Ich habe hier schon einmal über den Umzug von Asien nach Europa geschrieben und jetzt möchte ich schreiben, was ich in diesem Europa mache. Es gibt so einen Beruf - DevOps oder eher nicht, aber es ist so passiert, dass ich genau das jetzt mache. Für die Orchestrierung von allem, was im Docker ausgeführt wird, verwenden wir einen Rancher , über den ich auch geschrieben habe . Aber dann passierte etwas Schreckliches, Rancher 2.0 kam heraus und wechselte zu Kubernetes (im Folgenden einfach K8s). Da K8s nun wirklich der Standard für die Verwaltung des Clusters ist, bestand der Wunsch, die gesamte Infrastruktur mit Blackjack und Bibliothekaren wieder aufzubauen. Das Besondere daran ist, dass das Unternehmen ständig verschiedene Spezialisten aus verschiedenen Ländern und mit unterschiedlichen Traditionen anstellt und jemand eine puppet mitbringt, jemand ansible als ansible ist und im Allgemeinen glaubt, dass Makefile + bash unser Alles ist. Daher gibt es einfach keine eindeutige Meinung darüber, wie alles funktionieren soll, aber ich möchte es wirklich.
Ein solcher Zoo von Technologien und Werkzeugen wurde zuvor zusammengestellt:

Infrastrukturmanagement
- Minikube
- Rke
- Terraform
- Kops
- Kubespray
- Ansible
Anwendungsverwaltung
- Kubernetes
- Rancher
- Kubectl
- Helm
- Confd
- Kompose
- Jenkins
Protokollierung und Überwachung
- Elasticsearch
- Kibana
- Fließendes Bit
- Telegraf
- Influxdb
- Zabbix
- Prometheus
- Grafana
- Kapacitor
Als nächstes werde ich versuchen, jeden Punkt dieses Zoos kurz zu beschreiben, zu beschreiben, warum es notwendig ist und warum diese Lösung gewählt wurde. Tatsächlich kann fast jeder Artikel durch ein Dutzend Analoga ersetzt werden, und wir sind uns immer noch nicht ganz sicher, welche Wahl wir treffen. Wenn also jemand eine Meinung oder Empfehlungen hat, werde ich diese gerne in den Kommentaren lesen.
Kubernetes wird das Zentrum von allem sein, denn jetzt ist es wirklich eine Lösung, die einfach keine Alternativen hat, die von allen Anbietern von Amazon und Microsoft bis mail.ru unterstützt wird. Wie Alternativen in Betracht gezogen wurden
Swarm - der nie abhobNomad - das scheint von Fremden für Raubtiere geschrieben zu seinCattle ist der Motor von Ranger 1.x, von dem wir jetzt leben. Im Prinzip ist alles in Ordnung, aber der Rancher hat ihn bereits zugunsten von K8s aufgegeben, sodass es keine Entwicklung geben wird.
Infrastrukturgebäude
Zuerst müssen wir die Infrastruktur erstellen und einen k8s-Cluster darauf bereitstellen. Es gibt verschiedene Möglichkeiten, alle funktionieren und daher ist es schwierig, die besten auszuwählen.
Minikube ist eine großartige Option zum Starten eines Clusters auf einem Entwicklercomputer zu Testzwecken.
Rke - Rancher Kubernetes Engine, so einfach wie eine Tür, minimale Konfiguration zum Erstellen eines Cluster-Looks
nodes: - address: localhost role: [controlplane,worker,etcd]
Und das ist alles, dies reicht aus, um den Cluster auf dem lokalen Computer zu starten, während Sie produktionsbereite HA-Cluster erstellen, die Konfiguration ändern, den Cluster aktualisieren, die etcd-Datenbank sichern und vieles mehr können.
Kops - Mit dieser Option können Sie nicht nur einen Cluster erstellen, sondern auch Instanzen in aws oder gce vorab erstellen. Außerdem können Sie eine Konfiguration für Terraform erstellen. Ein interessantes Werkzeug, aber wir haben noch keine Wurzeln geschlagen. Es wird vollständig durch terraform + rke während es einfacher und flexibler ist.
Kubespray - in der Tat ist es nur eine ansible Rolle, die einen k8s-Cluster schafft, verdammt leistungsfähig, flexibel, konfigurierbar. Dies ist praktisch die Standardlösung für die Bereitstellung von k8s.
Terraform ist ein Tool zum Aufbau der Infrastruktur in aws, azurblau oder an vielen anderen Orten. Flexibel, stabil - ich empfehle.
Bei Ansible geht es nicht wirklich um k8s, aber wir verwenden es überall und auch hier: Konfigurationen optimieren, Software installieren / aktualisieren, Zertifikate verteilen. Billig und fröhlich.
Anwendungsverwaltung
Wir haben also einen Cluster, jetzt müssen wir etwas Nützliches darauf starten. Alles, was bleibt, ist die Frage, wie das geht.
