Im September fand der sechste Hyperbaton statt - die Yandex-Konferenz zu allen Fragen der technischen Dokumentation. Wir werden mehrere Vorträge von Hyperbaton veröffentlichen, die unserer Meinung nach für die Leser von Habr von größtem Interesse sein könnten.
Svetlana Kayushina, Leiterin der Abteilung Dokumentation und Lokalisierung:
- Es scheint, dass es auf der Welt keine Menschen mehr gibt, die manuell übersetzen. Heute möchten wir über Tools und Ansätze sprechen, mit denen Unternehmen einen effektiven Lokalisierungsprozess organisieren können, und Übersetzer erleichtern die Lösung ihrer alltäglichen Probleme. Heute werden wir über maschinelle Übersetzung, über die Bewertung der Effektivität von Maschinenmaschinen und über automatisierte Übersetzungssysteme für Übersetzer sprechen.
Beginnen wir mit dem Bericht unserer Kollegen. Ich lade Irina Rybnikova und Anastasia Ponomareva ein - sie werden über Yandex 'Erfahrung bei der Einführung der maschinellen Übersetzung in unsere Lokalisierungsprozesse sprechen.
Irina Rybnikova:
- Vielen Dank. Wir erzählen Ihnen etwas über die Geschichte der maschinellen Übersetzung und wie wir sie in Yandex verwenden.

Bereits im 17. Jahrhundert haben Wissenschaftler über die Existenz einer Sprache nachgedacht, die andere Sprachen verbindet, und dies ist wahrscheinlich zu lang. Kommen wir näher zurück. Wir alle wollen die Menschen um uns herum verstehen - egal woher wir kommen - wir wollen sehen, was auf den Schildern steht, wir wollen Ankündigungen lesen, Informationen über Konzerte. Die Idee des babylonischen Fisches macht Wissenschaftlern zu schaffen, findet sich in der Literatur, im Kino - überall. Wir wollen die Zeit reduzieren, für die wir Zugang zu Informationen erhalten. Wir möchten Artikel über chinesische Technologien lesen, alle Websites verstehen, die wir sehen, und sie hier und jetzt erhalten.

In diesem Zusammenhang ist es unmöglich, nicht über maschinelle Übersetzung zu sprechen. Dies hilft, dieses Problem zu lösen.

Der Ausgangspunkt ist 1954, als 60 Sätze zum allgemeinen Thema der organischen Chemie in den USA auf einer IBM 701-Maschine aus dem Russischen ins Englische übersetzt wurden. All dies basierte auf 250 Glossarbegriffen und sechs grammatikalischen Regeln. Dies wurde als Georgetown-Experiment bezeichnet und war so schockierend, dass die Zeitungen voller Schlagzeilen waren, dass für weitere drei bis fünf Jahre und das Problem vollständig gelöst sein wird, alle glücklich sein werden. Aber wie Sie wissen, lief alles etwas anders.
In den 70er Jahren erschien die regelbasierte maschinelle Übersetzung. Es basierte auch auf zweisprachigen Wörterbüchern, aber auch auf solchen Regeln, die zur Beschreibung jeder Sprache beitrugen. Beliebig, aber mit Einschränkungen.

Es wurden ernsthafte Sprachexperten benötigt, die die Regeln festlegten. Dies ist eine ziemlich komplizierte Aufgabe, sie konnte den Kontext immer noch nicht berücksichtigen, keine Sprache vollständig abdecken, aber sie waren Experten, und dann war keine hohe Rechenleistung erforderlich.

Wenn wir über Qualität sprechen, ist ein klassisches Beispiel ein Zitat aus der Bibel, das dann so übersetzt wurde. Noch nicht genug. Deshalb haben die Menschen weiter an Qualität gearbeitet. In den 90er Jahren erschien ein statistisches Übersetzungsmodell, SMT, das über die probabilistische Verteilung von Wörtern und Sätzen sprach, und dieses System unterschied sich grundlegend darin, dass es überhaupt nichts über die Regeln und die Linguistik wusste. Sie erhielt eine große Anzahl identischer Texte, die in einer Sprache und einer anderen gepaart waren, und traf dann selbst Entscheidungen. Es war leicht zu warten, es wurden keine Haufen Experten benötigt, kein Warten. Sie können das Ergebnis herunterladen und erhalten.

