übertragungen zwischen Prozessen aufgewendet wird, anhand der Anzahl der Elemente in Arrays, und die dritte beschreibt die Änderung der Zeit. ausgegeben für arithmetische Operationen, aus der Anzahl der Elemente von Arrays:
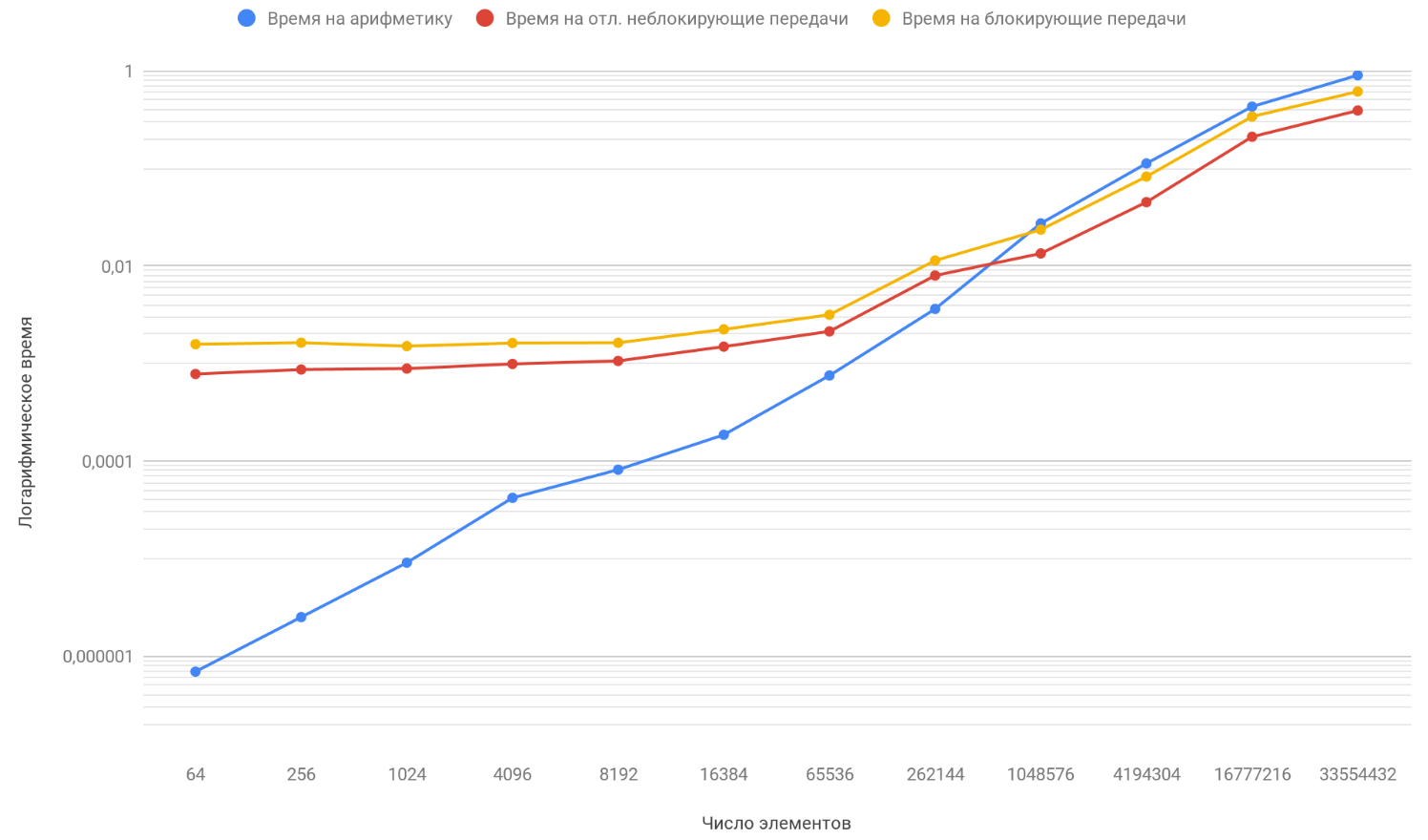
Wie Sie bereits bemerkt haben, ist die vertikale Skalierung des Diagramms logarithmisch, es ist ein notwendiges Maß, weil Die Streuung der Zeiten ist zu groß und auf einem normalen Diagramm wäre nichts sichtbar gewesen. Achten Sie auf die Funktion der Abhängigkeit der für die Arithmetik aufgewendeten Zeit von der Anzahl der Elemente, sie überholt die beiden anderen Funktionen sicher um etwa 1 Million Elemente. Die Sache ist, dass es im Unendlichen schneller wächst als seine beiden Gegner. Daher wird mit zunehmender Anzahl verarbeiteter Elemente die Laufzeit von Programmen immer mehr durch Arithmetik als durch Übertragungen bestimmt. Angenommen, Sie haben die Anzahl der Übertragungen zwischen Prozessen erhöht. Konzeptionell sehen Sie nur, dass der Moment, in dem die Rechenfunktion die beiden anderen überholt, später eintritt.
Zusammenfassung
Wenn Sie also die Länge der Arrays weiter erhöhen, werden Sie zu dem Schluss kommen, dass ein Programm mit verzögerten nicht blockierenden Übertragungen nur geringfügig schneller ist als das Programm, das den blockierenden Austausch verwendet. Wenn Sie die Länge der Arrays auf unendlich einstellen (oder nur sehr lange Arrays verwenden), wird die Betriebszeit Ihres Programms durch Berechnungen zu 100% bestimmt, und der Beschleunigungskoeffizient tendiert sicher zu 1.