Vollständige Standardisierung
Ich bereitete dieses Material für meine Rede auf der Konferenz vor und fragte unseren technischen Direktor, was das Hauptmerkmal von Kubernetes für unsere Organisation sei. Er antwortete:
Die Entwickler selbst verstehen nicht, wie viel zusätzliche Arbeit sie geleistet haben.
Anscheinend war er von dem kürzlich gelesenen Buch „Factfulness“ inspiriert - es ist schwierig, geringfügige und kontinuierliche Veränderungen zum Besseren zu bemerken, und wir verlieren ständig unsere Fortschritte aus den Augen.
Der Wechsel zu Kubernetes ist aber definitiv nicht unerheblich.

Fast 30 unserer Teams führen alle oder einige Workloads in den Clustern aus. Etwa 70% unseres HTTP-Datenverkehrs wird von Anwendungen in Kubernetes-Clustern generiert. Dies ist wahrscheinlich die größte Technologiekonvergenz seit meinem Eintritt in das Unternehmen, nachdem Forward 2010 uSwitch gekauft hat , als wir von .NET und physischen Servern auf AWS und von einem monolithischen System auf Microservices umgestiegen sind .
Und alles ging sehr schnell. Ende 2017 nutzten alle Teams ihre AWS-Infrastruktur. Sie richten Load Balancer, EC2-Instanzen, ECS-Cluster-Updates und ähnliches ein. Etwas mehr als ein Jahr verging und alles änderte sich.
Wir haben ein Minimum an Zeit für die Konvergenz aufgewendet. Infolgedessen hat Kubernetes uns bei der Lösung dringender Probleme geholfen - unsere Cloud wuchs, die Organisation wurde komplizierter und wir hatten Probleme, neue Mitarbeiter in Teams zu integrieren. Wir haben die Organisation nicht geändert, um Kubernetes zu verwenden. Im Gegenteil - wir haben Kubernetes verwendet, um die Organisation zu ändern.
Die Entwickler haben vielleicht keine großen Änderungen bemerkt, aber die Daten sprechen für sich. Dazu später mehr.
Vor vielen Jahren war ich auf einer Clojure-Konferenz und hörte einen Vortrag von Michael Nygard über Architektur, der nicht in seinen endgültigen Zustand gebracht werden kann . Er öffnete meine Augen. Ein ordentliches und ordentliches System sieht karikiert aus, wenn es Fernsehgeschäfte mit Küchenartikeln und der groß angelegten Softwarearchitektur vergleicht - das vorhandene System sieht aus wie ein dummes Messer, und anstelle von geraden Scheiben kommt eine Art Brei heraus. Ohne ein neues Messer gibt es nichts, woran man denken könnte.
Hier geht es darum, wie Organisationen dreijährige Projekte lieben: Das erste Jahr ist die Entwicklung und Vorbereitung, das zweite Jahr ist die Implementierung, das dritte ist die Rückkehr. In einem Vortrag sagt er, dass solche Projekte normalerweise kontinuierlich durchgeführt werden und selten das Ende des zweiten Jahres erreichen (oft aufgrund der Übernahme durch ein anderes Unternehmen und einer Änderung der Richtung und Strategie), so dass die übliche Architektur ist
Schichtung des Wandels in einem gewissen Anschein von Stabilität.
Und uSwitch ist ein gutes Beispiel.
Wir sind aus vielen Gründen zu AWS gewechselt - unser System konnte Spitzenlasten nicht bewältigen, und die Organisation wurde durch ein zu starres System und eng verwandte Teams behindert, die für bestimmte Projekte gebildet und durch Spezialisierung unterteilt wurden.
Wir wollten nicht alles beenden, alle Systeme übertragen und neu beginnen. Wir haben neue Dienste mit Proxy über den vorhandenen Load Balancer erstellt und die alte Anwendung schrittweise gedrosselt . Wir wollten sofort die Rückkehr zeigen und führten in der ersten Woche A / B-Tests der ersten Version des neuen Service in der Produktion durch. Infolgedessen nahmen wir langfristige Produkte und begannen, aus Entwicklern, Designern, Analysten usw. Teams für sie zu bilden. Und wir sahen sofort das Ergebnis. Im Jahr 2010 schien dies eine echte Revolution zu sein.
Jahr für Jahr haben wir neue Teams, Dienste und Anwendungen hinzugefügt und das monolithische System schrittweise „erwürgt“. Die Teams entwickelten sich schnell - jetzt arbeiteten sie unabhängig voneinander und bestanden aus Spezialisten in allen notwendigen Bereichen. Wir haben die Teaminteraktionen für Produktversionen minimiert. Wir haben nur für die Konfiguration des Load Balancers mehrere Befehle zugewiesen.
Die Teams selbst wählten Entwicklungsmethoden, Tools und Sprachen. Wir haben ihnen eine Aufgabe gestellt, und sie haben selbst eine Lösung gefunden, weil sie sich in dieser Angelegenheit am besten auskennen. Mit AWS sind diese Änderungen einfacher geworden.
Wir haben uns intuitiv an die Prinzipien der Programmierung gehalten - Teams, die lose miteinander verbunden sind, werden weniger wahrscheinlich kommunizieren und wir müssen keine wertvollen Ressourcen für die Koordination ihrer Arbeit aufwenden. All dies wird in dem kürzlich veröffentlichten Buch Accelerate großartig beschrieben.
Als Ergebnis haben wir, wie Michael Nygard beschrieben hat, ein System mit vielen Ebenen von Änderungen erhalten - einige Systeme wurden mit Puppet automatisiert, andere mit Terraform, irgendwo haben wir ECS verwendet, irgendwo EC2.
2012 waren wir stolz auf unsere Architektur, die leicht geändert werden konnte , um zu experimentieren , erfolgreiche Lösungen zu finden und diese zu entwickeln.
Aber 2017 haben wir festgestellt, dass sich viel geändert hat.
AWS ist jetzt viel komplexer als im Jahr 2010. Es bietet eine Vielzahl von Optionen und Funktionen - aber nicht ohne Konsequenzen. Heute muss jedes Team, das mit EC2 arbeitet, eine VPC, eine Netzwerkkonfiguration und vieles mehr auswählen.
Wir haben dies selbst erlebt - Teams begannen sich zu beschweren, dass sie immer mehr Zeit für die Wartung der Infrastruktur aufwenden, z. B. für die Aktualisierung von Instanzen in AWS ECS-Clustern , EC2-Maschinen, den Wechsel von ELB-Balancern zu ALB usw.
Mitte 2017 forderte ich bei einer Firmenveranstaltung alle auf, ihre Arbeit zu standardisieren, um die Gesamtqualität der Systeme zu verbessern. Ich habe die abgedroschene Eisberg-Metapher verwendet, um zu zeigen, wie wir Software erstellen und warten:

Ich sagte, dass die meisten Teams in unserem Unternehmen Services oder Produkte erstellen und sich auf Problemlösung, Anwendungscode, Plattformen und Bibliotheken usw. konzentrieren sollten. In dieser Reihenfolge. Unter Wasser bleibt noch viel Arbeit - Integration von Protokollen, Verbesserung der Beobachtbarkeit, Verwaltung von Geheimnissen usw.
Zu dieser Zeit befasste sich jedes Team von Anwendungsentwicklern mit fast dem gesamten Eisberg und traf alle Entscheidungen selbst - Auswahl der Sprache, der Entwicklungsumgebung, des Bibliotheks- und Metriktools, des Betriebssystems, des Instanztyps und des Speichers.
Am Fuße der Pyramide hatten wir eine Amazon Web Services-Infrastruktur. Es sind jedoch nicht alle AWS-Services gleich. Sie verfügen über ein Backend-as-a-Service (BaaS) , beispielsweise zur Authentifizierung und Datenspeicherung. Und es gibt andere, relativ niedrige Dienste wie EC2. Ich wollte die Daten studieren und verstehen, dass die Teams Grund zur Beschwerde haben und wirklich mehr Zeit damit verbringen, mit Low-Level-Diensten zu arbeiten und viele nicht die wichtigsten Entscheidungen zu treffen.
Ich habe die Dienste in Kategorien unterteilt, mithilfe von CloudTrail alle verfügbaren Statistiken gesammelt und dann mithilfe von BigQuery , Athena und ggplot2 festgestellt , wie sich die Situation für Entwickler in letzter Zeit geändert hat. Das Wachstum für Dienste wie RDS, Redshift usw. halten wir für wünschenswert (und erwartet) und das Wachstum für EC2, CloudFormation usw. - umgekehrt.

Jeder Punkt im Diagramm zeigt das 90. (rot), 80. (grün) und 50. (blau) Perzentil für die Anzahl der Dienste auf niedriger Ebene , die unsere Mitarbeiter für einen bestimmten Zeitraum jede Woche in Anspruch genommen haben. Ich habe Glättungslinien hinzugefügt, um den Trend zu zeigen.
Obwohl wir bei der Bereitstellung von Software, beispielsweise mithilfe von Containern und Amazon ECS , Abstraktionen auf höherer Ebene anstrebten, verwendeten unsere Entwickler regelmäßig immer mehr AWS-Services und abstrahierten nicht ausreichend von den Schwierigkeiten bei der Verwaltung von Systemen. In zwei Jahren hat sich die Anzahl der Dienstleistungen für 50% der Beschäftigten verdoppelt und für 20% fast verdreifacht.
Dies begrenzte das Wachstum unseres Unternehmens. Die Teams suchten Autonomie, aber wie kann man neue Leute einstellen? Wir brauchten starke Anwendungs- und Produktentwickler und Kenntnisse über das immer ausgefeilter werdende AWS-System.
Wir wollten unsere Teams erweitern und gleichzeitig die Prinzipien bewahren, mit denen wir erfolgreich waren: Autonomie, minimale Koordination und Self-Service-Infrastruktur.
Mit Kubernetes haben wir dies mit anwendungsorientierten Abstraktionen und der Fähigkeit erreicht, Cluster mit minimaler Teamkoordination zu verwalten und zu konfigurieren.
Anwendungsorientierte Abstraktionen
Kubernetes-Konzepte lassen sich leicht mit der Sprache des Anwendungsentwicklers abgleichen. Angenommen, Sie verwalten Anwendungsversionen als Bereitstellung . Sie können mehrere Replikate hinter dem Dienst ausführen und sie über Ingress HTTP zuordnen . Über Benutzerressourcen können Sie diese Sprache je nach Bedarf erweitern und spezialisieren.
Teams arbeiten effizienter mit diesen Abstraktionen. Grundsätzlich enthält dieses Beispiel alles, was Sie zum Bereitstellen und Ausführen einer Webanwendung benötigen. Der Rest ist Kubernetes.
Im Bild mit dem Eisberg befinden sich diese Konzepte auf Wasserspiegel und kombinieren die Aufgaben des Entwicklers von oben mit der Plattform unten. Das Cluster-Management-Team kann einfache und unbedeutende Entscheidungen treffen (über die Verwaltung von Metriken, die Protokollierung usw.) und gleichzeitig mit den Entwicklern über Wasser dieselbe Sprache sprechen.
Im Jahr 2010 hatte uSwitch traditionelle Teams für die Wartung eines monolithischen Systems, und zuletzt hatten wir eine IT-Abteilung, die unser AWS-Konto teilweise verwaltete. Es scheint mir, dass das Fehlen gemeinsamer Konzepte die Arbeit dieses Teams ernsthaft behinderte.
Versuchen Sie, etwas Nützliches zu sagen, wenn Ihr Vokabular, Ihre Load Balancer und Ihre Subnetze nur EC2-Instanzen enthalten. Es war schwierig oder sogar unmöglich, das Wesentliche der Anwendung zu beschreiben. Es könnte sich um ein Debian-Paket, die Bereitstellung über Capistrano usw. handeln. Wir konnten die Anwendung nicht in einer allen gemeinsamen Sprache beschreiben.
Anfang der 2000er Jahre arbeitete ich bei ThoughtWorks in London. Beim Interview wurde mir geraten, Eric Evans 'Problemorientiertes Entwerfen zu lesen. Auf dem Heimweg kaufte ich ein Buch und begann im Zug zu lesen. Seitdem erinnere ich mich in fast jedem Projekt und System an sie.
Eines der Hauptkonzepte des Buches ist eine einzige Sprache, in der verschiedene Teams kommunizieren. Kubernetes bietet Entwicklern und Infrastrukturwartungsteams eine einheitliche Sprache, und dies ist einer der Hauptvorteile. Darüber hinaus kann es um weitere Themenbereiche und Geschäftsbereiche erweitert und ergänzt werden.
Die Kommunikation in einer gemeinsamen Sprache ist produktiver, aber wir müssen die Interaktion zwischen den Teams so weit wie möglich einschränken.
Notwendiges Minimum an Interaktion
Die Autoren von Accelerate heben die Merkmale einer lose gekoppelten Architektur hervor, mit der IT-Teams effizienter arbeiten:
Im Jahr 2017 hing der Erfolg der kontinuierlichen Lieferung davon ab, ob das Team:
Ändern Sie die Struktur Ihres Systems ernsthaft ohne die Erlaubnis der Verwaltung.
Ändern Sie ernsthaft die Struktur Ihres Systems, ohne darauf zu warten, dass andere Teams ihre ändern, und ohne unnötige Arbeit für andere Teams zu verursachen.
Führen Sie ihre Aufgaben aus, ohne ihre Arbeit mit anderen Teams zu kommunizieren oder zu koordinieren.
Bereitstellen und Freigeben eines Produkts oder einer Dienstleistung bei Bedarf, unabhängig von anderen damit verbundenen Diensten.
Führen Sie die meisten Tests bei Bedarf ohne integrierte Testumgebung durch.
Wir brauchten zentralisierte Software-Multi-Tenant-Cluster für alle Teams, wollten aber gleichzeitig diese Eigenschaften beibehalten. Wir haben das Ideal noch nicht erreicht, aber wir versuchen so gut wir können:
- Wir haben mehrere Arbeitscluster, und die Teams selbst entscheiden, wo die Anwendung ausgeführt werden soll. Wir verwenden noch keinen Verbund (wir warten auf AWS-Unterstützung), aber wir haben Envoy für den Lastausgleich auf Ingress- Balancern in verschiedenen Clustern. Wir automatisieren die meisten dieser Aufgaben mithilfe der Pipeline für die kontinuierliche Bereitstellung (wir haben Drone ) und anderer AWS-Services.
- Alle Cluster haben den gleichen Namespace . Etwa eine für jedes Team.
- Wir steuern den Zugriff auf Namespaces über RBAC (rollenbasierte Zugriffskontrolle). Zur Authentifizierung und Autorisierung verwenden wir die Corporate Identity in Active Directory.
- Cluster werden automatisch skaliert und wir bemühen uns, die Startzeit des Knotens zu optimieren. Es dauert immer noch ein paar Minuten, aber im Allgemeinen verzichten wir auch bei großen Arbeitslasten auf Koordination.
- Anwendungen werden automatisch basierend auf Metriken auf Anwendungsebene von Prometheus skaliert. Entwicklungsteams steuern die automatische Skalierung ihrer Anwendung anhand von Abfragemetriken pro Sekunde, Vorgängen pro Sekunde usw. Dank der automatischen Skalierung des Clusters bereitet das System Knoten vor, wenn die Nachfrage die Funktionen des aktuellen Clusters überschreitet.
- Wir haben Go mit einem Befehlszeilentool namens u geschrieben , das die Befehlsauthentifizierung in Kubernetes standardisiert, Vault verwendet , Anforderungen für temporäre AWS-Anmeldeinformationen anfordert und so weiter.
Ich bin mir nicht sicher, ob wir mit Kubernetes mehr Autonomie haben, aber es blieb definitiv auf einem hohen Niveau, und gleichzeitig haben wir einige Probleme beseitigt.
Der Wechsel zu Kubernetes war schnell. Das Diagramm zeigt die Gesamtzahl der Namespaces (ungefähr gleich der Anzahl der Befehle) in unseren Arbeitsclustern. Der erste erschien im Februar 2017.
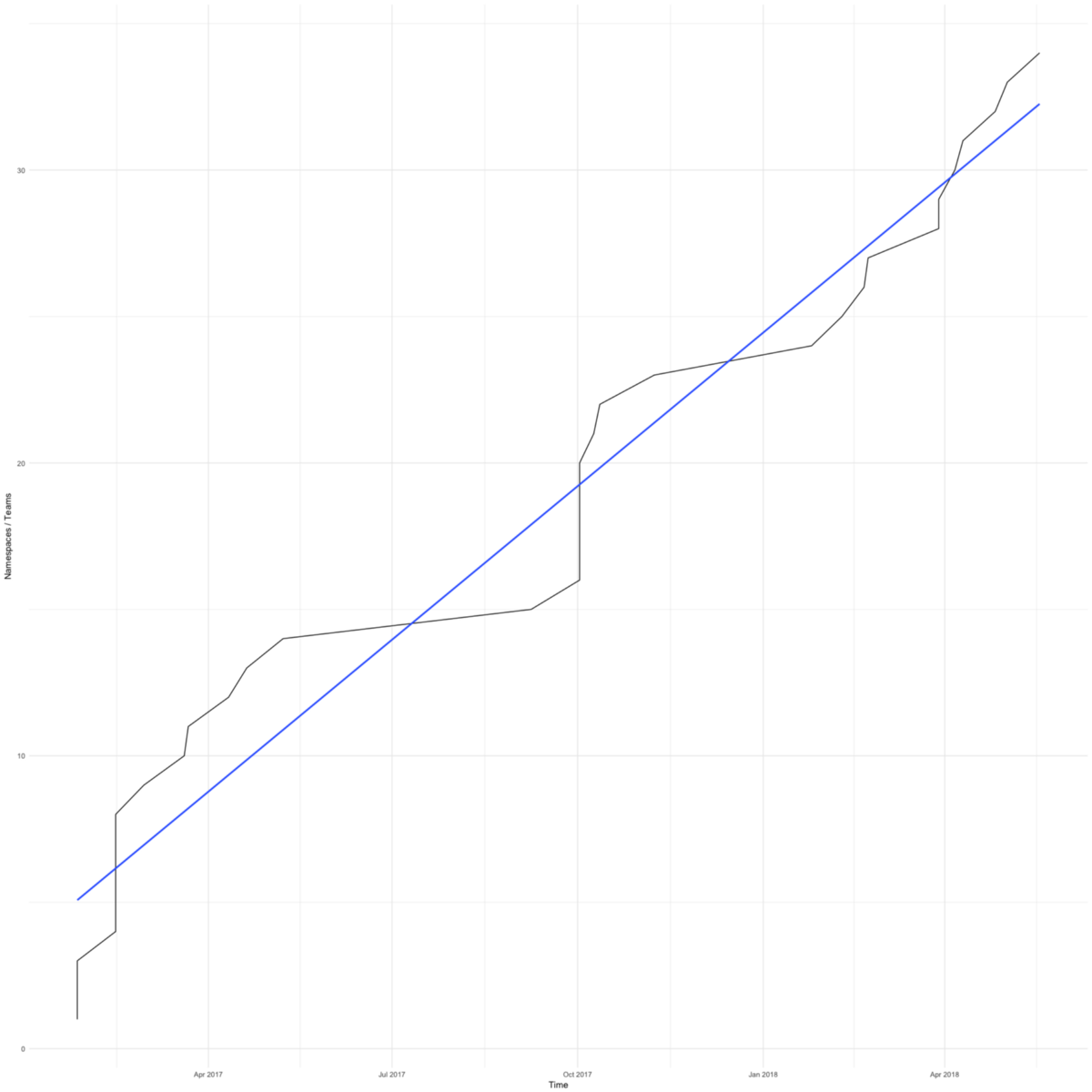
Wir hatten Gründe, uns zu beeilen - wir wollten die kleinen Teams, die sich auf ihr Produkt konzentrieren, vor Sorgen um die Infrastruktur bewahren.
Das erste Team erklärte sich bereit, zu Kubernetes zu wechseln, wenn der Anwendungsserver aufgrund falscher Logrotate-Einstellungen keinen Speicherplatz mehr hatte. Der Übergang dauerte nur wenige Tage, und sie machten sich wieder an die Arbeit.
Vor kurzem haben Teams auf Kubetnetes umgestellt, um die Tools zu verbessern. Kubernetes-Cluster vereinfachen die Integration mit Hashicorp Vault , Google Cloud Trace und ähnlichen Tools. Alle unsere Teams erhalten noch effektivere Funktionen.
Ich habe bereits ein Diagramm mit Perzentilen der Anzahl der Dienste gezeigt, die unsere Mitarbeiter von Ende 2014 bis 2017 jede Woche in Anspruch genommen haben. Und hier ist eine Fortsetzung dieses Diagramms bis heute.
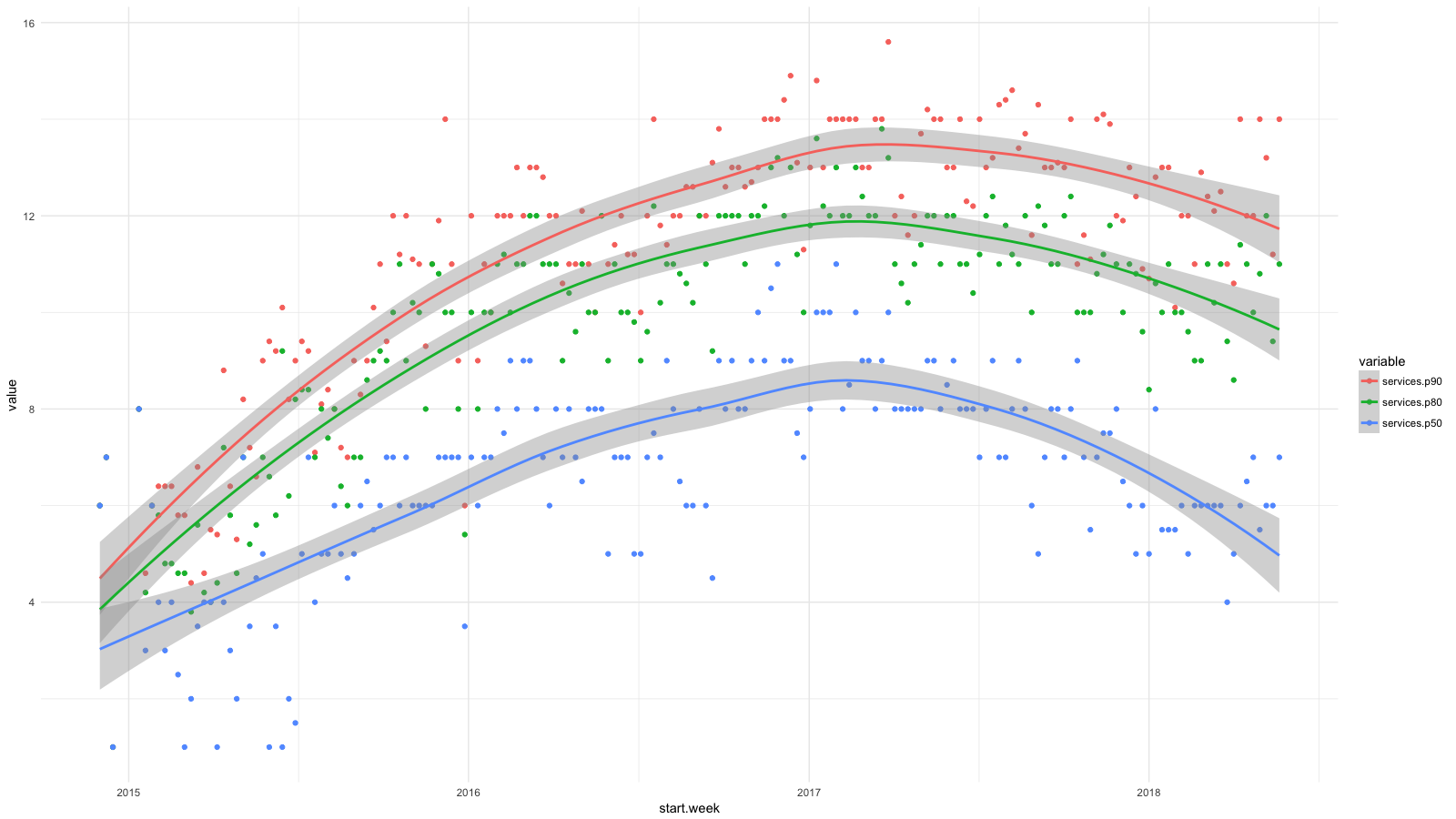
Wir haben Fortschritte bei der Verwaltung des komplexen AWS-Frameworks erzielt. Ich bin froh, dass jetzt die Hälfte der Mitarbeiter das Gleiche tut wie Anfang 2015. Wir haben 4-6 Mitarbeiter im Cloud-Computing-Team, etwa 10% der Gesamtzahl - es ist nicht verwunderlich, dass sich das 90. Perzentil fast nicht bewegt hat. Aber ich hoffe auch hier auf Fortschritte.
Abschließend werde ich darüber sprechen, wie sich unser Entwicklungszyklus verändert hat, und noch einmal an das kürzlich gelesene Accelerate-Buch erinnern.
Das Buch erwähnt zwei Lean-Entwicklungsmetriken: Vorlaufzeit und Paketgröße. Die Vorlaufzeit wird von der Anfrage bis zur Lieferung der fertigen Lösung berücksichtigt. Die Paketgröße ist der Arbeitsaufwand. Je kleiner die Packungsgröße, desto effizienter die Arbeit:
Je kleiner das Paket, desto kürzer der Produktionszyklus, weniger Prozessvariabilität, weniger Risiken, Kosten und Kosten, wir erhalten schneller Feedback, arbeiten effizienter, wir haben mehr Motivation, wir versuchen schneller fertig zu werden und verschieben die Lieferung seltener.
Das Buch schlägt vor, die Größe von Paketen anhand der Bereitstellungshäufigkeit zu messen. Je häufiger die Bereitstellung erfolgt, desto kleiner sind die Pakete.
Wir haben Daten für einige Bereitstellungen. Die Daten sind nicht ganz korrekt - einige Teams senden Releases direkt an den Hauptzweig des Repositorys, andere verwenden andere Mechanismen. Dies schließt nicht alle Anträge ein, aber Daten für 12 Monate können als Richtwerte angesehen werden.
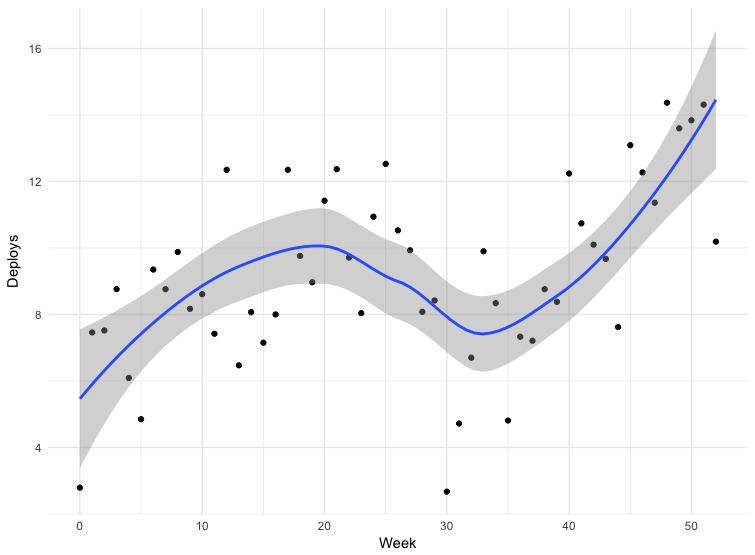
Das Scheitern in der dreißigsten Woche ist Weihnachten. Im Übrigen nimmt die Bereitstellungshäufigkeit zu, was bedeutet, dass die Paketgröße abnimmt. Von März bis Mai 2018 hat sich die Häufigkeit der Veröffentlichungen fast verdoppelt, und in letzter Zeit stellen wir manchmal mehr als hundert Ausgaben pro Tag her.
Der Wechsel zu Kubernetes ist nur ein Teil unserer Strategie zur Standardisierung, Automatisierung und Verbesserung von Tools. Höchstwahrscheinlich haben all diese Faktoren die Häufigkeit der Freisetzungen beeinflusst.
Accelerate spricht auch über die Beziehung zwischen der Bereitstellungshäufigkeit und der Anzahl der Mitarbeiter und darüber, wie schnell ein Unternehmen arbeiten kann, wenn mehr Mitarbeiter eingestellt werden. Die Autoren betonen die Grenzen verwandter Architekturen und Teams:
Es wird traditionell angenommen, dass die Erweiterung eines Teams die Gesamtproduktivität erhöht, aber die Produktivität einzelner Entwickler verringert.
Wenn wir dieselben Daten zur Häufigkeit von Bereitstellungen verwenden und ein Diagramm der Abhängigkeit von der Anzahl der Benutzer erstellen, können wir sehen, dass wir die Häufigkeit von Releases erhöhen können, selbst wenn wir mehr Mitarbeiter haben.

Am Anfang des Artikels erwähnte ich das Buch Factfulness (das unseren CTO inspirierte). Der Übergang zu Kubernetes ist für unsere Entwickler zur bedeutendsten und schnellsten Konvergenz der Technologie geworden. Wir bewegen uns in kleinen Schritten, und es ist leicht zu bemerken, wie sehr sich alles zum Besseren verändert hat. Es ist gut, dass wir Daten haben, und sie zeigen, dass wir erreicht haben, was wir wollen - unsere Mitarbeiter sind an ihrem Produkt beteiligt und treffen wichtige Entscheidungen auf ihrem Gebiet.
Früher war es gut für uns. Wir hatten Microservices, AWS, gut etablierte Teams für Produkte, Entwickler, die für ihre Dienstleistungen in der Produktion verantwortlich waren, lose gekoppelte Teams und Architektur. Ich habe 2012 in dem Bericht „Unser Zeitalter der Aufklärung“ („Unser Zeitalter der Aufklärung“) auf einer Konferenz darüber gesprochen. Der Perfektion sind jedoch keine Grenzen gesetzt.
Am Ende möchte ich ein anderes Buch zitieren - Scale . Ich habe kürzlich damit begonnen und es gibt ein interessantes Fragment zum Energieverbrauch in komplexen Systemen:
Um Ordnung und Struktur in einem sich entwickelnden System aufrechtzuerhalten, ist ein ständiger Energiezufluss erforderlich, der zu Störungen führt. Um das Leben zu erhalten, müssen wir daher die ganze Zeit essen, um die unvermeidliche Entropie zu besiegen.
Wir bekämpfen die Entropie, indem wir mehr Energie für Wachstum, Innovation, Wartung und Reparatur bereitstellen, was mit zunehmendem Alter des Systems schwieriger wird. Dieser Kampf ist die Grundlage für ernsthafte Diskussionen über Alterung, Sterblichkeit, Nachhaltigkeit und Selbstversorgung eines Systems, sei es eines lebenden Organismus , Unternehmen oder Gesellschaft.
Ich denke, Sie können hier IT-Systeme hinzufügen. Ich hoffe, dass unsere letzten Bemühungen die Entropie auch für eine Weile aufrechterhalten werden.