Einmal sagte ein bekannter russischer Musiker in einem Interview: „Wir arbeiten daran, an der Decke zu liegen und zu spucken.“ Ich kann dieser Aussage nur zustimmen, da die Tatsache, dass Faulheit die treibende Kraft bei der Entwicklung der Technologie ist, nicht argumentiert werden kann. In der Tat sind wir erst im letzten Jahrhundert von Dampfmaschinen zur digitalen Industrialisierung übergegangen, und jetzt wird die künstliche Intelligenz, die von Science-Fiction-Autoren und Zukunftsforschern des letzten Jahrhunderts beschrieben wurde, jeden Tag zu einer immer größeren Realität unserer Welt. Computerspiele, mobile Geräte, Smartwatches und vieles mehr Verwenden Sie grundsätzlich Algorithmen, die mit Mechanismen des maschinellen Lernens verbunden sind.
Heutzutage haben neuronale Netze aufgrund der zunehmenden Rechenleistung von Grafikprozessoren und der großen Datenmenge an Popularität gewonnen, mit der sie Klassifizierungs- und Regressionsprobleme lösen und sie auf vorbereitete Daten trainieren. Es wurden bereits viele Artikel darüber geschrieben, wie neuronale Netze trainiert werden und welche Frameworks dafür verwendet werden sollen. Es gibt jedoch eine frühere Aufgabe, die ebenfalls gelöst werden muss, und dies ist die Aufgabe, ein Datenarray zu bilden - einen Datensatz, um das neuronale Netzwerk weiter zu trainieren. Dies wird in diesem Artikel erläutert.
Vor nicht allzu langer Zeit musste ein akustischer Klassifikator für Fahrzeuggeräusche erstellt werden, mit dem Daten aus einem gemeinsamen Audiostream extrahiert werden können: Glasscherben, Öffnen von Türen und Betrieb eines Automotors in verschiedenen Modi. Die Entwicklung des Klassifikators war nicht schwierig, aber woher kann man den Datensatz beziehen, damit er alle Anforderungen erfüllt?
Google kam zur Rettung (keine Beleidigung für Yandex - ich werde etwas später auf seine Vorteile eingehen), mit deren Hilfe mehrere Hauptcluster mit den erforderlichen Daten herausgegriffen werden konnten. Ich möchte im Voraus darauf hinweisen, dass die in diesem Artikel angegebenen Quellen eine große Menge akustischer Informationen mit verschiedenen Klassen enthalten, mit denen Sie einen Datensatz für verschiedene Aufgaben erstellen können. Nun wenden wir uns einer Übersicht dieser Quellen zu.
Freesound.org
Höchstwahrscheinlich bietet
Freesound.org das größte Volumen an akustischen Daten und ist ein gemeinsames Repository für lizenzierte Musikbeispiele, das derzeit mehr als 230.000 Kopien von Soundeffekten enthält. Jedes Soundbeispiel kann unter einer anderen Lizenz vertrieben werden. Machen Sie sich daher besser
im Voraus mit der
Lizenzvereinbarung vertraut. Beispielsweise hat die
Zero- Lizenz
(cc0) den Status "Kein Urheberrecht" und ermöglicht Ihnen das Kopieren, Ändern und Verteilen, einschließlich der kommerziellen Nutzung, sowie das absolut legale Verwenden der Daten.
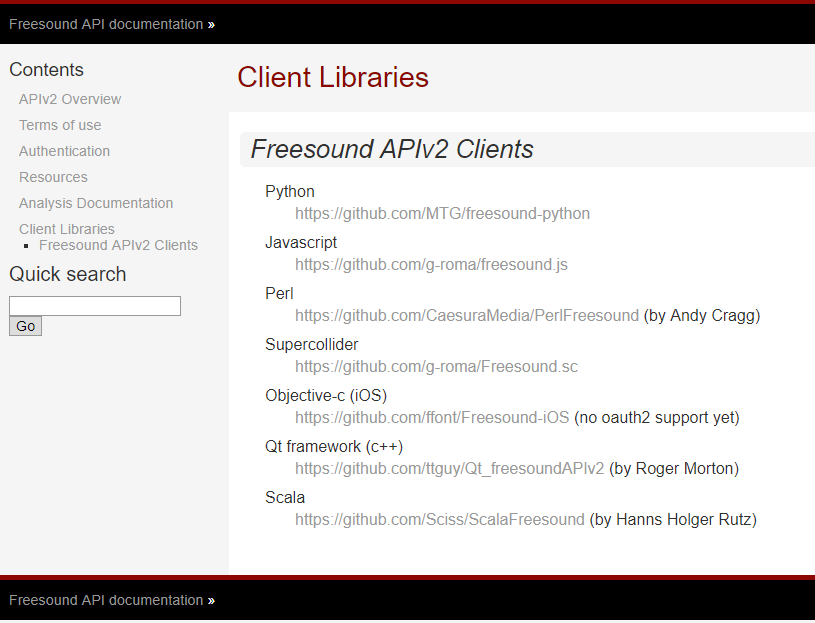
Um akustische Informationselemente in einer Vielzahl von freesound.org zu finden, haben die Entwickler eine
API bereitgestellt, mit der Daten aus Repositorys analysiert, gesucht und heruntergeladen werden können. Um damit arbeiten zu können, müssen Sie Zugriff erhalten. Dazu müssen Sie zum
Formular gehen und alle erforderlichen Felder ausfüllen. Danach wird der einzelne Schlüssel generiert.

