
Bei den Tests für den Code ist alles klar (zumindest die Tatsache, dass sie geschrieben werden müssen). Bei Konfigurationstests ist alles viel weniger offensichtlich, beginnend mit ihrer Existenz. Schreibt jemand sie? Ist es wichtig Ist es schwer Welche Ergebnisse können mit ihrer Hilfe erzielt werden?
Es stellt sich heraus, dass dies auch sehr nützlich ist. Es ist sehr einfach, damit zu beginnen, und gleichzeitig gibt es viele Nuancen beim Testen der Konfiguration. Welche - gemalt unter dem Schnitt basierend auf praktischen Erfahrungen.
Das Material basiert auf einer Abschrift eines Berichts von Ruslan- Zeremin Cheremin (einem Java-Entwickler bei der Deutschen Bank). Als nächstes kommt die Rede aus der ersten Person.Mein Name ist Ruslan, ich arbeite für die Deutsche Bank. Wir beginnen damit:

Es gibt viel Text, von weitem scheint es, dass es russisch ist. Das stimmt aber nicht. Dies ist eine sehr alte und gefährliche Sprache. Ich habe eine Übersetzung ins einfache Russisch gemacht:
- Alle Charaktere sind erfunden
- Mit Vorsicht verwenden
- Beerdigung auf eigene Kosten
Ich werde kurz beschreiben, worüber ich heute sprechen werde. Angenommen, wir haben einen Code:

Das heißt, anfangs hatten wir eine Aufgabe, wir schreiben einen Code, um sie zu lösen, und er verdient uns angeblich Geld. Wenn dieser Code aus irgendeinem Grund nicht richtig funktioniert, löst er die falsche Aufgabe und bringt uns das falsche Geld ein. Unternehmen mögen diese Art von Geld nicht - sie sehen im Jahresabschluss schlecht aus.
Daher haben wir für unseren wichtigen Code Tests:

Normalerweise dort. Jetzt hat es wahrscheinlich fast jeder. Tests bestätigen, dass der Code das richtige Problem löst und das richtige Geld verdient. Der Dienst ist jedoch nicht auf Code beschränkt, und neben dem Code gibt es auch eine Konfiguration:

Zumindest in fast allen Projekten, an denen ich teilgenommen habe, war diese Konfiguration in der einen oder anderen Form. (Ich kann mich nur an einige Fälle aus meinen frühen UI-Jahren erinnern, in denen es keine Konfigurationsdateien gab, aber alles über die UI konfiguriert wurde.) In dieser Konfiguration gibt es Ports, Adressen und Algorithmusparameter.
Warum ist die Konfiguration zum Testen wichtig?
Hier ist der Trick: Fehler in der Konfiguration beeinträchtigen die Programmausführung nicht weniger als Fehler im Code. Auch sie können dazu führen, dass der Code die falsche Aufgabe ausführt - und siehe oben.
Das Auffinden von Fehlern in der Konfiguration ist noch schwieriger als im Code, da die Konfiguration normalerweise nicht kompiliert wird. Ich habe die Eigenschaftendateien als Beispiel angeführt, im Allgemeinen gibt es verschiedene Optionen (JSON, XML, jemand speichert in YAML), aber es ist wichtig, dass nichts davon kompiliert und dementsprechend nicht überprüft wird. Wenn Sie versehentlich eine Java-Datei versiegelt haben, wird die Kompilierung höchstwahrscheinlich nicht bestanden. Ein zufälliger Tippfehler in der Eigenschaft wird niemanden erregen, er wird zur Arbeit gehen.
Und die IDE hebt den Fehler auch in der Konfiguration nicht hervor, da sie nur das primitivste über das Format (zum Beispiel) von Eigenschaftendateien weiß: dass es einen Schlüssel und einen Wert geben sollte und zwischen ihnen "gleich", ein Doppelpunkt oder ein Leerzeichen steht. Aber die Tatsache, dass der Wert eine Nummer, ein Netzwerkport oder eine Adresse sein muss - die IDE weiß nichts.
Und selbst wenn Sie die Anwendung in einer UAT oder in einer Staging-Umgebung testen, garantiert dies nichts. Da die Konfiguration in der Regel in jeder Umgebung unterschiedlich ist und Sie in der UAT nur die UAT-Konfiguration getestet haben.
Eine weitere Feinheit ist, dass selbst in der Produktion Konfigurationsfehler manchmal nicht sofort auftreten. Ein Dienst wird möglicherweise überhaupt nicht gestartet - und dies ist ein gutes Szenario. Aber es kann starten und sehr lange funktionieren - bis zu dem Moment X, in dem genau der Parameter benötigt wird, in dem der Fehler auftritt. Und hier stellen Sie fest, dass ein Dienst, der sich in letzter Zeit nicht viel geändert hat, plötzlich nicht mehr funktioniert.
Nach all dem, was ich gesagt habe, scheint es, dass das Testen von Konfigurationen ein heißes Thema sein sollte. Aber in der Praxis sieht es ungefähr so aus:
Zumindest war das bei uns der Fall - bis zu einem gewissen Punkt. Und eine der Aufgaben meines Berichts ist es, auch für Sie nicht mehr so auszusehen. Ich hoffe, dass ich Sie dazu drängen kann.
Vor drei Jahren arbeitete Andrei Satarin in unserer Deutschen Bank in meinem Team als QS-Leiter. Er brachte die Idee auf, Konfigurationen zu testen - das heißt, er hat einfach den ersten solchen Test gemacht und durchgeführt. Vor sechs Monaten hielt er beim vorherigen Heisenbug einen
Vortrag über das Testen der Konfiguration, wie er sie sieht. Ich empfehle Ihnen einen Blick darauf zu werfen, da er dort einen umfassenden Überblick über das Problem gab: sowohl von der Seite wissenschaftlicher Artikel als auch von der Erfahrung großer Unternehmen, die auf Konfigurationsfehler und deren Folgen gestoßen sind.
Mein Bericht wird enger gefasst sein - über praktische Erfahrungen. Ich werde darüber sprechen, auf welche Probleme ich als Entwickler beim Schreiben von Konfigurationstests gestoßen bin und wie ich diese Probleme gelöst habe. Meine Entscheidungen sind möglicherweise nicht die besten Entscheidungen, dies sind nicht die besten Praktiken - dies ist meine persönliche Erfahrung, ich habe versucht, keine umfassenden Verallgemeinerungen vorzunehmen.
Allgemeiner Überblick über den Bericht:
- „Was Sie vor Montagnachmittag tun können“: Einfache, nützliche Beispiele.
- "Montag, zwei Jahre später": wo und wie man es besser macht.
- Unterstützung für das Refactoring der Konfiguration: Wie erreicht man eine dichte Abdeckung? Softwarekonfigurationsmodell.
Der erste Teil ist motivierend: Ich werde die einfachsten Tests beschreiben, mit denen alles bei uns begann. Es wird eine Vielzahl von Beispielen geben. Ich hoffe, dass mindestens einer von ihnen mit Ihnen in Resonanz steht, das heißt, Sie werden ein ähnliches Problem und dessen Lösung sehen.
Die Tests selbst im ersten Teil sind einfach, sogar primitiv - aus technischer Sicht gibt es keine Raketenwissenschaft. Aber nur dass sie schnell erledigt werden können, ist besonders wertvoll. Dies ist ein so einfacher Einstieg in Konfigurationstests, und er ist wichtig, da das Schreiben dieser Tests eine psychologische Barriere darstellt. Und ich möchte zeigen, dass "Sie das können": Jetzt haben wir es gut für uns geklappt, und obwohl niemand gestorben ist, leben wir jetzt seit drei Jahren.
Im zweiten Teil geht es darum, was danach zu tun ist. Wenn Sie viele einfache Tests geschrieben haben, stellt sich die Frage nach der Unterstützung. Einige von ihnen beginnen zu fallen, Sie verstehen die Fehler, die sie angeblich hervorgehoben haben. Es stellt sich heraus, dass dies nicht immer bequem ist. Und es stellt sich die Frage, komplexere Tests zu schreiben - schließlich haben Sie bereits einfache Fälle behandelt, ich möchte etwas Interessanteres. Auch hier gibt es keine Best Practices. Ich beschreibe nur einige der Lösungen, die für uns funktioniert haben.
Im dritten Teil geht es darum, wie das Testen das Refactoring einer ziemlich komplexen und verwirrenden Konfiguration unterstützen kann. Wieder eine Fallstudie - wie wir es gemacht haben. Aus meiner Sicht ist dies ein Beispiel dafür, wie Konfigurationstests skaliert werden können, um größere Aufgaben zu lösen und nicht nur kleine Löcher zu schließen.
Teil 1. "Du kannst es so machen"
Jetzt ist es schwer zu verstehen, was der erste Konfigurationstest bei uns war. Andrei sitzt im Flur, er kann sagen, dass ich gelogen habe. Aber es scheint mir, dass alles damit begann:

Die Situation ist folgende: Wir haben n Dienste auf demselben Host, jeder von ihnen hebt seinen eigenen JMX-Server an seinem Port an und exportiert einige Überwachungs-JMXs. Ports für alle Dienste sind in der Datei konfiguriert. Die Datei nimmt jedoch mehrere Seiten ein, und es gibt viele andere Eigenschaften. Oft stellt sich heraus, dass die Ports verschiedener Dienste in Konflikt stehen. Es ist leicht, einen Fehler zu machen. Dann ist alles trivial: Einige Dienste steigen nicht, danach steigen sie nicht für diejenigen, die davon abhängig sind - Tester sind wütend.
Dieses Problem wird in mehreren Zeilen gelöst. Dieser Test, der (wie mir scheint) unser erster war, sah folgendermaßen aus:

Es ist nichts Kompliziertes: Wir gehen den Ordner durch, in dem sich die Konfigurationsdateien befinden, laden sie, analysieren sie als Eigenschaften, filtern die Werte heraus, deren Name "jmx.port" enthält, und überprüfen, ob alle Werte eindeutig sind. Es ist nicht erforderlich, Werte in Ganzzahlen umzuwandeln. Vermutlich gibt es nur Ports.
Meine erste Reaktion, als ich das sah, war gemischt:
Erster Eindruck: Was ist es in meinen schönen Unit-Tests? Warum sind wir in das Dateisystem geklettert?
Und dann kam die Überraschung: "Was, könnte das sein?"
Ich spreche darüber, weil es eine Art psychologische Barriere zu geben scheint, die es schwierig macht, solche Tests zu schreiben. Seitdem sind drei Jahre vergangen, das Projekt ist voll von solchen Tests, aber ich sehe oft, dass meine Kollegen, die auf einen Fehler in der Konfiguration stoßen, keine Tests darauf schreiben. Für den Code ist jeder bereits daran gewöhnt, Regressionstests zu schreiben, damit der gefundene Fehler nicht mehr reproduziert wird. Aber sie tun es nicht für die Konfiguration, etwas stört. Es gibt eine Art psychologische Barriere, die behandelt werden muss - deshalb erwähne ich eine solche Reaktion, damit Sie sie an sich selbst erkennen, wenn sie auftritt.
Das folgende Beispiel ist fast das gleiche, aber leicht modifiziert - ich habe alle "jmx" entfernt. Dieses Mal überprüfen wir alle Eigenschaften, die als "Something-There-Port" bezeichnet werden. Sie müssen ganzzahlige Werte sein und ein gültiger Netzwerkport sein. Matcher validNetworkPort () verbirgt unseren benutzerdefinierten Hamcrest Matcher, der überprüft, ob der Wert über dem Bereich der Systemports und unter dem Bereich der kurzlebigen Ports liegt. Wir wissen, dass einige Ports auf unseren Servern bereits belegt sind. Hier ist auch die gesamte Liste dieser Ports versteckt Das ist Matcher.
Dieser Test ist immer noch sehr primitiv. Beachten Sie, dass darin kein Hinweis darauf enthalten ist, welche bestimmte Eigenschaft wir überprüfen - sie ist massiv. Ein einziger solcher Test kann 500 Eigenschaften mit dem Namen "... port" überprüfen und sicherstellen, dass sie alle Ganzzahlen im gewünschten Bereich sind, unter allen erforderlichen Bedingungen. Sobald sie geschrieben haben, ein Dutzend Zeilen - und das war's. Dies ist eine sehr praktische Funktion, da die Konfiguration ein einfaches Format hat: zwei Spalten, einen Schlüssel und einen Wert. Daher kann es so massenverarbeitet werden.
Ein weiteres Testbeispiel. Was überprüfen wir hier?

Er prüft, ob echte Passwörter nicht in die Produktion gelangen. Alle Passwörter sollten ungefähr so aussehen:

Sie können viele Tests für Eigenschaftendateien schreiben. Ich werde keine weiteren Beispiele nennen - ich möchte mich nicht wiederholen, die Idee ist sehr einfach, dann sollte alles klar sein.
... und nachdem wir genug von diesen Tests geschrieben haben, taucht eine interessante Frage auf: Was meinen wir mit Konfiguration, wo ist ihre Grenze? Wir betrachten die Eigenschaftendatei als Konfiguration, wir haben sie behandelt - und was kann noch im selben Stil behandelt werden?
Was ist eine Konfiguration zu beachten?
Es stellt sich heraus, dass das Projekt viele Textdateien enthält, die nicht kompiliert wurden - zumindest im normalen Erstellungsprozess. Sie werden in keiner Weise überprüft, bis sie auf dem Server ausgeführt werden, dh Fehler in ihnen erscheinen zu spät. Alle diese Dateien können - mit etwas Dehnung - als Konfiguration bezeichnet werden. Zumindest werden sie ungefähr gleich getestet.
Zum Beispiel haben wir ein System von SQL-Patches, die während des Bereitstellungsprozesses in die Datenbank gerollt werden.