Die Anforderungen an eingehende Daten waren durchschnittlich und lagen zwischen 1 und 10 Millionen Segmenten. Segmente - Sätze, kleine Sätze. Aber ihre Schwierigkeiten blieben bestehen und der Kontext wurde nicht berücksichtigt, alles war nicht sehr einfach. In Russland beispielsweise traten solche Fälle auf.

Ich mag auch das Beispiel der Übersetzung von GTA-Spielen, das Ergebnis war großartig. Alles stand nicht still. 2016 war ein wichtiger Meilenstein, als die neuronale maschinelle Übersetzung begann. Es war ein ziemlich epochales Ereignis, das das Leben stark verändert hat. Mein Kollege, der sich die Übersetzungen und deren Verwendung angesehen hatte, sagte: „Cool, er spricht in meinen Worten.“ Und es war wirklich toll.
Welche Funktionen? Hohe Einreisebestimmungen, Schulungsunterlagen. Es ist schwierig, innerhalb des Unternehmens zu bleiben, aber eine signifikante Qualitätssteigerung ist das, wofür es konzipiert wurde. Nur eine qualitativ hochwertige Übersetzung löst die Aufgaben und erleichtert allen Teilnehmern des Prozesses das Leben. Dieselben Übersetzer, die eine schlechte Übersetzung nicht korrigieren möchten, neue kreative Aufgaben ausführen und der Maschine Routinephrasen geben möchten.
Es gibt zwei Ansätze für die maschinelle Übersetzung. Expertenbewertung / sprachliche Analyse von Texten, dh Überprüfung durch echte Linguisten, Experten auf Übereinstimmung mit der Bedeutung, Alphabetisierung der Sprache. In einigen Fällen wurden noch Experten gepflanzt, sie durften den übersetzten Text subtrahieren und bewerteten, wie effektiv er unter diesem Gesichtspunkt war.

Was sind die Merkmale dieser Methode? Es ist keine Beispielübersetzung erforderlich. Wir sehen uns jetzt den fertig übersetzten Text an und bewerten ihn objektiv für jeden Abschnitt. Aber es ist teuer und lang.

Es gibt einen zweiten Ansatz - automatische Referenzmetriken. Es gibt viele von ihnen, jeder hat seine Vor- und Nachteile. Ich werde nicht tiefer gehen. Weitere Informationen zu diesen Keywords finden Sie später.
Welche Funktion? Tatsächlich ist dies ein Vergleich von übersetzten Maschinentexten mit einigen beispielhaften Übersetzungen. Dies sind quantitative Metriken, die die Diskrepanz zwischen beispielhafter Übersetzung und dem, was passiert ist, zeigen. Es ist schnell, billig und kann sehr bequem durchgeführt werden. Aber es gibt Funktionen.

Tatsächlich verwenden sie meistens hybride Methoden. In diesem Fall wird zunächst automatisch etwas ausgewertet, dann eine Fehlermatrix analysiert und anschließend eine sprachliche Expertenanalyse für einen kleineren Textkörper durchgeführt.

In letzter Zeit ist die Praxis immer noch weit verbreitet, wenn wir dort keine Linguisten anrufen, sondern nur Benutzer. Es wird eine Schnittstelle erstellt - zeigen Sie, welche Übersetzung Ihnen am besten gefällt. Wenn Sie zu Online-Übersetzern gehen, geben Sie Text ein und können häufig darüber abstimmen, was Ihnen am besten gefällt, ob dieser Ansatz geeignet ist oder nicht. Tatsächlich trainieren wir jetzt alle diese Motoren, und sie verwenden alles für das Training, um zu trainieren und an ihrer Qualität zu arbeiten.
Ich möchte sagen, wie wir maschinelle Übersetzung in unserer Arbeit verwenden. Ich gebe das Wort an Anastasia weiter.
Anastasia Ponomareva:
- Wir bei Yandex in der Lokalisierungsabteilung haben sehr schnell erkannt, dass die maschinelle Übersetzungstechnologie ein großes Potenzial hat, und beschlossen, sie für unsere täglichen Aufgaben einzusetzen. Wo haben wir angefangen? Wir beschlossen, ein kleines Experiment durchzuführen. Wir haben uns entschlossen, dieselben Texte über einen regulären Übersetzer für neuronale Netze zu übersetzen und auch einen ausgebildeten maschinellen Übersetzer zusammenzustellen. Zu diesem Zweck haben wir für die Jahre, in denen wir in Yandex mit der Lokalisierung von Texten in diesen Sprachen befasst waren, ein Korpus von Texten in einem Paar Russisch-Englisch vorbereitet. Dann kamen wir mit diesem Korpus von Texten zu unseren Kollegen von Yandex.Translate und baten darum, den Motor zu trainieren.

Als der Motor trainiert wurde, übersetzten wir die nächsten Texte und wie Irina sagte, bewerteten wir mit Hilfe von Experten die Ergebnisse. Wir haben die Übersetzer gebeten, sich mit Alphabetisierung, Stil, Rechtschreibung und Bedeutungsübertragung zu befassen. Aber der Wendepunkt war, als einer der Übersetzer sagte: "Ich erkenne meinen Stil, ich erkenne meine Übersetzungen."
Um diese Empfindungen zu verstärken, haben wir beschlossen, die statistischen Indikatoren zu berechnen. Zuerst haben wir den BLEU-Koeffizienten für Übertragungen berechnet, die über eine reguläre neuronale Netzwerk-Engine durchgeführt wurden, und wir haben diese Zahl erhalten (0,34). Es scheint, dass es mit etwas verglichen werden muss. Wir gingen erneut zu Kollegen von Yandex.Translator und fragten, welcher BLEU-Koeffizient als Schwellenwert für Übertragungen angesehen wird, die von einer realen Person durchgeführt werden. Dies ist von 0,6.
Dann haben wir uns entschlossen, die Ergebnisse der geschulten Übersetzungen zu überprüfen. Habe 0,5. Die Ergebnisse sind wirklich ermutigend.

Ich gebe ein Beispiel. Dies ist eine echte russische Phrase aus der Dokumentation von Direct. Dann wurde es durch eine reguläre neuronale Netzwerk-Engine und dann durch eine trainierte neuronale Netzwerk-Engine in unseren Texten übertragen. Bereits in der ersten Zeile stellen wir fest, dass die traditionelle Art der Werbung für Direct nicht anerkannt wird. Und bereits in der trainierten neuronalen Netzwerk-Engine erscheint unsere Übersetzung, und selbst die Abkürzung ist fast korrekt.
Wir waren von den Ergebnissen sehr ermutigt und entschieden, dass es sich wahrscheinlich lohnt, die Engine in anderen Paaren, in anderen Texten zu verwenden, nicht nur in diesem grundlegenden Satz technischer Dokumentation. Eine Reihe von Experimenten wurde über mehrere Monate durchgeführt. Angesichts vieler Funktionen und Probleme sind dies die häufigsten Probleme, die wir lösen mussten.

Ich werde Ihnen mehr darüber erzählen.

Wenn Sie wie wir eine benutzerdefinierte Engine erstellen möchten, benötigen Sie eine relativ große Menge hochwertiger paralleler Daten. Der große Motor kann auf die Menge von 10 Tausend Angeboten trainiert werden, in unserem Fall haben wir 135 Tausend parallele Angebote vorbereitet.

Nicht bei allen Textarten zeigt Ihre Engine gleich gute Ergebnisse. In der technischen Dokumentation, wo es lange Sätze, Strukturen, Benutzerdokumentationen gibt, und sogar in der Benutzeroberfläche, wo es kurze, aber klare Schaltflächen gibt, wird es Ihnen höchstwahrscheinlich gut gehen. Aber vielleicht stoßen Sie wie bei uns auf Marketingprobleme.
Wir haben ein Experiment durchgeführt, Musikwiedergabelisten übersetzt und ein solches Beispiel erhalten.

Das ist es, was ein Maschinenübersetzer über Starfabrikarbeiter denkt. Was sind die Trommler der Arbeit.

Bei der Übersetzung über eine Maschinenmaschine wird der Kontext nicht berücksichtigt. Dies ist kein so lächerliches Beispiel mehr, sondern aus der technischen Dokumentation von Yandex.Direct ganz real. Es scheint, dass diese verständlich sind, wenn Sie die technische Dokumentation lesen, das sind die technischen. Aber nein, der Motor hat nicht getroffen.

