Ich arbeite als Entwickler bei
hh.ru und möchte zu Datenbanken gehen, aber bisher sind nicht genügend Fähigkeiten vorhanden. In meiner Freizeit studiere ich daher maschinelles Lernen und versuche, praktische Probleme aus diesem Bereich zu lösen. Kürzlich haben sie mir die Aufgabe gestellt, unsere Lebensläufe zu gruppieren. In diesem Beitrag geht es darum, wie ich es mithilfe von agglomerativem hierarchischem Clustering gelöst habe. Wenn Sie nicht lesen möchten, das Ergebnis aber interessant ist, können Sie die
Demo sofort sehen.

Hintergrund
Der Arbeitsmarkt ist ständig in Dynamik, neue Berufe entstehen, andere verschwinden, und ich möchte eine relevante Kategorisierung der Lebensläufe. Der Katalog der Fachgebiete und Spezialisierungen auf hh.ru ist längst veraltet: Vieles ist damit verbunden, so dass seit langem keine Änderungen mehr vorgenommen wurden. Es wäre nützlich zu lernen, wie man diese Kategorien schmerzlos bearbeitet. Ich versuche, diese Kategorien automatisch zu identifizieren. Ich hoffe, dass dies in Zukunft zur Lösung des Problems beitragen wird.
Über den gewählten Ansatz und über Clustering
Unter Clustering verstehe ich die Kombination von Objekten mit den ähnlichsten Merkmalen in einer Gruppe. In meinem Fall wird unter dem Objekt ein Lebenslauf betrachtet, und unter den Zeichen des Objekts befinden sich die zusammenfassenden Daten: zum Beispiel die Häufigkeit des Wortes „Manager“ im Lebenslauf oder die Höhe des Gehalts. Die Ähnlichkeit von Objekten wird durch eine vorgewählte Metrik bestimmt. Im Moment können Sie es sich als eine Black Box vorstellen, die zwei Objekte am Eingang empfängt, und die Ausgabe erzeugt eine Zahl, die beispielsweise den Abstand zwischen Objekten im Vektorraum widerspiegelt: Je kleiner der Abstand, desto ähnlicher sind die Objekte.
Der Ansatz, den ich verwendet habe, kann als aufwärts agglomeratives hierarchisches Clustering bezeichnet werden. Das Ergebnis der Clusterbildung ist ein Binärbaum, in dem sich in den Blättern einzelne Elemente befinden und die Wurzel des Baums eine Sammlung aller Elemente ist. Es wird als Aszendent bezeichnet, da die Clusterbildung auf der untersten Ebene des Baums mit Blättern beginnt, wobei jedes einzelne Element als Cluster betrachtet wird.

Dann müssen Sie die beiden nächstgelegenen Cluster finden und sie zu einem neuen Cluster zusammenführen. Dieser Vorgang muss wiederholt werden, bis nur noch ein Cluster mit allen Objekten vorhanden ist. Wenn Cluster kombiniert werden, wird der Abstand zwischen ihnen aufgezeichnet. In Zukunft können diese Abstände verwendet werden, um den Ort zu bestimmen, an dem diese Abstände groß genug sind, um die ausgewählten Cluster als getrennt zu betrachten.
Die meisten Clustering-Methoden setzen voraus, dass die Anzahl der Cluster im Voraus bekannt ist, oder versuchen, Cluster unabhängig vom Algorithmus und den Parametern dieses Algorithmus unabhängig voneinander zu isolieren. Der Vorteil der hierarchischen Clusterbildung besteht darin, dass Sie versuchen können, die erforderliche Anzahl von Clustern zu ermitteln, indem Sie die Eigenschaften des resultierenden Baums untersuchen. Wählen Sie beispielsweise Teilbäume mit unterschiedlichen Abständen zwischen verschiedenen Gruppen aus. Es ist praktisch, mit der resultierenden Struktur zu arbeiten, um nach Clustern darin zu suchen. Praktischerweise wird eine solche Struktur einmal erstellt und muss bei der Suche nach der erforderlichen Anzahl von Clustern nicht neu erstellt werden.
Unter den Mängeln würde ich erwähnen, dass der Algorithmus ziemlich viel Speicherplatz beansprucht. Und anstatt eine bestimmte Klasse zuzuweisen, möchte ich die Wahrscheinlichkeit haben, dass der Lebenslauf zur Klasse gehört, um nicht die nächste Spezialität, sondern die Gesamtheit zu betrachten.