Sie sind für SQL * Plus geschrieben. SQL * Plus ist ein Tool aus den 60er Jahren und erfordert alle möglichen seltsamen Dinge: Zum Beispiel, um sicherzustellen, dass sich das Ende der Datei in einer neuen Zeile befindet. Natürlich vergessen die Leute regelmäßig, das Ende der Linie dort zu setzen, weil sie nicht in den 60ern geboren wurden.
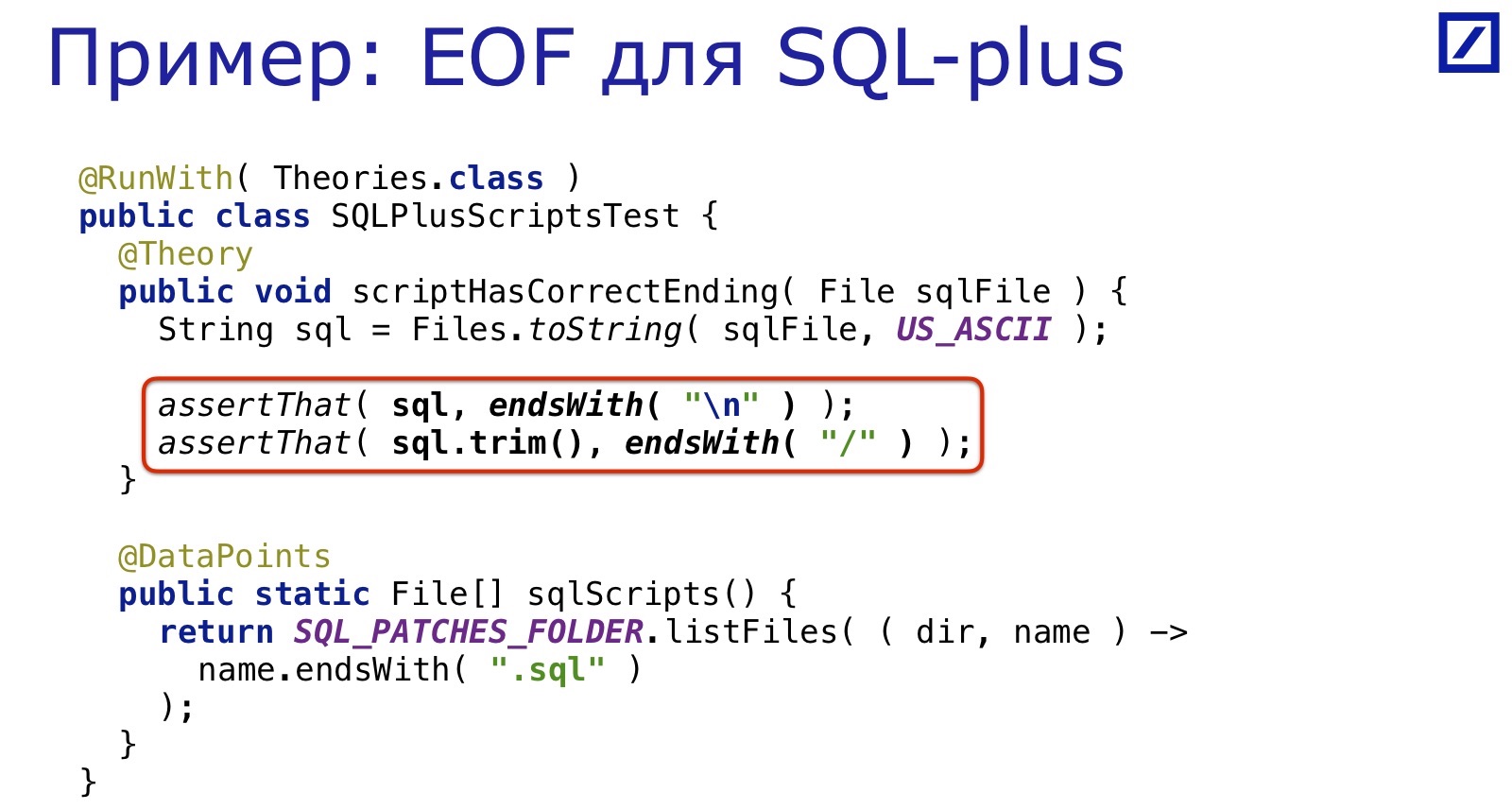
Und wieder wird es durch dasselbe Dutzend Zeilen gelöst: Wir wählen alle SQL-Dateien aus und prüfen, ob am Ende ein abschließender Schrägstrich steht. Einfach, bequem, schnell.
Ein weiteres Beispiel für "wie eine Textdatei" sind Crontabs. Unsere Crontab-Services starten und stoppen. Sie verursachen meistens zwei Fehler:
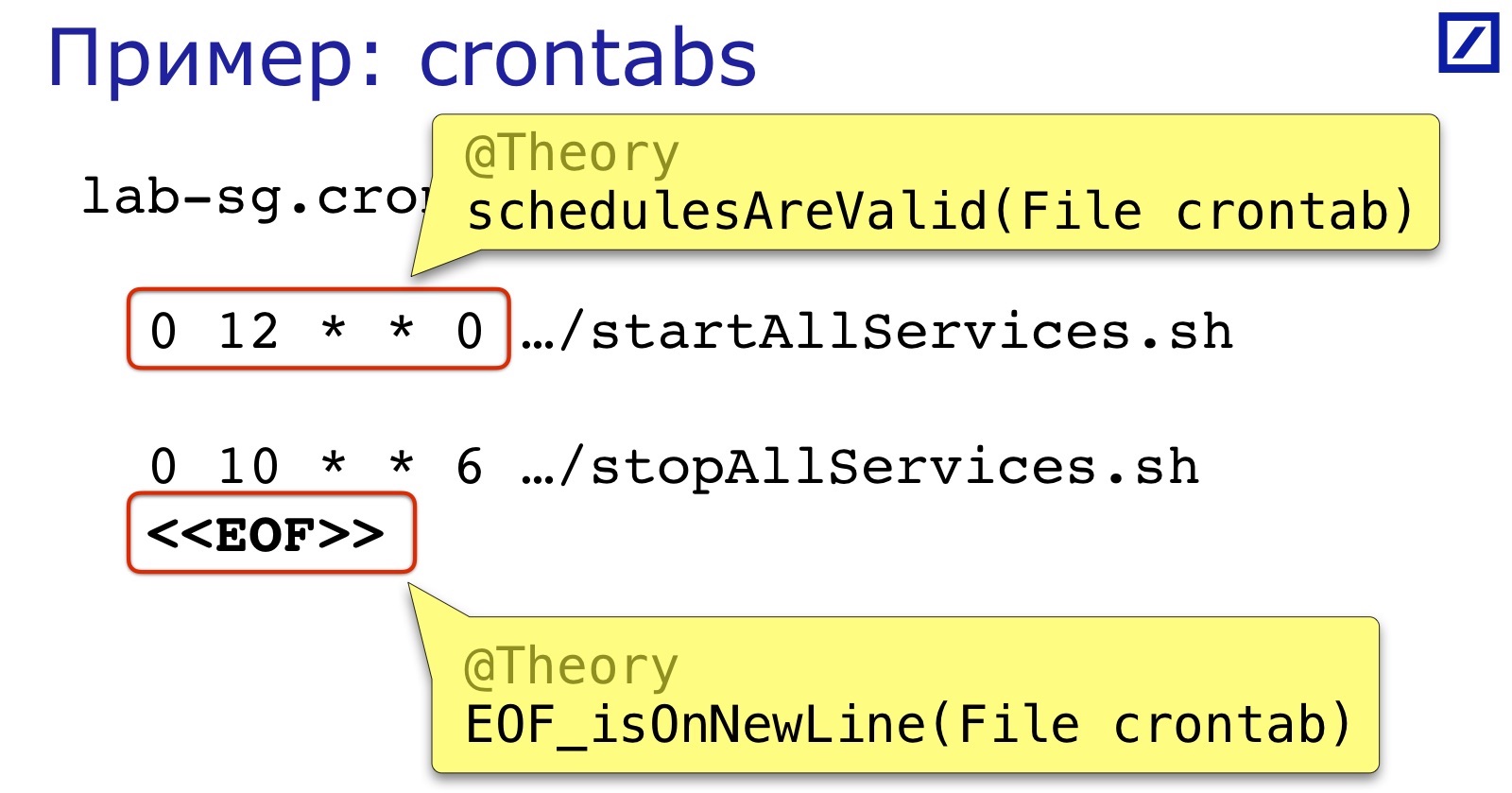
Erstens das Format des Zeitplanausdrucks. Es ist nicht so kompliziert, aber niemand überprüft es vor dem Start, so dass es einfach ist, ein zusätzliches Leerzeichen, Komma und dergleichen einzufügen.
Zweitens muss sich das Ende der Datei wie im vorherigen Beispiel in einer neuen Zeile befinden.
Und das alles ist ziemlich einfach zu überprüfen. Das Ende der Datei ist verständlich, aber um den Zeitplan zu überprüfen, finden Sie vorgefertigte Bibliotheken, die den Cron-Ausdruck analysieren. Vor dem Bericht habe ich gegoogelt: Es waren mindestens sechs. Ich habe sechs gefunden, aber im Allgemeinen kann es mehr geben. Als wir geschrieben haben, haben wir die einfachste der gefundenen genommen, da wir nicht den Inhalt des Ausdrucks überprüfen mussten, sondern nur seine syntaktische Korrektheit, damit cron ihn erfolgreich geladen hat.
Grundsätzlich können Sie mehr Schecks abwickeln - stellen Sie sicher, dass Sie am richtigen Wochentag beginnen und die Dienste nicht mitten am Arbeitstag einstellen. Dies stellte sich jedoch als nicht so nützlich für uns heraus, und wir haben uns nicht darum gekümmert.
Eine andere Idee, die großartig funktioniert, sind Shell-Skripte. Natürlich ist das Schreiben eines vollwertigen Parsers von Bash-Skripten in Java ein Vergnügen für die Mutigen. Das Fazit ist jedoch, dass eine große Anzahl dieser Skripte keine vollständige Bash ist. Ja, es gibt Bash-Skripte, bei denen der Code direkt ist, Hölle und Hölle, bei denen sie einmal im Jahr vorbeischauen und fluchend davonlaufen. Viele Bash-Skripte sind jedoch dieselben Konfigurationen. Es gibt eine Reihe von Systemvariablen und Umgebungsvariablen, die auf den gewünschten Wert eingestellt sind, wodurch andere Skripts konfiguriert werden, die diese Variablen verwenden. Und solche Variablen lassen sich leicht aus dieser Bash-Datei abrufen und etwas über sie überprüfen.