Option eins: Verwenden Sie nackte k8s, die alle mit kubectl . Grundsätzlich hat diese Option das Recht auf Leben. Kubectl ist ein leistungsstarkes Tool, mit dem wir alles tun können, was wir benötigen, einschließlich Bereitstellung, Upgrade, Überwachung des aktuellen Status, Änderung der Konfiguration im laufenden Betrieb, Anzeigen von Protokollen und Herstellen einer Verbindung zu bestimmten Containern. Aber manchmal möchte ich, dass alles etwas bequemer ist, also gehen wir weiter.
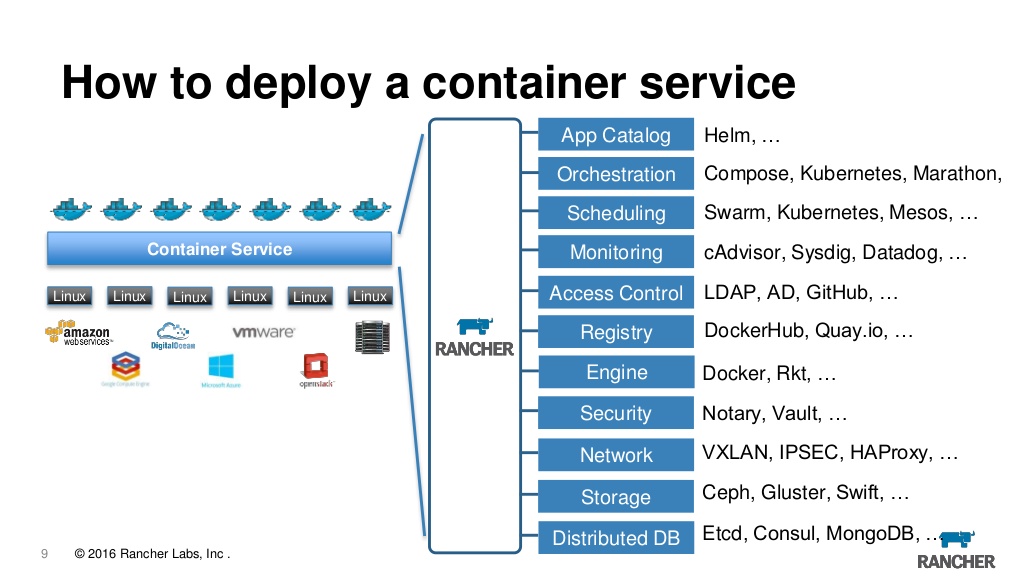
Tatsächlich ist Rancher jetzt ein Web-Maulkorb für die Verwaltung von K8s und gleichzeitig viele kleine Brötchen, die zusätzlichen Komfort bieten. Hier können Sie Protokolle anzeigen, auf die Konsole zugreifen und Anwendungen und rollenbasierte Zugriffssteuerung sowie einen integrierten Metadatenserver, Alarme, Protokollumleitung, Verwaltung von Geheimnissen und vieles mehr konfigurieren und aktualisieren. Wir verwenden den Rancher der ersten Version seit einigen Jahren und sind damit völlig zufrieden, obwohl wir zugeben müssen, dass sich beim Wechsel zu k8s die Frage stellt, ob wir ihn wirklich brauchen. Es ist schön, dass Sie jeden zuvor erstellten Cluster in den Rancher importieren können. Von jedem Anbieter aus können Sie einen Cluster aus EKS aus Azure importieren und lokal erstellen und von einem Ort auf einen Server übertragen. Wenn Sie sich plötzlich langweilen, können Sie den Server einfach abreißen und den Cluster weiterhin direkt über kubeclt oder ein anderes Tool verwenden.
Das sehr korrekte Konzept von allem als Code ist jetzt populär. Beispielsweise wird die Infrastruktur als Code mithilfe von terraform implementiert, die Assemblierung als Code über die jenkins pipeline . Nun ist die Wende zur Anwendung gekommen. Die Installation und Konfiguration der Anwendung sollte auch in einem Manifest beschrieben und im Git gespeichert werden. Die Rancher-Versionen 1.x verwendeten die Standard docker-compose.yml und alles war in Ordnung, aber als sie zu k8s wechselten, wechselten sie zu Helmkarten. Helm ist aus meiner Sicht ein absolut schrecklicher Austausch mit seltsamer Logik und Architektur. Dies ist eines dieser Projekte, bei denen das Gefühl bleibt, dass es von Raubtieren für Fremde geschrieben wurde oder umgekehrt. Das einzige Problem ist, dass es in der Welt des K8-Ruders einfach keine Alternativen gibt und dies de facto der Standard ist. Deshalb werden wir zum Weinen gestochen, aber weiterhin das Ruder benutzen. In Version 3.x versprechen die Entwickler, es von Grund auf neu zu schreiben, alle Kuriositäten herauszuholen und die Architektur zu vereinfachen. Dann werden wir heilen, aber jetzt werden wir essen, was ist.
Wir müssen hier auch zumindest jenkins erwähnen, es bezieht sich nicht direkt auf das Thema Kubernetis, aber mit seiner Hilfe werden Anwendungen im Cluster bereitgestellt. Er ist, er arbeitet und er ist ein Thema für einen separaten Artikel.