Die Entwickler von Freesound.org stellen
APIs für verschiedene Programmiersprachen bereit, sodass das gleiche Problem mit verschiedenen Tools gelöst werden kann. Die Liste der unterstützten Sprachen und Links für den Zugriff auf GitHub sind unten aufgeführt.
Um dieses Ziel zu erreichen, wurde Python verwendet, da diese schöne Programmiersprache für dynamische Typisierung aufgrund ihrer Benutzerfreundlichkeit an Popularität gewann und den Mythos der Komplexität der Softwareentwicklung vollständig auslöschte.
Das Modul für die Arbeit mit freesound.org für Python kann aus dem Repository von github.com geklont werden.
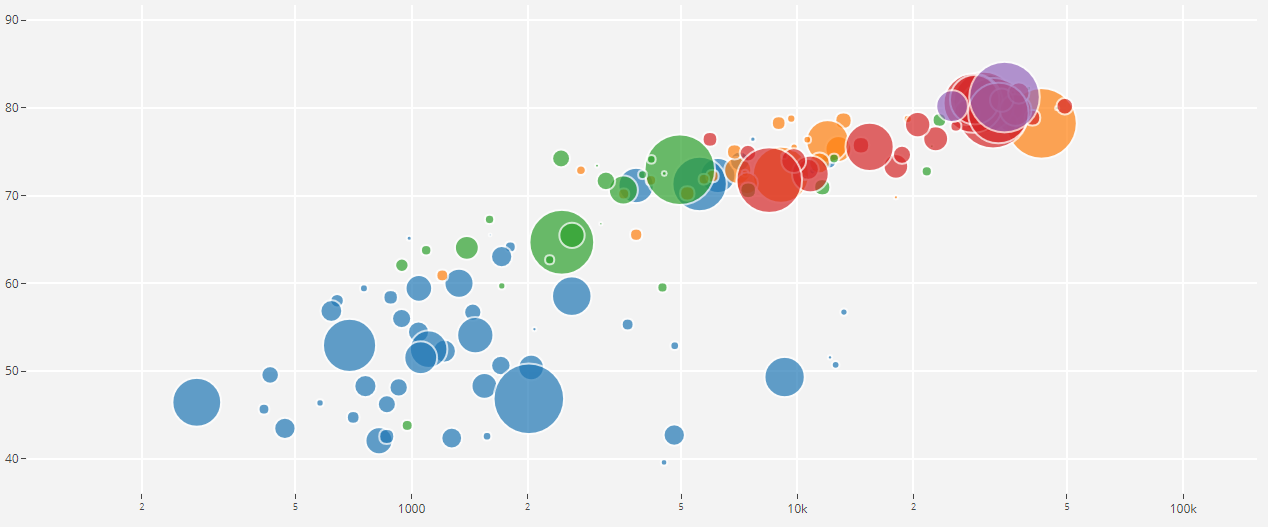
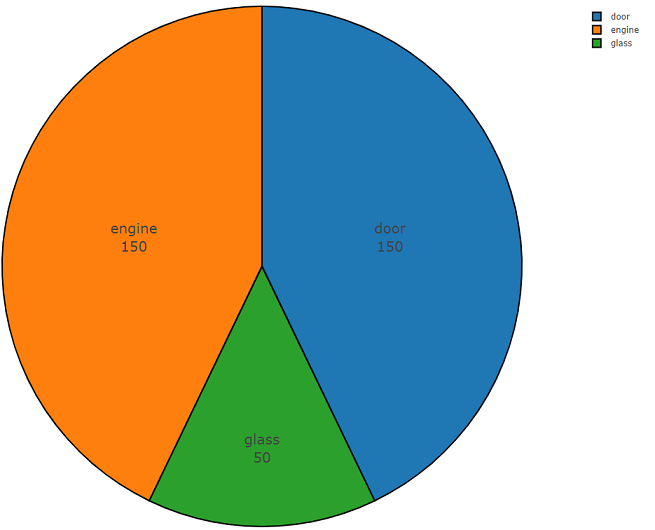
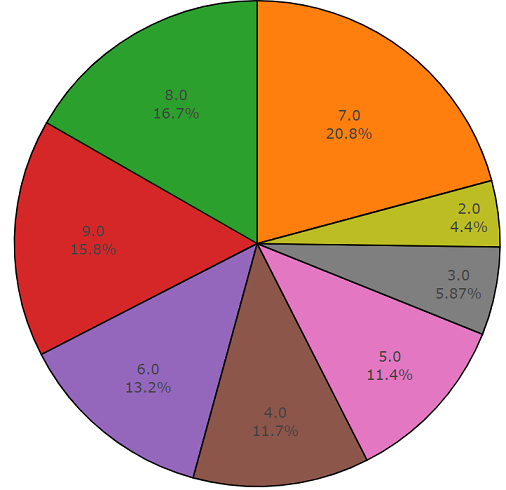
Unten finden Sie den zweiteiligen Code, der die Benutzerfreundlichkeit dieser API demonstriert. Der erste Teil des Programmcodes führt die Aufgabe der Datenanalyse aus, deren Ergebnis die Dichte der Datenverteilung für jede angeforderte Klasse ist, und der zweite Teil lädt Daten aus freesound.org-Repositorys für ausgewählte Klassen hoch. Die Verteilungsdichte bei der Suche nach akustischen Informationen mit den Schlüsselwörtern
Glas, Motor, Tür wird unten in einem Kreisdiagramm als Beispiel dargestellt.
Beispielcode für die Datenanalyse von Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
Beispielcode zum Herunterladen von freesound.org-Daten
Ein Merkmal von Freesound ist, dass die Analyse von Audiodaten ohne Herunterladen einer Audiodatei durchgeführt werden kann, sodass Sie MFCC, spektrale Energie, spektralen Schwerpunkt und andere Koeffizienten erhalten können. Weitere Informationen zu Lowlevel-Informationen finden Sie in der
Dokumentation zu freesound.ord .
Mit der freesound.org-API wird der Zeitaufwand für das Abrufen und Herunterladen von Daten minimiert, sodass Sie Arbeitsstunden beim Studium anderer Informationsquellen sparen können, da hochgenaue akustische Klassifizierer einen großen Datensatz mit großer Variabilität erfordern, der Daten mit unterschiedlichen Harmonischen auf einem und darstellt die gleiche Klasse von Ereignissen.
YouTube-8M und AudioSet
Ich denke, dass YouTube in der Präsentation nicht besonders erforderlich ist, aber Wikipedia sagt uns dennoch, dass YouTube eine Video-Hosting-Site ist, die Benutzern Videoanzeigedienste bietet, wobei zu vergessen ist, dass YouTube eine riesige Datenbank ist und diese Quelle für maschinelles Lernen verwendet werden muss und Google Inc stellt uns ein Projekt namens
YouTube-8M Dataset zur Verfügung .
Der YouTube-8M-Datensatz ist ein Datensatz, der mehr als eine Million Videodateien von YouTube in hoher Qualität enthält. Um genauere Informationen zu erhalten, gab es im Mai 2018 6,1 Millionen Videos mit 3862 Klassen. Dieser Datensatz ist unter
Creative Commons Attribution 4.0 International (CC BY 4.0) lizenziert. Mit einer solchen Lizenz können Sie Material auf jedem Medium und Format kopieren und verteilen.
Sie fragen sich wahrscheinlich: Woher kommen die Videodaten, wenn akustische Informationen für die Aufgabe benötigt werden, und Sie werden sehr richtig liegen. Tatsache ist, dass Google nicht nur Videoinhalte bereitstellt, sondern auch ein Teilprojekt mit Audiodaten namens
AudioSet separat
zuweist .
 AudioSet
AudioSet - bietet einen Datensatz aus YouTube-Videos, in dem viele Daten in einer Klassenhierarchie mithilfe
einer Ontologiedatei dargestellt werden . Die grafische Darstellung befindet sich unten.
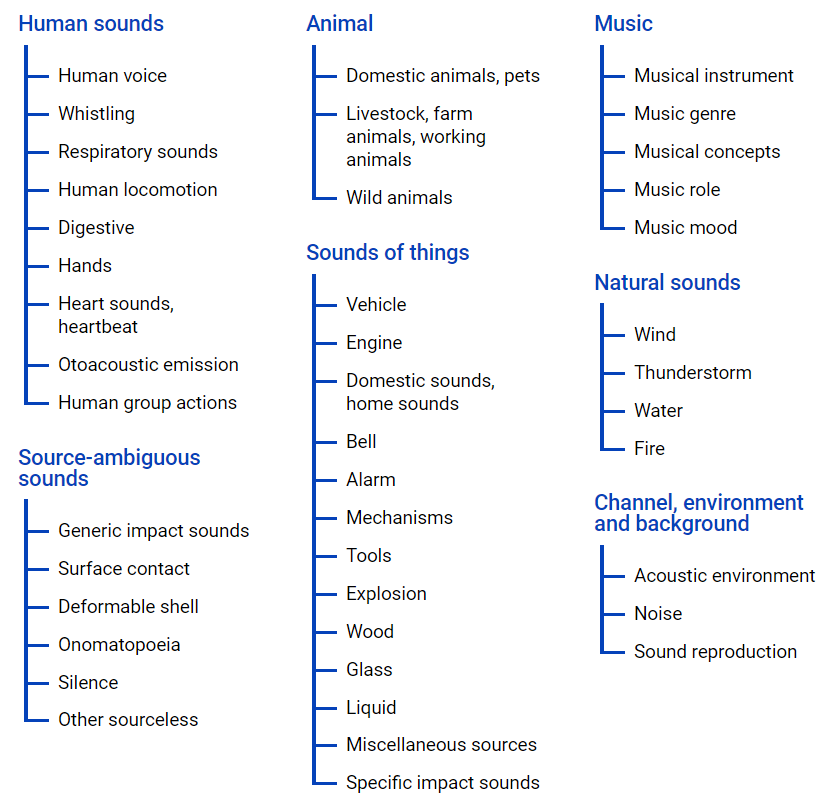
Mit dieser Datei erhalten Sie einen Überblick über die Verschachtelung von Klassen sowie den Zugriff auf YouTube-Videos. Um Daten aus dem Internet hochzuladen, können Sie das Python-Modul youtube-dl verwenden, mit dem Sie je nach erforderlicher Aufgabe Audio- oder Videoinhalte herunterladen können.
AudioSet stellt einen Cluster dar, der in drei Sätze unterteilt ist: Test, Training (ausgeglichen) und Trainingsdatensatz (nicht ausgeglichen).
Schauen wir uns diesen Cluster an und analysieren jeden dieser Sätze separat, um eine Vorstellung von den enthaltenen Klassen zu erhalten.
Training (ausgewogen)Gemäß der Dokumentation besteht dieser Datensatz aus
22.176 Segmenten, die aus verschiedenen Videos stammen, die nach Schlüsselwörtern ausgewählt wurden, wodurch jede Klasse mindestens 59 Kopien erhält. Wenn wir uns die Verteilungsdichte der Stammklassen in der Hierarchie der Menge ansehen, werden wir sehen, dass die Musikklasse die größte Gruppe von Audiodateien ist.
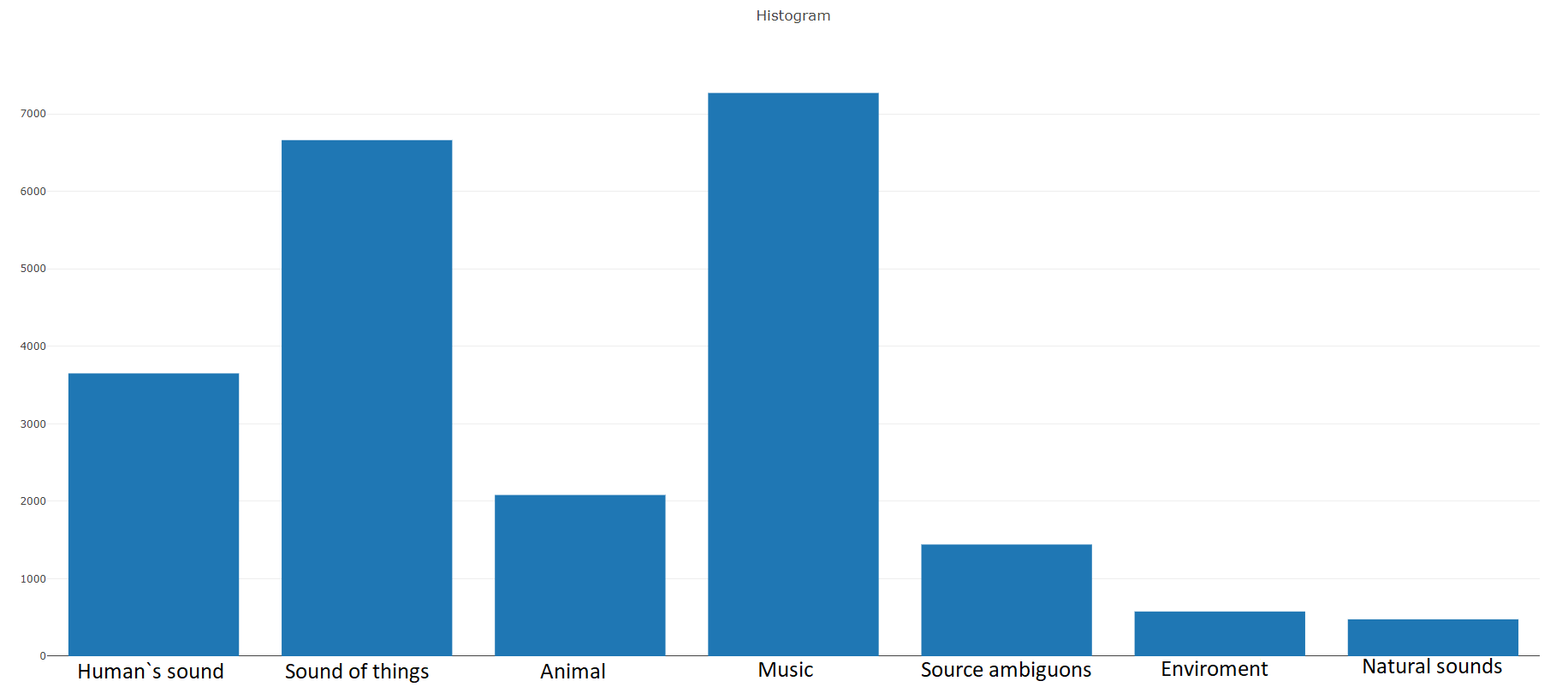
Organisierte Klassen werden in Teilmengen von Klassen zerlegt, sodass Sie bei der Verwendung detailliertere Informationen erhalten. Dieses ausgewogene Trainingsset hat eine Verteilungsdichte, bei der klar ist, dass ein Gleichgewicht vorhanden ist, aber auch einzelne Klassen unterscheiden sich stark von der allgemeinen Sichtweise.
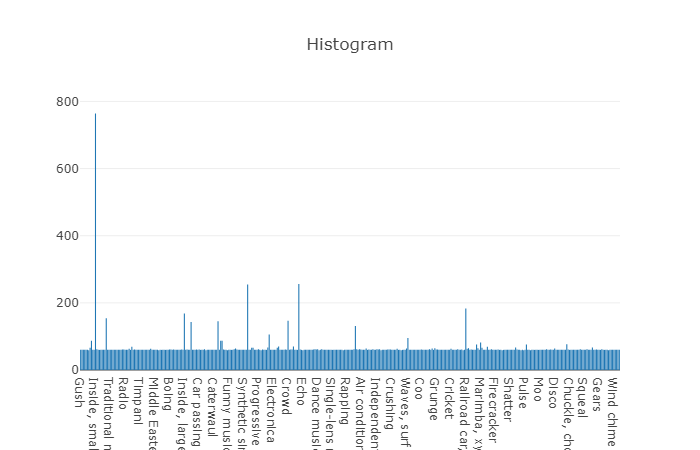
Die Verteilung von Klassen, deren Anzahl von Elementen den Durchschnittswert überschreitet
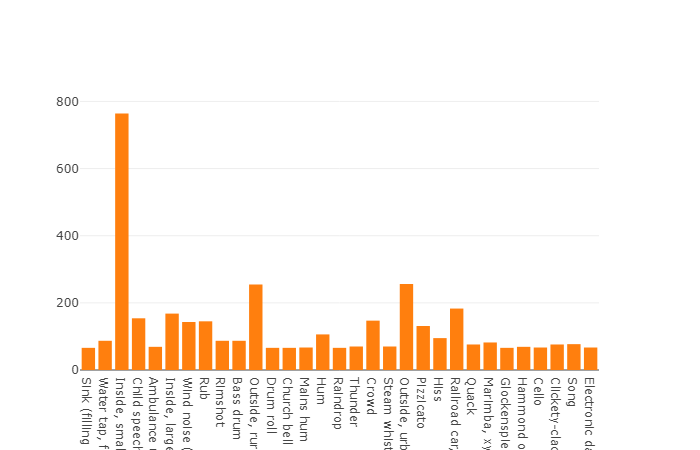
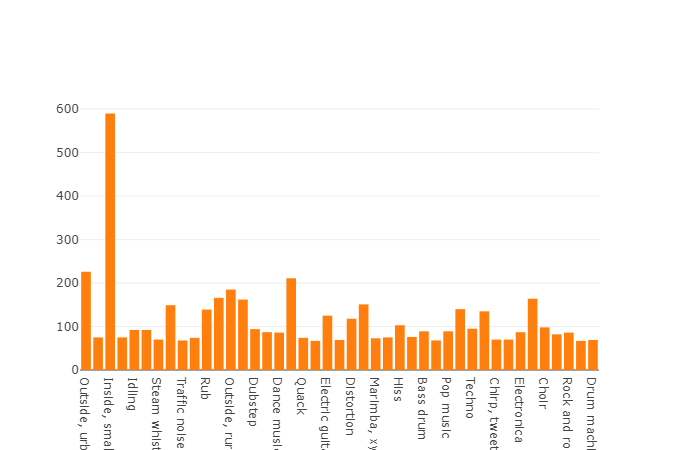
Die durchschnittliche Dauer jeder Audiodatei beträgt 10 Sekunden. Detailliertere Informationen finden Sie im Datenträgerdiagramm, aus dem hervorgeht, dass sich die Dauer einiger Dateien vom Hauptsatz unterscheidet. Dieses Diagramm wird ebenfalls dargestellt.
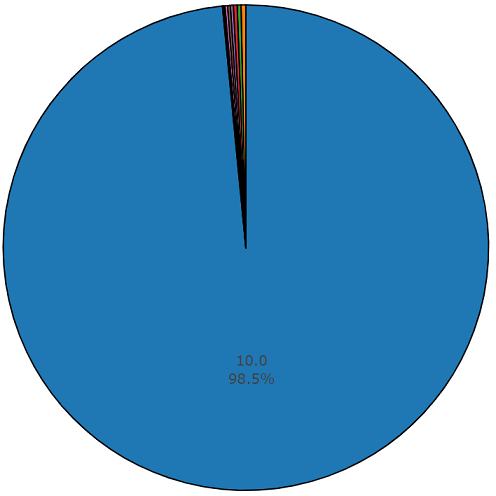
Diagramm von anderthalb Prozent nicht durchschnittlicher Dauer aus einem ausgewogenen Satz von Audiosets
 Training (unausgeglichen)
Training (unausgeglichen)Der Vorteil dieses Datensatzes ist seine Größe. Stellen Sie sich vor, dass dieser Satz laut Dokumentation 2.042.985 Segmente enthält und im Vergleich zu ausgeglichenen Datensätzen eine große Variabilität darstellt, die Entropie dieses Satzes jedoch viel höher ist.
