
Dieser Beitrag ist eine Übersetzung des Originalartikels
von Paid Nidrinhouse, Full-Stack-Softwareentwickler. Die Hauptspezialität ist JavaScript, aber Paige studiert auch andere Sprachen und Frameworks. Und er teilt seine Erfahrungen mit seinen Lesern. Der Artikel wird übrigens für Anfänger interessant sein.
Vor kurzem stand ich vor einer Aufgabe, die mich interessierte - es war notwendig, bestimmte Daten aus dem riesigen Volumen unstrukturierter Akten der US-Bundestagswahlkommission zu extrahieren. Ich habe nicht zu viel mit Rohdaten gearbeitet, also habe ich mich entschlossen, die Herausforderung anzunehmen und diese Aufgabe zu übernehmen. Als Werkzeug zur Lösung habe ich Node.js gewählt.
Skillbox empfiehlt: Der Online-Kurs Frontend Developer Profession .
Wir erinnern Sie daran: Für alle Leser von „Habr“ - ein Rabatt von 10.000 Rubel bei der Anmeldung für einen Skillbox-Kurs mit dem Promo-Code „Habr“.
Die Aufgabe wurde in vier Punkten beschrieben:
- Das Programm sollte die Gesamtzahl der Zeilen in der Datei berechnen.
- Jede achte Spalte enthält den Namen einer Person. Sie müssen diese Daten laden und ein Array mit allen in der Datei enthaltenen Namen erstellen. Der Name 432. und 43.243 muss angezeigt werden.
- Jede fünfte Spalte enthält das Datum der Spende durch Freiwillige. Zählen Sie, wie viele Spenden pro Monat insgesamt getätigt werden, und drucken Sie das Gesamtergebnis aus.
- Jede achte Spalte enthält den Namen einer Person. Erstellen Sie ein Array, indem Sie nur den Vornamen ohne den Nachnamen auswählen. Finden Sie heraus, welcher Name am häufigsten und wie oft gefunden wird?
(Die ursprüngliche Aufgabe kann
hier unter diesem Link eingesehen werden .)
Die Datei, mit der Sie arbeiten müssen, ist eine reguläre TXT-Datei mit 2,55 GB. Es gibt auch einen Ordner, der Teile der Hauptdatei enthält (Sie können das Programm darauf debuggen, ohne das gesamte große Array analysieren zu müssen).
Zwei mögliche Lösungen auf Node.js.
Grundsätzlich macht das Arbeiten mit großen Dateien einem JavaScript-Spezialisten keine Angst. Darüber hinaus ist dies eine der Hauptfunktionen von Node.js. Es gibt verschiedene mögliche Lösungen zum Lesen und Schreiben von Dateien.
Das vertraute ist fs.readFile (). Sie können die gesamte Datei lesen, in den Speicher ablegen und dann Node verwenden.
Eine Alternative ist fs.createReadStream (), eine Funktion, die Daten ähnlich wie in anderen Sprachen organisiert übergibt - beispielsweise in Python oder Java.
Die Lösung, die ich gewählt habe
Da ich die Gesamtzahl der Zeilen berechnen und die Daten analysieren musste, um Namen und Daten zu analysieren, entschied ich mich, bei der zweiten Option anzuhalten. Hier könnte ich die Funktion rl.on ('line', ...) verwenden, um die erforderlichen Daten aus den Zeilen abzurufen.
Node.js CreateReadStream () & ReadFile () Code
Unten ist der Code, den ich mit Node.js und der Funktion fs.createReadStream () geschrieben habe.