Überwachung
Jetzt haben wir einen Cluster und er dreht sogar eine Art Anwendung. Es scheint, dass Sie ausatmen können, aber tatsächlich fängt alles gerade erst an. Wie stabil ist unsere Anwendung? Wie schnell Hat er genug Ressourcen? Was passiert im Allgemeinen im Cluster?
Ja, das nächste Thema ist Überwachung und Protokollierung. Es gibt nur drei eindeutige Antworten. Speichern Sie Protokolle in elasticsearch und beobachten Sie sie durch kibana Draw-Grafiken in grafana . Für alle anderen Fragen gibt es ein Dutzend richtige Antworten.
Hier beginnen wir mit grafana für sich allein, es macht praktisch nichts, aber es kann wie ein schönes Gesicht an jedem der unten beschriebenen Systeme befestigt werden und schöne und manchmal klare Grafiken erhalten. Außerdem können Sie sofort Alarme einrichten, aber es ist besser, andere Lösungen dafür zu verwenden, zum Beispiel prometheus alertmanager und ElastAlert .
Aus meiner Sicht ist dies im Moment der beste Aggregator und Router für Protokolle. Außerdem wird K8s sofort unterstützt. Es gibt auch Fluentd aber es ist in Rubel geschrieben und zieht zu viel Legacy-Code, was es viel weniger attraktiv macht. Wenn Sie also ein bestimmtes Modul von fluentd benötigen, das noch nicht auf fluent-bit portiert wurde, verwenden Sie es im Übrigen - bit ist die beste Wahl. Es ist schneller, stabiler und verbraucht weniger Speicher. Ermöglicht das Sammeln von Protokollen aus allen oder aus ausgewählten Containern, das Filtern, Anreichern durch Hinzufügen von kubernetis-spezifischen Daten und das Senden aller Protokolle an elasticsearch oder an viele andere Repositorys. Wenn Sie es mit herkömmlichem logstash + docker-bit + file-bit vergleichen logstash + docker-bit + file-bit diese Lösung in jeder Hinsicht definitiv besser. Historisch gesehen verwenden wir immer noch logspout + logstash aber fließend gewinnt definitiv.
Ein Überwachungssystem, das speziell für die Microservice-Architektur geschrieben wurde. Als De-facto-Standard in der Branche gibt es außerdem ein Projekt namens Prometheus Operator , das speziell für k8s geschrieben wurde. Jeder entscheidet, was er wählt, aber es ist besser, mit bloßem Prometheus zu beginnen, nur um die Logik seiner Arbeit zu verstehen, unterscheidet sie sich erheblich von den üblichen Systemen. Wir müssen auch den node-exporter erwähnen, mit dem Sie Metriken auf Maschinenebene erfassen können, und den Prometheus-Rancher-Exporter, mit dem Sie Metriken über die Rancher-API erfassen können. Wenn Sie einen Cluster auf Kubernetes haben, ist Prometheus im Allgemeinen ein Muss.
Man könnte hier aufhören, aber historisch gesehen haben wir mehrere weitere Überwachungssysteme. Erstens ist es für zabbix sehr praktisch, alle Probleme der gesamten Infrastruktur auf einem Panel zu sehen. Dank der automatischen Erkennung können Sie schnell neue Netzwerke, Knoten, Dienste und im Allgemeinen fast alles zur Überwachung finden und hinzufügen. Dies macht es zu mehr als einem praktischen Tool für die Überwachung dynamischer Infrastrukturen. Darüber hinaus wurde in Version 4.0 eine Sammlung von Metriken von Prometheus-Exporteuren zu zabbix hinzugefügt, und es stellt sich heraus, dass all dies sehr schön in ein System integriert werden kann. Obwohl es noch keine eindeutige Antwort gibt, ob es notwendig ist, zabbix in einen k8s-Cluster zu ziehen, ist es auf jeden Fall interessant, es zu versuchen.
Alternativ können Sie TIG (telegraf + influxdb + grafana) einfach konfiguriert, es funktioniert stabil, es ermöglicht Ihnen, Metriken nach Containern, Anwendungen, Knoten usw. zu aggregieren, aber im Wesentlichen dupliziert es die Funktionalität von prometheus, und es sollte nur noch eine übrig sein.
Es stellt sich also heraus, dass Sie die Bindung von ein paar Dutzend Hilfsdiensten und Tools installieren und konfigurieren müssen, bevor Sie etwas Nützliches starten können. Gleichzeitig wurden in dem Artikel keine Probleme bei der Verwaltung persistenter Daten, Geheimnisse und anderer seltsamer Dinge angesprochen, die jeweils in eine separate Veröffentlichung verschoben werden können.
Und wie sehen Sie die ideale Infrastruktur?
Wenn Sie eine Meinung haben, schreiben Sie bitte in die Kommentare oder treten Sie unserem Team bei und helfen Sie, alles zusammenzustellen.