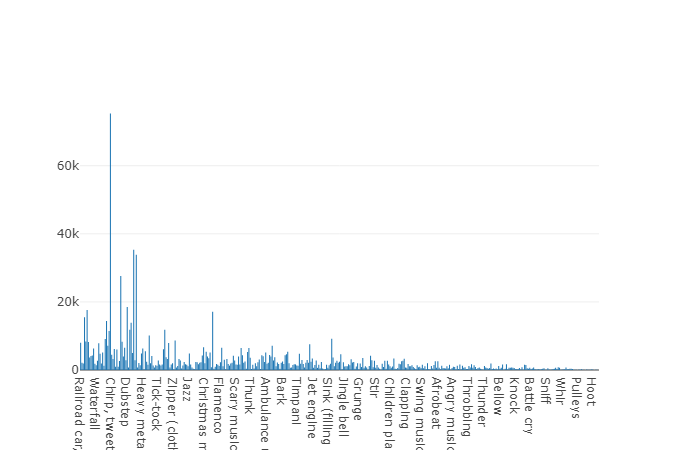
In diesem Satz beträgt die durchschnittliche Dauer jeder Audiodatei ebenfalls 10 Sekunden. Das Datenträgerdiagramm für diesen Datensatz ist unten dargestellt.
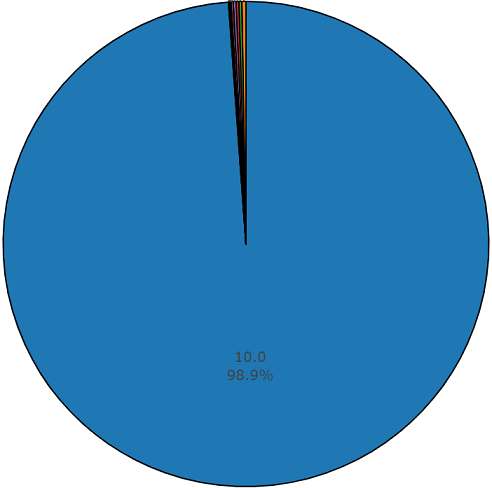
Diagramm mit nicht durchschnittlicher Dauer aus einem unausgeglichenen Satz von Audiosets
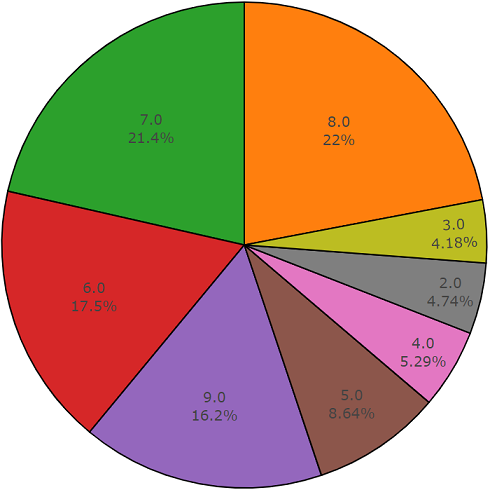
 Testset
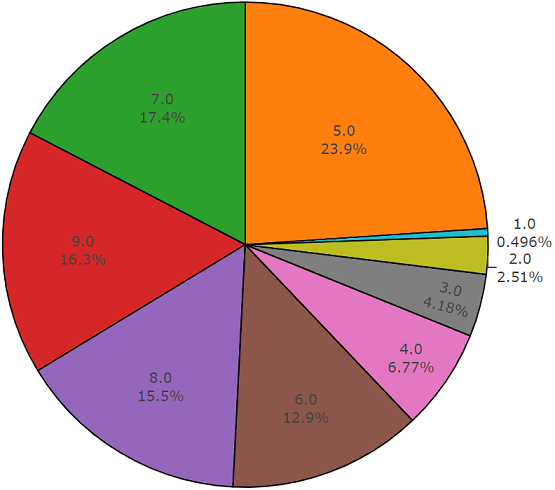
TestsetDiese Menge ist einer ausgeglichenen Menge sehr ähnlich, mit dem Vorteil, dass sich die Elemente dieser Mengen nicht schneiden. Ihre Verteilung ist unten dargestellt.
Die Verteilung von Klassen, deren Anzahl von Elementen den Durchschnittswert überschreitet
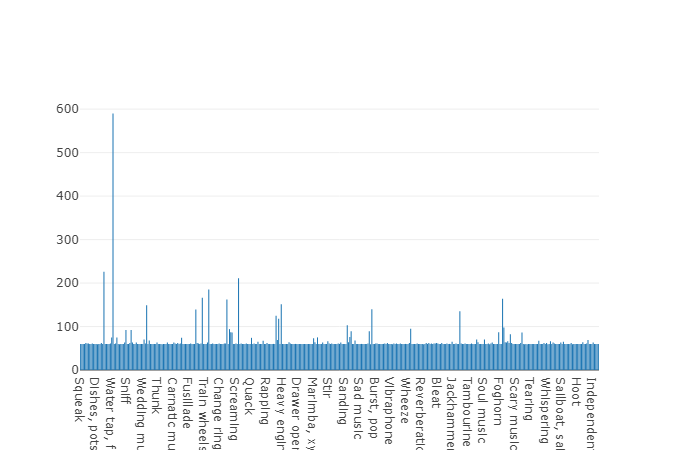
Die durchschnittliche Dauer eines Segments aus diesem Datensatz beträgt ebenfalls 10 Sekunden
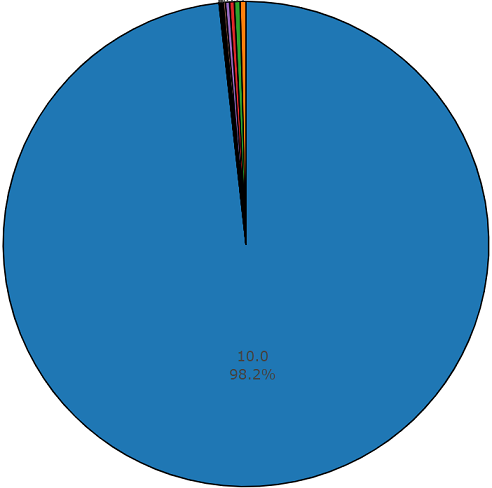
und der Rest hat die im Plattendiagramm angegebene Dauer
Beispielcode zum Analysieren und Herunterladen von akustischen Daten gemäß dem ausgewählten Datensatz:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
Um detailliertere Informationen zur Analyse von Audioset-Daten zu erhalten oder diese Daten gemäß der
Ontologiedatei und dem ausgewählten
Audioset-Satz aus dem Yotube-Bereich hochzuladen , steht der Programmcode
dem GitHub-Repository frei zur
Verfügung .
urbansound
Urbansound ist einer der größten Datensätze mit markierten Klangereignissen, deren Klassen zur städtischen Umgebung gehören. Diese Menge wird taxonomisch (kategorisch) genannt, d.h. Jede Klasse ist in ihre Unterklassen unterteilt. Eine solche Menge kann in Form eines Baumes dargestellt werden.
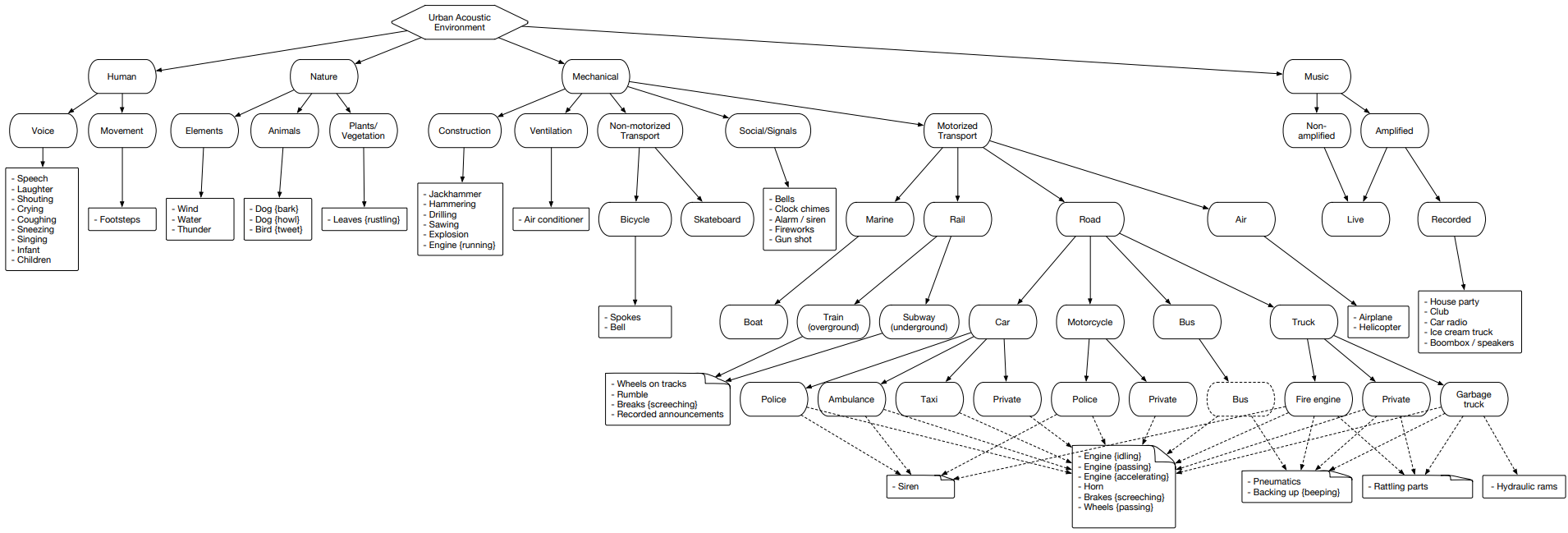
Um urbansound-Daten für die spätere Verwendung hochzuladen, gehen Sie einfach auf die Seite und klicken Sie auf
Download .