Datenerfassung und -aufbereitung
Der wichtigste Teil bei der Arbeit mit Daten ist die Vorbereitung, Auswahl und das Abrufen von Attributen. Auf der Grundlage, welche Zeichen am Ende erhalten werden, hängt es davon ab, ob sie Muster enthalten, ob diese Muster dem erwarteten Ergebnis entsprechen und ob dieses „erwartete Ergebnis“ überhaupt möglich ist. Bevor Daten einem Algorithmus für maschinelles Lernen zugeführt werden, muss eine Vorstellung von jedem Merkmal vorliegen, ob es Lücken gibt, zu welchem Attributtyp das Attribut gehört, welche Eigenschaften dieser Attributtyp hat und wie die Werteverteilung in diesem Attribut ist. Es ist auch sehr wichtig, den richtigen Algorithmus auszuwählen, mit dem die verfügbaren Daten verarbeitet werden.
Ich habe Lebensläufe erstellt, die in den letzten sechs Monaten aktualisiert wurden. Es stellte sich heraus, dass 2,7 Millionen. Aus den Daten im Lebenslauf wählte ich die einfachsten Zeichen, von denen, wie es mir schien, die Mitgliedschaft im Lebenslauf von der einen oder anderen Gruppe abhängen sollte. Mit Blick auf die Zukunft werde ich sagen, dass mich das Ergebnis des Clustering aller Lebensläufe auf einmal nicht zufriedenstellte. Daher mussten wir den Lebenslauf zunächst durch die bestehenden 28 Berufsfelder teilen.
Für jedes Merkmal habe ich die Verteilung aufgezeichnet, um eine Vorstellung davon zu bekommen, wie die Daten aussehen. Vielleicht sollten sie irgendwie konvertiert oder ganz aufgegeben werden.
Region Damit die Werte dieser Funktion miteinander verglichen werden können, habe ich jeder Region die Gesamtzahl der Lebensläufe zugewiesen, die zu dieser Region gehören, und den Logarithmus aus dieser Zahl genommen, um den Unterschied zwischen sehr großen und kleinen Städten auszugleichen.
Paul In ein Binärzeichen umgewandelt.
Geburtsdatum . In der Anzahl der Monate gezählt. Nicht jeder hat Geburtstag. Ich habe die Lücken mit den Durchschnittswerten des Alters aus der Spezialisierung gefüllt, zu der dieser Lebenslauf gehört.
Bildungsniveau . Dies ist ein kategorisches Zeichen. Ich habe es mit einem
LabelBinarizer codiert .
Der Name der Werbebuchung . Ich
bin mit ngram_range = (1,2) durch
TfidfVectorizer gefahren und habe einen
Stemmer verwendet .
Gehalt . Alle Werte in Rubel übersetzt. Ich habe die Lücken genauso ausgefüllt wie in meinem Alter. Hat den Logarithmus aus dem Wert genommen.
Arbeitszeitplan . Codierter LabelBinarizer.
Beschäftigungsquote . Ich habe es binär gemacht und es in zwei Teile geteilt: Vollzeit und alles andere.
Sprachkenntnisse . Ich habe das am häufigsten verwendete gewählt. Jede Sprache ist als separate Funktion festgelegt. Die Eigentumsstufen werden durch Zahlen von 0 bis 5 abgeglichen.
Schlüsselkompetenzen . Ich bin durch TfidfVectorizer gefahren. Als Stoppwort habe ich ein kleines Wörterbuch mit allgemeinen Fähigkeiten und Wörtern zusammengestellt, die, wie es mir schien, die Spezialität nicht beeinflussen. Alle Wörter werden durch den Stemmer geleitet. Jede Schlüsselkompetenz kann nicht nur aus einem Wort bestehen, sondern auch aus mehreren. Bei mehreren Wörtern in der Schlüsselkompetenz habe ich die Wörter sortiert und jedes Wort als separates Attribut verwendet. Diese Funktion hat sich nur im professionellen Bereich „Informationstechnologien, Internet, Telekommunikation“ bewährt, da häufig Fähigkeiten angegeben werden, die für ihre Spezialität relevant sind. In anderen Berufsfeldern habe ich es wegen der Fülle an Fähigkeiten allgemeiner Wörter nicht verwendet.
Spezialisierungen Ich habe jede der benutzerdefinierten Spezialisierungen als binäres Attribut festgelegt.
Berufserfahrung . Hat den Logarithmus der Anzahl der Monate + 1 genommen, weil es Leute ohne Berufserfahrung gibt.
