Hallo Habr! Mein Name ist Nikolai Izhikov, ich arbeite für Sberbank Technologies im Open Source Solutions Development Team. Hinter 15 Jahren kommerzieller Entwicklung in Java. Ich bin ein Apache Ignite-Committer und Apache Kafka-Mitarbeiter.
Unter der Katze finden Sie eine Video- und Textversion meines Berichts über Apache Ignite Meetup, wie Sie Apache Ignite mit Apache Spark verwenden und welche Funktionen wir dafür implementiert haben.
Was Apache Spark kann
Was ist Apache Spark? Mit diesem Produkt können Sie schnell verteilte Computer- und Analyseabfragen durchführen. Grundsätzlich ist Apache Spark in Scala geschrieben.
Apache Spark verfügt über eine umfangreiche API zum Herstellen einer Verbindung zu verschiedenen Speichersystemen oder zum Empfangen von Daten. Eine der Funktionen des Produkts ist eine universelle SQL-ähnliche Abfrage-Engine für Daten, die aus verschiedenen Quellen empfangen werden. Wenn Sie über mehrere Informationsquellen verfügen, diese kombinieren und einige Ergebnisse erzielen möchten, ist Apache Spark genau das Richtige für Sie.
Eine der wichtigsten Abstraktionen, die Spark bereitstellt, ist Data Frame, DataSet. In Bezug auf eine relationale Datenbank ist dies eine Tabelle, eine Quelle, die Daten auf strukturierte Weise bereitstellt. Die Struktur, der Typ jeder Spalte, ihr Name usw. sind bekannt. Datenrahmen können aus verschiedenen Quellen erstellt werden. Beispiele hierfür sind JSON-Dateien, relationale Datenbanken, verschiedene Hadoop-Systeme und Apache Ignite.
Spark unterstützt Joins in SQL-Abfragen. Sie können Daten aus verschiedenen Quellen kombinieren und Ergebnisse erhalten sowie analytische Abfragen durchführen. Darüber hinaus gibt es eine API zum Speichern von Daten. Wenn Sie die Abfragen abgeschlossen und eine Studie durchgeführt haben, bietet Spark die Möglichkeit, die Ergebnisse auf dem Empfänger zu speichern, der diese Funktion unterstützt, und dementsprechend das Problem der Datenverarbeitung zu lösen.
Welche Funktionen haben wir für die Integration von Apache Spark in Apache Ignite implementiert?
- Lesen von Daten aus Apache Ignite SQL-Tabellen.
- Schreiben von Daten in Apache Ignite SQL-Tabellen.
- IgniteCatalog in IgniteSparkSession - die Möglichkeit, alle vorhandenen Ignite SQL-Tabellen zu verwenden, ohne sich "von Hand" zu registrieren.
- SQL-Optimierung - Die Möglichkeit, SQL-Anweisungen in Ignite auszuführen.
Apache Spark kann Daten aus Apache Ignite SQL-Tabellen lesen und in Form einer solchen Tabelle schreiben. Jeder in Spark gebildete DataFrame kann als Apache Ignite SQL-Tabelle gespeichert werden.
Mit Apache Ignite können Sie alle vorhandenen Ignite SQL-Tabellen in Spark Session verwenden, ohne sich "von Hand" zu registrieren. Verwenden Sie dazu IgniteCatalog in der Standarderweiterung SparkSession - IgniteSparkSession.
Hier müssen Sie etwas tiefer in das Spark-Gerät einsteigen. In Bezug auf eine reguläre Datenbank ist ein Verzeichnis ein Ort, an dem Metainformationen gespeichert werden: Welche Tabellen sind verfügbar, welche Spalten befinden sich in ihnen usw. Wenn eine Anfrage eintrifft, werden Metainformationen aus dem Katalog abgerufen und die SQL-Engine macht etwas mit Tabellen und Daten. Standardmäßig müssen in Spark alle gelesenen Tabellen (egal, aus einer relationalen Datenbank, Ignite, Hadoop) manuell in Sitzungen registriert werden. Als Ergebnis erhalten Sie die Möglichkeit, eine SQL-Abfrage für diese Tabellen durchzuführen. Spark erfährt davon.
Um mit den Daten zu arbeiten, die wir auf Ignite hochgeladen haben, müssen wir die Tabellen registrieren. Anstatt jede Tabelle mit unseren Händen zu registrieren, haben wir die Möglichkeit implementiert, automatisch auf alle Ignite-Tabellen zuzugreifen.