Überprüfen Sie beispielsweise, ob JAVA_HOME in jeder Umgebung installiert ist oder ob in LD_LIBRARY_PATH eine JNI-Bibliothek vorhanden ist. Irgendwie sind wir von einer Java-Version zu einer anderen gewechselt und haben den Test erweitert: Wir haben überprüft, ob JAVA_HOME für genau diese Teilmenge der Umgebung „1.8“ enthält, die wir schrittweise auf die neue Version übertragen haben.
Hier einige Beispiele. Lassen Sie mich den ersten Teil der Schlussfolgerungen zusammenfassen:
- Konfigurationstests sind zunächst verwirrend, es gibt eine psychologische Barriere. Aber nach der Überwindung gibt es viele Stellen in der Anwendung, die nicht durch Schecks abgedeckt sind und abgedeckt werden können.
- Dann werden sie leicht und fröhlich geschrieben : Es gibt viele „niedrig hängende Früchte“, die schnell große Vorteile bringen.
- Reduzieren Sie die Kosten für das Erkennen und Korrigieren von Konfigurationsfehlern. Da es sich tatsächlich um Komponententests handelt, können Sie diese bereits vor dem Festschreiben auf Ihrem Computer ausführen - dies reduziert die Rückkopplungsschleife erheblich. Viele von ihnen wären natürlich beispielsweise in der Testbereitstellungsphase getestet worden. Und viele würden nicht getestet - wenn dies eine Produktionskonfiguration ist. Und so werden sie direkt auf dem lokalen Computer überprüft.
- Sie geben eine zweite Jugend. In dem Sinne, dass man das Gefühl hat, noch viele interessante Dinge testen zu können. In der Tat ist es im Code nicht mehr so einfach zu finden, was Sie testen können.
Teil 2. Komplexere Fälle
Fahren wir mit komplexeren Tests fort. Nachdem die meisten trivialen Überprüfungen, wie die hier gezeigten, behandelt wurden, stellt sich die Frage: Ist es möglich, etwas Komplizierteres zu überprüfen?
Was bedeutet es "schwerer"? Die Tests, die ich gerade beschrieben habe, haben ungefähr die folgende Struktur:

Sie überprüfen etwas gegen eine bestimmte Datei. Das heißt, wir gehen die Dateien durch und wenden auf jede eine bestimmte Bedingungsprüfung an. Somit kann vieles überprüft werden, aber es gibt nützlichere Szenarien:
- Die UI-Anwendung stellt eine Verbindung zum Server ihrer Umgebung her.
- Alle Dienste derselben Umgebung stellen eine Verbindung zu demselben Verwaltungsserver her.
- Alle Dienste in derselben Umgebung verwenden dieselbe Datenbank.
Eine UI-Anwendung stellt beispielsweise eine Verbindung zu ihrem Umgebungsserver her. Höchstwahrscheinlich sind die Benutzeroberfläche und der Server unterschiedliche Module, wenn überhaupt keine Projekte, und sie haben unterschiedliche Konfigurationen. Es ist unwahrscheinlich, dass sie dieselben Konfigurationsdateien verwenden. Daher müssen Sie sie verknüpfen, damit alle Dienste einer Umgebung mit einem Schlüsselverwaltungsserver verbunden sind, über den Befehle verteilt werden. Auch dies sind höchstwahrscheinlich unterschiedliche Module, unterschiedliche Dienste und im Allgemeinen unterschiedliche Teams, die sie entwickeln.
Oder alle Dienste verwenden dieselbe Datenbank, dasselbe - Dienste in verschiedenen Modulen.
In der Tat gibt es ein solches Bild: Viele Dienste, jeder von ihnen hat seine eigene Struktur von Konfigurationen, Sie müssen einige von ihnen reduzieren und etwas an der Kreuzung überprüfen:

Natürlich können Sie genau das tun: Laden Sie eines herunter, das zweite, ziehen Sie irgendwo etwas heraus, kleben Sie den Testcode ein. Aber Sie können sich vorstellen, wie groß der Code sein wird und wie lesbar er sein wird. Wir haben damit angefangen, aber dann haben wir gemerkt, wie schwierig es ist. Wie kann man es besser machen?
Wenn Sie träumen, wäre es bequemer, dann träumte ich, dass der Test so aussehen würde, als würde ich ihn in menschlicher Sprache erklären:
@Theory public void eachEnvironmentIsXXX( Environment environment ) { for( Server server : environment.servers() ) { for( Service service : server.services() ) { Properties config = buildConfigFor( environment, server, service );
Für jede Umgebung ist eine Bedingung erfüllt. Um dies zu überprüfen, benötigen Sie aus der Umgebung eine Liste der Server und eine Liste der Dienste. Laden Sie dann die Konfigurationen und überprüfen Sie etwas an der Kreuzung. Dementsprechend brauche ich so etwas, ich nannte es Bereitstellungslayout.
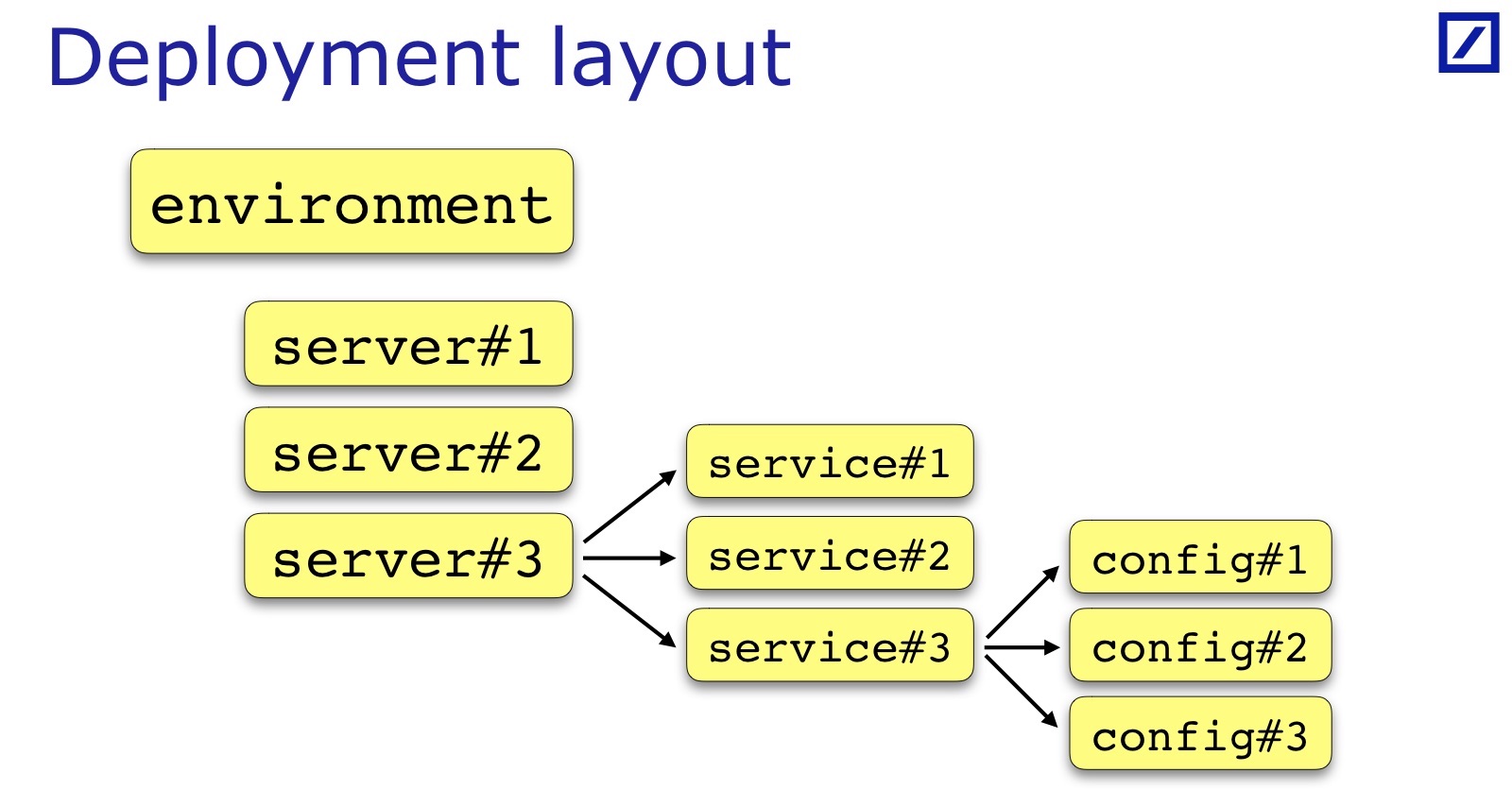
Wir benötigen eine Möglichkeit aus dem Code, um Zugriff auf die Bereitstellung der Anwendung zu erhalten: Auf welchen Servern, welche Dienste, in welcher Umgebung, um diese Datenstruktur abzurufen. Und von dort aus beginne ich, die Konfiguration zu laden und zu verarbeiten.
Das Bereitstellungslayout ist für jedes Team und jedes Projekt spezifisch. Ich habe gezeichnet - dies ist ein allgemeiner Fall: Normalerweise gibt es eine Reihe von Servern, Diensten, ein Dienst hat manchmal eine Reihe von Konfigurationsdateien und nicht nur eine. Manchmal sind zusätzliche Parameter erforderlich, die für Tests nützlich sind. Sie müssen hinzugefügt werden. Beispielsweise kann das Rack wichtig sein, in dem sich der Server befindet. Andrey gab in seinem Bericht ein Beispiel, als es für ihre Dienste wichtig war, dass sich Backup- / Primärdienste in verschiedenen Racks befinden müssen. In seinem Fall müsste er im Bereitstellungslayout einen Verweis auf das Rack beibehalten:
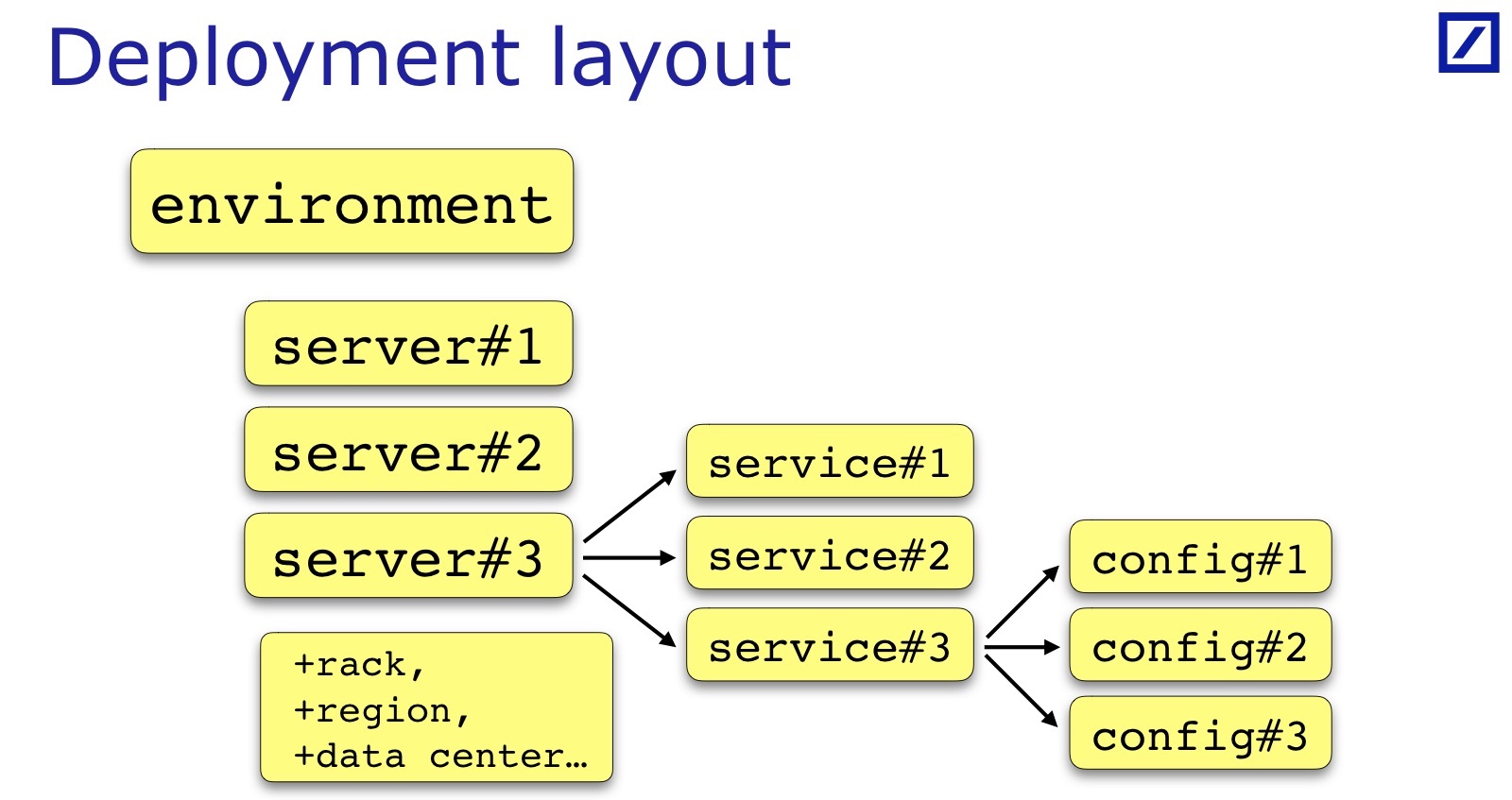
Für unsere Zwecke ist die Serverregion wichtig, im Prinzip auch das spezifische Rechenzentrum, damit sich Backup / Primary in verschiedenen Rechenzentren befinden. Dies sind alles zusätzliche Servereigenschaften, sie sind projektspezifisch, aber auf der Folie ist dies ein gemeinsamer Nenner.
Wo bekomme ich das Bereitstellungslayout? Es scheint, dass es in jedem großen Unternehmen ein Infrastruktur-Management-System gibt, alles wird dort beschrieben, es ist zuverlässig, zuverlässig und all das ... eigentlich nicht.
Zumindest hat meine Praxis in zwei Projekten gezeigt, dass es einfacher ist, zuerst fest zu codieren und dann nach drei Jahren ... harthäutig zu bleiben.
Wir leben jetzt seit drei Jahren mit diesem Projekt. Im zweiten Fall scheinen wir uns in einem Jahr noch in das Infrastrukturmanagement zu integrieren, aber all diese Jahre haben wir so gelebt. Aus Erfahrung ist es sinnvoll, die Aufgabe der Integration in IM zu verschieben, um so schnell wie möglich vorgefertigte Tests zu erhalten, die zeigen, dass sie funktionieren und nützlich sind. Und dann kann sich herausstellen, dass diese Integration möglicherweise nicht so notwendig ist, da die Verteilung der Dienste auf die Server nicht so häufig geändert wird.
Hardcode kann buchstäblich so sein:
public enum Environment { PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP, PROD_US_PRIMARY, PROD_US_BACKUP, PROD_SG_PRIMARY, PROD_SG_BACKUP ) … public Server[] servers() {…} } public enum Server { PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"), PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"), PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"), public Service[] services() {…} }
Der einfachste Weg, den wir in unserem ersten Projekt verwenden, besteht darin, Environment mit einer Liste von Servern in jedem von ihnen aufzulisten. Es gibt eine Liste von Servern und anscheinend sollte es eine Liste von Diensten geben, aber wir haben betrogen: Wir haben Startskripte (die auch Teil der Konfiguration sind).

Sie führen Dienste für jede Umgebung aus. Und die services () -Methode greift einfach alle Dienste aus der Datei ihres Servers auf. Dies geschieht, weil es nicht so viele Umgebungen gibt und Server auch selten hinzugefügt oder gelöscht werden - aber es gibt viele Dienste, und sie werden ziemlich oft gemischt. Es war sinnvoll, das eigentliche Layout von Diensten aus Skripten zu laden, um das fest codierte Layout nicht zu oft zu ändern.
Nach dem Erstellen eines solchen Softwarekonfigurationsmodells erscheinen angenehme Boni. Sie können beispielsweise einen Test wie folgt schreiben:

Der Test ist, dass in jeder Umgebung alle wichtigen Dienste vorhanden sind. Angenommen, es gibt vier Schlüsseldienste, und der Rest kann oder kann nicht sein, aber ohne diese vier macht es keinen Sinn. Sie können überprüfen, ob Sie sie nirgendwo vergessen haben und ob sie alle Backups in derselben Umgebung haben. In den meisten Fällen treten solche Fehler beim Konfigurieren der UAT dieser Instanzen auf, sie können jedoch auch in PROD übertragen werden. Letztendlich verschwenden Fehler in der UAT auch Zeit und Nerven der Tester.
Es stellt sich die Frage, ob die Relevanz des Konfigurationsmodells erhalten bleibt. Sie können auch einen Test dafür schreiben.
public class HardCodedLayoutConsistencyTest { @Theory eachHardCodedEnvironmentHasConfigFiles(Environment env){ … } @Theory eachConfigFileHasHardCodedEnvironment(File configFile){ … } }
Es gibt Konfigurationsdateien und ein Bereitstellungslayout im Code. Und Sie können dies für jede Umgebung / jeden Server / usw. überprüfen. Es gibt eine entsprechende Konfigurationsdatei und für jede Datei des erforderlichen Formats die entsprechende Umgebung. Sobald Sie vergessen haben, etwas an einer Stelle hinzuzufügen, wird der Test fallen.
Das Endergebnis ist das Bereitstellungslayout:
- Vereinfacht das Schreiben komplexer Tests, bei denen Konfigurationen aus verschiedenen Teilen der Anwendung zusammengeführt werden.
- Macht sie klarer und lesbarer. Sie sehen so aus, wie Sie auf hohem Niveau über sie denken, und nicht so, wie sie Konfigurationen durchlaufen.
- Wenn Leute während der Erstellung Fragen stellen, werden viele interessante Dinge über die Bereitstellung herausgestellt. Einschränkungen, implizites heiliges Wissen, ergeben sich beispielsweise hinsichtlich der Möglichkeit, zwei Umgebungen auf einem Server zu hosten. Es stellt sich heraus, dass die Entwickler anders denken und ihre Dienste entsprechend schreiben. Und solche Momente sind nützlich, um sich zwischen den Entwicklern zu einigen.
- Ergänzt die Dokumentation gut (besonders wenn dies nicht der Fall ist). Selbst wenn dies der Fall ist, ist es für mich als Entwickler angenehmer, dies im Code zu sehen. Außerdem können Sie dort Kommentare schreiben, die mir wichtig sind, und nicht jemand anderem. Und Sie können auch fest codieren. Wenn Sie also entscheiden, dass sich nicht zwei Umgebungen auf demselben Server befinden können, können Sie eine Prüfung einfügen, die jetzt nicht mehr ausgeführt wird. Zumindest werden Sie herausfinden, ob es jemand versucht. Das heißt, dies ist eine Dokumentation mit der Fähigkeit, sie durchzusetzen. Das ist sehr hilfreich.
Lass uns weitermachen. Nachdem die Tests geschrieben wurden, haben sie sich ein Jahr lang „niedergelassen“, einige beginnen zu fallen. Einige beginnen früher zu fallen, aber es ist nicht so beängstigend. Es ist beängstigend, wenn ein vor einem Jahr geschriebener Test fällt, Sie sich die Fehlermeldung ansehen und nicht verstehen.

Angenommen, ich verstehe und stimme zu, dass dies ein ungültiger Netzwerkport ist - aber wo ist er? Vor dem Vortrag habe ich mir die Tatsache angesehen, dass das Projekt 1.200 Eigenschaftendateien enthält, die auf 90 Module verteilt sind und insgesamt 24.000 Zeilen enthalten. (Ich war zwar überrascht, aber wenn Sie zählen, dann ist dies keine so große Zahl - für einen Dienst für 4 Dateien.) Wo ist dieser Port?
Es ist klar, dass assertThat () ein Nachrichtenargument enthält. Sie können etwas eingeben, das zur Identifizierung des Ortes beiträgt. Aber wenn Sie einen Test schreiben, denken Sie nicht darüber nach. Und selbst wenn Sie denken, müssen Sie noch raten, welche Beschreibung detailliert genug ist, um in einem Jahr verstanden zu werden. Ich möchte diesen Moment automatisieren, damit es eine Möglichkeit gibt, Tests mit automatischer Generierung einer mehr oder weniger klaren Beschreibung zu schreiben, anhand derer Sie einen Fehler finden können.
Wieder träumte und träumte ich von so etwas:
SELECT environment, server, component, configLocation, propertyName, propertyValue FROM configuration(environment, server, component) WHERE propertyName like “%.port%” and propertyValue is not validNetworkPort()
Das ist so ein Pseudo-SQL - nun, ich kenne nur SQL, und das Gehirn hat die Lösung aus dem Vertrauten herausgeworfen. Die Idee ist, dass die meisten Konfigurationstests aus mehreren Teilen desselben Typs bestehen. Zunächst wird eine Teilmenge von Parametern durch die Bedingung ausgewählt:

In Bezug auf diese Teilmenge überprüfen wir dann etwas in Bezug auf den Wert:

Und wenn es Eigenschaften gibt, deren Werte den Wunsch nicht erfüllen, ist dies das „Blatt“, das wir in der Fehlermeldung erhalten möchten:

Einmal dachte ich sogar, ich könnte einen Parser wie SQL schreiben, da es jetzt nicht schwierig ist. Aber dann wurde mir klar, dass die IDE dies nicht unterstützt und vorschlägt, sodass die Leute blind auf dieses selbst erstellte „SQL“ schreiben müssen, ohne IDE-Eingabeaufforderungen, ohne Kompilierung, ohne Überprüfung - dies ist nicht sehr praktisch. Daher musste ich nach Lösungen suchen, die von unserer Programmiersprache unterstützt werden. Wenn wir .NET hätten, würde LINQ helfen, es ist fast SQL-ähnlich.
In Java gibt es keinen LINQ, so nah wie möglich an Streams. So sollte dieser Test in Streams aussehen:
ValueWithContext[] incorrectPorts = flattenedProperties( environment ) .filter( propertyNameContains( ".port" ) ) .filter( !isInteger( propertyValue ) || !isValidNetworkPort( propertyValue ) ) .toArray(); assertThat( incorrectPorts, emptyArray() );
flattenedProperties () übernimmt alle Konfigurationen dieser Umgebung, alle Dateien für alle Server, Dienste und erweitert sie zu einer großen Tabelle. Dies ist im Wesentlichen eine SQL-ähnliche Tabelle, jedoch in Form einer Reihe von Java-Objekten. Und flattenedProperties () gibt diesen Satz von Zeichenfolgen als Stream zurück.

Anschließend fügen Sie einige Bedingungen für diesen Satz von Java-Objekten hinzu. In diesem Beispiel: Wir wählen diejenigen aus, die "property" im propertyName enthalten, und filtern diejenigen, bei denen die Werte nicht in Integer konvertiert werden oder nicht aus dem gültigen Bereich. Dies sind fehlerhafte Werte, und theoretisch sollten sie eine leere Menge sein.

Wenn es sich nicht um eine leere Menge handelt, wird ein Fehler ausgegeben, der folgendermaßen aussieht:

Teil 3. Testen als Unterstützung für das Refactoring
In der Regel ist das Testen von Code eine der leistungsstärksten Refactoring-Unterstützungen. Refactoring ist ein gefährlicher Prozess, viel Wiederherstellen, und ich möchte sicherstellen, dass die Anwendung danach noch funktionsfähig ist. Eine Möglichkeit, dies sicherzustellen, besteht darin, zuerst alles mit Tests auf allen Seiten zu überlagern und dann damit umzugestalten.
Und jetzt war vor mir die Aufgabe, die Konfiguration zu überarbeiten. Es gibt eine Anwendung, die vor sieben Jahren von einer klugen Person geschrieben wurde. Die Konfiguration dieser Anwendung sieht ungefähr so aus:

Dies ist ein Beispiel, es gibt noch viel mehr. Dreifache Verschachtelungspermutationen, die in der gesamten Konfiguration verwendet werden:

Die Konfiguration selbst enthält nur wenige Dateien, die jedoch ineinander enthalten sind. Es verwendet eine kleine Erweiterung von iu Properties - Apache Commons Configuration, die nur Einschlüsse und Berechtigungen in geschweiften Klammern unterstützt.
Und der Autor hat mit genau diesen beiden Dingen einen fantastischen Job gemacht. Ich glaube, er hat dort eine Turing-Maschine gebaut. An einigen Stellen scheint es wirklich so, als würde er versuchen, Berechnungen mit Einschlüssen und Substitutionen durchzuführen. Ich weiß nicht, ob dieses Turing-System vollständig ist, aber er hat meiner Meinung nach versucht, dies zu beweisen.
Und der Mann ging. Schrieb, die Anwendung funktioniert, und er verließ die Bank. Alles funktioniert, nur niemand versteht die Konfiguration vollständig.
Wenn wir einen separaten Service in Anspruch nehmen, ergeben sich 10 Einschlüsse mit dreifacher Tiefe und insgesamt 450 Parameter, wenn alles erweitert wird. Tatsächlich verwendet dieser bestimmte Dienst 10-15% von ihnen, der Rest der Parameter bezieht sich auf andere Dienste, da die Dateien gemeinsam genutzt werden und von mehreren Diensten verwendet werden. Aber was genau 10-15% diesen speziellen Service nutzen, ist nicht so einfach zu verstehen. Der Autor hat anscheinend verstanden. Sehr kluge Person, sehr.
Die Aufgabe bestand jeweils darin, die Konfiguration und das Refactoring zu vereinfachen. Gleichzeitig wollte ich die Anwendung am Laufen halten, da in dieser Situation die Chancen dafür gering sind. Ich möchte:
- Vereinfachen Sie die Konfiguration.
- Damit hat jeder Service nach dem Refactoring noch alle notwendigen Parameter.
- Damit er keine zusätzlichen Parameter hat. 85% derjenigen, die nichts damit zu tun haben, sollten die Seite nicht überladen.
- Diese Dienste waren immer noch erfolgreich in Clustern verbunden und führten eine Zusammenarbeit durch.
Das Problem ist, dass nicht bekannt ist, wie gut sie sich jetzt verbinden, da das System hochredundant ist. Mit Blick auf die Zukunft: Während des Refactorings stellte sich heraus, dass in einer der Produktionskonfigurationen vier Server im Sicherungsclip enthalten sein sollten, tatsächlich waren es jedoch zwei. Aufgrund des hohen Redundanzniveaus bemerkte dies niemand - der Fehler trat versehentlich auf, aber tatsächlich war das Redundanzniveau lange Zeit niedriger als erwartet. Der Punkt ist, dass wir uns nicht darauf verlassen können, dass die aktuelle Konfiguration überall korrekt ist.
Ich führe dazu, dass Sie die neue Konfiguration nicht einfach mit der alten vergleichen können. Es mag gleichwertig sein, bleibt aber gleichzeitig irgendwo falsch. Es ist notwendig, den logischen Inhalt zu überprüfen.
Minimales Programm: Isolieren Sie jeden einzelnen Parameter jedes benötigten Dienstes und überprüfen Sie die Richtigkeit, ob Port ein Port ist, Adresse eine Adresse ist, TTL eine positive Zahl ist usw. Überprüfen Sie auch die Schlüsselbeziehungen, die Dienste im Wesentlichen an den Hauptendpunkten verbinden. Zumindest wollte ich das erreichen. Das heißt, im Gegensatz zu den vorherigen Beispielen besteht die Aufgabe hier nicht darin, einzelne Parameter zu überprüfen, sondern die gesamte Konfiguration mit einem vollständigen Netzwerk von Überprüfungen abzudecken.
Wie teste ich es?
public class SimpleComponent { … public void configure( final Configuration conf ) { int port = conf.getInt( "Port", -1 ); if( port < 0 ) throw new ConfigurationException(); String ip = conf.getString( "Address", null ); if( ip == null ) throw new ConfigurationException(); … } … }
Wie habe ich dieses Problem gelöst? Es gibt eine einfache Komponente, im Beispiel ist sie maximal vereinfacht. (Für diejenigen, die nicht auf Apache Commons Configuration gestoßen sind: Das Konfigurationsobjekt ist wie Eigenschaften, nur hat es noch die typisierten Methoden getInt (), getLong () usw .; Wir können davon ausgehen, dass dies juProperties für kleine Steroide sind.) Angenommen, eine Komponente benötigt zwei Parameter: beispielsweise eine TCP-Adresse und einen TCP-Port. Wir ziehen sie heraus und überprüfen. Was sind die vier gemeinsamen Teile hier?

Dies sind der Parametername, der Typ, die Standardwerte (hier sind sie trivial: null und -1, manchmal gibt es vernünftige Werte) und einige Validierungen. Der Port hier wird zu einfach und unvollständig validiert. Sie können den Port angeben, der ihn passieren soll, aber kein gültiger Netzwerkport ist. Deshalb möchte ich auch diesen Moment verbessern. Aber zuerst möchte ich diese vier Dinge in eine Sache verwandeln. Zum Beispiel:
IProperty<Integer> PORT_PROPERTY = intProperty( "Port" ) .withDefaultValue( -1 ) .matchedWith( validNetworkPort() ); IProperty<String> ADDRESS_PROPERTY = stringProperty( "Address" ) .withDefaultValue( null ) .matchedWith( validIPAddress() );
Ein solches zusammengesetztes Objekt ist eine Beschreibung einer Eigenschaft, deren Name und Standardwert eine Validierung durchführen können (hier verwende ich erneut den Hamcrest-Matcher). Und dieses Objekt hat so etwas wie diese Schnittstelle:
interface IProperty<T> { FetchedValue<T> fetch( final Configuration config ) } class FetchedValue<T> { public final String propertyName; public final T propertyValue; … }
Das heißt, nachdem Sie ein für eine bestimmte Implementierung spezifisches Objekt erstellt haben, können Sie ihn bitten, den von ihm dargestellten Parameter aus der Konfiguration zu extrahieren. Und er wird diesen Parameter herausziehen, den Prozess überprüfen, wenn es keinen Parameter gibt, wird er einen Standardwert angeben, zum gewünschten Typ führen und ihn sofort mit dem Namen zurückgeben.
Das heißt, hier ist der Name des Parameters und ein solcher tatsächlicher Wert, dass der Dienst sieht, ob er von dieser Konfiguration anfordert. Auf diese Weise können Sie mehrere Codezeilen in eine Entität einschließen. Dies ist die erste Vereinfachung, die ich benötige.
Die zweite Vereinfachung, die ich zur Lösung des Problems benötigte, bestand darin, eine Komponente einzuführen, die für ihre Konfiguration mehrere Eigenschaften benötigt. Komponentenkonfigurationsmodell:

Wir hatten eine Komponente, die diese beiden Eigenschaften verwendete. Es gibt ein Modell für ihre Konfiguration - die IConfigurationModel-Schnittstelle, die diese Klasse implementiert. IConfigurationModel erledigt alles, was die Komponente tut, aber nur den Teil, der sich auf die Konfiguration bezieht. Wenn die Komponente Parameter in einer bestimmten Reihenfolge mit bestimmten Standardwerten benötigt, kombiniert IConfigurationModel diese Informationen in sich selbst und kapselt sie. Alle anderen Aktionen der Komponente sind für ihn nicht wichtig. Dies ist ein Komponentenmodell für den Konfigurationszugriff.

Der Trick dieser Ansicht ist, dass die Modelle kombinierbar sind. Wenn es eine Komponente gibt, die andere Komponenten verwendet und diese dort kombiniert werden, kann das Modell dieser komplexen Komponente auf die gleiche Weise die Ergebnisse von Aufrufen zweier Unterkomponenten zusammenführen.
Das heißt, es ist möglich, eine Hierarchie von Konfigurationsmodellen parallel zur Hierarchie der Komponenten selbst zu erstellen. Rufen Sie im oberen Modell fetch () auf, um das Blatt aus den Parametern zurückzugeben, die er aus der Konfiguration mit ihren Namen abgerufen hat - genau die, die die entsprechende Komponente in Echtzeit benötigt. Wenn wir alle Modelle richtig geschrieben haben, natürlich.
Das heißt, die Aufgabe besteht darin, solche Modelle für jede Komponente in der Anwendung zu schreiben, die Zugriff auf die Konfiguration hat. In meiner Anwendung gab es einige solcher Komponenten: Die Anwendung selbst ist ziemlich belaubt, verwendet den Code jedoch aktiv wieder, sodass nur 70 Hauptklassen konfiguriert sind. Für sie musste ich 70 Modelle schreiben.
Was es gekostet hat:
- 12 Dienstleistungen
- 70 konfigurierbare Klassen
- => 70 Konfigurationsmodelle (~ 60 sind trivial);
- 1-2 Personenwochen.
Ich habe einfach den Bildschirm mit dem Komponentencode geöffnet, der sich selbst konfiguriert, und auf dem nächsten Bildschirm habe ich den Code für das entsprechende Konfigurationsmodell geschrieben. Die meisten von ihnen sind trivial, wie das gezeigte Beispiel. In einigen Fällen gibt es Verzweigungen und bedingte Übergänge - dort wird der Code verzweigter, aber alles ist auch gelöst. In anderthalb bis zwei Wochen habe ich dieses Problem gelöst, für alle 70 Komponenten habe ich die Modelle beschrieben.
Wenn wir alles zusammenfügen, erhalten wir den folgenden Code:

Für jeden Service / jede Umgebung / etc. Wir nehmen das Konfigurationsmodell, dh den obersten Knoten dieses Baums, und bitten darum, alles aus der Konfiguration zu erhalten. Zu diesem Zeitpunkt werden alle Überprüfungen durchgeführt. Wenn sich eine der Eigenschaften aus der Konfiguration herauszieht, überprüft sie ihren Wert auf Richtigkeit. Wenn mindestens einer nicht bestanden wird, wird eine Ausnahme ausgelöst. Der gesamte Code wird erhalten, indem überprüft wird, ob alle Werte isoliert gültig sind.
Service-Abhängigkeiten
Wir hatten immer noch eine Frage, wie die gegenseitige Abhängigkeit von Diensten überprüft werden kann. Dies ist etwas komplizierter. Sie müssen sich ansehen, welche Art von gegenseitiger Abhängigkeit es gibt. Es stellte sich für mich heraus, dass die gegenseitigen Abhängigkeiten darauf zurückzuführen sind, dass sich Dienste auf Netzwerkendpunkten „treffen“ sollten. Dienst A sollte genau die Adresse abhören, an die Dienst B Pakete sendet, und umgekehrt. In meinem Beispiel sind alle Abhängigkeiten zwischen den Konfigurationen verschiedener Dienste darauf zurückzuführen. Es war möglich, dieses Problem auf so einfache Weise zu lösen: Ports und Adressen von verschiedenen Diensten abrufen und überprüfen. Es würde viele Tests geben, sie wären sperrig. Ich bin eine faule Person und ich wollte das nicht. Deshalb habe ich es anders gemacht.
Erstens wollte ich diesen Netzwerkendpunkt selbst irgendwie abstrahieren. Für eine TCP-Verbindung benötigen Sie beispielsweise nur zwei Parameter: Adresse und Port. Für eine Multicast-Verbindung vier Parameter. Ich würde es gerne in eine Art Objekt zusammenbrechen lassen. Ich habe dies im Endpoint-Objekt getan, das alles verbirgt, was Sie brauchen. Die Folie ist ein Beispiel für OutcomingTCPEndpoint, eine ausgehende TCP-Netzwerkverbindung.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
Endpoint matches(), Endpoint, , .
« »? , : , , - , — . , , / . , , .
Dementsprechend haben wir anstelle primitiver Eigenschaftswerte, Portadressen-Multicast-Gruppen jetzt eine komplexe Eigenschaft, die Endpoint zurückgibt. Und in allen ConfigurationModels gibt es anstelle separater Eigenschaften so komplexe. Was gibt uns das? Dies gibt uns diese Art der Cluster-Konnektivitätsprüfung: ValueWithContext[] allEndpoints = flattenedConfigurationValues(environment) .filter( valueIsEndpoint() ) .toArray(); ValueWithContext[] unpairedEndpoints = Arrays.stream( allEndpoints ) .filter( e -> !hasMatchedEndpoint(e, allEndpoints) ) .toArray(); assertThat( unpairedEndpoints, emptyArray() );
environment' endpoint', , , , . . « » O(n^2), , endpoint' , .
Endpoint , , . , , - .
, , , «» — , . . , , . , .
. , , . , , , c, , .
ConfigurationModel :
, . , , , — . : , . , , , , .
Das reicht aber nicht.
Mit diesem Konstrukt kann ich mithilfe von ConfigurationModels Konfigurationsanforderungen ausführen. Heben Sie es in den Speicher und finden Sie heraus, welche bestimmten UDP-Ports auf diesem Server von verschiedenen Diensten verwendet werden. Fordern Sie eine Liste der verwendeten Ports mit den Anweisungen der Dienste an.Darüber hinaus kann ich die Dienste auf Endpunkten verbinden und in Form eines Diagramms anzeigen, nach .dot exportieren. Und andere ähnliche Anfragen sind leicht zu stellen. Das Ergebnis war ein solches Schweizer Messer - die Baukosten haben sich recht gut ausgezahlt.Hier höre ich auf. Schlussfolgerungen:
- Meiner Meinung nach ist das Testen der Konfiguration wichtig und macht Spaß.
- Es gibt viele niedrig hängende Früchte, die Eintrittsschwelle für einen Start ist niedrig. Sie können komplexe Probleme lösen, aber es gibt auch viele einfache.
- , , , .
Heisenbug 2018 Piter , : 6-7 Heisenbug . . 1 — .