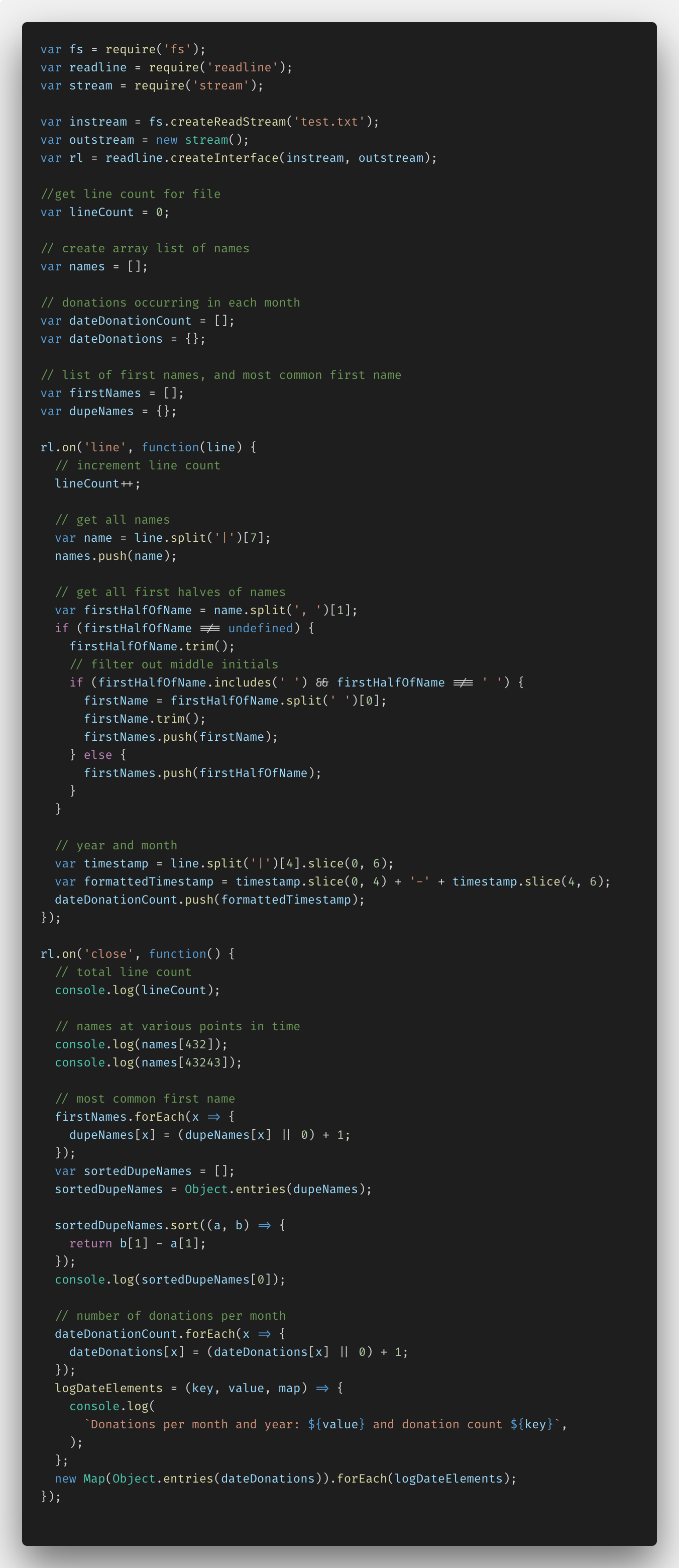
Zunächst musste ich alles einrichten, um zu erkennen, dass für das Importieren von Daten Node.js-Funktionen wie fs (Dateisystem), readline und stream erforderlich sind. Als nächstes konnte ich zusammen mit readLine.createInterface () instream und outstream erstellen. Der resultierende Code ermöglichte es, die Datei zeilenweise unter Verwendung der erforderlichen Daten zu analysieren.
Außerdem habe ich mehrere Variablen und Kommentare hinzugefügt, um mit bestimmten Daten zu arbeiten. Dies sind lineCount, dupeNames und Arrays von Namen, Spenden und Vornamen.
In der Funktion rl.on ('line', ...) konnte ich das Parsen von Dateien zeilenweise festlegen. Also habe ich die Variable lineCount für jede Zeile eingegeben. Ich habe die JavaScript-Methode split () verwendet, um Namen zu analysieren, indem ich sie meinem Namensarray hinzufügte. Als nächstes habe ich nur Namen ohne Nachnamen getrennt und dabei Ausnahmen hervorgehoben, z. B. das Vorhandensein von Doppelnamen, Initialen in der Mitte des Namens usw. Als Nächstes habe ich das Jahr und das Datum von der Datenspalte getrennt, dies alles in das Format JJJJ-MM konvertiert und dem Array den dateDonationCount hinzugefügt.
In der Funktion rl.on ('close', ...) habe ich alle Transformationen der den Arrays hinzugefügten Daten mit den in console.log empfangenen Informationen durchgeführt.
lineCount und Namen werden benötigt, um den 432. und 43.243. Namen zu bestimmen, hier sind keine Konvertierungen erforderlich. Die Identifizierung des gebräuchlichsten Namens im Array und die Bestimmung der Anzahl der Spenden sind jedoch kompliziertere Aufgaben.
Um den gebräuchlichsten Namen zu identifizieren, musste ich für jeden Namen (Schlüssel) und die Anzahl der Verweise auf Object.entries () ein Objekt mit Wertepaaren erstellen. (Wert) und konvertieren Sie dann alles mit der ES6-Funktion in ein Array von Arrays. Danach war es nicht mehr schwierig, die Namen zu sortieren und die am häufigsten wiederholten zu identifizieren.