Was ist die Funktion hier? Aus irgendeinem Grund weiß ich nicht, dass das Verzeichnis in Spark eine interne API ist, d. H. Ein Außenstehender kann nicht kommen und seine eigene Katalogimplementierung erstellen. Und da Spark aus Hadoop hervorgegangen ist, unterstützt es nur Hive. Und Sie müssen alles andere mit Ihren Händen registrieren. Benutzer fragen häufig, wie Sie dies umgehen und sofort SQL-Abfragen durchführen können. Ich habe ein Verzeichnis implementiert, mit dem Sie Ignite-Tabellen durchsuchen und darauf zugreifen können, ohne ~ und sms ~ zu registrieren, und diesen Patch zunächst in der Spark-Community vorgeschlagen, auf die ich eine Antwort erhalten habe: Ein solcher Patch ist aus internen Gründen nicht interessant. Und sie gaben die interne API nicht heraus.
Jetzt ist der Ignite-Katalog eine interessante Funktion, die mithilfe der internen API von Spark implementiert wurde. Um dieses Verzeichnis zu verwenden, haben wir eine eigene Implementierung der Sitzung. Dies ist die übliche SparkSession, in der Sie Anforderungen stellen und Daten verarbeiten können. Die Unterschiede bestehen darin, dass wir ExternalCatalog für die Arbeit mit Ignite-Tabellen sowie IgniteOptimization integriert haben, die im Folgenden beschrieben werden.
SQL-Optimierung - Die Möglichkeit, SQL-Anweisungen in Ignite auszuführen. Standardmäßig liest Spark beim Ausführen von Verknüpfungen, Gruppierungen, Aggregatberechnungen und anderen komplexen SQL-Abfragen Daten zeilenweise. Die Datenquelle kann nur Zeilen effizient herausfiltern.
Wenn Sie Join oder Gruppierung verwenden, zieht Spark alle Daten aus der Tabelle mithilfe der angegebenen Filter in den Arbeitsspeicher des Workers und gruppiert sie erst dann oder führt andere SQL-Vorgänge aus. Im Fall von Ignite ist dies nicht optimal, da Ignite selbst eine verteilte Architektur hat und die darin gespeicherten Daten kennt. Daher kann Ignite selbst Aggregate effizient berechnen und Gruppierungen durchführen. Darüber hinaus kann es viele Daten geben, und um sie zu gruppieren, müssen Sie alles subtrahieren und alle Daten in Spark erhöhen, was ziemlich teuer ist.
Spark bietet eine API, mit der Sie den ursprünglichen Plan der SQL-Abfrage ändern, eine Optimierung durchführen und den Teil der SQL-Abfrage, der dort ausgeführt werden kann, an Ignite weiterleiten können. Dies ist sowohl hinsichtlich der Geschwindigkeit als auch des Speicherverbrauchs effektiv, da wir damit keine Daten abrufen, die sofort gruppiert werden.
Wie funktioniert es?
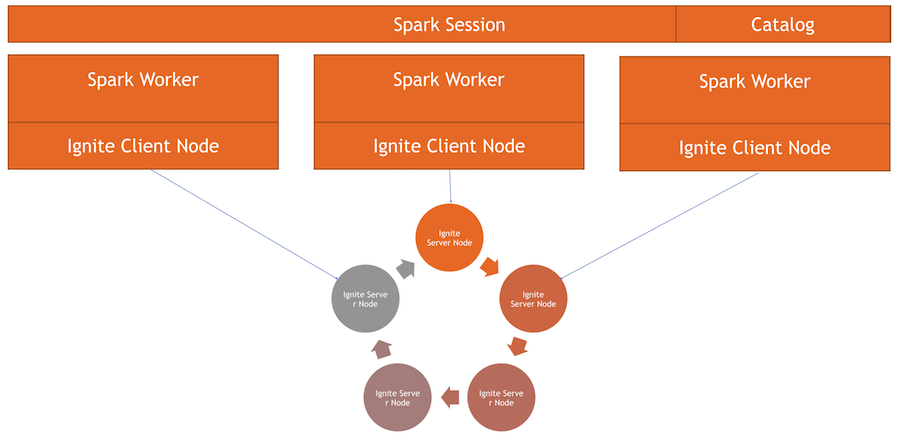
Wir haben einen Ignite-Cluster - dies ist die untere Bildhälfte. Es gibt keinen Zookeeper, da es nur fünf Knoten gibt. Es gibt Spark-Worker. In jedem Worker wird der Ignite-Client-Knoten ausgelöst. Dadurch können wir eine Anfrage stellen, die Daten lesen und mit dem Cluster interagieren. Außerdem steigt der Clientknoten in IgniteSparkSession an, damit das Verzeichnis funktioniert.
Datenrahmen entzünden
Wir wenden uns dem Code zu: Wie liest man Daten aus einer SQL-Tabelle? Bei Spark ist alles ganz einfach und gut: Wir sagen, wir wollen einige Daten berechnen, geben das Format an - dies ist eine bestimmte Konstante. Darüber hinaus haben wir mehrere Optionen - den Pfad zur Konfigurationsdatei für den Clientknoten, der beim Lesen von Daten beginnt. Wir geben an, welche Tabelle wir lesen möchten, und weisen Spark an, sie zu laden. Wir bekommen die Daten und können damit machen, was wir wollen.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
Nachdem wir die Daten generiert haben - optional aus Ignite, aus einer beliebigen Quelle - können wir genauso einfach alles speichern, indem wir das Format und die entsprechende Tabelle angeben. Wir befehlen Spark zu schreiben, wir geben ein Format an. In der Konfiguration schreiben wir vor, zu welchem Cluster eine Verbindung hergestellt werden soll. Geben Sie die Tabelle an, in der wir speichern möchten. Darüber hinaus können wir Dienstprogrammoptionen vorschreiben - geben Sie den Primärschlüssel an, den wir in dieser Tabelle erstellen. Wenn die Daten einfach gestört werden, ohne eine Tabelle zu erstellen, wird dieser Parameter nicht benötigt. Klicken Sie am Ende auf Speichern und die Daten werden geschrieben.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
Nun wollen wir sehen, wie alles funktioniert.
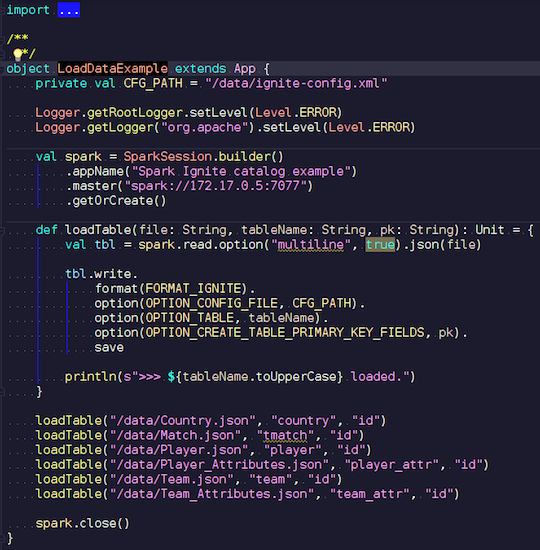 LoadDataExample.scala
LoadDataExample.scalaDiese offensichtliche Anwendung demonstriert zunächst die Aufnahmefunktionen. Zum Beispiel habe ich die Daten zu Fußballspielen ausgewählt und Statistiken von einer bekannten Ressource heruntergeladen. Es enthält Informationen zu Turnieren: Ligen, Spiele, Spieler, Teams, Spielerattribute, Teamattribute - Daten, die Fußballspiele in Ligen europäischer Länder (England, Frankreich, Spanien usw.) beschreiben.
Ich möchte sie auf Ignite hochladen. Wir erstellen eine Spark-Sitzung, geben die Adresse des Assistenten an und rufen das Laden dieser Tabellen auf, wobei wir Parameter übergeben. Das Beispiel ist in Scala, nicht in Java, weil Scala weniger ausführlich und zum Beispiel besser ist.
Wir übertragen den Dateinamen, lesen ihn und geben an, dass er mehrzeilig ist. Dies ist eine Standard-JSON-Datei. Dann schreiben wir in Ignite. Die Struktur unserer Datei ist nirgends zu beschreiben - Spark selbst bestimmt, welche Daten wir haben und wie sie strukturiert sind. Wenn alles reibungslos verläuft, wird eine Tabelle erstellt, in der alle erforderlichen Felder der erforderlichen Datentypen vorhanden sind. So können wir alles in Ignite laden.
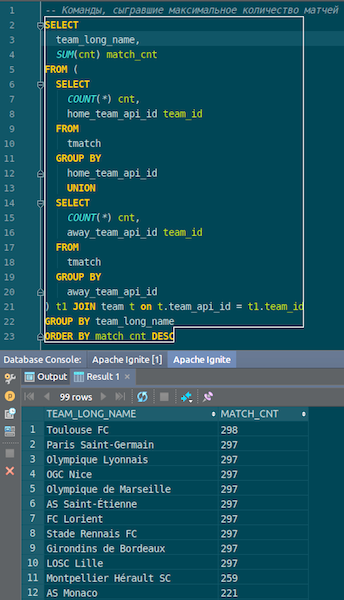
Wenn die Daten geladen sind, können wir sie in Ignite sehen und sofort verwenden. Als einfaches Beispiel eine Abfrage, mit der Sie wissen, welche Mannschaft die meisten Spiele gespielt hat. Wir haben zwei Kolumnen: Heimteam und Auswärtsteam, Gastgeber und Gäste. Wir wählen, gruppieren, zählen, summieren und verbinden Daten mit dem Befehl, um den Namen des Befehls einzugeben. Ta-dam - und die Daten von json-chiks, die wir in Ignite erhalten haben. Wir sehen Paris Saint-Germain, Toulouse - wir haben viele Daten über die französischen Mannschaften.
Wir fassen zusammen. Wir haben jetzt Daten aus der Quelle, der JSON-Datei, zu Ignite hochgeladen, und das ziemlich schnell. Aus Sicht von Big Data ist dies möglicherweise nicht zu groß, aber für einen lokalen Computer angemessen. Das Tabellenschema wird in seiner ursprünglichen Form aus der JSON-Datei übernommen. Die Tabelle wurde erstellt, die Spaltennamen wurden aus der Quelldatei kopiert, der Primärschlüssel wurde erstellt. ID ist überall und der Primärschlüssel ist ID. Diese Daten sind in Ignite eingegangen, wir können sie verwenden.
IgniteSparkSession und IgniteCatalog
Mal sehen, wie es funktioniert.
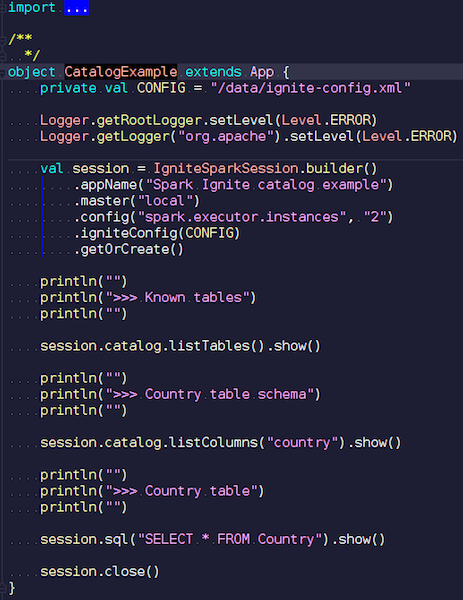 CatalogExample.scala
CatalogExample.scalaAuf relativ einfache Weise können Sie auf alle Ihre Daten zugreifen und diese abfragen. Im letzten Beispiel haben wir die Standard-Spark-Sitzung gestartet. Und es gab dort keine Ignite-Spezifität - außer dass Sie ein JAR mit der richtigen Datenquelle platzieren müssen - völlig Standardarbeit über die öffentliche API. Wenn Sie jedoch automatisch auf Ignite-Tabellen zugreifen möchten, können Sie unsere Erweiterung verwenden. Der Unterschied ist, dass wir anstelle von SparkSession IgniteSparkSession schreiben.
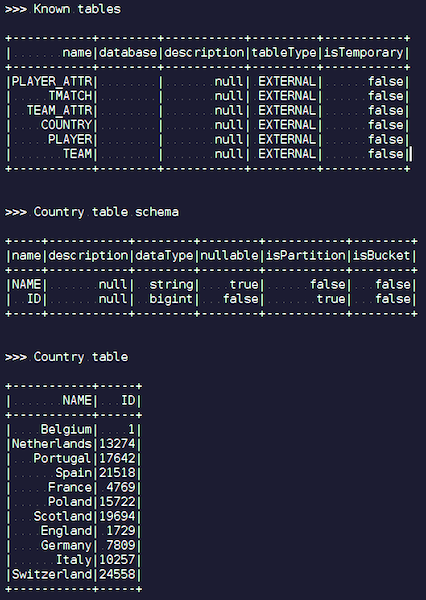
Sobald Sie ein IgniteSparkSession-Objekt erstellen, werden im Verzeichnis alle Tabellen angezeigt, die gerade in Ignite geladen wurden. Sie können ihr Diagramm und alle Informationen sehen. Spark kennt bereits die Tabellen von Ignite und Sie können problemlos alle Daten abrufen.
Igniteoptimization
Wenn Sie in Ignite mit JOIN komplexe Abfragen durchführen, zieht Spark zuerst die Daten heraus und erst dann gruppiert JOIN sie. Um den Prozess zu optimieren, haben wir die IgniteOptimization-Funktion entwickelt. Sie optimiert den Spark-Abfrageplan und ermöglicht es Ihnen, die Teile der Anforderung weiterzuleiten, die in Ignite in Ignite ausgeführt werden können. Wir zeigen Optimierung auf eine bestimmte Anfrage.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
Wir erfüllen die Anfrage. Wir haben einen Personentisch - einige Angestellte, Leute. Jeder Mitarbeiter kennt den Ausweis der Stadt, in der er lebt. Wir wollen wissen, wie viele Menschen in jeder Stadt leben. Wir filtern - in welcher Stadt mehr als eine Person lebt. Hier ist der erste Plan, den Spark erstellt:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
Die Beziehung ist nur eine Ignite-Tabelle. Es gibt keine Filter - wir pumpen einfach alle Daten aus der Personentabelle über das Netzwerk aus dem Cluster aus. Dann aggregiert Spark all dies - entsprechend der Anforderung und gibt das Ergebnis der Anforderung zurück.
Es ist leicht zu erkennen, dass all dieser Teilbaum mit Filter und Aggregation in Ignite ausgeführt werden kann. Dies ist viel effizienter als das Abrufen aller Daten aus einer potenziell großen Tabelle in Spark - genau das leistet unsere IgniteOptimization-Funktion. Nach der Analyse und Optimierung des Baums erhalten wir den folgenden Plan:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
Als Ergebnis erhalten wir nur eine Beziehung, da wir den gesamten Baum optimiert haben. Und im Inneren können Sie bereits sehen, dass Ignite eine Anfrage sendet, die nahe genug an der ursprünglichen Anfrage liegt.
Angenommen, wir verbinden verschiedene Datenquellen: Zum Beispiel haben wir einen DataFrame von Ignite, den zweiten von json, den dritten erneut von Ignite und den vierten von einer Art relationaler Datenbank. In diesem Fall wird nur der Teilbaum im Plan optimiert. Wir optimieren, was wir können, legen es in Ignite ab und Spark erledigt den Rest. Dadurch erhalten wir einen Geschwindigkeitsgewinn.
Ein weiteres Beispiel mit JOIN:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
Wir haben zwei Tische. Wir halten nach Wert zusammen und wählen aus allen aus - IDs, Werte. Spark bietet einen solchen Plan an:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
Wir sehen, dass er alle Daten aus einer Tabelle herausziehen wird, alle Daten aus der zweiten, sie in sich zusammenfügen und die Ergebnisse geben wird. Nach der Verarbeitung und Optimierung erhalten wir genau die gleiche Anfrage, die an Ignite geht, wo sie relativ schnell ausgeführt wird.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
Ich werde Ihnen ein Beispiel zeigen.
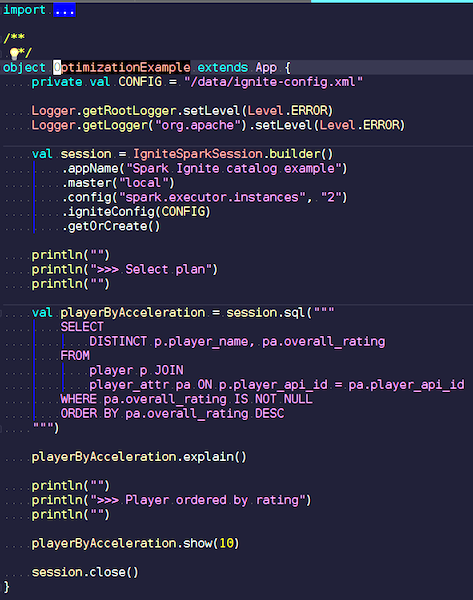 OptimizationExample.scala
OptimizationExample.scalaWir erstellen eine IgniteSpark-Sitzung, in der alle unsere Optimierungsfunktionen bereits automatisch enthalten sind. Hier lautet die Anfrage: Finde die Spieler mit der höchsten Bewertung und zeige ihre Namen an. In der Spielertabelle ihre Attribute und Daten. Wir schließen uns an, filtern Junk-Daten und zeigen Spieler mit der höchsten Bewertung an. Lassen Sie uns sehen, welche Art von Plan wir nach der Optimierung erhalten haben, und die Ergebnisse dieser Abfrage anzeigen.
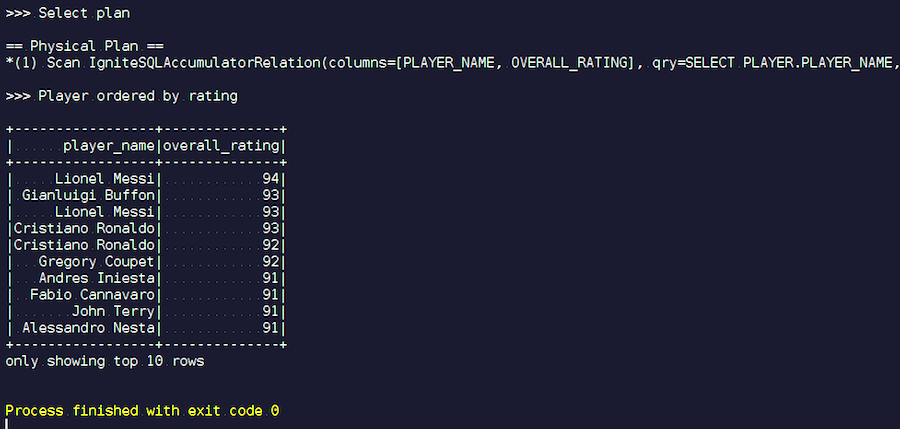
Wir fangen an. Wir sehen bekannte Nachnamen: Messi, Buffon, Ronaldo usw. Übrigens treffen sich einige aus irgendeinem Grund in zwei Formen - sowohl Messi als auch Ronaldo. Fußballliebhaber finden es vielleicht seltsam, dass unbekannte Spieler auf der Liste erscheinen. Dies sind Torhüter, Spieler mit ziemlich hohen Eigenschaften - vor dem Hintergrund anderer Spieler. Nun schauen wir uns den Abfrageplan an, der ausgeführt wurde. In Spark wurde fast nichts getan, dh wir haben die gesamte Anfrage erneut an Ignite gesendet.
Apache Ignite-Entwicklung
Unser Projekt ist ein Open Source-Produkt, daher freuen wir uns immer über Patches und Feedback von Entwicklern. Ihre Hilfe, Feedback, Patches sind sehr willkommen. Wir warten auf sie. 90% der Ignite-Community spricht Russisch. Zum Beispiel waren für mich bis zu meiner Arbeit an Apache Ignite nicht die besten Englischkenntnisse abschreckend. Es lohnt sich kaum, auf Russisch auf eine Entwicklerliste zu schreiben, aber selbst wenn Sie etwas falsch schreiben, werden sie Ihnen antworten und Ihnen helfen.
Was kann an dieser Integration verbessert werden? Wie kann ich helfen, wenn Sie einen solchen Wunsch haben? Liste unten. Sternchen zeigen die Komplexität an.

Um die Optimierung zu testen, müssen Sie Tests mit komplexen Abfragen schreiben. Oben habe ich einige offensichtliche Fragen gezeigt. Es ist klar, dass etwas fallen kann, wenn Sie viele Gruppierungen und viele Verknüpfungen schreiben. Dies ist eine sehr einfache Aufgabe - kommen Sie und machen Sie es. Wenn wir aufgrund der Testergebnisse Fehler finden, müssen diese behoben werden. Dort wird es schwieriger.
Eine weitere klare und interessante Aufgabe ist die Integration von Spark in einen Thin Client. Zunächst können einige Sätze von IP-Adressen angegeben werden. Dies reicht aus, um dem Ignite-Cluster beizutreten, was bei der Integration in ein externes System praktisch ist. Wenn Sie sich plötzlich der Lösung für dieses Problem anschließen möchten, werde ich Ihnen persönlich dabei helfen.
Wenn Sie der Apache Ignite-Community beitreten möchten, finden Sie hier einige nützliche Links:
Wir haben eine reaktionsschnelle Entwicklerliste, die Ihnen helfen wird. Es ist noch lange nicht ideal, aber im Vergleich zu anderen Projekten ist es wirklich lebendig.
Wenn Sie Java oder C ++ kennen, suchen Sie Arbeit und möchten Open Source (Apache Ignite, Apache Kafka, Tarantool usw.) entwickeln. Schreiben Sie hier: join-open-source@sberbank.ru.