Standardisierung
Infolgedessen begann jeder Lebenslauf ein Vektor von Zahlenzeichen zu sein. Der ausgewählte Clustering-Algorithmus basiert auf der Berechnung des Abstands zwischen Objekten. Wie kann bestimmt werden, wie jedes Merkmal zu dieser Entfernung beitragen soll? Zum Beispiel gibt es ein Binärzeichen - 0 und 1, und ein anderes Vorzeichen kann viele Werte von 0 bis 1000 annehmen.
Standardisierung hilft. Ich habe
StandardScaler verwendet . Er transformiert jedes Merkmal so, dass sein Durchschnittswert Null und die Standardabweichung vom Mittelwert Eins ist. Daher versuchen wir, alle Daten auf dieselbe Verteilung zu bringen - die Standardnormalen. Natürlich ist es weit davon entfernt, dass die Daten selbst die Natur einer Normalverteilung haben. Dies ist nur einer der Gründe, Diagramme der Verteilung ihrer Parameter zu erstellen und froh zu sein, dass sie wie ein Gaußscher aussehen.
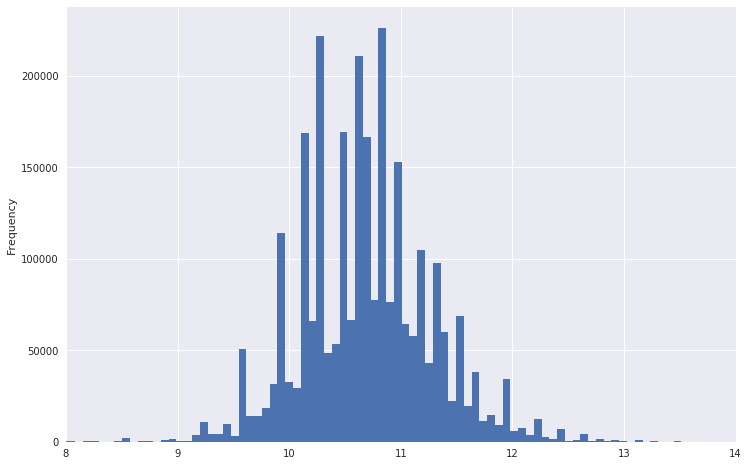
So sah beispielsweise eine Gehaltsverteilung aus.

Es ist zu sehen, dass er einen sehr schweren Schwanz hat. Um die Verteilung normaler zu gestalten, können Sie den Logarithmus aus diesen Daten entnehmen. Gleichzeitig werden die Emissionen nicht so hoch sein.
Downgrade
Jetzt ist es sinnvoll, die Daten in einen Raum kleinerer Dimension zu übertragen, damit der Clustering-Algorithmus sie in Zukunft in akzeptabler Zeit und in akzeptablem Speicher verarbeiten kann. Ich habe
TruncatedSVD verwendet ,
weil es weiß, wie man mit spärlichen Matrizen arbeitet, und am Ausgang gibt es die übliche dichte Matrix, die wir für die weitere Arbeit benötigen. Übrigens muss TruncatedSVD auch standardisierte Daten einreichen.
Gleichzeitig lohnt es sich, den resultierenden Datensatz zu visualisieren und ihn mit
t-SNE in einen zweidimensionalen Raum zu übersetzen. Dies ist ein sehr wichtiger Schritt. Wenn im resultierenden Bild keine Struktur sichtbar ist oder diese Struktur umgekehrt sehr seltsam aussieht, haben Ihre Daten entweder nicht die erforderliche Regelmäßigkeit oder es wurde irgendwo ein Fehler gemacht.
Ich habe viele sehr verdächtige Bilder bekommen, bevor alles gut lief. Zum Beispiel, als es einmal so ein schönes Bild gab:

Der Grund für die resultierenden Würmer war das Abrufen von Lebenslaufkennungen im Datensatz. Und hier ist etwas ähnlicheres wie die Wahrheit:

Clustering
Wenn mit den Daten alles in Ordnung zu sein scheint, können Sie mit dem Clustering beginnen. Ich habe das
Hierarchical Clustering- Paket von SciPy verwendet. Es ermöglicht das Clustering mithilfe der
Verknüpfungsmethode . Ich habe alle im Algorithmus vorgeschlagenen Cluster-Entfernungsmetriken ausprobiert. Das beste Ergebnis wurde mit
der Ward-Methode erzielt .
Das Hauptproblem, auf das ich gestoßen bin, ist, dass der Clustering-Algorithmus die Abstandsmatrix zwischen allen Elementen berechnet, was eine quadratische Speicherabhängigkeit der Anzahl der Elemente bedeutet. Für 2,7 Millionen Lebensläufe war ich nicht erfolgreich, weil Der erforderliche Speicherplatz beträgt Terabyte. Alle Berechnungen wurden auf einem normalen Computer durchgeführt. Ich habe nicht so viel RAM. Daher erschien es mir vernünftig, dass Sie zuerst die in der Nähe befindlichen Lebensläufe kombinieren, die Zentren der resultierenden Gruppen übernehmen und sie bereits mit dem gewünschten Algorithmus gruppieren können. Ich nahm
MiniBatchKMeans , bildete damit 30.000 Cluster und schickte sie an hierarchische Cluster. Es hat funktioniert, aber das Ergebnis war mittelmäßig. Viele der auffälligsten Lebenslaufgruppen stachen heraus, aber die Detaillierung reicht nicht aus, um Spezialisierungen auf einem guten Niveau zu finden.
Um die Qualität der erhaltenen Spezialisierungen zu verbessern, habe ich die Daten in Berufsfelder unterteilt. Es stellte sich heraus, dass Datensätze aus 400 000 Lebensläufen und weniger vorhanden waren. In diesem Moment kam mir der Gedanke, dass das Clustering einer Datenprobe besser ist als die Verwendung von zwei Algorithmen hintereinander. Also gab ich MiniBatchKMeans auf und nahm bis zu 100.000 Lebensläufe für jede Spezialisierung auf, damit die Verknüpfungsmethode sie verdauen konnte. 32 GB RAM waren nicht genug, deshalb habe ich zusätzliche 100 GB für den Swap zugewiesen. Infolgedessen liefert die Verknüpfung eine Matrix mit den Abständen zwischen den bei jedem Schritt kombinierten Clustern und der Anzahl der Elemente im resultierenden Cluster.
Als Qualitätskontrollmetrik zum Vergleichen verschiedener Versionen von Datensätzen und verschiedener Methoden zum Berechnen des Abstands zwischen Clustern verwendete der Algorithmus den aus Cophenet erhaltenen kophenetischen Korrelationskoeffizienten. Dieser Koeffizient zeigt, wie gut das resultierende Dendrogramm die Unähnlichkeit von Objekten untereinander widerspiegelt. Je näher der Wert an der Einheit liegt, desto besser.
Visualisierung
Der beste Weg, um die Qualität des Clusters zu überprüfen, war die Visualisierung. Die
Dendrogrammmethode zeichnet die resultierenden Dendrogramme, auf denen Sie Cluster nach Entfernung oder Ebene im Baum auswählen können:

Das folgende Diagramm zeigt die Abhängigkeit des Abstands zwischen Clustern von der Iterationsschrittnummer, bei der die beiden nächsten Cluster zu einem neuen kombiniert werden. Die grüne Linie zeigt, wie sich die Beschleunigung ändert - die Geschwindigkeit des Abstands zwischen den zu verbindenden Clustern.
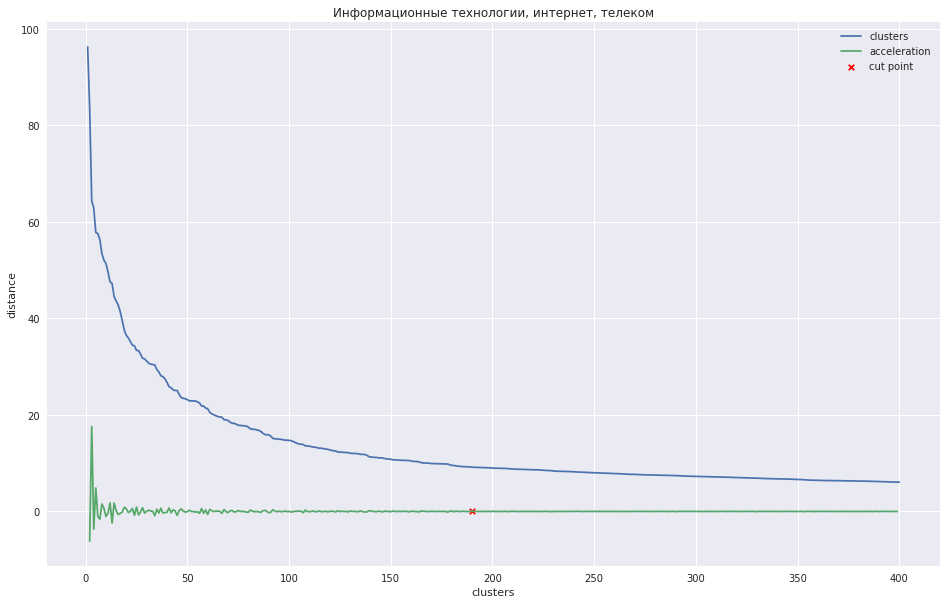
Im Fall einer kleinen Anzahl von Clustern könnte man versuchen, den Baum an dem Punkt zu beschneiden, an dem die maximale Beschleunigung, d. H. Der Abstand zu dem Zeitpunkt, zu dem die beiden Cluster kombiniert wurden, noch größer und bereits im nächsten Schritt kleiner war. In meinem Fall ist alles anders - ich habe viele Cluster, und ich schlug vor, dass es besser ist, das Dendrogramm an dem Punkt zu schneiden, an dem die Beschleunigung monotoner abnimmt, d. H. Die Abstände zwischen den Clustern auf dieser Ebene weisen nicht mehr auf eine separate Gruppe hin. In der Grafik befindet sich dieser Ort ungefähr an dem Punkt, an dem die grüne Linie aufhört zu tanzen.
Man könnte sich eine Art programmatische Methode
ausdenken , aber es stellte sich heraus, dass es schneller war, diese Stellen mit 28 Händen für 28 professionelle Domänen zu markieren und
die gewünschte Anzahl von Clustern an die
fcluster- Methode zu übergeben, die den Baum an der richtigen Stelle schneidet.
Ich habe die zuvor von t-SNE erhaltenen Daten gespeichert und die resultierenden Cluster darauf notiert. Es sieht ziemlich gut aus:

Als Ergebnis habe ich eine Weboberfläche erstellt, in der Sie die Zusammenfassung jedes Clusters, seine Position im Diagramm und einen aussagekräftigen Namen sehen können. Der Einfachheit halber habe ich den häufigsten Titel des Lebenslaufs abgeleitet - er kennzeichnet häufig den Namen des Clusters gut.
Das Ergebnis des Clusters können Sie
hier einsehen.
Ich kam zu dem Schluss, dass das System funktioniert. Obwohl die Aufteilung in Cluster unvollständig ist und einige Gruppen einander sehr ähnlich sind, könnten einige im Gegenteil in Teile unterteilt werden, aber die Haupttrends des Spezialmarktes sind deutlich sichtbar. Sie können auch sehen, wie sich neue Gruppen bilden. Das Entladen des Lebenslaufs erfolgte im Sommer, so dass zum Beispiel
Fahrer auffielen, die bei der Weltmeisterschaft arbeiten wollten . Wenn Sie lernen, Cluster von Start zu Start miteinander abzugleichen, können Sie beobachten, wie sich die Hauptbereiche der Spezialisierung im Laufe der Zeit ändern. Tatsächlich sind die Ideen zur Verbesserung von Qualität und Entwicklung noch voll. Wenn ich die richtige Motivation in mir finde, werde ich mich weiterentwickeln.
Zusätzliche Materialien
Video über agglomeratives hierarchisches Clustering aus dem Kurs über die Suche nach einer Struktur in Daten
Über Skalierung und Normalisierung von ZeichenTutorial zum hierarchischen Clustering aus der SciPy-Bibliothek, das ich als Grundlage für meine Aufgabe verwendet habe
Vergleich verschiedener Arten von Clustering am Beispiel von sklearn-Bibliotheken
Kleiner Bonus. Ich fand es für Leute interessant, wie jemand an einer Aufgabe arbeitet. Ich möchte sagen, dass ich in einigen Ausgaben während dieses Projekts gut gepumpt habe. Ich habe verschiedene Optionen ausprobiert, studiert und darüber nachgedacht, wie dieses oder jenes Ding funktioniert. Das Fehlen einer guten mathematischen Basis wurde vielerorts durch Einfallsreichtum und eine Vielzahl von Versuchen ausgeglichen. Und ich möchte das erlittene
Evernote-Blatt teilen, in dem ich mir während der Arbeit an der Aufgabe Notizen gemacht habe. Die Überlegungen darin waren nur für mich gedacht, es gibt viele Häresien und Unverständnisse, aber ich denke, das ist normal.
UPD: Ich habe Laptops mit
Datenvorbereitungs- und
Clustering- Code gepostet. Ich hatte nicht vor, den Code hochzuladen. Entschuldigen Sie die Qualität.