Da für die Aufgabe nicht alle Unterklassen verwendet werden müssen und nur eine einzige Klasse für das Fahrzeug erforderlich ist, müssen zunächst die erforderlichen Klassen mithilfe der Metadatei gefiltert werden, die sich im Stammverzeichnis des Verzeichnisses befindet, das beim Entpacken der heruntergeladenen Datei abgerufen wurde.
Nach dem Entladen aller erforderlichen Daten aus den aufgelisteten Quellen stellte sich heraus, dass ein Datensatz mit mehr als 15.000 Dateien gebildet wurde. Ein solches Datenvolumen ermöglicht es uns, mit der Aufgabe fortzufahren, den akustischen Klassifikator zu trainieren, aber es bleibt ein ungelöstes Problem hinsichtlich der "Reinheit" der Daten, d. H. Der Trainingssatz enthält Daten, die sich nicht auf die erforderlichen Klassen des zu lösenden Problems beziehen. Wenn Sie beispielsweise Dateien aus der Klasse "Glas zerbrechen" anhören, können Sie Leute finden, die darüber sprechen, "wie es nicht gut ist, das Glas zu zerbrechen". Daher stehen wir vor der Aufgabe, Daten zu filtern, und als Werkzeug zur Lösung dieser Art von Problem ist ein Werkzeug perfekt geeignet, dessen Kern von belarussischen Leuten entwickelt wurde und den seltsamen Namen „Yandex.Toloka“ erhielt.
Yandex.Toloka
Yandex.Toloka ist ein Crowdfunding-Projekt, das 2014 ins Leben gerufen wurde, um eine große Datenmenge für die weitere Verwendung beim maschinellen Lernen zu markieren oder zu sammeln. Mit diesem Tool können Sie Daten mithilfe einer Personalressource erfassen, markieren und filtern. Ja, mit diesem Projekt können Sie nicht nur Probleme lösen, sondern auch andere Menschen Geld verdienen. Die finanzielle Belastung liegt in diesem Fall auf Ihren Schultern, aber aufgrund der Tatsache, dass mehr als 10.000 Tolker von Seiten der Darsteller handeln, werden die Arbeitsergebnisse in naher Zukunft eingehen. Eine gute Beschreibung der Funktionsweise dieses Tools finden Sie im
Yandex-Blog .
Im Allgemeinen ist die Verwendung des Crushs nicht besonders schwierig, da für die Veröffentlichung einer Aufgabe nur eine Registrierung auf der
Website , ein Mindestbetrag von 10 US-Dollar und eine korrekt ausgeführte Aufgabe erforderlich sind. Wie man eine Aufgabe richtig formuliert, kann man der
Yandex.Tolok-Dokumentation entnehmen oder es gibt keinen schlechten
Artikel über Habr . Von mir selbst zu diesem Artikel möchte ich hinzufügen, dass selbst wenn eine Vorlage fehlt, die für die Anforderung Ihrer Aufgabe geeignet ist, ihre Entwicklung nicht länger als ein paar Stunden Arbeit dauert, mit einer Pause für Kaffee und eine Zigarette, und die Ergebnisse der Darsteller bis zum Ende des Arbeitstages erhalten werden können.
FazitBeim maschinellen Lernen besteht eine der Hauptaufgaben bei der Lösung des Klassifizierungs- oder Regressionsproblems darin, einen zuverlässigen Datensatz zu entwickeln - einen Datensatz. In diesem Artikel wurden Informationsquellen mit einer großen Menge akustischer Daten berücksichtigt, die es ermöglichten, den für eine bestimmte Aufgabe erforderlichen Datensatz zu bilden und auszugleichen. Der vorgestellte Programmcode ermöglicht es uns, das Hochladen von Daten auf ein Minimum zu vereinfachen, wodurch die Zeit zum Empfangen von Daten verkürzt und der Rest für die Entwicklung eines Klassifikators aufgewendet wird.
Nachdem ich Daten aus allen in diesem Artikel vorgestellten Quellen gesammelt und anschließend gefiltert hatte, gelang es mir, den erforderlichen Datensatz für das Training des akustischen Klassifikators zu bilden, der auf einem neuronalen Netzwerk basiert. Ich hoffe, dass dieser Artikel es Ihnen und Ihrem Team ermöglicht, Zeit zu sparen und sie für die Entwicklung neuer Technologien aufzuwenden.
PS Ein in Python entwickeltes Softwaremodul zum Analysieren und Hochladen von akustischen Daten für jede der präsentierten Quellen, das Sie im
Github-Repository finden