Sie müssen auch berücksichtigen, dass die Qualität und Bedeutung der Übersetzung stark von der Originalsprache abhängt. Wir übersetzen den Satz aus dem Russischen ins Französische, wir erhalten ein Ergebnis. Wir bekommen einen ähnlichen Satz mit der gleichen Bedeutung, aber aus dem Englischen, und wir bekommen ein anderes Ergebnis.

Wenn Sie wie in unserem Text über eine große Anzahl von Tags, Markups und einige technische Funktionen verfügen, müssen Sie diese höchstwahrscheinlich nachverfolgen, bearbeiten und einige Skripte schreiben.
Hier sind Beispiele für echte Phrasen aus dem Browser. In Klammern stehen technische Informationen, die nicht übersetzt werden sollten, insbesondere mehrere Formulare. Auf Englisch sind sie auf Englisch und auf Deutsch müssen sie auch auf Englisch bleiben, aber sie werden übersetzt. Sie müssen diese Punkte im Auge behalten.
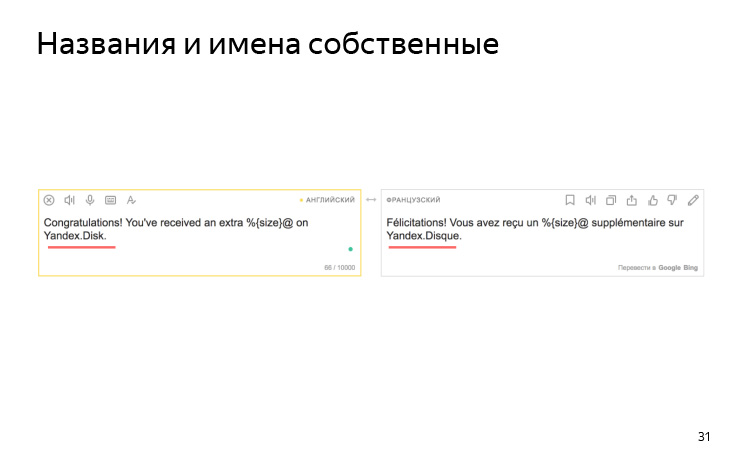
Die Engine weiß nichts über Ihre Namenskonventionen. Zum Beispiel haben wir eine Vereinbarung, dass wir Yandex.Disk immer in Latein in allen Sprachen nennen. Aber auf Französisch verwandelt er sich in eine Scheibe auf Französisch.

Abkürzungen werden manchmal richtig erkannt, manchmal nicht. In diesem Beispiel wird BY, das die Zugehörigkeit zu den belarussischen technischen Anforderungen für Werbung bezeichnet, zu einer Entschuldigung auf Englisch.

Eines meiner Lieblingsbeispiele sind neue und geliehene Wörter. Hier ist ein cooles Beispiel, das Wort Haftungsausschluss "ursprünglich russisch". Die Terminologie muss für jeden Teil des Textes überprüft werden.
Und noch ein nicht so bedeutendes Problem - veraltetes Schreiben.

Früher war das Internet eine Neuheit, es wurde in allen Texten groß geschrieben, und als wir unsere Engine trainierten, wurde das Internet überall groß geschrieben. Jetzt ist eine neue Ära, das Internet wird bereits mit einem kleinen Brief geschrieben. Wenn Sie möchten, dass Ihr Motor das Internet weiterhin mit einem kleinen Buchstaben schreibt, müssen Sie ihn neu trainieren.

Wir haben nicht verzweifelt, diese Probleme gelöst. Zunächst änderten sie das Textkorps und versuchten, zu anderen Themen zu übersetzen. Wir haben unsere Kommentare an Kollegen von Yandex.Translator weitergeleitet, das neuronale Netzwerk neu trainiert und die Ergebnisse überprüft, ausgewertet und um Abschluss gebeten. Zum Beispiel Tag-Erkennung, HTML-Markup-Verarbeitung.
Ich werde echte Anwendungsfälle zeigen. Wir haben eine gute maschinelle Übersetzung für die technische Dokumentation. Dies ist ein realer Fall.

Hier ist der Satz auf Englisch und Russisch. Der Übersetzer, der sich mit dieser Dokumentation befasste, wurde durch die geeignete Wahl der Terminologie sehr ermutigt. Ein weiteres Beispiel.

Der Übersetzer schätzte die Wahl von anstelle des Bindestrichs, dass sich die Struktur der Phrase in Englisch geändert hat, eine angemessene Wahl des korrekten Begriffs und des Wortes Sie, das nicht im Original enthalten ist, aber diese Übersetzung genau englisch macht, natürlich.

Ein weiterer Fall ist die Übersetzung von Schnittstellen im laufenden Betrieb. Einer der Dienste hat beschlossen, sich nicht um die Lokalisierung zu kümmern und Texte direkt beim Start zu übersetzen. Nachdem der Motor etwa einmal im Monat gewechselt worden war, änderte sich das Wort "Lieferung" im Kreis. Wir haben vorgeschlagen, dass das Team keine gewöhnliche neuronale Netzwerk-Engine anschließt, sondern unsere, die in technischer Dokumentation geschult ist, damit immer derselbe Begriff verwendet wird, der mit dem Team vereinbart wurde, das bereits in der Dokumentation enthalten ist.

Wie funktioniert das alles für einen monetären Moment? Ursprünglich war es so, dass ein Paar Russisch-Ukrainisch nur eine minimale Bearbeitung der ukrainischen Übersetzung erfordert. Aus diesem Grund haben wir uns vor einigen Monaten entschlossen, auf ein Nachbearbeitungssystem umzusteigen. So wachsen unsere Einsparungen. Der September ist noch nicht vorbei, aber wir haben festgestellt, dass wir unsere Nachbearbeitungskosten auf Ukrainisch um etwa ein Drittel gesenkt haben, und wir werden fast alles außer Marketingtexten bearbeiten. Das Wort Irina zusammenzufassen.
Irina:
- Für alle wird klar, dass es notwendig ist, es zu benutzen, es ist bereits unsere Realität und es ist unmöglich, es von unseren Prozessen und Interessen auszuschließen. Aber Sie müssen über ein paar Dinge nachdenken.

Entscheiden Sie sich für die Dokumenttypen und den Kontext, mit dem Sie arbeiten. Ist diese Technologie für Sie geeignet?
Zweiter Moment. Wir haben über Yandex.Translator gesprochen, weil wir in einer guten Beziehung stehen, direkten Zugang zu Entwicklern haben und so weiter. Tatsächlich müssen Sie jedoch entscheiden, welche Engine für Sie, Ihre Sprache und Ihr Fach am besten geeignet ist. Der
nächste Bericht wird diesem Thema gewidmet sein. Seien Sie darauf vorbereitet, dass es immer noch Schwierigkeiten gibt, die Entwickler der Motoren arbeiten zusammen, um die Schwierigkeiten zu lösen, aber bis jetzt treffen sie sich immer noch.

Ich würde gerne verstehen, was uns in Zukunft erwartet. Tatsächlich ist dies aber nicht weiter, sondern unsere aktuelle Zeit, was hier und jetzt passiert. Wir alle brauchen eher Anpassungen an unsere Terminologie, an unsere Texte, und dies wird jetzt öffentlich. Jetzt arbeiten alle daran, dass Sie nicht in das Unternehmen eintreten, nicht mit den Entwicklern einer bestimmten Engine übereinstimmen und wie Sie dies für Sie optimieren können. Sie können es in öffentlichen offenen Engines auf API empfangen.
Die Anpassung erfolgt nicht nur in den Texten, sondern auch in der Terminologie, um die Terminologie für Ihre eigenen Anforderungen zu konfigurieren. Dies ist ein wichtiger Punkt. Das zweite Thema ist die interaktive Übersetzung. Wenn ein Übersetzer einen Text übersetzt, kann er mithilfe der Technologie die folgenden Wörter unter Berücksichtigung der Ausgangssprache und des Ausgangstextes vorhersagen. Dieser Auger kann die Arbeit erheblich erleichtern.
Das ist jetzt sehr teuer. Jeder denkt darüber nach, wie man einige Engines mit weniger Text viel weniger effektiv unterrichtet. Das passiert überall und läuft überall. Ich finde das Thema sehr interessant, und dann wird es noch interessanter.
Wir haben mehrere Artikel zusammengestellt, die Sie interessieren könnten. Vielen Dank!
-
Zwei Modelle sind besser als eines. Erfahrung von Yandex.Translator-
Wie Yandex künstliche Intelligenz zur Übersetzung von Webseiten einsetzte-
Maschinelle Übersetzung. Vom Kalten Krieg bis zum Dipllernen