Mit Spenden habe ich ungefähr den gleichen Trick gemacht: Ich habe ein Objekt aus Wertepaaren und eine logDateElements () -Funktion erstellt, mit der ich mithilfe der ES6-Interpolation Schlüssel und Werte für jeden Monat anzeigen konnte. Dann habe ich eine neue Map () erstellt, das dateDonations-Objekt in ein Metamarray konvertiert und jedes Array mit logDateElements () durchlaufen. (Es stellte sich heraus, dass es nicht so einfach war, wie es am Anfang schien.)
Aber es hat funktioniert, ich konnte eine relativ kleine Datei von 400 MB lesen und die notwendigen Informationen hervorheben.
Danach habe ich fs.createReadStream () ausprobiert - ich habe die Aufgabe auf fs.readFile () implementiert, um den Unterschied zu erkennen. Hier ist der Code:
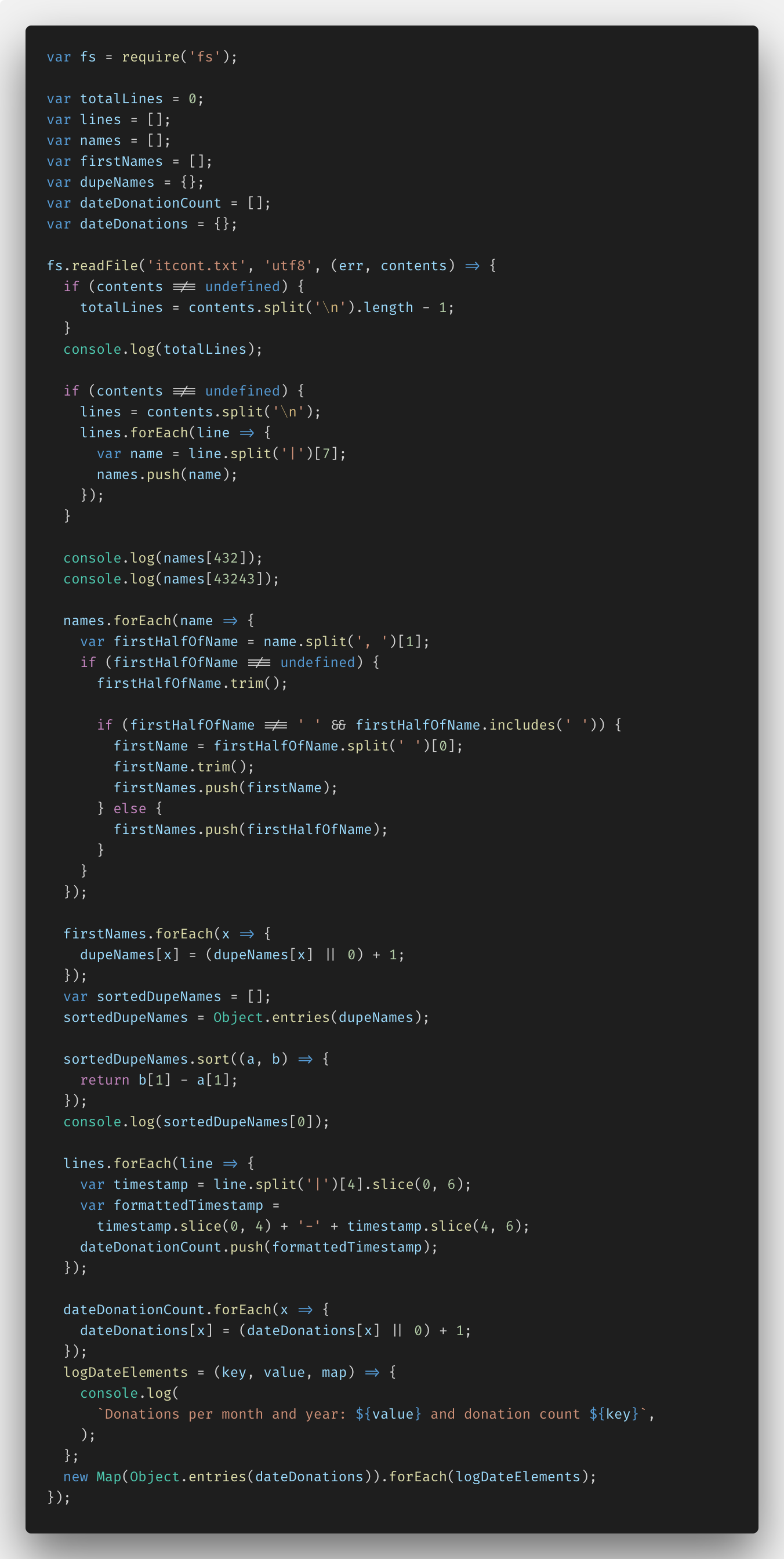
Sie können die gesamte Lösung
hier sehen .
Ergebnisse der Arbeit mit Node.js.
Die Lösung hat sich bewährt. Ich habe den Pfad zur Datei readFileStream.js hinzugefügt und ... beobachtet, wie der Knotenserver mit einem JavaScript-Heap-Speicherfehler fehlgeschlagen ist.

Es stellte sich heraus, dass zwar alles funktionierte, diese Lösung jedoch versuchte, den gesamten Inhalt der Datei in den Speicher zu übertragen, was mit einer Kapazität von 2,55 GB unmöglich war. Der Knoten kann gleichzeitig mit 1,5 GB Arbeitsspeicher arbeiten, nicht mehr.
Daher kam keine meiner Entscheidungen zustande. Es brauchte eine neue, die auch mit solch umfangreichen Dateien funktionieren konnte.
Neue Lösung
Wie sich herausstellte, musste das beliebte NPM-Modul EventStream verwendet werden.
Nachdem ich die Dokumentation studiert hatte, konnte ich verstehen, was zu tun ist. Hier ist die dritte Version des Programmcodes.

In der Dokumentation für das Modul wurde angegeben, dass der Datenstrom unter Verwendung des Zeichens \ n am Ende jeder Zeile der txt-Datei in separate Elemente unterteilt werden sollte.
Grundsätzlich musste ich nur die Namensantwort ändern. Ich konnte keine 130 Millionen Namen in das Array einfügen - der Speichermangelfehler trat erneut auf. Ich habe das Problem gelöst, indem ich die Namen 432. und 43.243 berechnet und meinem eigenen Array hinzugefügt habe. Ein wenig nicht, was in den Bedingungen gefragt wurde, aber wer hat gesagt, dass man nicht kreativ sein kann?
Runde 2. Wir versuchen das Programm in Arbeit
Ja, alle die gleiche Datei mit einem Volumen von 2,55 GB, wir drücken die Daumen und folgen dem Ergebnis.
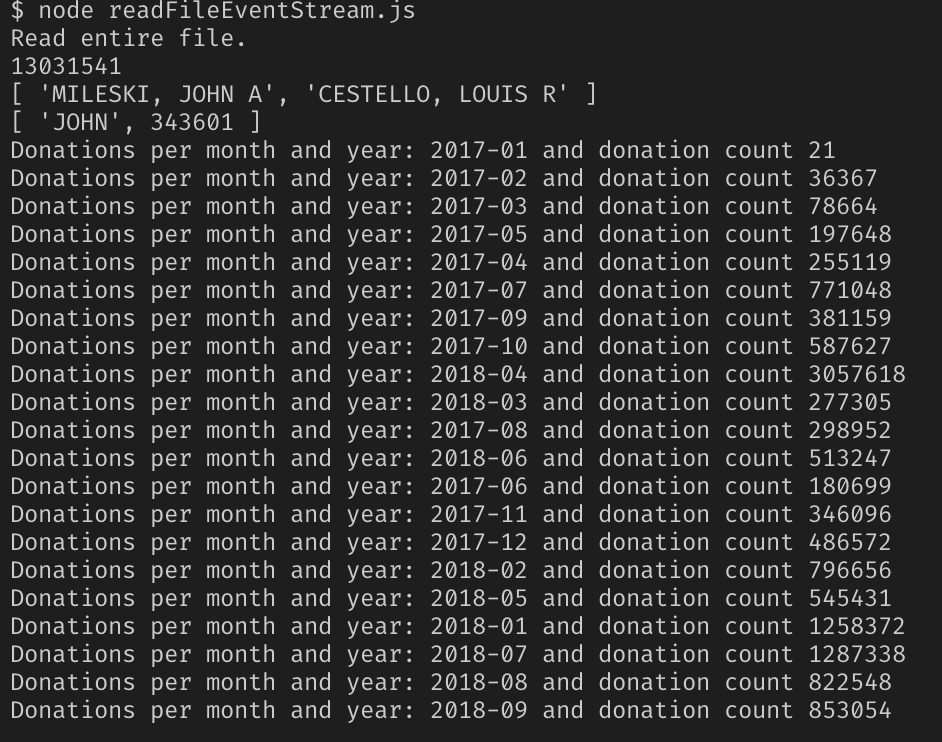
Erfolg!
Wie sich herausstellte, ist nur Node.js nicht zur Lösung solcher Probleme geeignet, seine Fähigkeiten sind etwas eingeschränkt. Wenn Sie sie jedoch mithilfe von Modulen erweitern, können Sie mit so großen Dateien arbeiten.
Skillbox empfiehlt: