Hinweis perev. : Der Originalartikel wurde von einem technischen Redakteur von Google verfasst, der an der Dokumentation für Kubernetes (Andrew Chen) und dem Director of Software Engineering von SAP (Dominik Tornow) arbeitet. Ziel ist es, die Grundlagen der Organisation und Implementierung von Hochverfügbarkeit in Kubernetes klar und deutlich zu erläutern. Es scheint uns, dass die Autoren erfolgreich waren, daher freuen wir uns, die Übersetzung zu teilen.
Kubernetes ist eine Container-Orchestrierungs-Engine, mit der containerisierte Anwendungen auf mehreren Knoten ausgeführt werden können, die üblicherweise als Cluster bezeichnet werden. In diesen Veröffentlichungen verwenden wir einen Systemmodellierungsansatz, um das Verständnis von Kubernetes und den zugrunde liegenden Konzepten zu verbessern. Die Leser werden ermutigt, bereits ein grundlegendes Verständnis von Kubernetes zu haben.
Kubernetes ist eine skalierbare und zuverlässige Container-Orchestrierungs-Engine. Die Skalierbarkeit wird hier durch die Reaktionsfähigkeit bei Vorhandensein einer Last bestimmt, und die Zuverlässigkeit wird durch die Reaktionsfähigkeit bei Vorhandensein von Fehlern bestimmt.
Beachten Sie, dass die Skalierbarkeit und Zuverlässigkeit von Kubernetes nicht die Skalierbarkeit und Zuverlässigkeit der darin ausgeführten Anwendung bedeutet. Kubernetes ist eine skalierbare und zuverlässige Plattform, aber jede K8-Anwendung muss noch bestimmte Phasen durchlaufen, um eine zu werden und Engpässe und einzelne Fehlerquellen zu vermeiden.
Wenn die Anwendung beispielsweise als ReplicaSet oder Deployment bereitgestellt wird, plant und startet Kubernetes Pods, die von Knotenabstürzen betroffen sind, (neu) und (neu). Wenn die Anwendung jedoch als Pod bereitgestellt wird, ergreift Kubernetes im Falle eines Knotenausfalls keine Maßnahmen. Obwohl Kubernetes selbst betriebsbereit bleibt, hängt die Reaktionsfähigkeit Ihrer Anwendung von der gewählten Architektur und den Bereitstellungsentscheidungen ab.
Diese Veröffentlichung konzentriert sich auf die Zuverlässigkeit von Kubernetes. Sie spricht darüber, wie Kubernetes bei Fehlern die Reaktionsfähigkeit beibehält.
Kubernetes Architektur
 Schema 1. Meister und Arbeiter
Schema 1. Meister und ArbeiterAuf konzeptioneller Ebene werden Kubernetes-Komponenten in zwei unterschiedliche Klassen eingeteilt:
Master- Komponenten und
Worker- Komponenten.
Die Meister sind für die Verwaltung aller Dinge verantwortlich, mit Ausnahme der Ausführung der Herde. Die Komponenten des Assistenten umfassen:
Die Arbeiter sind für die Verwaltung der Ausführung der Herde verantwortlich. Sie haben eine Komponente:
Arbeiter sind trivial zuverlässig: Ein vorübergehender oder dauerhafter Ausfall eines Arbeiters in einem Cluster wirkt sich nicht auf den Master oder andere Clusterarbeiter aus. Wenn die Anwendung ordnungsgemäß bereitgestellt wird, plant und startet Kubernetes alle, die vom Ausfall des Workers betroffen sind, (neu).
Konfiguration eines einzelnen Assistenten
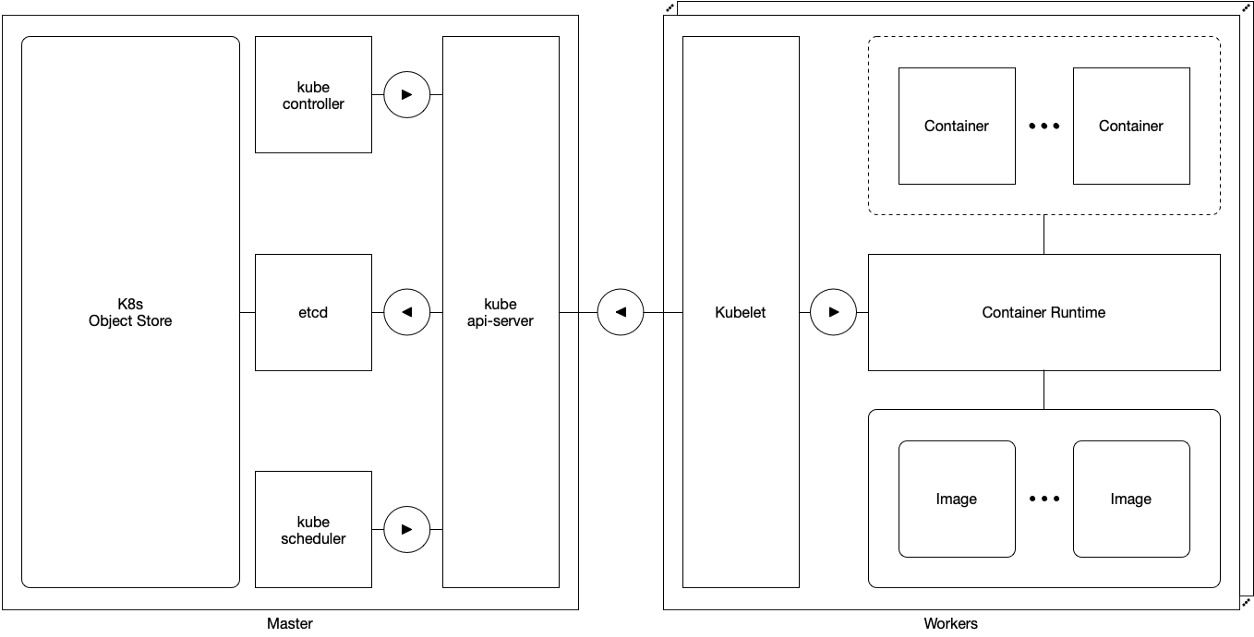 Schema 2. Konfiguration mit einem einzelnen Master
Schema 2. Konfiguration mit einem einzelnen MasterIn einer Single-Master-Konfiguration besteht der Kubernetes-Cluster aus einem Master und mehreren Workern. Letztere sind direkt mit dem kube-apiserver-Assistenten verbunden und interagieren mit ihm.
In dieser Konfiguration hängt die Reaktionsfähigkeit von Kubernetes ab von:
- der einzige Meister
- Arbeiter mit einem einzigen Meister verbinden.
Da der einzige Master ein einzelner Fehlerpunkt ist, gehört diese Konfiguration nicht zur Kategorie der Hochverfügbarkeit.
Konfiguration mit mehreren Assistenten
 Schema 3. Konfiguration mit vielen Mastern
Schema 3. Konfiguration mit vielen MasternIn einer Multi-Master-Konfiguration besteht der Kubernetes-Cluster aus vielen Mastern und vielen Workern. Die Mitarbeiter stellen eine Verbindung zum Kube-Apiserver eines Masters her und interagieren mit ihm über einen leicht zugänglichen Load Balancer.
In dieser Konfiguration ist Kubernetes unabhängig von:
- der einzige Meister
- Arbeiter mit einem einzigen Meister verbinden.
Da es in dieser Konfiguration keinen einzelnen Fehlerpunkt gibt, wird er als sehr zugänglich angesehen.
Führer und Anhänger in Kubernetes
In einer Konfiguration mit mehreren Assistenten sind zahlreiche Kube-Controller-Manager und Kube-Scheduler beteiligt. Wenn zwei Komponenten dieselben Objekte ändern, können Konflikte auftreten.
Um mögliche Konflikte zu vermeiden, implementiert Kubernetes für kube-controller-manager und kube-scheduler das Muster "
Master-Slave "
(Leader / Follower) . Jede Gruppe wählt einen Anführer
(oder Anführer) und die verbleibenden Mitglieder der Gruppe übernehmen die Rolle von Anhängern. Zu jedem Zeitpunkt ist nur ein Anführer aktiv und die Anhänger sind passiv.
 Abbildung 4. Assistent für redundante Bereitstellungskomponenten im Detail
Abbildung 4. Assistent für redundante Bereitstellungskomponenten im DetailDiese Abbildung zeigt ein detailliertes Beispiel, in dem Kube-Controller-1 und Kube-Scheduler-2 unter Kube-Controller-Managern und Kube-Schedulern führend sind. Da jede Gruppe ihren eigenen Anführer wählt, müssen sie überhaupt nicht auf demselben Meister sein.
Lead-Auswahl
Ein neuer Anführer wird von den Gruppenmitgliedern zum Zeitpunkt des Starts oder im Falle eines Sturzes des Anführers ausgewählt. Lead - ein Mitglied mit dem sogenannten
Leader Lease (derzeit „geleaster“ Leader Status).
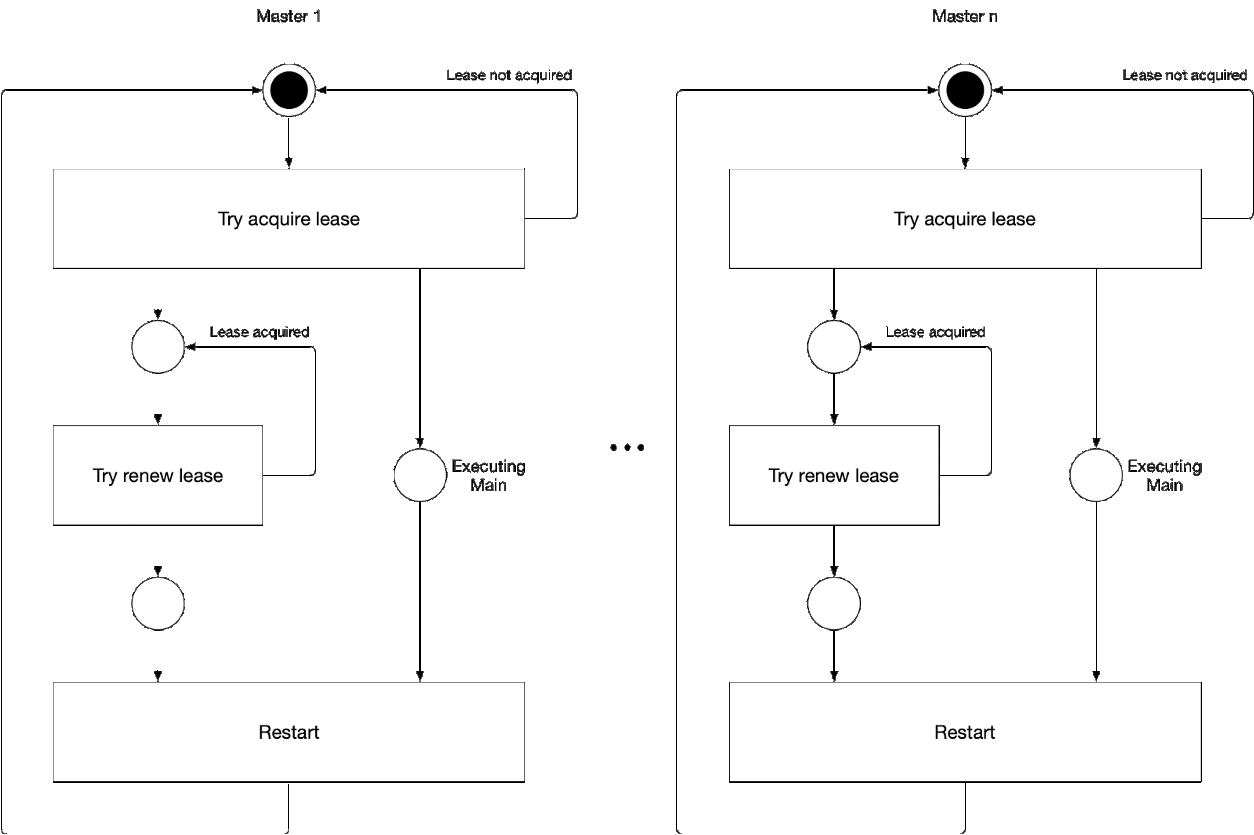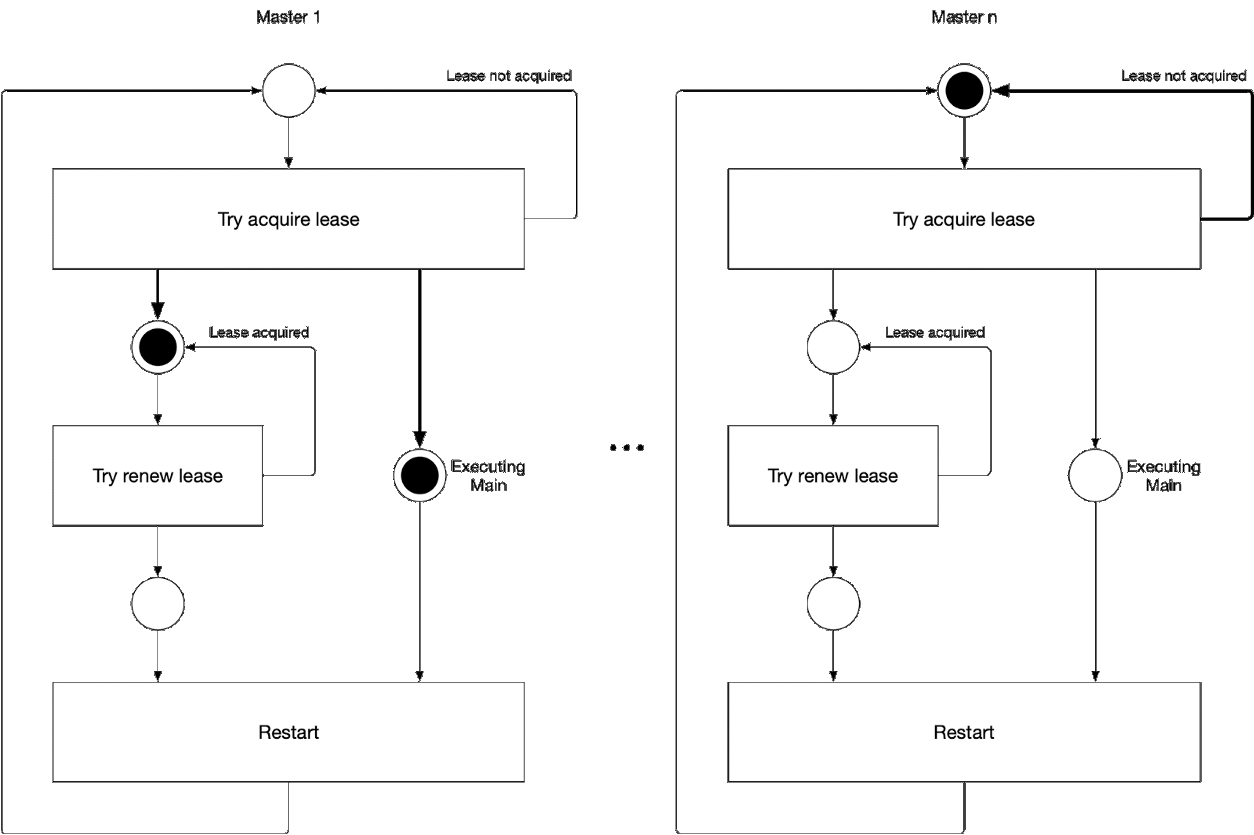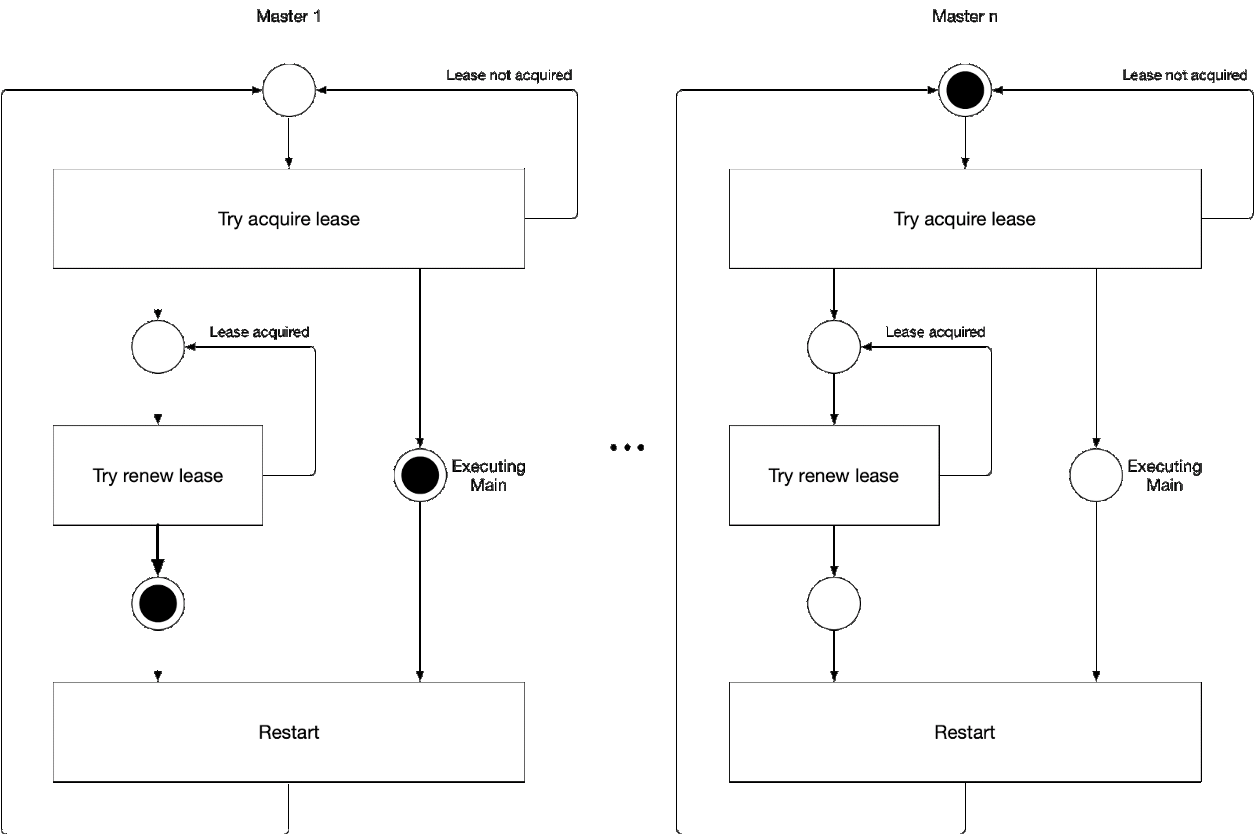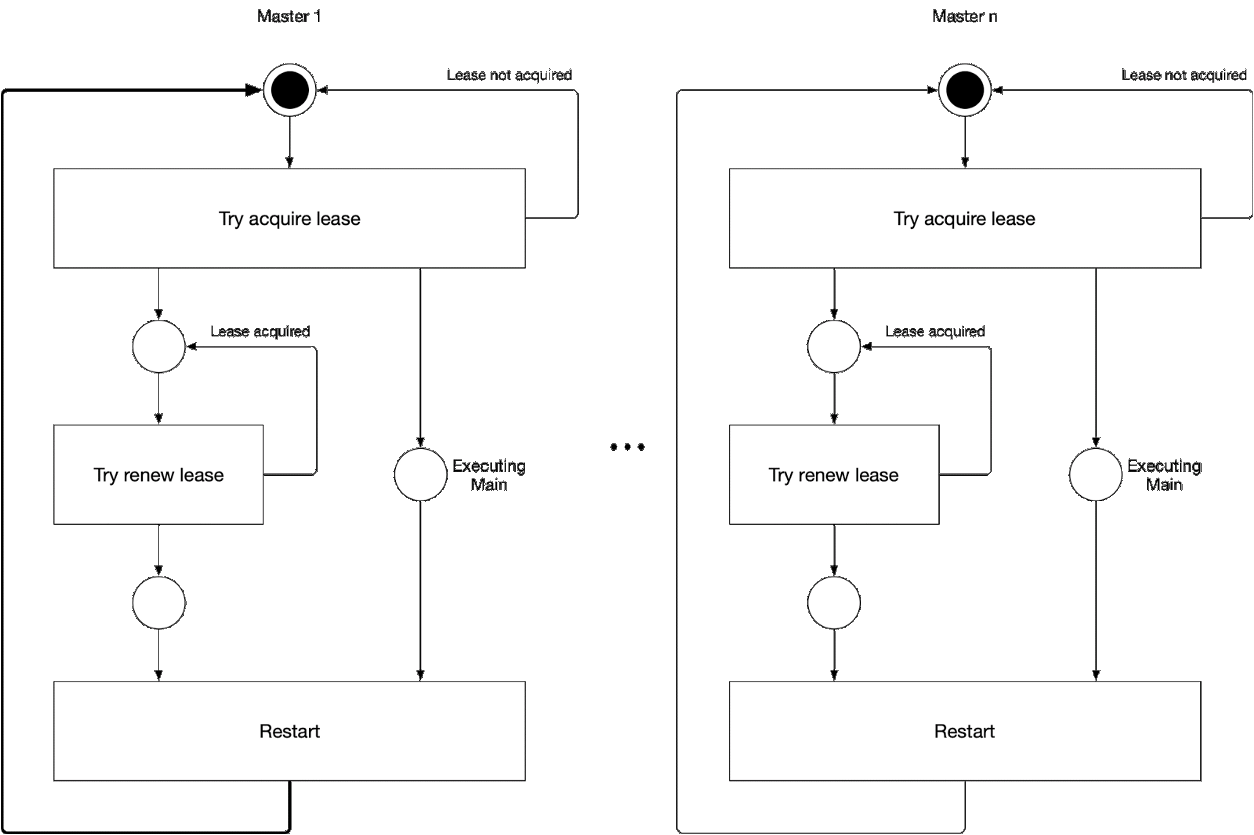 Abbildung 5. Auswahl der Hauptkomponente des Assistenten
Abbildung 5. Auswahl der Hauptkomponente des AssistentenDiese Abbildung zeigt den Master-Auswahlprozess für den Kube-Controller-Manager und den Kube-Scheduler. Die Logik dieses Prozesses ist wie folgt:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Führende Verfolgung
Die aktuellen Leader-Status für kube-controller-manager und kube-scheduler werden dauerhaft im Kubernetes-Objektspeicher als
Endpunktobjekte im
kube-system Namespace gespeichert. Da zwei Kubernetes-Objekte nicht gleichzeitig denselben Namen, Typ
(Typ) und Namespace haben können, kann es nur einen
Endpunkt für den Kube-Scheduler und den Kube-Controller-Manager geben.
Demo mit dem
kubectl console:
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
Informationen zum Kube-Scheduler und zum Kube-Controller-Manager von
Endpoint speichern den Leader in der Annotation
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
Obwohl Kubernetes garantiert, dass es jeweils einen Master gibt, garantiert Kubernetes nicht, dass zwei oder mehr Komponenten des Assistenten nicht
fälschlicherweise glauben, dass sie derzeit führend sind - dieser Zustand wird als
geteiltes Gehirn bezeichnet .
Eine lehrreiche Diskussion des Split-Brain-Themas und möglicher Lösungen finden Sie in Martin Kleppmanns Artikel
How to do Distributed Locking .
Kubernetes verwendet keine Gegenmaßnahmen gegen das geteilte Gehirn. Stattdessen verlässt er sich auf seine Fähigkeit, im Laufe der Zeit nach dem gewünschten Zustand zu streben, was die Folgen von Konfliktentscheidungen mildert.
Fazit
In einer Multi-Master-Konfiguration ist Kubernetes eine skalierbare und zuverlässige Container-Orchestrierungs-Engine. In dieser Konfiguration bietet Kubernetes Zuverlässigkeit mit einer Vielzahl von Assistenten und vielen Mitarbeitern. Viele Master arbeiten nach dem Master / Slave-Muster, und die Arbeiter arbeiten parallel. Kubernetes verfügt über einen eigenen Hostauswahlprozess, bei dem Hostinformationen als
Endpunktobjekte gespeichert
werden .
Informationen zum Vorbereiten eines Kubernetes-Hochverfügbarkeitsclusters für den Betrieb finden Sie in der
offiziellen Dokumentation .
Über die Veröffentlichung
Dieser Beitrag ist Teil einer gemeinsamen Initiative von CNCF, Google und SAP, um das Verständnis von Kubernetes und den zugrunde liegenden Konzepten zu verbessern.PS vom Übersetzer
Lesen Sie auch in unserem Blog: