Hallo, Wachen. In dem heutigen Beitrag geht es darum, wie Sie sich nicht in der Wildnis der vielfältigen Möglichkeiten verlieren können, TensorFlow für maschinelles Lernen zu verwenden und Ihr Ziel zu erreichen. Der Artikel ist so konzipiert, dass der Leser die Grundlagen der Prinzipien des maschinellen Lernens kennt, aber noch nicht versucht hat, dies mit eigenen Händen zu tun. Als Ergebnis erhalten wir eine funktionierende Demo für Android, die etwas mit ziemlich hoher Genauigkeit erkennt. Aber das Wichtigste zuerst.

Nachdem man sich die neuesten Materialien angesehen hatte, entschied man sich für Tensorflow , das jetzt an Dynamik gewinnt, und Artikel in Englisch und Russisch scheinen genug zu sein, um nicht in alles einzudringen und herauszufinden, was was ist.
Verbringen Sie zwei Wochen, studieren Sie Artikel und zahlreiche Ex-Proben im Büro. Ich habe festgestellt, dass ich nichts verstanden habe. Zu viele Informationen und Optionen zur Verwendung von Tensorflow. Mein Kopf ist bereits geschwollen davon, wie viel sie unterschiedliche Lösungen bieten und was ich damit anfangen soll, wie es für meine Aufgabe gilt.

Dann habe ich beschlossen, alles auszuprobieren, von den einfachsten und am besten vorgefertigten Optionen (bei denen ich eine Abhängigkeit in Gradle registrieren und ein paar Codezeilen hinzufügen musste) bis zu komplexeren Optionen (bei denen ich selbst Diagrammmodelle erstellen und trainieren und lernen musste, wie man sie in einem Mobiltelefon verwendet Anwendung).
Am Ende musste ich eine komplizierte Version verwenden, auf die weiter unten näher eingegangen wird. In der Zwischenzeit habe ich für Sie eine Liste einfacherer Optionen zusammengestellt, die gleichermaßen effektiv sind. Nur jede Option entspricht ihrem Zweck.

Die einfachste Lösung - ein paar Codezeilen, die Sie verwenden können:
- Texterkennung (Text, lateinische Zeichen)
- Gesichtserkennung (Gesichter, Emotionen)
- Barcode-Scannen (Barcode, QR-Code)
- Bildbeschriftung (eine begrenzte Anzahl von Objekttypen im Bild)
- Wahrzeichenerkennung (Sehenswürdigkeiten)
Es ist etwas komplizierter. Mit dieser Lösung können Sie auch Ihr eigenes TensorFlow Lite-Modell verwenden. Die Konvertierung in dieses Format verursachte jedoch Schwierigkeiten, sodass dieses Element nicht ausprobiert wurde.
Wie die Schöpfer dieses Nachwuchses schreiben, können die meisten Aufgaben mit diesen Entwicklungen gelöst werden. Wenn dies jedoch nicht für Ihre Aufgabe gilt, müssen Sie benutzerdefinierte Modelle verwenden.

Ein sehr praktisches Tool zum Erstellen und Trainieren Ihrer benutzerdefinierten Modelle mithilfe von Bildern.
Von den Profis - es gibt eine kostenlose Version, mit der Sie ein Projekt behalten können.
Of the Cons - Die kostenlose Version begrenzt die Anzahl der "eingehenden" Bilder auf 3.000. Es reicht aus, ein mittelmäßiges Netzwerk von Genauigkeit aufzubauen. Für genauere Aufgaben benötigen Sie mehr.
Der Benutzer muss lediglich markierte Bilder hinzufügen (z. B. Bild1 ist "Waschbär", Bild2 ist "Sonne"), das Diagramm trainieren und für die zukünftige Verwendung exportieren.
Fürsorge Microsoft bietet sogar ein eigenes Beispiel an , mit dem Sie Ihr empfangenes Diagramm ausprobieren können.
Für diejenigen, die sich bereits im Subjekt befinden, wird der Graph bereits im eingefrorenen Zustand erzeugt, d. H. Sie müssen nichts damit tun / konvertieren.
Diese Lösung ist gut, wenn Sie eine große Stichprobe und (Aufmerksamkeits-) VIELE verschiedene Klassen im Training haben. Weil Andernfalls wird es in der Praxis viele falsche Definitionen geben. Sie haben zum Beispiel Waschbären und Sonnen trainiert, und wenn sich eine Person am Eingang befindet, kann sie mit gleicher Wahrscheinlichkeit von einem System wie dem einen oder anderen definiert werden. Obwohl in der Tat - weder der eine noch der andere.
3. Manuelles Erstellen eines Modells

Wenn Sie das Modell für die Bilderkennung selbst optimieren müssen, kommen komplexere Manipulationen mit der Eingabebildauswahl ins Spiel.
Zum Beispiel möchten wir keine Einschränkungen für das Volumen der Eingabestichprobe haben (wie im vorherigen Absatz), oder wir möchten das Modell genauer trainieren, indem wir die Anzahl der Epochen und andere Trainingsparameter selbst einstellen.
Bei diesem Ansatz gibt es mehrere Beispiele von Tensorflow, die die Prozedur und das Endergebnis beschreiben.
Hier einige Beispiele:
Es enthält ein Beispiel für die Erstellung eines Klassifikators für Farbtypen basierend auf der geöffneten ImageNet-Datenbank mit Bildern. Bereiten Sie Bilder vor und trainieren Sie das Modell. Es wird auch ein wenig erwähnt, wie Sie mit einem ziemlich interessanten Werkzeug arbeiten können - TensorBoard. Von seinen einfachsten Funktionen zeigt es auf vielfältige Weise die Struktur Ihres fertigen Modells sowie den Lernprozess.
Kodlab Tensorflow for Poets 2 - Fortsetzung der Arbeit mit dem Farbklassifikator. Es zeigt, wie Sie die Anwendung auf Android ausführen können, wenn Sie über die Grafikdateien und deren Beschriftungen verfügen (die im vorherigen Codelab erhalten wurden). Einer der Punkte des Codelabs ist die Konvertierung vom "üblichen" Grafikformat ".pb" in das Tensorflow Lite-Format (was einige Dateioptimierungen zur Reduzierung der endgültigen Grafikdateigröße beinhaltet, da mobile Geräte dies erfordern).
Handschrifterkennung MNIST .
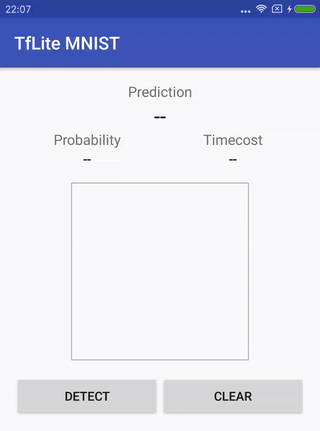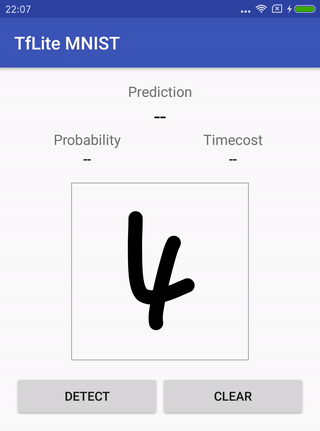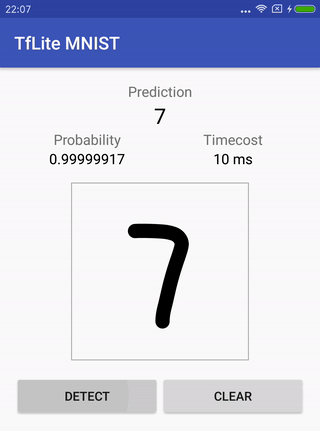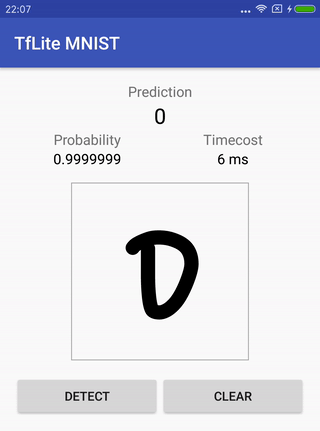
Die Rübe enthält das Originalmodell (das bereits für diese Aufgabe vorbereitet wurde), Anweisungen zum Trainieren, Konvertieren und zum Ausführen eines Projekts für Android am Ende, um zu überprüfen, wie alles funktioniert
Anhand dieser Beispiele können Sie herausfinden, wie Sie mit benutzerdefinierten Modellen in Tensorflow arbeiten und versuchen, entweder eigene Modelle zu erstellen oder eines der vorab trainierten Modelle zu verwenden, die auf einem Github zusammengebaut sind:
Modelle von Tensorflow
Apropos "vorgeübte" Modelle. Interessante Nuancen bei der Verwendung dieser:
- Ihre Struktur ist bereits auf eine bestimmte Aufgabe vorbereitet.
- Sie sind bereits in großen Stichproben ausgebildet.
Wenn Ihre Probe nicht ausreichend gefüllt ist, können Sie daher ein vorab trainiertes Modell verwenden, das Ihrem Aufgabenbereich nahe kommt. Wenn Sie dieses Modell verwenden und Ihre eigenen Trainingsregeln hinzufügen, erhalten Sie ein besseres Ergebnis, als wenn Sie versuchen würden, das Modell von Grund auf neu zu trainieren.
4. Objekterkennungs-API + manuelle Modellerstellung
Alle vorhergehenden Absätze ergaben jedoch nicht das gewünschte Ergebnis. Von Anfang an war es schwierig zu verstehen, was mit welchem Ansatz getan werden muss. Dann wurde ein cooler Artikel über die Objekterkennungs-API gefunden, in dem beschrieben wird, wie mehrere Kategorien auf einem Bild sowie mehrere Instanzen derselben Kategorie gefunden werden. Während der Arbeit an diesem Beispiel erwiesen sich Quellartikel und Video-Tutorials zum Erkennen benutzerdefinierter Objekte als praktischer (Links finden Sie am Ende).
Die Arbeit wäre jedoch ohne einen Artikel über die Pikachu-Erkennung nicht abgeschlossen worden - denn dort wurde auf eine sehr wichtige Nuance hingewiesen, die aus irgendeinem Grund in keinem Leitfaden oder Beispiel erwähnt wird. Und ohne sie wäre die ganze geleistete Arbeit vergebens.
Nun also endlich darüber, was noch zu tun war und was auf dem Weg nach draußen passiert ist.
- Zunächst das Mehl der Tensorflow-Installation. Wer kann es nicht installieren oder die Standardskripte zum Erstellen und Trainieren eines Modells verwenden? Seien Sie einfach geduldig und googeln Sie. Fast jedes Problem wurde bereits in Problemen mit Githib oder Stackoverflow geschrieben.
Gemäß den Anweisungen zur Objekterkennung müssen wir vor dem Training des Modells ein Eingabemuster vorbereiten. In diesen Artikeln wird detailliert beschrieben, wie dies mit einem praktischen Tool - labelImg - durchgeführt wird. Die einzige Schwierigkeit besteht darin, eine sehr lange und sorgfältige Arbeit zu leisten, um die Grenzen der Objekte hervorzuheben, die wir benötigen. In diesem Fall Stempel auf Bilder von Dokumenten.
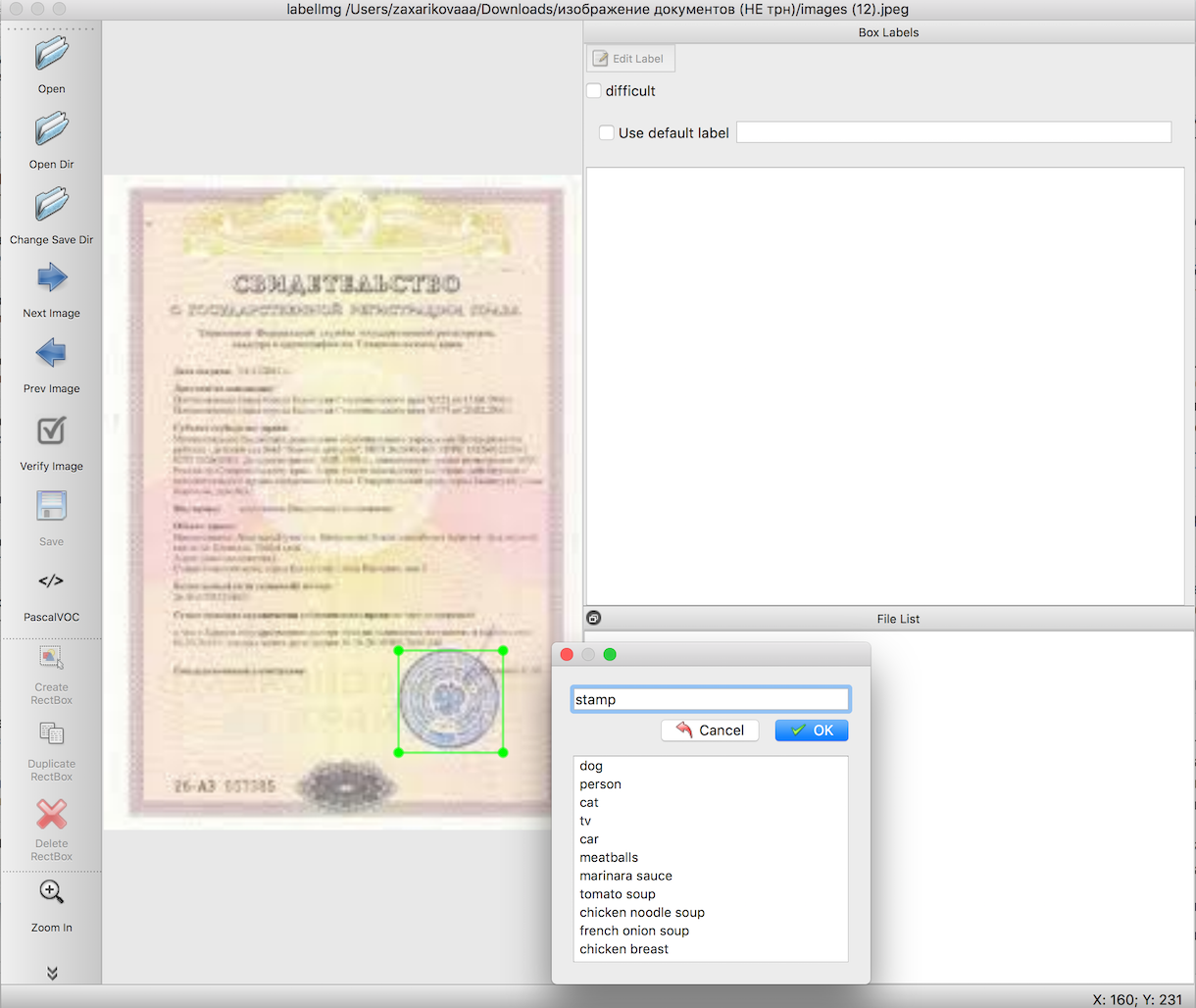
Im nächsten Schritt exportieren wir mithilfe von vorgefertigten Skripten die Daten aus Schritt 2 zuerst in CSV-Dateien und dann in TFRecords - das Tensorflow-Eingabedatenformat. Hier sollten keine Schwierigkeiten auftreten.
Die Auswahl eines vorab trainierten Modells, auf dessen Grundlage wir den Graphen vorab trainieren, sowie das Training selbst. Hier kann die größte Anzahl unbekannter Fehler auftreten, deren Ursache darin besteht, dass für die Arbeit erforderliche Pakete deinstalliert (oder schief installiert) werden. Aber Sie werden Erfolg haben, nicht verzweifeln, das Ergebnis ist es wert.

Exportieren Sie die nach dem Training erhaltene Datei in das Format 'pb'. Wählen Sie einfach die letzte Datei 'ckpt' aus und exportieren Sie sie.
Ausführen eines Beispiels für die Arbeit unter Android.
Herunterladen der offiziellen Objekterkennungsprobe vom Tensorflow-Github -
TF Detect . Fügen Sie dort Ihr Modell und Ihre Datei mit Beschriftungen ein. Aber. Nichts wird funktionieren.

Hier passierte seltsamerweise der größte Knebel in der ganzen Arbeit - nun, die Tensorflow-Proben wollten in keiner Weise funktionieren. Alles ist gefallen. Nur der mächtige Pikachu mit seinem Artikel hat es geschafft, alles zum Laufen zu bringen.
Die erste Zeile in der Datei labels.txt muss die Aufschrift "???" sein, weil Standardmäßig beginnen in der Objekterkennungs-API die ID-Nummern von Objekten nicht wie gewohnt mit 0, sondern mit 1. Aufgrund der Tatsache, dass die Nullklasse reserviert ist, sollten magische Fragen angegeben werden. Das heißt, Ihre Tag-Datei sieht ungefähr so aus:
??? stamp
Und dann - führen Sie die Probe aus und sehen Sie die Erkennung von Objekten und den Grad des Vertrauens, mit dem sie empfangen wurden.
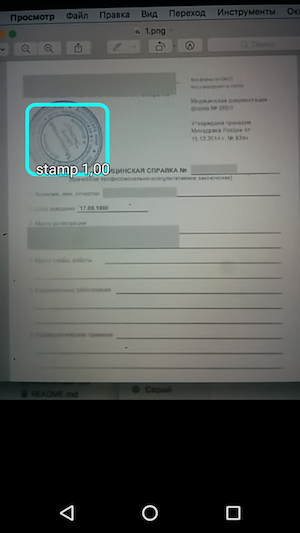
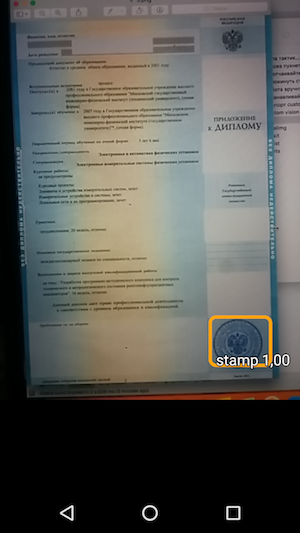
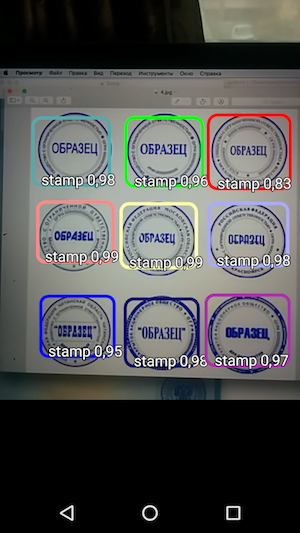
Das Ergebnis ist somit eine einfache Anwendung, die beim Bewegen des Mauszeigers über die Kamera die Stempelgrenzen auf dem Dokument erkennt und zusammen mit der Erkennungsgenauigkeit anzeigt.
Und wenn wir die Zeit ausschließen, die für die Suche nach dem richtigen Ansatz und den Versuch, ihn zu starten, aufgewendet wurde, stellte sich heraus, dass die Arbeit insgesamt ziemlich schnell und wirklich nicht kompliziert war. Sie müssen nur die Nuancen kennen, bevor Sie mit der Arbeit beginnen.
Bereits als zusätzlichen Abschnitt (hier können Sie den Artikel bereits schließen, wenn Sie keine Informationen mehr haben) möchte ich ein paar Life-Hacks schreiben, die bei der Arbeit mit all dem geholfen haben.
Sehr oft funktionierten Tensorflow-Skripte nicht, weil sie aus den falschen Verzeichnissen ausgeführt wurden. Darüber hinaus war es auf verschiedenen PCs anders: Jemand musste für die Arbeit aus dem tensroflowmodels/models/research , und jemand tensroflowmodels/models/research/object-detection tiefere Ebene aus dem tensroflowmodels/models/research/object-detection
Denken Sie daran, dass Sie für jedes geöffnete Terminal den Pfad mit dem Befehl erneut exportieren müssen
export PYTHONPATH=/ /tensroflowmodels/models/research/slim:$PYTHONPATH
Wenn Sie kein eigenes Diagramm verwenden und Informationen dazu erhalten möchten (z. B. " input_node_name ", das in Zukunft bei der Arbeit benötigt wird), führen Sie zwei Befehle aus dem Stammordner aus:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ /frozen_inference_graph.pb"
Dabei ist " / /frozen_inference_graph.pb " der Pfad zu dem Diagramm, über das Sie Bescheid wissen möchten
Um Informationen zum Diagramm anzuzeigen, können Sie Tensorboard verwenden.
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
Hier müssen Sie den Pfad zum Diagramm ( model_dir ) und den Pfad zu den Dateien angeben, die während des Trainings empfangen wurden ( log_dir ). Öffnen Sie dann einfach localhost im Browser und beobachten Sie, was Sie interessiert.
Und der letzte Teil - über die Arbeit mit Python-Skripten in den Anweisungen der Objekterkennungs-API - ein kleines Spickzettel mit Befehlen und Tipps wurde für Sie vorbereitet.
SpickzettelExport von labelimg nach csv (aus dem Verzeichnis object_detection)
python xml_to_csv.py
Darüber hinaus sollten alle unten aufgeführten Schritte im selben Tensorflow-Ordner ausgeführt werden (" tensroflowmodels/models/research/object-detection " oder eine Ebene tensroflowmodels/models/research/object-detection - je nachdem, wie Sie vorgehen) - das ist alles Bilder der Eingabeauswahl, TFRecords und anderer Dateien müssen vor Arbeitsbeginn in dieses Verzeichnis kopiert werden.
Export von CSV nach Tfrecord
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
* Vergessen Sie nicht, die Zeilen 'train' und 'test' in den Pfaden in der Datei selbst (generate_tfrecord.py) sowie zu ändern
Der Name der erkannten Klassen in der Funktion class_text_to_int (die in der pbtxt Datei dupliziert werden muss, die Sie vor dem Training des Diagramms erstellen).
Schulung
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
** Vergessen Sie vor dem Training nicht, die Datei " training/object-detection.pbtxt " zu überprüfen - es sollten alle erkannten Klassen und die Datei " training/ssd_mobilenet_v1_coco.config " vorhanden sein - dort müssen Sie den Parameter " num_classes " auf die Anzahl Ihrer Klassen ändern.
Modell nach pb exportieren
python export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=training/pipeline.config \ --trained_checkpoint_prefix=training/model.ckpt-110 \ --output_directory=output
Vielen Dank für Ihr Interesse an diesem Thema!
Referenzen
- Originalartikel zur Objekterkennung
- Ein Video-Zyklus zum Artikel über die Erkennung von Objekten in englischer Sprache
- Der Satz von Skripten, die im Originalartikel verwendet wurden